2018-10-25 18:40:0 Author: www.cnblogs.com(查看原文) 阅读量:2 收藏
1、ELK架构中Logstash的位置:
1.1、小规模集群部署(学习者适用的架构)
简单的只有Logstash、Elasticsearch、Kibana,由Logstash收集日志或者流量信息,过滤后由Elasticsearch存储,前台kibana进行展示、搜索、聚合。适合小规模部署或者学习使用。
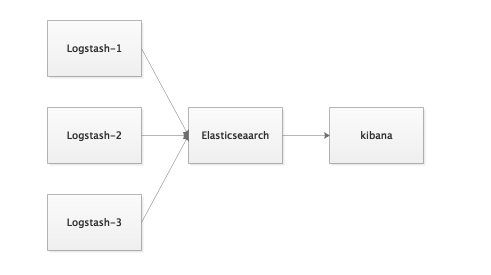
1.2、大规模集群部署
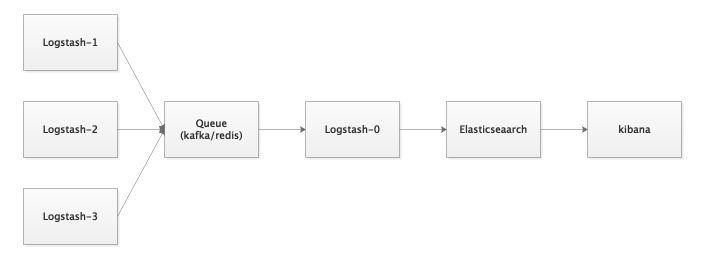
由Logstash进行最初的信息收集和处理,之后传入消息队列(可以是kafka、redis等),然后又Logstash从消息队列中再读取信息处理后存入Elasticsearch集群,由kibana展示
、搜索、聚合等。该架构适合大规模部署,当然对与Logstash进程多消耗性能的问题,还有一些其他的解决办法,可以参考专门的ELK架构方面的文章,这里就不在赘述了。
2、Logstash的输入
2.1、标准输入
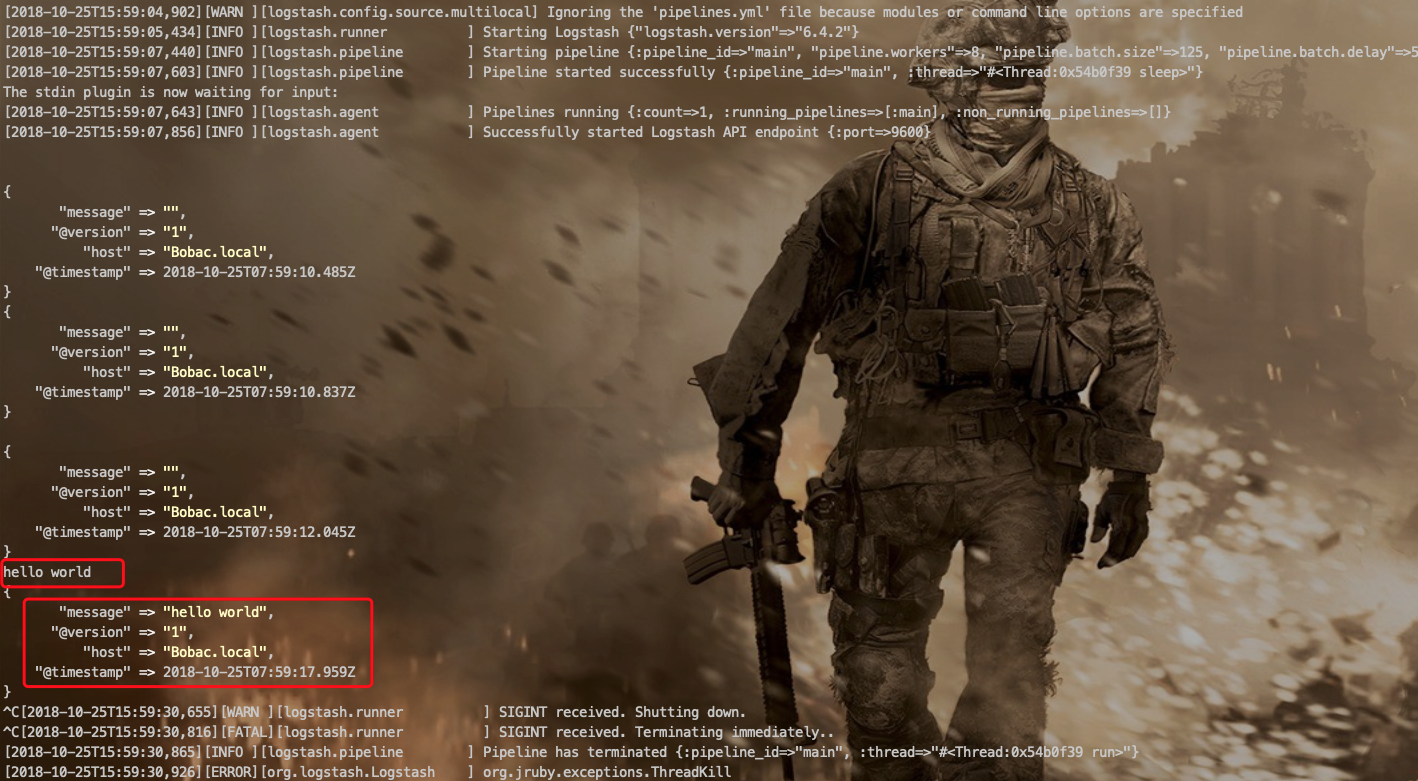
首先我们来拟定一个标准输出用来测试我们不同的输入:
input {
stdin{}
}
output{
stdout{
codec => rubydebug{}
}
}
简单的一些添加字段的方
标准输入中我们来加入一些添加固定字段的办法
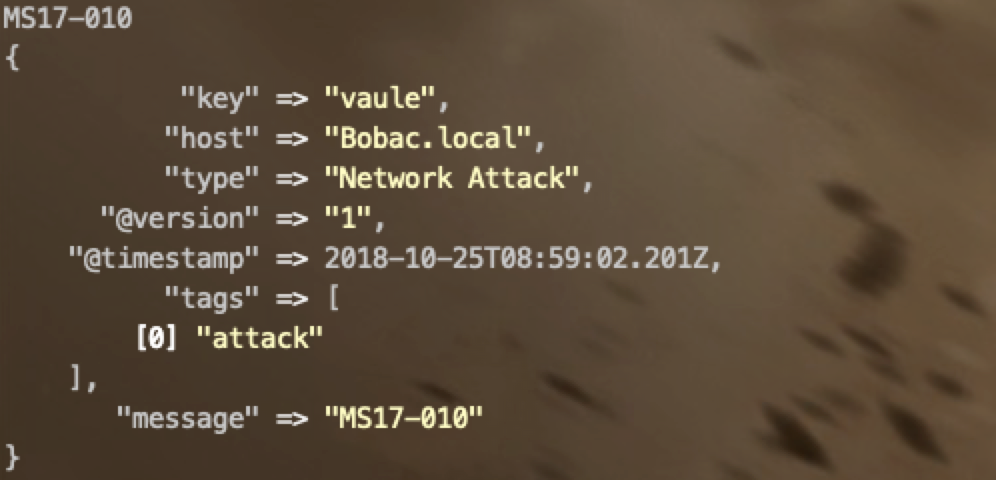
#1
add_field => {"key":"value"}
#2
tags => ["tag1",tag2] #打标签
type => "type1" #标明类型
#3
host标签是不能修改的,否则会报错
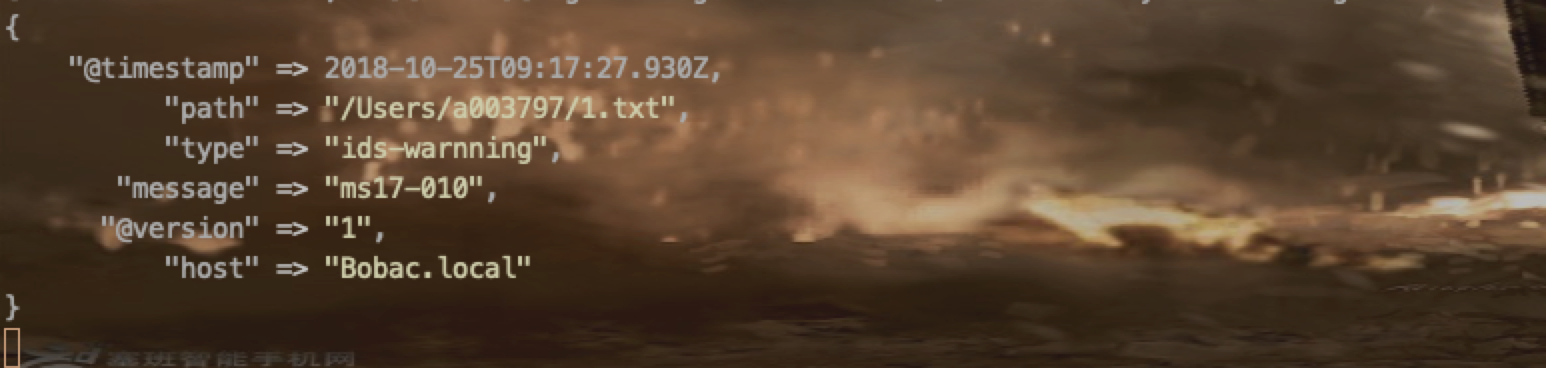
2.2、文件输入
input {
file{
path => ["/Users/a003797/1.txt"]
type => 'ids-warnning'
start_position => "beginning"
}
}
output{
stdout{
codec => rubydebug{}
}
}
如上面的代码,path指的是文件位置,是一个list,start_position是监控位置,从开始监控还是从结尾监控(beginning和end)
#还有一些知识点
1、path里面的路径支持通配符
2、discover_interval 检查path下新文件时间间隔,默认15s
3、exclude 与path配合,表示批量文件中不需要监听的部分
4、stat_interval 检查监听文件的更新状态的时间间隔,默认1s
2.3、网络输入
这个很少用
把logstash配置成syslog服务器 codec这个字段是控制编码形式的 多行编码input {
tcp {
port => 5580
mode => "server"
ssl_enable => false
}
}
output{
stdout{
codec => rubydebug{}
}
}
2.4、其他输入
input {
syslog{
port => "514"
}
}
3、编解码:
code => "json" #可选项还有plain等
codec => {
pattern => "^\["
negate => true
what => "previous"
}
如有侵权请联系:admin#unsafe.sh