前言
JS 中 GBK 编码转字符串是非常简单的,直接调用 TextDecoder 即可:
const gbkBuf = new Uint8Array([196, 227, 186, 195, 49, 50, 51])
new TextDecoder('gbk').decode(gbkBuf) // "你好123"
但反过来,字符串转 GBK 编码却没这么简单,因为 TextEncoder 无法指定字集,只能将字符串转成 UTF-8 编码的二进制数据。
因此业内绝大多数的解决方案都是使用第三方编码库,例如 iconv。由于这些库打包了大量字集数据,体积非常可观,即便是精简版的 iconv-lite 也有几百 kB,这在浏览器端显然很不完美。我们希望只用几百字节就能解决!
遍历
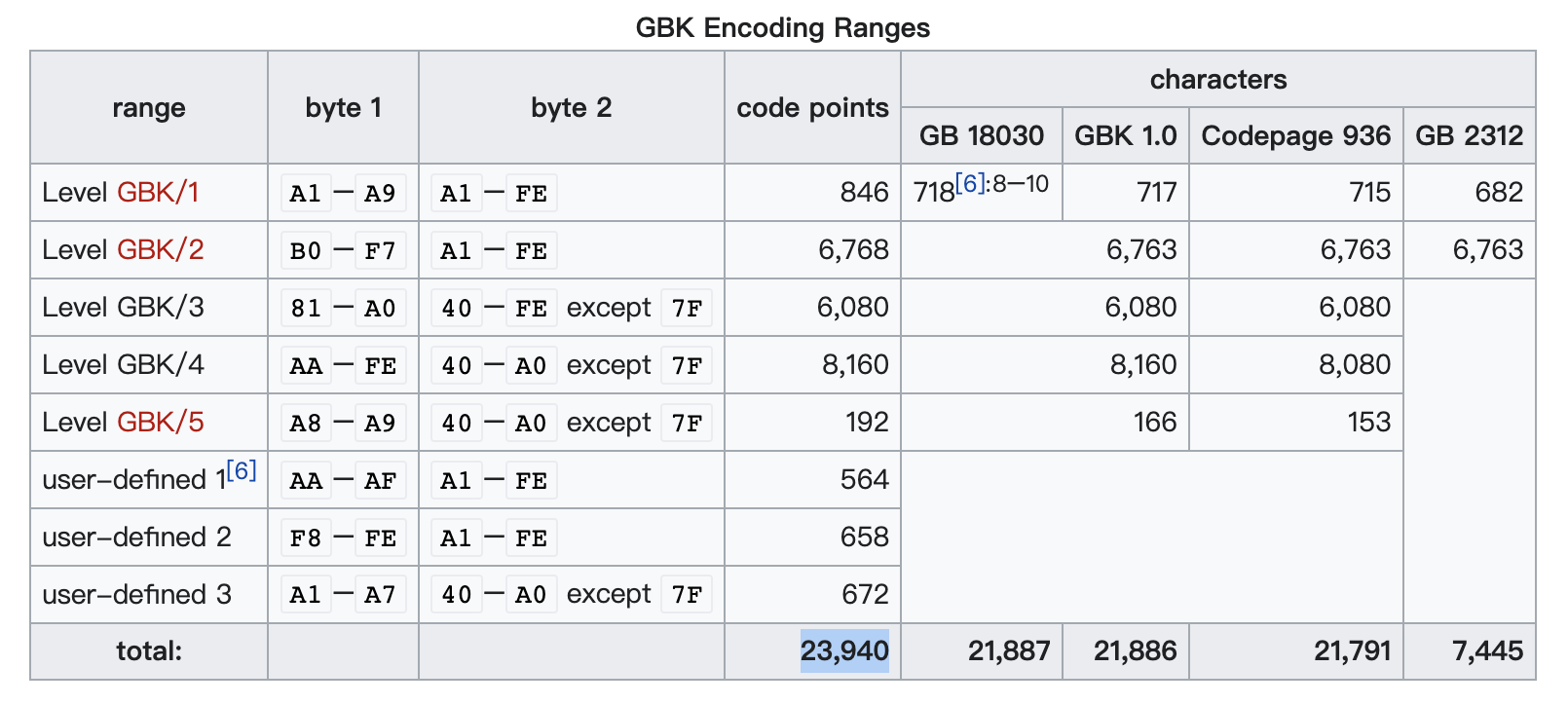
查阅资料可得,GBK 其实只有两万多个字符,因此最简单的办法就是「暴力穷举」。借助 TextDecoder 可遍历出每个 GBK 对应的 JS 字符,之后的编码过程无非就是查表而已。
事实上 GBK 的编码范围是有规律的:

https://en.wikipedia.org/wiki/GBK_(character_encoding)#Encoding
因此只需在预定范围中遍历,即使多花十几行代码但能提高性能,也是值得的。
const ranges = [
[0xA1, 0xA9, 0xA1, 0xFE],
[0xB0, 0xF7, 0xA1, 0xFE],
[0x81, 0xA0, 0x40, 0xFE],
[0xAA, 0xFE, 0x40, 0xA0],
[0xA8, 0xA9, 0x40, 0xA0],
[0xAA, 0xAF, 0xA1, 0xFE],
[0xF8, 0xFE, 0xA1, 0xFE],
[0xA1, 0xA7, 0x40, 0xA0],
]
const codes = new Uint16Array(23940)
let i = 0
for (const [b1Begin, b1End, b2Begin, b2End] of ranges) {
for (let b2 = b2Begin; b2 <= b2End; b2++) {
if (b2 !== 0x7F) {
for (let b1 = b1Begin; b1 <= b1End; b1++) {
codes[i++] = b2 << 8 | b1
}
}
}
}
const str = new TextDecoder('gbk').decode(codes)
// 编码表
const table = new Uint16Array(65536)
for (let i = 0; i < str.length; i++) {
table[str.charCodeAt(i)] = codes[i]
}
如果每遍历一个 GBK 就调用一次 TextDecoder,那显然是十分低效的。因此我们将所有 GBK 集中存放在上述 codes 数组中,最后只调用一次 TextDecoder 批量转换。
这个初始化过程只需 1ms ~ 2ms,开销非常低。
查表
有了映射表,编码时直接查表即可:
function stringToGbk(str) {
const buf = new Uint16Array(str.length)
for (let i = 0; i < str.length; i++) {
const code = str.charCodeAt(i)
buf[i] = table[code]
}
return new Uint8Array(buf.buffer)
}
stringToGbk('你好') // [196, 227, 186, 195]
输出结果和本文开头演示的一致。
不过上述忽略了 ASCII 范围,如果传入「你好123」就有问题了。由于 GBK 的 ASCII 部分是单字节存储的,因此编码逻辑需调整:
function stringToGbk(str) {
const buf = new Uint8Array(str.length * 2)
let n = 0
for (let i = 0; i < str.length; i++) {
const code = str.charCodeAt(i)
if (code < 0x80) {
buf[n++] = code
} else {
const gbk = table[code]
buf[n++] = gbk & 0xFF
buf[n++] = gbk >> 8
}
}
return buf.subarray(0, n)
}
stringToGbk('你好123') // [196, 227, 186, 195, 49, 50, 51]
输出结果和本文开头演示的一致。
出于性能考虑,这里使用 Uint8Array 而不是 Array。但 Uint8Array 长度是固定的,申请后不能改变,因此假设输入的字符串中都是非 ASCII 字符,从而确保缓冲区充足,最后返回时再截取。(使用 subarray 引用,无需复制)
完善
如果编码时传入了 GBK 不支持的字符,按上述逻辑将会变成 0 字符,因为 table 空缺位置默认为 0。而 0 本身也是 GBK 的一部分,因此并不完善。
因此我们可将 table 填充成其他值,之后查表时出现该值,可作为异常处理。
此外根据百科上科普,微软基于 GBK 实现的 Code page 936 多一个 0x80 字码,对应的字符是欧元符号 €。
试了下,即使非 Windows 系统的浏览器也支持:
const gbkBuf = new Uint8Array([0x80])
new TextDecoder('gbk').decode(gbkBuf) // "€"
演示:https://jsbin.com/vuxawul/edit?html,output
最终实现:https://github.com/EtherDream/str2gbk
使用这种方案,几十行代码几百字节就能实现 GBK 编码,并且性能非常高。
如有侵权请联系:admin#unsafe.sh