
2024-11-14 05:48:13 Author: securityboulevard.com(查看原文) 阅读量:2 收藏
In a company, who owns the cloud? It’s not always clear. Maybe a better question is: who is responsible for the cloud’s cost? That answer is always the head of Operations. This person could be titled as ‘DevOps,’ or running a ‘Platform’ team – the title doesn’t matter. This is the person whose job it is to make sure there’s a cloud environment that 1) is highly available for development projects, 2) is adequately architected for current and future performance needs, and 3) costs about as much to run as the company thought it would cost to run.
Operations: all the ownership, none of the control
These days, this person is in a bit of a bind.
Imagine: you’re a cost center, but you’re feeding what’s perceived as the heartbeat of profit for most companies (new software development). Your main complaint from above you is about cost. Cost comes from cloud assets being spun up. The profit center (dev) is creating new assets all the time – they have to, the business wants them to; there’s no downward pressure on resource use for them. And you have little to zero control over them using new resources. Oftentimes, you find out about new service utilization afterwards – when the cloud bill comes. So the most important thing the higher ups are asking you to do is countermanded by what they’re asking someone else to do, and you can’t exert control before utilization occurs. That’s not an ideal situation.


The cloud is inherently difficult to inventory or control
How we got here is no mystery: the reason to move to cloud was the inherent dynamism, the immediate availability and scalability of new resources and services. To the business, this was intoxicating. So was the rapid expansion of services from the cloud service providers. It’s not a webpage with S3 and cloudfront anymore. Major CSPs (AWS, Azure, GCP) have over 600+ services, and they all come with new unique permissions. Regions have exploded as well – AWS alone has 34 regions and 108 availability zones. CSPs release new stuff frequently enough that if you average it out, you see 17 new types of cloud permissions per day. Do you use all of them? Good luck tracking if you do.
The cloud operations person is tasked with keeping costs down and keeping things secure. But downstream of that, the ops person needs clarity and order. Most operations people don’t have an accurate cloud inventory. It’s not possible when you probably inherited the infrastructure you’re managing, and you don’t have a governor on new resources. There’s not an accurate inventory of cloud resources. There’s so much to track and too much utilization happens without the person responsible for utilization ever knowing. What’s sorely missing: guardrails preventing unknown utilization before it happens.
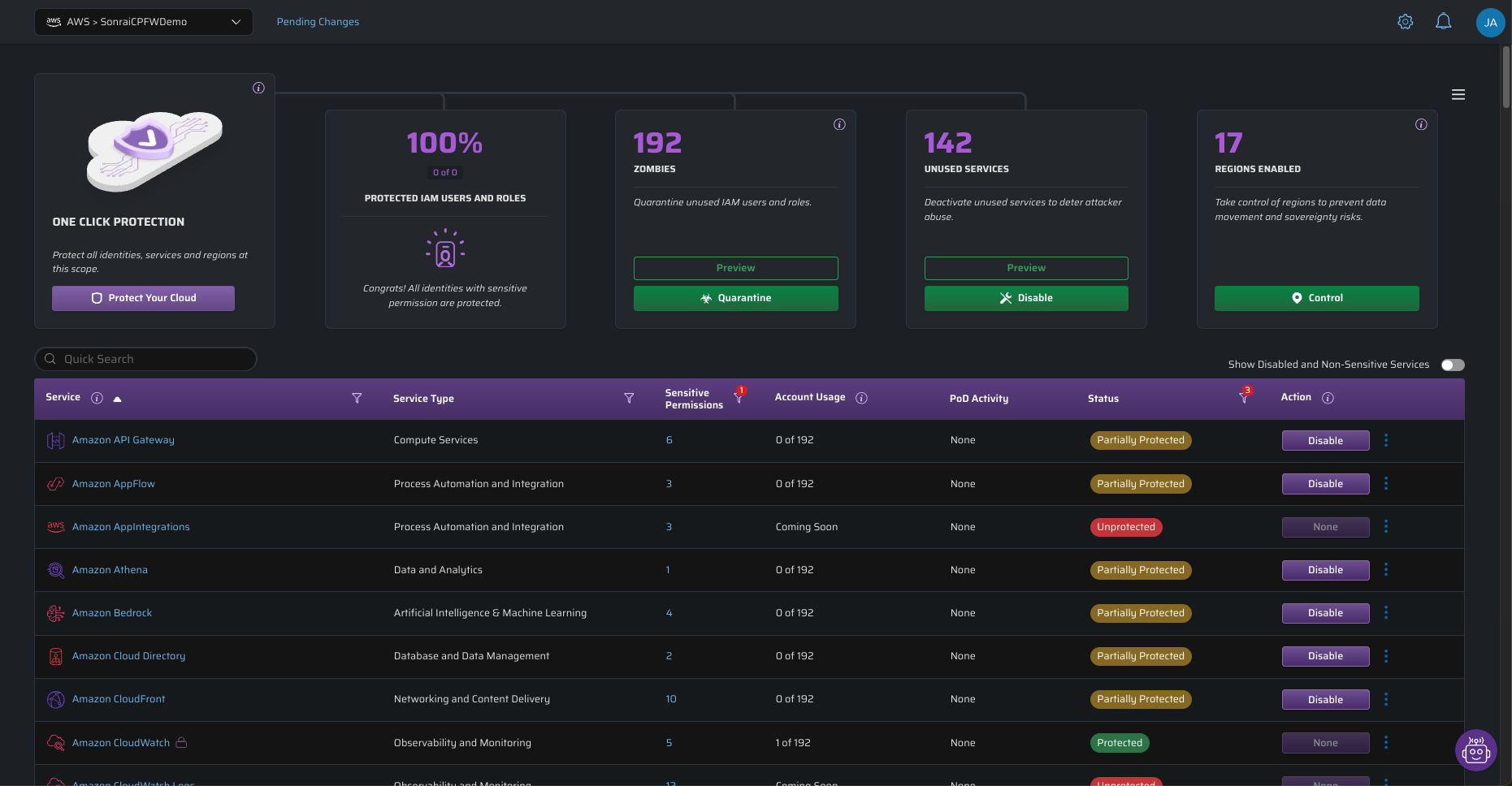
Here’s a place to start: what if you could just turn off cloud services and regions that you know you don’t use?
A possible control point: Services and Regions
As an Ops person, if you find yourself in this mess, you have several options:
- Painstakingly inventory every cloud asset.
- Commit to a constant upkeep of new services. Try and preempt usage if deemed out of scope or risk-inducing.
- Stop the bleeding, let people use what they need, but set central guardrails around that. Future-proof against further unsanctioned utilization with ‘default deny’ and approval system.
So far, most Ops folks have tried some mix of #1 and #2. It’s natural to feel the pull of getting to an accurate cloud manifest, if only you had a little more time to keep cleaning up and documenting it. Option 3 hasn’t been available, because there’s no clear way to centralize controls that doesn’t threaten to break code. There’s not even cloud-specific a way to make sure services are turned ‘off’ if you’re not using them – certainly no way to turn them off for everyone not using them currently.
Yet we can unlock option 3 if we think of it as a permissions problem. It starts with the simple action of turning off services you don’t use.

Permission, not forgiveness
A common scenario: a hot new AI service has come online. The business is eager to see how it can be incorporated into existing offerings. As usual, a developer will first play around with it, trying it out in a sandbox environment. Operations hasn’t vetted it, has no idea what it will cost, and will not be notified when it gets turned on. What if we can stop the utilization right there – instead of the ops lead finding out about post-usage, they get asked for permission to use it. If we give the Operations lead an ‘off’ button for the new service, and set up a way for the developer to request access to the service. That way, the ops person knows exactly what it is and what utilization to expect.
The same goes for availability regions. If you’re a US-based company with no need for AWS’s APAC-Tokyo region, why make it available? It’s just another place for rogue utilization to happen – not to mention any data sovereignty violations that you need to worry about.
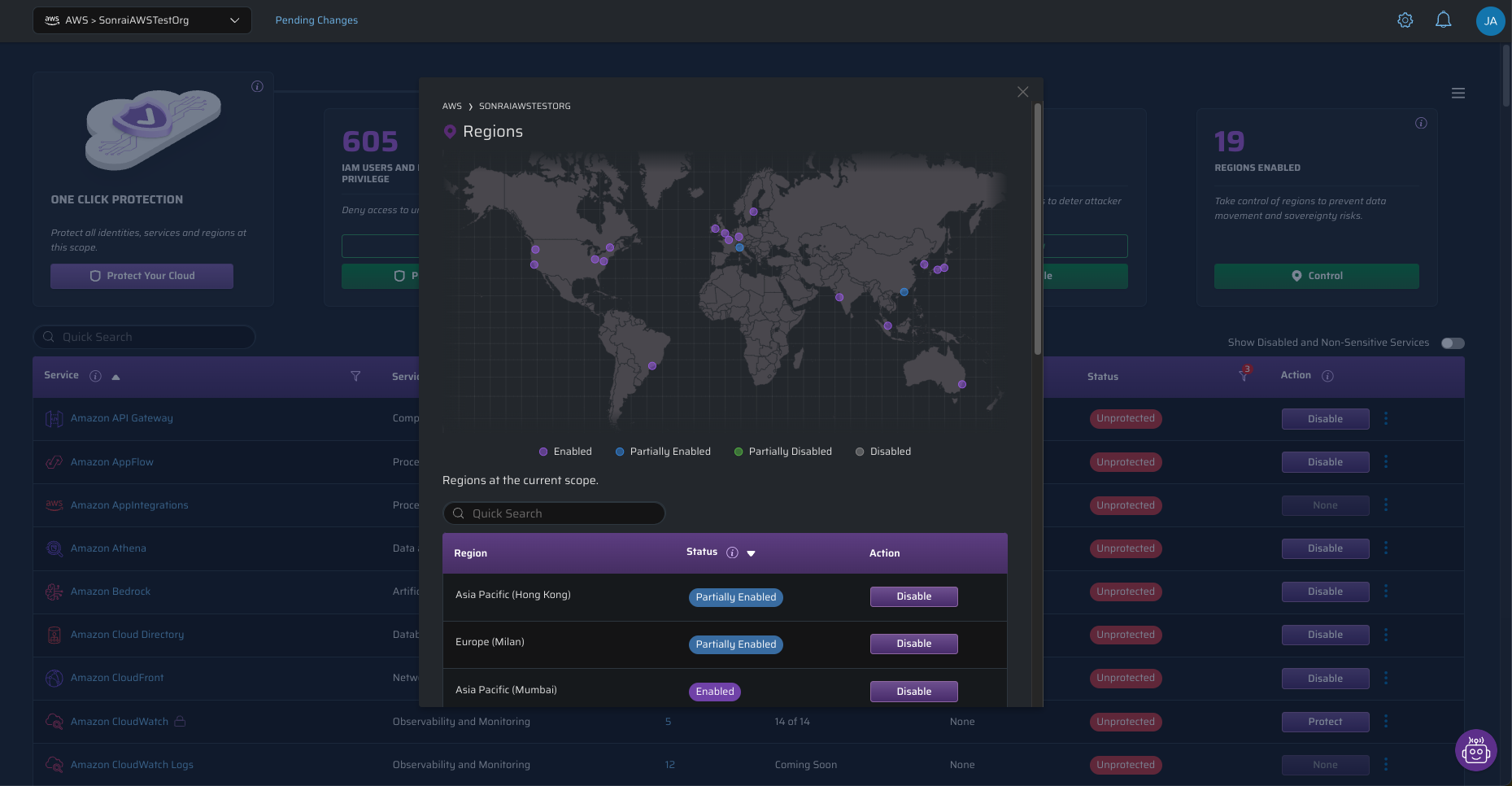
Sonrai’s Cloud Permissions Firewall gives you these controls. Want to disable new AI services? Hit that disable button, and they’re restricted at whatever scope (org, OU, accounts) you determine. Want to only turn off sensitive permissions (aka, actions that would likely be used in an attack)? Hit the Protect button. The point is: it’s a central control for services that’s in the possession of the cloud owner, instead of every developer choosing how and when services get utilized.
When someone does want to open up use of a service, there’s a simple, ChatOps-integrated process for them doing so.
How permissions are part of FinOps
In addition to just turning services off to control usage before it happens, having a centralized permissions control gives you a way to investigate how unseen utilizations took place.
Tracking down rogue charges on your bill starts in the same place you look to turn off services. You’ll be able to see if the service that incurred the charge is protected, and if any identity has exempted status to use sensitive permissions in it.
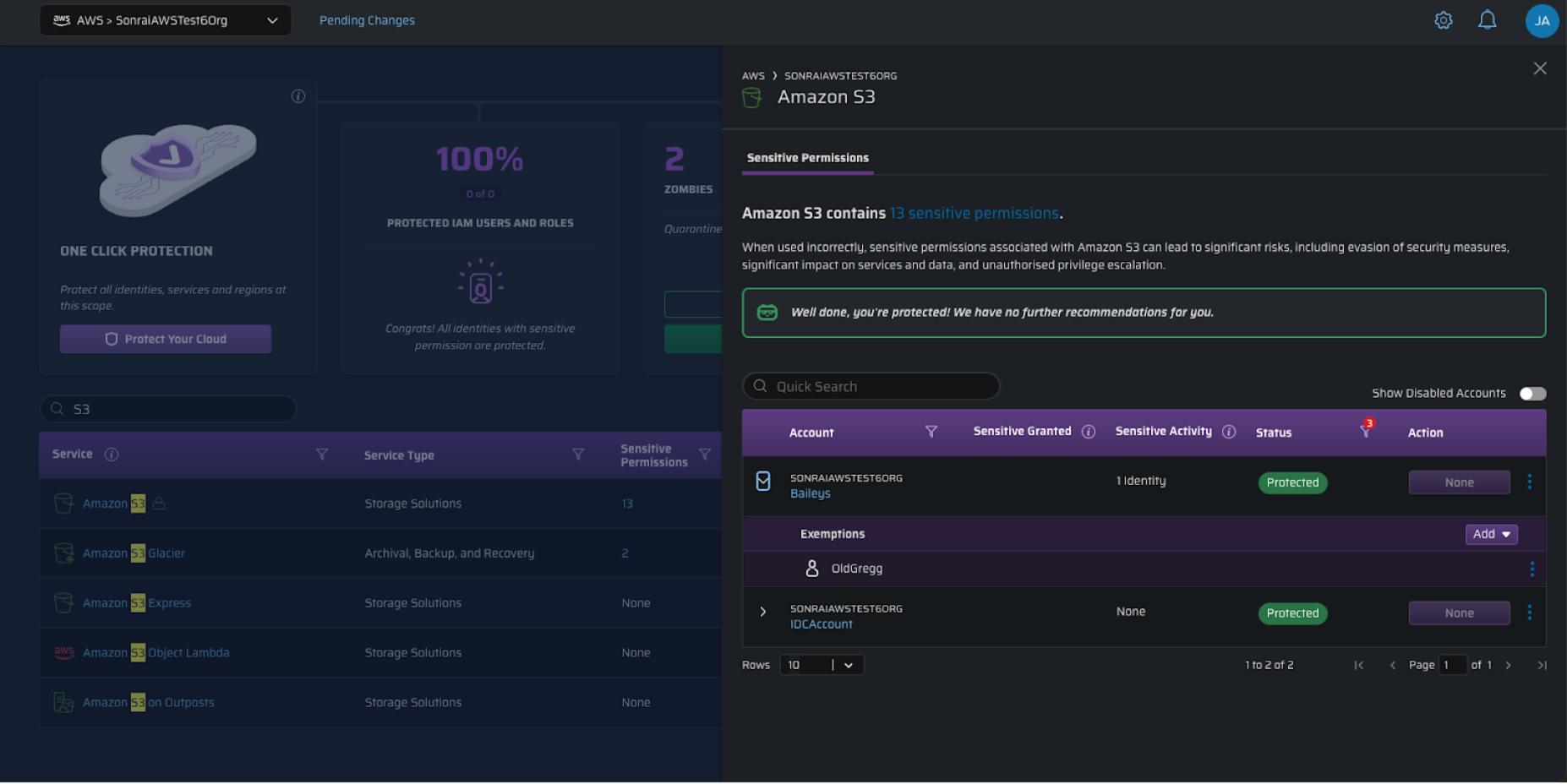
Now we have the ARN to look up in our repo to see what this was connected to, and why they used it. You’ve also got an auditable history to see if the user requested this access, who granted it, and when. While the primary benefit of this protection is to reduce risk, it also gives us a place to see who can use what. If we do get unexpected utilizations, we can quickly investigate who’s likely responsible for it.
The end of chaos starts with the ‘off’ button
Anyone responsible for running the platform has been mired in a problem begotten of too much scale and complexity. While the cloud is undeniably complex, solutions to utilization and risk control don’t have to be. In our attempts to be more forward-thinking, cloud pros – vendors included – have mistaken complexity for robustness. Shifting left, democratized control, developer-led security – these are all modern concepts we can continue to bake into our cloud strategy. But centralization of simple guardrails, like whether a service or a region is available, are necessary to be in the control of whoever is responsible for the platform. You can still offer easy methods of requesting access, but ultimately, the operations person is in control. Up until now, cloud tools have struggled balancing the competing priorities of time-to-production and asset control. Giving some common-sense on/off buttons to the operations lead for unused services and regions is a good start towards controlling the cloud chaos without slowing anything down.

*** This is a Security Bloggers Network syndicated blog from Sonrai | Enterprise Cloud Security Platform authored by James Casagrande. Read the original post at: https://sonraisecurity.com/blog/turn-off-unused-aws-services-regions-utilization-risk/
如有侵权请联系:admin#unsafe.sh