
作者: f-undefined团队 v1n3gar
原文链接:https://mp.weixin.qq.com/s/JPbwYA2sS9jCMMgwBxONjg
知识点:
(1)使用 msg_msg 构造任意写来篡改 modprobe_path,通过 FUSE 来处理页错误(克服5.11版本之后用户没有userfaultfd权限的问题,肯定有一大波CTF题将要效仿)。
(2)由于漏洞对象位于 8-page,已经不能用常规的堆喷(slub allocator)来利用了,得利用页喷射(buddy system),作者分析了伙伴系统的源码,可以学习页喷知识(主要采用 ring_buffer 进行页喷和页风水,值得学习)。某种程度上来说本漏洞是一种 cross-cache overflow,从一个页溢出覆盖到下一个页上的cache(因为页上可以含有cache也可以是单纯的页)。
(3)采用新的弹性对象来泄露信息,也即user_key_payload弹性对象,由于长度变量和数据在一起,所以不担心溢出时覆盖到指针(限制是只能分配最多200个最长20000字节)。
影响版本:Linux-v5.17-rc8 以前,v5.17-rc8已修补。
测试版本:Linux-v5.16.14 exploit及测试环境下载地址
编译选项:所有和 INET6 / TUNNEL / XFRM / CONFIG_NET_KEY / CONFIG_NF_SOCKET_IPV6 相关的选项都勾上y,特别是以下选项。
CONFIG_XFRM_ESP=y
CONFIG_INET_ESP=y
CONFIG_INET_ESP_OFFLOAD=y
CONFIG_INET6_ESP=y
CONFIG_INET6_ESP_OFFLOAD=y在编译时将.config中的CONFIG_E1000和CONFIG_E1000E,变更为=y。参考
$ wget https://mirrors.tuna.tsinghua.edu.cn/kernel/v5.x/linux-5.16.14.tar.xz
$ tar -xvf linux-5.16.14.tar.xz
# KASAN: 设置 make menuconfig 设置"Kernel hacking" ->"Memory Debugging" -> "KASan: runtime memory debugger"。
$ make -j32
$ make all
$ make modules
# 编译出的bzImage目录:/arch/x86/boot/bzImage。漏洞描述:位于目录 net/ipv4/esp4.c 和 net/ipv6/esp6.c 中的 IPsec ESP transformation 代码存在堆溢出。漏洞自2017年引入(cac2661c53f3 / 03e2a30f6a27)。
本漏洞能够在最新的 Ubuntu 21.10 上提权,来自于pwn2own 2022,能够影响 Ubuntu / Fedora / Debian。首次进行 page-level heap fengshui 和 cross-cache overflow(环境:4G内存,2 CPU)。
补丁:patch 补丁引入 ESP_SKB_FRAG_MAXSIZE,大小为 32768 ,也就是 8-page,如果 allocsize 大于8页,则跳转到 COW。
diff --git a/include/net/esp.h b/include/net/esp.h
index 9c5637d41d951..90cd02ff77ef6 100644
--- a/include/net/esp.h
+++ b/include/net/esp.h
@@ -4,6 +4,8 @@
#include <linux/skbuff.h>
+#define ESP_SKB_FRAG_MAXSIZE (PAGE_SIZE << SKB_FRAG_PAGE_ORDER)
+
struct ip_esp_hdr;
static inline struct ip_esp_hdr *ip_esp_hdr(const struct sk_buff *skb)
diff --git a/net/ipv4/esp4.c b/net/ipv4/esp4.c
index e1b1d080e908d..70e6c87fbe3df 100644
--- a/net/ipv4/esp4.c
+++ b/net/ipv4/esp4.c
@@ -446,6 +446,7 @@ int esp_output_head(struct xfrm_state *x, struct sk_buff *skb, struct esp_info *
struct page *page;
struct sk_buff *trailer;
int tailen = esp->tailen;
+ unsigned int allocsz;
/* this is non-NULL only with TCP/UDP Encapsulation */
if (x->encap) {
@@ -455,6 +456,10 @@ int esp_output_head(struct xfrm_state *x, struct sk_buff *skb, struct esp_info *
return err;
}
+ allocsz = ALIGN(skb->data_len + tailen, L1_CACHE_BYTES);
+ if (allocsz > ESP_SKB_FRAG_MAXSIZE)
+ goto cow;
+
if (!skb_cloned(skb)) {
if (tailen <= skb_tailroom(skb)) {
nfrags = 1;
diff --git a/net/ipv6/esp6.c b/net/ipv6/esp6.c
index 7591160edce14..b0ffbcd5432d6 100644
--- a/net/ipv6/esp6.c
+++ b/net/ipv6/esp6.c
@@ -482,6 +482,7 @@ int esp6_output_head(struct xfrm_state *x, struct sk_buff *skb, struct esp_info
struct page *page;
struct sk_buff *trailer;
int tailen = esp->tailen;
+ unsigned int allocsz;
if (x->encap) {
int err = esp6_output_encap(x, skb, esp);
@@ -490,6 +491,10 @@ int esp6_output_head(struct xfrm_state *x, struct sk_buff *skb, struct esp_info
return err;
}
+ allocsz = ALIGN(skb->data_len + tailen, L1_CACHE_BYTES);
+ if (allocsz > ESP_SKB_FRAG_MAXSIZE)
+ goto cow;
+
if (!skb_cloned(skb)) {
if (tailen <= skb_tailroom(skb)) {
nfrags = 1;保护机制:KASLR / SMEP / SMAP
利用总结:主要利用过程位于 loop() 函数:
(1)初始化:设置CPU affinity,设置漏洞socket(文件描述符存在 r[1]);
(2)缓解噪声(避免 order-2 从 order-3 取页 或者 order-2 的页合并到 order-3,影响到漏洞对象的排布):
- (2-1)耗尽 order-0/1/2 的 freelist:喷射0x1000个大小为0x1000的
ring_buffer; - (2-2)分配
(10*100*2)个 4-page,释放一半:采用ring_buffer; - (2-3)释放
(2-1)中堆喷的对象;
(3)泄露 msg_msg->next(尝试9次):堆上布局3个相邻的对象—— vul object -> user_key_payload -> msg_msg。
- (3-1)耗尽 order-3 的freelist,使得堆排布时从 order-4 取页,保证8-page 相邻:喷射 0x2000 个大小为 0x8000 的
ring_buffer; - (3-2)耗尽 kmalloc-4k,使得分配
user_key_payload时从 buddy system 取页(order-3):调用setxattr()分配0x50*8个 kmalloc-4k; - (3-3)分配3个连续的 8-page 占位对象:采用
ring_buffer对象; - (3-4)释放第2个占位对象,分配1个8-page slab(分配1个
user_key_payload和7个setxattr()); - (3-5)喷射 100 个
seq_operations对象,便于之后泄露内核基址; - (3-6)释放第3个占位对象,分配1个8-page slab(喷射16个
msg_msg,位于 kmalloc-4k / kmalloc-32); - (3-7)释放第1个占位对象,分配漏洞对象,触发越界写来修改
user_key_payload->datalen; - (3-8)通过
user_key_payload进行越界读,泄露msg_msg->next;
(4)泄露内核基址(尝试50次):堆上布局2个相邻的对象——vul object -> msg_msg。
- (4-1)耗尽 kmalloc-4k,使得分配
msg_msg时从 buddy system 取页(order-3):堆喷0x100个大小为0x1000 的ring_buffer; - (4-2)耗尽 order-3 的freelist,使得堆排布时从 order-4 取页,保证8-page 相邻:喷射 0x100 个大小为 0x8000 大小的
ring_buffer; - (4-3)分配8*2个连续的 8-page 占位对象(占位对象):采用
ring_buffer对象; - (4-4)释放第2个占位对象,分配1个8-page slab (分配 9 个
msg_msg,位于 kmalloc-4k / kmalloc-32); - (4-5)释放第1个占位对象,分配漏洞对象,触发越界写来修改
msg_msg->m_ts&msg_msg->next(改成上一步泄露的msg_msg->next); - (4-6)通过
msg_msg进行越界读,泄露seq_operations->start / stop / next指针;
(5)篡改 modprobe_path 提权(尝试50次):堆上布局2个相邻的对象——vul object -> msg_msg。
- (5-1)设置 FUSE,页错误处理地址为 fuse_evil_addr = 0x1339000(FUSE的 evil_read_pause() 函数在处理页错误时,会往该地址写入字符串 /tmp/get_rooot\x00,也即提权程序);
- (5-2)耗尽 order-3 的freelist,使得堆排布时从 order-4 取页,保证8-page 相邻:喷射 0x100 个大小为 0x8000 大小的 ring_buffer;
- (5-3)分配2个连续的 8-page 占位对象(占位对象):采用 ring_buffer 对象;
- (5-4)释放第2个占位对象,分配1个8-page slab (分配 9 个 msg_msg,位于 kmalloc-4k / kmalloc-32)(注意,用户message地址设置为 fuse_evil_addr-8 == 0x1339000-8,以便在内核拷贝消息时触发页错误而暂停);
- (5-5)释放第1个占位对象,分配漏洞对象,触发越界写来修改 msg_msg->next(改成 modprobe_path-8);
- (5-6)通过写pipe来通知 FUSE 的 evil_read_pause() 函数,结束页错误处理,使得 msg_msg 消息完成拷贝,篡改 modprobe_path;
- (5-7)执行错误binary文件触发modprobe,完成提权。
1. 漏洞分析
简介:漏洞来自 Linux esp6 crypto 模块,接收缓冲区是 8-page,但发送者可以发送大于 8-page 的数据,导致页溢出。
1-1 漏洞对象创建
漏洞对象创建:esp6_output_head() 负责创建 receive buffer,allocsize 变量不重要,因为 skb_page_frag_refill() 会默认分配 8-page 内存(order-3 pages)。
调用栈:sendmsg() -> __sys_sendmsg() -> ___sys_sendmsg() -> ____sys_sendmsg() -> sock_sendmsg() -> sock_sendmsg_nosec() -> rawv6_sendmsg() -> rawv6_push_pending_frames() -> ip6_push_pending_frames() -> ip6_send_skb() -> ip6_local_out() -> dst_output() -> xfrm6_output() -> NF_HOOK_COND() -> __xfrm6_output() -> xfrm_output() -> xfrm_output2() -> xfrm_output_resume() -> dst_output() -> ip6_output() -> NF_HOOK_COND() -> ip6_finish_output -> __ip6_finish_output -> ip6_finish_output2() -> neigh_output() -> neigh_hh_output() -> dev_queue_xmit() -> __dev_queue_xmit() -> validate_xmit_skb() -> validate_xmit_xfrm() -> esp6_xmit() -> esp_output_head() 34层,太复杂了。。。
int esp6_output_head(struct xfrm_state *x, struct sk_buff *skb, struct esp_info *esp)
{
...
struct page_frag *pfrag = &x->xfrag; // x->xfrag->page = vul object
int tailen = esp->tailen;
allocsize = ALIGN(tailen, L1_CACHE_BYTES);
spin_lock_bh(&x->lock);
if (unlikely(!skb_page_frag_refill(allocsize, pfrag, GFP_ATOMIC))) { // [1]
spin_unlock_bh(&x->lock);
goto cow;
}
...
}
bool skb_page_frag_refill(unsigned int sz, struct page_frag *pfrag, gfp_t gfp)
{
if (pfrag->offset + sz <= pfrag->size)
return true;
...
if (SKB_FRAG_PAGE_ORDER &&
!static_branch_unlikely(&net_high_order_alloc_disable_key)) {
pfrag->page = alloc_pages((gfp & ~__GFP_DIRECT_RECLAIM) | // [2]
__GFP_COMP | __GFP_NOWARN |
__GFP_NORETRY,
SKB_FRAG_PAGE_ORDER);
...
}
...
return false;
}1-2 越界写
漏洞对象越界:null_skcipher_crypt() 函数中,内核拷贝了 N-page 数据,导致OOB。
static int null_skcipher_crypt(struct skcipher_request *req)
{
struct skcipher_walk walk;
int err;
err = skcipher_walk_virt(&walk, req, false);
while (walk.nbytes) {
if (walk.src.virt.addr != walk.dst.virt.addr)
// out-of-bounds write
memcpy(walk.dst.virt.addr, walk.src.virt.addr,
walk.nbytes);
err = skcipher_walk_done(&walk, 0);
}
return err;
}调用栈:... -> esp6_xmit() -> esp6_output_tail() -> crypto_aead_encrypt() -> crypto_authenc_encrypt() -> crypto_authenc_copy_assoc() -> crypto_skcipher_encrypt() -> null_skcipher_crypt() 可以看到,esp6_xmit() 先调用 esp6_output_head() 分配漏洞对象的 8-page 内存(地址存放在x->xfrag->page),再调用 esp6_output_tail() 将该内存赋值给 req.dst 并最后触发OOB。
static int esp6_xmit(struct xfrm_state *x, struct sk_buff *skb, netdev_features_t features)
{
int err;
int alen;
struct esp_info esp;
bool hw_offload = true;
... ...
esp.tailen = esp.tfclen + esp.plen + alen; // esp.tailen -> allocsize
if (!hw_offload || !skb_is_gso(skb)) {
esp.nfrags = esp6_output_head(x, skb, &esp); // [1] alloc the vulnerable object, saved at x->xfrag->page
if (esp.nfrags < 0)
return esp.nfrags;
}
... ...
err = esp6_output_tail(x, skb, &esp); // [2] trigger OOB
... ...
}
int esp6_output_tail(struct xfrm_state *x, struct sk_buff *skb, struct esp_info *esp)
{
... ...
if (!esp->inplace) {
int allocsize;
struct page_frag *pfrag = &x->xfrag;
... ...
page = pfrag->page;
get_page(page);
/* replace page frags in skb with new page */
__skb_fill_page_desc(skb, 0, page, pfrag->offset, skb->data_len);
pfrag->offset = pfrag->offset + allocsize;
spin_unlock_bh(&x->lock);
sg_init_table(dsg, skb_shinfo(skb)->nr_frags + 1);
err = skb_to_sgvec(skb, dsg,
(unsigned char *)esph - skb->data,
assoclen + ivlen + esp->clen + alen);
... ...
aead_request_set_crypt(req, sg, dsg, ivlen + esp->clen, iv); // [2-1] dsg = x->xfrag->page
aead_request_set_ad(req, assoclen);
... ...
err = crypto_aead_encrypt(req); // [2-2] req->dst = dsg
... ...
}
EXPORT_SYMBOL_GPL(esp6_output_tail);
static int null_skcipher_crypt(struct skcipher_request *req)
{
struct skcipher_walk walk;
int err;
err = skcipher_walk_virt(&walk, req, false); // [3] walk->dst = req.dst
while (walk.nbytes) {
if (walk.src.virt.addr != walk.dst.virt.addr)
memcpy(walk.dst.virt.addr, walk.src.virt.addr, // [4] trigger OOB
walk.nbytes);
err = skcipher_walk_done(&walk, 0);
}
return err;
}漏洞缺陷:作者利用时,发送 16-page 数据,可以溢出 8-page,问题是 esp_output_fill_trailer() 会根据消息长度和所用协议类型,在末尾添加几个字节(对我们来说是垃圾数据)。
static inline void esp_output_fill_trailer(u8 *tail, int tfclen, int plen, __u8 proto)
{
/* Fill padding... */
if (tfclen) {
memset(tail, 0, tfclen);
tail += tfclen;
}
do {
int i;
for (i = 0; i < plen - 2; i++)
tail[i] = i + 1;
} while (0);
tail[plen - 2] = plen - 2;
tail[plen - 1] = proto;
}2. Buddy system 知识
说明:分析伙伴系统的原理是研究 page-level heap fengshui 的前提。
2-1 page allocator
页分配器的知识可以参见 page_alloc.c 源码。
简介:Linux page allocator 管理内核底层的物理页,SLUB / SLAB / SLOB 内存分配器都在 Page allocator 之上。例如,当内核耗尽所有 kmalloc-4k slab之后,内存分配器会向 Page allocator 申请内存,由于 kmalloc-4k 位于 8-page slab (order 3),所以 Page allocator 会申请 8-page 内存给内存分配器。
存储结构:Page allocator 采用 free_area 结构(zone->free_area 数组,长度为 MAX_ORDER == 1,所以最大order为11)来保存空闲页,也就是个保存不同 order/size 页的数组,采用 order 来区分不同大小的页(例如,N-order 表示大小为 PAGE_SIZE<<3 的页;order-0 就表示大小为 PAGE_SIZE 的页)。free_area 中每个 order 都对应一个 free_list,从 free_list 分配或将页释放后放入 free_list。
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};cache 与页分配:不同的slab如果耗尽了会申请不同 order 的页,例如,kmalloc-256 会从 order-0 申请页,而 kmalloc-512 会从 order-1 申请页,kmalloc-4k 会从 order-3 申请页。
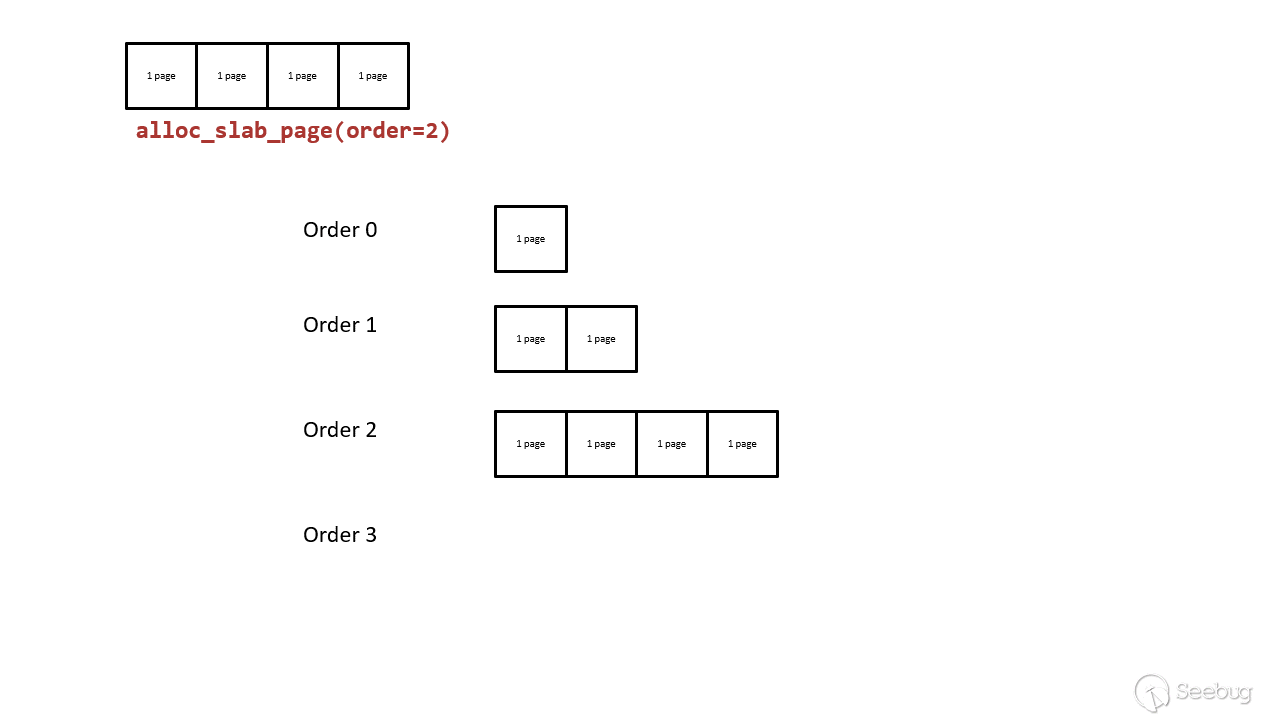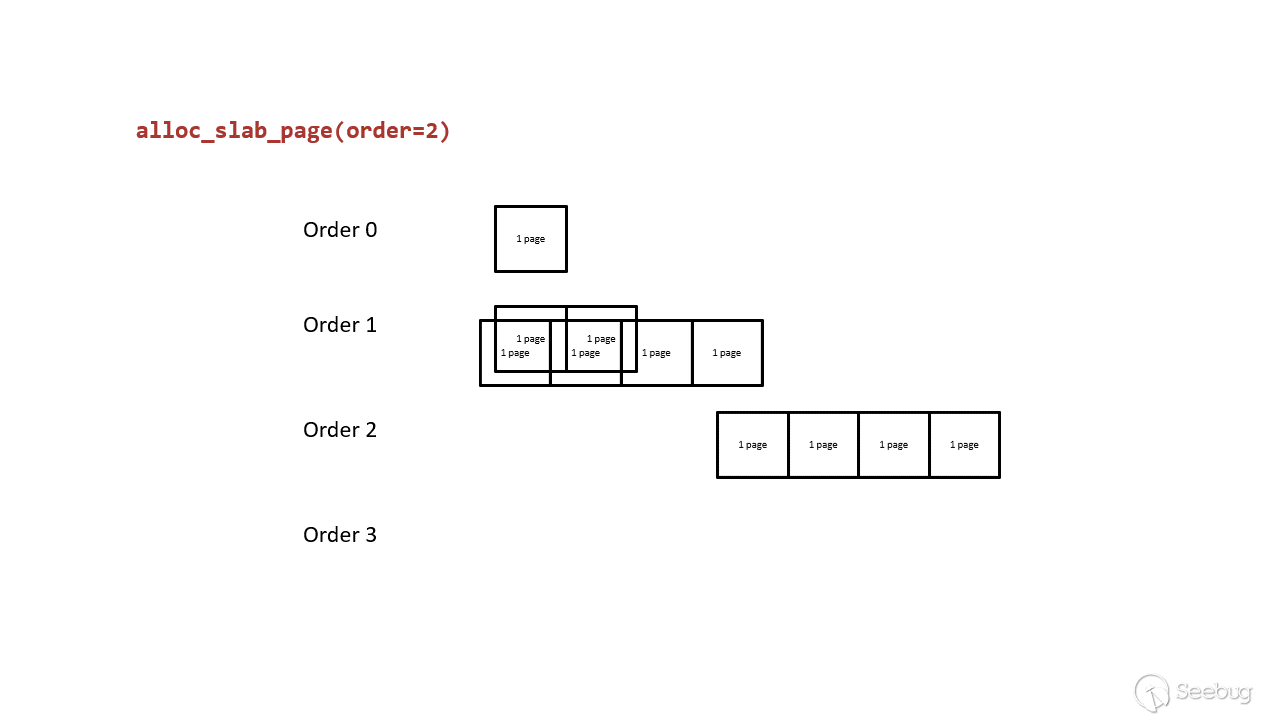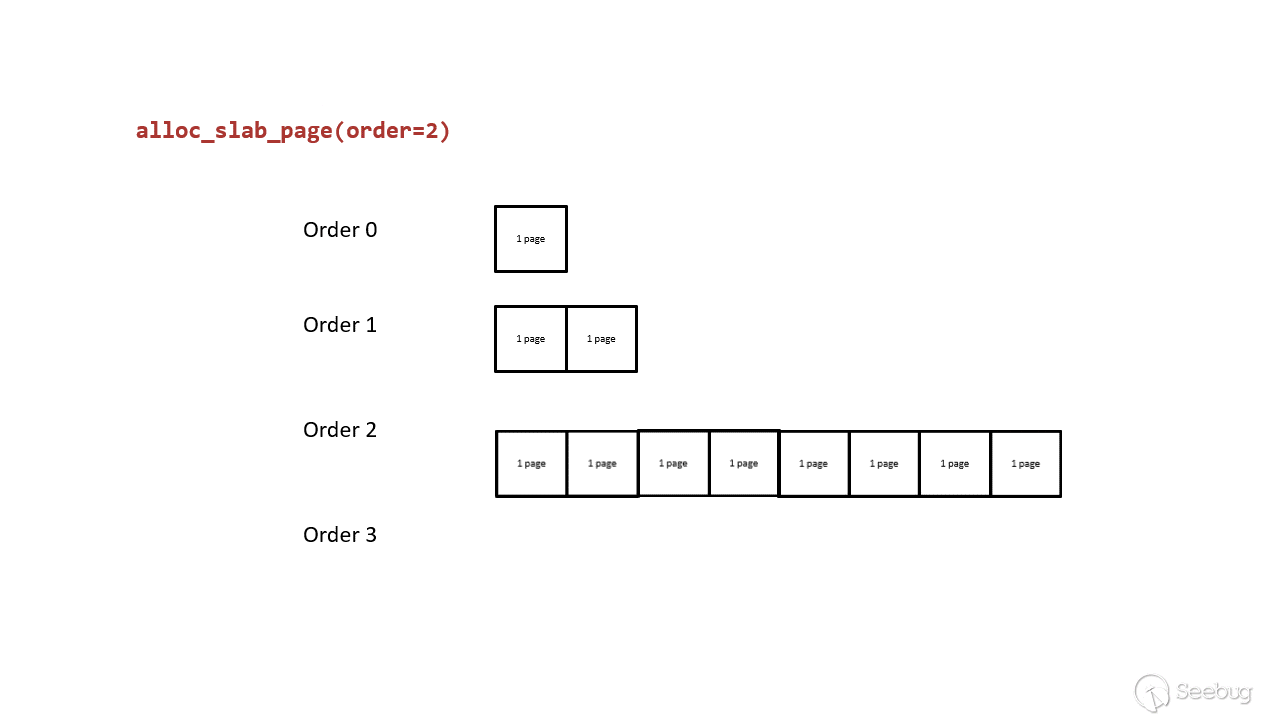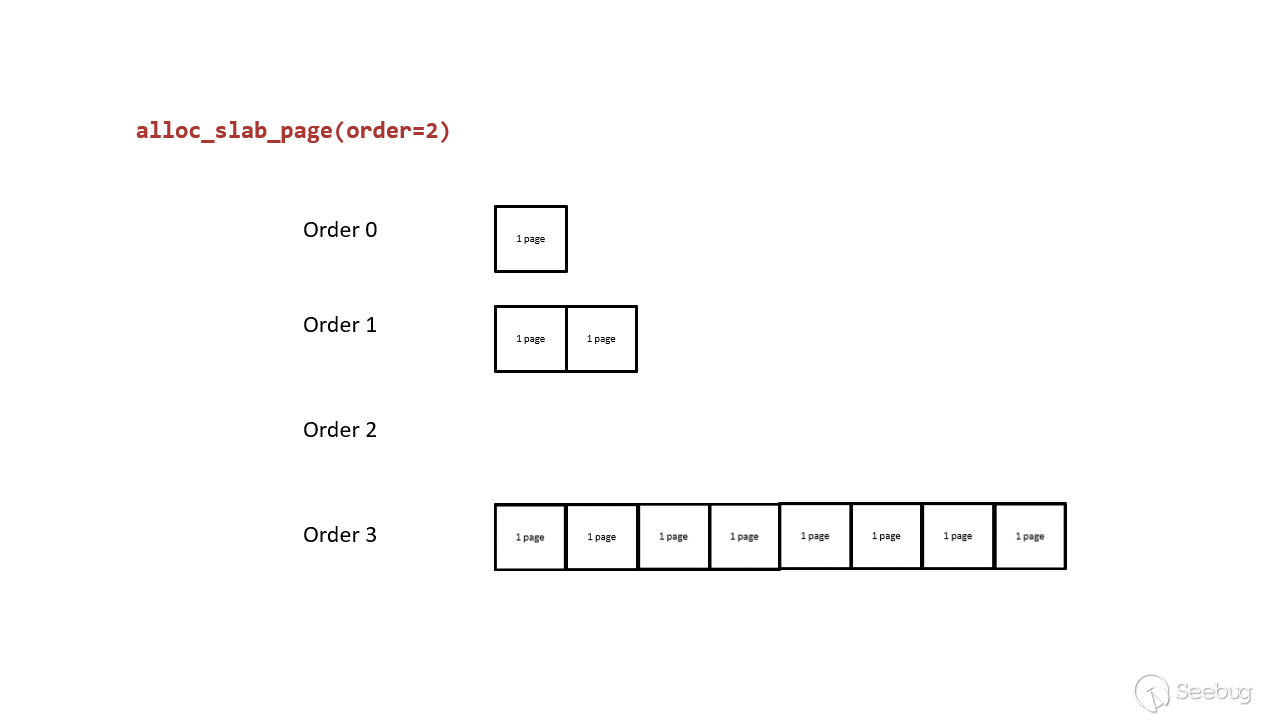
split page:如果 free_list 中没有空闲页,则 lower-order free_area 从 higher-order free_area 取页,higher-order free_area 将页一分为二,然后 lower-order free_area 将页返回给申请者(例如 alloc_pages())。例如,当 order-2(4-page)的 free_list 耗尽之后,就从 order-3 申请页,order-3 的页分成两个 4-page 页,位于低地址的 4-page 返回给申请者,高地址的 4-page 保存在 order-2 的free_list 中供下次申请。原理如下所示:
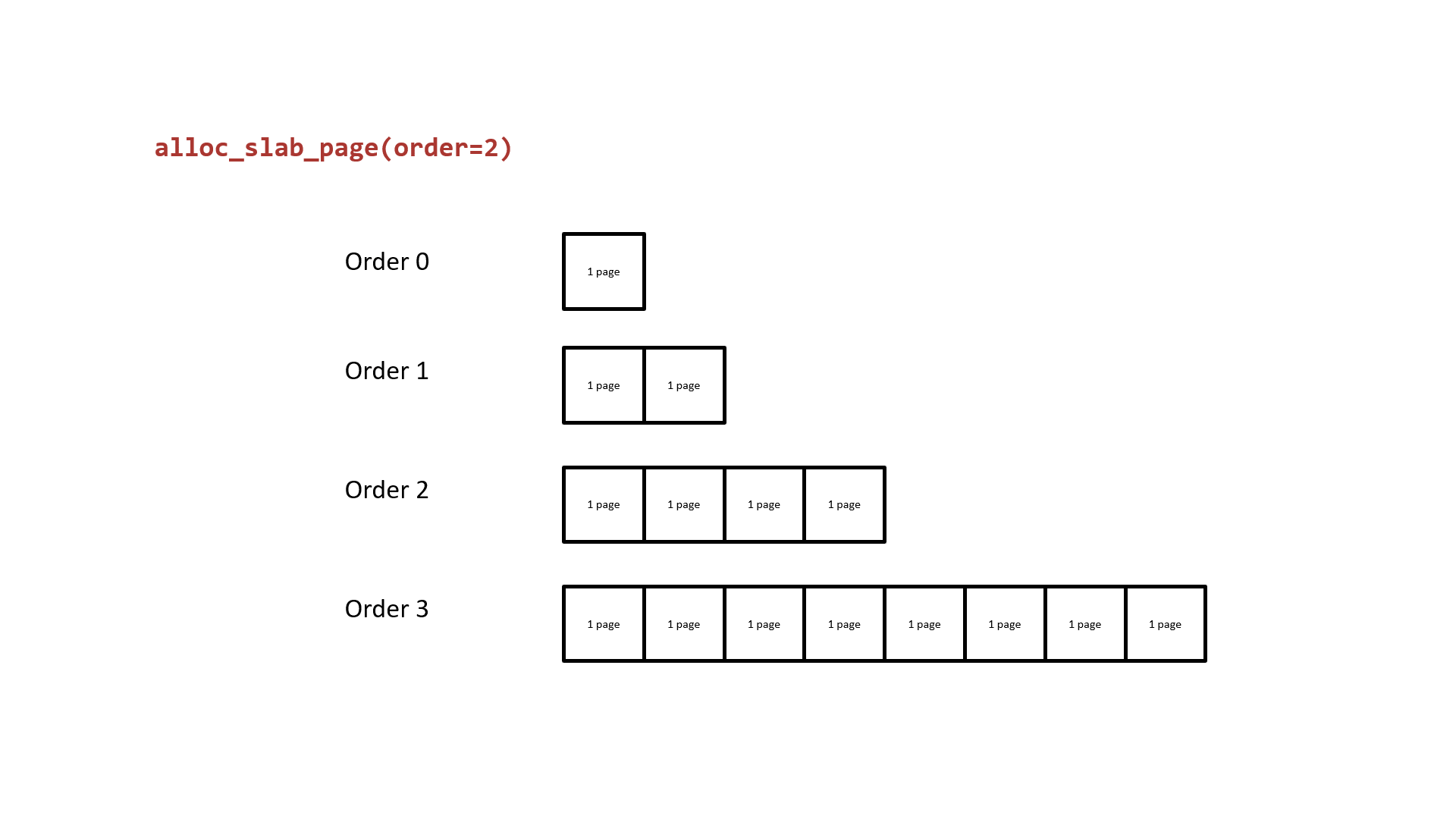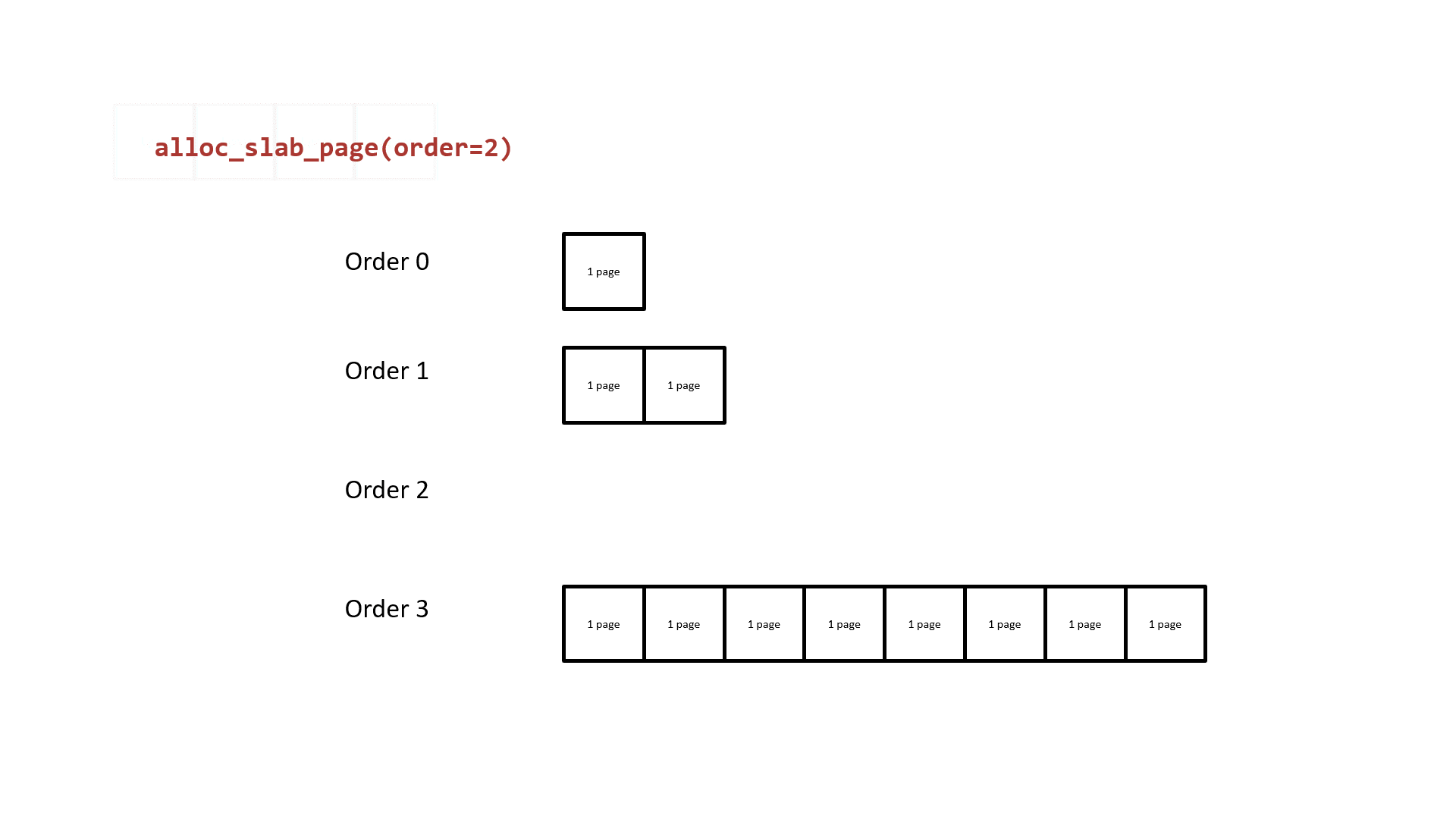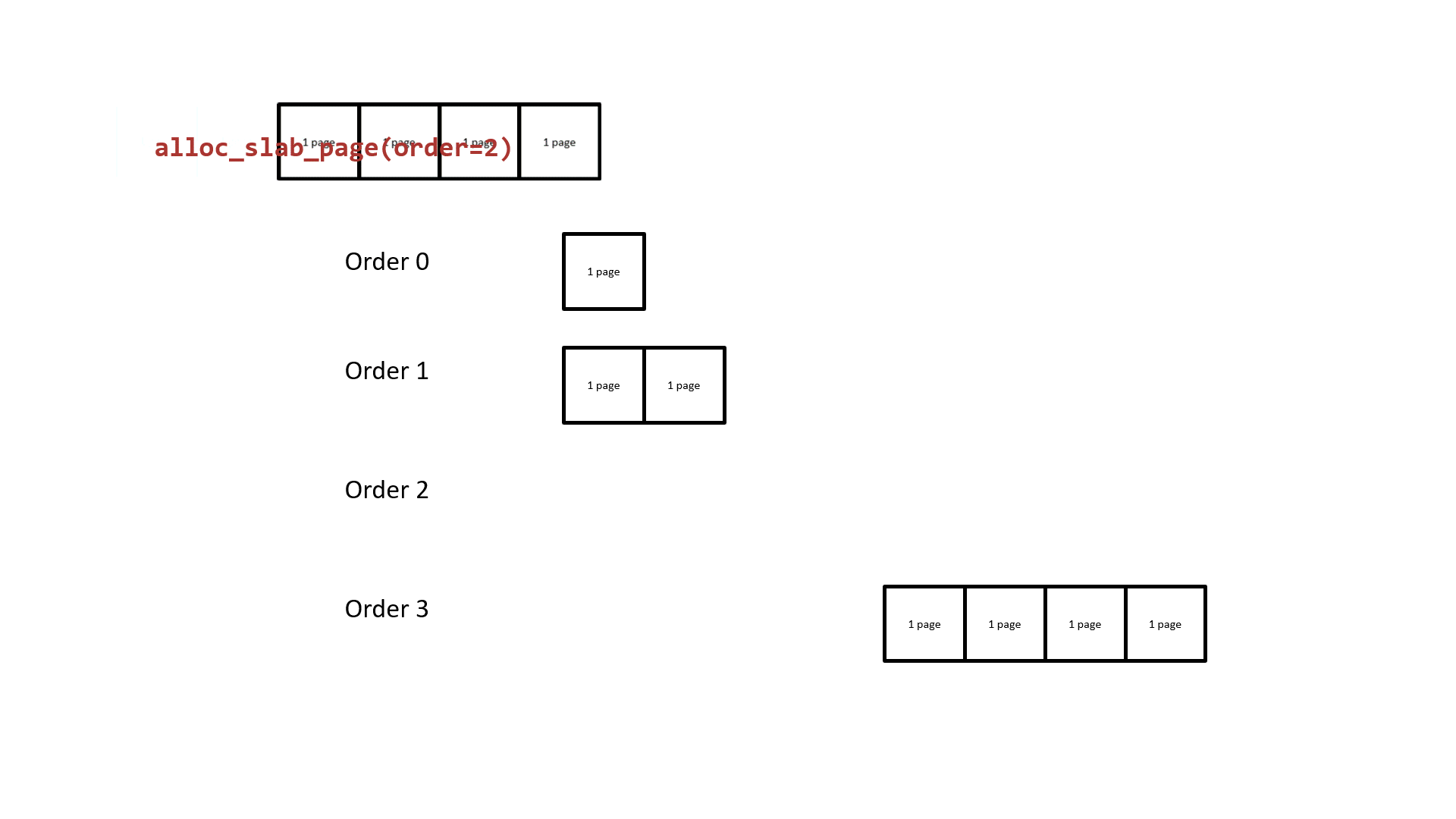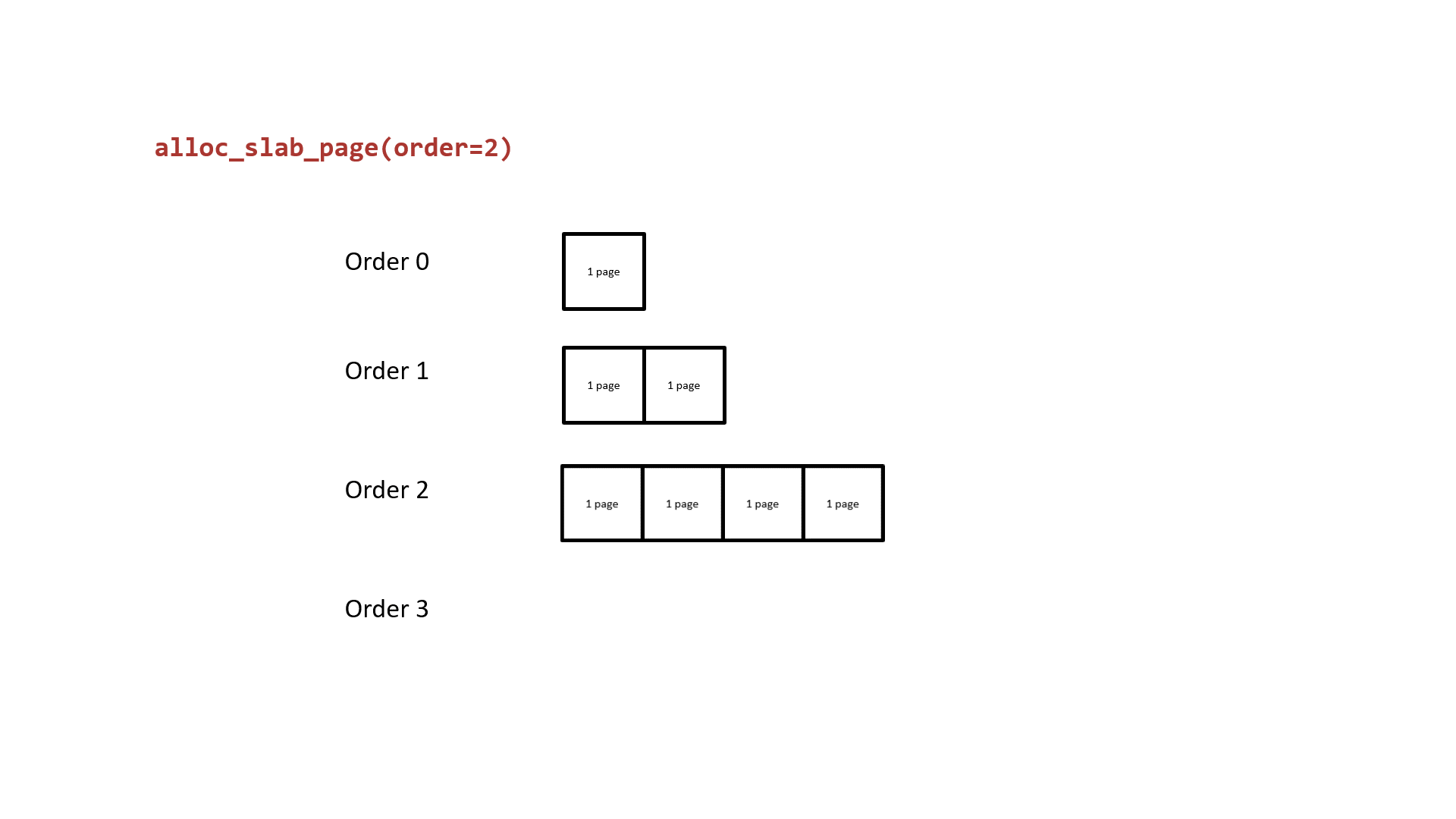
merge page:如果 free_list 中有很多空闲页,页分配器会整合两个相邻的、order相同的页,并放入 higher-order free_area 。还是以刚才的例子来看,假设 order-3 被分成两个 order-2 的页,其中一个存放在 order-2 的 free_list,只要被分配的页又被释放回 order-2 的 free_list,页分配器会检查新释放的页在同一 free_list 中是否存在相邻的页(这俩就被称为 buddy),存在的话就将这俩合并后放入 order-3。
对应源码:以下代码展示了页分配器如何从 free_area 中选取页以及如何从 higher-order 中取页。
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
// Pick up the right order from free_area
area = &(zone->free_area[current_order]);
// Get the page from the free_list
page = get_page_from_free_area(area, migratetype);
// If no freed page in free_list, goes to high order to retrieve
if (!page)
continue;
del_page_from_free_list(page, zone, current_order);
expand(zone, page, order, current_order, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}
static inline struct page *get_page_from_free_area(struct free_area *area,
int migratetype)
{
return list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
}2-2 shaping heap
页风水目标:现在讨论下如何为 OOB write 布局堆结构。现在已知在页分配器中,每种 order 的页都保存在 free_area->free_list 中。由于不能保证在同一 free_list 中的两个页是连续的,所以即便连续申请2个同一order的页,这2个页可能相隔很远。为了更好的控制堆布局,我们需要确保 free_list 中所有的页是连续的。首先耗尽目标order的 free_list,迫使其向 higher-order 取页,这样取过来的页会被划分成两段连续的内存。
缓解噪声(保证连续):有些内核进程也会分配和释放页,影响了堆布局。回到本漏洞中来,我们的目标是布局连续的 order-3 的页,但是可能会有 order-3 的页被划分到 order-2 或者有 order-2 的页被整合到 order-3。为了缓解噪声影响,可以采取以下步骤:
(1)耗尽 order 0, 1, 2 的 free_list;(采用socket中的 ring_buffer 来堆喷—页风水)
(2)分配大量的 order-2 对象 (假定为N个),这样,order-2 会向 order-3 取页;(分10个进程,每个进程喷200个 4-page 大小的 ring_buffer)
(3)释放第2步中一半的对象,这样,有 N/2 个对象会存入 order-2 的 free_list;
(4)释放第1步所有的对象;
第3步中,释放一半的 order-2 就避免其发生整合而被存入 order-3,这样 order-2 的 free_list 中就有 N/2 个页可以使用了,之后就不会从 order-3 取页或者整合到 order-3 了。避免我们构造连续的 8-page 时受到影响。
3. 漏洞利用
3-1 泄露方法
思路一(失败):利用 msg_msg,覆写 msg_msg->m_ts 构造越界读。但是测试时发现,漏洞的垃圾字节会覆写 msg_msg->next 指针(m_ts 和 next 相邻),导致越界读失败。
思路二:利用 user_key_payload 结构(从 ELOISE 论文中找到)。可以看到,这个结构的 datalen 长度和数据在一起,这样即便垃圾字节会填到末尾,也不会破坏到指针了。
struct user_key_payload {
struct rcu_head rcu; // rcu指针可以被设置为NULL
unsigned short datalen; /* length of this data */
char data[] __aligned(__alignof__(u64)); /* actual data */
};key长度限制:Ubuntu 上默认会限制key的数量和长度。问题是导致溢出的对象位于 8-page,我们在漏洞对象后面也要布置一个 8-page 对象(暂时称为 victim slab),而在Ubuntu上,只有 kmalloc-2k / kmalloc-4k / kmalloc-8k 会从 order-3 取页。所以至少要使key被分配在 kmalloc-2k 上,才能使key位于 8-page 的页中。
$ sudo cat /proc/sys/kernel/keys/maxbytes
20000
$ sudo cat /proc/sys/kernel/keys/maxkeys
200victim个数限制:可以用8个 kmalloc-4k 对象来填充victim slab,采用长度为 2049 的 user_key_payload 即可。这样 user_key_payload 总长度为 2049*8=16392,由于限制最多 20000 字节的key,只剩下 1 个 user_key_payload 可用 — ((20000-16392)/2049 = 1),所以最多可以布置2个 victim slab,条件非常严苛。
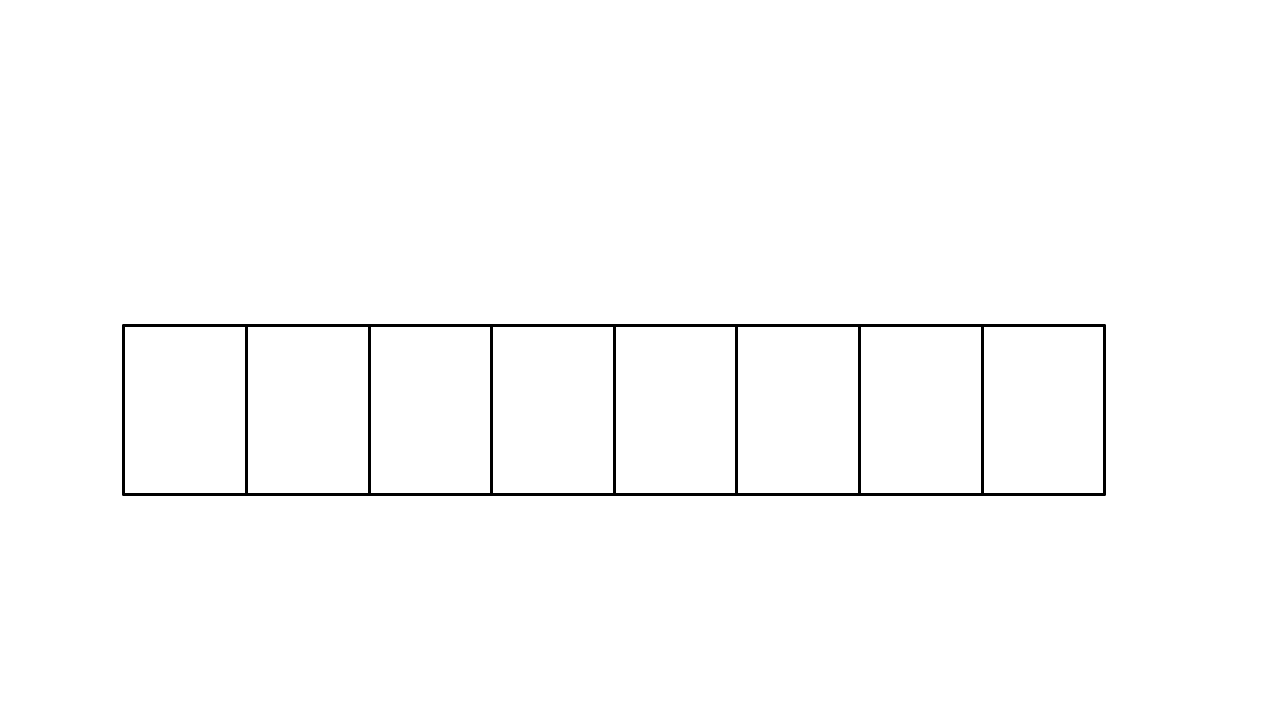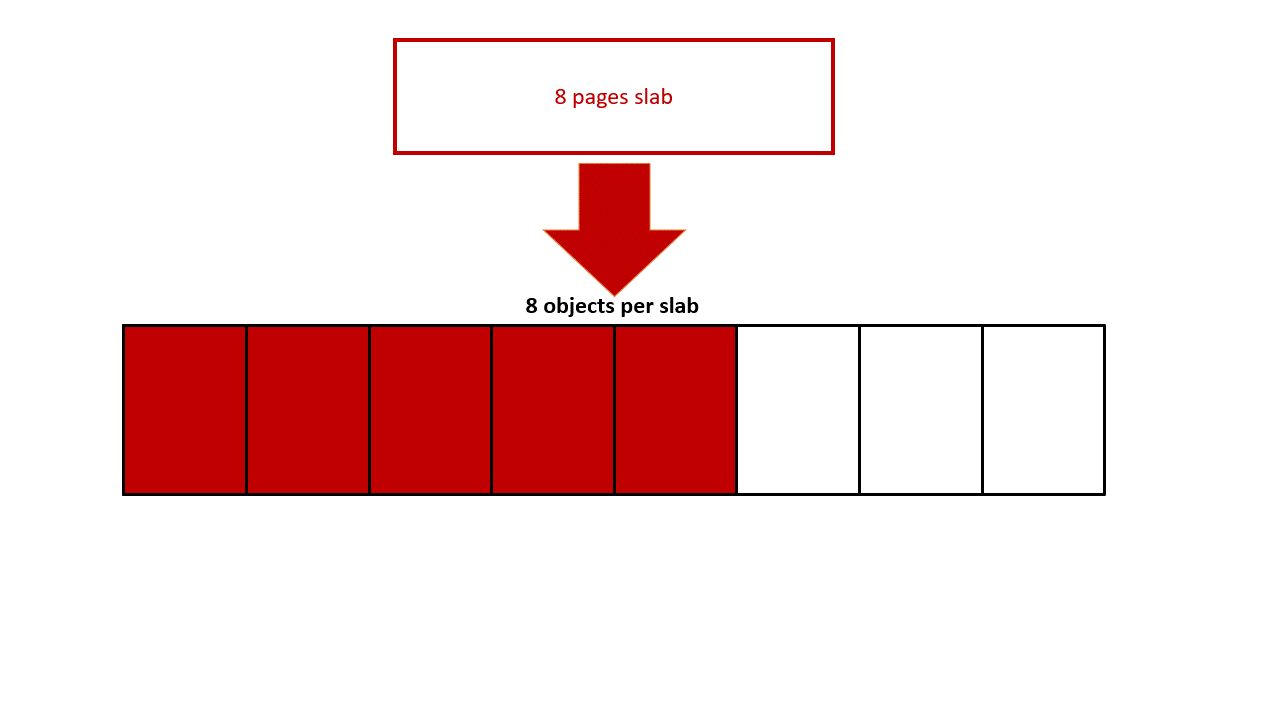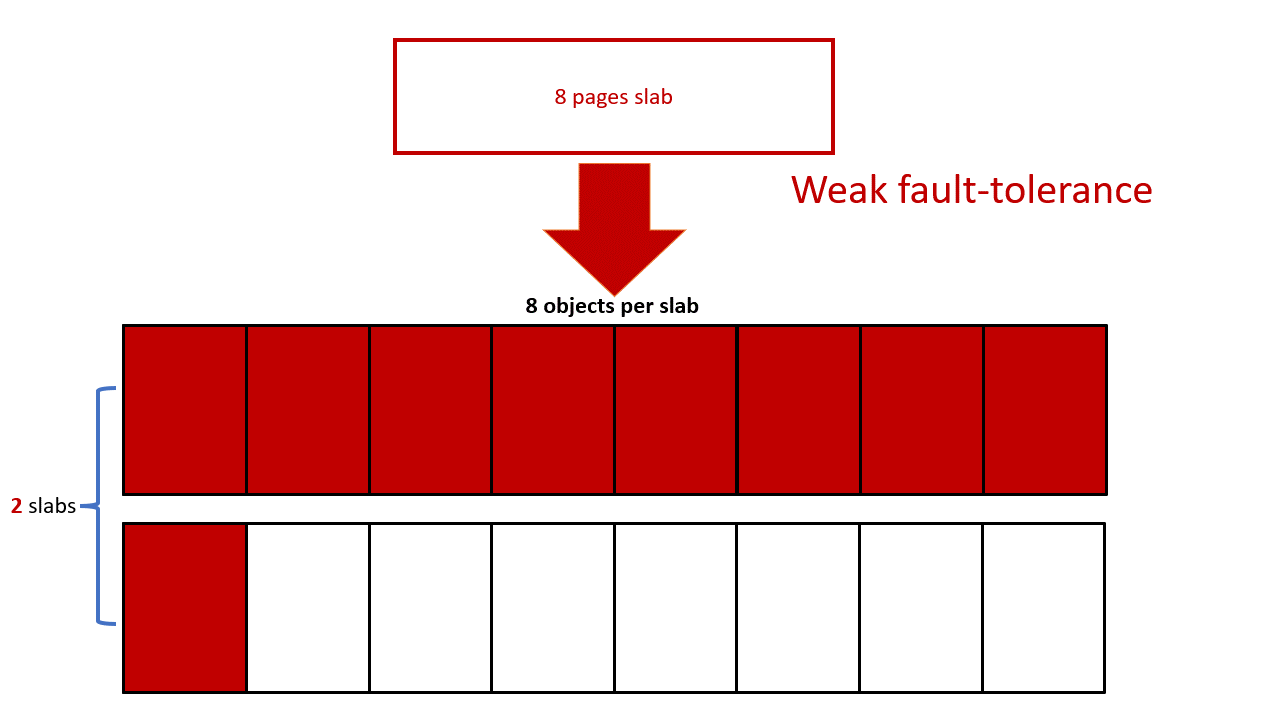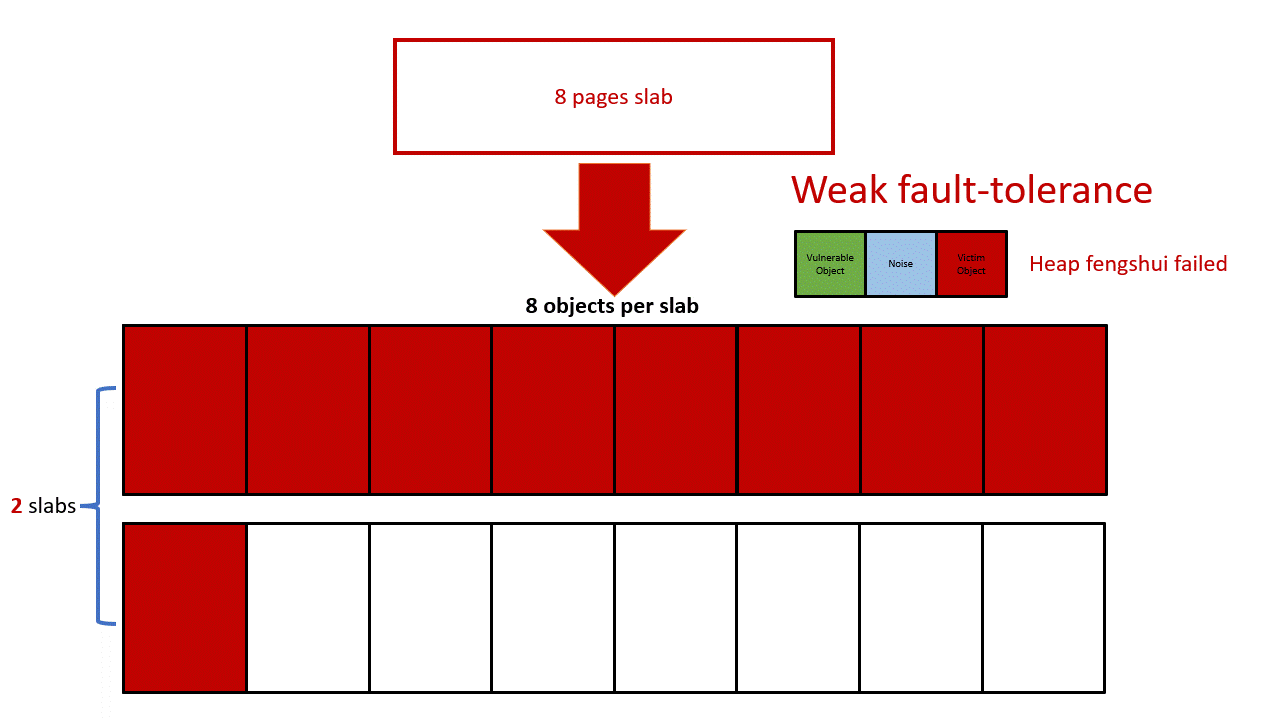
增大victim个数:可以每个 victim slab 放一个 user_key_payload 对象,剩下的空间填充其他对象,user_key_payload 可以在 victim slab 中任意位置,因为本漏洞可以溢出覆盖整个 victim slab。这样,我们就可以喷9个 victim slab 了,增大的泄露的成功几率。

3-2 泄露内核基址
方法:其实本可以直接在 victim slab 后面放一个包含内核指针的对象,但是作者很想尝试 post 中通过篡改 msg_msg->next 进行任意读写的技术。先通过 user_key_payload 越界读来泄露 msg_msg->next 指针,然后伪造 msg_msg->m_ts & msg_msg->next (msg_msg->security 在Ubuntu上没用,可覆盖为0)进行任意读。
泄露msg_msg->next:堆上布局3个相邻的对象—— vul object -> user_key_payload -> msg_msg,注意 msg_msg->next 指向 kmalloc-32,并堆喷大量的 struct seq_operations 对象。触发越界写来篡改 user_key_payload->datalen,通过 user_key_payload 越界读来泄露 msg_msg->next 指针。为了增大成功几率,可以创建9对这种布局(3个相邻对象的堆布局)。
泄露内核基址:堆上布局2个相邻的对象——vul object -> msg_msg,触发越界写来篡改 msg_msg->m_ts & msg_msg->next ,通过 msg_msg 越界读来泄露 struct seq_operations 对象上的函数指针(因为之前泄露的 msg_msg->next 指向 kmalloc-32,而kmalloc-32 上已经喷射了很多 struct seq_operations 对象)。
总体步骤:(1)~(8)泄露 msg_msg->next ,(9)~(12)泄露内核基址。
(1)分配大量8-page 页来耗尽 order-3 的 free_list,这样 order-3 就会从 order-4 取页,保证内存连续性;
(2)分配3个连续的 8-page dumy 对象(占位对象);(占位对象采用 ring_buffer)
(3)释放第2个占位对象,分配1个8-page slab,其中包含1个 user_key_payload 对象和7个其他对象(这7个对象采用多个子线程调用setxattr()来堆喷);
(4)释放第3个占位对象,分配1个8-page slab,填满大小在4056~4072之间的 msg_msg,使得 msg_msgseg 位于 kmalloc-32;
(5)喷射大量的 struct seq_operations,和第4步的 msg_msgseg 位于同一cache;
(6)释放第1个占位对象,分配漏洞对象,触发越界写来修改 user_key_payload->datalen;
(7)如果第(6)步成功,就能通过 user_key_payload 进行越界读;
(8)如果第(7)步成功,就能泄露出 msg_msg->next 指针;
(9)分配2个连续的 8-page dumy 对象(占位对象);
(10)释放第2个占位对象,分配1个8-page slab,填满 msg_msg;
(11)释放第1个占位对象,分配漏洞对象,触发越界写来篡改 msg_msg->m_ts & msg_msg->next ;
(12)如果第(11)步成功,就能越界读来泄露 struct seq_operations 对象上的函数指针。
3-3 提权
任意写:还是利用 msg_msg 来进行任意写。由于普通用户需要 specific capability 才能使用userfaultfd,可以采用 CVE-2022-0185 中的介绍的FUSE方法来进行任意写。通过FUSE可以实现用户空间文件系统,然后映射我们的内存地址,只要有读写访问到该地址就可以调用我们的页错误处理函数,这样可以控制当 msg_msg->next 被篡改之后,再允许 copy_from_user() 继续访问用户空间的数据。

提权:利用任意写来篡改 modprbe_path 提权。后面方法和 CVE-2022-0185 一样。将 modprbe_path 改为 /tmp/get_rooot (运行chmod u+s /bin/bash),这样提权后只要运行 /bin/bash 即可提权。
(1)分配2个连续的 8-page dumy 对象(占位对象);
(2)映射消息内容到FUSE,释放第2个占位对象,分配1个8-page slab,填满 msg_msg,线程会暂停在 copy_from_user();
(3)释放第1个占位对象,分配漏洞对象,触发越界写来篡改 msg_msg->next 为 modprobe_path 地址;
(4)执行一个错误格式的binary 触发 modprobe;
(5)打开 /bin/bash 即可提权。
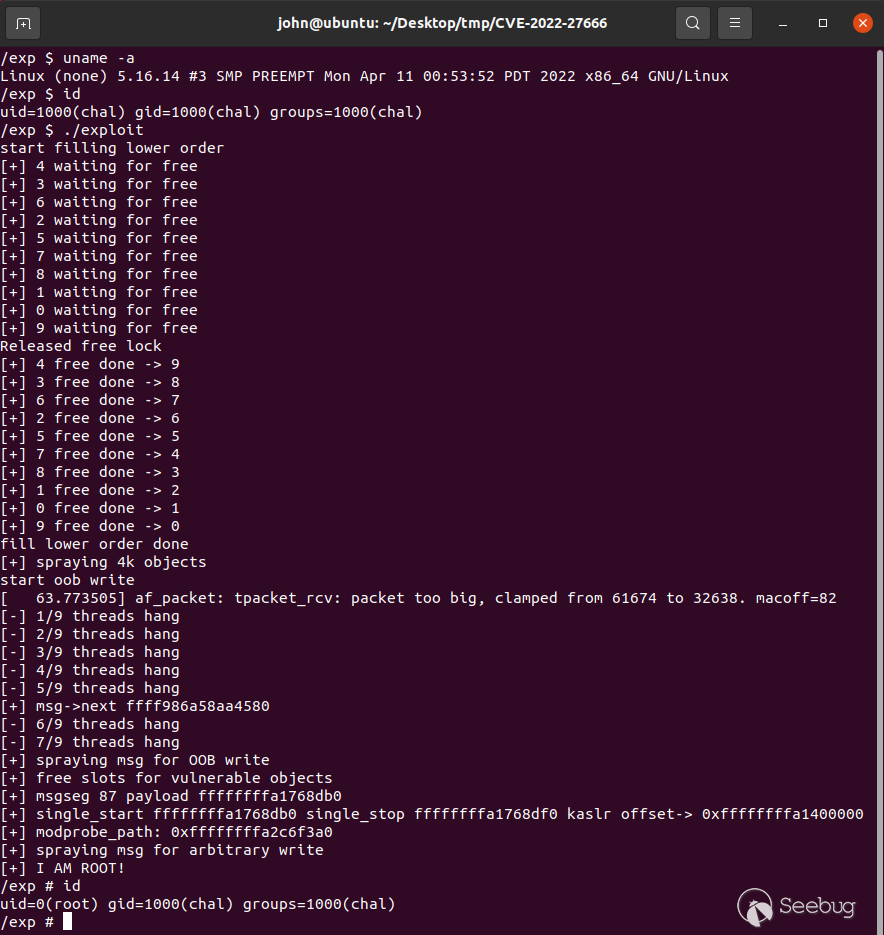
exp说明:
-
原exp中前1271行是设置环境,不重要(作者说,环境设置部分的代码是syzkaller自动生成的,非常复杂;只有利用部分,也即
loop()函数是作者写的,我们需要重点研究该函数),需要用到几个符号:single_start/single_next/single_stop/modprobe_path,在原exploit的111行修改即可。 -
exp中 main 函数设置完环境之后,调用
clone()创建子进程执行loop()函数,loop()函数实现主要利用过程。参见 clone()分析,不同于fork()/vfork(),clone()克隆生成的子进程继续运行时不以调用处为起点,转而去调用以参数func所指定的函数;当函数func返回或者是调用exit()(或者_exit())之后,克隆产生的子进程就会终止,父进程可以通过wait()一类函数来等待克隆子进程;调用者必须分配一块大小适中的内存空间供子进程的栈使用,同时将这块内存的指针置于参数child_stack中。
#define _GNU_SOURCE
#include <sched.h>
int clone(int (*func)(void*),void *child_stack,int flags,void *func_arg,....
/*pid_t *ptid,struct user_desc *tls,pid_t *ctid*/);
Return process ID of child on success,or -1 on error- 页喷射对象:进行页风水和页占位的对象是
ring_buffer,因为其size设置很灵活,适合页喷射。
参考
CVE-2022-27666: Exploit esp6 modules in Linux kernel
[漏洞分析] CVE-2022-27666 IPV6 ESP协议页溢出内核提权
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1889/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1889/
如有侵权请联系:admin#unsafe.sh