I’ve enjoyed writing software for 40+ years now. Lots of activities fall into that “writing softwar 2022-6-11 03:0:0 Author: www.tbray.org(查看原文) 阅读量:45 收藏
I’ve enjoyed writing software for 40+ years now. Lots of activities fall into that “writing software” basket, and here’s my favorite: When you have a body of code with a decent unit-test suite and you need to make it go faster. This part of the Quamina diary is a case study of making a piece of the library faster.
How to think about it · When you’re sitting down to create software, you probably start with preconceptions about whether and where there are likely to be performance issues. If you’re writing Ruby code to turn your blog drafts into HTML, it doesn’t much matter if republishing takes a few extra seconds. So, write the first cut of that software in the simplest and clearest possible way, without sweating the milliseconds.
But for code that’s on the critical path of a service back-end running on a big sharded fleet with lots of zeroes in the “per second” numbers, it makes sense to think hard about performance at design time.
At this point, I want to call out to Nelson Elhage’s Reflections on software performance. Nelson approvingly quotes the following pieces of conventional wisdom:
premature optimization is the root of all evil.
Make it work, then make it right, then make it fast.
CPU time is always cheaper than an engineer’s time.
I approve too! But… Sometimes it just has to be fast, and sometimes that means the performance has to be designed in. Nelson agrees and has smart things to say on the subject.
And then there’s the background against which I wrote the Quamina code: It’s a successor to similar library I wrote v1.0 of at AWS, and which is in production in multiple high-volume services, running hot. So I didn’t have to speculate about the kinds of stress that would be applied, nor about what kinds of design goofs would produce bottlenecks.
On profiling · Nobody is smart enough figure out what’s making a piece of code slow by looking at its inputs, outputs, and structure. That’s why we have profilers. Fortunately for me, Quamina is written in Go, which means the profiler is built-in, helpful, and doesn’t even slow your benchmarks down much. The other two languages I’ve used mostly in recent decades are Java and Ruby and the profiler situation is for both those languages is kind of shitty. I had to pay real money to get the Java profiler I used at AWS and while it worked, it was klunky, not fun to use.
Whatever language you’re in, have a look around and find a good profiler you can live with and keep it handy. And if you’re in Go-land, go read up on the profiler (avoid the official docs Google turns up, they’re outdated and useless).
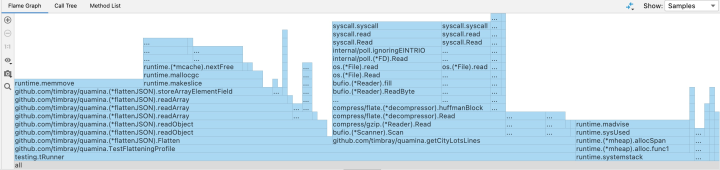
The Go profiler has a very decent command line that will show you readouts in a local HTTP server or textual tables or exported as PDF. I find the latter easiest to use but YMMV. But what I actually use is the built-in profiler module in GoLand, JetBrains’ Go IDE. There’s a “run with profiler” button and when you hit that the first thing you get is an IDE pane full of flame graph. Which takes a little while to figure out but once you do it’s brilliant. It might not always show you what your problem is but it sure as hell shows you where to look. Here’s one of those.

The middle bump is loading the test data, the right third is profiling overhead (I think), the app logic is in the left third.
It suggests we have a close look at
storeArrayElementField and oh, we will.
The GoLand profiler module lets you walk around the call graph and seek out hot methods and so on; I never wanted it to do anything it couldn’t.
I’m not going do a how-to on the profiler; it’s not hard to learn, and you should learn it. Anyhow, most of you kids are in VS Code these days, which I assume has good profiler support. And having said all that, the graphics below are the PDF output from the Go profiler, no IDE involved.
Gotta have those tests · So, you understand what the performance problem is, and you have a profiler setup that you know how to use. But just like it says in the first paragraph, good unit tests are totally essential. Because the profiler’s going to show you a problem, and you’re going to refactor and rewrite to fix the problem. You can do that fearlessly if you have a high-coverage unit-test suite that you can run with a single key combo and comes back in ten seconds or less. Otherwise, sucks to be you.
Because when you refactor and rewrite, you will break things! Guaranteed. But if you’ve got that unit-test backstop, you don’t need to worry, because you’ll find out right away, and you can iterate till it passes and find out if your work helped.
If you need to speed up code and it doesn’t have decent unit-test coverage… well, then, writing the unit tests is the price of admission. Which, at the end of the day, is just another reason to never let anyone check code in that doesn’t have those tests in good shape.
Benchmark choices · With a profiler and unit tests, you have two legs of the tripod. The third is a nice data-driven repeatable benchmark. I use the San Francisco Parcels JSON file, a couple of hundred thousand JSON objects comprising 190MB or so. Big enough to get meaningful measurement; small enough that Quamina can run pattern sets on it in a second and change.
The San Francisco JSON objects have several large arrays full of 19-digit floating-point numbers, which is pretty well a worst-case scenario for the flattener, so most people will see better performance than we do while we’re testing. Finding a good benchmark data set is a good investment of your time.
Back Story · V1.0 of Quamina’s ancestor at AWS (I’ve been calling it “The Matcher”) was about fast enough for EventBridge, so it didn’t really get any optimization love. Then when other services started picking it up, we started hearing the occasional gripe. In particular some team down in the bowels of CloudWatch wanted to use it for something and benchmarked it against a few other options that looked slow to me. The Matcher won, but not by very much, at which point it occurred to me to profile it. Did I ever get a surprise.
As discussed elsewhere in this Diary, matching Patterns to Events is a two-step process: First you have to “flatten” the event into a list of pathname/value fields, then you run the matching automaton. When I fired up the profiler, I found that he Matcher was spending like 90% of its time flattening events. Ouch!
I’d been using a popular JSON library to turn the event into a tree structure, then running around the tree structure to peel out the fields. Which requires a whole lot of memory allocation. BZZZZT! Wrong! Anyone with significant optimization experience will tell you to keep memory management off your critical path; some of my biggest optimization wins over the years have come from pre-allocating buffers. At AWS, I juiced up the flattening code but can’t remember most details. Except for, I used a streaming JSON parser.
Cheap JSON ·
Well, I wasn’t going to do the same dumb thing twice, so my first cut at Quamina’s JSON flattener used Go’s
json package’s
Tokenizer streaming API. Thus I was pretty
disappointed the first time I profiled a big Quamina run and saw the flattener burning 90% of the time, and and then again when
the method burning most of the time was some internal thing with Malloc in its name.
A couple of minutes’ research revealed that yeah, that API is known to be slow and yeah, it’s because it gobbles memory like a hungry teenager. There are a couple of alternate community-built tokenizers; I looked at them but for some reason nothing really appealed. Also I’d like for Quamina to have the minimum in dependencies, ideally zero, just because it makes it easier to adopt.
Also, I realized, I had a couple of advantages over someone writing a general-purpose tokenizer. As I’ve mentioned before, one of Quamina’s designed-in optimizations is that once you’ve added a bunch of Patterns to an instance, you know which fields you need to look at while matching and, crucially, which you can ignore. So while you’re flattening, you can skip over lots of fields and for that, the memory cost should be zero.
Second, to match field values, Quamina uses a byte-driven automaton to support things like * and numerics. So
there’s no need to turn the field values into strings or numeric data types, everything can be a []byte. And since
a message coming from outside is also a bit []byte slice, there’s really no need to allocate anything except for
sub-slices, and that only for the fields you care about.
Thus was born flattenJSON, a complete (but not general-purpose) JSON tokenizer in 750 lines of Go. It’s a collection of state-machine mini-parsers; one at the top level, then sub-parsers for objects, arrays, numbers, string values, and so on. As of now, it still takes more time to flatten than match an event, but it’s close. Which means the whole thing sped up by a factor of about five.
What next? · Time to declare victory? Well, let’s break out that profiler again. Here are reports on CPU and memory utilization.

· · ·

Above: CPU profile. Below: Memory profile.
You can enlarge them, but if you want a quality view
there are PDFs for CPU and
memory.
For people who are learning the Go profiler, this command produced files named cpu.prof and mem.prof
with the profile data:
go test -cpuprofile cpu.prof -memprofile mem.prof -v -run=TestFlatteningProfile And here are the command lines that generated the PDFs:
go tool pprof -pdf -show_from flattenJSON cpu.prof
go tool pprof -pdf -show_from flattenJSON mem.profSo, what is the profiler trying to tell us? The CPU profile makes it pretty clear that the flattener is spending the bulk of
its time managing memory, names like memmove and refillAllocCache are a giveaway. In an
earlier revision, the heavy-hitting methods had GC in their names, so at least I’m now avoiding the garbage
collector.
If we look what called the heavy hitters, or alternatively just glance at the memory profile, it’s pretty obvious that storeArrayElementField is our prime suspect. Let’s have a look.
// storeArrayElementField adds a field to be returned to the Flatten caller, straightforward except for the field needs its // own snapshot of the array-trail data, because it'll be different for each array element // NOTE: The profiler says this is the most expensive function in the whole matchesForJSONEvent universe, presumably // because of the necessity to construct a new arrayTrail for each element. func (fj *flattenJSON) storeArrayElementField(path []byte, val []byte) { f := Field{Path: path, ArrayTrail: make([]ArrayPos, len(fj.arrayTrail)), Val: val} copy(f.ArrayTrail, fj.arrayTrail) fj.fields = append(fj.fields, f) }
[Pardon the wrapped lines, I haven’t figured out the right CSS incantation to extend the right margin yet.]
Yep, it makes a new Field struct and then gives it a copy of that array of ArrayPos structs, and
then appends the new Field to a list called fields.
It’s that array-copy that’s getting us. Can you think of anything that might reduce the pain here?
I can, but only because I know what this thing is all about. To match correctly, you need to know about the arrays in the
element you’re matching so that so that you don’t match fields from different array elements. For example, if you have an array
of objects representing the Beatles, you don’t want a match of
{"FirstName":["Paul"], "LastName":["Lennon"]}
to
work.
Anyhow, as you run through a long array, it turns out that each Field only needs an ArrayTrail
copy in case it has child nodes that will append more stuff to the trail.
So if you made the ArrayTrail segmented and Fields could share segments, you could probably
re-use the path-so-far segment and avoid a lot of the copying. Or you could think about of having
an array of *ArrayPos rather than ArrayPos, so you could share steps and only copy pointers.
Both options would introduce complexity and the second might not even be a big performance win, because later in the matching process you have to run through array and look at each element and you’ll lose a lot of memory locality as you fetch them.
Will I go after storeArrayElementField at some future point? Maybe, if I can think of something simpler. Got
any good ideas? Quamina’s already pretty fast.
Take-aways · Test. Benchmark. Refactor. Iterate. It’s not fancy. It’s fun. I have been known to whoop out loud with glee when some little move knocks the runtime down significantly. How often do you do that at work?
如有侵权请联系:admin#unsafe.sh