原文标题:Price TAG: Towards Semi-Automatically Discovery Tactics, Techniques and Procedures OF E-Commerce Cyber Threat Intelligence
原文作者:Yiming Wu; Qianjun Liu; Xiaojing Liao; Shouling Ji; Peng Wang; Xiaofeng Wang; Chunming Wu; Zhao Li
原文链接:https://ieeexplore.ieee.org/abstract/document/9576636/
原文来源:TDSC'21
笔记作者:[email protected]
文章小编:[email protected]
简介
电子商务中的网络安全威胁体现在欺诈行为、声誉操纵等方面,这些攻击行为会对用户数据的完整性造成破坏,例如销售量膨胀,商品排名升级,或操纵搜索引擎的结果以在短时间内获得流量。如常见的刷销量行为,就是通过虚假订单伪造出高销售量来提高人气,从而促销某种目标商品,也被称作”拍A发B“。由于电子商务威胁不同于拒绝服务、入侵攻击等传统网络安全威胁,之前的研究工作对于识别这类威胁行为并不适用。因此,作者设计了TAG(TTP Semi-Automatic Generator)的新方法,提取电子商务领域的TTP。
方法
上图是TAG的总体结构图,主要包含四个部分:语料库收集器、文本预处理器、主题词标识器、TTP实体识别器。
语料库收集:利用阿里的”先知“平台,从900多个网站中收集威胁文章,并与阿里合作,人工定义了34种电子商务TTP,如下表所示。利用这些TTP作为种子,以关键词匹配的方式收集电子商务威胁相关的页面。 文本预处理:首先,关键词匹配后的文章有可能存在重复,通过计算两篇文章的SimHash值的汉明距离比较它们的相似性,如果汉明距离大于2bits,则删除其中一篇。对于电子商务威胁的中文分词,jieba和LTP等工具都不能正确分词,因此作者设计了一种基于n-gram的邻居词频率统计方法来辅助分词。若相邻词的频率相等,则两个都丢弃,采用更长的n-gram继续统计;否则保留频率较高的那一个,如下图所示。 主题词标识:在这一场景中,文章的主题词一般与上述定义的34种TTP有相似的语义和结构,因此分别计算词汇的语义相似度和结构相似度,加权后取其中的最大值;其中语义相似度由词向量的余弦相似度得到,结构相似度由编辑距离得到。 TTP实体识别:由于语料库中收集到的文章还包含了广告等其他内容,TTP在其中的分布比较稀疏,因此首先删除了文章中的不相关信息。预处理后,剩余的内容从语法结构入手,定义了6种规则来提取TTP实体。
实验
作者分两个时期共收集了22380篇文章作为实验数据集,使用分层抽样从每个时期中抽取500篇文章人工标记,再进行五折交叉验证来评估模型,各个部分的实验结果如下:
预处理在识别:53.55%的准确率和83.12%的召回率; 过滤不相关TTP句子:正确与错误的数量分别为483条和203条; 主题词识别:49.33%的准确率和95.41%的召回率; TTP识别:45.56%的准确率和88.47%的召回率;
从结果上看,这一算法可以达到较高的召回率,但代价则是准确率相对较低。
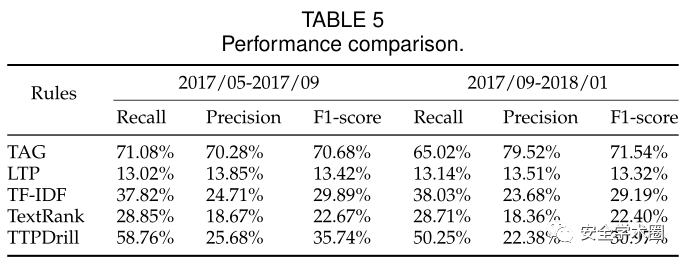
作者在自己收集的语料库中对比了几种方法的实验结果,如下图所示,作者的方法要优于其他一些主流的方法。
虽然作者的这一方法要比其他NLP方法有着更高的准确性和覆盖面,但攻击者也有可能通过省略某些词汇、调换黑话的顺序等方式来绕过模型的检测,同时对于人类理解而言不会有很大的影响,即模型的抗干扰能力还存在一定的改进空间。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh