
By Nat Chin
Welcome to our deep dive into the world of invariant development with Curvance.
We’ve been building invariants as part of regular code review assessments for more than 6 years now, but our work with Curvance marks our very first official invariant development project, in which developing and testing invariants is all we did.
Over the nine-week engagement, we wrote and tested 216 invariants, which helped us uncover 13 critical findings. We also found opportunities to significantly enhance our tools, including advanced trace printing and corpus preservation. This project was a journey of navigating learning curves and accomplishing technological feats, and this post will highlight our collaborative efforts and the essential role of teamwork in helping us meet the challenge. And yes, we’ll also touch on the brain-cell-testing moments we experienced throughout this project!
A collective “losing it” moment, capturing the challenges of this project
Creating a quality fuzzing suite
The success of a fuzzing suite is grounded in the quality of its invariants. Throughout this project, we focused on fine-tuning each invariant for accuracy and relevance. Fuzzing, in essence, is like having smart monkeys on keyboards testing invariants, whose effectiveness relies heavily on their precision. Our journey with Curvance over nine weeks involved turning in-depth discussions on codebase properties into precise English explanations and then coding them into executable tests, as shown in the screenshots below.
Examples of what our daily discussions looked like to clarify invariants
From the get-go, Chris from Curvance was often available to help clarify the code’s expected behavior and explain Curvance’s design choices. His insights always clarified complex functions and behavior, and he always helped with hands-on debugging and checking our invariants. This engagement was as productive as it was thanks to Chris’s consistent feedback and working alongside us the entire time. Thank you, Curvance!
The tools (and support teams) behind our success
Along with Curvance’s involvement, support from our internal teams behind Echidna, Medusa, and CloudExec helped our project succeed. Their swift responses to issues, especially during extensive rebases and complex debugging, were crucial. The Curvance engagement pushed these tools to their limits, and the solutions we had to come up with for the challenges we faced led to significant enhancements in these tools.
CloudExec proved invaluable for deploying long fuzzing jobs onto DigitalOcean. We integrated it with Echidna and Medusa for prolonged runs, enabling Curvance to easily set up its own future fuzzing runs. We pinpointed areas of improvement for CloudExec, such as its preservation of output data, which you can see on its GitHub issue tracker. We’ve already addressed many of these issues.
Echidna, our property-based fuzzer for Ethereum contracts, was pivotal in falsifying assertions. We first used Echidna in exploration mode to broadly cover the Curvance codebase, and then we moved into assertion mode, using anywhere from 10 million to 100 billion iterations. This intense use of Echidna throughout our nine-week engagement helped us uncover vital areas of improvement for the tool, making it easier for it to debug and retain the state of explored code areas.
Medusa, our geth-based experimental fuzzer, complemented Echidna in its coverage efforts for falsifying invariants on Curvance. Before we could use Medusa for this engagement, we needed to fix a known out-of-memory bug. The fix for this bug—along with fixes implemented in CloudExec to help it better preserve output data—critically improved the tool and helped maximize our coverage of the Curvance code. Immediately after it started running, it found a medium-severity bug in the code that Echidna had missed. (Echidna eventually found this bug after we changed the block time delay, likely due to the fuzzer’s non-determinism.)
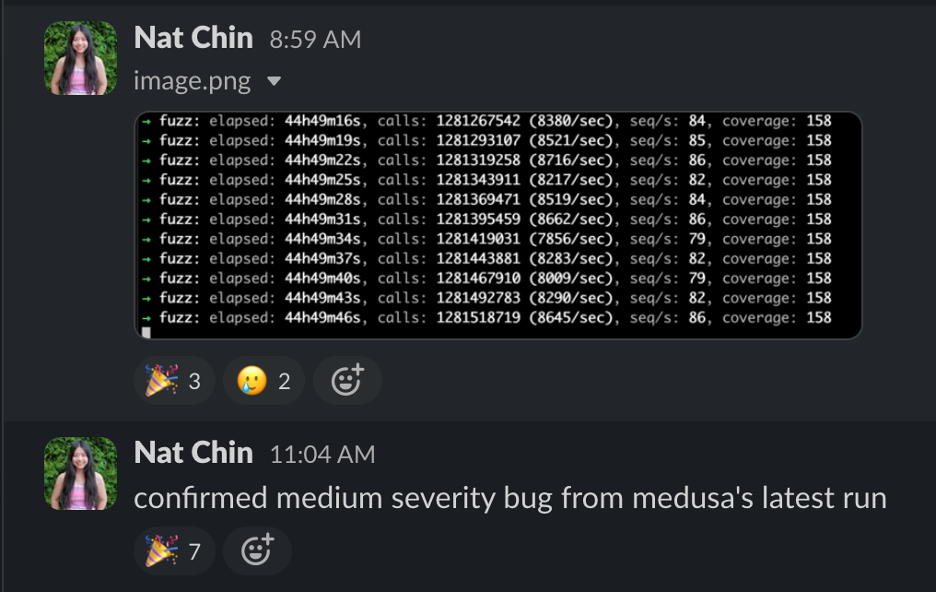
Our first Medusa run of 48+ hours resulted in a medium-severity bug.
The long and winding road
While we had the best support from the teams behind our tools and from our client that we could have asked for, we still faced considerable challenges throughout this project—from the need to keep pace with Curvance’s continued development, to the challenges of debugging assertion failures. But by meeting these challenges, we learned important lessons about the nature of invariant development, and we were able to implement crucial upgrades to our tools to improve our process overall.
Racing to keep up with Curvance’s code changes
Changes to the Curvance codebase—like function removals, additions of function parameters, adjustments to arguments and error messages, and renaming of source contracts—often challenged our fuzzing suite by invalidating existing invariants or causing a series of assertion failures. Ultimately, these changes rendered our existing corpus items obsolete and unusable, and we had to rebase our fuzzing suite and revise both existing and new invariants constantly to ensure their continued relevance to the evolving system. This iterative process paralleled the client’s code development, presenting a mix of true positives (actual bugs in the client’s code) and false positives (failures due to incorrect or outdated invariants). Such outcomes emphasized that fuzzing isn’t a static, one-time setup; it demands ongoing maintenance and updates, akin to development of any active codebase.
Understanding the rationale behind each invariant change post-rebase is crucial. Hasty adjustments without fully grasping their implications could inadvertently mask bugs, undermining the effectiveness of the fuzzing suite. Keeping the suite alive and relevant is as vital as the development of the codebase itself. It’s not just about letting the fuzzer run; it’s about maintaining its alignment with the system it tests. Remember, the true power of a fuzzing suite lies in the accuracy of its invariants.
Critical tool upgrades and lessons learned
We had to make a significant rebase after the Lendtroller contract’s name was changed to MarketManager in commit a96dc9a. This change drastically impacted our work, as Echidna had just finished 43 days of running in the cloud using CloudExec. This nonstop execution had allowed Echidna to develop a detailed corpus capable of autonomously tackling complex liquidations. Unfortunately, the change rendered this corpus obsolete, and each corpus item caused Echidna worker threads to crash upon transaction replay. With our setup of 15 workers, it took only 14 more transactions that could not be replayed for all the Echidna workers to crash, halting Echidna entirely:
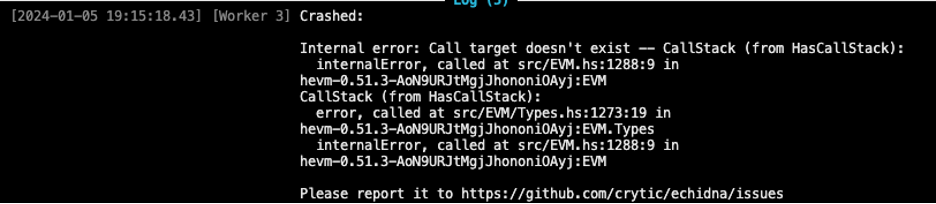
An Echidna crash resulting from not being able to replay corpus item
Our rebase due to Curvance’s code change led to a significant problem: our fuzzers could no longer access MarketManager functions needed to explore complex state, like posting collateral and borrowing debt. This issue prompted us to make crucial updates to Echidna, specifically to enhance its ability to validate and replay corpus sequences without crashing. We also made updates to Medusa to improve its tracking of corpus health and ability to fix start-up panics. Extended discussions about maintaining a dynamic corpus ensued, with our engineering director stepping in to manually adjust the corpus, offering some relief.
We shifted our strategy to adjust to the new codebase’s lack of coverage. We developed liquidation-specific invariants for the codebase version before the contract name change, while running the updated version in different modes to boost coverage. CloudExec’s new features, like named jobs, improved checkpointing of output directories, and checkpointing for failed jobs, were key in differentiating and managing these runs. Despite all these improvements, we let the old corpus go and chose to integrate setup functions into key contracts to speed up coverage. While effective in increasing coverage, this strategy introduced biases, especially in liquidation scenarios, by relying on static values. This limitation, marked in the codebase with /// @coverage:limitation tags, underscores the importance of broadening input ranges in our stateful tests to ensure comprehensive system exploration.
Trials and tribulations: Debugging
The Curvance invariant development report mainly highlights the results of our debugging without delving into the complex journey of investigation and root cause analysis behind these findings. This part of the process, involving detailed analysis once assertion failures were identified, required significant effort.
Our primary challenge was dissecting long call sequences, often ranging from 9 to 70 transactions, which required deep scrutiny to identify where errors and unexpected values crept in. Some sequences spanned up to 29 million blocks or included time delays exceeding 6 years, adding layers of complexity to our understanding of the system’s behavior. To tackle this, we had to manually insert logs for detailed state information, turning debugging into an exhaustive and manual endeavor:

Echidna’s debugging at the beginning of the engagement
Our ability to manually shrink transaction sequences hinged on our deep understanding of Curvance’s system. This detailed knowledge was critical for us to effectively identify which transactions were essential for uncovering vulnerabilities and which could be discarded. As we gained this deeper insight into the system throughout the project, our ability to streamline transaction sequences improved markedly.
Based on our work with combing through transaction sequences, we implemented a rich reproducer trace feature in Echidna, providing us with detailed traces of the system during execution and elaborate printouts of the system state at each step of the transaction failure sequence. Meanwhile, we also added shrinking limits of transaction sequences to Medusa to fix intermittent assertion failures, and we updated Medusa’s coverage report to increase its readability. The stark difference in Echidna’s trace printing after these updates can easily be seen in the figure below:
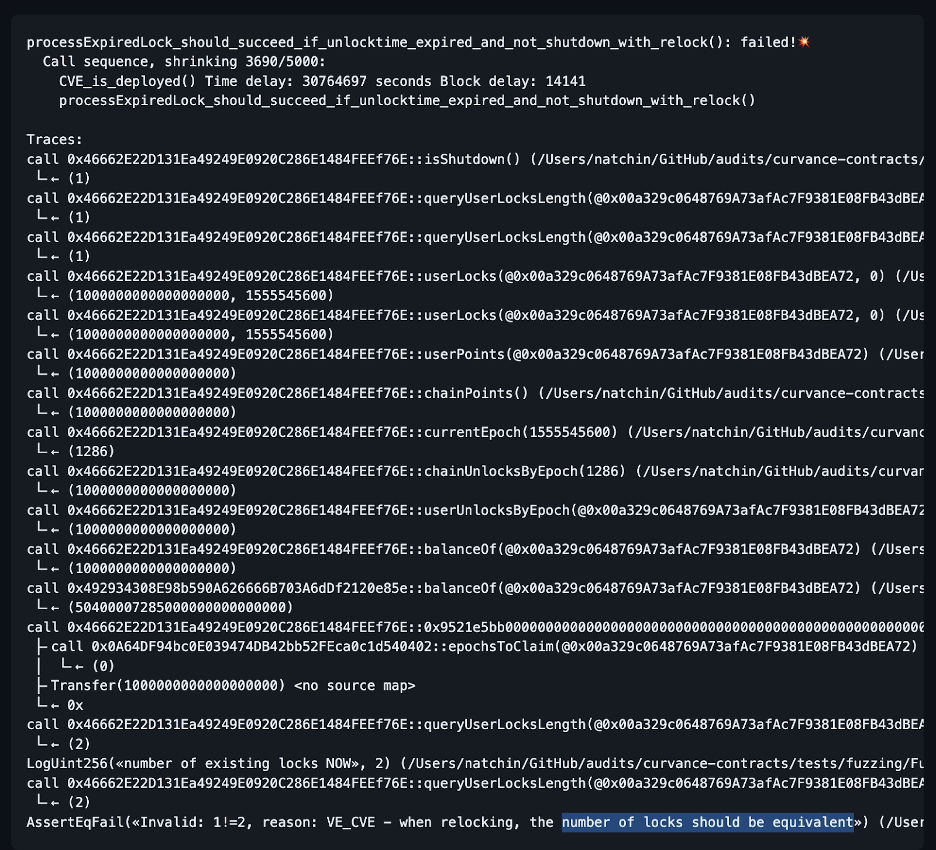
Echidna’s call sequences with rich traces at the end of the engagement
Finally, we created corresponding unit tests based on most assertion failures during our engagement. Initially, converting failures to unit tests was manual and time-consuming, but by the end, we streamlined the process to take just half an hour. We used the insights we gained from this experience to develop fuzz-utils, an automated tool for converting assertion failures into unit tests. Although it’s yet to be extensively tested, its potential for future engagements excites us!
One lock too many: The story behind TOB-CURV-4
After a significant change to the Curvance codebase, we encountered a puzzling assertion failure. Initially, we suspected it might be a false positive, a common occurrence with major code changes. However, after checking the changes in the Curvance source code, the root cause wasn’t immediately apparent, leading us into a complex and thorough debugging process.

We analyzed the full reproducer traces in Echidna (an Echidna feature that was added during this engagement, as mentioned in the previous section), and we tested assumptions on different senders. We crafted and executed a series of unit tests, each iteration shedding more light on the underlying mechanics. It was time to zoom out to identify the commonalities in the functions involved in the new assertion failures, leading us to focus on the processExpiredLock function. By closely scrutinizing this function, we discovered an important assertion was missing: ensuring the number of user locks stays the same after a call to the function with the “relock” option.
When we reran the fuzzer, it immediately revealed the error: such a call would process the expired lock but incorrectly grant the user a new lock without removing the old one, leading to an unexpected increase in the total number of locks. This caused all forms of issues in the combineAllLocks function: the contracts always thought the user had one more lock than they actually had. Eureka!
This trace shows the increase in the number of user locks after the expired lock is processed:

The trace for the increase in user locks, provided in the full invariant development report in finding TOB-CURV-4
What made this finding particularly striking was its ability to elude detection through the various security reviews and tests. The unit tests, as it turned out, were checking an incorrect postcondition, concealing the bug in its checks, masking its error within the testing suite. The stateless fuzzing tests on this codebase (built by Curvance before this engagement) actually started to fail after this bug was fixed. This highlighted the necessity of not only complex and meticulous testing that validates every aspect of the codebase, but also of continually questioning and validating every aspect of the target code—and its tests.
What’s next?
Reflecting on our journey with Curvance, we recognize the importance of a comprehensive security toolkit for smart contracts, including unit, integration, and fuzz tests, to uncover system complexities and potential issues. Our collaboration over the past nine weeks has allowed us to meticulously examine and understand the system, enhancing our findings’ accuracy and deepening our mutual knowledge. Working closely with Curvance has proven crucial in revealing the technology’s intricacies, leading to the development of a stateful fuzzing suite that will evolve and expand with the code, ensuring continued security and insights.
Take a look at our findings in the public Curvance report! Or dive into the Curvance fuzzing suite, now open through the Cantina Competition! Simply download and unzip corpus.zip into the curvance/ directory, then run make el for Echidna or make ml for Medusa. We’ve designed it for ease of use and expansion. Encounter any issues? Let us know! For detailed instructions and suite extension tips, check the Curvance-CantinaCompetition README and keep an eye out for the /// @custom:limitation tags in the suite.
And if you’re developing a project and want to explore stateful fuzzing, we’d love to chat with you!