作者:腾讯星辰算力团队
1. 背景
1.1. 问题源起
近年来,随着腾讯内部自研上云项目的不断发展,越来越多的业务开始使用云原生方式托管自己的工作负载,容器平台的规模因此不断增大。以 Kubernetes 为底座的云原生技术极大推动了云原生领域的发展,已然成为各大容器平台事实上的技术标准。在云原生场景下,为了最大化实现资源共享,单台宿主机往往会运行多个不同用户的计算任务。如果在宿主机内没有进行精细化的资源隔离,在业务负载高峰时间段,多个容器往往会对资源产生激烈的竞争,可能导致程序性能的急剧下降,主要体现为:
资源调度时频繁的上下文切换时间 频繁的进程切换导致的 CPU 高速缓存失效
因此,在云原生场景下需要针对容器资源分配加以精细化的限制,确保在 CPU 利用率较高时,各容器之间不会产生激烈竞争从而引起性能下降。
1.2. 调度场景
腾讯星辰算力平台承载了全公司的 CPU 和 GPU 算力服务,拥有着海量多类型的计算资源。当前,平台承载的多数重点服务偏离线场景,在业务日益增长的算力需求下,提供源源不断的低成本资源,持续提升可用性、服务质量、调度能力,覆盖更多的业务场景。然而,Kubernetes 原生的调度与资源绑定功能已经无法满足复杂的算力场景,亟需对资源进行更加精细化的调度,主要体现为:
Kubernetes 原生调度器无法感知节点资源拓扑信息导致 Pod 生产失败
kube-scheduler 在调度过程中并不感知节点的资源拓扑,当 kube-scheduler 将 Pod 调度到某个节点后,kubelet 如果发现节点的资源拓扑亲和性要求无法满足时,会拒绝生产该 Pod,当通过外部控制环(如 deployment)来部署 Pod 时,则会导致 Pod 被反复创建-->调度-->生产失败的死循环。
基于离线虚拟机的混部方案导致的节点实际可用 CPU 核心数变化
面对运行在线业务的云主机平均利用率较低的现实,为充分利用空闲资源,可将离线虚拟机和在线虚拟机混合部署,解决公司离线计算需求,提升自研上云资源平均利用率。在保证离线不干扰在线业务的情况下,腾讯星辰算力基于自研内核调度器 VMF 的支持,可以将一台机器上的闲时资源充分利用起来,生产低优先级的离线虚拟机。由于 VMF 的不公平调度策略,离线虚拟机的实际可用核心数受到在线虚拟机的影响,随着在线业务的繁忙程度不断变化。因此,kubelet 通过 cadvisor 在离线宿主机内部采集到的 CPU 核心数并不准确,导致了调度信息出现偏差。
资源的高效利用需要更加精细化的调度粒度
kube-scheduler 的职责是为 Pod 选择一个合适的 Node 完成一次调度。然而,想对资源进行更高效的利用,原生调度器的功能还远远不够。在调度时,我们希望调度器能够进行更细粒度的调度,比如能够感知到 CPU 核心、GPU 拓扑、网络拓扑等等,使得资源利用方式更加合理。
2. 预备知识
2.1. cgroups 之 cpuset 子系统
cgroups 是 Linux 内核提供的一种可以限制单个进程或者多个进程所使用资源的机制,可以对 CPU、内存等资源实现精细化的控制。Linux 下的容器技术主要通过 cgroups 来实现资源控制。
在 cgroups 中,cpuset 子系统可以为 cgroups 中的进程分配独立的 CPU 和内存节点。通过将 CPU 核心编号写入 cpuset 子系统中的 cpuset.cpus文件中或将内存 NUMA 编号写入 cpuset.mems文件中,可以限制一个或一组进程只使用特定的 CPU 或者内存。
幸运的是,在容器的资源限制中,我们不需要手动操作 cpuset 子系统。通过连接容器运行时(CRI)提供的接口,可以直接更新容器的资源限制。
// ContainerManager contains methods to manipulate containers managed by a
// container runtime. The methods are thread-safe.
type ContainerManager interface {
// ......
// UpdateContainerResources updates the cgroup resources for the container.
UpdateContainerResources(containerID string, resources *runtimeapi.LinuxContainerResources) error
// ......
}
2.2. NUMA 架构
非统一内存访问架构(英语:Non-uniform memory access,简称 NUMA)是一种为多处理器的电脑设计的内存架构,内存访问时间取决于内存相对于处理器的位置。在 NUMA 下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。现代多核服务器大多采用 NUMA 架构来提高硬件的可伸缩性。
从图中可以看出,每个 NUMA Node 有独立的 CPU 核心、L3 cache 和内存,NUMA Node 之间相互连接。相同 NUMA Node 上的 CPU 可以共享 L3 cache,同时访问本 NUMA Node 上的内存速度更快,跨 NUMA Node 访问内存会更慢。因此,我们应当为 CPU 密集型应用分配同一个 NUMA Node 的 CPU 核心,确保程序的局部性能得到充分满足。
2.3. Kubernetes 调度框架
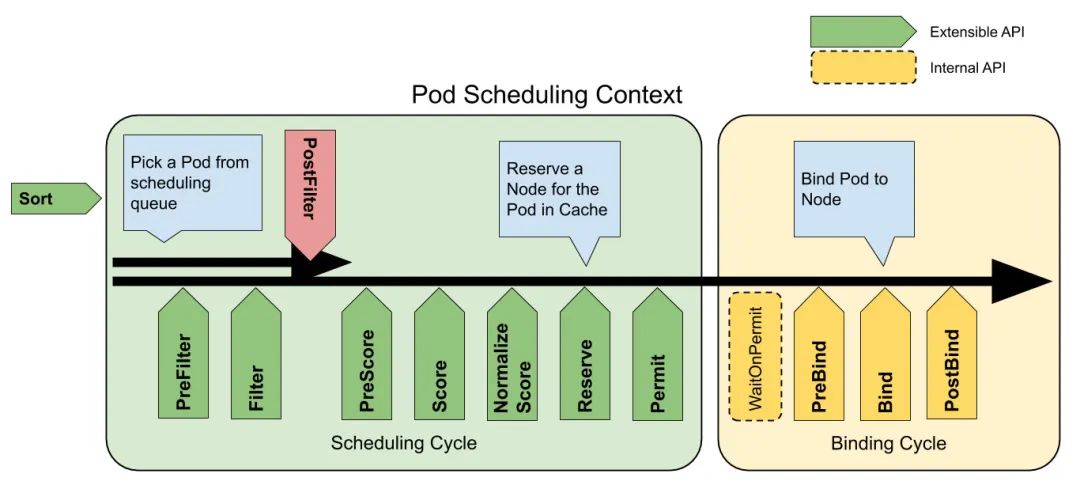
Kubernetes 自 v1.19 开始正式稳定支持调度框架,调度框架是面向 Kubernetes 调度器的一种插件架构,它为现有的调度器添加了一组新的“插件”API,插件会被编译到调度器之中。这为我们自定义调度器带来了福音。我们可以无需修改 kube-scheduler 的源代码,通过实现不同的调度插件,将插件代码与 kube-scheduler 编译为同一个可执行文件中,从而开发出自定义的扩展调度器。这样的灵活性扩展方便我们开发与配置各类调度器插件,同时无需修改 kube-scheduler 的源代码的方式使得扩展调度器可以快速更改依赖,更新到最新的社区版本。
调度器的主要扩展点如上图所示。我们扩展的调度器主要关心以下几个步骤:
PreFilter和Filter
这两个插件用于过滤出不能运行该 Pod 的节点,如果任何 Filter 插件将节点标记为不可行,该节点都不会进入候选集合,继续后面的调度流程。
PreScore、Score和NormalizeScore
这三个插件用于对通过过滤阶段的节点进行排序,调度器将为每个节点调用每个评分插件,最终评分最高的节点将会作为最终调度结果被选中。
Reserve和Unreserve
这个插件用于在 Pod 真正被绑定到节点之前,对资源做一些预留工作,保证调度的一致性。如果绑定失败则通过 Unreserve 来释放预留的资源。
Bind
这个插件用于将 Pod 绑定到节点上。默认的绑定插件只是为节点指定 spec.nodeName来完成调度,如果我们需要扩展调度器,加上其他的调度结果信息,就需要禁用默认 Bind 插件,替换为自定义的 Bind 插件。
3. 国内外技术研究现状
目前 Kubernetes 社区、Volcano 开源社区均有关于拓扑感知相关的解决方案,各方案有部分相同之处,但各自都有局限性,无法满足星辰算力的复杂场景。
3.1. Kubernetes 社区
Kubernetes 社区 scheduling 兴趣小组针对拓扑感知调度也有过一套解决方案,这个方案主要是由 RedHat 来主导,通过scheduler-plugins和node-feature-discovery配合实现了考虑节点拓扑的调度方法。社区的方法仅仅考虑节点是否能够在满足 kubelet 配置要求的情况下,完成调度节点筛选和打分,并不会执行绑核,绑核操作仍然交给 kubelet 来完成,相关提案在这里。具体实现方案如下:
节点上的 nfd-topology-updater 通过 gRPC 上报节点拓扑到 nfd-master 中(周期 60s)。 nfd-master 更新节点拓扑与分配情况到 CR 中( NodeResourceTopology)。扩展 kube-scheduler,进行调度时考虑 NodeTopology。 节点 kubelet 完成绑核工作。
该方案存在较多的问题,不能解决生产实践中的需求:
具体核心分配依赖 kubelet 完成,因此调度器只会考虑资源拓扑信息,并不会选择拓扑,调度器没有资源预留。这导致了节点调度与拓扑调度不在同一个环节,会引起数据不一致问题。 由于具体核心分配依赖 kubelet 完成,所以已调度 Pod 的拓扑信息需要依靠 nfd-worker 每隔 60s 汇报一次,导致拓扑发现过慢因此使得数据不一致问题更加严重,参见这里。 没有区分需要拓扑亲和的 pod 和普通的 pod,容易造成开启拓扑功能的节点高优资源浪费。
3.2. Volcano 社区
Volcano 是在 Kubernetes 上运行高性能工作负载的容器批量计算引擎,隶属于 CNCF 孵化项目。在 v1.4.0-Beta 版本中进行了增强,发布了有关 NUMA 感知的特性。与 Kubernetes 社区 scheduling 兴趣小组的实现方式类似,真正的绑核并未单独实现,直接采用的是 kubelet 自带的功能。具体实现方案如下:
resource-exporter 是部署在每个节点上的 DaemonSet,负责节点的拓扑信息采集,并将节点信息写入 CR 中( Numatopology)。Volcano 根据节点的 Numatopology,在调度 Pod 时进行 NUMA 调度感知。节点 kubelet 完成绑核工作。
该方案存在的问题基本与 Kubernetes 社区 scheduling 兴趣小组的实现方式类似,具体核心分配依赖 kubelet 完成。虽然调度器尽力保持与 kubelet 一致,但因为无法做资源预留,仍然会出现不一致的问题,在高并发场景下尤其明显。
3.3. 小结
基于国内外研究现状的结果进行分析,开源社区在节点资源绑定方面还是希望交给 kubelet,调度器尽量保证与 kubelet 的一致,可以理解这比较符合社区的方向。因此,目前各个方案的典型实现都不完美,无法满足腾讯星辰算力的要求,在复杂的生产环境中我们需要一套更加稳健、扩展性更好的方案。因此,我们决定从各个方案的架构优点出发,探索出一套更加强大的、贴合腾讯星辰算力实际场景的资源精细化调度增强方案。
4. 问题分析
4.1. 离线虚拟机节点实际可用 CPU 核心数变化
从 1.2 节中我们可以知道,腾讯星辰算力使用了基于离线虚拟机的混部方案,节点实际的 CPU 可用核心数会收到在线业务的峰值影响从而变化。因此,kubelet 通过 cadvisor 在离线宿主机内部采集到的 CPU 核心数并不准确,这个数值是一个固定值。因此,针对离线资源我们需要调度器通过其他的方式来获取节点的实际算力。
目前调度和绑核都不能到离线虚拟机的实际算力,导致任务绑定到在线干扰比较严重的 NUMA node,资源竞争非常严重使得任务的性能下降。
幸运的是,我们在物理机上可以采集到离线虚拟机每个 NUMA node 上实际可用的 CPU 资源比例,通过折损公式计算出离线虚拟机的实际算力。接下来就只需要让调度器在调度时能够感知到 CPU 拓扑以及实际算力,从而进行分配。
4.2. 精细化调度需要更强的灵活性
通过 kubelet 自带的 cpumanager进行绑核总是会对该节点上的所有 Pod 均生效。只要 Pod 满足 Guaranteed 的 QoS 条件,且 CPU 请求值为整数,都会进行绑核。然而,有些 Pod 并不是高负载类型却独占 CPU,这种方式的方式很容易造成开启拓扑功能的节点高优资源浪费。
同时,对于不同资源类型的节点,其拓扑感知的要求也是不一样的。例如,星辰算力的资源池中也含有较多碎片虚拟机,这部分节点不是混部方式生产出来的,相比而言资源稳定,但是规格很小(如 8 核 CVM,每个 NUMA Node 有 4 核)。由于大多数任务规格都会超过 4 核,这类资源就在使用过程中就可以跨 NUMA Node 进行分配,否则很难匹配。
因此,拓扑感知调度需要更强的灵活性,适应各种核心分配与拓扑感知场景。
4.3. 调度方案需要更强的扩展性
调度器在抽象拓扑资源时,需要考虑扩展性。对于今后可能会需要调度的扩展资源,如各类异构资源的调度,也能够在这套方案中轻松使用,而不仅仅是 cgroups 子系统中含有的资源。
4.4. 避免超线程带来的 CPU 竞争问题
在 CPU 核心竞争较为激烈时,超线程可能会带来更差的性能。更加理想的分配方式是将一个逻辑核分配给高负载应用,另一个逻辑核分配给不繁忙的应用,或者是将两个峰谷时刻相反的应用分配到同一个物理核心上。同时,我们避免将同一个应用分配到同一个物理核心的两个逻辑核心上,这样很可能造成 CPU 竞争问题。
5. 解决方案
为了充分解决上述问题,并考虑到未来的扩展性,我们设计了一套精细化调度的方案,命名为 cassini。整套解决方案包含三个组件和一个 CRD,共同配合完成资源精细化调度的工作。
注:cassini这个名称来源于知名的土星探测器卡西尼-惠更斯号,对土星进行了精准无误的探测,借此名来象征更加精准的拓扑发现与调度。
5.1. 总体架构
各模块职责如下:
cassini-worker:负责收集节点资源拓扑、执行资源绑定工作,作为 DaemonSet 在每个节点上运行。cassini-master:从外部系统负责收集节点特性(如节点的offline_capacity,节点电力情况),作为 controller 采用 Deployment 方式运行。scheduler-plugins:新增调度插件的扩展调度器替换原生调度器,在节点绑定的同时还会分配拓扑调度结果,作为静态 Pod 在每个 master 节点上运行。
调度整体流程如下:
cassini-worker启动,收集节点上的拓扑资源信息。创建或更新 NodeResourceTopology(NRT)类型的 CR 资源,用于记录节点拓扑信息。 读取 kubelet 的 cpu_manager_state文件,将已有容器的 kubelet 绑核结果 patch 到 Pod annotations 中。cassini-master根据外部系统获取到的信息来更新对应节点的 NRT 对象。扩展调度器 scheduler-plugins执行 Pod 调度,根据 NRT 对象感知到节点的拓扑信息,调度 Pod 时将拓扑调度结构写到 Pod annotations 中。节点 kubelet 监听并准备启动 Pod。 节点 kubelet 调用容器运行时接口启动容器。 cassini-worker周期性地访问 kubelet 的 10250 端口来 List 节点上的 Pod 并从 Pod annotations 中获取调度器的拓扑调度结果。cassini-worker调用容器运行时接口来更改容器的绑核结果。
整体可以看出,cassini-worker在节点上收集更详细的资源拓扑信息,cassini-master从外部系统集中获取节点资源的附加信息。scheduler-plugins扩展了原生调度器,以这些附加信息作为决策依据来进行更加精细化的调度,并将结果写到 Pod annotations 中。最终,cassini-worker又承担了执行者的职责,负责落实调度器的资源拓扑调度结果。
5.2. API 设计
NodeResourceTopology(NRT)是用于抽象化描述节点资源拓扑信息的 Kubernetes CRD,这里主要参考了 Kubernetes 社区 scheduling 兴趣小组的设计。每一个 Zone 用于描述一个抽象的拓扑区域,ZoneType来描述其类型,ResourceInfo来描述 Zone 内的资源总量。
// Zone represents a resource topology zone, e.g. socket, node, die or core.
type Zone struct {
// Name represents the zone name.
// +required
Name string `json:"name" protobuf:"bytes,1,opt,name=name"` // Type represents the zone type.
// +kubebuilder:validation:Enum=Node;Socket;Core
// +required
Type ZoneType `json:"type" protobuf:"bytes,2,opt,name=type"`
// Parent represents the name of parent zone.
// +optional
Parent string `json:"parent,omitempty" protobuf:"bytes,3,opt,name=parent"`
// Costs represents the cost between different zones.
// +optional
Costs CostList `json:"costs,omitempty" protobuf:"bytes,4,rep,name=costs"`
// Attributes represents zone attributes if any.
// +optional
Attributes map[string]string `json:"attributes,omitempty" protobuf:"bytes,5,rep,name=attributes"`
// Resources represents the resource info of the zone.
// +optional
Resources *ResourceInfo `json:"resources,omitempty" protobuf:"bytes,6,rep,name=resources"`
}
注意到,为了更强的扩展性,每个 Zone 内加上了一个 Attributes来描述 Zone 上的自定义属性。如 4.1 节中所示,我们将采集到的离线虚拟机实际算力写入到 Attributes字段中,来描述每个 NUMA Node 实际可用算力。
5.3. 调度器设计
扩展调度器在原生调度器基础上扩展了新的插件,大体如下所示:
Filter:读取 NRT 资源,根据每个拓扑内的实际可用算力以及 Pod 拓扑感知要求来筛选节点并选择拓扑。Score:根据 Zone 个数打分来打分,Zone 越多分越低(跨 Zone 会带来性能损失)。Reserve:在真正绑定前做资源预留,避免数据不一致,kube-scheduler 的 cache 中也有类似的 assume 功能。Bind:禁用默认的 Bind 插件,在 Bind 时加入 Zone 的选择结果,附加在 annotations 中。
通过 TopologyMatch插件使得调度器在调度时能够考虑节点拓扑信息并进行拓扑分配,并通过 Bind 插件将结果附加在 annotations 中。
值得一提的是,这里还额外实现了关于节点电力调度等更多维度调度的调度器插件,本篇中不作展开讨论,感兴趣的同学可以私戳我了解。
5.4. master 设计
cassini-master是中控组件,从外部来采集一些节点上无法采集的资源信息。我们从物理上采集到离线虚拟机的实际可用算力,由 cassini-master负责将这类结果附加到对应节点的 NRT 资源中。该组件将统一资源收集的功能进行了剥离,方便更新与扩展。
5.5. worker 设计
cassini-worker是一个较为复杂的组件,作为 DaemonSet 在每个节点上运行。它的职责分两部分:
采集节点上的拓扑资源。 执行调度器的拓扑调度结果。
5.5.1. 资源采集
资源拓扑采集主要是通过从 /sys/devices下采集系统相关的硬件信息,并创建或更新到 NRT 资源中。该组件会 watch 节点 kubelet 的配置信息并上报,让调度器感知到节点的 kubelet 的绑核策略、预留资源等信息。
由于硬件信息几乎不变化,默认会较长时间采集一次并更新。但 watch 配置的事件是实时的,一旦 kubelet 配置后会立刻感知到,方便调度器根据节点的配置进行不同的决策。
5.5.2. 拓扑调度结果执行
拓扑调度结果执行是通过周期性地 reconcile 来完成制定容器的拓扑分配。
获取 Pod 信息
为了防止每个节点的 cassini-worker都 watch kube-apiserver 造成 kube-apiserver 的压力,cassini-worker改用周期性访问 kubelet 的 10250 端口的方式,来 List 节点上的 Pod 并从 Pod annotations 中获取调度器的拓扑调度结果。同时,从 status 中还可以获取到每个容器的 ID 与状态,为拓扑资源的分配创建了条件。
记录 kubelet 的 CPU 绑定信息
在 kubelet 开启 CPU 核心绑定时,扩展调度器将会跳过所有的 TopologyMatch插件。此时 Pod annotations 中不会包含拓扑调度结果。在 kubelet 为 Pod 完成 CPU 核心绑定后,会将结果记录在 cpu_manager_state文件中,cassini-worker读取该文件,并将 kubelet 的绑定结果 patch 到 Pod annotations 中,供后续调度做判断。
记录 CPU 绑定信息
根据 cpu_manager_state文件,以及从 annotations 中获取的 Pod 的拓扑调度结果,生成自己的 cassini_cpu_manager_state文件,该文件记录了节点上所有 Pod 的核心绑定结果。
执行拓扑分配
根据 cassini_cpu_manager_state文件,调用容器运行时接口,完成最终的容器核心绑定工作。
6. 优化结果
根据上述精细化调度方案,我们对一些线上的任务进行了测试。此前,用户反馈任务调度到一些节点后计算性能较差,且由于 steal_time升高被频繁驱逐。在替换为拓扑感知调度的解决方案后,由于拓扑感知调度可以细粒度地感知到每个 NUMA 节点的离线实际算力(offline_capacity),任务会被调度到合适的 NUMA 节点上,测试任务的训练速度可提升至原来的 3 倍,与业务在高优 CVM 的耗时相当,且训练速度较为稳定,资源得到更合理地利用。
同时,在使用原生调度器的情况下,调度器无法感知离线虚拟机的实际算力。当任务调度到某个节点上后,该节点 steal_time会因此升高,任务无法忍受这样的繁忙节点就会由驱逐器发起 Pod 的驱逐。在此情况下,如果采用原生调度器,将会引起反复驱逐然后反复调度的情况,导致 SLA 收到较大影响。经过本文所述的解决方案后,可将 CPU 抢占的驱逐率大大下降至物理机水平。
7. 总结与展望
本文从实际业务痛点出发,首先简单介绍了腾讯星辰算力的业务场景与精细化调度相关的各类背景知识,然后充分调研国内外研究现状,发现目前已有的各种解决方案都存在局限性。最后通过痛点问题分析后给出了相应的解决方案。经过优化后,资源得到更合理地利用,原有测试任务的训练速度能提升至原来的 3 倍,CPU 抢占的驱逐率大大降低至物理机水平。
未来,精细化调度将会覆盖更多的场景,包括在 GPU 虚拟化技术下对 GPU 整卡、碎卡的调度,支持高性能网络架构的调度,电力资源的调度,支持超售场景,配合内核调度共同完成等等。
如有侵权请联系:admin#unsafe.sh