每周文章分享2022.08.01-2022.08.07标题:DAEMON: Unsupervised Anomaly Detection and Interpretation for Multivar 2022-8-6 13:42:53 Author: 网络与安全实验室(查看原文) 阅读量:32 收藏
每周文章分享
2022.08.01-2022.08.07
标题:DAEMON: Unsupervised Anomaly Detection and Interpretation for Multivariate Time Series
期刊:2021 IEEE 37th International Conference on Data Engineering (ICDE), 2021, pp. 2225-2230.
作者:Xuanhao Chen, Liwei Deng, Feiteng Huang, Chengwei Zhang, Zongquan Zhang, Yan Zhao, Kai Zheng
分享人:河海大学——陈建杭
01
研究背景
BACKGROUND
研究背景
异常检测的目的是确定哪些实例与其他实例相比表现出异常行为,在许多领域引起了广泛的关注,本文专注于多变量时间序列的异常检测。在许多实际应用中,被监测的设备会产生大量的多变量时间序列,如航天器、服务器机器、水处理系统等。操作人员主要关心实体层面的异常,而不是基于单变量时间序列的度量层面的异常,这往往会涉及到多个变量指标。而为每个指标训练一个模型是很耗时的,特别是在复杂和大规模的系统中。另一方面,由于一个事件可能导致多个指标的异常,如果我们在指标级发现异常,需要大量的领域知识来定义指标之间的关系,以确定实体是否异常。
虽然在实体层面检测异常是比较直观的,但也有很多挑战。首先,真实的数据是缺乏标签的,因为异常情况很少。第二,由于工业服务中有许多不同的模式,因此检测方法在各种模式中都有良好的表现是很重要的。第三,在工业应用中,监控系统通常会近乎实时地处理数以百万计的时间序列。异常检测框架应该在有限的时间内完成检测。第四,由于一个事件可能会引起多个指标的异常,因此显示异常的根本原因以帮助操作人员更好地理解事件是非常重要的。大多数现有的方法只关注异常检测框架,而忽略了对多变量时间序列异常的解释。
02
关键技术
TECHNOLOGY
关键技术
本文提出了对抗性自动编码器异常检测解释(DAEMON),这是一个在线无监督的异常检测和解释框架,它基于对抗性生成的时间序列来检测异常情况。
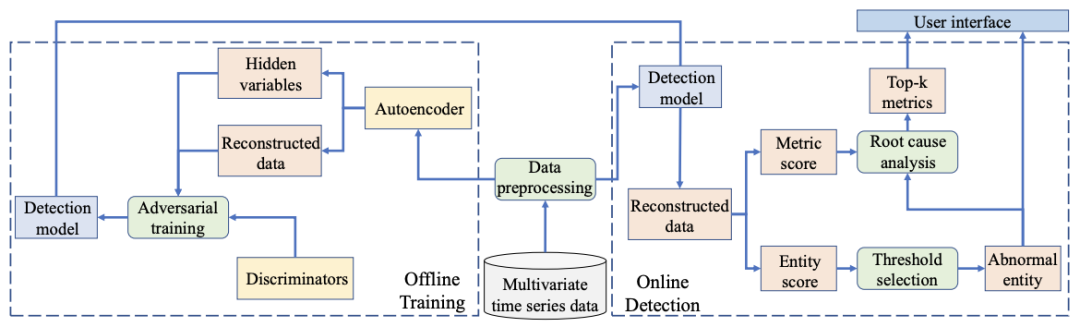
如图1所示,DAEMON由两部分组成。离线训练和在线检测。在离线训练部分,用三个目标训练自动编码器,即重建误差、引导自动编码器的隐性变量的后验分布与给定的先验分布相匹配的对抗性训练标准,以及另一个使原始和重建的时间序列之间的差异最小的对抗性训练标准。
图1 DAEMON整体结构图
首先采用一维卷积神经网络(CNN)对原始多变量时间序列进行编码。我们没有直接对隐藏变量进行解码,而是对潜伏向量施加了一个先验分布,并采用对抗性训练程序将隐藏变量的后验分布与先验分布进行匹配。这背后的原因是,如果之前从未观察到类似的模式,直接对原始潜伏向量进行解码并使用重建误差来训练网络将不能很好地重建时间序列。
随后,一个解码器被用来生成重构的时间序列。同时,采用另一个对抗性训练程序来最小化原始时间序列和重构时间序列之间的差异,以避免过度拟合。在线检测模块使用训练好的模型来衡量基于重建误差的新观察的异常得分。异常得分将被用来识别该观测值是否为异常。为了解释异常的根本原因,将计算观察的每个维度的重建误差,然后将重建误差最大的前k个维度作为异常的根本原因返回。
该方法的创新和贡献如下:
1)提出了DAEMON,一种基于对抗性自动编码器的新型架构,用于多变量时间序列异常检测。设计了两个对抗性训练过程,以保证DAEMON的鲁棒性和避免过度拟合。
2)提出了异常解释方法,同时,考虑到多变量时间序列各个维度的不同重要性,提出了一个新的解释指标。
3)DAEMON在四个真实数据集上的表现优于最先进的基线方法,取得了0.94的总体F1分数,证明了两个对抗性训练标准的好处。此外,DAEMON表现出了非常快的训练和推理速度(平均每个历时169秒,每个实体0.1毫秒)。
03
算法介绍
ALGORITHMS
算法介绍
DAEMON算法的总体网络结构如下图所示,包含了三个网络模块,变分自编码器GA(其中包含编码器GE和解码器GD,编码器和解码器同时作为两个GAN结构中的生成器), 对应编码器的GAN结构判别器DE以及对应解码器的GAN结构判别器DD。
图2 DAEMON网络结构图
其中,变分自编码器用来学习输入序列的正常趋势并得到输入序列的重构。由于重构是基于数据的正常分布,其与输入的欧式距离即可用于判断输入数据是否存在异常。变分自编码器的中间输出服从分布q(z),为了约束这个分布以提高重构的鲁棒性和减少重构的过拟合效应,算法规定了一个约束分布p(z)并用判别器DE来对比q(z)与p(z)的差别来让q(z)更接近于p(z)。这一种思想源自对抗自编码器,是一种约束变分自编码器中间输出的好方法。判别器DD的作用是为了让变分自编码器的重构输出W’_xt更接近于输入以学习输入数据的分布,一般情况下会令损失函数为输入和输出的距离。然而,单独用范数距离并不一定能准确刻画输入和输出的相似性。因此,DAEMON算法提出利用GAN的判别器进一步来辨认输出和重构的相似性。
由于GAN结构网络需要异步训练,因此,DAEMON结构对应了三个异步的训练过程,每个训练规程都对应了各自的优化器以及损失函数。
第一个模块GAN1, 生成器对应的是变分自编码器的编码器部分GE,而判别器对应的是DE,此GAN结构的目的是约束生成器的分布。由GAN的标准损失函数公式可以推导出生成器和判别器的损失函数分别为
在GAN结构2中,生成器对应的是变分自编码器中的解码器部分GD,判别器对应的是DD,此GAN结构的目的是进一步约束自编码器的输出以让自编码器更好的学习时序数据的正常分布。和上面相似,生成器和判别器的损失函数为:
变分自编码器用于数据的重构,其自身的损失函数用输入和输出的一范数距离定义:
值得注意的是GAN结构1,2中的判别器损失函数都只涉及到判别器本身,而生成器的损失函数和变分自编码器的损失函数同时涉及到一个公共的模块,即变分自编码器本身,因此,在训练自编码器网络时,实际上要同时训练三个损失函数,具体的方法为,令三个损失函数的加权和为变分自编码器的损失函数,即:
在线数据W_xt输入到检测器后,得到重构W’_xt,之后把被检测点xt和被检测点的重构x't做比较以求取异常得分,即
从上面公式中可以看出,异常得分实际上是由每一个维度的误差所加和得出的,因此,在根因定位的时候,直接从Sj_xt中找出最大的k个得分对应的指标既可视为根因可能出现的位置。
04
实验结果
EXPERIMENTS
实验结果
本文实验中使用了四个数据集,分别是SMD、SMAP、MSL和SWaT,其参数如下表所示:
图3 训练数据集参数
性能使用Precision (Pre)、Recall (Rec)和F1-score (f1)来评估。
结果如下:
图4 算法检测结果对比
从表中可以看出,DAEMON在SMD、MSL和SWaT数据集上的性能优于所有基线,它的f1只比SMAP数据集上的最佳基线略低。DAEMON的鲁棒性优于所有基线,因为DAEMON的精度和召回值在所有数据集上都高于0.89,这是任何基线都无法达到的。原因是设计了两个鉴别器来反向研究输入数据的模式,这保证了DAEMON的健壮性和通用性。
图5 算法训练时间和测试时间结果对比
图5是每个算法训练和测试时间的对比,用来反映算法的效率。可以看出DAEMON的训练时间要比EncDec-AD、LSTM- NDT、LSTM- VAE和OmniAnomaly小得多,这是因为卷积神经网络(CNN)的训练过程要快于长短时记忆网络(LSTM)。DAEMON在SMD、SMAP、MSL和SWaT上每个epoch的训练时间分别只有510、92、41和35秒左右,保证了它在频繁训练模型的真实场景中的应用。此外,DAEMON的测试时间比大多数最先进的方法都要短,每个实体只需要0.1毫秒。实验结果表明了DAEMON的优越性。更快的训练和测试时间,以及出色的异常检测性能,保证了其在不同场景的在线业务中的应用。
为了验证每个模块带来的提升,作者做了三个变体。首先将CNN替换为LSTM和GRU,分别表示为DAEMONLS和DAEMON-GR。然后将自动编码器隐藏变量的对抗性正则化被VAE中使用的KL-divergence所取代,记作DAEMON-KL。同时,去掉了自编码器隐藏变量的对敌正则化,记为DAEMON-RH。最后去掉原始数据和重构数据的对抗性正则化,记作DAEMON-RR。结果如下:
图6 算法变体F1-Score性能对比
可以看出,CNN在大多数数据集上的表现都优于LSTM和GRU,这说明CNN也能捕捉到时间序列的长期依赖性,更适合研究当前窗口中发生的动态变化和模式。此外,通过隐藏变量的对抗性训练,DAEMON比使用KL-divergence的变体表现更好。这是因为与对抗性正则化相比,KL-divergence不能捕获隐藏空间某些区域的数据流形,导致重构效果较差。最后,从图4可以清楚地看出,通过对重构数据进行对抗性正则化,DAEMON的性能得到了提高。如果没有重构数据的对抗性正则化,模型(DAEMON-RR)将更容易过拟合,导致性能更差。
对于异常的解释,提出了一个重构折现累积增益,计算公式如下:
对于解释的准确性实验结果如下:
图7 异常解释的精度
因此,从整体来看,本文方法优于其他方法,这证明了本文方法模型的优越性。
05
总结
CONCLUSION
总结
多变量时间序列异常检测是监测系统的一项重要任务。一种高效、通用和准确的异常检测方法在实际应用中是不可或缺的。在本文中,提出了一种用于多变量时间序列异常检测的新型架构,即对抗性自动编码器异常检测解释(DAEMON),它在各种情况下都显示出很高的准确性和效率。
此外,DAEMON提供了一种直观有效的方法来识别异常,并根据不同指标的重建误差来分析异常的根本原因。大量的实验结果表明,DAEMON在四个数据集上的表现优于最先进的方法,这表明DAEMON是强大的,可以应用于各种在线异常检测服务。
END
扫描二维码关注我们
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh