注:本文是「100 小时后请叫我程序员」栏目的试读文章。
本文涉及大量技术概念和代码,如果目前阅读起来还稍显吃力,可直接跳转至「分析与可视化」一节阅读数据分析的结果。
学会编程的人都知道:自己掌握了一门「魔法」。
在绝大多数编程课程中,第一个例子一定是经典的「在终端打印出『Hello, World』」。在五、六十年前计算机科学刚兴起的时代,这算得上是一件非常酷炫的案例,但是在 2022 年,我相信大家很难通过这个案例,体会到编程的魅力和乐趣。
本文将会对哔哩哔哩(下文简称 B 站)UP 主 刘庸干净又卫生(网友称庸子)的视频数据进行抓取(数据截止到 4 月 2 日),并基于抓取到的数据进行数据分析与可视化,得到类似下图的图表:

又或是这样分析图表:

希望通过这一综合性的例子展示 Python 在数据抓取、分析与可视化等使用场景中的作用。在阅读过程中你肯定会遇到不少不理解的概念和技术,在后续的文章中都会一一详细介绍,这一篇就请先体会编程这件事的「魔力」所在。
注:完整源代码可前往栏目仓库下载。
数据抓取与爬虫程序设计
接口分析与数据源确定
目前我们所在的互联网,主要通过 HTTP 协议进行网络通信与资源传输,即通过该协议中的相关方法向持有资源的目标服务器发送请求,服务器接收请求后会返回相应的响应数据。
对于现在用于数据抓取的大多数爬虫而言,往往会试图通过模拟类型人类使用浏览器的行为,访问持有数据资源的服务器接口,从而得到响应的服务器数据,而这种数据形式通常会以主流的 JSON 格式进行传输。但出于对数据安全与保护层面考虑,不同站点的服务器往往会存在相应的「反爬虫」、混淆、加密等措施,以保证数据安全和服务的正常运行。
对于爬虫而言最常用的两种数据获取方式是请求 JSON 数据和网页内容提取,因此本小节也会试图从这两个方面来进行说明。
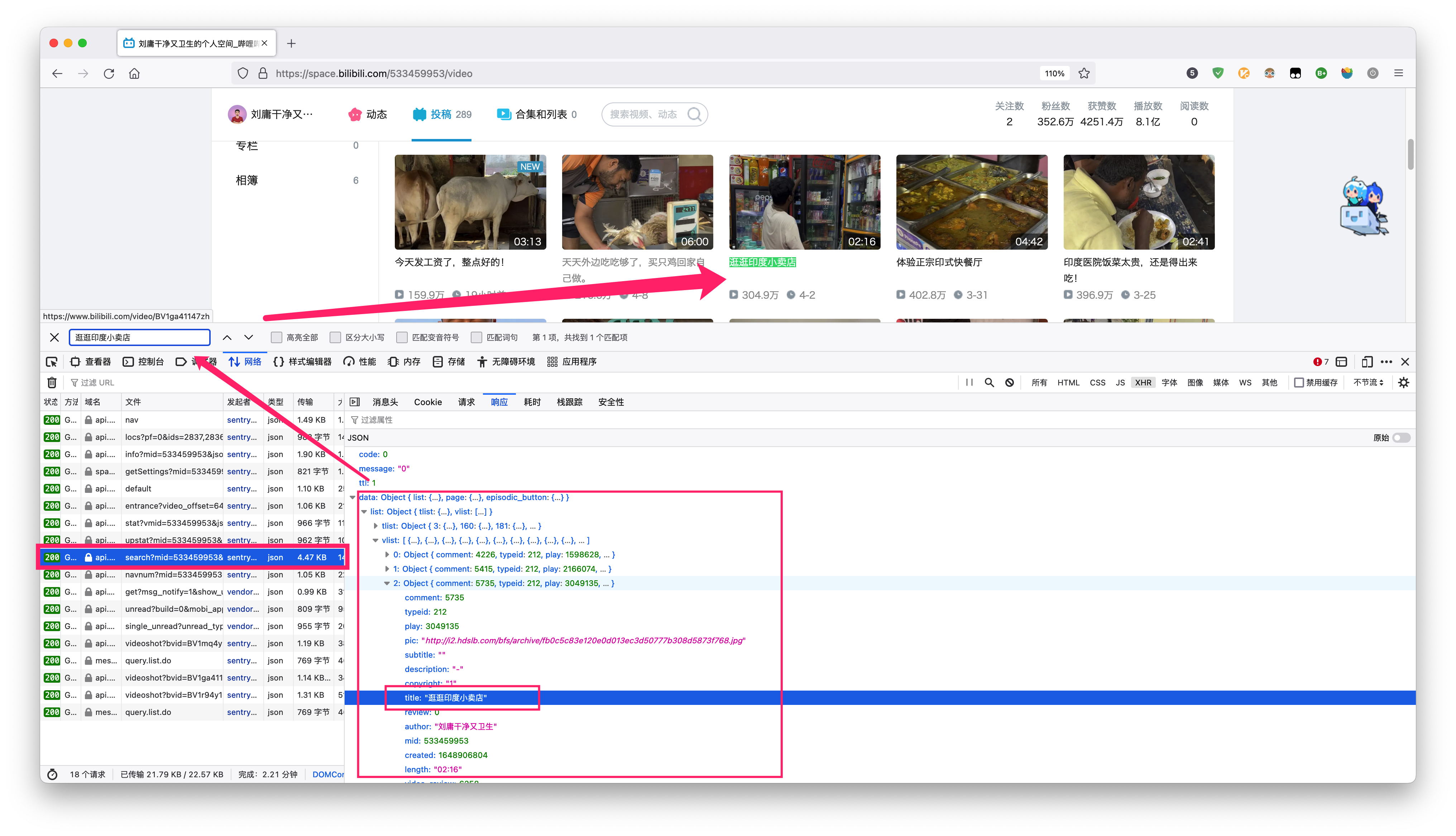
首先我们可以通过 B 站的相关搜索功能进入到 UP 主刘庸的视频投稿界面,然后按下 F12 键使用浏览器都会自带的开发者工具台,并点击「网络」选项卡重新刷新页面以记录请求相关的内容。
这里笔者主要使用的是 FireFox 浏览器,不同浏览器的开发者工具台可能样式有所不同:

进入到网络选项卡后再点击右侧的 XHR 选项卡只筛选与该内容相关的请求。
在这些请求中我们可以看到下面所示的类型一列中有很多个 JSON 记录,因此我们可以逐条往下翻,每次点击时查看点击右边栏的「响应」选项:

最后会发现一个内容为 search?mid=xxxx 相关的请求得到的 JSON 数据中即包含了该视频下的相关数据信息。因此即可以确定我们能通过该 URL 地址获取到对应每页的相关数据。
之后我们再点击其中的一个视频进入到相应的视频页中,以同样的方式试图的寻找类似的请求。但很快我们会发现这行不通,因为这说明 B 站对数据存在了相应的反爬或加密措施,不过我们倒是可以通过直接获取到视频页上存在的一些 HTML 标签,来获取到和视频有关的数据信息,比如一键三连、分享及历史排名等。
这里我们还是可以使用开发者工具台,此时需要将选项卡切换至「查看器」(在 Chrome 或 Edge 为「元素」)以查看 HTML 页面内容,这也是从服务器请求得到的一种数据表现形式,并且我们可以基于 HTML 中的节点标签获取到相应的数据:

当然如果读者有一些相关爬虫经验或是前端知识,再继续对视频页面进行深挖就会发现有关于视频一键三连、分享及历史排名等数据都被加载到了 HTML 页面的 <head>...</head> 头标签中的 JavaScript 代码里:

到此为止,基本上我们已经通过分析网络请求和 HTML 页面内容确定了获取数据的源头及获取方式。出于本章后续对数据分析与可视化章节的需要,笔者对上述两部分数据的获取思路为:
- 通过 API 请求获取 UP 主主页的视频列表数据;
- 遍历列表数据中的 BVID 号去获取到对应视频页的 HTML 内容,并从中提取出一键三连、分享及历史排名这几个数据。
接下来我们就可以进入到编写获取数据的爬虫程序设计步骤。
前期准备
在编写相应的程序项目前,我们需要事先进行一些前期的准备,包括依赖引入、自定义类型设定、公用常量设定、全局变量定义等,从而使得程序代码排布整洁有序,提高整体的代码质量。
相关依赖
抓取数据的依赖主要由 Python 内置的标准库和第三方库两部分组成,具体如下:
#!/usr/bin/env python3
# coding:utf-8
import itertools
import logging
import math
import pathlib
from concurrent.futures import ThreadPoolExecutor
from typing import Dict, List, TypeVar
import pandas as pd
import requests
import requests_html在本程序中笔者主要会通过 requests 库和 requests-html 这两个第三方库获取到相应的数据,最后通过 pandas 这一数据分析与处理工具库对实现对所有数据的合并处理,并将其转化成相应的结构化数据并导出保存。
常量与公用变量
导入特定的依赖之后就是定义公用的常量与变量,在程序中我们可以随时引用这些常量和变量,从而减少重复性代码。
自定义类型
Python 虽然是个解释型编程语言,但自从 PEP-484(https://peps.python.org/pep-0484/)提案之后就开始逐渐流行类似其他编译型编程语言的类型编程风格,以便在使用 IDE 和 Linter 工具时能够获得更好的补全提示以及代码检查。
因此,这里我们定义三个类型,分别用于表示所有类型、JSON 数据类型以及包含多个 JSON 数据的数组类型:
_T = TypeVar("_T")
APIData = Dict[str, _T]
Records = List[APIData]API 和视频页数据链接
除了自定义类型之外,我们还需要额外的将数据来源的请求 URL 定义成常量,方便后续引用,这里主要就是我们在上一小节分析过程中得到的接口和数据源地址:
VIDEO_API_URL = "https://api.bilibili.com/x/space/arc/search"
VIDEO_PAGE_URL = "https://www.bilibili.com/video/{bvid}"其中因为视频页链接需要变动 BVID 号,因此特地给 VIDEO_PAGE_URL 预留了一个可以被格式化的模板以便后续调用时每次进行修改。
模拟请求头与请求参数
数据获取本质就是在模拟 HTTP 请求向服务器发送获取数据的相关请求,因此大多数编程语言的网络请求也都是在模拟类似于 HTTP 的行为,所以在请求前我们需要简单设置与浏览器类似的请求头(Request Header)参数信息与请求参数:
# request header
USER_AGENTS = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2)",
"AppleWebKit/537.36 (KHTML, like Gecko)",
"Chrome/81.0.4044.92",
"Safari/537.36",
"Edg/81.0.416.53",
]
HEADERS = {"User-Agent": " ".join(USER_AGENTS)}
MID_NUMBER = "533459953"
params = {"ps": "30", "tid": "0", "order": "pubdate"}其中大写部分也可以视为公共的常量,而 params 则是公共变量。
日志与信息记录
大部分程序都会有一个用于记录程序某些时刻运行情况的日志记录器,这里笔者就直接基于 Python 内置的 logging 标准库进行简单配置:
# logger
logging.basicConfig(
level=logging.INFO,
format="[{asctime}]-[{levelname:<8}]-[{funcName}:{lineno}] - {message}",
datefmt="%Y-%m-%d %H:%M:%S",
style="{",
)
log = logging.getLogger(__name__)
最后我们可以通过使用 log 日志记录器根据自己的需要在代码的某些部分记录日志信息并输出。
爬虫程序设计思路与实现
通过前期对接口进行分析以及确定数据源后,笔者主要将抓取数据的爬虫程序主要核心逻辑分为了四个部分:
- 获取对应 UP 主的总视频数量,得到相应的总页数,作为批量请求的基础依据;
- 在总页数的基础上,批量分页请求 API 获得关于视频的基本数据信息;
- 从获取到的视频信息中提取 BVID 号并再次请求网页获取到 HTML 页面内容,并通过 CSS 解析 HTML 中的数据;
- 最后将所有数据合并到一起并导出。
因此本小节的章节安排也是围绕着这四个部分展开。
获取视频总页数
根据前面对浏览器页面访问的接口分析,在访问得到的 JSON 数据里,data 部分的 page 中存在一个名为 count 的内容,大致对应该 UP 主的视频总量。
基于该数值只需要除以请求参数中的 30,再向上取整(因为有的页数可能不满 30 个视频)得到总页数,最后将总页数返回。
由于每次通过 API 请求都会携带该数据,因此我们只需要请求一次即可,因此有如下代码:
def fetch_page_number(mid: str) -> int:
"""fetch total page number from API at first time query."""
total = 0
payloads = {"mid": mid, "pn": 1, **params}
with requests.Session() as sess:
response = sess.get(
url=VIDEO_API_URL,
headers=HEADERS,
params=payloads,
)
response.raise_for_status()
count = response.json()["data"]["page"]["count"]
total += math.ceil(int(count) / 30)
return total分页请求 API 获取每页的视频基本数据
分页请求的思路和获取视频总页数的逻辑类似,稍微有点差异的地方在于每次我们都需要修改对应的页数,以及获取到 JSON 数据的内容部分不同:
def fetch_video_data(mid: str, page: int) -> List[APIData]:
"""fetch video data from API."""
payload = {"mid": mid, "pn": str(page), **params}
with requests.Session() as sess:
response = sess.get(
url=VIDEO_API_URL,
headers=HEADERS,
params=payload,
)
response.raise_for_status()
jsons = response.json()["data"]["list"]["vlist"]
log.info(f"fetch video from '{mid}' at {page} page.")
return jsons解析网页 HTML 获取一键三连相关信息
因为在前面的接口分析中未发现暴露对应视频一键三连相关的数据接口,因为可能存在相应的混淆加密。所以为了降低数据获取难度笔者采取了一个折中的办法,即通过每个 BVID 所对应的网页来获取相应的 HTML 页面内容,然后再从 HTML 当中提取相应的数据信息。
同时,因为请求网页时会获取到相应的 HTML 页面内容,而数据也就藏在页面内容中的 HTML 节点或标签中,所以这里需要通过特定的 CSS 选择器语法获取到包含此次爬取目标数据信息的节点,最后再提取当中的内容。
而每次请求一个网页就等同于发送一个请求,因此这里采用异步并发的方式来加快请求效率;但好在前面导入的 requests-html 库支持异步请求,我们可以直接调用即可。
最后会将所有视频的排名情况和一键三连的数据以 Python 中的字典数据类型返回(类似 JSON):
async def fetch_stats(bvid: str, asess) -> APIData:
"""fetch like, coin, collect and share from video page."""
info = {}
stats = ["rank", "like", "coin", "collect", "share"]
response = await asess.get(
url=VIDEO_PAGE_URL.format(bvid=bvid),
headers=HEADERS,
)
response.raise_for_status()
html = response.html
has_rank = html.find(".video-data .rank", first=True)
if has_rank:
info["rank"] = has_rank.text.strip()
try:
info["like"] = html.find(".ops .like", first=True).text.strip()
info["coin"] = html.find(".ops .coin", first=True).text.strip()
info["collect"] = html.find(".ops .collect", first=True).text.strip()
info["share"] = html.find(".ops .share", first=True).text.strip()
except AttributeError:
log.warning(f"cant' get stats from '{bvid}', use default.")
return {k: "" for k in stats}
log.info(f"fetch stats from '{bvid}'.")
return info因为有些视频可能会存在对应的排名情况,如果存在相应的节点则更新结果数据,否则就使用默认的空字符串。
除吃之外,代码当中需要对可能出现的异常进行一下简单处理,防止程序崩溃或终止运行,即:如果数据不存在一键三连的对应标签,那么就说明该视频可能为特殊类型,默认即不处理而是直接返回默认数据。
因本小节的数据获取方式是为了数据分析与可视化部分而设计,如果读者有相应的编程经验,那么也可以通过以下 JavaScript 代码获取到相应的 API 数据,会比通过获取 HTML 节点的方式更佳:
(function () {
let api = window.__INITIAL_STATE__;
let stat = undefined;
try {
stat = api.videoData.stat;
} catch (e) {}
const cols = ["rank", "like", "coin", "collect", "share"];
let blankStat = {};
for (const col of cols) {
blankStat[col] = "";
}
if (stat === undefined) {
return blankStat;
}
return {
rank: stat.his_rank,
like: stat.like,
coin: stat.coin,
collect: stat.favorite,
share: stat.share,
};
})();封装与合并导出
前三部分获取数据信息的步骤完成后,就可以开始将其组合到一块构成一个整体。
但在这之前我们还需要简单地封装一个函数,它会将每 BVID 所对应视频的 JSON 基本数据,与从该视频页面所获取到的排名情况与一键三连数据整合在一起,最后它返回的才是我们想要的每个视频的完整数据:
async def bundle(json, asess) -> APIData:
"""bundle json data with stats."""
bvid = json["bvid"]
stats = await fetch_stats(bvid, asess)
info = {**json, **stats}
return info万事俱备后我们就可以将所有前面编写好的部分再封装到一起,形成简洁的 API 入口:
def query(mid: str) -> List[APIData]:
"""query data by mid number."""
log.info(f"querying data from '{mid}'...")
total_page = fetch_page_number(mid)
with ThreadPoolExecutor(max_workers=2) as p:
features = [
p.submit(fetch_video_data, mid=mid, page=page)
for page in range(1, total_page + 1)
]
jsons = itertools.chain(*[f.result() for f in features])
# async session for html request
asess = requests_html.AsyncHTMLSession(workers=2)
# compatibility for requests-html async coroutine code
# see: https://github.com/psf/requests-html/issues/362
results = asess.run(
*[lambda json=json, asess=asess: bundle(json, asess) for json in jsons]
)
return results该部分代码的核心思路就是:
- 将前面三部分的函数封装到一起,先根据 MID 号获取到对应 UP 主频道总视频所对应的页数之后,采用多线程的方式请求每一页数据,再将获取到的结果合并到一个新列表中;
- 使用
request-html构建一个异步的 HTML 会话对象,并调用该对象的run()方法将每个 Lambda 匿名函数作为一个协程任务提交到对应的事件循环中等待任务完成,最终返回结果,每个任务就代表了一个网络请求。
最后再额外封装一个用于合并数据的函数,即将包含 JSON 数据的数组转换成对一个 DataFrame 数据类型并返回,这里调用的是来自于 pandas 库中的 json_normalize() 函数。
def parse(jsons: Records) -> pd.DataFrame:
"""normalize and combine json data."""
return pd.json_normalize(jsons)
最后编写一个程序运行入口的 main() 函数,用于统一调配上述的封装函数,运行程序后会将所有获取到的数据统一导出到桌面上一个名为 bilibili.csv 的 CSV 文件中:
def main():
csvfile = pathlib.Path("~/Desktop/bilibili.csv").expanduser()
jsons = query(MID_NUMBERS)
data = parse(jsons)
data.to_csv(csvfile, index=False)
if __name__ == "__main__":
main()
数据分析与可视化
本小节,我们将会对第一部分通过爬虫程序获取到的数据进行分析与可视化展示。这里我们将会使用到 Jupyter Notebook(https://jupyter.org/)来作为编写数据分析与可视化代码的编程环境。
关于 Jupyter 的相关内容可以参考我在少数派上曾发表的文章:
前期准备
使用魔法命令(Magic Commands)设置可视化展示效果
因为 Jupyter Notebook 会默认使用 IPython(Python 解释器的增强版本)作为执行代码的内核,所以支持在线实时显示可视化图形的功能。
但需要在开头加入以下两行魔法命令(Magic Commands)开启嵌入图形的展示模式,以及提高画质的 SVG 渲染模式:
%matplotlib inline
%config InlineBackend.figure_formats=["svg"]相关依赖与可视化前期设置
因为会涉及到对数据的处理、分析与可视化,因此除了内置的 pathlib 标准库之外,还需要额外用到其他 Python 社区常用的数据分析与可视化库:
import pathlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns同时,由于我们会使用到 Seaborn 这一可视化绘图库,它是在 Matplotlib 上进行封装的,因此我们可以直接在 Seaborn 的基础上设置全局可视化相关的效果,如主题、字体等:
sns.set_theme()
style_settings = {
"font.sans-serif": ["Songti SC", "SimHei"],
"axes.unicode_minus": False,
}
sns.set_style("darkgrid", style_settings)数据初步探索
虽然通过爬虫获取到了相应 UP 主的数据,但是数据仍然可能存在一些瑕疵的地方,比如数据缺失、存在无用字段等,因此需要对原始数据的整体状况有一个大致的了解,以决定接下来的数据使用方式。
Pandas 库提供了丰富数据处理与分析功能,因此与数据处理和分析相关的方面大部分都会使用它来辅助我们完成。在使用数据之前我们需要将其载入到计算机的内容之中:
csvfile = pathlib.Path("~/Desktop/bilibili.csv").expanduser()
raw = pd.read_csv(csvfile)原始数据情况
通过 Pandas 的 read_csv() 读取得到的数据会是一个 DataFrame 对象,因此我们可以使用 DataFrame.info() 方法查看一下该数据的相关情况:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 281 entries, 0 to 280
Data columns (total 26 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 comment 281 non-null int64
1 typeid 281 non-null int64
2 play 281 non-null int64
3 pic 281 non-null object
4 subtitle 0 non-null float64
5 description 279 non-null object
6 copyright 281 non-null int64
7 title 281 non-null object
8 review 281 non-null int64
9 author 281 non-null object
10 mid 281 non-null int64
11 created 281 non-null int64
12 length 281 non-null object
13 video_review 281 non-null int64
14 aid 281 non-null int64
15 bvid 281 non-null object
16 hide_click 281 non-null bool
17 is_pay 281 non-null int64
18 is_union_video 281 non-null int64
19 is_steins_gate 281 non-null int64
20 is_live_playback 281 non-null int64
21 like 279 non-null object
22 coin 279 non-null object
23 collect 279 non-null object
24 share 279 non-null object
25 rank 102 non-null object
dtypes: bool(1), float64(1), int64(13), object(11)
memory usage: 55.3+ KB截止到 4 月 7 日为止:
- 共获取 UP 主 281 个视频数据,数据包含了 26 个字段;
subtitle字段没有任何数据,需要剔除;- 在一键三连的几个相关字段上(
like、coin、collect、share)缺失两个视频的数据; - 通过
rank字段可以得知,在 281 个视频里,仅有 102 个数据存在排名情况,超过一半以上的数据在该字段上存在缺失数据的情况,需要进一步处理。
保留有效信息字段
了解了原始数据的基本情况后,我们还需要对每个字段有大致的了解,这里我们简单地使用 DataFrame.describe() 方法查看一下每个字段的基本统计描述情况,默认情况下只会显示数值字段:
raw.describe()最后可以得到如下表格:
| created | play | comment | video_review | |
| count | 281 | 281 | 281 | 281 |
| mean | 1.63218e+09 | 2.76805e+06 | 3587.99 | 6372.62 |
| std | 8.10626e+06 | 1.75495e+06 | 4407.25 | 8871.61 |
| min | 1.61738e+09 | 333669 | 172 | 51 |
| 25% | 1.62565e+09 | 1.64808e+06 | 1286 | 1430 |
| 50% | 1.6317e+09 | 2.43546e+06 | 2577 | 3514 |
| 75% | 1.63885e+09 | 3.41576e+06 | 4639 | 7998 |
| max | 1.64891e+09 | 1.56532e+07 | 46792 | 82150 |
当然我们也可以查看一下非数值字段的信息:
raw.describe(include="object")同样会得到类似表格:
| mid | author | title | length | rank | like | coin | collect | share | |
| count | 281 | 281 | 281 | 281 | 102 | 279 | 279 | 279 | 279 |
| unique | 1 | 1 | 281 | 146 | 68 | 176 | 223 | 262 | 260 |
| top | 5.3346e+08 | 刘庸干净又卫生 | 印度阿姆利则降旗仪式,富有娱乐精神的表演。 | 00:49 | 全站排行榜最高第 19 名 | 4.0 万 | 1.2 万 | 1.2 万 | 1.1 万 |
| freq | 281 | 281 | 1 | 7 | 3 | 5 | 10 | 7 | 4 |
通过以上我们可以得到如下信息:
数值型变量:
copyright字段值都为 1,不存在数据差异,因此可能对分析没有太大帮助,需要删除;created字段应该为视频上传日期时间,但实际表示为 UNIX 时间格式,需要转换成符合阅读习惯的「年月日与时分秒」形式;is_XXX的几个字段以及review字段的值都为 0,不存在有效的数据信息,需要删除;- 数据中存在旧版的
avid号,但目前视频都主要以bvid号为主,因此取其中一个字段即可;
非数值型变量:
pic字段表示视频的封面图片链接,description字段为视频的简介描述,但都不存在对后续的数据分析有帮助的信息,需要删除;length字段表示视频播放时长,但目前是以分秒的形式记录,后面需要将其进行转化成时间样式;- 一键三连和排名字段虽然都携带了相关的数值信息,但也存在其他文本,因此需要对其进行抽取,即将数字抽取出来并清理额外文本内容。
紧接着我们再查看一下每条视频数据是否都是独立投稿,还是存在联合作者投稿的情况,这里我们直接使用 DataFrame.value_counts() 对 mid 字段进行统计:
raw.value_counts("mid")最后结果如下:
+-----------+-----+
| mid | 0 |
+-----------+-----+
| 533459953 | 281 |
+-----------+-----+说明目前获取到的数据都是 UP 主独立投稿的数据。
综合上述初步的探索情况,目前我们需要将用不上的字段剔除,只保留可以进行分析的字段,并在此基础上进行数据清洗以便更好地能供数据分析和可视化使用。
因此,这里我们定义一个包含目标字段的列表,然后再通过 DataFrame 对象的相关方法进行过滤:
# target columns
cols = [
# BVID 号
"bvid",
# UP 主频道号
"mid",
# UP 主名称
"author",
# 视频标题
"title",
# 视频上传时间
"created",
# 视频长度
"length",
# 视频播放量
"play",
# 视频评论数
"comment",
# 视频弹幕数
"video_review",
# 视频全站排名(第 N 名或无)
"rank",
# 视频点赞量
"like",
# 视频投币数
"coin",
# 视频收藏量
"collect",
# 视频分享量
"share",
]
raw: pd.DataFrame = raw.astype({"mid": "str"}).filter(items=cols).set_index("bvid")
raw.head()数据清洗与处理
因为在前面初步的数据探索中,发现有个别字段虽然包含了一些有效信息记录,但是仍然不适用于数理统计,因此需要对其进行清洗、处理,使最后的数据能够更好地供后续的数据分析和可视化使用。
公共基础数据构建
首先我们需要将原始数据中一部分数据信息相对完整的字段抽离出来,作为公共的基础数据,以便后续进行拼接。代码如下:
# tidy common
def divide_hour(hour: int):
if 8 <= hour < 17:
return "08h-16h"
elif 17 <= hour < 24:
return "17h-23h"
else:
return "00h-07h"
ops = ["like", "coin", "collect", "share"]
common: pd.DataFrame = raw.assign(
title=raw["title"].str.strip(),
created=raw["created"].apply(pd.to_datetime, unit="s"),
created_type=lambda data: (
data["created"].dt.hour.map(divide_hour).pipe(
pd.Categorical,
ordered=True,
categories=["08h-16h", "17h-23h", "00h-07h"],
)
),
rank=(
raw["rank"]
.fillna("")
.str.extract(r"(?P<rank>\d+)")
.fillna(0)
.astype("int")
),
).drop([*ops, "length"], axis=1)
common.head()这里笔者主要做了以下几件事:
- 对视频标题进行简单清洗去除空格;
- 将前面的
created视频上传日期时间字段转换成人类可读的时间格式,并在此的基础上通过一个divide_hour函数,将其划分成不同上传时间段,并新建一个上传时间段分类字段created_type; - 提取原始数据中
rank字段的数字部分; - 最后将一键三连相关的字段以及播放时长字段单独剔除。
最后我们将会得到以下结果:
| bvid | mid | author | title | created | play | comment | video_review | rank | created_type |
| BV19r4y1r7wx | 533459953 | 刘庸干净又卫生 | 印度阿姆利则降旗仪式,富有娱乐精神的表演。 | 2021-11-15 04:01:27 | 1695848 | 2073 | 1050 | 0 | 00h-07h |
| BV14r4y1y7Ln | 533459953 | 刘庸干净又卫生 | 发烧怎么办?看开挂的民族如何应对! | 2021-10-18 03:04:00 | 2240231 | 6026 | 6124 | 0 | 00h-07h |
| BV1Rq4y1Z7TT | 533459953 | 刘庸干净又卫生 | 依旧是甘蔗汁,天太热,如果没有糖分补充就会昏倒。 | 2021-09-08 09:46:02 | 2435455 | 2875 | 1766 | 0 | 08h-16h |
| BV1n54y1E7D5 | 533459953 | 刘庸干净又卫生 | 印度新德里街头水果摊大全,堪比超市! | 2021-07-12 09:54:17 | 959967 | 807 | 1070 | 0 | 08h-16h |
| BV1Yf4y1t7VV | 533459953 | 刘庸干净又卫生 | 这什么玩意儿?买了个寂寞! | 2021-06-24 13:12:41 | 2163298 | 596 | 853 | 0 | 08h-16h |
一键三连相关数据清洗
通过前面初步数据探索我们可以发现,因为是通过 HTML 获取到的一键三连相关的数据,当中存在中文计量单位,需要将其完全转化成数字后才能用于统计分析。
思路很简单,即将万字转换成数字 10000 再与原有的数字相乘即可,如果不存在万字则直接转换成整数即可。因此代码如下:
# make operators data numeric.
def numeric_ops(text: str):
if "万" in text:
digits = float(text.replace("万", "")) * 10000
return int(digits)
else:
return int(text)
operators: pd.DataFrame = (
raw.filter(items=ops)
.fillna("0")
.applymap(numeric_ops)
.astype("int")
)
operators.head()最后得到如下样式的数值化后的一键三连与历史排名数据:
| bvid | like | coin | collect | share |
| BV19r4y1r7wx | 79000 | 2182 | 2088 | 1856 |
| BV14r4y1y7Ln | 95000 | 5265 | 3241 | 8044 |
| BV1Rq4y1Z7TT | 104000 | 8106 | 2410 | 1844 |
| BV1n54y1E7D5 | 32000 | 976 | 658 | 472 |
| BV1Yf4y1t7VV | 51000 | 1483 | 1289 | 481 |
时间数据提取与转化
前面剔除的 length 播放时长字段,我们可以将其分秒部分的时间分别提取出来,然后将分钟的部分转换成秒,并与额外的秒数相加,以秒为单位来表示播放时长,这样既能用于计算、可视化,也可以在需要的时候从秒转换成其他时间单位:
timer: pd.DataFrame = (
raw["length"].str
.extract(r"(?P<minute>\d{2}):(?P<second>\d{2})")
.astype("int")
.assign(seconds=lambda data: data["minute"] * 60 + data["second"])
.filter(like="seconds")
)
timer.head()之后会得到如下样式数据:
| bvid | seconds |
| BV19r4y1r7wx | 20 |
| BV14r4y1y7Ln | 144 |
| BV1Rq4y1Z7TT | 50 |
| BV1n54y1E7D5 | 59 |
| BV1Yf4y1t7VV | 55 |
数据整合
将各个部分的数据都处理好之后,我们就可以通过前面为数据基于 BVID 号而设置好的索引,将其整合到一起,最终构成一个完整的、可以直接用于分析使用的数据集:
# combine common, operators and timer frame together.
df: pd.DataFrame = (
pd.concat(
[common, operators, timer],
axis=1,
join="inner",
verify_integrity=True,
)
.sort_values(by="created")
.assign(
since_last_days=lambda data: (
data["created"]
.diff()
.dt.ceil("d")
.dt.days
.fillna(0)
.astype("int")
)
)
.reset_index()
)
df.head()这里我们将数据合并后根据 created 视频上传日期,对所有数据进行升序排序,并再新建一个 since_last_days 字段来表示每个视频距上次传的间隔天数,以供后续使用。
完整数据集的前五条数据如下所示:
| bvid | mid | author | title | created | play | comment | video_review | rank | created_type | like | coin | collect | share | seconds | since_last_days | |
| 0 | BV1Rh411D755 | 533459953 | 刘庸干净又卫生 | 原创首发 | 2021-04-02 17:31:29 | 1769938 | 2570 | 4809 | 0 | 17h-23h | 65000 | 6296 | 7349 | 3728 | 277 | 0 |
| 1 | BV175411A7L3 | 533459953 | 刘庸干净又卫生 | 喝一个养颜美容芦荟汁 | 2021-04-05 12:46:03 | 1865198 | 1802 | 5065 | 0 | 08h-16h | 70000 | 16000 | 9947 | 17000 | 131 | 3 |
| 2 | BV1jK4y1m7Dc | 533459953 | 刘庸干净又卫生 | 刷刷鞋 | 2021-04-06 17:00:02 | 761236 | 311 | 535 | 0 | 17h-23h | 16000 | 509 | 503 | 120 | 85 | 2 |
| 3 | BV1M54y1b7tD | 533459953 | 刘庸干净又卫生 | 我知道你们早就看过了,我只是怀念一下而已。 | 2021-04-07 15:35:02 | 2190407 | 919 | 1017 | 0 | 08h-16h | 53000 | 5952 | 6343 | 1476 | 59 | 1 |
| 4 | BV1nb4y1D77D | 533459953 | 刘庸干净又卫生 | 天热买个冰棍儿 | 2021-04-08 16:49:32 | 1682582 | 453 | 956 | 0 | 08h-16h | 42000 | 1322 | 1393 | 519 | 54 | 2 |
除此之外,我们也可以查看一下清洗之后数据集各个字段的类型情况如何,这里我们直接使用 DataFrame.dtypes 属性即可:
df.dtypes
video_review int64
rank int64
created_type category
like int64
coin int64
collect int64
share int64
seconds int64
since_last_days int64
dtype: object分析与可视化
数据清洗与处理这一步骤完成后就可以正式进入到对数据的应用阶段,包括数据分析、可视化等。为方便陈述结论与分析观点,在本小节中必要时会以图和表相结合的方式进行说明。
过去一年视频平均播放量约为 240 万
通过前面的数据类型可以看到数据集中字段大多数为数值类型,因此我们可以通过 DataFrame.describe() 方法查看关于这些数值型字段的数据概况:
df.describe(percentiles=[0.5], datetime_is_numeric=True)由于 DataFrame.describe() 方法的指标过多,这里我们在分位数上只查看中位数情况,并且将时间字段使用数值形式纳入到指标中:
| created | play | comment | video_review | rank | like | coin | collect | share | seconds | since_last_days | |
| count | 281 | 281 | 281 | 281 | 281 | 281 | 281 | 281 | 281 | 281 | 281 |
| mean | 2021-09-20 22:42:29.647686656 | 2.76805e+06 | 3587.99 | 6372.62 | 14.1032 | 134621 | 13328.2 | 5659.75 | 6202 | 155.228 | 1.78292 |
| min | 2021-04-02 17:31:29 | 333669 | 172 | 51 | 0 | 0 | 0 | 0 | 0 | 9 | 0 |
| 50% | 2021-09-15 08:43:32 | 2.43546e+06 | 2577 | 3514 | 0 | 95000 | 5839 | 3398 | 2751 | 76 | 2 |
| max | 2022-04-02 13:40:04 | 1.56532e+07 | 46792 | 82150 | 91 | 1.124e+06 | 350000 | 89000 | 106000 | 2877 | 7 |
| std | nan | 1.75495e+06 | 4407.25 | 8871.61 | 23.9082 | 128260 | 30758 | 8698.44 | 12144.3 | 327.589 | 0.909784 |
从上述基本统计指标中我们可以得到关于数据集 df 的以下信息:
- 最早上传的视频为 2021 年 4 月 2 日,截止至数据获取的 4 月 7 日为止,也是刘庸来 B 站的一周年;
- 刘庸的视频共有 281 条,其中播放量最高达到 1560 万,播放量最少的视频也有 30 几万左右,但从中位数来看,平均刘庸的视频播放量在 240 万左右;
在视频的几个指标中:
comment视频评论字段最多的时候有 4.5 万条左右,最少仅有 172 条,中位数平均每条视频的评论有大约 2500 条左右;video_review视频弹幕数字段最多的时候有 8.3 万条,最少仅有 51 条,中位数平均每条视频的评论有大约 3500 条左右;rank字段因为对未有排名记录的使用 0 进行补齐,因此但根据中位数来看补齐的数量较多,可能需要单独过滤已有排名的数据进行统计;like、coin、collect、share一键三连及分享四个字段中除了点赞的统计数值较高之外,其余三个字段数值分布差异较大;不过从最小值一行来看,数据中存在一键三连与分享都为 0 的记录,可能为异常记录,因此需要进一步查看;- 在刘庸的 281 条视频数据中,最长的视频播放时长大约有 48 分钟(2877 秒),最短的不过 9 秒,中位数平均每条视频的播放时长为 1 分钟左右,属于短视频类型;
- 从
since_last_days自上一次更新视频间隔天数字段来看,刘庸平均每 2 天会更新一次视频(中位数),当然也会有间隔小于一天就更新的时候(即days=0),最长「鸽子」时间长达一周(和少数派的作者相比还不够鸽)。
感染了新冠及康复的视频最受欢迎
因为 rank 字段中还有的视频没有排名而使用 0 进行补齐,但这并不能很好地显示出该字段的数据分布情况。因此我们可以对该字段进行简单地分析,并筛选出有历史名次的视频,更进一步地分析这些视频的排名情况。
我们可以先简单查看一下 rank 排名为前三名的视频有哪些,然后再基于这些视频的排名和上传时间进行排序:
df.query("1 <= rank <= 3").sort_values(["rank", "created"])结果如下:
| bvid | mid | author | title | created | play | comment | video_review | rank | created_type | like | coin | collect | share | seconds | since_last_days | |
| 251 | BV1AY41187b3 | 533459953 | 刘庸干净又卫生 | 久等了,昏昏沉沉好几天,今天清醒多了。 | 2022-01-25 05:00:05 | 8986409 | 35247 | 82150 | 1 | 00h-07h | 1124000 | 350000 | 65000 | 48000 | 257 | 5 |
| 252 | BV16F411H7gW | 533459953 | 刘庸干净又卫生 | 历时 8 天,我康复了,谢谢所有的朋友们。 | 2022-01-30 04:58:33 | 7348868 | 30466 | 66680 | 1 | 00h-07h | 1011000 | 289000 | 60000 | 62000 | 105 | 5 |
| 248 | BV1Lr4y1e7WH | 533459953 | 刘庸干净又卫生 | 印度白领区的街头咖啡,非常的好喝。 | 2022-01-18 10:05:09 | 4056024 | 5467 | 10100 | 2 | 08h-16h | 262000 | 9782 | 6916 | 4307 | 91 | 1 |
| 197 | BV18r4y1Q7sE | 533459953 | 刘庸干净又卫生 | 应广发粉丝的要求,印度晚上街头走一走,闲聊几句! | 2021-11-24 03:00:04 | 4162761 | 14103 | 38706 | 3 | 00h-07h | 285000 | 108000 | 27000 | 18000 | 908 | 1 |
| 249 | BV1qS4y1o7Yk | 533459953 | 刘庸干净又卫生 | 快过年了,提前吃点好吃的。 | 2022-01-19 11:00:18 | 6794331 | 14981 | 25761 | 3 | 08h-16h | 481000 | 49000 | 20000 | 16000 | 164 | 2 |
从结果可以看到,庸子播放量排名最靠前的是 1 月下旬时两条自己感染了新冠及康复的视频,视频能冲到 B 站第一也体现了广大网友对其的关心及关注度之高。同时感染新冠视频之前的前两条视频(即 2022 年 1 月 18 和 19 号的视频)的排名也连带被冲到了第二第三的位置。
为了进一步探究刘庸视频历史排名的情况,我们可以将没有历史排名的记录过滤后再查看最后的统计指标情况:
df_rank = df.query("rank != 0")["rank"]
df_rank.describe()结果如下所示:
+-------+-------------------+
| | rank |
+-------+-------------------+
| count | 102.0 |
| mean | 38.85294117647059 |
| std | 24.76919080321379 |
| min | 1.0 |
| 25% | 19.0 |
| 50% | 35.0 |
| 75% | 58.75 |
| max | 91.0 |
+-------+-------------------+在 281 条视频中,仅有 102 条视频有历史排名,距中位数显示,这些视频大多数排名在第 35 的位置。这可以用直方图来反应其分布情况:
sns.histplot(data=df_rank, kde=True)
我们也可以对已有的 102 条有排名数据进一步切分,用以查看不同区间范围的排名情况:
rank_interval = [(0, 3), (3, 10), (10, 20), (20, 100)]
bins = pd.IntervalIndex.from_tuples(rank_interval)
counts = (
df_rank.to_frame()
.assign(
rank_interval = df["rank"].pipe(pd.cut, bins=bins)
)
)
counts.head()最后会每个排名都会对应一个区间范围:
| rank | rank_interval | |
| 126 | 35 | (20, 100] |
| 128 | 70 | (20, 100] |
| 129 | 57 | (20, 100] |
| 132 | 81 | (20, 100] |
| 135 | 46 | (20, 100] |
并在此排名区间的基础上进行分组统计,最终能得到每个排名区间的数据分布:
rank_interval_freq = counts.value_counts("rank_interval", ascending=True)
rank_interval_freq.head()| rank_interval | 0 |
| (0, 3] | 5 |
| (3, 10] | 8 |
| (10, 20] | 16 |
| (20, 100] | 73 |
基于此频数统计结果,还能进一步可视化以便直观查看数据的真实形态,在展示时我们可以连同统计数字一同绘制到图形中:
ax = sns.countplot(x="rank_interval", data=counts)
ax.bar_label(container=ax.containers[0], labels=rank_interval_freq.values)
从结果上可以看到,虽然刘庸的视频均播放量在 200 万左右,但在排名上能进入到前 20 的数量相对较少,能排名在前 3 的视频也仅有寥寥 5 个。但考虑到他每个视频的平均播放时长在 1 分多钟,且大部分都能进入到 B 站的前 100 名中,又可以说是领先于很多人了。
如果有和笔者一样经常看刘庸视频的朋友就知道,庸子平时拍的视频没有过多华丽的剪辑技巧,多以自己在印度的日常生活 Vlog 记录形式为主,也比较接地气,因此结合数据上可以看出其群众基础之高。
「海盗狗」是播放量最高的一期
由于庸子视频的均播放量在 200 万左右,这可以说是一个令很多 UP 主都羡慕的数值,这里我们对 play 播放量字段进一步探究。
类似的,我们可以查看播放量最高的 TOP 5 视频是哪些:
df.sort_values("play", ascending=False).head()| bvid | mid | author | title | created | play | comment | video_review | rank | created_type | like | coin | collect | share | seconds | since_last_days | |
| 156 | BV1PQ4y167xk | 533459953 | 刘庸干净又卫生 | 刘庸神作,万人要求的海盗狗。 | 2021-10-03 12:30:36 | 15653236 | 14163 | 8221 | 79 | 08h-16h | 439000 | 108000 | 89000 | 97000 | 33 | 2 |
| 135 | BV1Lb4y127dj | 533459953 | 刘庸干净又卫生 | 还是芦荟店的芦荟汁干净又卫生啊! | 2021-09-10 08:40:58 | 10565366 | 10196 | 21830 | 46 | 08h-16h | 327000 | 39000 | 20000 | 55000 | 132 | 2 |
| 128 | BV15b4y1U7kV | 533459953 | 刘庸干净又卫生 | 刘庸继芦荟汁后又一重磅力作,水果捞! | 2021-09-03 05:19:21 | 10029294 | 9371 | 33730 | 70 | 00h-07h | 277000 | 40000 | 20000 | 106000 | 123 | 1 |
| 251 | BV1AY41187b3 | 533459953 | 刘庸干净又卫生 | 久等了,昏昏沉沉好几天,今天清醒多了。 | 2022-01-25 05:00:05 | 8986409 | 35247 | 82150 | 1 | 00h-07h | 1124000 | 350000 | 65000 | 48000 | 257 | 5 |
| 129 | BV1W44y187z5 | 533459953 | 刘庸干净又卫生 | 好久没来吃这玩意,这次我得休息几天? | 2021-09-04 05:57:32 | 8674471 | 6814 | 12417 | 57 | 00h-07h | 258000 | 29000 | 11000 | 25000 | 152 | 2 |
在刘庸所有视频中,播放最多的当属「海盗狗」这一期(笔者按:视频主要记录刘庸见到一只花色斑驳狗的所闻所感),并且自从该视频后,也出现了许多模仿其风格记录遇见长相怪异的动物时的视频。
表演实力得到了网友认可
除此之外我们也可以查看一下一键三连及分享,这几个对于所有 B 站视频最重要的指标的数据情况如何。这里我们简单对查看一下刘庸所有视频根据一键三连及分享的综合排序情况:
df.sort_values(ops, ascending=False).head()结果如下:
| bvid | mid | author | title | created | play | comment | video_review | rank | created_type | like | coin | collect | share | seconds | since_last_days | |
| 251 | BV1AY41187b3 | 533459953 | 刘庸干净又卫生 | 久等了,昏昏沉沉好几天,今天清醒多了。 | 2022-01-25 05:00:05 | 8986409 | 35247 | 82150 | 1 | 00h-07h | 1124000 | 350000 | 65000 | 48000 | 257 | 5 |
| 252 | BV16F411H7gW | 533459953 | 刘庸干净又卫生 | 历时 8 天,我康复了,谢谢所有的朋友们。 | 2022-01-30 04:58:33 | 7348868 | 30466 | 66680 | 1 | 00h-07h | 1011000 | 289000 | 60000 | 62000 | 105 | 5 |
| 253 | BV1vF411H7ZG | 533459953 | 刘庸干净又卫生 | 除夕在印度买牛肉做大餐。 | 2022-01-31 08:08:27 | 5668822 | 12304 | 37290 | 6 | 08h-16h | 576000 | 84000 | 25000 | 11000 | 213 | 2 |
| 164 | BV1oL41137tf | 533459953 | 刘庸干净又卫生 | 第二部 5+5=9 | 2021-10-11 06:07:06 | 5234232 | 8771 | 5686 | 5 | 00h-07h | 491000 | 79000 | 40000 | 16000 | 70 | 2 |
| 249 | BV1qS4y1o7Yk | 533459953 | 刘庸干净又卫生 | 快过年了,提前吃点好吃的。 | 2022-01-19 11:00:18 | 6794331 | 14981 | 25761 | 3 | 08h-16h | 481000 | 49000 | 20000 | 16000 | 164 | 2 |
当然基于此数据我们也可以进一步可视化,同样是将视频的相关数据也绘制到图形中:
ax = (
df.loc[:, ["bvid", "title", *ops]]
.assign(
title=(
df["title"].str.replace(r"[!,。!.,]", "\n")
+ df["bvid"].map(lambda v: "\n({})".format(v))
)
)
.sort_values(ops, ascending=False)
.head(5)
.set_index("title")
.plot.barh(
figsize=(12, 12),
xlabel="",
)
)
# Revert display rank.
ax.invert_yaxis()
# Annotation
for patch in ax.patches:
ax.text(
patch.get_width() + 0.3,
patch.get_y() + 0.1,
" {:,}".format(patch.get_width()),
fontsize=8,
color="black",
)图形显示如下:

从综合排名看,播放量和排名靠前的视频受到的关注度会非常之高,因此一键三连及分享排名相对也会靠前;但在上述视频中,《第二部 5+5=9》这一视频能在综合排序中拥有一席之地是让有些意想不到的,该视频是庸子回国时参演的一部短视频,在视频中庸子表现出的演技可以说超出国内流量明星一大截。
播放越多,弹幕越多
当然我最初关注刘庸的原因在于其视频中的弹幕文字,结合视频内容来看——尤其是与「美食」相关的——每期都可以算得上是「中国生僻字大赛」海选现场以及化学课堂,十分有意思。因此我们也可以基于弹幕数和评论数对其视频进行综合排序:
df.sort_values(["video_review", "comment"], ascending=False).head()| bvid | mid | author | title | created | play | comment | video_review | rank | created_type | like | coin | collect | share | seconds | since_last_days | |
| 251 | BV1AY41187b3 | 533459953 | 刘庸干净又卫生 | 久等了,昏昏沉沉好几天,今天清醒多了。 | 2022-01-25 05:00:05 | 8986409 | 35247 | 82150 | 1 | 00h-07h | 1124000 | 350000 | 65000 | 48000 | 257 | 5 |
| 252 | BV16F411H7gW | 533459953 | 刘庸干净又卫生 | 历时 8 天,我康复了,谢谢所有的朋友们。 | 2022-01-30 04:58:33 | 7348868 | 30466 | 66680 | 1 | 00h-07h | 1011000 | 289000 | 60000 | 62000 | 105 | 5 |
| 197 | BV18r4y1Q7sE | 533459953 | 刘庸干净又卫生 | 应广发粉丝的要求,印度晚上街头走一走,闲聊几句! | 2021-11-24 03:00:04 | 4162761 | 14103 | 38706 | 3 | 00h-07h | 285000 | 108000 | 27000 | 18000 | 908 | 1 |
| 253 | BV1vF411H7ZG | 533459953 | 刘庸干净又卫生 | 除夕在印度买牛肉做大餐。 | 2022-01-31 08:08:27 | 5668822 | 12304 | 37290 | 6 | 08h-16h | 576000 | 84000 | 25000 | 11000 | 213 | 2 |
| 128 | BV15b4y1U7kV | 533459953 | 刘庸干净又卫生 | 刘庸继芦荟汁后又一重磅力作,水果捞! | 2021-09-03 05:19:21 | 10029294 | 9371 | 33730 | 70 | 00h-07h | 277000 | 40000 | 20000 | 106000 | 123 | 1 |
我们也可以在弹幕数的基础上,加入播放量数据,用以探究弹幕数和播放量的关系。这里我们直接以散点图并结合线性回归来展示:
g = sns.lmplot(x="play", y="video_review", data=df, height=3)
g.fig.set_size_inches(16, 8)
g.ax.set_xticklabels([f"{int(n) / 1000:,.0f} K" for n in g.ax.get_xticks()])
g.ax.set_yticklabels([f"{n:,.0f}" for n in g.ax.get_yticks()])
从图形中可以看到二者存在一定的线性关系,即随着播放量的增长,受到关注的机会也就越多越容易被其他 B 站用户关注,进而观看视频发表弹幕。
除此之外,我们也可以加入时间维度,进一步发现当中的规律和趋势情况:
(
df.loc[:, "created":"video_review"]
.set_index("created")
.plot.line(
figsize=(12, 10),
alpha=0.5,
x_compat=True,
xlabel="",
subplots=True,
)
)
从图中可以发现每次上传视频的弹幕数和评论数存在高度相关的趋势,并且当中出现的部分峰值也与播放量的峰值相吻合。
由于视频数据的相关指标较多,受限于篇幅和分析目标,我们可以直接用一张大图来查看数据集中各个数值类型字段的分布情况:
import itertools
fig, ax = plt.subplots(3, 3, figsize=(12, 12))
targets = [
"play", "comment", "video_review", "seconds", "since_last_days",
*ops,
]
# combination like: (0, 0), (0, 1), (1, 0), (1, 1) etc.
locations = itertools.product(range(ax.shape[0]), range(ax.shape[1]))
for i, j in locations:
position = i * 3 + j
sns.histplot(
x=df.filter(items=targets).iloc[:, position],
ax=ax[i][j],
kde=True,
alpha=0.5,
palette="crest",
)最终会得到一张较大的直方图矩阵:

从矩阵中可以看到关于视频的几个指标数据多呈右偏态分布,反映数据主要集中在某些数值范围内居多;有意思的是,前面构造的 since_last_days 字段呈现「双峰」,说明刘庸的视频大多要么在一天之内更新多次,要么隔两天才更新。
除了视频的几个指标数据之外,我们还可以看看庸子视频与时间相关的字段,比如播放时长、视频上传时间段等。
从短视频博主开始转型
因为我们已经事先将每个视频的播放时长统一转换成用秒钟来进行表示,因此可以方便地将其作为数字来处理,这里我们还是类似于前面的数据探索过程,先对播放时长进行降序排序,看看其前 TOP 10 的情况:
df.sort_values(["seconds"], ascending=False).head(10)结果如下:
| bvid | mid | author | title | created | play | comment | video_review | rank | created_type | like | coin | collect | share | seconds | since_last_days | |
| 136 | BV1gg411c7AD | 533459953 | 刘庸干净又卫生 | 乔治理发超长版,乔治买了新手机。 | 2021-09-11 10:14:39 | 1317949 | 2412 | 7054 | 0 | 08h-16h | 80000 | 36000 | 11000 | 2041 | 2877 | 2 |
| 118 | BV1fQ4y1Y7Nt | 533459953 | 刘庸干净又卫生 | 乔治理发超长版,满足一些粉丝的要求。 | 2021-08-24 08:18:14 | 1267113 | 3415 | 9467 | 0 | 08h-16h | 75000 | 29000 | 12000 | 2801 | 2678 | 2 |
| 148 | BV1FM4y137pf | 533459953 | 刘庸干净又卫生 | 终于可以睡个好觉了,失眠患者的福音,半个月一次的乔治理发又来了。 | 2021-09-25 13:11:59 | 1747505 | 2502 | 6738 | 0 | 08h-16h | 71000 | 13000 | 7555 | 2157 | 2470 | 2 |
| 175 | BV1Uv411M7s8 | 533459953 | 刘庸干净又卫生 | 失眠患者的福音,沉浸式体验,乔治理发超长版! | 2021-10-22 03:40:11 | 1188746 | 2349 | 7519 | 0 | 00h-07h | 62000 | 11000 | 6489 | 1887 | 2056 | 1 |
| 270 | BV1WL4y1371r | 533459953 | 刘庸干净又卫生 | 印度按摩完整版 | 2022-03-03 12:21:58 | 2189504 | 3863 | 12196 | 0 | 08h-16h | 117000 | 14000 | 15000 | 5957 | 1807 | 2 |
| 204 | BV1FL4y1W74f | 533459953 | 刘庸干净又卫生 | 德里街头日常刮胡子 | 2021-12-01 16:18:56 | 1471000 | 2577 | 4616 | 0 | 08h-16h | 75000 | 4515 | 3569 | 990 | 922 | 2 |
| 197 | BV18r4y1Q7sE | 533459953 | 刘庸干净又卫生 | 应广发粉丝的要求,印度晚上街头走一走,闲聊几句! | 2021-11-24 03:00:04 | 4162761 | 14103 | 38706 | 3 | 00h-07h | 285000 | 108000 | 27000 | 18000 | 908 | 1 |
| 207 | BV1pR4y1s7j2 | 533459953 | 刘庸干净又卫生 | 清真餐厅吃羊肉随拍。 | 2021-12-03 17:43:08 | 3394668 | 4983 | 13973 | 63 | 17h-23h | 160000 | 18000 | 5713 | 2751 | 706 | 1 |
| 169 | BV1oq4y1V7KC | 533459953 | 刘庸干净又卫生 | 进来一起互相陪伴吃个饭吧,一顿真实而普通的家常便饭。顺便聊个天。 | 2021-10-16 04:05:05 | 1816158 | 4793 | 12540 | 0 | 00h-07h | 121000 | 23000 | 4337 | 1417 | 642 | 1 |
| 238 | BV1UR4y1u754 | 533459953 | 刘庸干净又卫生 | 分享日常早餐 | 2022-01-06 03:00:16 | 2400879 | 3782 | 12881 | 0 | 00h-07h | 130000 | 12000 | 3398 | 1472 | 603 | 1 |
可以看到,视频时长超过半小时(1800 秒)的有五个,全都是用于「助眠」的超长版视频;除此之外视频时长最长的也就在 15 分钟左右(900 秒)。因此我们以 1000 秒为界限对数据集中的所有视频进行一个简单频数统计:
df["seconds"].map(lambda v: v <= 1000 or False).value_counts()结果如下所示:
+-------+---------+
| | seconds |
+-------+---------+
| True | 276 |
| False | 5 |
+-------+---------+基于频数统计结果,我们可以将 5 个时长在半小时以上的视频数据进行剔除后,再看看剩下视频时长的数据分布如何:
import math
import matplotlib.transforms as transforms
base = (
df.filter(items=["created", "seconds"])
.query("seconds <= 1000")
.set_index("created")
)
ax = base.plot.line(
figsize=(12, 10),
x_compat=True,
alpha=0.5,
xlabel="",
ylabel="Seconds(s)",
)
(
base.rolling(7)
.mean()
.rename({"seconds": "lagging seconds(per 7 days)"}, axis=1)
.plot.line(ax=ax, color="red", xlabel="")
)
# reference: https://stackoverflow.com/a/42879040
trans = transforms.blended_transform_factory(
ax.get_yticklabels()[0].get_transform(), ax.transData
)
seconds_mean = df["seconds"].median().round(2)
ax.axhline(y=seconds_mean, linestyle="--", alpha=0.5, label="median seconds", color="grey")
ax.text(
x=0,
y=seconds_mean,
s=f"{int(seconds_mean / 60)} min {math.ceil(seconds_mean % 60)} s",
ha="right",
va="center",
transform=trans,
)
ax.legend()可视化情况如下:

我们除了基于上传时间绘制每个视频的播放时长之外,还对播放时长采用处理时间序列数据的数据滑窗方法对数据进行平滑处理,从而能反映出其基本趋势特征,同时作为参考这里也直接将前面得到的播放时长的中位数情况绘制到图形中。
从图中可以看到两个比较明显的规律,以 2021 年 9 月份为界限,在此时间点之前上传的视频大多数视频的播放时长仅在 1 分半左右。但在此时间点之后上传的视频播放时长数据点波动较明显,差异较大,甚至逐渐出现较多 1 分半甚至以上的视频,播放时长的增加趋势也较为明显。
喜欢在早 8 点到晚 4 点时间段上传视频
在前面数据清洗与处理部分由于我们事先基于 created 视频上传日期时间字段构造了一个上传日期时间段的字段,因此我们可以根据该字段查看刘庸每次视频上传的分布情况:
+--------------+------+
| created_type | bvid |
+--------------+------+
| 08h-16h | 148 |
| 17h-23h | 9 |
| 00h-07h | 124 |
+--------------+------+从视频可以看到在上传时间段中,在每天 8 点至 16 点上传的视频数量最多,除此就是在凌晨至早上 7 点左右上传的视频数量较多,但在 17 点至 23 点左右的这段时间里上传的视频相对较少。
注:这里的时间段是以北京时间来算,而刘庸所在的地区为印度和国内存在 2 个半小时的时间差,因此更为精确的描述方式应该要推算出当时的印度时间后再进行划分。
上述数据我们可以将其直观地以饼图的形式可以表现各个时间段的占比情况:
df.groupby("created_type")["bvid"].count().plot.pie(
autopct="%1.2f%%",
figsize=(8, 8),
ylabel="",
startangle=270,
explode=[0.01]*3,
)
我们还可以将上传时间段与前面的视频指标相关数据结合起来,以观察不同时间段上传的视频其视频指标相关数据的分布情况,从而发现它们之间是否有相关关系。
这里我们可以直接调用 DataFrame.corr() 方法计算几个数值型指标之间的相关系数(这里一键三连的部分笔者只取了点赞和投币数):
targets = ["created_type", "play", "comment", "video_review", "like", "coin"]
df[targets].corr()
+--------------+--------------------+--------------------+--------------------+--------------------+--------------------+
| | play | comment | video_review | like | coin |
+--------------+--------------------+--------------------+--------------------+--------------------+--------------------+
| play | 1.0 | 0.6283839281359768 | 0.5930639277083839 | 0.7359797684393793 | 0.5205785852300863 |
| comment | 0.6283839281359768 | 1.0 | 0.805081752263332 | 0.7882063806528907 | 0.7432404002803288 |
| video_review | 0.5930639277083839 | 0.805081752263332 | 1.0 | 0.8264620824078313 | 0.8252291010928197 |
| like | 0.7359797684393793 | 0.7882063806528907 | 0.8264620824078313 | 1.0 | 0.8131507651362301 |
| coin | 0.5205785852300863 | 0.7432404002803288 | 0.8252291010928197 | 0.8131507651362301 | 1.0 |
+--------------+--------------------+--------------------+--------------------+--------------------+--------------------+
相关系数矩阵结果中,当结果如果大于 0.5,说明对应的两个变量之间 可能 存在正向的相关关系。
这里我们可以绘制散点图与线性回归矩阵,用观察不同时间段上传的视频的数据情况。但因为不同数据指标之间存在较大的数值差异,为了避免在绘制时造成图形元素溢出,这里我们需要对其进行量纲(Scale)处理,这里使用 Z-Score 标准化算法 进行标准化:
# Z-score
normalize = lambda col: (col - col.mean()) / col.std()
normalized_df = (
df[targets]
.set_index("created_type")
.transform(normalize)
.reset_index()
)
normalized_df.head()最后得到的结果如下所示:
+---+--------------+---------------------+----------------------+----------------------+---------------------+----------------------+
| | created_type | play | comment | video_review | like | coin |
+---+--------------+---------------------+----------------------+----------------------+---------------------+----------------------+
| 0 | 17h-23h | -0.5687413529858454 | -0.23098070767218556 | -0.17624980275088126 | -0.542813795973336 | -0.22862914975682616 |
| 1 | 08h-16h | -0.5144606092560827 | -0.405239100503351 | -0.14739370466043183 | -0.5038305713190906 | 0.08686573201270403 |
| 2 | 17h-23h | -1.1435166496654485 | -0.7435454334607307 | -0.6580113779015877 | -0.924849397584942 | -0.41677515973212204 |
| 3 | 08h-16h | -0.3291510733794046 | -0.6055908724693914 | -0.6036807557156634 | -0.6363735351435252 | -0.23981322223505355 |
| 4 | 08h-16h | -0.618518265113256 | -0.7113257827028849 | -0.6105566228387782 | -0.7221366293828654 | -0.39034303495073003 |
+---+--------------+---------------------+----------------------+----------------------+---------------------+----------------------+之后我们基于标准化的数据再进行可视化:
sns.pairplot(
data=normalized_df,
hue="created_type",
kind="reg",
plot_kws={
"line_kws": {"alpha": 0.2},
"scatter_kws": {"alpha": 0.6},
}
)最后得到的图形如下所示:
从图中可以看到,笔者这里所选的几个视频指标数据都有着一定程度的正相关关系,并且在不同时间段中数据也有差异,比如在底部中间的弹幕数 video_review 与投币数 coin 一图中,凌晨至 7 点左右上传的视频数据有时会比其他时间段的数据要好(即绿色的数据点在蓝色的数据点之上)。
「印度」是刘庸最突出的标签
最后我们把分析目标转向视频标题,通过简单地对视频的标题进行简单的分词,看看刘庸视频中的词汇使用情况。这里我们使用到结巴分词来提取标题中的关键词:
import jieba
import jieba.analyse as ja
jieba.add_word("干净又卫生", tag="n")
jieba.add_word("芦荟汁", tag="n")
title = "\n".join(df["title"].tolist())
keywords = ja.extract_tags(
title,
topK=100,
withWeight=True,
allowPOS=("nr", "v", "n", "ns", "vn"),
)
keywords[:10]最后可以简单地输出一下关键词后大致会得到如下结果:
[('印度', 0.683859592143686),
('干净又卫生', 0.3195038085407572),
('甘蔗汁', 0.15681817260167039),
('芦荟汁', 0.14256197509242763),
('乔治', 0.12482552216675946),
('理发', 0.11240551405567928),
('刨冰', 0.09979338256469934),
('早餐', 0.08616520567403119),
('味道', 0.07351749903948775),
('小吃', 0.07328070809749444)]接着基于分词后得到的关键词,我们再对其进行可视化展示。在众多可视化图形中,专门有一种可以展示字词重要程度的图形——词云。
由于标题中包含中文,为了得到更好的展示效果这里笔者选择来自基于 Echarts 这款前端可视化的开源绘图库而封装的 Pyecharts 进行绘制,恰好 Pyecharts 中也提供了绘制词云的接口,不过在使用前我们需要简单地对其进行配置:
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_LAB紧接着再设定词云图形实例及其他可视化元素配置,并调用一下 load_javascript() 方法加载一些 Echarts 中可能用到的 JavaScript 代码:
graphics = (
WordCloud(
init_opts=opts.InitOpts(
height="800px",
width="1000px",
bg_color="white",
)
)
.add("", keywords, word_size_range=[25, 80])
.set_global_opts(
title_opts=opts.TitleOpts(
title="视频标题关键词 TOP 100",
subtitle="UP 主:刘庸干净又卫生",
pos_left="center",
),
toolbox_opts=opts.ToolboxOpts(
is_show=True,
pos_left="center",
pos_top="8%",
),
)
)
graphics.load_javascript()然后再单独调用一下 render_notebook() 即可将图形渲染绘制到 Jupyter Notebook 中:
graphics.render_notebook()最后我们将会得到一副交互式的词云图形:
免责声明:
- 本文所提供的数据抓取程序代码及思路仅供学习、交流使用,不得用于其他用途;如因使用者恶意使用所产生的任何法律后果本作者均不负相应责任;
- 如因数据接口存在变动、更新而导致本章节中所使用请求接口的代码失效或是程序无法正常运行,可能需要使用者自行修改相关程序,本作者不保证实时维护并修改代码,仅供学习参考。
《中华人民共和国刑法》第二百八十六条【破坏计算机信息系统罪】:违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,处五年以下有期徒刑或者拘役;后果特别严重的,处五年以上有期徒刑。违反国家规定,对计算机信息系统中存储、处理或者传输的数据和应用程序进行删除、修改、增加的操作,后果严重的,依照前款的规定处罚。故意制作、传播计算机病毒等破坏性程序,影响计算机系统正常运行,后果严重的,依照第一款的规定处罚。单位犯前三款罪的,对单位判处罚金,并对其直接负责的主管人员和其他直接责任人员,依照第一款的规定处罚。
> 下载 少数派 2.0 客户端、关注 少数派公众号,解锁全新阅读体验 📰
> 实用、好用的 正版软件,少数派为你呈现 🚀
© 本文著作权归作者所有,并授权少数派独家使用,未经少数派许可,不得转载使用。
如有侵权请联系:admin#unsafe.sh