原文作者:LAVANYA ELLURI, (Member, IEEE), SAI SREE LAYA CHUKKAPALLI, (Graduate Student Member, IEEE), KARUNA PANDE JOSHI, (Senior Member, IEEE), TIM FININ, (Member, IEEE), AND ANUPAM JOSHI, (Fellow, IEEE) 原文标题:A BERT Based Approach to Measure Web Services Policies Compliance With GDPR 原文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9592800 原文来源:IEEE Access 笔记作者:[email protected] 笔记小编:[email protected]
介绍
应用供应商需要更新其服务政策来应对大量监管文件,但是其提供的隐私政策相对监管文件来说较短,因此很难确定政策文件是否涉及法规的基本要素。
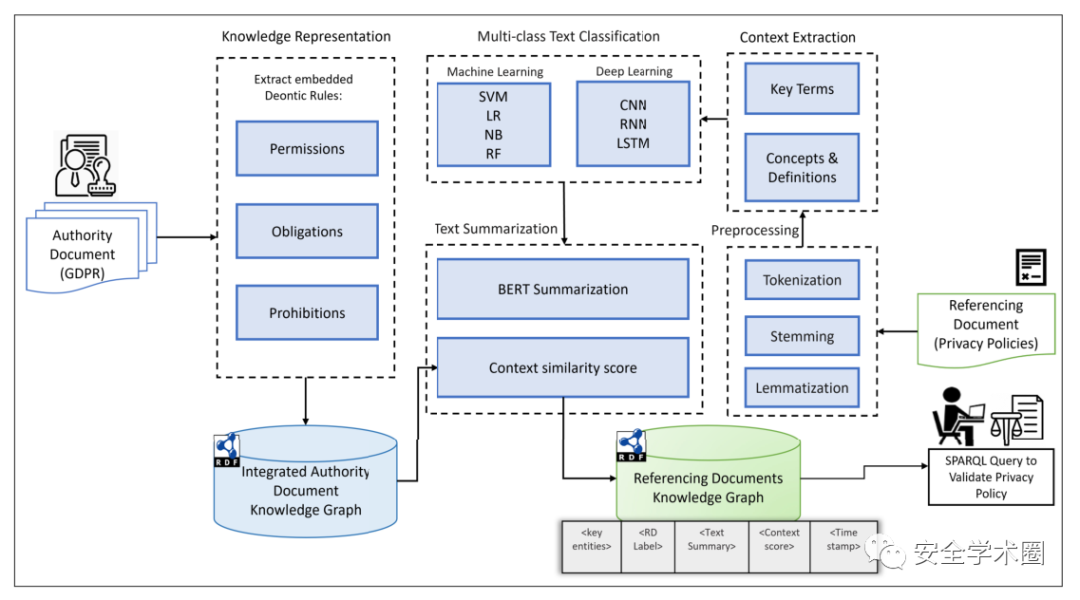
本文提出的自动化框架使用BiLSTM多分类器识别GDPR类,针对提取出的上下文,使用基于BERT的文本摘要器进行处理,以获得隐私策略和GDPR文档之间的相似性分数。
提出的方法
A. GDPR文档知识图谱构建
使用命名实体识别等方法来确定GDPR语料库中最频繁出现的实体,选择了四个最常出现的实体:Controller(判断处理操作正误的法律机构)、Processor(处理个人数据者)、Data Subject(被收集信息者)、Supervisory Authority(保护个人数据者)。
在规则定义方面,使用“权利”和“义务”将句子标记,带有“could”、“may”、“can”等动词的句子被归类为权利,有“must”、“shall”、“should”等动词的句子被归类为义务。
B. 数据集收集
爬取了全球3000多个试图遵守GDPR的隐私政策文件。再从这些文件中提取A中的四中实体,在这3000多个隐私政策文件中,这四个实体可能全部都不出现,也有可能全部都出现,因此总共有有16种组合方式,统计如下:
例如上图中,有122个隐私政策中没有出现与GDPR相关的实体(C13-No Entities)。
C. 对隐私政策的文本多分类
使用多种机器学习方式来进行B中定义的16分类。
D. 文本摘要
使用BERT + K-means获取隐私政策文本摘要:
E. 隐私政策文档知识图谱
下图展示了知识图谱中的Azure实例:
上图中的Context_Score代表从GDPR和从隐私政策文档中提取的与关键实体相关的文本摘要的相似性得分。
总结
本文从GDPR和web提供商的政策文本获取知识并存储在知识图谱中。首先在GDPR文档中识别关键实体,然后使用实体的组合作为不同GDPR类别;然后应用机器学习和深度学习来分类隐私策略文档;在识别类别后,使用BERT文本摘要对提取的文本进行处理;最后,比较GDPR文件和隐私政策文本的摘要,以获得上下文相似性分数;提取的摘要和上下文相似性分数存储在知识图谱中。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh