
传统网络流量分析任务依赖于大量的专家知识和人力成本,如何将整个过程自动化?
目前机器学习广泛应用于网络流量分析任务,特征提取、模型选择、参数调优等众多因素决定着模型的性能,每当面对不同的网络流量或新的任务,就需要研究人员重新开发模型,这个反复性的过程往往是费时费力的。因此有必要为不同网络流量创建一个通用的表示,可以用于各种不同的模型,跨越广泛的问题类,并将整个建模过程自动化。本文关注通用的自动化网络流量分析问题,致力于使研究人员将更多的精力用于优化模型和特征上,并有更多的时间在实践中解释和部署最佳模型。
传统基于机器学习的网络流量分析严重依赖人工,在实践中,获得特征、模型和参数的最优组合通常是一个迭代的过程,这个过程有一些弊端。首先,数据的合适表示和特征选择对于流量分析任务是十分重要的,但即便有专业领域知识,特征工程仍然是一个脆弱且不完善的过程,人工分析时可能会忽略不够明显的或包含复杂关系的特征;其次,网络环境复杂多变,流量模式的变化带来特征的失效;最后,对于每一个新的流量检测或分类任务,都需要重新设计新的特征,选择合适的模型,并重新调整参数。
为了避免这些问题,本节介绍一种适用于不同网络流量分析任务的自动化的方法[1],通过对网络流量进行统一表示,并结合自动机器学习(AutoML)方法,实现在不同网络流量分析问题上的简单快速的自动化迭代和部署。
2.1 数据表示
对于许多分类问题,数据表示与模型选择同等重要,所以在应用机器学习方法时,如何对数据进行表示和编码是非常重要的。对于网络流量数据的编码需要满足以下三个要求:
(1)完整的表示。我们的目标不是选择特定的特征,而是一种统一的数据编码,以避免依赖专家知识,所以需要保留包含包头在内的所有数据包信息;
(2)固定的大小。许多机器学习模型的输入总是保持相同的大小,所以每个数据包表示都必须是常量大小;
(3)固有的规范化。当特征被归一化后,机器学习模型通常会表现得更好,也能减少训练时间并增加模型的稳定性,所以如果数据的初始表示本身就是规范化的,将会非常方便;
(4)一致的表示。数据表示的每个位置都应该对应于所有数据包包头的相同部分,也就是说,即使协议和报文长度不同,特定的特征总是在数据包中具有相同的偏移量,对齐后的数据都能让模型基于这样的前提来学习特征表示。
如图1所示,网络流量表示的主要方式包括语义表示法和朴素二进制表示法。
(1)语义表示法:每个报头都有各自的语义字段,但它不保留具有区分度的可选字段的顺序,同时需要领域专业知识来解析每个协议的语义结构,即使拥有这些知识,后续也还是不可避免进行繁琐的特征工程;
(2)朴素二进制表示法:使用数据包的原始位图表示来保持顺序,但是忽略了不同的大小和协议,导致两个数据包的特征向量对同一特征具有不同的含义,这种不对齐可能会在重要特征的地方引入噪声而降低模型性能,同时也因为无法将每一位都映射到语义上而导致不可解释。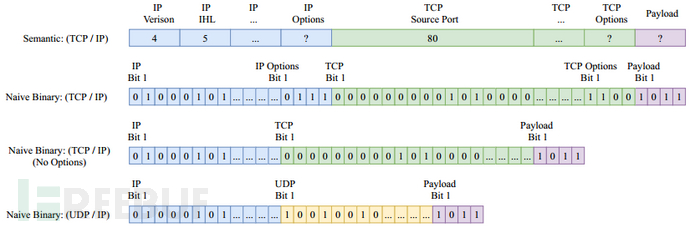
图1 语义表示法和朴素二进制表示法
以上两种表示方法都无法满足统一化表示数据的需求,如图2所示,研究人员结合语义表示法和朴素二进制表示法提出一种统一的网络数据包表示方法nPrint。首先,它会保证任何数据包都可以被完整表示而不丢失任何信息;然后,使用内部填充确保每个数据包以相同数量的特征表示,并且每个特征具有相同含义,这种在位级上可解释的表示使我们能够更好的理解模型;其次,直接使用数据包的位,区分于某个位被设置为0,将不存在的包头用-1填充;最后,每个数据包都用相同数量的特征表示,对于给定的网络流量分析任务,将载荷设置为可选的字节数。此外,nPrint具有模块化和可扩展的特性,不仅可以将其他协议添加到表示中,也可以将一组数据包表示串联起来构建多包的nPrint指纹。
图2 nPrint
2.2 nPrintML
专家往往花费数周甚至数年从原始数据包中提取特征,并在认为最好的一个或一组模型上进行训练,最后通过手工或结构化搜索对模型进行调优。为了将整个过程标准化,在nPrint的基础上结合AutoML工具,提出nPrintML,如图3所示,实现了机器学习流程的自动化。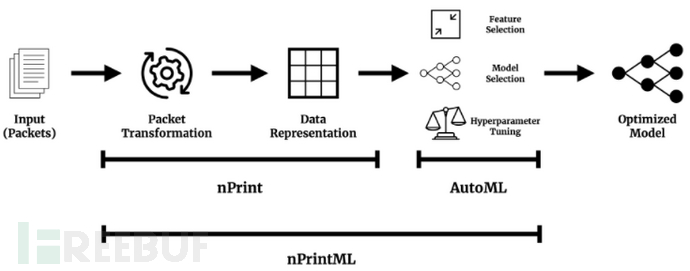
图3 nPrintML
nPrint使不同流量分析工作的特征提取过程标准化,AutoML旨在自动化特征选择、模型选择和超参数调优,以便为给定的特征和带标签数据集找到最优模型。最终,nPrint为每个网络流量分析任务提取最佳特征,AutoML用于确定最佳模型和超参数。
因为AutoGluon集成了多个性能良好的单一模型,优于许多其他AutoML工具,所以选择AutoGluon作为AutoML工具。这里使用处理表格数据的功能子集AutoGluon-Tabular,它通过搜索一组基模型来进行特征选择、模型选择和超参数优化,包括深度神经网络、基于树的方法(如随机森林)、非参数方法(如k近邻)以及梯度增强树方法。此外,AutoGluon-Tabular也能从基模型中创建加权集成模型,以更少的训练时间实现比其他AutoML工具更高的性能。
研究人员结合nPrint与AutoGluon,用python实现了nPrintML[2],允许用户在单个调用中在整个目录上运行。以被动操作系统检测为例,用例如下:
nprintml -L os_labels.txt -a index -P traffic.pcap -4 –t
2.3 实验结果
针对8个网络流量分析场景,图4展示了用nPrintML进行分析的案例研究,实验结果表明,nPrintML不仅可以解决不同场景的网络流量分析问题,并且具有相较于传统方法更好的性能。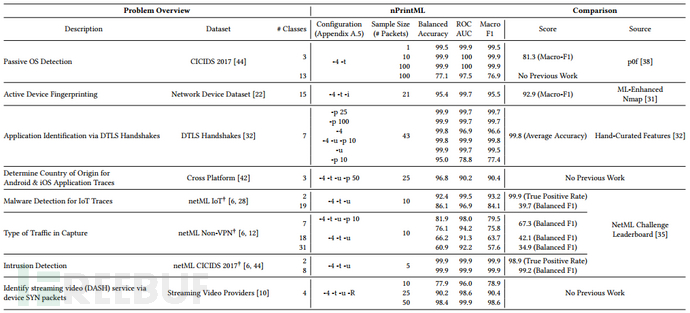
图4 nPrintML案例研究结果
将机器学习应用于网络流量分析任务的性能,除了取决于模型本身之外,数据的适当表示和特征的选择同样重要。本文介绍了一种自动网络流量分析的新思路,通过将数据包进行统一表示,并将其转化为适合表示学习和模型训练的格式,然后结合现有的自动机器学习,最终将整个网络流量分析过程完全自动化。这种方法不仅适用于常见的网络流量分析任务,而且表现出比现有模型更好的性能。
[1] Holland J , Schmitt P , Feamster N , et al. New Directions in Automated Traffic Analysis. 2021 ACM Computer and Communications Security Conference [C]. 2021.
[2] https://nprint.github.io/
如有侵权请联系:admin#unsafe.sh