Everyone knows about Docker but not a lot of people are aware of the underlying technologies used by it. In this blogpost we will analyze one of the most fundamental and powerful technologies hidden behind Docker - runc.

Picture by Kirill Shirinkin
Brief container history: from a mess to standards and proper architecture
Container technologies appeared for the first time after the invention of cgroups and namespaces. Two of the first-known projects trying to combine them to achieve isolated process environments were LXC and LMCTFY. The latter, in a typical Google style, tried to provide a stable abstraction from the Linux internals via an intuitive API.
In 2013 a technology named Docker, built on top of LXC, was created. The Docker team introduced the notions of container “packaging” (called images) and “portability” of these images between different machines. In other words, Docker tried to create an independent software component following the Unix philosophy (minimalism, modularity, interoperability).
In 2014 a software called libcontainer was created. Its objectives were to create processes into isolated environments and manage their lifecycle. Also in 2014, Kubernetes was announced at DockerCon and that is when a lot of things started to happen in the container world.
The OCI (Open Container Initiative) was then created in response to the need for standardization and structured governance. The OCI project ended up with two specifications - the Runtime Specification (runtime-spec) and the Image Specification (image-spec). The former defined a detailed API for the developers of runtimes to follow. The libcontainer project was donated to OCI and the first standardized runtime following the runtime-spec was created - runc. It represents a fully compatible API on top of libcontainer allowing users to directly spawn and manage containers.
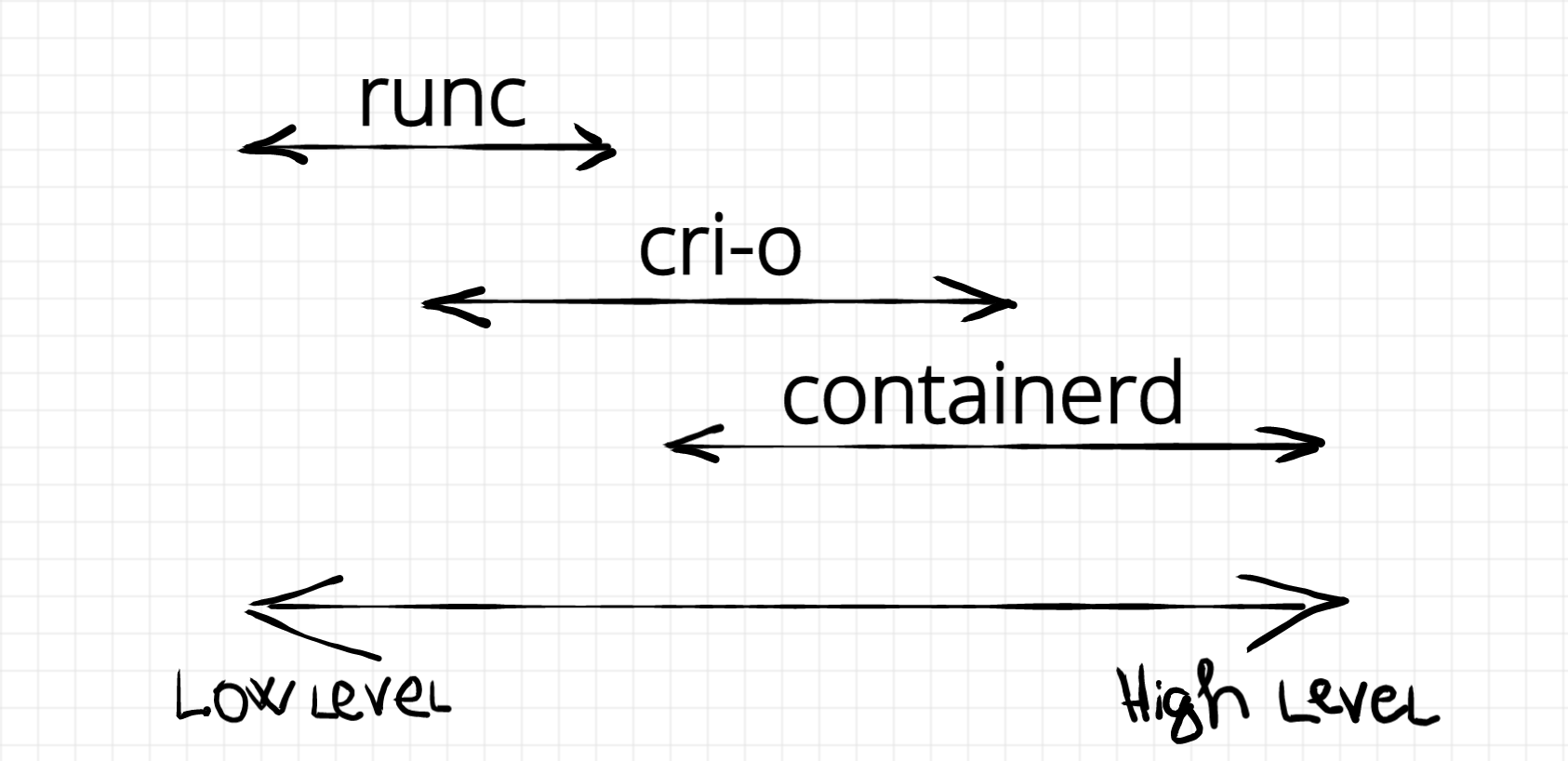
Today container runtimes are often divided into two categories - low-level (runc, gVisor, Firecracker) and high-level (containerd, Docker, CRI-O, podman). The difference is in the amount of consumed OCI specification and additional features.
Runc is a standardized runtime for spawning and running containers on Linux according to the OCI specification. However, it doesn’t follow the image-spec specification of the OCI.
There are other more high-level runtimes, like Docker and Containerd, which implement this specification on top of runc. By doing so, they solve several disadvantages related to the usage of runc alone namely - image integrity, bundle history log and efficient container root file system usage. Be prepared, we are going to look into these more evaluated runtimes in the next article !

Runc
runc - Open Container Initiative runtime runc is a command line client for running applications packaged according to the Open Container Initiative (OCI) format and is a compliant implementation of the Open Container Initiative specification Runc is a so-called “container runtime”.
As mentioned above, runc is an OCI compliant runtime - a software component responsible for the creation, configuration and management of isolated Linux processes also called containers. Formally, runc is a client wrapper around libcontainer. As runc follows the OCI specification for container runtimes it requires two pieces of information:
- OCI configuration - a JSON-like file containing container process information like namespaces, capabilities, environment variables, etc.
- Root filesystem directory - the root file system directory which is going to be used by the container process (chroot).
Let’s now inspect how we can use runc and the above-mentioned specification components.
Generating an OCI configuration
Runc comes out of the box with a feature to generate a default OCI configuration:
[email protected]:~$ runc spec && cat config.json { "ociVersion": "1.0.2-dev", "process": { "terminal": true, "user": { "uid": 0, "gid": 0 }, "args": [ "sh" ], "env": [ "PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin", "TERM=xterm" ], "cwd": "/", "capabilities": { "bounding": [ "CAP_AUDIT_WRITE", "CAP_KILL", "CAP_NET_BIND_SERVICE" ], "effective": [ "CAP_AUDIT_WRITE", "CAP_KILL", "CAP_NET_BIND_SERVICE" ], "inheritable": [ "CAP_AUDIT_WRITE", "CAP_KILL", "CAP_NET_BIND_SERVICE" ], "permitted": [ "CAP_AUDIT_WRITE", "CAP_KILL", "CAP_NET_BIND_SERVICE" ], "ambient": [ "CAP_AUDIT_WRITE", "CAP_KILL", "CAP_NET_BIND_SERVICE" ] }, "rlimits": [ { "type": "RLIMIT_NOFILE", "hard": 1024, "soft": 1024 } ], "noNewPrivileges": true }, "root": { "path": "rootfs", "readonly": true }, "hostname": "runc", "mounts": [ { "destination": "/proc", "type": "proc", "source": "proc" }, { "destination": "/dev", "type": "tmpfs", "source": "tmpfs", "options": [ "nosuid", "strictatime", "mode=755", "size=65536k" ] }, { "destination": "/sys/fs/cgroup", "type": "cgroup", "source": "cgroup", "options": [ "nosuid", "noexec", "nodev", "relatime", "ro" ] } ], "linux": { "resources": { "devices": [ { "allow": false, "access": "rwm" } ] }, "namespaces": [ { "type": "pid" }, { "type": "network" }, { "type": "ipc" }, { "type": "uts" }, { "type": "mount" } ], "maskedPaths": [ "/proc/acpi", "/proc/asound", "/proc/kcore", "/proc/keys", "/proc/latency_stats", "/proc/timer_list", "/proc/timer_stats", "/proc/sched_debug", "/sys/firmware", "/proc/scsi" ], "readonlyPaths": [ "/proc/bus", "/proc/fs", "/proc/irq", "/proc/sys", "/proc/sysrq-trigger" ] } }
From the above code snippet, one can see that the config.json file contains information about:
All of the above configuration is almost completely sufficient for libcontainer to create an isolated Linux process (container). There is one thing missing to spawn a container - the process root directory. Let’s download one and make it available for runc.
# download an alpine fs [email protected]:~$ wget http://dl-cdn.alpinelinux.org/alpine/v3.10/releases/x86_64/alpine-minirootfs-3.10.1-x86_64.tar.gz ... [email protected]:~$ mkdir rootfs && tar -xzf \ alpine-minirootfs-3.10.1-x86_64.tar.gz -C rootfs [email protected]:~$ ls rootfs bin dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var
We have downloaded the root file system of an Alpine Linux image - the missing part of the OCI runtime-spec. Now we can create a container process executing a sh shell.
[email protected]:~$ runc create --help NAME: runc create - create a container ... DESCRIPTION: The create command creates an instance of a container for a bundle. The bundle is a directory with a specification file named "config.json" and a root filesystem.
Okay, let’s put everything together in this bundle and spawn a new baby container! We will distinguish two types of containers: - root - containers running under UID=0. - rootless - containers running under a UID different from 0.
Creating root container
To be able to create a root container (process running under UID=0), one has to change the ownership of the root filesystem which was just downloaded (if the user is not already root).
[email protected]:~$ sudo su - # move the config.json file and the rootfs # to the bundle directory [email protected]:~ # mkdir bundle && mv config.json ./bundle && mv rootfs ./bundle; # change the ownership to root [email protected]:~ #chown -R $(id -u) bundle
Almost everything is ready. We have one last detail to take care of: since we would like to detach our root container from runc and its file descriptors to interact with it, we have to create a TTY socket and connect to it from both sides (from the container side and from our terminal). We are going to use recvtty which is part of the official runc project.
Now we switch to another terminal to create the container via runc.
# in another terminal [email protected]:~$ sudo runc create -b bundle --console-socket $(pwd)/tty.sock container-crypt0n1t3 [email protected]:~$ sudo runc list ID PID STATUS BUNDLE CREATED OWNER container-crypt0n1t3 86087 created ~/bundle 2022-03-15T15:46:41.562034388Z root [email protected]:~$ ps aux | grep 86087 root 86087 0.0 0.0 1086508 11640 pts/0 Ssl+ 16:46 0:00 runc init ...
Our baby container is now created but it is not running the defined sh program as configured in the JSON file. That is because the runc init process is still keeping the process which has to load the sh program in a namespaced (isolated) environment. Let’s inspect what is going on inside runc init.
# inspect namespaces of runc init process [email protected]:~$ sudo ls -al /proc/86087/ns total 0 dr-x--x--x 2 root root 0 mars 15 16:57 . dr-xr-xr-x 9 root root 0 mars 15 16:46 .. lrwxrwxrwx 1 root root 0 mars 15 16:57 cgroup -> 'cgroup:[4026531835]' lrwxrwxrwx 1 root root 0 mars 15 16:57 ipc -> 'ipc:[4026532681]' lrwxrwxrwx 1 root root 0 mars 15 16:57 mnt -> 'mnt:[4026532663]' lrwxrwxrwx 1 root root 0 mars 15 16:57 net -> 'net:[4026532685]' lrwxrwxrwx 1 root root 0 mars 15 16:57 pid -> 'pid:[4026532682]' lrwxrwxrwx 1 root root 0 mars 15 16:57 pid_for_children -> 'pid:[4026532682]' lrwxrwxrwx 1 root root 0 mars 15 16:57 time -> 'time:[4026531834]' lrwxrwxrwx 1 root root 0 mars 15 16:57 time_for_children -> 'time:[4026531834]' lrwxrwxrwx 1 root root 0 mars 15 16:57 user -> 'user:[4026531837]' lrwxrwxrwx 1 root root 0 mars 15 16:57 uts -> 'uts:[4026532676]' # inspect current shell namespaces [email protected]:~$ sudo ls -al /proc/$$/ns total 0 dr-x--x--x 2 cryptonite cryptonite 0 mars 15 16:57 . dr-xr-xr-x 9 cryptonite cryptonite 0 mars 15 16:16 .. lrwxrwxrwx 1 cryptonite cryptonite 0 mars 15 16:57 cgroup -> 'cgroup:[4026531835]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 15 16:57 ipc -> 'ipc:[4026531839]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 15 16:57 mnt -> 'mnt:[4026531840]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 15 16:57 net -> 'net:[4026532008]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 15 16:57 pid -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 15 16:57 pid_for_children -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 15 16:57 time -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 15 16:57 time_for_children -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 15 16:57 user -> 'user:[4026531837]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 15 16:57 uts -> 'uts:[4026531838]
We can confirm that, except for the user and time namespaces, the init runc process is using a different set of namespaces than our regular shell. But why hasn’t it launched our shell process?
Here is the time to say again that runc is a pretty low-level runtime and does not handle a lot of configurations compared to other more high-level runtimes. For example, it doesn’t configure any networking interface for the isolated process. In order to further configure the container process, runc puts it in a containment facility (runc-init) where additional configurations can be added. To illustrate in a more practical way why this containment can be useful, we are going to refer to a previous article and configure the network namespace for our baby container.
Configuring runc-init with network interface
# enter the container network namespace [email protected]:~$ sudo nsenter --target 86087 --net [email protected]:~ # ifconfig -a lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 # no network interface ;(
We see that indeed there are no interfaces in the network namespace of the runc init process, it is cut off from the world. Let’s bring it back!
# create a virtual pair and turn one of the sides on [email protected]:~$ sudo ip link add veth0 type veth peer name ceth0 [email protected]:~$ sudo ip link set veth0 up # assign an IP range [email protected]:~$ sudo ip addr add 172.12.0.11/24 dev veth0 # and put it in the net namespace of runc init [email protected]:~$ sudo ip link set ceth0 netns /proc/86087/ns/net
We can now inspect once again what is going on in the network namespace.
[email protected]:~$ sudo nsenter --target 86087 --net [email protected]:~ # ifconfig -a ceth0: flags=4098<BROADCAST,MULTICAST> mtu 1500 ether 8a:4f:1c:61:74:f4 txqueuelen 1000 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 # and there it is ! # let's configure it to be functional [email protected]:~ # ip link set lo up [email protected]:~ # ip link set ceth0 up [email protected]:~ # ip addr add 172.12.0.12/24 dev ceth0 [email protected]:~ # ping -c 1 172.12.0.11 PING 172.12.0.11 (172.12.0.11) 56(84) bytes of data. 64 bytes from 172.12.0.11: icmp_seq=1 ttl=64 time=0.180 ms --- 172.12.0.11 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.180/0.180/0.180/0.000 ms
Now we have configured a virtual interface and connected the network namespace of the runc init process with the host network namespace. This configuration is not mandatory and the container process executing a sh shell could be started without any connection to the host. However, this configuration can be useful for other processes delivering network functionalities. The sh program is still not running inside the process as desired. After the configuration is done, one can finally spawn the container running the predefined program.
Starting the root container
[email protected]:~$ sudo runc start container-crypt0n1t3 [email protected]:~$ ps aux | grep 86087 root 86087 0.0 0.0 1632 892 pts/0 Ss+ 16:46 0:00 /bin/sh [email protected]:~$ ps aux | grep 86087 sudo runc list ID PID STATUS BUNDLE CREATED OWNER container-crypt0n1t3 86087 running ~/bundle 2022-03-15T15:46:41.562034388Z root
The container is finally running under the same PID but has changed its executable to /bin/sh. Meanwhile, in the terminal holding the recvtty a shell pops out - yay! We can interact with our newly spawned container.
[email protected]:~$ recvtty tty.sock # the shell drops here / # ls ls bin etc lib mnt proc run srv tmp var dev home media opt root sbin sys usr / # ifconfig -a ifconfig -a ceth0 Link encap:Ethernet HWaddr 8A:4F:1C:61:74:F4 inet addr:172.12.0.12 Bcast:0.0.0.0 Mask:255.255.255.0 inet6 addr: fe80::884f:1cff:fe61:74f4/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:43 errors:0 dropped:0 overruns:0 frame:0 TX packets:16 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:6259 (6.1 KiB) TX bytes:1188 (1.1 KiB) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:0 (0.0 B) TX bytes:0 (0.0 B) / # id id uid=0(root) gid=0(root) / # ps aux ps aux PID USER TIME COMMAND 1 root 0:00 /bin/sh 19 root 0:00 ps aux
For those familiar with other container technologies, this terminal is familiar ;). Okay runc is really cool but what more can we do with it? Well, pretty much anything concerning the life management of this container.
Writable storage inside a container
By default when creating a container, runc mounts the root file system as read-only. This is problematic because our process cannot use the file system in which it is “chrooted”.
# in recvtty terminal / # touch hello touch hello touch: hello: Read-only file system / # mount mount /dev/mapper/vgubuntu-root on / type ext4 (ro,relatime,errors=remount-ro) ... # ;((
To change that, one can modify the config.json file.
"root": { "path": "rootfs", "readonly": false },
[email protected]:~$ sudo runc create -b bundle --console-socket $(pwd)/tty.sock wcontainer-crypt0n1t3 [email protected]:~$ sudo runc start wcontainer-crypt0n1t3 # in the recvtty shell / # touch hello touch hello / # ls ls bin etc home media opt rootfs sbin sys usr dev hello lib mnt proc run srv tmp var
This solution is rather too general. It is better from here to define more specific rules for the different subdirectories under the root file system.
Pause and resume a container
# pause and inspect the process state [email protected]:~$ sudo runc pause container-crypt0n1t3 [email protected]:~$ sudo sudo runc list ID PID STATUS BUNDLE CREATED OWNER container-crypt0n1t3 86087 paused ~/bundle 2022-03-15T15:46:41.562034388Z root # investigate the system state of the process [email protected]:~$ ps aux | grep 86087 root 86087 0.0 0.0 1632 892 pts/0 Ds+ 16:46 0:00 /bin/sh
From the above code snippet, one can see that after pausing a container, the system process is put in a state Ds+. This state translates to uninterruptible sleep (state for I/O). In this state the process doesn’t receive almost any of the OS signals and can’t be debugged (ptrace). Let’s resume it and inspect its state again.
One can see that after resuming, the process has changed its state to Ss+ (interruptible sleep). In this state it can again receive signals and be debugged. Let’s investigate deeper how the sleep and resume are done on kernel level.
[email protected]:~$ strace sudo runc pause container-crypt0n1t3 ... rt_sigaction(SIGRTMIN, {sa_handler=0x7f198de71bf0, sa_mask=[], sa_flags=SA_RESTORER|SA_SIGINFO, sa_restorer=0x7f198de7f3c0}, NULL, 8) = 0 rt_sigaction(SIGRT_1, {sa_handler=0x7f198de71c90, sa_mask=[], sa_flags=SA_RESTORER|SA_RESTART|SA_SIGINFO, sa_restorer=0x7f198de7f3c0}, NULL, 8) = 0 rt_sigprocmask(SIG_UNBLOCK, [RTMIN RT_1], NULL, 8) = 0 ... [email protected]:~ strace sudo runc resume container-crypt0n1t3 ... rt_sigaction(SIGRTMIN, {sa_handler=0x7fcb0f28cbf0, sa_mask=[], sa_flags=SA_RESTORER|SA_SIGINFO, sa_restorer=0x7fcb0f29a3c0}, NULL, 8) = 0 rt_sigaction(SIGRT_1, {sa_handler=0x7fcb0f28cc90, sa_mask=[], sa_flags=SA_RESTORER|SA_RESTART|SA_SIGINFO, sa_restorer=0x7fcb0f29a3c0}, NULL, 8) = 0 rt_sigprocmask(SIG_UNBLOCK, [RTMIN RT_1], NULL, 8) = 0 ...
From the above code snippets we can see that the container pause is implemented using Linux signals (SIGRTMIN, SIGRT_1) and predefined handlers.
Inspect the current state of a container
Runc also allows to inspect the state of the running container on the fly. It shows the usage limit of different OS resources (CPU usage per core, RAM pages and page faults, I/O, SWAP, Network card) at the time of execution of the container:
# stopped and deleted old container - started with a new default one [email protected]:~$ sudo runc events container-crypt0n1t3 {"type":"stats","id":"container-crypt0n1t3","data":{"cpu":{"usage":{ "total":22797516,"percpu":[1836602,9757585,1855859,494447,2339327,3934238, 139074,2440384],"percpu_kernel":[0,0,391015,0,0,0,0,0], "percpu_user":[1836602,9757585,1464844,494447,2339327,3934238,139074,2440384], "kernel":0,"user":0},"throttling":{}},"cpuset":{"cpus":[0,1,2,3,4,5,6,7], "cpu_exclusive":0,"mems":[0],"mem_hardwall":0,"mem_exclusive":0, "memory_migrate":0,"memory_spread_page":0,"memory_spread_slab":0, "memory_pressure":0,"sched_load_balance":1,"sched_relax_domain_level":-1}, "memory":{"usage":{"limit":9223372036854771712,"usage":348160,"max":3080192, "failcnt":0},"swap":{"limit":9223372036854771712,"usage":348160,"max":3080192, "failcnt":0},"kernel":{"limit":9223372036854771712,"usage":208896,"max":512000, "failcnt":0},"kernelTCP":{"limit":9223372036854771712,"failcnt":0},"raw": {"active_anon":4096,"active_file":0,"cache":0,"dirty":0, "hierarchical_memory_limit":9223372036854771712,"hierarchical_memsw_limit":9223372036854771712, "inactive_anon":135168,"inactive_file":0,"mapped_file":0, "pgfault":1063,"pgmajfault":0,"pgpgin":657,"pgpgout":623,"rss":139264, "rss_huge":0,"shmem":0,"swap":0, "total_active_anon":4096,"total_active_file":0,"total_cache":0, "total_dirty":0,"total_inactive_anon":135168,"total_inactive_file":0, "total_mapped_file":0,"total_pgfault":1063,"total_pgmajfault":0,"total_pgpgin":657, "total_pgpgout":623,"total_rss":139264,"total_rss_huge":0,"total_shmem":0,"total_swap":0, "total_unevictable":0,"total_writeback":0,"unevictable":0,"writeback":0}}, "pids":{"current":1},"blkio":{},"hugetlb":{"1GB":{"failcnt":0},"2MB":{"failcnt":0}}, "intel_rdt":{},"network_interfaces":null}}
Some of the above limits represent the hard limits imposed by the cgroups Linux feature.
[email protected]:~$ cat /sys/fs/cgroup/memory/user.slice/user-1000.slice/[email protected]/container-crypt0n1t3/memory.limit_in_bytes 9223372036854771712 # same memory limit [email protected]:~$ cat /sys/fs/cgroup/cpuset/container-crypt0n1t3/cpuset.cpus 0-7 # same number of cpus used
This feature gives a really precise idea of what is going on with the process in terms of consumed resources in real time. This log can be really useful for forensics investigation.
By default runc outputs global information about each container upon creation in a file under /var/run/runc/state.json.
Checkpoint a container
Checkpointing is another interesting feature of runc. It allows you to snapshot the current state of a container (in RAM) and save it as a set of files. This state includes open file descriptors, memory content (pages in RAM) registers, mount points, etc. The process can be later resumed from this saved state. This can be really useful when one wants to transport a container from one host to another without losing its internal state (live migration). This feature can also be useful to reverse the process to a stable state (debugging). Runc does the checkpointing with the help of the criu software. However, the latter does not come out of the box with runc and has to be installed separately and added to /usr/local/sbin in order to work properly. To illustrate the checkpointing we are going to stop a printer process and resume it afterwards. The config.json file will contain this:
"args": [ "/bin/sh", "-c", "i=0; while true; do echo $i;i=$(expr $i + 1); sleep 1; done" ],
Here we will demonstrate another way to run a container skipping the configuration phase (runc init). Let’s run it.
[email protected]:~$ sudo runc run -b bundle -d --console-socket $(pwd)/tty.sock container-printer # in the recvtty shell recvtty tty.sock 0 1 2 3 4
Now let’s stop it.
[email protected]:~$ sudo runc checkpoint --image-path $(pwd)/image-checkpoint \ container-printer # inspect what was produced by criu [email protected]:~$ ls image-checkpoint cgroup.img fs-1.img pagemap-176.img tmpfs-dev-73.tar.gz.img core-176.img ids-176.img pagemap-1.img tmpfs-dev-74.tar.gz.img core-1.img ids-1.img pages-1.img tmpfs-dev-75.tar.gz.img descriptors.json inventory.img pages-2.img tmpfs-dev-76.tar.gz.img fdinfo-2.img ipcns-var-10.img pstree.img tmpfs-dev-86.tar.gz.img fdinfo-3.img mm-176.img seccomp.img tty-info.img files.img mm-1.img tmpfs-dev-69.tar.gz.img utsns-11.img fs-176.img mountpoints-12.img tmpfs-dev-71.tar.gz.img
From the above snippet one can see that the checkpointing represents a set of files of the format img (CRIU image file v1.1). The contents of these files are hardly readable and are a mix of binary and test content. Let’s now resume our printer process which at the time of stopping was at 84.
[email protected]:~$ sudo runc restore --detach --image-path $(pwd)/image-checkpoint \ -b bundle --console-socket $(pwd)/tty.sock container-printer-restore
Let’s go back to the recvtty shell.
recvtty tty.sock 85 86 87 88 89 90 91 92
The process resumed at its previous state as if nothing had happened. We have spawned the exact same copy of the container (file descriptors, processes, etc.) but in the previous saved state (the state when the checkpoint was taken).
- Note: There is an interesting option –leave-running which doesn’t stop the process. Also, once a container is stopped it can't be started again.
Executing a new process in an existing container
Runc offers the possibility to execute a new process inside a container. This translates as creating a new process and applying the same set of isolation mechanisms as another process hence putting them in the same “container”.
[email protected]:~$ sudo runc exec container-crypt0n1t3-restore sleep 120 # in a new terminal # by default runc allocates a pseudo tty and connects it with the exec terminal [email protected]:~$ sudo runc list ID PID STATUS BUNDLE CREATED OWNER container-crypt0n1t3 0 stopped ~/bundle 2022-03-16T08:44:37.440444742Z root container-crypt0n1t3-restore 13712 running ~/bundle 2022-03-16T10:24:03.925419212Z root [email protected]:~$ sudo runc ps container-crypt0n1t3-restore UID PID PPID C STIME TTY TIME CMD root 13712 2004 0 11:24 pts/0 00:00:00 /bin/sh root 14405 14393 0 11:36 ? 00:00:00 sleep 120 # the sleep process is part of the crypt0n1t3-container
Let’s see what is going on from the container’s point of view.
/ # ps aux
ps aux
PID USER TIME COMMAND
1 root 0:00 /bin/sh
47 root 0:00 sleep 120
53 root 0:00 ps aux
# the shell process sees the sleep process
# check the new process namespaces
/ # ls /proc/47/ns -al
ls /proc/47/ns -al
total 0
dr-x--x--x 2 root root 0 Mar 16 10:36 .
dr-xr-xr-x 9 root root 0 Mar 16 10:36 ..
lrwxrwxrwx 1 root root 0 Mar 16 10:36 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 Mar 16 10:36 ipc -> ipc:[4026532667]
lrwxrwxrwx 1 root root 0 Mar 16 10:36 mnt -> mnt:[4026532665]
lrwxrwxrwx 1 root root 0 Mar 16 10:36 net -> net:[4026532670]
lrwxrwxrwx 1 root root 0 Mar 16 10:36 pid -> pid:[4026532668]
lrwxrwxrwx 1 root root 0 Mar 16 10:36 pid_for_children -> pid:[4026532668]
lrwxrwxrwx 1 root root 0 Mar 16 10:36 time -> time:[4026531834]
lrwxrwxrwx 1 root root 0 Mar 16 10:36 time_for_children -> time:[4026531834]
lrwxrwxrwx 1 root root 0 Mar 16 10:36 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Mar 16 10:36 uts -> uts:[4026532666]
# check own namespaces
/ # ls /proc/self/ns -al
ls /proc/self/ns -al
total 0
dr-x--x--x 2 root root 0 Mar 16 10:35 .
dr-xr-xr-x 9 root root 0 Mar 16 10:35 ..
lrwxrwxrwx 1 root root 0 Mar 16 10:35 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 Mar 16 10:35 ipc -> ipc:[4026532667]
lrwxrwxrwx 1 root root 0 Mar 16 10:35 mnt -> mnt:[4026532665]
lrwxrwxrwx 1 root root 0 Mar 16 10:35 net -> net:[4026532670]
lrwxrwxrwx 1 root root 0 Mar 16 10:35 pid -> pid:[4026532668]
lrwxrwxrwx 1 root root 0 Mar 16 10:35 pid_for_children -> pid:[4026532668]
lrwxrwxrwx 1 root root 0 Mar 16 10:35 time -> time:[4026531834]
lrwxrwxrwx 1 root root 0 Mar 16 10:35 time_for_children -> time:[4026531834]
lrwxrwxrwx 1 root root 0 Mar 16 10:35 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Mar 16 10:35 uts -> uts:[4026532666]
The new container sleep process has indeed inherited the same namespaces as the shell process already inside the container. The same applies for other things such as capabilities, cwd, etc. These can be changed with the help of runc.
Hooks
Runc allows you to execute commands in an order relative to a container lifecycle. This feature was developed to facilitate the setup and cleaning of a container environment. There exists several types of hooks which we’ll discuss separately.
CreateRuntime
The CreateRuntime hooks are called after the container environment has been created (namespaces, cgroups, capabilities). However, the process executing the hook is not enclosed in this environment hence it has access to all resources in the current context. The process is not chrooted and its current working directory is the bundle directory. The executable path is also resolved in the runtime namespace (runc’s set of namespaces). The CreateRuntime hooks are useful for initial container configuration (eg: configure the network namespace).
CreateContainer
The CreateContainer hooks are called after the CreateRuntime hooks. These hooks are executed in the container namespace (after nsenter) but the executable path is resolved in the runtime namespace. The process has entered the set of namespaces but it is not yet “chrooted”. However, its current working directory is the container rootfs directory.
This functionality of runc can be useful to report to the user the status of the environment configuration.
StartContainer
The StartContainer hooks are called before the user-specified program is executed as part of the start operation. This hook can be used to add additional functionalities relative to the execution context (eg: load an additional library).
The hook executable path is resolved and it is executed in the container namespace.
PostStart
The Poststart hooks are called after the user-specified process is executed but before the start operation returns. For example, this hook can notify the user that the container process is spawned.
The executable path resolves and it is executed in the runtime namespace.
PostStop
The PostStop hooks are called after the container is deleted (or the process exits) but before the delete operation returns. Cleanup or debugging functions are examples of such a hook.
The executable path resolves and it is executed in the runtime namespace.
The syntax for defining hooks in the config.json is the following:
"hooks":{ "createRuntime": [ { "path": "/bin/bash", "args": ["/bin/bash", "-c", "../scripts-hooks/runtimeCreate.sh"] } ], "createContainer": [ { "path": "/bin/bash", "args": ["/bin/bash", "-c", "./home/tmpfssc/containerCreate.sh"] } ], "poststart": [ { "path": "/bin/bash", "args": ["/bin/bash", "-c", "../scripts-hooks/postStart.sh"] } ], "startContainer": [ { "path": "/bin/sh", "args": ["/bin/sh", "-c", "/home/tmpfssc/startContainer.sh"] } ], "poststop": [ { "path": "/bin/bash", "args": ["/bin/bash", "-c", "./scripts-hooks/postStop.sh"] } ] },
A small POC for the purpose of truly understanding this feature was developed. Here are the main elements of it:
- runtimeCreate.sh - initializes the network namespace;
- containerCreate.sh - tests the above configuration;
- postStop.sh - runs an http server on the host after the initialization is completed;
- postStop.sh - cleans up the network namespace and stops the http server.
Each of these scripts output information about their environment.
Information about the defined hooks of a running container can be found under /run/runc/state.json (customizable path with --root flag).
Updating container resource limit
The runtime also allows to modify on the fly the resource limits in terms of cgroups. This can be really useful for scaling and improving performance but also for degradation of performances/denial of service of programs sharing or depending hierarchically on the set of cgroups of a current process. By default runc creates a sub-cgroup of the root one under /sys/fs/cgroup/user.slice/. For this paragraph we are going to run in the container the following program:
"args": [
"/bin/sh", "-c", "i=0; while true; do echo $i;i=$(expr $i + 1); sleep 1; done"
],
[email protected]:~ $runc update --help ... --blkio-weight value Specifies per cgroup weight, range is from 10 to 1000 (default: 0) --cpu-period value CPU CFS period to be used for hardcapping (in usecs). 0 to use system default --cpu-quota value CPU CFS hardcap limit (in usecs). Allowed cpu time in a given period --cpu-share value CPU shares (relative weight vs. other containers) --cpu-rt-period value CPU realtime period to be used for hardcapping (in usecs). 0 to use system default --cpu-rt-runtime value CPU realtime hardcap limit (in usecs). Allowed cpu time in a given period --cpuset-cpus value CPU(s) to use --cpuset-mems value Memory node(s) to use --memory value Memory limit (in bytes) --memory-reservation value Memory reservation or soft_limit (in bytes) --memory-swap value Total memory usage (memory + swap); set '-1' to enable unlimited swap --pids-limit value Maximum number of pids allowed in the container (default: 0) ...
Let’s start a container and update its hardware limitations.
Now we will impose a new limit in terms of RAM consumption. This limit is relative to the cgroup memory group.
# after some adjustments to the process current memory usage # define an upper bound to the RAM usage to 300kB [email protected]:~ $sudo runc update --memory 300000 container-spammer
If we look in our virtual tty, the process suddenly freezes.
Let’s inspect further what happened.
[email protected]:~ $sudo runc list ID PID STATUS BUNDLE CREATED OWNER container-spammer 0 stopped ~/bundle 2022-03-17T10:05:16.623692849Z root # stopped? [email protected]:~ $sudo tail /var/log/kern.log ... Mar 17 11:06:32 qb kernel: [ 3772.833645] oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=container-spammer,mems_allowed=0,oom_memcg=/user.slice/user-1000.slice/[email protected]/container-spammer,task_memcg=/user.slice/user-1000.slice/[email protected]/container-spammer,task=sh,pid=13681,uid=0 Mar 17 11:06:32 qb kernel: [ 3772.833684] Memory cgroup out of memory: Killed process 13681 (sh) total-vm:1624kB, anon-rss:0kB, file-rss:880kB, shmem-rss:0kB, UID:0 pgtables:36kB oom_score_adj:0
By updating the cgroup memory limit of the container we actually forced the Out Of Memory (OOM) killer of the kernel to intervene and kill the container process. An update of the CPU cgroup can also increase or decrease the performance of the container. Cgroups are a swiss army knife but a careful configuration is required.
Creating rootless container
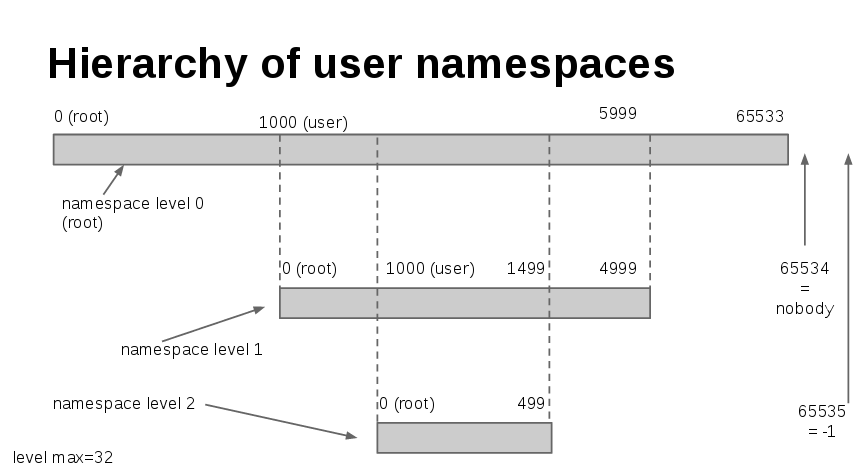
Until now, all the manipulations we demonstrated were on container processes running as root on the host. But what happens if we want to harden the security and run the container processes with a UID different from zero? Separately, we would also like system users without root privileges to be able to run containers in a safe manner. In this article we refer to the term “rootless container” as a container which uses the user namespace. By default runc instantiates the container with the UID of the user triggering the command. The default OCI configuration is also generated without user namespace hence it relates to UID 0 on the host.
[email protected]:~ $runc create -b bundle --console-socket $(pwd)/tty.sock rootless-crypt0n1t3 ERRO[0000] rootless container requires user namespaces
If you go up to the default JSON configuration file you’ll notice that there is no user namespace. If you are familiar with our previous article you will understand what is the problem and how to circumvent it. If you are not, here is a nice graphical representation resuming how user namespace works:
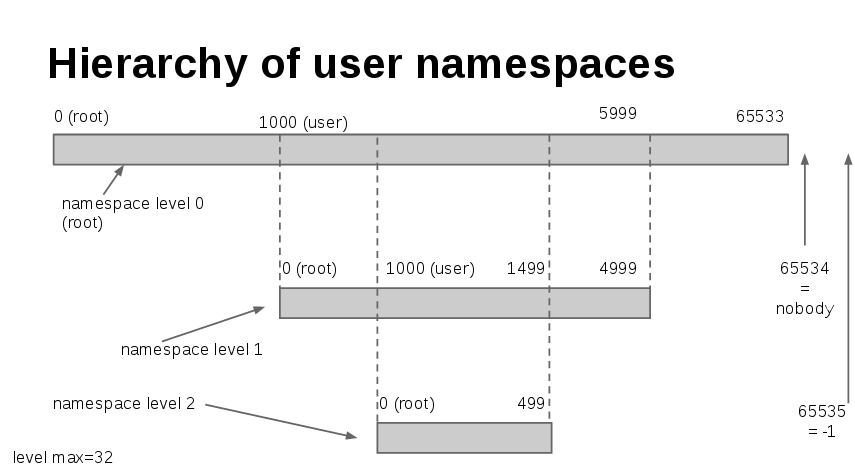
Runc comes with a means to generate rootless configuration files.
[email protected]:~$ runc spec --rootless # inspect what is different with the previous root config [email protected]:~$ diff config.json ./bundle/config.json ... 135,148c135,142 < "uidMappings": [ < { < "containerID": 0, < "hostID": 1000, < "size": 1 < } < ], < "gidMappings": [ < { < "containerID": 0, < "hostID": 1000, < "size": 1 < } < ], ...
We can see that runc added two fields in the file indicating to whom to remap the user of the process inside the container. By default it maps it to the uid of the user running the command. Let’s now create a new container with the new runtime specification.
# first change the ownership of the bundle files [email protected]:~$ sudo chown -R $(id -u) bundle # overwrite the old specification [email protected]:~$ mv config.json bundle/config.json [email protected]:~$ runc create -b bundle --console-socket $(pwd)/tty.sock rootless-crypt0n1t3 # no error - yay; let's run it [email protected]:~$ runc start rootless-crypt0n1t3
Now we can move the recvtty terminal and inspect in detail what runc has created.
/ # id id uid=0(root) gid=0(root) groups=65534(nobody),65534(nobody),65534(nobody),65534(nobody),65534(nobody),65534(nobody),65534(nobody),65534(nobody),65534(nobody),0(root) / # ls -al ls -al total 64 drwx------ 19 root root 4096 Jul 11 2019 . drwx------ 19 root root 4096 Jul 11 2019 .. drwxr-xr-x 2 root root 4096 Jul 11 2019 bin drwxr-xr-x 5 root root 360 Mar 16 11:54 dev drwxr-xr-x 15 root root 4096 Jul 11 2019 etc drwxr-xr-x 2 root root 4096 Jul 11 2019 home drwxr-xr-x 5 root root 4096 Jul 11 2019 lib drwxr-xr-x 5 root root 4096 Jul 11 2019 media drwxr-xr-x 2 root root 4096 Jul 11 2019 mnt drwxr-xr-x 2 root root 4096 Jul 11 2019 opt dr-xr-xr-x 389 nobody nobody 0 Mar 16 11:54 proc drwx------ 2 root root 4096 Mar 16 10:25 root drwxr-xr-x 2 root root 4096 Jul 11 2019 run drwxr-xr-x 2 root root 4096 Jul 11 2019 sbin drwxr-xr-x 2 root root 4096 Jul 11 2019 srv dr-xr-xr-x 13 nobody nobody 0 Mar 16 08:35 sys drwxrwxr-x 2 root root 4096 Jul 11 2019 tmp drwxr-xr-x 7 root root 4096 Jul 11 2019 usr drwxr-xr-x 11 root root 4096 Jul 11 2019 var
This looks really familiar to the user namespace shown in the previous article, right? Let’s check the namespaces and user ids from both “points of view”.
# check within the container / # ls -al /proc/self/ns ls -al /proc/self/ns total 0 dr-x--x--x 2 root root 0 Mar 16 11:59 . dr-xr-xr-x 9 root root 0 Mar 16 11:59 .. lrwxrwxrwx 1 root root 0 Mar 16 11:59 cgroup -> cgroup:[4026531835] lrwxrwxrwx 1 root root 0 Mar 16 11:59 ipc -> ipc:[4026532672] lrwxrwxrwx 1 root root 0 Mar 16 11:59 mnt -> mnt:[4026532669] lrwxrwxrwx 1 root root 0 Mar 16 11:59 net -> net:[4026532008] lrwxrwxrwx 1 root root 0 Mar 16 11:59 pid -> pid:[4026532673] lrwxrwxrwx 1 root root 0 Mar 16 11:59 pid_for_children -> pid:[4026532673] lrwxrwxrwx 1 root root 0 Mar 16 11:59 time -> time:[4026531834] lrwxrwxrwx 1 root root 0 Mar 16 11:59 time_for_children -> time:[4026531834] lrwxrwxrwx 1 root root 0 Mar 16 11:59 user -> user:[4026532663] lrwxrwxrwx 1 root root 0 Mar 16 11:59 uts -> uts:[4026532671] # check from the root user namespace [email protected]:~$ ls /proc/$$/ns -al total 0 dr-x--x--x 2 cryptonite cryptonite 0 mars 16 13:02 . dr-xr-xr-x 9 cryptonite cryptonite 0 mars 16 11:36 .. lrwxrwxrwx 1 cryptonite cryptonite 0 mars 16 13:02 cgroup -> 'cgroup:[4026531835]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 16 13:02 ipc -> 'ipc:[4026531839]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 16 13:02 mnt -> 'mnt:[4026531840]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 16 13:02 net -> 'net:[4026532008]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 16 13:02 pid -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 16 13:02 pid_for_children -> 'pid:[4026531836]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 16 13:02 time -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 16 13:02 time_for_children -> 'time:[4026531834]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 16 13:02 user -> 'user:[4026531837]' lrwxrwxrwx 1 cryptonite cryptonite 0 mars 16 13:02 uts -> 'uts:[4026531838]' # check uid of the process in the container (owner field) [email protected]:~$ runc list ID PID STATUS BUNDLE CREATED OWNER rootless-crypt0n1t3 19104 running /home/cryptonite/docker-security/internals/playground/bundle 2022-03-16T11:54:10.930816557Z cryptonite # double check [email protected]:~$ ps aux | grep 19104 crypton+ 19104 0.0 0.0 1632 1124 ? Ss+ 12:54 0:00 sh
We can see that the classical user namespace definitions apply as expected. If you wish to learn about this interesting namespace, please refer to our previous article. All of the manipulations described in the root containers part apply to the rootless containers. The main and most important difference is that system-wide operations are performed with a non-privileged UID hence less security risk on the host system.
A word on security
Runc is a powerful tool usually used by more high-level runtimes. That is because, by itself, runc is a pretty low-level runtime. It doesn’t include a lot of security enhancement features out of the box like seccomp, SELinux and AppArmor. Nevertheless, the tool has native support for the above security enhancements but they are not included in the default configurations. High-level runtimes running on top of runc handle these types of configuration.
# no AppArmor [email protected]:~$ cat /proc/19104/attr/current unconfined # no Seccomp [email protected]:~$ cat /proc/19104/status | grep Seccomp Seccomp: 0 Seccomp_filters: 0
Greetings
I would like to thank some key members of the team for helping me to structure and write this article (mahé, pappy, sébastien, erynian). I would also like to thank angie and mahé for proofreading, and last but not least, pappy for guiding me and giving me the chance to grow.
References
- A nice runc introductionary video
- The tool that really runs your containers: deep dive into runc and OCI specifications (KIRILL SHIRINKIN)
- Demystifying containers part II: container runtimes (Sascha Grunert)
- Container live migration with CRIU and runc (Adrian Reber)
- Checkpointing and restoring Docker containers with CRIU (Hirokuni Kim)
- A nice post on Linux Control Groups and Process Isolation (Petros Koutoupis)
- Don't Let Linux Control Groups Run Uncontrolled (Zhenyun Zhuang)
- Managing Containers in runc (Andrej Yemelianov)
- Simple rootless containers with runc on CentOS and RedHat (Murat Kilic)
- The original OCI runtime configuration specification