
Loading...


In Cloudflare’s global network, every server runs the whole software stack. Therefore, it's critical that every server performs to its maximum potential capacity. In order to provide us better flexibility from a supply chain perspective, we buy server hardware from multiple vendors with the exact same configuration. However, after the deployment of our Gen X AMD EPYC Zen 2 (Rome) servers, we noticed that servers from one vendor (which we’ll call SKU-B) were consistently performing 5-10% worse than servers from second vendor (which we'll call SKU-A).
The graph below shows the performance discrepancy between the two SKUs in terms of percentage difference. The performance is gauged on the metric of requests per second, and this data is an average of observations captured over 24 hours.
/ Pre-Performance Improvements")
Compute performance via DGEMM
The initial debugging efforts centered around the compute performance. We ran AMD’s DGEMM high performance computing tool to determine if CPU performance was the cause. DGEMM is designed to measure the sustained floating-point computation rate of a single server. Specifically, the code measures the floating point rate of execution of a real matrix–matrix multiplication with double precision. We ran a modified version of DGEMM equipped with specific AMD libraries to support the EPYC processor instruction set.
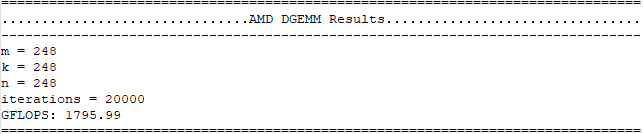
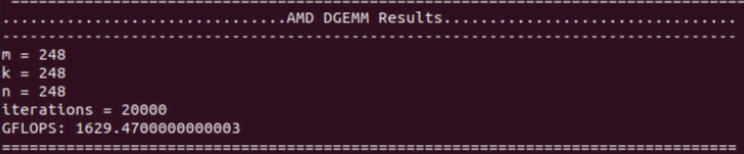
The DGEMM test brought out a few points related to the processor’s Thermal Design Power (TDP). TDP refers to the maximum power that a processor can draw for a thermally significant period while running a software application. The underperforming servers were only drawing 215 to 220 watts of power when fully stressed, whereas the max supported TDP on the processors is 240 watts. Additionally, their floating-point computation rate was ~100 gigaflops (GFLOPS) behind the better performing servers.
Screenshot from the DGEMM run of a good system:
Screenshot from an underperforming system:
To debug the issue, we first tried disabling idle power saving mode (also known as C-states) in the CPU BIOS configuration. The servers reported expected GFLOPS numbers and achieved max TDP. Believing that this could have been the root cause, the servers were moved back into the production test environment for data collection.
However, the performance delta was still there.
Further debugging
We started the debugging process all over again by comparing the BIOS settings logs of both SKU-A and SKU-B. Once this debugging option was exhausted, the focus shifted to the network interface. We ran the open source network interface tool iPerf to check if there were any bottlenecks — no issues were observed either.
During this activity, we noticed that the BIOS of both SKUs were not using the AMD Preferred I/O functionality, which allows devices on a single PCIe bus to obtain improved DMA write performance. We enabled the Preferred I/O option on SKU-B and tested the change in production. Unfortunately, there were no performance gains. After the focus on network activity, the team started looking into memory configuration and operating speed.
AMD HSMP tool & Infinity Fabric diagnosis
The Gen X systems are configured with DDR4 memory modules that can support a maximum of 2933 megatransfers per second (MT/s). With the BIOS configuration for memory clock Frequency set to Auto, the 2933 MT/s automatically configures the memory clock frequency to 1467 MHz. Double Data Rate (DDR) technology allows for the memory signal to be sampled twice per clock cycle: once on the rising edge and once on the falling edge of the clock signal. Because of this, the reported memory speed rate is twice the true memory clock frequency. Memory bandwidth was validated to be working quite well by running a Stream benchmark test.
Running out of debugging options, we reached out to AMD for assistance and were provided a debug tool called HSMP that lets users access the Host System Management Port. This tool provides a wide variety of processor management options, such as reading and changing processor TDP limits, reading processor and memory temperatures, and reading memory and processor clock frequencies. When we ran the HSMP tool, we discovered that the memory was being clocked at a different rate from AMD’s Infinity Fabric system — the architecture which connects the memory to the processor core. As shown below, the memory clock frequency was set to 1467 MHz while the Infinity Fabric clock frequency was set to 1333 MHz.

Ideally, the two clock frequencies need to be equal for optimized workloads sensitive to latency and throughput. Below is a snapshot for an SKU-A server where both memory and Infinity Fabric frequencies are equal.

Improved Performance
Since the Infinity Fabric clock setting was not exposed as a tunable parameter in the BIOS, we asked the vendor to provide a new BIOS that set the frequency to 1467 MHz during compile time. Once we deployed the new BIOS on the underperforming systems in production, we saw that all servers started performing to their expected levels. Below is a snapshot of the same set of systems with data captured and averaged over a 24 hours window on the same day of the week as the previous dataset. Now, the requests per second performance of SKU-B equals and in some cases exceeds the performance of SKU-A!
 / Post-Performance Improvements")
Hello, I am Yasir Jamal. I recently joined Cloudflare as a Hardware Engineer with the goal of helping provide a better Internet to everyone. If you share the same interest, come join us!