2023-10-31 06:29:16 Author: blogs.sap.com(查看原文) 阅读量:7 收藏
Some customers have specific requirements regarding the search relevancy with SOLR.
For instance we have a customer who found out that some use cases are stil missing after trying different standard stemmers for French : SnowballPorterFilterFactory, FrenchLightStemFilterFactory, FrenchMinimalStemFilterFactory
In order to address the missing use cases, we identified that it was necessary to create a custom stemmer which is based on the standard FrenchMinimalStemmer but less agressive.
Algorithm
Custom French Stemmer to handle customer specific requirements
- keeps the standard behaviour of FrenchMinimalStemmer for
- Removal of ‘s’ for plural
- Removal of ‘x’ for plural in some cases
- Transformation of plural ‘aux’ to singular ‘al’
- Handle duplicates letter in the end of the word
- In addition, the custom stemmer should change the following
- Non-removal of ‘r’ at the end of the word (No stemmer for verbs)
- Non-removal of ‘e’ for feminine at the end of the word if the pervious letter is ‘s’ (liasse not transformed into lias) or ‘r’ (timbre not transformed into ‘timbr’ )
Implementation
-
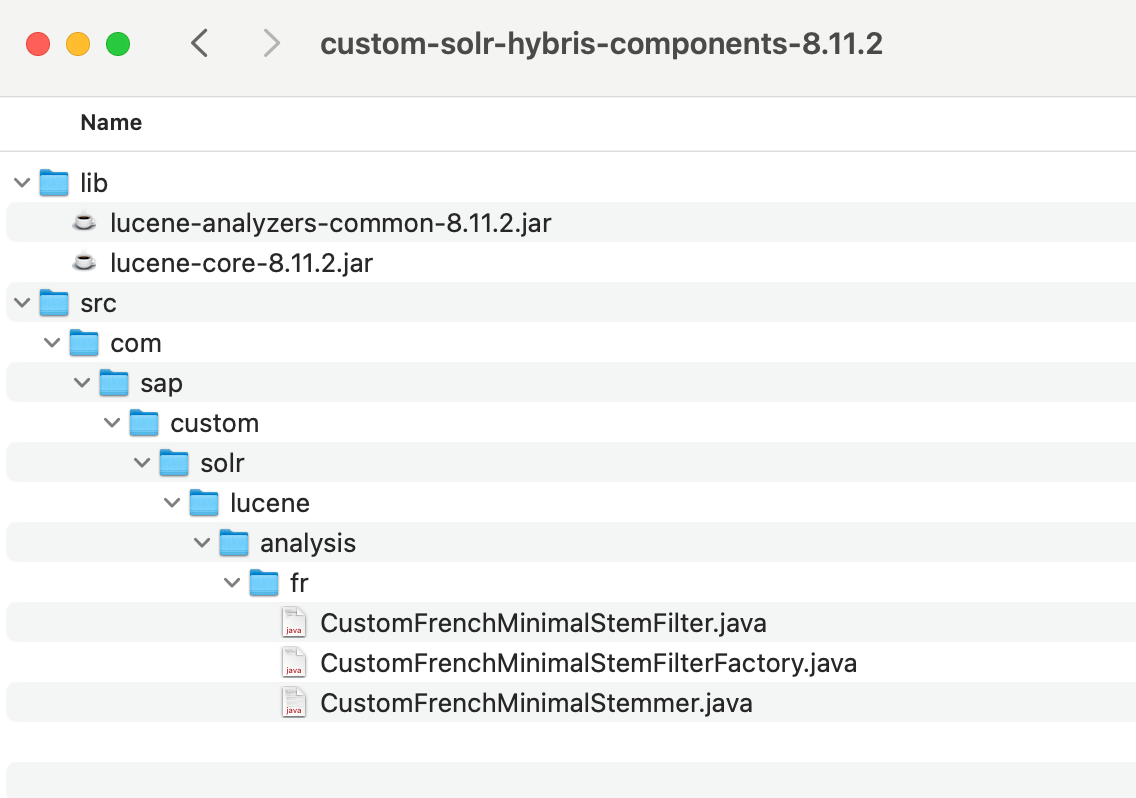
Create a Java Module custom-solr-hybris-components-8.11.2
- Add dependencies to the libraries lucene-core-8.11.2.jar and lucene-analyzers-common-8.11.2.jar
- Create the following classes based on the standard stemmer FrenchMinimalStemmer
-
CustomFrenchMinimalStemFilterFactory contains similar code as FrenchMinimalStemFilterFactory, the only difference is the references to custom classes
package com.sap.custom.solr.lucene.analysis.fr; import java.util.Map; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.fr.FrenchMinimalStemFilter; import org.apache.lucene.analysis.util.TokenFilterFactory; public class CustomFrenchMinimalStemFilterFactory extends TokenFilterFactory { public static final String NAME = "customFrenchMinimalStem"; public CustomFrenchMinimalStemFilterFactory(Map<String, String> args) { super(args); if (!args.isEmpty()) { throw new IllegalArgumentException("Unknown parameters: " + args); } } public TokenStream create(TokenStream input) { return new CustomFrenchMinimalStemFilter(input); } } -
CustomFrenchMinimalStemFilter contains similar code as FrenchMinimalStemFilter, the only difference is the references to custom classes
package com.sap.custom.solr.lucene.analysis.fr; import java.io.IOException; import org.apache.lucene.analysis.TokenFilter; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.apache.lucene.analysis.tokenattributes.KeywordAttribute; public final class CustomFrenchMinimalStemFilter extends TokenFilter { private final CustomFrenchMinimalStemmer stemmer = new CustomFrenchMinimalStemmer(); private final CharTermAttribute termAtt = (CharTermAttribute)this.addAttribute(CharTermAttribute.class); private final KeywordAttribute keywordAttr = (KeywordAttribute)this.addAttribute(KeywordAttribute.class); public CustomFrenchMinimalStemFilter(TokenStream input) { super(input); } public boolean incrementToken() throws IOException { if (this.input.incrementToken()) { if (!this.keywordAttr.isKeyword()) { int newlen = this.stemmer.stem(this.termAtt.buffer(), this.termAtt.length()); this.termAtt.setLength(newlen); } return true; } else { return false; } } } -
CustomFrenchMinimalStemmer is inspired from FrenchMinimalStemmer but in addition we will add the specific algorithm for customer specific requirements
package com.sap.custom.solr.lucene.analysis.fr; /** * Custom French Stemmer to handle specific requirement * - So far Handles * - * - Non-removal of 'r' at the end of the word (No stemmer for verbs) * - Non-removal of 'e' for feminin at the end of the word if the pervious letter is * 's' (liasse not transformed into lias) or * 'r' (timbre not transformed in 'timbr') or * 'i' (monnaie not transformed in 'monnaie') or * 't' (porte not transformed in 'port') * - Transformation of plural 'aux' to singular 'al' except for token finishing with 'eaux' * - otherwise it keeps the algorithm of FrenchMinimalStemmer by * - Removal of 's' for plural * - Removal of 'x' for plural for some cases * - To be enriched with additional specific requirements * */ public class CustomFrenchMinimalStemmer { public CustomFrenchMinimalStemmer() { } public int stem(char[] s, int len) { if (len < 5) { // Change Standard FrenchMinimalStemmer use 5 instead of 6 for token length return len; } else if (s[len - 1] == 'x') { // Change Standard FrenchMinimalStemmer handle plural with aux (-> al) and remove 'x' for some cases (ignore words finishing with '-eaux') // if ends with 'aux' replace 'aux' by 'al' except for 'eaux' if (s[len - 3] == 'a' && s[len - 2] == 'u' && s[len - 4] != 'e') { s[len - 2] = 'l'; } // Otherwise juste remove 'x' return len - 1; } else { // Keep the Standard FrenchMinimalStemmer remove 's' for plural if (s[len - 1] == 's') { --len; } // Change Standard FrenchMinimalStemmer - Remove 'r' for verbs at the end - Customization cancel this rule to keep the 'r' /* if (s[len - 1] == 'r') { --len; }*/ // Change Standard FrenchMinimalStemmer - Customization Remove 'e' for feminine if (s[len - 1] == 'e') { //Remove "e" only if the previous letter is not s or r or i or t if(s[len - 2] != 's' && s[len - 2] != 'r' && s[len - 2] != 'i' && s[len - 2] != 't') { --len; } } // Keep the Standard FrenchMinimalStemmer if (s[len - 1] == 233) { --len; } // Keep the Standard FrenchMinimalStemmer - remove duplicated letters at the end of the word (ex. timbree -> timbre, timbress -> timbres) if (s[len - 1] == s[len - 2]) { --len; } return len; } } } - Only this class needs to be modified if we want to enrich the stemming algorithm
-
- Module should look as follow

- Now that we created the custom stemmer, we need to create a JAR to be deployed locally and on the cloud
- Create an artifact for the module on IntelliJ
- Once the build is finished the JAR (custom-solr-hybris-components-8.11.2.jar) is generated in the folder out/artifacts/custom_solr_hybris_components_8_11_2_jar
Deploy on Local Environment
- Deploy the jar locally, by placing it under hybris/bin/modules/search-and-navigation/solrserver/resources/solr/8.11/server/contrib/hybris/lib (This could be done using antcallback or ant customize)
- Configure schema.xml (under core-customize/hybris/config/solr/instances/default/configsets/default/conf) with the new custom stemmer
<fieldType name="text_fr" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> [...] <!-- <filter class="solr.SnowballPorterFilterFactory" language="French" />--> <!-- <filter class="solr.FrenchLightStemFilterFactory" /> --> <!-- <filter class="solr.FrenchMinimalStemFilterFactory" /> --> <!-- <filter class="solr.ASCIIFoldingFilterFactory" /> --> <filter class="com.sap.custom.solr.lucene.analysis.fr.CustomFrenchMinimalStemFilterFactory" /> [...] </analyzer> <analyzer type="query"> [...] <!-- <filter class="solr.SnowballPorterFilterFactory" language="French" />--> <!-- <filter class="solr.FrenchLightStemFilterFactory" /> --> <!-- <filter class="solr.FrenchMinimalStemFilterFactory" /> --> <!-- <filter class="solr.ASCIIFoldingFilterFactory" /> --> <filter class="com.sap.custom.solr.lucene.analysis.fr.CustomFrenchMinimalStemFilterFactory" /> [...] </analyzer> </fieldType> - Compile and start the server
- Test the stemmer on SOLR console
- In case there is an issue with the loading the stemmer class, you will see a message error on solr console(you can also check the solr log file solr.log under core-customize/hybris/log/solr/instances/default/)
- Otherwise you will be able to analyse the tokens with type name_text with the custom stemmer
Deploy on the Cloud
To deploy on the cloud you will need to place the generated jar custom-solr-hybris-components-8.11.2.jar under the folder core-customize/<solr_folder>/contrib/hybris/lib
Automation of Jar Generation & Deployment
In order to integrate the SOLR customisations within SAP Commerce CI/CD in an automatic way, we could proceed as follow
- Create a custom extension based on yempty template (→ ant extgen)
- Move the source code of the stemmer (classes, libraries) to the custom extension
- Change buildcallback.xml of the custom extension by adding the following targets
- Compile the custom stemmer classes
- Generate an output JAR out of the bin classes
- Copy the jar under cloud solr folder (<solr_folder>/contrib/hybris/lib)
SOLR is a powerful tool when it come to language processing and word stemming with several out of the box filters, tokenisers and stemmers. However, it can happen sometimes that customers are not satisfied with the relevance of the results provided by SOLR especially for some specific terms largely used in their websites.
This article will allow customers to create their own stemmers by inspiring from standard ones and test the search relevance based on their specific requirements when the standard stemmers do not fit their expectations.
如有侵权请联系:admin#unsafe.sh