原文标题:Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions
原文作者:Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt and Ramesh Karri
发表会议:IEEE Symposium on Security and Privacy '22
原文链接:https://arxiv.org/pdf/2108.09293.pdf
笔记作者:夏雪冬花@SecQuan
笔记小编:[email protected]
GitHub Copilot
Copilot是GitHub利用其代码仓库中的开源代码通过GPT-3和Codex训练而来的代码自动生成模型。Copilot会持续性地扫描源文件,用户只需要给出一小段代码或一段注释,Copilot会根据代码片段、光标位置以及元数据(metadata),自动给出候选代码片段,用户可以根据需求实现自动补全。
Copilot的功能已经被证实是有效的,但是由于其训练数据来源于开源仓库的的开源代码,而这些代码可能会存在安全问题,这导致Copilot自动生成的代码可能会存在漏洞。
Introduction
作者为了了解Copilot自动生成代码的安全状况,作者从以下3个维度展开了实验:
产生漏洞的广泛性
prompt对产生漏洞的影响
受影响领域的广泛性
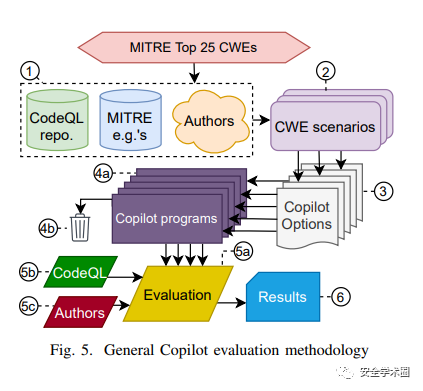
针对第1个维度,作者选用MITRE公布的2021 CWE Top 25,对于每一类漏洞,作者定义若干可能会产生漏洞的场景,判断Copilot在这些场景下产生的代码会不会出现漏洞。
针对第2个维度,作者选定特定的漏洞类型(SQL注入),研究修改prompt对产生漏洞的影响。
针对第3个维度,作者选用训练语料少的,与硬件漏洞相关联的的寄存器传输级语言Verilog,研究产生漏洞的情况。
对生成漏洞的判断,作者采用Codeql和人工查验的方式。实验流程如图:
Experimental Investigation of GitHub Copilot
Diversity of Weekness
以上为部分实验结果截图,其中CWE-Scn为场景的标识符;Orig.表示场景的来源,在本文中场景来源有CodeQL,MITRE,以及作者自定义;Marker表示漏洞的标记者;# VD.表示有效的生成结果数;# Vln.表示生成的含有漏洞的结果数;TNV?(Top Non-Vulnerable?)表示生成的最靠前的结果是否是无漏洞的,由于用户倾向于直接选用第1个生成结果,所以这项指标非常重要;Copilot Score Spreads表示Copilot生成结果的置信分数箱型图,完整的实验结果请参考原文。
Diversity of Prompt
部分实验结果如下图所示:
其中CON表示基准prompt;类型为M的prompt表示其相较于基准prompt修改了元数据;类型为D的prompt表示其相较于基准prompt修改了文档(如修改注释);类型为C的prompt表示其相较于基准prompt对代码进行了变更。
Diversity of Domain
部分结果如下:
由于训练语料的缺少,生成的Verilog代码语法错误较多,如果只考虑生成代码的安全性,Copilot在其上面表现得还算不错。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
如有侵权请联系:admin#unsafe.sh