作者:Y4er
原文链接:https://y4er.com/post/fileupload-bypass-with-dotnet/
看了赛博群的《从commons-fileupload源码看文件上传绕waf》,文末提到了dotnet也有这种问题,于是看了下dotnet的源码。
public ActionResult Index()
{
if (Request.Files.Count>0)
{
var file = Request.Files[0];
var filename = file.FileName;
var contenttype = file.ContentType;
var reader = new StreamReader(file.InputStream);
var content = reader.ReadToEnd();
var filepath = Request.MapPath("~/ ") + filename;
file.SaveAs(filepath);
var resp = $" filename:{filename}\n save file path:{filepath}\n file content:{content}\n file content type:{contenttype}";
return Content(resp);
}
else
{
return Content("no file");
}
}对于上传的文件处理类位于System.Web.HttpMultipartContentTemplateParser.Parse()函数
internal static MultipartContentElement[] Parse(HttpRawUploadedContent data, int length, byte[] boundary, Encoding encoding)
{
HttpMultipartContentTemplateParser httpMultipartContentTemplateParser = new HttpMultipartContentTemplateParser(data, length, boundary, encoding);
httpMultipartContentTemplateParser.ParseIntoElementList();
return (MultipartContentElement[])httpMultipartContentTemplateParser._elements.ToArray(typeof(MultipartContentElement));
}和Request.Files的层级调用关系如图
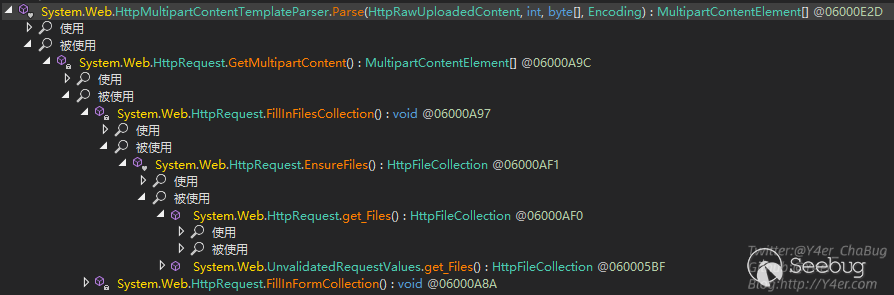
在FillInFilesCollection()中,content-type必须以multipart/form-data开头
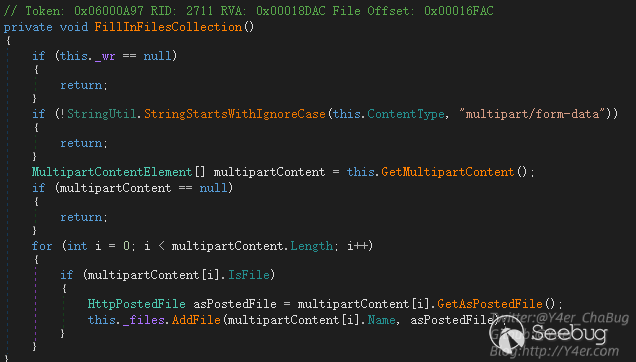
这里和common fileupload的处理不同,然后进入this.GetMultipartContent()
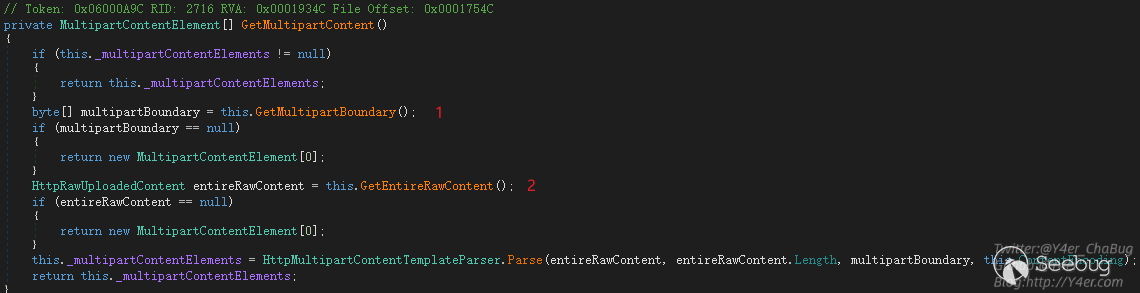
1来处理boundary 2来解析上传文件流 主要看1
private byte[] GetMultipartBoundary()
{
string text = HttpRequest.GetAttributeFromHeader(this.ContentType, "boundary");
if (text == null)
{
return null;
}
text = "--" + text;
return Encoding.ASCII.GetBytes(text.ToCharArray());
}GetAttributeFromHeader是关键函数
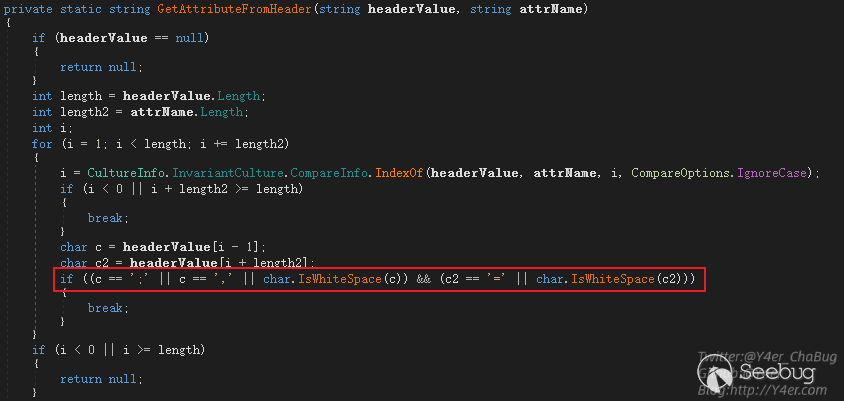
分号逗号和等于号作为分隔符,并根据字符集忽略一些空白字符
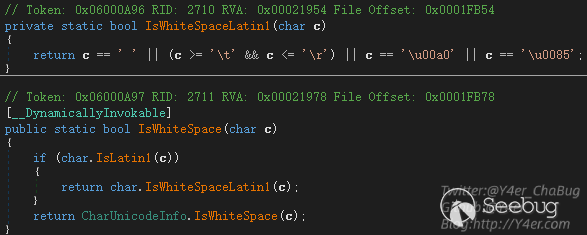
所以content-type可以这么写
Content-Type: multipart/form-data\u0085,;;,,,,,;;, boundary = aaa接着看GetMultipartContent函数,解析完boundary和文件内容流之后,进入3 Parse函数也就是我们开篇提到的函数。
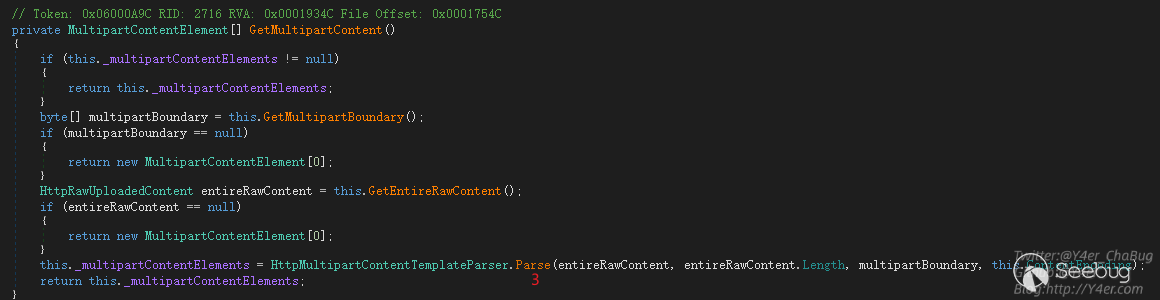
Parse函数就直接跟进了ParseIntoElementList函数
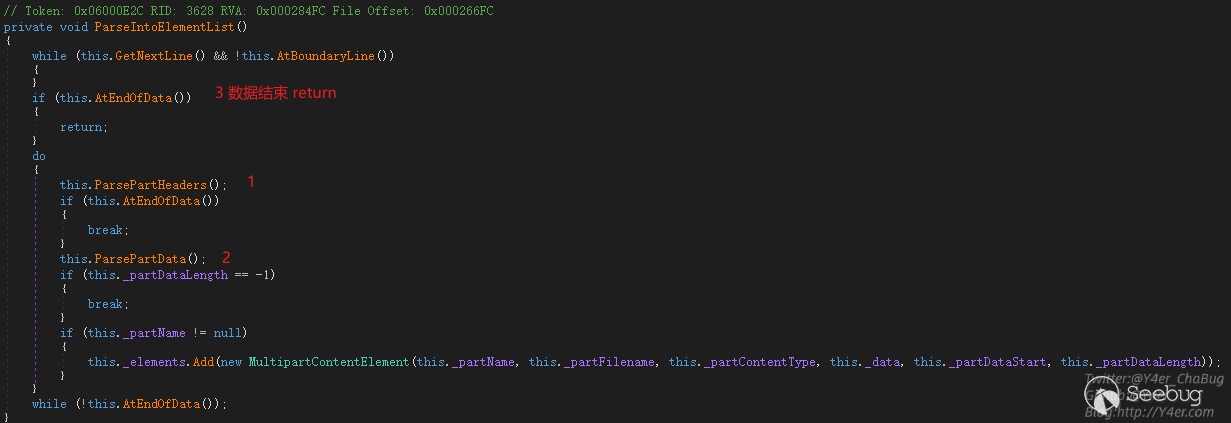
其中1 ParsePartHeaders是关键函数
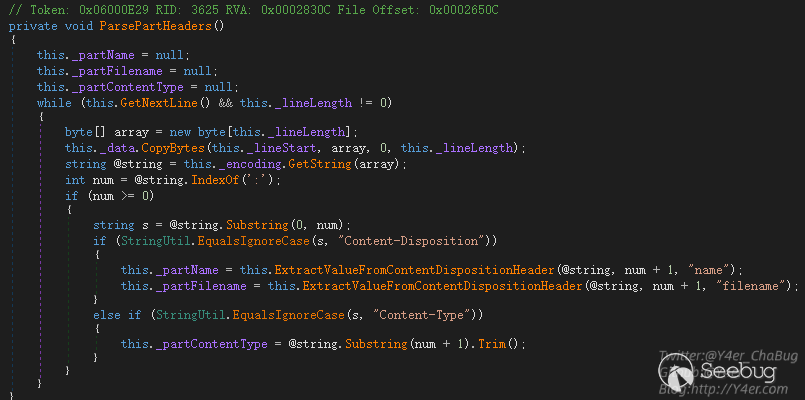
能看到这个函数用来解析Content-Disposition和Content-Type,先以冒号分割拿到冒号后的部分
Content-Disposition: form-data; name="file"; filename="1.txt"
Content-Type: text/plain即form-data; name="file"; filename="1.txt"
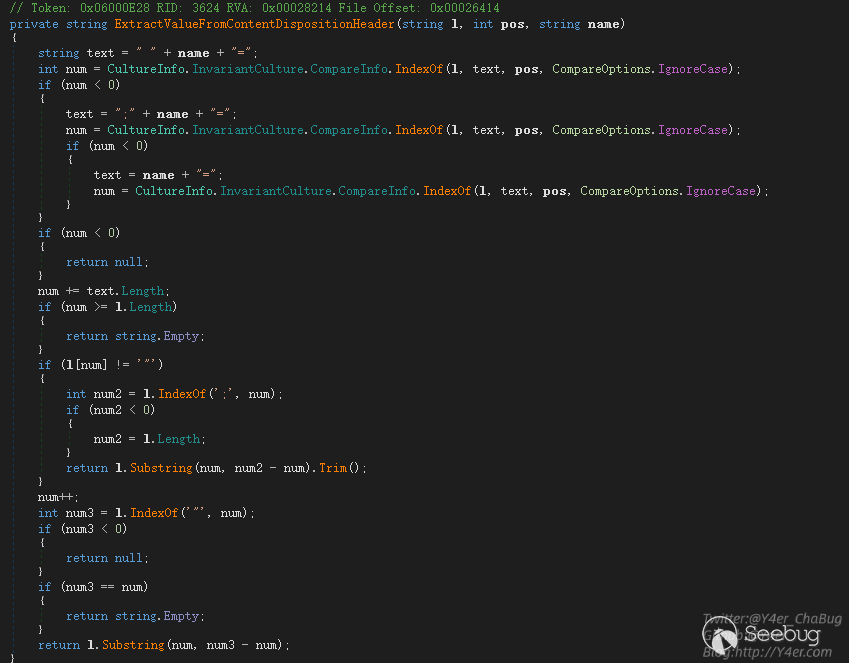
再看ExtractValueFromContentDispositionHeader函数
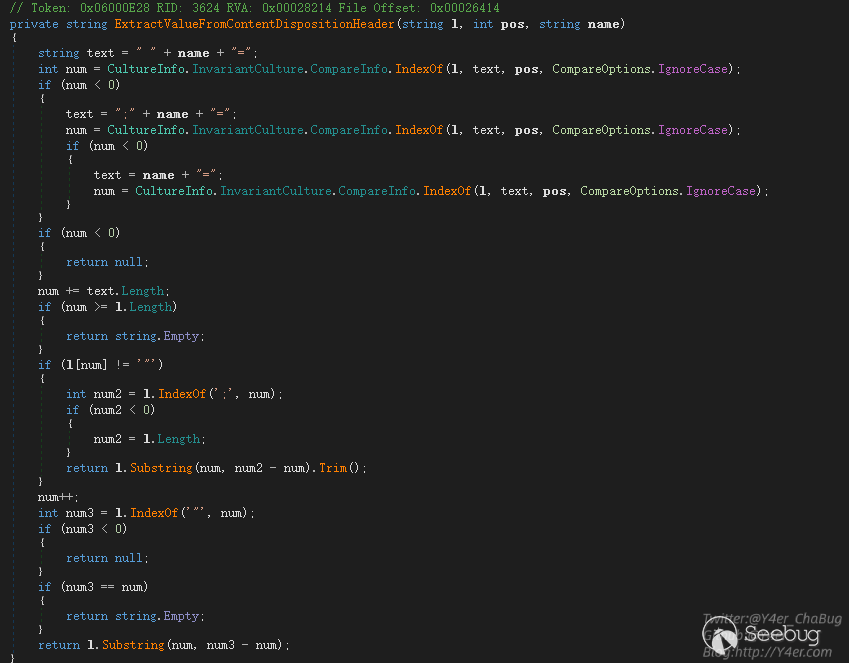
string text = " " + name + "=";
int num = CultureInfo.InvariantCulture.CompareInfo.IndexOf(l, text, pos, CompareOptions.IgnoreCase);
if (num < 0)
{
text = ";" + name + "=";
num = CultureInfo.InvariantCulture.CompareInfo.IndexOf(l, text, pos, CompareOptions.IgnoreCase);
if (num < 0)
{
text = name + "=";
num = CultureInfo.InvariantCulture.CompareInfo.IndexOf(l, text, pos, CompareOptions.IgnoreCase);
}
}会自动加上分号和等号,所以可以随便构造
Content-Disposition:\u0;;;;[email protected]#$%^&*(;asdas\u0085d;085filename=11.aspx
Content-Disposition:filename=11.aspx
Content-Disposition:aaaaaaaaaaafilename=11.aspx;aaaaaaaaa两个对比一下就知道
Content-Disposition: form-data; name="file";filename="11.aspx"- form-data字段可以不要
- 可以随便在
filename和name前随意填充字段 - 但是
filename和name后必须跟随等号,并且末尾有分号标识结束。
在ExtractValueFromContentDispositionHeader函数中会对取的值进行Trim()处理,也能用\u0085来处理
content-type同上
最后贴一张构造的图
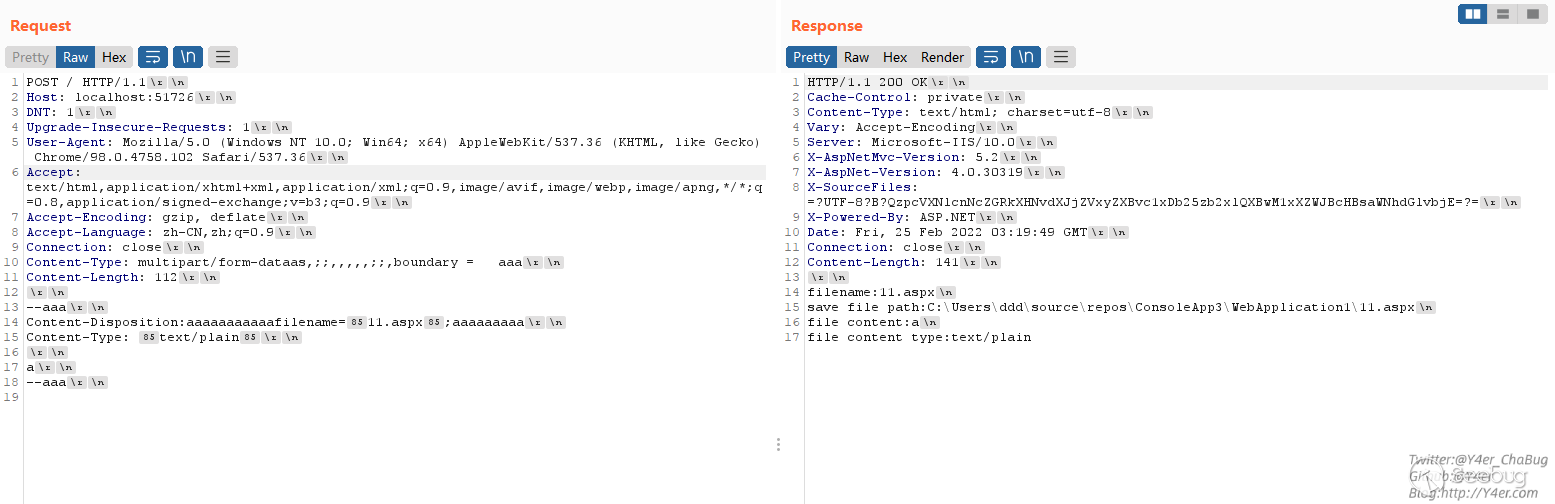
Request.Files[0]的name字段是忽略大小写的,Request.Files[0]和Request.Files[“file”]两种写法绕过时可能会出一些拿不到name的问题。
dotnet的特殊空白符如上文,但是位置一般只能放在两侧来用Trim去除。
文笔垃圾,措辞轻浮,内容浅显,操作生疏。不足之处欢迎大师傅们指点和纠正,感激不尽。
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1879/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1879/
如有侵权请联系:admin#unsafe.sh