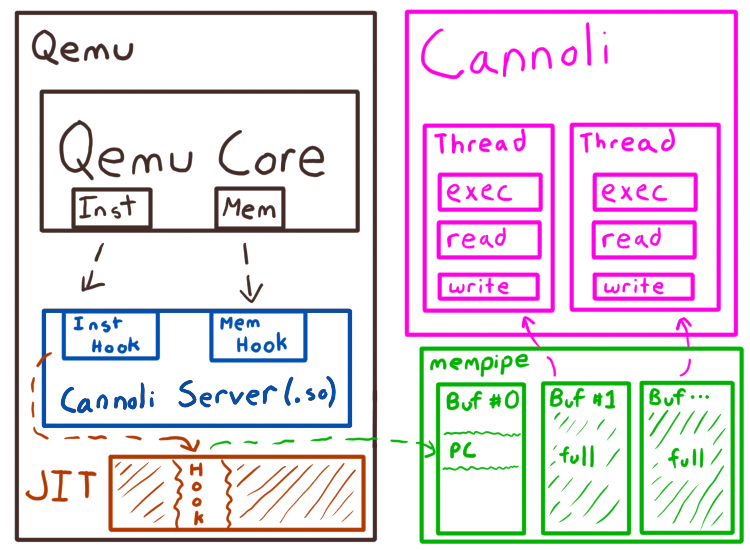
内部机制

Mempipe
Mempipe是一种超高速的IPC机制,它使Cannoli能够第一时间工作。它提供了一个低延迟的API,用于通过Linux上的shm*() API将缓冲区从一个进程传输到另一个进程。具体来说,它是一种基于轮询的IPC机制,这意味着使用者在新数据到达之前对邮箱进行热轮询。
你可以在 mempipe/src/lib.rs 中找到所有代码。其核心有两个结构,一个 SendPipe 和一个 RecvPipe。
Const泛型
SendPipe和RecvPipe都使用两个Const泛型,分别是CHUNK_SIZE和NUM_BUFFERS泛型。CHUNK_SIZE以字节为单位定义每个缓冲区的大小。这个块的大小越小,需要进行的传输就越多,缓存中的数据就越多。这实际上是缓冲区的大小,该缓冲区将被数据填满,填满时会自动刷新。
NUM_BUFFERS泛型指定内存管道中的缓冲区数量。实际上,这就是启用来自 QEMU 的非阻塞数据流的原因。当QEMU向另一个缓冲区生成数据时,用户可以处理一个缓冲区。建议将此值设置为大于1,否则QEMU将在处理缓冲区时阻塞,但不要设置得太高,否则只会增加可能用于流媒体的内存数量,导致更多的缓存不稳定。
这两种泛型都是可调的,会显著影响性能。就我个人而言,我发现将CHUNK_SIZE设置为L1缓存的1/2(在大多数x86系统上是16kib),将NUM_BUFFERS设置为4似乎是一个不错的基准。
管道创建
创建一个 SendPipe 很简单。你调用 SendPipe::create() 并返回一个 SendPipe。在内部,它生成一个随机的 64 位数字,用作管道标识符。然后它以这个管道 ID 作为文件名创建一个共享内存文件,设置共享内存的长度,并将其映射为可读写。我们还在共享内存中放置了一个小的标头文件,这样我们就可以确保当我们连接到管道时,它与我们期望的参数匹配。
打开管道
创建 RecvPipe 也很简单,只需使用分配给 SendPipe 的 UID(可从 SendPipe::uid() 获得)调用 RecvPipe::open()。然后,确保RecvPipe的Const泛型与SendPipe的Const泛型相匹配(包括在共享内存的元数据中),最后,它将映射内存并返回管道。
数据产生
要从SendPipe生成数据,你需要调用SendPipe::alloc_buffer。这给了用户一个只写的ChunkWriter,它可以用ChunkWriter::send来写。调用alloc_buffer会在热循环中阻塞,直到缓冲区可用。重要的是,用户要以尽可能快的速度使用数据,以防止发送方停顿太长时间。使用正确的可调参数,用户应该总是领先于运营程序,因此 alloc_buffer 应该立即有效地返回。
当通过 alloc_buffer 获得缓冲区时,应保证为发送进程所有,因此我们可以安全地可变地写入它。内存是未初始化的,但没关系,因为 ChunkWriter 只提供写入访问,因此读取未初始化的内存是不可能的。
数据处理
在撰写本文时,我对使用数据的最终设计并不满意。首先,你从 RecvPipe::request_ticket 请求一个票据。这有效地让管道知道你对数据感兴趣,并为你获取将要处理的数据的唯一 ID。然后,你调用 RecvPipe::try_recv 来使用票据,并将返回新票据(如果数据已处理)或旧票据(如果 recv 没有任何数据)。 try_recv 是非阻塞的。如果不存在数据,则立即返回。
票据模型有点奇怪,但它允许我们循环分配用户线程到缓冲区。这会在处理线程之间尽可能均匀地分配处理负载。它也很重要,因为它决定了正在处理的数据的顺序,这对于我们有序的跟踪要求很重要。
我想找到对这个API的改进,但我还没有这么做,主要是因为它工作得很好,速度超级快。
QEMU补丁
Cannoli 包含一些 QEMU 的补丁。你可以在文件 qemu_patches.patch 的 repo 中找到这些内容。这些是目前最新的 QEMU eec398119fc6911d99412c37af06a6bc27871f85 的补丁,但是它们被设计为在 QEMU 版本之间可以移动。
这些补丁向QEMU引入了大约200行代码。
QEMU 挂钩
当 -cannoli 命令行参数传入 QEMU 时,它会触发 Cannoli 共享库的 dlopen()。然后它获取 Cannoli 条目点的地址(称为 query_version32 或 query_version64)。 32 位或 64 位后缀不是指共享库本身的位数(目前所有东西都只支持 x86_64 作为主机/JIT 目标),而是指被模拟的目标的位数。所有的挂钩都设计为以不同的方式处理 32 位和 64 位目标,因为这会减小数据流的大小,从而在模拟 32 位目标时最大限度地提高性能。
调用 query_versionX 返回对 Cannoli 结构的引用,该结构定义了 QEMU 将在某些事件上调度的各种回调。
登记预订
因为我们将在几乎每条目标指令上生成数据,所以我们实际上希望在寄存器中存储少量关于跟踪缓冲区和长度的元数据。在内存中执行此操作将非常耗能,因为它将导致对每个目标指令进行多个内存访问。
因此,我们对tcg_target_reg_alloc_order打补丁,以从QEMU寄存器调度器中删除x86_64寄存器r12、r13和r14。这可以防止QEMU在其JIT中使用它们,从而使我们在JIT执行期间独占地控制这些寄存器。这些寄存器是基于SYS-V ABI被调用保存的寄存器。这一点很重要,因为QEMU可以在JIT中调用C函数,我们希望确保在发生这些调用时保留寄存器。
JIT进入和退出
由于我们保留了对一些寄存器的控制权,因此我们需要确保这些寄存器在 QEMU JIT 进入和退出时被正确设置和保存。 JIT 条目和出口是 QEMU 从运行 QEMU C 代码过渡到运行生成的 JIT 代码,再回到退出 QEMU 的边界。这些条目和出口是在 tcg_target_qemu_prologue() 函数中为每个 JIT-target-architecture 定义的。这有效地设置上下文、调用 JIT 并恢复上下文。对于熟悉操作系统开发的人来说,这实际上是一种有效的上下文切换。
我们在这里添加了一些挂钩,允许我们调用 Rust 共享库中的代码。具体来说,就是jit_entry() 和 jit_exit() 函数。这些在 JIT 的上下文中被调用,并提供对 r12、r13 和 r14 寄存器的访问,以便可以在每次 JIT 进入和退出时保存和恢复它们。
在我们的示例中,$entry 函数 (cannoli/cannoli_server/src/cannoli_internals.rs) 从 mempipe中分配一个缓冲区,在 r12 中设置一个指向它的指针,在 r13 中设置一个指向它末尾的指针,然后返回。这将通过执行JIT建立r12和r13的状态。
$exit函数决定JIT产生的字节数(由r12中的当前指针表示,它已经是高级了),并通过IPC将数据发送给用户。
加载和存储
对于加载和存储,我们钩住了tcg_out_qemu_ld()和tcg_out_qemu_st()。这些函数是特定于x86_64- jit目标的函数,它们为到来宾地址空间的内存操作提供了捕获所有接收器(catch-all sink),用于各自的加载和存储。
指令执行
对于指令执行,我们挂钩 tcg_gen_code(),特别是 INDEX_op_insnstart() QEMU TCG 指令,它表示指令开始执行的地址。
JIT shellcode 注入
内存和指令挂钩都做同样的事情。它们在Rust代码中调用一个回调函数,该回调函数被传递给qemu提供的缓冲区和长度。然后,此回调可以使用直接发送到 JIT 流中的 shellcode 填充 QEMU 提供的缓冲区。这为我们的 Rust 库提供了将任意代码注入 JIT 流的能力。如果你是高级用户,则可以通过为不同的指令提供不同的挂钩来做一些非常酷的事情。
Cannoli服务器
Cannoli 服务器(通过挂钩加载到 QEMU 中)已经预定义了一些挂钩。这些是指令和内存操作挂钩。
Cannoli 的整个流程(在其默认配置中)是在 JIT 条目分配一个 IPC 缓冲区,在 JIT 期间填充它,如果它填满了就刷新它,在JIT退出时也刷新它。
默认的指令和内存挂钩执行最少的组装,以确保跟踪缓冲区中有足够的空间,刷新它(通过回调到Rust,如果它是满的,它可以在这里调用Rust,因为这些事件“很少”发生,例如。每几千条目标指令),最后将内存或指令执行指令以相对简单的格式存储到跟踪中。
Cannoli 服务器共享对象包含所有挂钩和代码的两个副本,这样同一个共享对象就可以同时用于32位和64位目标,而无需重新编译!
这些挂钩直接写入 mempipe 提供的缓冲区,就这么简单!任何更复杂的内容都将严重损害性能!
Cannoli
最后,Cannoli 本身就是一个用户库。由于我们每秒可能处理数十亿条指令,所以我们将所有Cannoli设计成使用线程。这允许你在多个线程上执行相对复杂的跟踪使用和处理,同时不会影响QEMU单线程任务。
这很简单。 Cannoli 创建请求的线程数,并在那些等待数据的线程上旋转。使用 mempipe 票据系统,每个线程都要排队等待数据进入。当缓冲区出现他们的票号时,该线程处理来自 QEMU 的数据。
由于并行处理意味着跟踪不再是有序的,我们允许用户为每个事件返回他们自己的结构,然后在排序后将其返回给他们。这允许用户进行线程处理,直到他们需要排序。
总结
尽可能快地将数据从一个进程传输到另一个进程是一个非常困难的问题。关于处理器的详细信息,如缓存一致性,对于获得高吞吐量至关重要,特别是在希望尽可能防止生成线程阻塞时。
本文翻译自:https://margin.re/blog/cannoli-the-fast-qemu-tracer.aspx如若转载,请注明原文地址
如有侵权请联系:admin#unsafe.sh