
阅读: 6
一、互联网时代的欺诈
在互联网技术蓬勃发展的当下,许多行业开始了数字化转型。然而,在给用户带来便利的同时,互联网一度也成为了不法分子进行欺诈的温床。一方面,海量用户在互联网上或多或少地留下了数据,不法分子得以利用这些信息对用户实习精确诈骗,提高诈骗成功率;另一方面,银行、电商等线上财务交易业务也为不法分子有了更多的欺诈途径。
各类诈骗手段层出不穷,通过电话、信息、钓鱼等手段实施的欺诈,不光每年为社会带来数以亿计的损失,更对人民生命安全产生了巨大威胁。监管和防御网络欺诈,是网络安全行业的一个重要课题。
二、基于机器学习的欺诈检测手段
对于已知的网络欺诈行为,基于钓鱼站点域名、发送欺诈信息的账号与手机号等信息,可以通过黑名单来进行简单有效的监管和防御。然而对于未记录在案的欺诈,传统手段难以进行有效防御。随着机器学习技术的发展,通过机器学习技术发掘欺诈行为信息来源和信息内容的特征,作出实时、连续的准确判断,是目前欺诈检测手段的主要研究方向。
2.1 面向稀缺资源的检测
欺诈团伙需要通过给用户发送信息以实施欺诈。由于发送信息使用的电话号码、应用账号,以及实行钓鱼的网站域名都属于稀缺资源,欺诈团伙必须付出一定成本才能获得,因此针对这些稀缺资源进行分析,关注用于欺诈的资源和正常使用资源的不同特征,往往能够取得很好的检测效果。
2.1.1 涉诈号码检测
用来进行欺诈的号码,在通信行为上与正常号码会有明显区别。林宇俊等[1]研究发现,涉诈号码在主叫日通话次数、主叫率、外地通话次数、通话频率、通话时长、回拨率等通话行为特征上与正常号码都有明显的区别,如图1所示。类似通话行为,欺诈号码在收发短信的行为特征上也会与正常号码有区别。
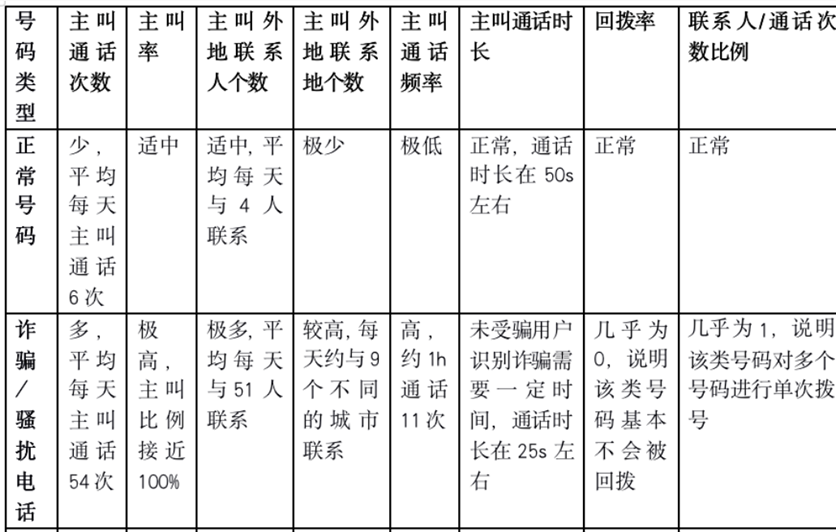
基于这些行为特征对电话号码进行分类是一个二分类问题,通过KNN、SVM、决策树等机器学习算法可以取得很好的识别效果。此外,其他一些特征,如号码账户是否实名制、用户和号码归属地是否相同、号码的使用时间、号码账户购买的增值服务类型等,也可以加入特征集来辅助机器学习算法对正常号码与欺诈号码进行分类。
针对软件平台欺诈账号的治理思路与针对欺诈号码的治理方案类似:利用机器学习算法基于账号的行为特征进行分类,以实时自动化地持续识别未知的高风险欺诈账号。
2.1.2 钓鱼URL检测
利用钓鱼URL进行网络欺诈是欺诈团伙的惯用手段。通过发送钓鱼URL,诱导用户进入伪造成正常站点的网站,欺诈团伙即可获取用户输入的敏感信息。
钓鱼URL与正常URL在许多地方都有明显的区别。Andrei Butnaru等的研究[2]发现,钓鱼URL的平均长度通常比正常URL要长,且极值差距非常明显。研究中,99%的正常URL不会超过141个字符,而10%的恶意URL长度大于143个字符,如图2所示。
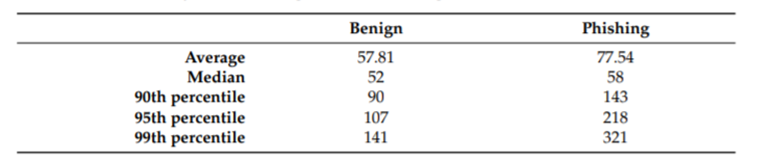
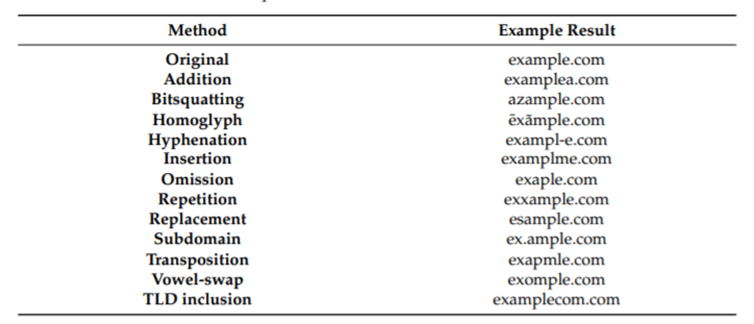
虽然统计数据展现了明显的差异,但对于一个具体的URL来说,其长度很难单独作为是否是钓鱼URL的判断指标。因此,研究者尝试通过多维度的特征去识别钓鱼URL。研究中发现,如图5所示,许多钓鱼URL会针对一些常用的域名进行字符的增加、删除、近似替换等混淆,以达到误导目标用户的目的。
研究综合正常URL与钓鱼URL在各维度的差异,通过URL的长度、是否是https链接、数字字符的数量、特殊字符的数量、点号的数量、连字符的数量、子域数量、指向性词汇(login,confirm,banking等)、域名与知识库中常用的正常域名相似度等特征,通过随机森林分类器识别恶意URL,达到了较好的识别效果。
2.2 面向信息内容的检测
网络欺诈通常需要向用户传递虚假信息以误导用户。类似用于欺诈的资源和正常使用的资源在许多特征上有明显差异,用于欺诈的信息内容与正常信息内容也有明显的不同。针对信息内容进行分析以识别欺诈是欺诈检测的一个重要思路。
2.2.1 欺诈文本识别
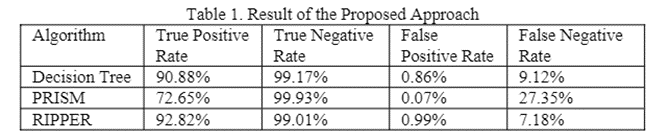
Ankit KumarJain等人[3]针对欺诈SMS的内容进行了研究,研究发现欺诈SMS通常更倾向于包含联系方式(email、电话号码等)、钓鱼链接(url、apk下载地址等)、货币符号(¥、$等)、欺诈关键词(释放、免费、约会、中奖、彩票、赌博、套现、意外等),形象语素(火星文、拼接汉字等),这些正常SMS中基本不会出现的特征。此外,欺诈SMS的文本往往比正常SMS长,其内容形式一般也更倾向于通知警告,不需要用户回复。这些特征的提取主要基于正则匹配和关键词匹配。对于中文文本,进行NLP分词再进行匹配可以提升匹配精确度。钓鱼链接的检测方案可参考本文上一节介绍的方案。结合多维度的规则,研究人员使用RIPPER分类器以判断信息是否涉嫌欺诈,取得了较高的准确率,如图4所示。
2.2.2 语音通话检测
通过语音通话方式实施欺诈是常见的欺诈手段。由于对语音信息的分析过程比较复杂,且不同个体的语音表述方式存在较大偏差,口语表述也不如文字表述规范,难以结构化,因此对语音信息很难像对文本信息那样精确收集内容中的多维特征。
Qianqian Zhao等[4]对欺诈通话中经常出现的关键词进行研究。研究者首先通过科大讯飞的iFLYTEK开源语音识别平台将语音信息转化为文本信息,随后研究者从各渠道搜集欺诈中经常出现的关键词,构建了欺诈关键词词库。
这些涉诈关键词出现的频率分布与正常通话中欺诈关键词出现的频率有明显差异。如图5所示,蓝点代表正常通话中关键词频率分布,红点代表欺诈通话中关键词频率分布。横轴表示该词与欺诈的关联系数(按:论文中关联系数通过比较关键词在样本库欺诈样本中的出现频率和正常样本的出现频率计算得到,具体计算步骤未介绍),纵轴表示该词出现频率。由图可见,对于欺诈通话,涉诈关键词的相关系数与出现频率在欺诈通话中基本呈现正相关的趋势,对于正常通话,高关联系数欺诈敏感词的出现频率整体不如低关联系数敏感词高。
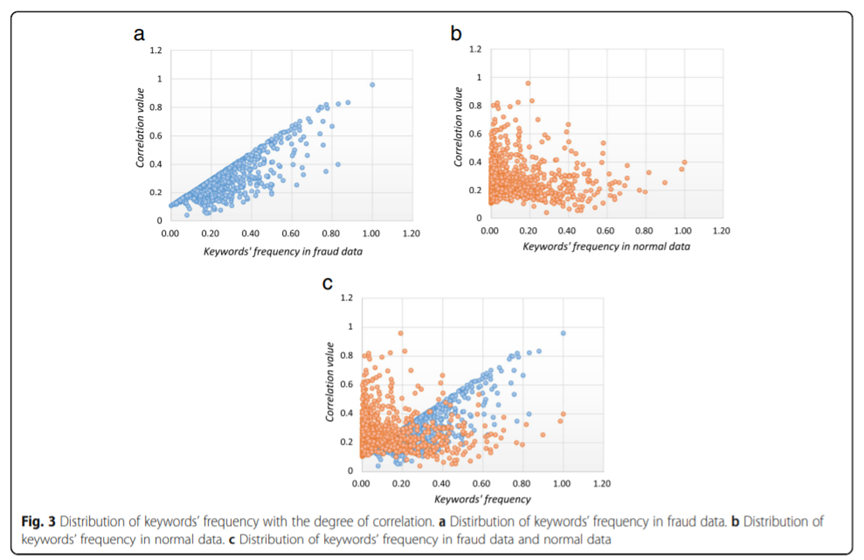
有鉴于此,研究者使用NLP技术从语音转化来的的文本中提取欺诈关键词,基于该特征设计了一个判断规则对语音通话的内容是否涉及欺诈进行判断。图6展示从通过语音转化来的文本中提取涉诈敏感词并计算频率与关联系数的过程。
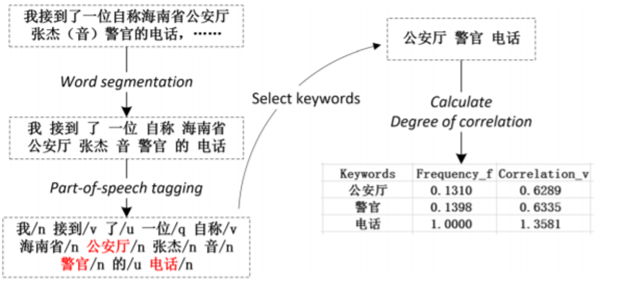
由于部分正常通话在特定场景下也可能频繁出现涉诈敏感词,因此需要对全部敏感词的出现频率进行衡量。
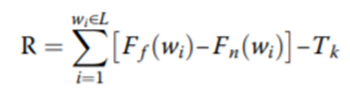
公式1 基于检出敏感词在知识库中出现频率判断是否是欺诈通话,引用自[4]

三、基于机器学习的反欺诈攻防案例
机器学习技术虽然在反欺诈解决方案中发挥着重要作用,但另一方面,机器学习技术也可以被不法分子用来进行欺诈。USENIX 2020收录的《Boxer: Preventing fraud by scanning credit cards 》一文,就对利用虚假信用卡信息,对金融支付类应用进行欺诈的攻防进行了系统研究。
Zainul Abi Din等[5]将伪造信用卡进行的攻击与对信用卡的安全检测功能各自分成四个等级。其中攻击等级由轻到重分为输入虚假卡号、构建假卡文本、利用计算机视觉技术成假卡、利用计算机视觉技术技术生成假卡并打印四个等级,防御等级由轻到重分为简单OCR识别、基于卡号一致性检测、屏幕检测、基于设备信息的检测四个等级。
3.1 面向信用卡号检测的攻击
研究者采用的部分攻击样本效果如图7所示,左上为使用文本伪造的信用卡。该攻击方法虽然看似简陋,但论文中提到,大多数应用并不能防止这种简单的攻击。这些应用仅仅在使用OCR识别卡号并与用户输入的卡号信息匹配后,就发起了支付。右上和左下均为研究者通过自行研发的机器学习计算机视觉工具Fugazi生成的假卡照片,区别在于右上图的照片卡号不符合对应银行的卡号分配规则。右下为照片打印后的物理假卡。

图7中用来生成假卡的Fugazi工具结合机器学习与传统机器学习技术(图8),从真卡的照片上抹去原有的卡号,利用生成对抗神经网络(GAN)生成假的卡号(图9),再通过传统计算机视觉技术重新编排生成的数字贴图大小并混淆其与周围像素的色差,进行后期处理。

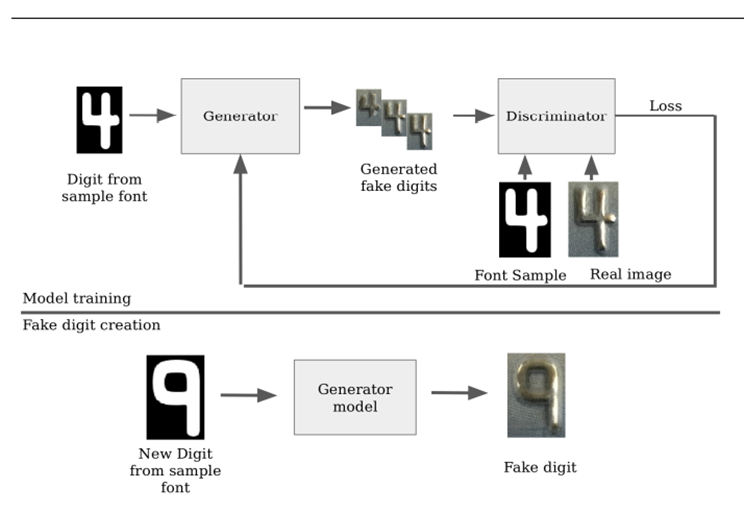
关于这种结合机器学习和计算机视觉技术伪造的假数字,我们能否通过机器学习技术去识别呢?遗憾的是,由于目前关于伪造图像恶意样本的研究很少会关注数字,更少有关注于信用卡图片,加上信用卡上的字大多凸起,可能积累灰尘,因此通用的检测方案很难处理识别信用卡上假数字贴图的任务。如图10所示,通过Faster-RCNN识别真卡与Faguzi生成卡,真卡上相当一部分区域也被识别成了被修改过的区域。如图11所示,Faguzi生成卡的Consistency Map十分平滑,说明图像连续性很好,传统的计算机视觉方案也很难发现修改痕迹。


3.2 面向信用卡号检测的防御加固
说完攻击手段,我们在来看检测加固手段。OCR技术目前已广泛使用,用于从图片中提取文字。基于OCR的信用卡检测方案会从设备拍摄的信用卡图片中提取文字,验证提取出的卡号与用户输入的卡号是否一致,以此来判断用户是否确实持有其输入卡号的信用卡。然而,如同上文中提到的,单独使用OCR的检测方案,甚至可以被仅包含卡号的文本图片所欺骗。
有鉴于此,研究者在OCR的基础上加入了定制化的目标检测模型,进行卡号一致性检测。该模型不光能提取图片上的文字,更能识别银行卡上诸如芯片、标记、持卡人姓名栏等区域是否存在这些卡面特征(图12)。除此之外,研究者还通过大量真实信用卡的信息,构建了一个银行卡号规则库,包含如:4开头的卡号应该有VISA标记,卡号的头6个字符是否属于卡面上的发卡银行等。结合卡面特征与规则库,质量较低的伪造信用卡也会被检测出来。

接下来,研究者对通过Faguzi生成,且符合银行卡号规则的假信用卡发起了挑战。为了用较小的性能开销过滤掉直接拍摄屏幕上的照片试图绕过检测的攻击,研究者首先通过设备拍摄的照片中是否包含屏幕的边角,以及照片是否带有莫尔条纹来进行屏幕检测。如图13所示,莫尔条纹是摄像设备与被拍摄设备屏幕之间发生光学干涉的一种明显的光学现象,诸如在使用手机拍摄电脑屏幕等场景下,就能明显地在手机拍到的照片中观察到。若未通过屏幕检测,说明拍摄到的卡不是真卡,仅是卡的照片或视频。

接下来就只剩下对物理假卡的检测了。由于现有的计算机视觉与机器学习技术很难对制造精良的假卡进行检测(见3.1节),因此研究者采用了基于设备信息的方式对假卡进行检测。攻击者如果使用虚拟机进行攻击,现有的虚拟机检测技术可以通过硬件特征将其检测出来(设备陀螺仪工作数据、地理位置变化情况、是否有SIM卡等);而面对使用真实设备进行攻击的攻击者,由于真实设备的成本高昂,攻击者往往会在一个设备上使用多个账号,绑定多张假卡来实施诈骗。应用开发者可以通过在该设备上账号的登录次数与绑定银行卡的个数来判断该设备是否属于攻击者。
然而,由于隐私保护和合规要求,设备的唯一标识符是不能够采集的。隐私友好的设备标识符,在重装应用或恢复设备出场模式后都会被重置。由于没有严格意义上的设备唯一标识符,攻击者只要对设备进行设置,应用开发者就无法追踪该设备上应用使用的数据。
有鉴于此,研究者基于IOS系统的硬件机制实现了对设备上登录行为和绑定银行卡个数的统计。IOS系统提供一个API,可以用来获取当前设备在某个服务器中的状态。 DeviceCheck 允许开发者通过开发者自己的服务器与 Apple 服务器通讯,并为单个设备设置2bit 的数据,在保护用户隐私的同时,标识正在使用应用的设备。由于2bit只能表示4种状态,研究者将一定范围内的次数用一个2bit的数字表示,如图14所示。这样一来,即使攻击者即使重装应用或重置设备,被DeviceCheck编码保存的技术依然不会清空。基于该设备上的登录次数与绑定卡数的范围,应用开发者仍然可以使用设备信息来判断绑定信用卡的设备是否有攻击行为。

3.3 案例总结和思考
上文介绍的研究不光被USENIX 2020收录,实际产品Boxer也以SDK的形式投放市场,在论文发表时已被323个应用使用,扫描超过一千万张信用卡信息,可见其实际检测能力。如表1所示,Boxer对于物理伪卡之外的其他攻击,能够收到很好的防御效果。表1中Man.代表人工输入卡号信息,Text代表用文本伪造信用卡,Photoshop代表用机器学习计算机视觉技术生成的高质量假卡图像,Phys.代表用物理打印的高质量假卡。白点代表不具备防御能力,黑点代表完全防御,半白半黑代表具有一定的防御效果。

然而从安全研究的角度看,与Boxer同样值得注意的是文中介绍的伪卡生成工具Faguzi。该工具生成的假卡图像不光具有很好的连续性,更能绕过包括faster-RCNN在内的伪造图像检测模型。机器学习在该案例中,不光扮演了盾的角色,也扮演了矛的角色。随着机器学习技术的广泛普及,不法分子利用机器学习进行欺诈的案例有可能会越来越多。此外,该案例中研究人员开发的机器学习攻击方法已攻破自己开发机器学习防御方案,也证明了机器学习应用于欺诈可能造成的巨大威胁。
四、总结与思考
互联网时代,网络欺诈给用户带来了巨大的风险。现有的技术手段主要从施行欺诈依赖的稀缺资源和发送信息内容两个维度出发,对欺诈行为做出检测。
如本文介绍,近年关于欺诈检测方案的研究几乎都使用了机器学习技术。从技术维度上看,一方面,欺诈检测本身是一个二分类问题,而机器学习在处理分类问题上有优异的表现;另一方面,对语音、文本的处理离不开NLP技术。机器学习技术的应用在欺诈检测任务中发挥了重要作用。
然而,一些欺诈手段从本质上来说是人与人之间的交互行为,用户在收到欺诈信息时所处境况也很复杂,因此欺诈团伙在充分掌握用户情报的前提下实施的欺诈将更具有迷惑性。对于这些欺诈,上述几种现有技术手段均很难收到理想的检测效果。因此做好个人信息防护工作,避免欺诈团伙掌握用户情报,是提高欺诈团伙攻击门槛,防范网络欺诈的重要手段。
此外,不论是基于号码、账号等稀缺资源还是基于短信内容、通话或应用内部信息的检测方案,都需要依赖运营商或平台提供的数据进行支撑。而这些数据通常由数据持有者独立存储,因此单个机构很难从技术层面去系统地对网络欺诈进行治理和分析,如本文介绍的研究中,一些研究者只能通过自己构建互联网语料库来作为样本数据集。构建跨行业的反欺诈技术生态,促进行业合作,整合优势资源,对于反欺诈技术的发展将能起到显著的推动作用。
最后,机器学习不光能在反欺诈中起到重要作用,也有可能成为不法分子进行欺诈的工具,并有能力对现有防御方案造成巨大威胁。因此,反欺诈研究工作不光需要关注机器学习解决方案,也应该关注基于机器学习的欺诈手段。从攻防的角度出发,是反欺诈研究的重要课题。
参考文献
[1] 林宇俊,许鑫伶,何洋,鲁银冰,5G时代下基于大数据AI的全周期反通信信息诈骗方案研究,电信工程技术与标准化,Telecom Engineering Technics and Standardization, 编辑部邮箱 ,2019年11期
[2] Butnaru, A.; Mylonas, A.; Pitropakis, N. Towards Lightweight URL-Based Phishing Detection. Future Internet 2021, 13, 154. https://doi.org/10.3390/fi13060154
[3]Ankit Kumar Jain, B.B. Gupta,Rule-Based Framework for Detection of Smishing Messages in Mobile Environment, Procedia Computer Science, Volume 125, 2018, Pages 617-623, ISSN 1877-0509, https://doi.org/10.1016/j.procs.2017.12.079.
[4]Zhao, Q., Chen, K., Li, T. et al. Detecting telecommunication fraud by understanding the contents of a call. Cybersecur 1, 8 (2018). https://doi.org/10.1186/s42400-018-0008-5
[5]Din, Z. A., Venugopalan, H., Park, J., Li, A., Yin, W., Mai, H., Lee, Y. J., Liu, S., & King, S. T. (1970, January 1). Boxer: Preventing fraud by scanning credit cards. USENIX. Retrieved January 19, 2022, from https://www.usenix.org/conference/usenixsecurity20/presentation/din
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。