
阅读: 3
在人工智能实践中,数据是载体和基础,智能是追求的目标,而机器学习则是从数据通往智能的技术桥梁。因此,在人工智能领域,机器学习才是核心,是现代人工智能的本质。
本文作者:李阳/李忠义/郝传洲/赵粤征
引言
“从希腊哲学到现代物理学的整个科学史中,不断有人试图把表面上极为复杂的自然现象归结为几个简单的基本概念和关系,这就是整个自然哲学的基本原理。”
——爱因斯坦
近年来,在IT圈大家谈论最多的就是人工智能。AlphaGo与围棋选手的人机大战更是让我们领略到人工智能技术巨大潜力的同时,又将人工智能推向了一个新的制高点。所谓人工智能,通俗地讲是指由人工制造出来的系统所表现出来的智能。人工智能研究的核心问题包括推理、知识、交流、感知、移动和操作物体的能力,而机器学习是人工智能的一个分支,很多时候机器学习几乎成为人工智能的代名词。机器学习简单来讲就是通过算法,使机器能从大量历史数据中学习规律,从而对新的样本做出智能识别或对未来做预测。
在人工智能实践中,数据是载体和基础,智能是追求的目标,而机器学习则是从数据通往智能的技术桥梁。因此,在人工智能领域,机器学习才是核心,是现代人工智能的本质。传统的基于规则的安全威胁分析是构建于已知数据模型到已知威胁模型的构建过程,面对越来越复杂、越来越隐秘的安全攻击方式,在需要分析的特征维度大规模增长的情况下,是有其局限性的,特别是在“know-unknows”方面的分析上,规则方法上就显得太单薄了;而通过机器学习构建行为基线识别未知的异常上具备较大的优势,但单纯的机器学习通过各类聚类算法或者神经网络的迭代学习后形成的基线去检测出来的异常可能对客户来说是没有意义的,也就是没有清晰的视角去引导客户说明这样一个未知的威胁是一个什么威胁,这也是机器学习特别是聚类分析中得到分析结果的片面性,因此需要将两者有机的结合起来,才能最终实现安全威胁分析从“know-knowns”阶段到“know-unknows”阶段的飞跃。
微软的资深专家Bugra Karabey分享的如何把机器学习作为分析工具在安全攻击分析中的应用切中目前机器学习在安全分析中主要发展方向,他提出的一个场景“如何使用主成分分析聚类识别安全事件模式”引起我们的关注。他们针对大规模的安全事件库,构造了一个采用PCA聚类分析进行降维分析模型,形成安全事件数据集并识别潜在威胁,对安全事件进行分组聚类,形成不同的数据聚类模式或者说是事件之间存在不同的行为模式。在此基础之上,有经验的安全分析专家针对这些已经分类的数据集进行风险或威胁的关联分析,最终从数据中获得潜在的威胁。
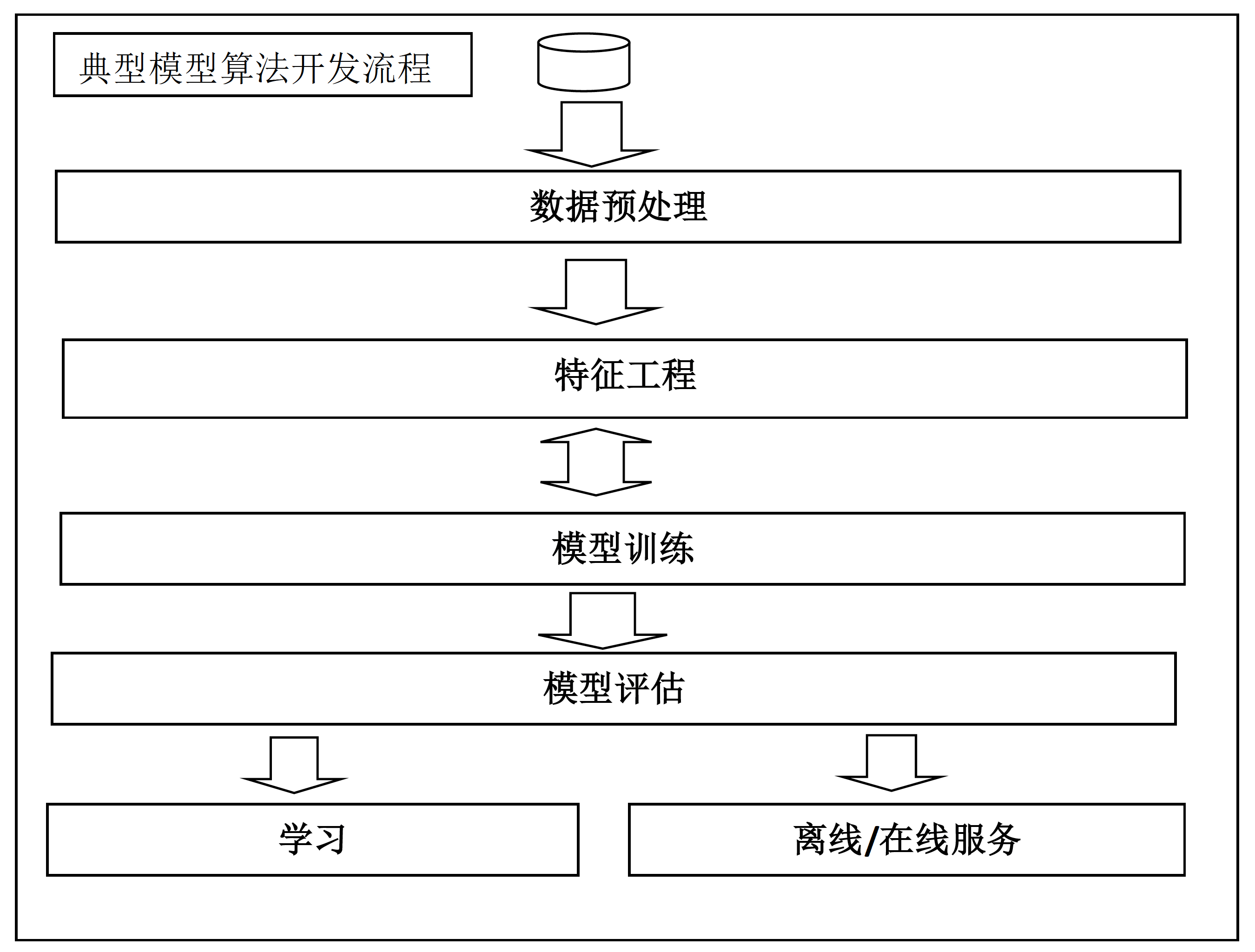
整个机器学习的数据分析流程大致可以分为6个步骤,整个流程按照数据流自上而下的顺序排列,分别是场景解析、数据预处理、特征工程、模型训练、模型评估、离线/在线服务。如下图所示:
规则检测只能检测已有的威胁,无法对未知威胁进行检测、也无法对历史数据中存在的潜在的威胁进行分析,利用机器学习算法中的聚类算法对这些历史数据进行分析,发现数据中的未知的威胁,达到获取未知威胁,降低潜在风险的目的。我们在标准机器学习算法的基础上对于分析步骤进行了优化,创新实现了聚类分析的无监督分析方式,同时实现了自动的数据分析方式(本文不涉及)。在此基础上对某电信数据进行了分析,对于可能存在的异常进行了预测与数据进行逆向分析,推理出了异常行为,该分析结果得到了用户的确认。
1. 样本数据情况
| 数据类别 | 数据条数 | 数据跨度 | 数据大小 |
| 登陆数据 | 43472 | 2019/02/13-2019/02/20 | 28.5G |
| 提权数据 | 3395574 | 2019/02/14-2019/02/20 | |
| 业务数据 | 227420675(Kernel) | – | |
| 926434(cron) | – |
2. 算法和特征维度
本次分析中采用的层次聚类,层次聚类算法是递归地对数据对象进行合并或者分裂,直到满足某种迭代终止条件,例如最终类簇的个数为m或者簇与簇之间的距离不大于μ。根据层次的分解方式,层次聚类算法具体又可以分为“自底向上”(分裂法)和“自顶向下”(合并法)两种方案。在层次聚类算法中大多采用合并法,合并法的主要思想是:给定n个对象的集合D,合并型层次聚类得到D的一系列划分: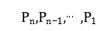 ,其中
,其中 有n个单成员聚类,
有n个单成员聚类,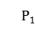 只有一个聚类,它包含所有的对象。合并型层次聚类算法具体步骤图所示:
只有一个聚类,它包含所有的对象。合并型层次聚类算法具体步骤图所示:
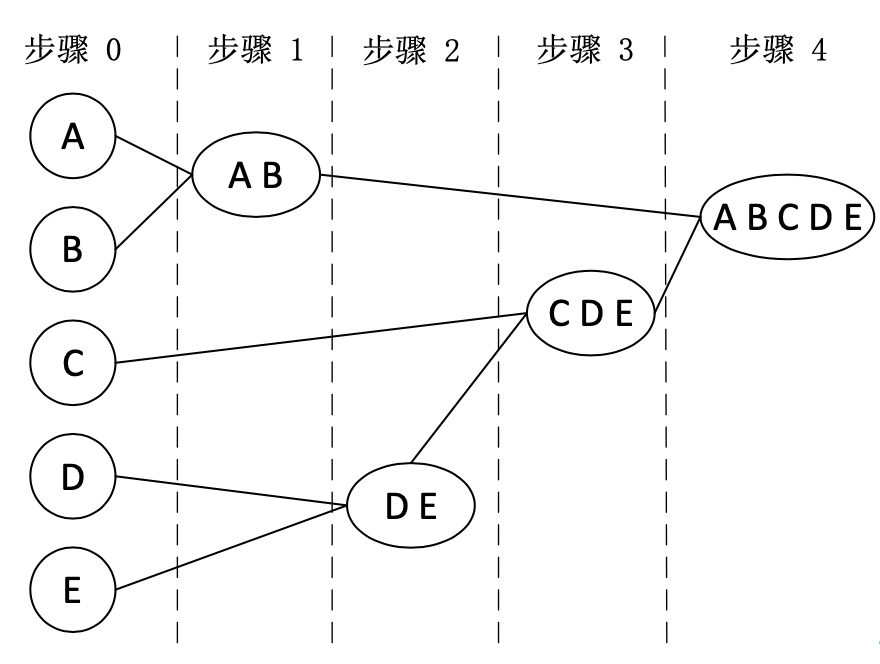
1)将每个数据点(即每条文件下载日志)当作一个类簇,并提取日志特征,其特征向量表示为: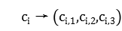 ,其中,向量的各个维度分别表示文件下载时间、文件大小以及远端IP地址。
,其中,向量的各个维度分别表示文件下载时间、文件大小以及远端IP地址。
2)计算两两类簇之间的距离。计算两个类簇数据点间距离的方法有三种,计算两个组合数据点中的每个数据点与其他所有数据点的距离。将所有距离的均值作为两个组合数据点间的距离。
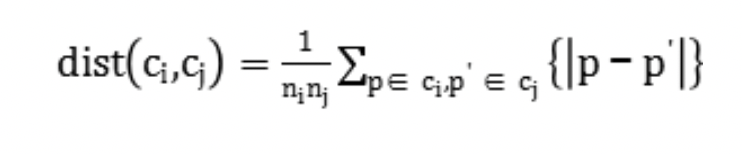
式中,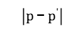 表示点
表示点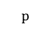 和点
和点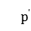 之间的距离。考虑到类簇数据点中各个维度之间的尺度不同,故对各个维度分别进行处理,使得各个维度分别满足标准正态分布,通过计算数据点之间的标准欧式距离实现,公式如下。
之间的距离。考虑到类簇数据点中各个维度之间的尺度不同,故对各个维度分别进行处理,使得各个维度分别满足标准正态分布,通过计算数据点之间的标准欧式距离实现,公式如下。
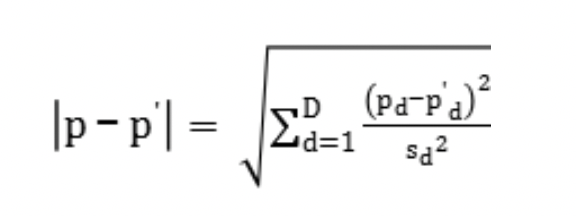
式中,D表示向量的维度,即日志包含的特征,在本场景中D为3。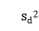 表示第d维度的方差。
表示第d维度的方差。
3)找到距离最小的两个类簇 和
和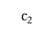 ,将其合并为一个类簇
,将其合并为一个类簇
4)重复步骤2)、3),直至类簇之间距离不大于μ,μ为训练参数。当类簇建距离小于等于μ时聚类结束,得到所有分类结果。
整个分析过程采用分层聚类算法的无监督方式对数据进行聚类,找到离群点,对离群数据进行逆向分析,定位攻击事件及攻击者和被攻击者。在保持原有数据格式的基础上,算法采用的特征维度包括:用户名、时间、源IP、目的IP,同时加入了高频提权命令的分析过程。
| 登录时间 | 源IP | 目的IP | 用户名 |
| 201922002 | 10.*.*.* | 10.*.*.* | mdncluster |
以登录数据为例,将时间点转换到为以小时为单位的数据,将源IP、目的IP和用户名组合形成可唯一确定访问关系的形式,然后将整体数据进行聚类,以频次为切入点得出用户登录的行为基线,从而以基线为准,判断超出基线的行为即属于异常行为。
3. 数据分析过程
3.1、暴力破解
Step 1 全局聚类发现异常点
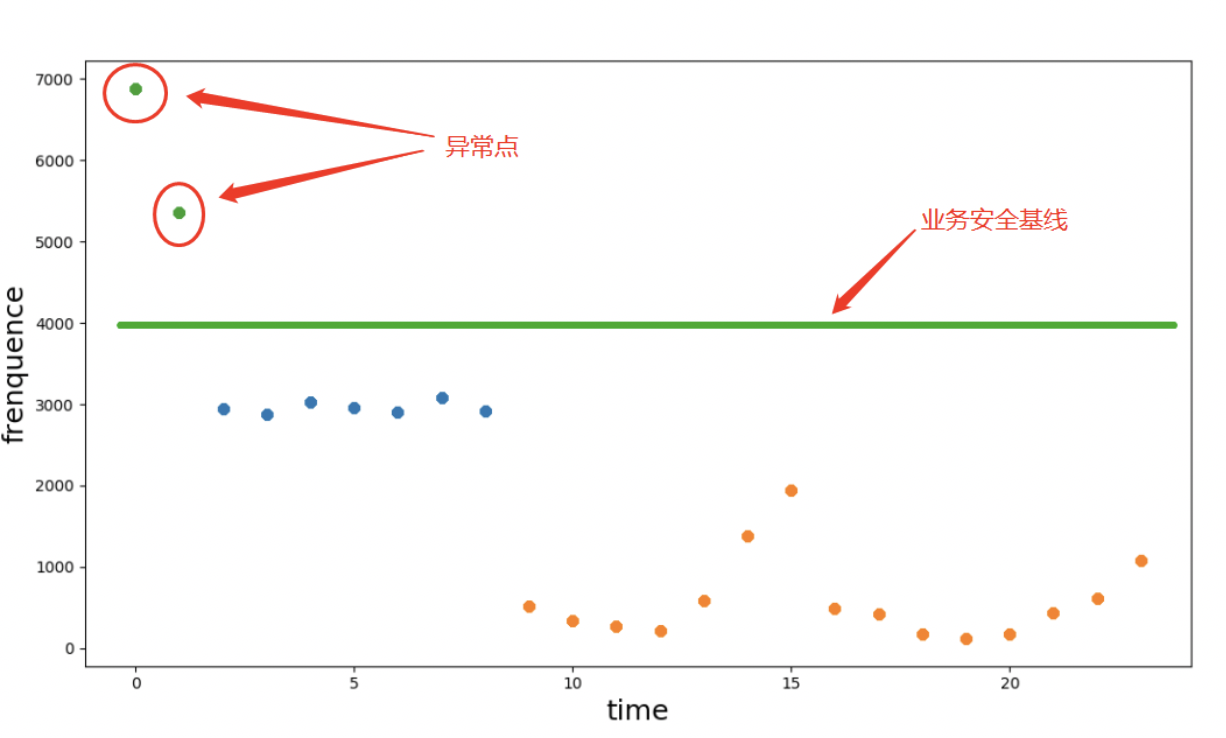
上图以主机登陆维度,展示2019年2月13日到2019年2月20日行为散列情况,其中0点至1点出现明显与其他时间业务习惯不符的异常情况,存在潜在威胁。
Step 2 锁定威胁来源
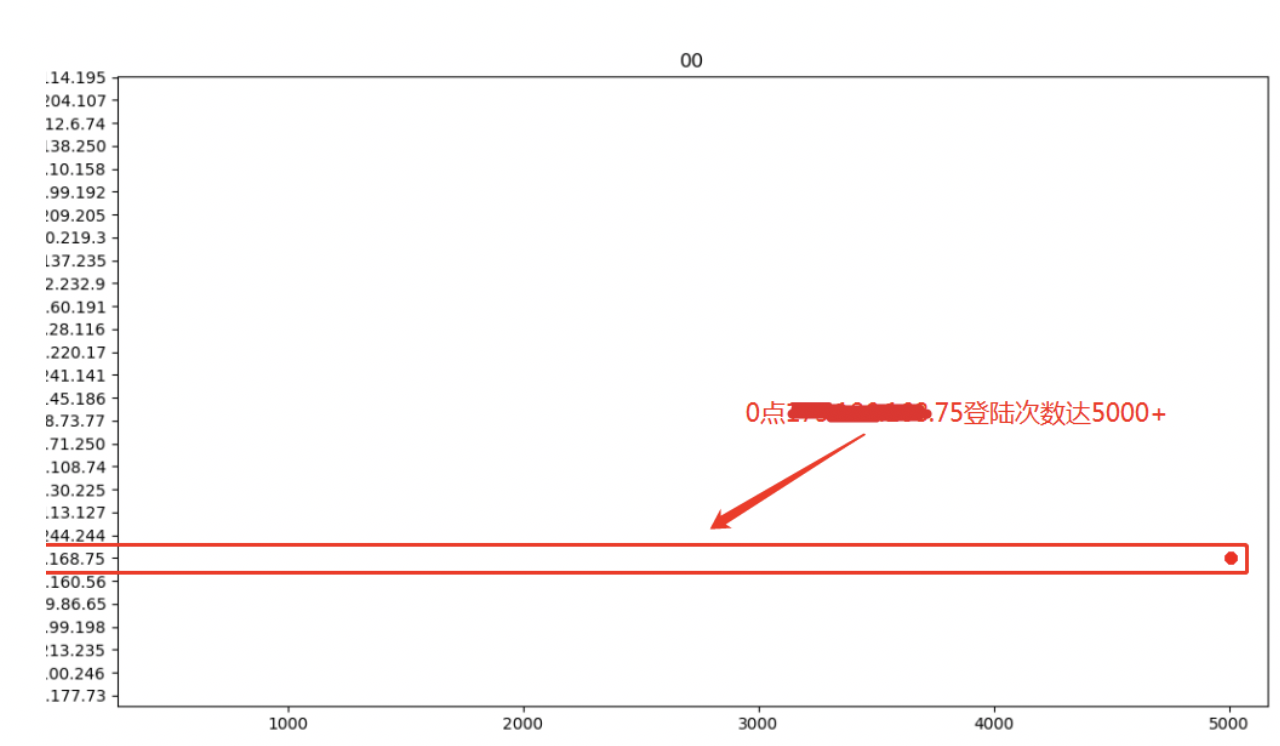
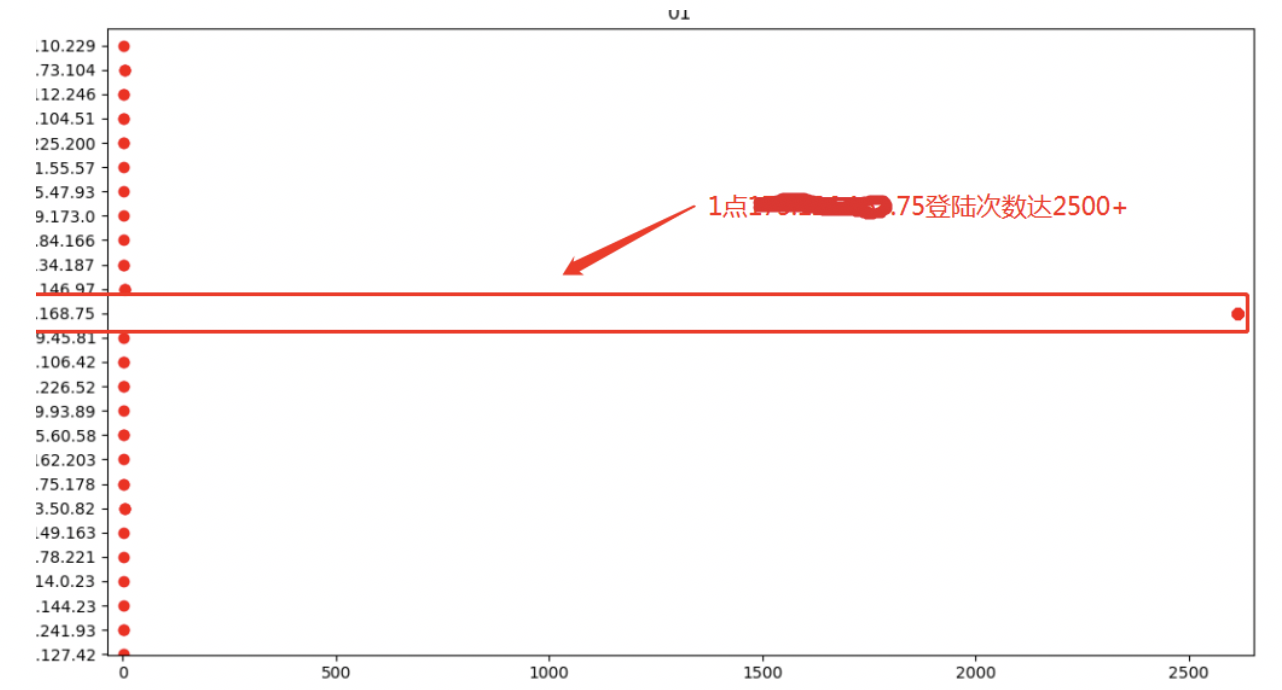
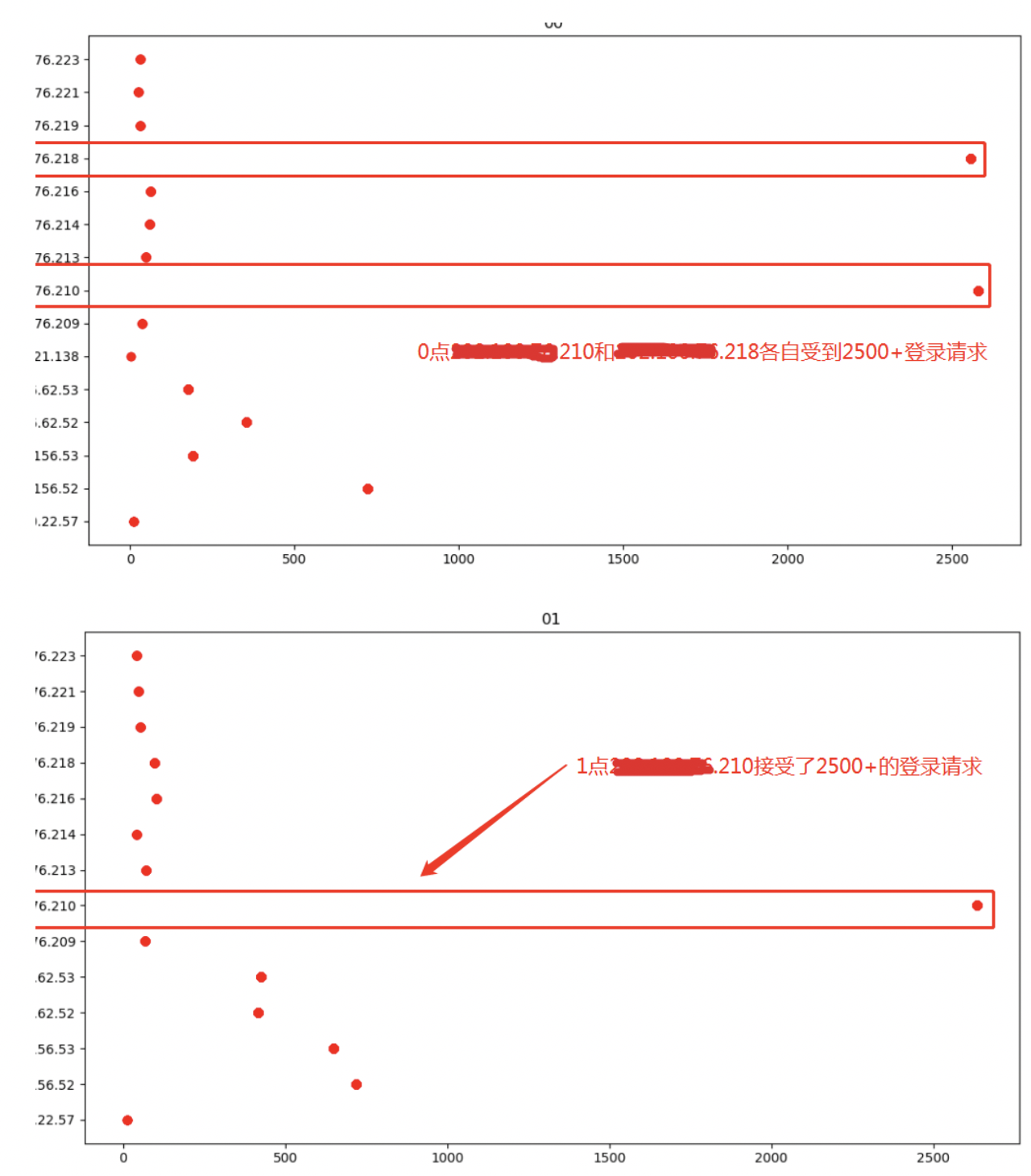
以主机维度分析,锁定攻击源,将攻击行为追溯到具体的行为主体。图示,2019年2月20日0点至1点主机*.*.*.75共发出7500多条登陆请求,未成功登陆。
Step 3 确定受害者范围

以主机维度分析,围绕一次攻击事件圈定受害者范围,横向关联到具体的受害者实体。图示,自0点至1点*.*.*.75主机登陆请求目的地,确定被攻击者分别为*.*.*.218,*.*.*.210两台主机。
Step 4 评估损失
未登陆成功,根据现有的样本未发现损失。以下列表是经过分析后有暴力破解可能的主机访问关系。
| des_ip | src_ip | frenquence | username |
| *.*.*.53 | *.*.*.8 | 3600+ | mdncluster |
| *.*.*.53 | *.*.*.8 | 2800+ | mdncluster |
| *.*.*.218 | *.*.*.75 | 2550+ | root |
| *.*.*.52 | *.*.*.53 | 3350+ | mdncluster |
| *.*.*.52 | *.*.*.8 | 3750+ | mdncluter |
| *.*.*.213 | *.*.*.75 | 2500+ | root |
| *.*.*.53 | *.*.*.53 | 2600+ | mdncluter |
| *.*.*.210 | *.*.*.75 | 5000+ | root |
| *.*.*.52 | *.*.*.8 | 3200+ | mdncluster |
Step 5 处理建议
进一步排查*.*.*.75被多次访问的原因。
3.2、数据泄露
Step 1 全集聚类发现异常点
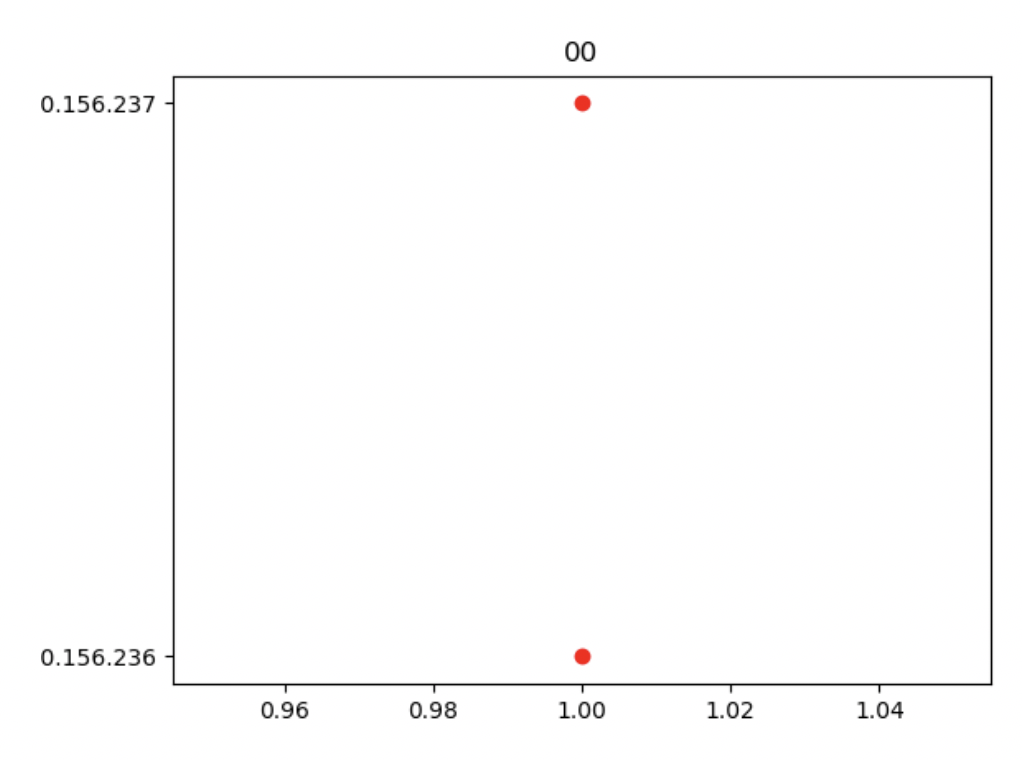
2019年2月17日0点时*.*.*.237和*.*.*.236发生了一次登陆请求,时间点和频次都和其他主机有很大差异,通过这一次的登陆我们找到了用户疑似密码泄露的数据。
Step 2 锁定威胁来源
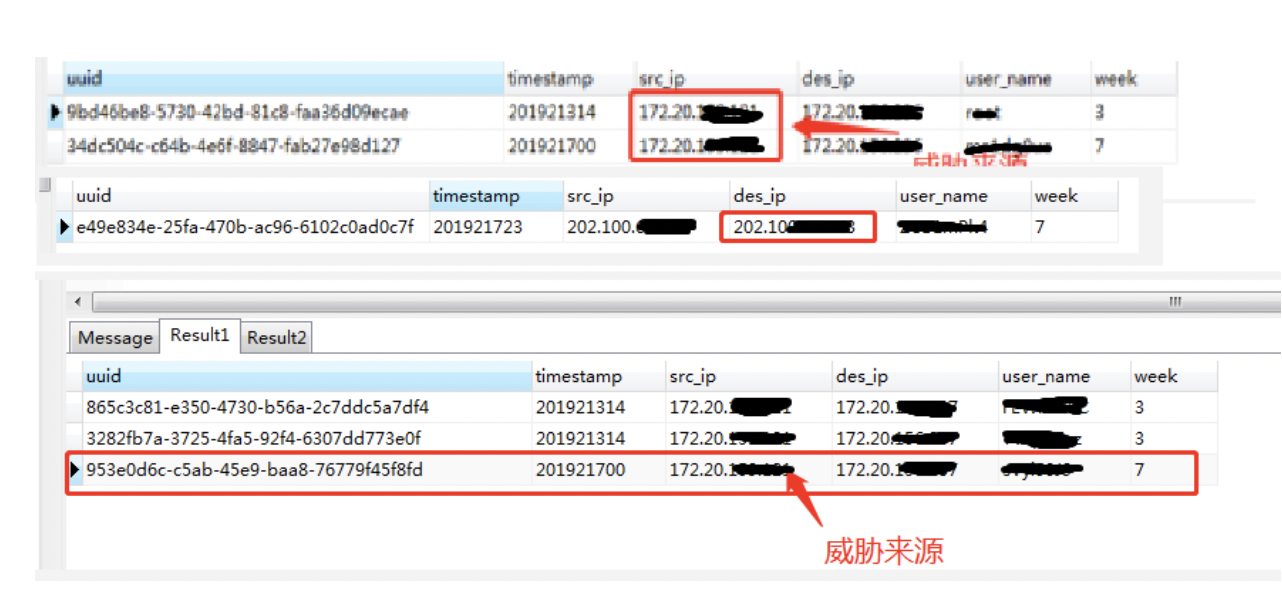
Step 3 定位受害者范围
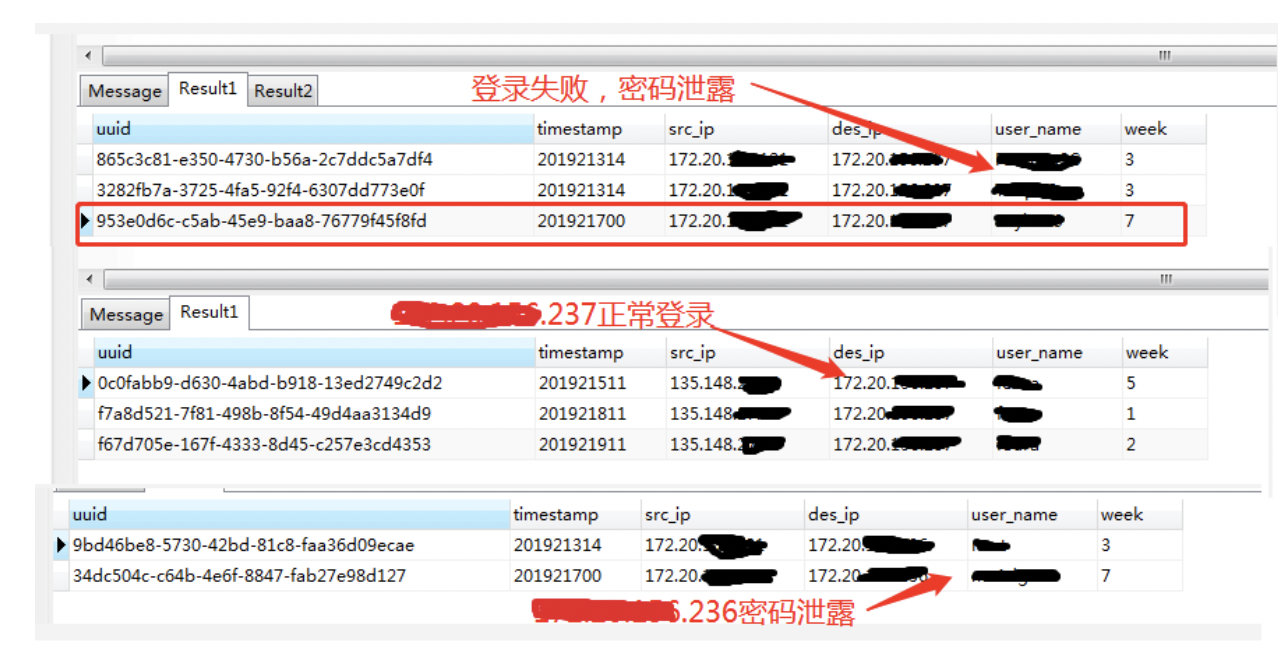
通过数据分析发现*.*.*.237和*.*.*.236两台主机存在密码泄露的异常。
3.3、高频次提权
Step 1 全集聚类发现异常点
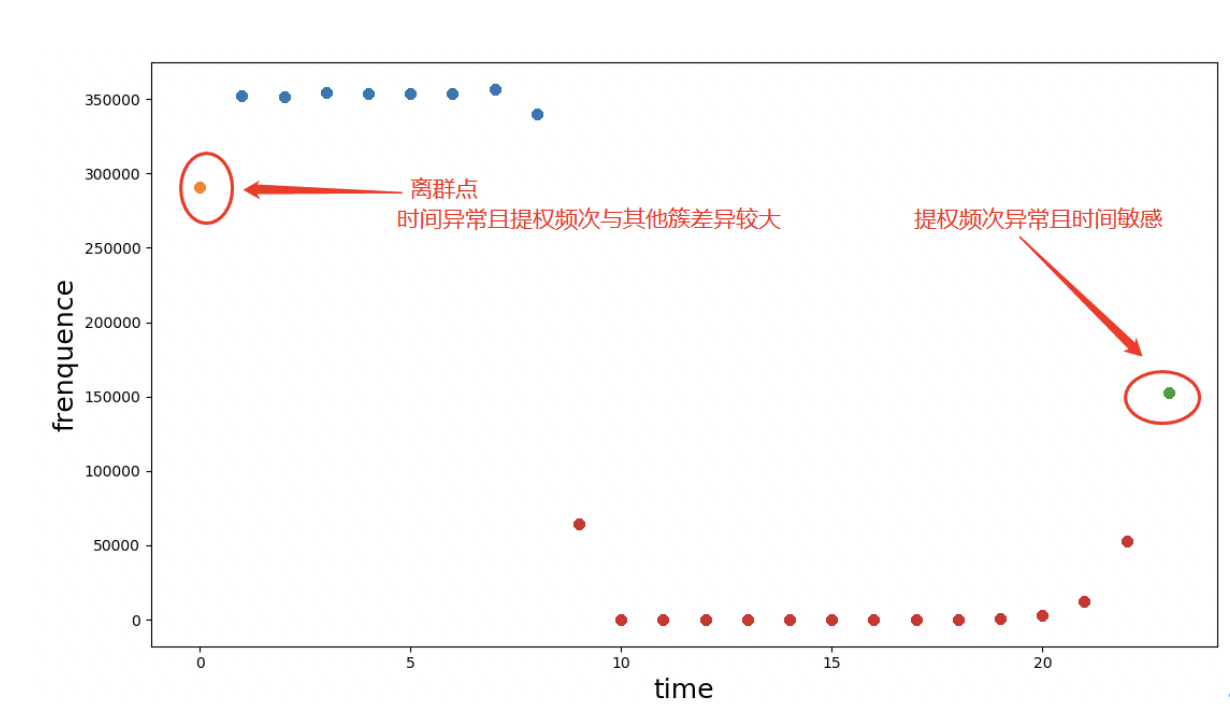
从整体的提权数据聚类结果来看,1点到8点为用户提权行为的高发期,9点到22点期间提权行为发生频次低且波动不明显,23点和0点为两个离群点,提权时间和频次和其他簇存在交大差异,可断定其为异常点。
Step 2 锁定威胁来源
提权数据无法锁定威胁来源
Step 3 定位受害者范围
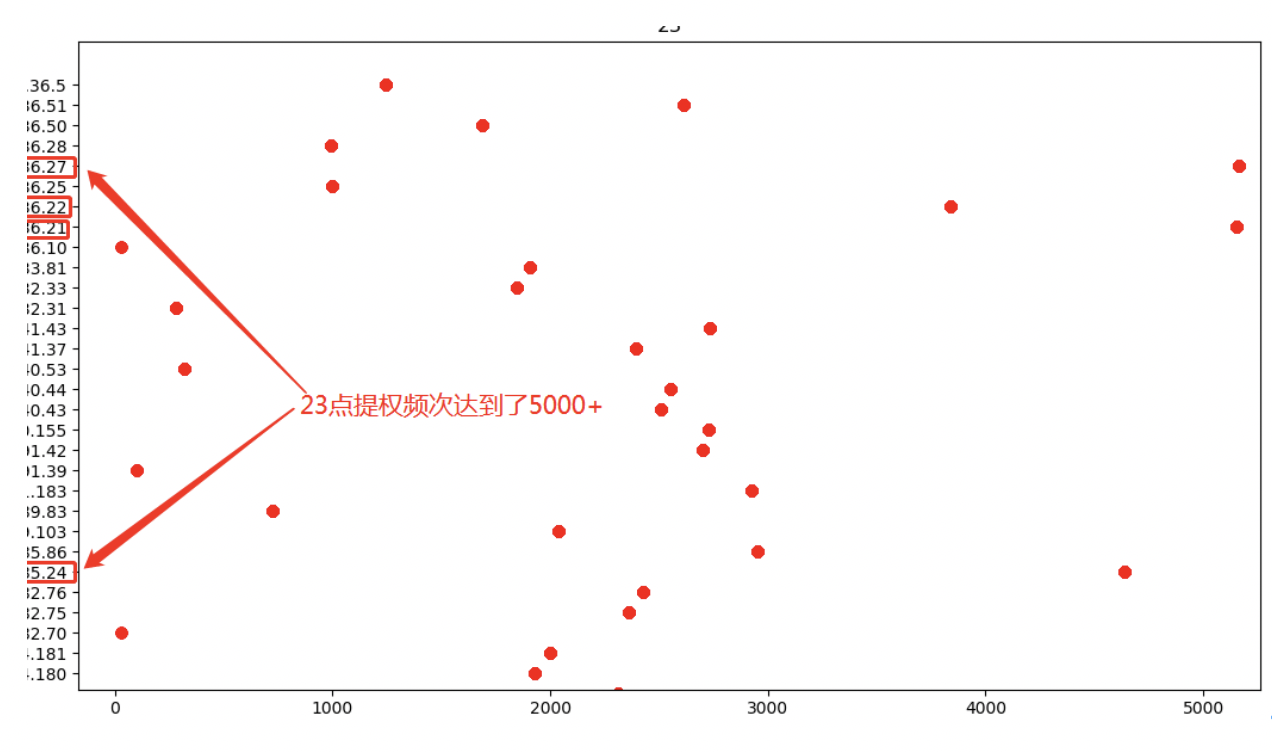
对23点进行详细分析,发现以下IP:*.*.*.27、*.*.*.22、*.*.*.21、*.*.*.24单个Server提权次数达到了5000次,可疑程度较大。
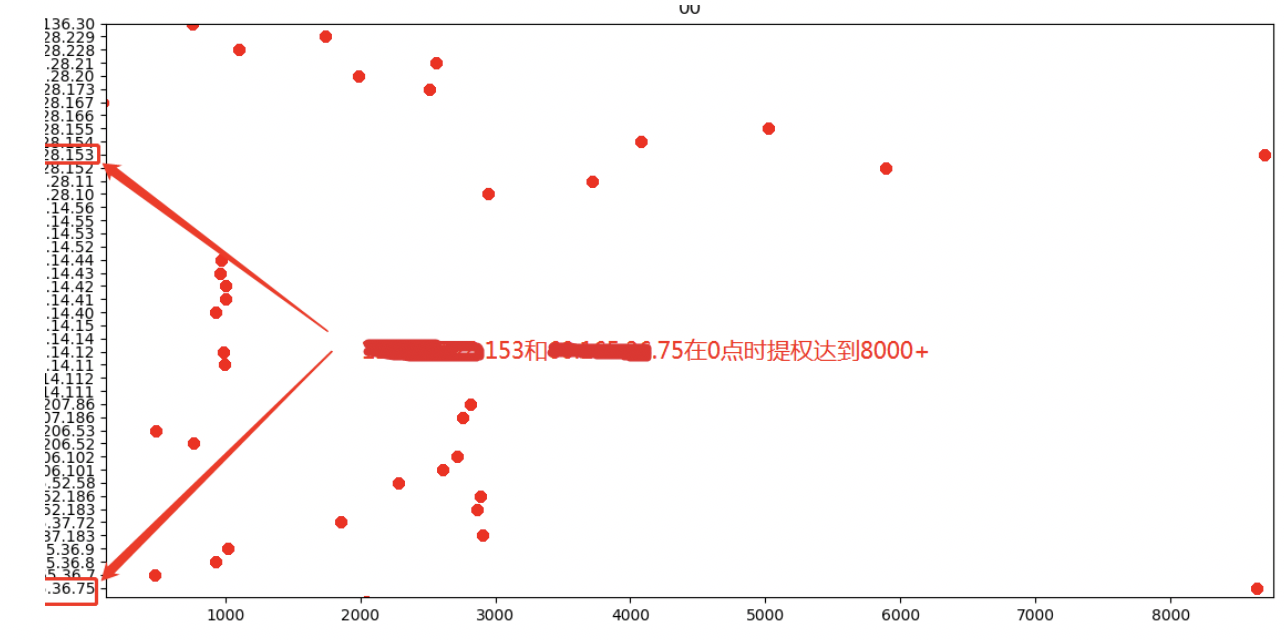
对0点进行详细分析,发现以下IP:*.*.*.153、*.*.*.75单个Server提权次数达到了8000次,可疑程度较大。
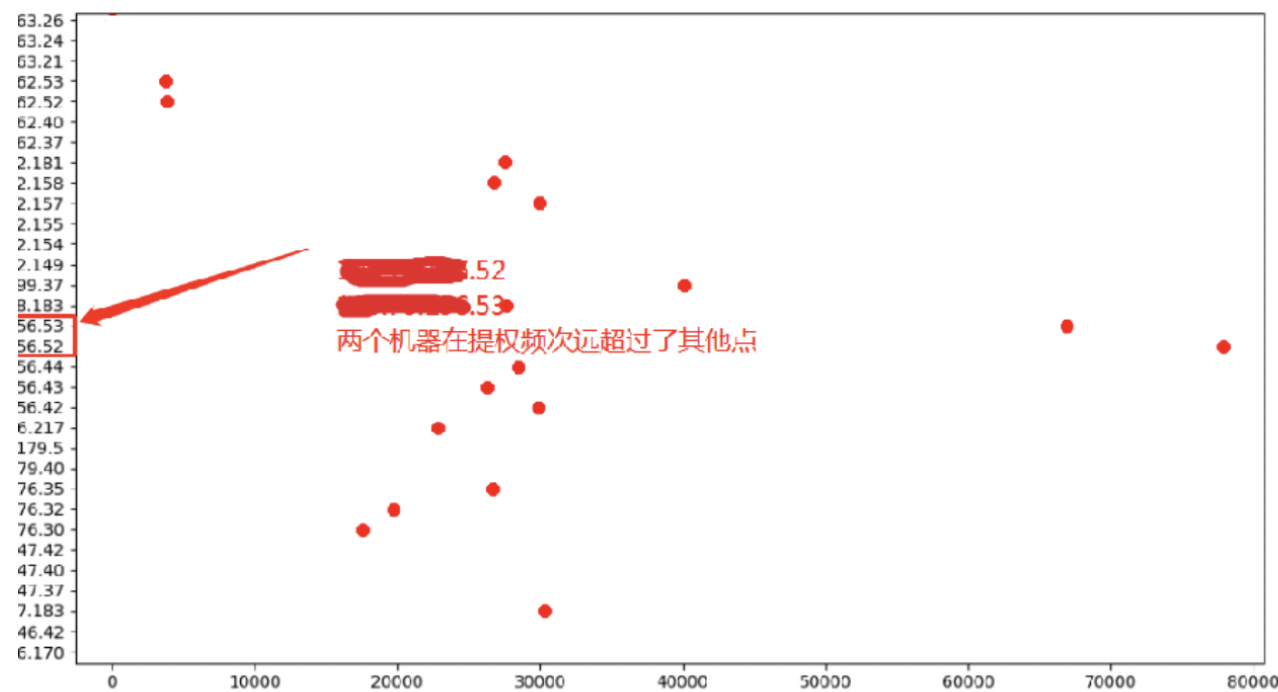
整体数据按照IP划分后发现,*.*.*.52、*.*.*.53发生了多大近8W次提权操作,占整体提权数据的3%,可疑程度较大。
| 小时 | IP | 频次 | 高频提权 |
| 23 | *.*.*.21 | 5000次 | /root/modules/agent/shell/runcommand.sh
/usr/sbin/crm_mon |
| 23 | *.*.*.22 | 5000次 | /root/modules/agent/shell/runcommand.sh
/usr/sbin/crm_mon |
| 23 | *.*.*.27 | 5000次 | /root//modules/agent/shell/runcommand.sh
/usr/sbin/crm_mon |
| 23 | *.*.*.24 | 5000次 | /root/modules/agent/shell/runcommand.sh |
| 0 | *.*.*.75 | 8000次 | /root/modules/agent/shell/runcommand.sh
/usr/local/slb/slb_healthcheck_rrs.sh |
| 0 | *.*.*.153 | 8000次 | /root/modules/agent/shell/runcommand.sh
/usr/local/slb/slb_healthcheck_rrs.sh |
| 0-23 | *.*.*.52 | 80000次 | /usr/bin/lsof
/home/userslb/slb/config/testPort |
| 0-23 | *.*.*.53 | 80000次 | /usr/bin/lsof
/home/userslb/slb/config/testPort |
通过以上分析过程的分析我们发现,对于离群点的重点分析可以定位大量数据中存在的潜在问题,以下是我们的分析结论。
4. 数据分析结论
4.1、登陆行为分析结论——快速暴力破解
| 事件1 | |
| 事件时间 | 2019年2月20日0点至1点 |
| 事件类型 | 暴力破解 |
| 攻击源 | *.*.*.75 |
| 攻击目标 | *.*.*.223、*.*.*.218、*.*.*.210 |
| 攻击详情 | 1.2019年2月20日0点起,*.*.*.75主机分别向*.*.*.223、*.*.*.218两台主机发出5000多条登陆请求,未成功登陆;
2. 当日1点,*.*.*.75又向*.*.*.210主机发出2500多条登陆请求,未成功登陆; 3. 较全天业务行为习惯而言,*.*.*.75主机明显存在异常情况,具有快速暴力破解其他主机登陆口令的威胁特质; |
| 处理建议 | 进一步排查*.*.*.75被多次访问的原因; |
| 事件2 | |
| 事件时间 | 2019年2月20日0点至1点 |
| 事件类型 | 可疑数据泄露 |
| 攻击源 | *.*.*.8 |
| 攻击目标 | *.*.*.52/*.*.*.53 |
| 攻击详情 | 1.2019年2月20日0点起*.*.*.8向*.*.*.53发起了每小时400次的登陆请求,直到6点结束;
2.2019年2月20日0点起*.*.*.53、*.*.*.8分别向*.*.*.52发起了每小时多达400次的登陆请求,直到8点结束; 3.*.*.*.53、*.*.*.8具有快速暴力破解其他主机登陆口令的威胁特质; |
| 处理建议 | 进一步排查*.*.*.53、*.*.*.8被多次访问的原因; |
4.2、登陆行为分析结论——慢速暴力破解
| 事件时间 | 2019/02/13-2019/02/20 |
| 事件类型 | 慢速暴力破解 |
| 攻击源 | – |
| 攻击目标 | *.*.*.57 |
| 攻击详情 | 1.每小时尝试10次登陆,分布规律;
2.登陆结果都为失败; 3.符合慢速暴力破解的特征; |
| 处理建议 | 获取详细日志,查看是否存在脚本,尝试登陆本机; |
4.3、登陆行为分析结论——数据泄露
| 事件时间 | 2019/02/13-2019/02/20 |
| 事件类型 | 可疑数据泄露 |
| 攻击源 | – |
| 攻击目标 | *.*.*.237、*.*.*.236、*.*.*.147 |
| 攻击详情 | 以上Server在登陆过程中疑似泄露密码 |
| 处理建议 | 查看是否存在密码泄露情况 |
4.4、提权行为分析结论——高频次提权
| 事件时间 | 2019/02/14-2019/02/20 |
| 事件类型 | 高频次提权 |
| 攻击源 | – |
| 攻击目标 | *.*.*.27、*.*.*.22、*.*.*.21、*.*.*.24、*.*.*.153、*.*.*.75 |
| 攻击详情 | 1. 经过统计发现23点和0点数据存在异常;
2. 23点*.*.*.27、*.*.*.22、*.*.*.21、*.*.*.24服务器单小时提权达到了5000次/6天; 3. 0点*.*.*.153、*.*.*.75发生了提权多达8000次/6天; |
| 处理建议 | 提权次数过于频繁的主机存在较大风险,需要进一步确认是否存在非法操作。 |
通过聚类算法的使用和对历史数据的分析,我们发现算法在大数据量的分析中是可以发挥其作用的,前提是要选择正确的特征维度,要通过参数调整来达到不断提升计算效果的目的。
参考资料:《机器学习实战应用》 李博