污点分析是一种挖掘安全漏洞的有效手段,即使对于大型代码库,也是如此。我的同事Lucas Leong最近演示了如何使用Clang Static Analyzer和CodeQL,通过污点分析来建模和查找MySQL NDB Cluster中的漏洞。受到该项工作的启发,我也开始尝试类似的东西,但这里使用的工具是Binary Ninja,因为它也可以很好地处理闭源程序。
以下是我在从事这项工作时想到的几件事:
◼在不进行边界检查的情况下,识别由于使用不受信任的值而导致的漏洞
◼污点的传播和过滤应该对控制流敏感
◼支持过程间分析
对于这个问题,我将其作为一个图的可达性问题来处理,这方面,“Tainted Flow Analysis on e-SSA-form Programs”是一篇很好的参考文献。本文的所有分析都是基于MySQL Cluster 8.0.25和Binary Ninja 2.4.2846完成的。
定义污点源
进行污点分析时,必须明确定义污点源。因为MySQL Cluster具有一个消息传递架构,所以,我们感兴趣的污点源就是消息本身。本节提供了关于消息处理以及如何识别消息处理程序方面的详细信息。
MySQL NDB Cluster信号
MySQL NDB Cluster将功能定义为“块”,将它们之间传递的消息定义为“信号”。NDB块通常以C++类的形式实现,每个块在初始化时都注册了多个信号处理程序,这些处理程序也是该类的方法。到目前为止,人们发现的大多数漏洞都位于这些消息处理程序中,也被称为信号处理程序。
所有的块都继承了SimulatedBlock类,所以,它们都是使用addRecSignal()来方法来注册其信号,而该方法则会调用SimulatedBlock::addRecSignalImpl()方法。实际上,注册的信号处理程序的类型为ExecSignalLocal,并且需要一个参数。对这方面有兴趣的读者,可以参考Frazer Clement的文章“Ndb software architecture”,以及Steinway Wu的文章“Code Reading Notes – MySQL Cluster”,以了解更多细节。在本文中,我们只对信号处理程序的入口点感兴趣。下面是一个NDBCNTR块注册信号处理程序的示例代码:
addRecSignal(GSN_CNTR_WAITREP, &Ndbcntr::execCNTR_WAITREP); SimulatedBlock::addRecSignalImpl(GlobalSignalNumber gsn, ExecSignalLocal f, bool force) typedef void (BLOCK::* ExecSignalLocal) (Signal* signal);
处理程序收到的“Signal”对象通常都包含不受信任的数据,而信号处理程序可以通过signal->getDataPtr()方法或其他一些方法来访问这些数据。处理程序也可以进一步将"Signal"对象传递给其他函数。对于这一步的分析,方法有多种。比如,我们可以分析任何以Signal为参数的函数,或者通过交叉引用,查找对SimulatedBlock::addRecSignalImpl()的调用,只分析实际的信号处理程序,然后,通过过程间分析来处理剩下的问题。这里,我们先介绍前面一步,至于过程间分析,我们将在后文加以介绍。
虽然Signal对象的大小为0x8030字节,但是,并非所有的字节都应该被视为污点。相反,我们应该只把该对象的一小块内存区域定义为污点,这样的话,只有从污点区域读取的内存数据才会被传播。如果将整个结构都标记为污点的话,会导致大量的误报。就本例来说,信号的污点数据从偏移量0x28处开始,也就是说,从这个偏移量处开始加载的任何内存数据,都被标记为污点。另外,方法Signal::getDataPtr()和Signal::getDataPtrSend()都会返回一个指向该内存地址的指针。
Uint32 m_sectionPtrI[3];
SignalHeader header;
union {
Uint32 theData[8192]; /* Tainted memory region at an offset 0x28 */
Uint64 dummyAlign;
};
Uint32 m_extra_signals;
inline const Uint32* Signal::getDataPtr() const {
return &theData[0];
}
inline Uint32* Signal::getDataPtrSend() {
return &theData[0];
}将类型信息从IDA Pro移植到Binary Ninja上
这里分析的可执行文件是“ndbd”,它是利用DWARF调试信息构建的NDB Cluster Data Node Daemon进程。为了查找以指向Signal对象的指针作为参数的函数,请检查所有函数的类型信息,如下所示:
for func in bv.functions: for index, param in enumerate(func.parameter_vars): if param.type is not None and param.type.type_class == TypeClass.PointerTypeClass: if param.type.tokens[0].text == "Signal":
然而,就目前来说,Binary Ninja还无法像IDA Pro那样鲁棒地处理DWARF信息。Binary Ninja的另一个问题是:在分析C++可执行文件时,它无法检测“this”参数。因此,它的参数检测并不准确,从而对我们的污点源分析带来很大障碍。一个简单的解决方法是,将类型信息从IDA Pro导入Binary Ninja。例如,Dblqh::prepareContinueAfterBlockedLab()方法在IDA Pro中的类型信息如下所示:
void __fastcall Dblqh::prepareContinueAfterBlockedLab(Dblqh *this, Signal *signal, Dblqh::TcConnectionrecPtr tcConnectptr)
同样的函数,在Binary Ninja中看起来却差别很大。就本例来说,“this”指针“不见”了,而Signal则成了第一个参数。因此,如果将“arg1”标记为污点源的话,将使整个分析出错:
int32_t* Dblqh::prepareContinueAfterBlockedLab(Signal* arg1, __gnu_cxx::__ops::_Iter_comp_iter
由于我们只对Signal参数的正确参数位置和类型信息感兴趣,因此,我们可以使用ida2bn目录中提供的脚本对其进行修复:
int32_t* Dblqh::prepareContinueAfterBlockedLab(void* arg1, Signal* arg2, int64_t* arg3, int32_t arg4)
一旦类型信息得到修复,我们就可以使用Signal参数来识别函数并标记污染源了。关于通过Binary Ninja处理类型的更多细节,请参考https://docs.binary.ninja/guide/type.html。
污点的传播与过滤
污点传播的目标很简单:当某变量被赋予来自Signal数据中的值时,将其标记为污点。如果任何其他变量是从受污染的变量派生出来的,也将其标记为受污染的变量,依此类推。当存在sanitizer时,挑战就来了。假设一个变量被污染了,但是在某些代码路径中存在对该变量的验证处理。在这种情况下,该变量在该代码路径中就不会受污染了。污点传播应该对控制流敏感,以避免过度污染和误报。在下面的小节中,我们将介绍如何使用Binary Ninja的IL和SSA形式解决这个问题。此外,如果读者想要透彻掌握这个主题的话,可以进一步阅读https://blog.trailofbits.com/2017/01/31/breaking-down-binary-ninjas-low-level-il/和https://blog.trailofbits.com/2017/01/31/breaking-down-binary-ninjas-low-level-il/这两篇文章。
Binary Ninja的IL和SSA形式
Binary Ninja支持各种中间语言(IL),如低级IL(LLIL)、中级IL(MLIL)和高级IL(HLIL)。由于MLIL用变量抽象出了堆栈内存访问,并提供了与调用位置相关的参数,所以,我认为它更适合执行过程间的污点分析。此外,与HLIL相比,MLIL具有更加丰富的文档可用。
Binary Ninja提供的另一种强大功能是:能够为可用的IL提供静态单赋值(Single Static Assignment,SSA)形式。在SSA形式中,每个变量只被定义一次。当变量被重新赋予另一个值时,会创建一个新的变量版本。因此,我们可以在函数中“全方位地”跟踪一个被污染的变量。现在,请考虑下面最简单的例子:当变量x被重新赋值时,在SSA形式中会创建一个新版本的变量:
x = 1 x#0 = 1 x = x + 1 x#1 = x#0 + 1
SSA变量的def-use链
Binary Ninja提供了如下两个API:get_ssa_var_definition()和get_ssa_var_uses(),分别用来获取一个变量的定义位置及其用途。为了便于说明,请看下面Thrman::execOVERLOAD_STATUS_REP()方法的MLIL SSA代码片段:
Thrman::execOVERLOAD_STATUS_REP: 2 @ 00784165 rax#1 = zx.q([arg2#0 + 0x28].d @ mem#0) 3 @ 00784168 rcx#1 = [arg2#0 + 0x2c].d @ mem#0 4 @ 0078416b [arg1#0 + (rax#1 << 3) + 0x3ca0].d = rcx#1 @ mem#0 -> mem#1
这里,arg2是一个指向Signal对象的指针。在地址0x00784165处,SSA变量“rax#1”被赋予了一个来自[arg2#0+0x28]的污点值。使用这个被污染的SSA变量rax#1的MLIL指令可以被通过下列方式获得:
>>> current_function.get_low_level_il_at(here).mlil.ssa_form >>> current_function.get_low_level_il_at(here).mlil.ssa_form.dest>> ssa_var = current_function.get_low_level_il_at(here).mlil.ssa_form.dest >>> current_function.mlil.ssa_form.get_ssa_var_definition(ssa_var) >>> current_function.mlil.ssa_form.get_ssa_var_uses(ssa_var) [<il: [arg1#0 + (rax#1 << 3) + 0x3ca0].d = rcx#1 @ mem#0 ->mem#1>]
这些API是我们进一步进行污染分析的构建块。
用SSA def-use链进行污染传播
由于Binary Ninja的IL的组织形式为表达式树,因此,某个操作的操作数可以由其他操作组成。下图是BNIL Instruction Graph插件为MLIL SSA指令生成的:
>>> current_function.get_low_level_il_at(here).mlil.ssa_form >>> current_function.get_low_level_il_at(here).mlil.ssa_form.operation

其中,MLIL_SET_VAR_SSA操作标记了一个新SSA变量的定义,它将dest变量的值设为src表达式的结果,而src表达式可以由许多其他操作组成。就这里来说,MLIL_ADD向Signal的基址添加偏移量0x28,然后,MLIL_LOAD_SSA从通过MLIL_ADD计算得到的地址中读取该值。注意,有效的污染传播需要访问每个指令表达式的所有MLIL SSA操作。Josh Watson的emILator和Jordan的IL指令计数代码是访问和处理MLIL SSA指令表达式的好例子。那么,污点传播算法到底做了些什么呢?
◼线性访问函数中的所有MLIL SSA指令
◼对于任何MLIL_SET_VAR_SSA操作,解析src表达式以检查它是否是受污染的数据
◼如果src操作数返回受污染的数据,则使用get_ssa_var_uses()获取dest SSA变量的使用情况
◼访问使用受污染SSA变量的指令,并在遇到MLIL_SET_VAR_SSA时传播受污染的SSA变量
◼一旦某个指令污染了某个变量,将其标记为已访问,并且不再访问该变量
对SSA变量的约束
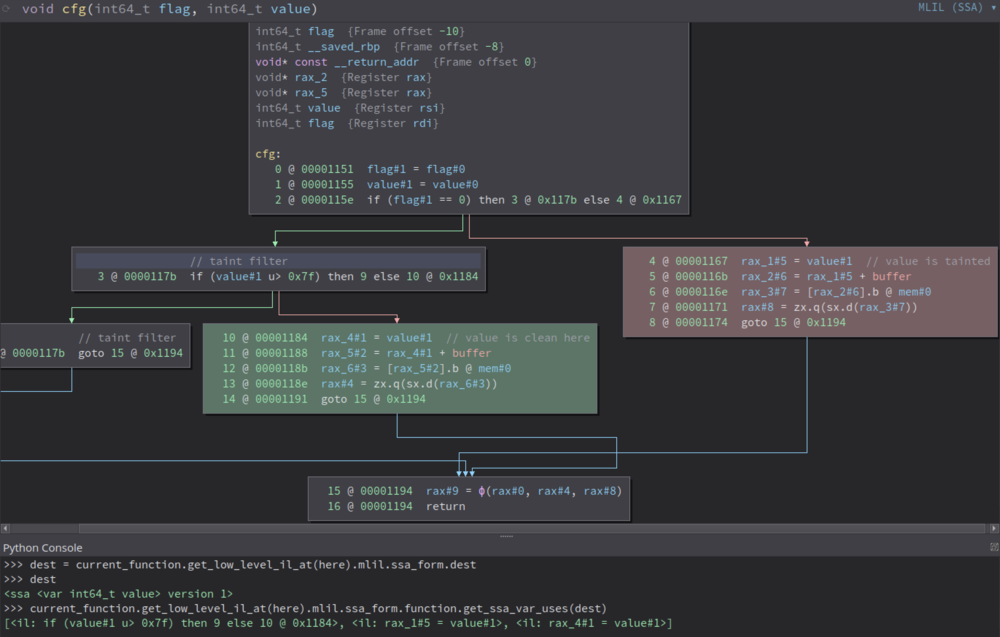
一旦确定了污点传播算法,接下来该如何处理污点变量的sanitizer呢?我们只对不进行任何验证的代码路径感兴趣。考虑到这一点,让我们重新审视一下基于def-use链的污点传播算法。实际上,def-use链就是代码的顺序语句;因此,这种污点传播对控制流并不敏感,具体请看下面的演示示例:

其中,传递给函数的变量“value”已经收到污染,并在两个不同的代码路径中被用到。在执行0x1184处的基本块的代码路径中,该变量进行了相应的验证,并被认为是“干净的”。同时,用于该变量的get_ssa_var_uses()函数返回了3条指令,具体如下所示:
>>> current_function.get_low_level_il_at(here).mlil.ssa_form.function.get_ssa_var_uses(dest) [
线性处理这3条指令会导致错误的结论,即验证在污点值的两次使用之前进行。实际上,只有一条指令是受保护的;而其他两条指令则是易受攻击的。这个问题可以通过引入控制流来解决。
基于约束图的控制流敏感传播
其中,MediumLevelILInstruction类有一个il_basic_block属性,可用来获取MLIL指令的基本块信息。
>>> current_function.get_low_level_il_at(here).mlil.ssa_form.il_basic_block
利用这个属性,我们可以获取SSA变量的定义和SSA变量的使用情况的基本块,其中也包括进行验证的基本块。这些基本块也被称为“约束”块。这些基本块的一些特性如下所示:
◼定义块总是支配着SSA变量的所有使用情况。
◼拥有定义的基本块可以包含约束。这同样适用于def-use链的任何基本块。
◼一个定义块总是可达的,因此,其中的所有指令也是可达的。
考虑到这是一个图的可达性问题,所以,现在问题就变成:在有约束块的情况下,我们能不能到达SSA变量的def-use链中的所有指令?为了回答这个问题,我们可以通过函数的CFG建立一个约束图,并对其应用如下路径查找算法:
◼从CFG中删除约束块的外向边。这就是我们的约束图。
◼在约束图中寻找定义基本块和其他def-use链的基本块之间是否存在路径。
◼如果任何def-use基本块无法到达,那么这些指令就不会被用于污点传播。
由于每个赋值操作在SSA表示中都是唯一的,因此,我们可以维护一个包括约束图在内的每个变量的必要信息的字典,以便做进一步的分析。下面是一个在存在约束块的情况下寻找可达块的示例伪码:
self.var_def_uses.setdefault(ssa_var, dict()) refs = definition.function.get_ssa_var_uses(ssa_var) basic_blocks = self.refs_to_basic_blocks(definition, refs) for ref in refs: self.get_constrained_blocks(ref, constraint_blocks, ssa_var) subgraph = self.get_constrained_subgraph(constraint_blocks) self.var_def_uses[ssa_var]["subgraph"] = subgraph reachable_blocks = self.get_reachable_blocks(definition, ssa_var, basic_blocks) for blk, stmts in basic_blocks.items(): if blk in reachable_blocks: pruned_refs += stmts self.var_def_uses[ssa_var]["def"] = definition self.var_def_uses[ssa_var]["refs"] = pruned_refs
要发现某个SSA变量是否在给定指令中被污染的,我们只需检查其可达的def-use链即可:
def is_reachable(self, var, expr): if self.function_mlilssa[expr.instr_index] in self.var_def_uses[var]["refs"]: return True
将算术运算作为过滤器
除了显式过滤器之外,还可以将算术运算用作污点过滤器。例如,AND运算或逻辑右移(LSR)运算可能会对值施加约束。在这种情况下,可以使用启发式方法过滤掉不想要的结果,例如:

在这里,表面上看污染值并未与任何值进行显式比较,但是,LSR和AND之类的逻辑运算实际上已经限制了输入范围。这就是我发现possible_values属性非常有用的地方。Binary Ninja的数据流分析可以为一个表达式提供可能的值:
>>> current_function.get_low_level_il_at(here).mlil.ssa_form.src >>> current_function.get_low_level_il_at(here).mlil.ssa_form.src.possible_values>> current_function.get_low_level_il_at(here).mlil.ssa_form.src >>> current_function.get_low_level_il_at(here).mlil.ssa_form.src.possible_values<unsigned ranges: [
处理污染变量的传递关系
分析的第一阶段,我们需要传播污染数据并生成相关信息,如污染变量列表、每个SSA变量的约束,以及它们各自的约束子图。
在分析的第二阶段,我们将考察受污染的SSA变量之间的关系。为什么这很重要?因为我们只寻找unbounded型SSA变量。虽然在第一阶段已经处理了对SSA变量施加的任何直接约束,但还没有处理通过传递关系施加给SSA变量的那些间接约束。考虑下面的示例:

变量index#0可能被污染且不受约束。但是,由于对派生变量constrained_var#1进行了验证,从而间接地对index变量施加了约束,因此,index#3在0x11f2的内存访问期间不会被污染。下面是另一个例子:

这里,index#1、index#2、rax#1和constrained_var#1是变量index#0的副本或直接赋值。当变量constrained_var#1被验证时,其他变量也会被验证。因此,如果不分析约束对派生变量或变量副本的影响,则会导致误报。接下来,我们将详细介绍如何处理相关变量的约束问题。
通过传递关系施加给SSA变量的约束
在污点传播阶段结束后,我们将遍历所有有约束的污点变量。对于每一个有约束的变量,我们需要找出其子变量和父变量:
◼从给定变量派生的变量称为子变量。
◼派生给定变量的变量称为父变量。
为了检查所考查的变量上的约束是否对其父变量或子变量产生影响,我们需要进行以下检查:
为所考查的SSA变量挑选约束子图。
检查子变量的定义是否可以从当前变量的定义中到达:
如果不可达,则在CFG中定义子变量之前放置约束,因此,def-use链中的基本块都不会被污染。
如果可达,则在CFG中定义子变量之后放置约束。在这种情况下,还要检查子变量的def-use链上的所有基本块是否可以从自变量的定义中到达;并将不能到达的块标记为“干净的”。
对于每个父变量,获得其子变量的列表。虽然当前变量的所有子变量也是父变量的子变量,但父变量也可能有其他子变量。在上一步中已经访问过的子变量可以跳过。然后,检查子变量的定义是否可以从父变量的定义中到达,并重复上一步提到的方法,将不可到达的块标记为“干净的”。
这样一来,非可达的基本块就从与受约束变量相关的变量的污点条目中被移除。我们也可以选择对派生的变量进行分析,或者只是使用与变量相关的标签进行直接赋值。
在传播污点时,使用了两种不同的标签:使用MLIL_LOAD_SSA从污点内存中直接加载内存会返回一个偏移量、大小对作为标签,并与目标变量相关联。而对于任何派生变量,目标变量与一个标签相关联,但不返回偏移量和大小,例如,请看下面的代码:
7 @ 007615a3 rcx_1#2 = zx.q([arg2#0 + 0x2c].d @ mem#2) 8 @ 007615a6 rbx#1 = rcx_1#2 9 @ 007615a9 rbx_1#2 = rbx#1 u>> 5 10 @ 007615ad rax_1#2 = [arg1#0 + (rbx_1#2 << 2) + 0x3b40].d @ mem#2
变量rcx_1#2是一个污染变量,并且带有一个标签[0x2c, 0x4],分别表示偏移量和大小。这个变量与rbx#1变量的情况基本相同,只不过后者是直接赋值的。然而,从表达式rbx#1 u>>5派生出来的rbx_1#2变量是污染变量,标签为[0xdeadbeef, 0xdeadbeef]。不同的标签类型信息,可用于确定污点传播的性质。
小结
在本文中,我们为读者介绍了污点源的定义等静态污点分析方面的知识,在接下来的文章中,我们将继续为读者演示如何处理来自多个污染源的SSA变量的约束等技巧。更多精彩内容,敬请期待!
(未完待续)
本文翻译自:https://www.zerodayinitiative.com/blog/2022/2/14/static-taint-analysis-using-binary-ninja-a-case-study-of-mysql-cluster-vulnerabilities如若转载,请注明原文地址
如有侵权请联系:admin#unsafe.sh