0x01 前言【本篇纯理论搬的,暂时不具备这块的知识体系,看的有点槽,准备后面慢慢补充一些实验结果以及实操记录,感兴趣的可以关注该专栏:https://blog.csdn.n 2022-8-13 07:0:17 Author: 哆啦安全(查看原文) 阅读量:41 收藏
0x01 前言
【本篇纯理论搬的,暂时不具备这块的知识体系,看的有点槽,准备后面慢慢补充一些实验结果以及实操记录,感兴趣的可以关注该专栏:https://blog.csdn.net/ananas_orangey/category_11673665.html】
注:【最后的最后,真的五体投地佩服文中里的大佬,是真的大佬,向大佬们看起】
前面理论多,不想看的可以直接跳过
0x01 前言的内容,直接到0x02 车机(Android)设备中监控命令执行的一些想法
在入侵检测的过程中,进程创建监控是必不可少的一点,因为攻击者的绝大多数攻击行为都是以进程的方式呈现,例如进程发起网络连接请求传输数据,并可能产生文件读写行为。所以从进程的角度出发关联出命令执行、网络连接、读写文件,可以快速分析出大量安全攻击场景,还原出入侵行为攻击的链路脑图
切记,不管是事前、还是事中、甚至事后的攻击行为,都可以依赖进程数据为基础进行入侵行为的基础数据分析,并结合不同的攻击向量,多维度快速高效的分析出攻击行为或异常攻击行为
命令行终端:实际是一个叫bash/sh的端终程序提供的功能,该程序底层的实质还是调用一些操作系统提供的函数
再开始之前之前先来了解内核的一些东西和实例,本篇主要还是理论篇,无实操
Ring 权限关系图:
使用这种权限控制的好处在于计算机用户的软件不会危及系统的安全,只有稳定的系统软件才能够操作系统的关键内存等硬件设备。从而最大程度保证系统运行的稳定
从内到外依次使用0-3标识,这些环(ring)。越内部的圈代表的权限越大。内圈可以访问,修改外圈的资源;外圈不可以访问,修改内圈的资源
为什么会有4个ring?因为x86的CPU,在
Data segment selector中使用了2个bits来描述权限。
我们最常见的是ring 0(内核态),和ring 3(用户态)。因为例如Windows和Unix这些常见的操作系统,只提供了两种权限模式,所以并没有完全使用整个ring架构。所以,一般情况下,完全可以使用ring 0 表示内核态,ring 3表示用户态
Linux进程监控,通常使用hook技术,而hook大概分为两类:
应用级
内核级
1.x
此处都是为后续的内容理解做学习铺垫的,感兴趣的可以点击阅读原文,不喜欢的,可以直接跳过,看0x02 车机(Android)设备中监控命令执行的一些想法
1.5.3 总结
Hook技术是进行主动防御、动态入侵检测的关键技术,从技术上来说,目前的很多Hook技术都属于"猥琐流",即:
通过"劫持"在关键流程上的某些函数的执行地址,在Hook函数执行完之后,再跳回原始的函数继续执行(做好现场保护)
或者通过dll、进程、线程注入比原始程序提前获得CPU执行权限
但是随着windows的PatchGuard的出现,这些出于"安全性"的内核patct将被一视同仁地看作内核完整性的威胁者
更加优美、稳定的方法,包括如下:
注册标准的回调方法,包括:
进程
线程
模块的创建
卸载回调函数
文件/网络等各种过滤驱动
内核提供的标准处理流程Hook点
kprobe机制
网络协议栈提供的标准Hook点
netfilter的链式处理流程
系统命令执行的监控,也就是对外部进程创建的监控。在linux中,启动外部进程,是通过execve系统调用进行创建的,我们使用strace打印一下在bash中启动ls的系统调用,第一句就是通过execve启动ls
但是我们在开发linux程序的时候,执行系统命令,并没有直接使用execve系统调用,这是因为libc/glibc库对execve系统调用封装成了函数,方便我们调用
因此基于execve的系统命令监控方式,分成了用户态和内核态。用户态通过劫持libc/glibc的exec相关函数来实现,内核态则通过系统自身组件或者劫持execve syscall来实现
Linux进程监控,通常使用hook技术,而hook大概分为两类:
应用级
内核级
常见的获取进程创建的信息的方式有以下四种:
So preload(用户态)Netlink Connector(内核态)Audit(内核态)Syscall hook(内核态)
实现内核系统调用的方式:
通过修改内核源代码添加系统调用
利用内核模块添加系统调用
用户态:
在
libc/glibc中,对execve syscall进行了一系列的封装,简称exec族函数。exec系列函数调用时,启动新进程,替换掉当前进程。即程序不会再返回到原进程,具体内容如下:
int execl(constchar*path,constchar*arg0,...,(char*)0);int execlp(constchar*file,constchar*arg0,...,(char*)0);int execle(constchar*path,constchar*arg0,...,(char*)0,char*const envp[]);int execv(cosnt char*path,char*const argv[]);int execvp(cosnt char*file,char*const argv[]);int execve(cosnt char*path,char*const argv[],char*const envp[]);
劫持libc/glibc中的函数,就是我们前言内容和本文后面说的so preload劫持
内核态:
在内核态监控其实是最准确,而且是最难绕过的。在内核态,一般是通过三种办法来监控:
Netlink ConnectorAuditHook execve syscall
进程事件数据采集方案:
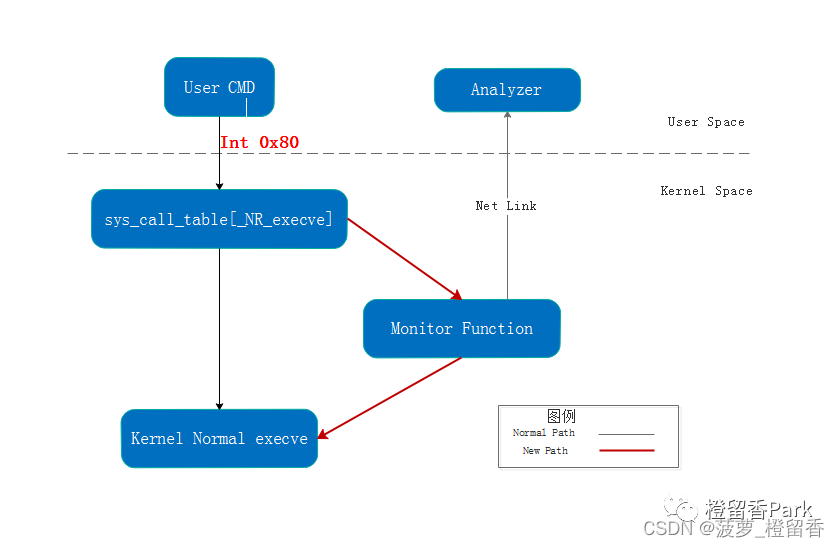
Hook 内核模块:拦截系统调用符号表
sys_call_table地址,hook fork、exec、connect等系统调用地址更改成内核模块中自定义函数地址优点:能抓取全量进程事件,不易被绕过
缺点:方案过重,侵入内核,主机风险较高,需要兼容多个版本,稳定性低
Linux 动态库 preload 机制:利用 Linux 动态库 preload 机制,拦截 libc 同名 fork、exec 族函数,优先加载 hook 动态库自实现同名函数
优点:方案轻量,实现简单
缺点:侵入到主机所有进程,与业务耦合,稳定性低,并且对静态链接程序失效,会遗漏进程事件
Linux 连接器 (
netlink connector) :由 Linux 内核提供的接口,安全可靠,结合用户态轻量级 ncp 自实现应用程序,抓取全量进程事件,能够覆盖更多安全检测场景,并对主机影响面较小优点:能抓取全量进程事件,且能够覆盖更多安全检测场景和对主机影响面较小,因为linux内核提供连接器模块与进程事件收集机制,无需任何改动,而在用户态实现轻量级ncp(
netlink connector process)应用程序接收netlink进程事件消息缺点:无法获取ptrace的,是附加,解绑,还是获取/设置寄存器,读/写内存
https://www.freebuf.com/company-information/285300.html
先说说传统LInux主机检测命令执行的一些方式,包括如下:
Bash历史指令的history syslog功能w命令top命令实时提供流程活动的视图,用top命令每秒钟从/proc读取所有进程的状态。其实,就是从
/proc/[pid]/stat和/proc/[pid]/status,这个两个proc的接口进行读取各个进程的信息find命令find /proc -path '/proc/sys/fs' -prune -o -print |xargs ls -al | grep 'exe ->' | sort -usys/fs用于描述系统中的所有文件系统,排除/proc/sys/fs搜索所有exe表示具体的执行路径lsof命令为什么选用lsof命令?因为netstat无权限控制,lsof有权限控制,只能看到本用户。而losf能看到PID和用户,可以找到哪个进程占用了这个端口
lsof -nPi | grep -v "127.0.0.1" |grep -v "::1" |sort -u'Sydig是Linux开源,跨平台,功能强大且灵活的系统监控系统日志
Web日志
沙盒(
Androdeb + 自编内核 + 内核移植 + 高本版内核)通过沙盒等方式在Android中运行一个常见的 Linux 发行版,比如 Ubuntu 或者 Debian。androdeb 就是提供了一个沙盒方式在Android 中运行其它系统,其核心是基于 chroot 在 Android 中运行了一个
Debian aarch64镜像,并可以通过 apt 等包管理工具安装所需要的编译工具链,从而在上面编译和运行 bcc 等 Linux 项目。其中的关键之处在于正确挂载原生 Android 中的映射,比如procfs、devfs、debugfs等需要一个支持动态调试的内核环境。在绝大多数官方固件中自带的内核都没有开启
KPROBES的支持,这意味着需要自行编译和加载内核,详细内容移步:https://evilpan.com/2022/01/03/kernel-tracing/#android-移植当你成功编译好内核并启动后,很可能会发现有一些内核分析工具比如
BCC在使用上会出现各种问题,这通常是内核版本的原因。由于eBPF目前在内核中也在频繁更新,因此许多新的特性并没有增加到当前内核上。因此,为了减少可能遇到的兼容性问题,尽量使用最新版本的内核,当然通常厂商都只维护一个较旧的LTS版本,只进行必要的安全性更新,如果买机不淑的话就需要自食其力了基于内核级别的监控,让应用或系统中所有的进程隐藏、命令执行等攻击手段无所遁形,且可在应用启动的初期进行观察,让应用或系统中的一切行为在我们眼中无所遁形
在 Android 上运行 Debian 系统的示例如下:
strace命令strace 是 Linux 中一个知名的用户态系统调用跟踪工具,可以输入目标进程所执行的系统调用的名称以及参数,常用于快速的应用调试和诊断
对于需要监控系统调用的场景,
strace是个非常合适的工具,因为它基于PTRACE_SYSCALL去跟踪并基于中断的方式去接管所有系统调用,因此即便目标使用了不依赖 libc 的内联 svc 也可以被识别到。不过这个缺点也很明显,从名称也看出来,本质上该程序是基于ptrace对目标进行跟踪,因此如果对方代码中有反调试措施,那么就很有可能被检测到另外,在 Android 系统中,APP 进程都是由
zygote fork而出,因此使用strace比较不容易确定跟踪时机,而且由于许多应用有多个进程,就需要对输出结果进行额外的过滤和清洗更多关于
strace的实现原理可以参考: How does strace work?jtrace支持系统属性的访问监控 (
setprop/getprop)支持输入事件的监控 (
InputReader)支持 Binder 信息的解析
支持 AIDL 的解析
……
在早期
strace程序还不支持 arm64,因此Jonathan Levin在编写Android Internal一书时就写了jtrace这个工具,旨在用于对 Android 应用的跟踪。虽然现在 Google 也在 AOSP 中支持了 strace,但 jtrace 仍然有其独特的优点:jtrace 是闭源的,但提供了独特的插件功能,用户可以根据其提供的接口去编写一个插件(动态库),并使用
--plugin参数或者JTRACE_EXT_PATH环境变量指定的路径加载插件,从而实现自定义的系统调用参数解析处理jtrace优点比 strace 多了不少,但其缺点并没有解决,jtrace 本身依然是基于
PTRACE_SYSCALL进行系统调用跟踪的,因此还是很容易被应用的反调试检测到更多关于
jtrace的内容: jtrace - 具有插件架构的增强型、Linux/Android 感知 straceFridafrida-gum基于inline-hook对目标跟踪代码进行实时重编译 (JIT),对于应用本身有较大的侵入性frida-inject需要依赖ptrace对目标应用进行第一次注入并加载agent,有一个较短的注入窗口可能会被反调试应用检测到frida目前尚不支持系统调用事件级别的追踪,虽然frida-stalker可以做到汇编级别,但是开销过大frida太过知名,以至于有很多针对 frida 的特征检测……
类似的
Instrumentation工具还有 QDBI,hookzz 等等。Frida 是目前全球最为知名的动态跟踪工具集 (
Instrumentation),支持使用 JS 脚本来对目标应用程序进行动态跟踪。其功能之丰富毋庸置疑,但也有一些硬伤,比如:ebpf当用户调用
bpf()系统调用把 eBPF 字节码加载到内核时,内核先会对 eBPF 字节码进行安全验证使用
JIT(Just In Time)技术将 eBPF 字节编译成本地机器码(Native Code)然后根据 eBPF 程序的功能,将 eBPF 机器码挂载到内核的不同运行路径上(如用于跟踪内核运行状态的 eBPF 程序将会挂载在 kprobes 的运行路径上)。当内核运行到这些路径时,就会触发执行相应路径上的 eBPF 机器码
用户编写 eBPF 程序,可以使用 eBPF 汇编或者 eBPF 特有的 C 语言来编写
使用
LLVM/CLang编译器,将 eBPF 程序编译成 eBPF 字节码调用
bpf()系统调用把 eBPF 字节码加载到内核Android 从9.0版本开始全面支持eBPF(
extended Berkeley Packet Filters),其主要用在流量统计上,也可以用来监控CPU/IO/内存等模块的状态。简单来说,eBPF可以与内核的kprobe/tracepoints/skfilter等模块相结合,将eBPF的函数hook到内核事件从而监控相应的系统状态改内核?水平不够;自编译ROM?太复杂,而且耗时,并高定制化;使用沙盒APP或利用容器系统挂载到Android设备里进行检测?沙盒APP难以贴近真机环境,容器系统会产生新的容器安全风险,增加攻击面。而eBPF可以以不侵入的方式去记录程序的一举一动,对于APP或攻击者执行系统命令来说是完全无感的
使用 eBPF 来跟踪
fork()系统调用,我们编写 eBPF 程序有多种方式,比如使用原生 eBPF 汇编来编写,但使用原生 eBPF 汇编编写程序的难度较大;也可以使用 eBPF 受限的 C 语言来编写,难度比使用原生 eBPF 汇编简单些;最简单的方法是使用 BCC 工具来编写,BCC 工具帮我们简化了很多繁琐的工作,比如不用编写加载器由于
eBPF对内核的版本有较高的要求,不同版本的内核对 eBPF 的支持可能有所不相同。所以使用 eBPF 时,最好使用最新版本的内核需要注意,Android系统自带有追踪系统调用的功能,正是基于eBPF提供的
用户态:
内核态:
eBPF的hook点,作用在syscall的
kprobe、tracepoint事件类型,倘若用在后门rootkit场景,是十分可怕的。比如,修改内核态返回给用户态的数据,拦截阻断用户态行为等为所欲为。而更可怕的是,常见的HIDS都是基于内核态或者用户态做行为监控,就绕过了大部分HIDS的监控,且不产生任何日志。然而,比如之前很火的log4j漏洞还可怕的是rootkit这种本身并没有产生用户态行为日志,也没有改文件,系统里查不到这个用户信息。整个后门行为不产生数据,让大部分HIDS失灵其它工具:比如
ltrace、gdb等但这些工具都不能完美实现监控系统调用的需求常规的主机安全防御产品一般用
netlink linux kernel module等技术实现进程创建、网络通讯等行为感知,而eBPF的hook点可以比这些技术更加深,比他们执行更早,意味着常规HIDS并不能感知发现他们传统rootkit,采用
Hook API方法,替换原来函数,导致执行函数调用地址发生变化,已有成熟检测机制,eBPF hook不同于传统rootkit ,函数调用堆栈不变,更多详情请移步:https://www.anquanke.com/post/id/269887#h3-14
注:/proc/[pid]/cmdline,获取进程启动的是启动命令, 可以通过获取/proc/[pid]/cmdline的内容来获得
多啰嗦一句,如果是基于 proc_events (基于 netlink,自动创建进程事件netlink socket并监听,并返回一个告警事件,比如开源项目:https://github.com/dbrandt/proc_events)采集入侵检测的事件,是需要异步的对处理内核传递的所有消息,会比较损耗服务器性能,且会有串号问题,这里就有人会使用 ld.so.preload机制注入 so,来让在每个进程启动时选择性上报异常告警,且无串号问题,以及可以采集全部的进程信息,需要注意注入的 so 和配置文件要设置为只能root修改以及增加so完整性校验,
上面有针对内核的或用户态、日志、系统内置命令等来实现的检测,但是否兼容性高?、是否高定制?、是否难以维护?、是否会遍历/proc路径会影响设备性能开销?在传统安全里面,最简单最不吃开销的依然是读取bash历史指令的history syslog功能回传日志到安全运营平台进行数据分析,但存在绕过的风险,如果攻击者无日志执行系统命令呢?这里延伸出一个新的话题,就是我们即想要发生命令执行时我们能检测到,但又不想牺牲服务器性能,真有种想要马儿跑,就是不给马儿吃草的感觉,哈哈。为了解决这个问题,一般情况下会考虑在内核方向上来做命令执行的入侵检测,那么只是为了实现系统调用监控,以及部分系统调用参数的修改(例如 IO 重定向),许多开发人员都会想到修改内核源码然后自行编译再导入Android设备中,但这样做存在几个问题,第一个问题:重新编译内核以及对应的 AOSP 代码,编译效率低且复杂,容易失败,并且不一定兼容所有Android设备;第二个问题:在不同的系统调用相关函数中增加代码,引入过多修改后可能会导致后期更新内核失败的现象出现。还有一种情况(考虑在内核方向上来做命令执行的入侵检测),是通过在内核代码中引入一次性的 trampoline,然后在后续增加或者减少系统调用监控入口时通过内核模块的方式去进行修改,但现在市面上关于内核已经有了许多类似的监控方案,纯属重复造轮子,效率低不说,还可能随时引入kernel panic
传统Linux 中的hook 系统调用,是否适合Android?
答:Linux 发行版上的 trace 方法在 Android 上行得通吗?理论上 AOSP 的代码是开源的,内核也是开源的,编译一下内核再导入设备即,但真正做起来会遇到一些困难,如下:
1、许多工具需要编译代码,BCC 工具还需要 Python 运行,这在默认的 Android 环境中不存在2、原厂提供的预编译内核镜像不带有 kprobe 等监控功能支持,需要自行修改配置,烧写和编译内核3、Linux 旧版本对于 eBPF 的支持不完善,许多新功能都是在 5.x 后才引进,而 Android 的 Linux 内核都比较旧,需要进行 cherry-pick 甚至手动 backport4、AOSP 较新版本引入了 GKI(Generic Kernel Image),需要保持内核驱动接口的兼容性,因此内核代码不能引入过多修改
GKI地址:https://source.android.com/devices/architecture/kernel/generic-kernel-image……
那么,内核中都有哪些监控方案?
答:kprobe、jprobe、uprobe、eBPF、tracefs、systemtab、perf
内核中监控方案的详情:Linux tracing systems & how they fit together
如下内容来自:https://evilpan.com/2022/01/03/kernel-tracing/#现有方案
内核监控方案/工具可大概分为三类:
数据: 根据监控数据的来源划分
KprobesUprobesTracepointsUserland Statically Defined Tracing,也称为USDT采集: 根据内核提供给用户态的原始事件回调接口进行划分
前端: 获取和解析监控事件数据的用户工具
BCCbpftrace采集
&&前端包含的工具:ftraceperfeBPFSystemTapLTTngtrace-cmdkernelshark
| 内核监控方案 | 静态 | 动态 | 内核 | 用户 |
|---|---|---|---|---|
| Kprobes | ✔ | ✔ | ||
| Uprobes | ✔ | ✔ | ||
| Tracepoints | ✔ | ✔ | ||
| USDT | ✔ | ✔ |
2.1 kprobe
简单来说,kprobe 可以实现动态内核的注入,基于中断的方法在任意指令中插入追踪代码,并且通过 pre_handler/post_handler/fault_handler去接收回调
参考 Linux 源码中的 samples/kprobes/kprobe_example.c,一个简单的 kprobe 内核模块实现如下:
#include <linux/kernel.h>#include <linux/module.h>#include <linux/kprobes.h>#define MAX_SYMBOL_LEN 64static char symbol[MAX_SYMBOL_LEN] = "_do_fork";module_param_string(symbol, symbol, sizeof(symbol), 0644);/* For each probe you need to allocate a kprobe structure */static struct kprobe kp = {
.symbol_name = symbol,};/* kprobe pre_handler: called just before the probed instruction is executed */static int handler_pre(struct kprobe *p, struct pt_regs *regs){
pr_info("<%s> pre_handler: p->addr = 0x%p, pc = 0x%lx\n", p->symbol_name, p->addr, (long)regs->pc);
/* A dump_stack() here will give a stack backtrace */
return 0;}/* kprobe post_handler: called after the probed instruction is executed */static void handler_post(struct kprobe *p, struct pt_regs *regs, unsigned long flags){
pr_info("<%s> post_handler: p->addr = 0x%p\n", p->symbol_name, p->addr);}/*
* fault_handler: this is called if an exception is generated for any
* instruction within the pre- or post-handler, or when Kprobes
* single-steps the probed instruction.
*/static int handler_fault(struct kprobe *p, struct pt_regs *regs, int trapnr){
pr_info("fault_handler: p->addr = 0x%p, trap #%dn", p->addr, trapnr);
/* Return 0 because we don't handle the fault. */
return 0;}static int __init kprobe_init(void){
int ret;
kp.pre_handler = handler_pre;
kp.post_handler = handler_post;
kp.fault_handler = handler_fault;ret = register_kprobe(&kp);
if (ret < 0) {
pr_err("register_kprobe failed, returned %d\n", ret);
return ret;
}
pr_info("Planted kprobe at %p\n", kp.addr);
return 0;}static void __exit kprobe_exit(void){
unregister_kprobe(&kp);
pr_info("kprobe at %p unregistered\n", kp.addr);}module_init(kprobe_init)module_exit(kprobe_exit)MODULE_LICENSE("GPL");
安装该内核模块后,每当系统中的进程调用 fork,就会触发我们的 handler,从而在 dmesg 中输出对应的日志信息。值得注意的是,kprobe 模块依赖于具体的系统架构,上述 pre_handler中我们打印指令地址使用的是 regs->pc,这是 ARM64 的情况,如果是 X86 环境,则对应regs->ip,可查看对应 arch 的 struct pt_regs实现
kprobe 框架基于中断实现。当 kprobe 被注册后,内核会将对应地址的指令进行拷贝并替换为断点指令(比如 X86 中的 int 3),随后当内核执行到对应地址时,中断会被触发从而执行流程会被重定向到我们注册的pre_handler函数;当对应地址的原始指令执行完后,内核会再次执行post_handler(可选),从而实现指令级别的内核动态监控。也就是说,kprobe 不仅可以跟踪任意带有符号的内核函数,也可以跟踪函数中间的任意指令
另一个 kprobe 的同族是 kretprobe,只不过是针对函数级别的内核监控,根据用户注册时提供的entry_handler和 ret_handler来分别在函数进入时和返回前进行回调。当然,在实现上和 kprobe 也有所不同,不是通过断点而是通过 trampoline进行实现,可略为减少运行开销
有人可能听说过 Jprobe,那是早期 Linux 内核的的一个监控实现,现已被 Kprobe替代
拓展阅读:
An introduction to KProbes
Documentation/trace/kprobetrace.rst
samples/kprobes/kprobe_example.c
samples/kprobes/kretprobe_example.c
2.2 uprobe
uprobe顾名思义,相对于内核函数/地址的监控,主要用于用户态函数/地址的监控。听起来是不是有点神奇,内核怎么监控用户态函数的调用呢?
站在用户视角,我们先看个简单的例子,假设有这么个一个用户程序:
// test.c<p data-line="341" class="sync-line" style="margin:0;"></p># include <stdio.h><p class="mume-header " id="include-stdioh"></p>void foo() {
printf("hello, uprobe!\n");}int main() {
foo();
return 0;}<p data-line="349" class="sync-line" style="margin:0;"></p>
编译好之后,查看某个符号的地址,然后告诉内核我要监控这个地址的调用:
$ gcc test.c -o test
$ readelf -s test | grep foo 87: 0000000000000764 32 FUNC GLOBAL DEFAULT 13 foo
$ echo 'p /root/test:0x764' > /sys/kernel/debug/tracing/uprobe_events
$ echo 1 > /sys/kernel/debug/tracing/events/uprobes/p_test_0x764/enable
$ echo 1 > /sys/kernel/debug/tracing/tracing_on<p data-line="360" class="sync-line" style="margin:0;"></p>
运行用户程序并检查内核的监控返回:
$ ./test && ./test
hello, uprobe!hello, uprobe!$ cat /sys/kernel/debug/tracing/trace<p data-line="370" class="sync-line" style="margin:0;"></p># tracer: nop<p class="mume-header " id="tracer-nop"></p><p data-line="371" class="sync-line" style="margin:0;"></p>#
<p class="mume-header " id=""></p><p data-line="372" class="sync-line" style="margin:0;"></p># WARNING: FUNCTION TRACING IS CORRUPTED<p class="mume-header " id="warning-function-tracing-is-corrupted"></p><p data-line="373" class="sync-line" style="margin:0;"></p># MAY BE MISSING FUNCTION EVENTS<p class="mume-header " id="may-be-missing-function-events"></p><p data-line="374" class="sync-line" style="margin:0;"></p># entries-in-buffer/entries-written: 3/3 #P:8<p class="mume-header " id="entries-in-bufferentries-written-33-p8"></p><p data-line="375" class="sync-line" style="margin:0;"></p>#
<p class="mume-header " id="-1"></p><p data-line="376" class="sync-line" style="margin:0;"></p># _-----=> irqs-off<p class="mume-header " id="_-irqs-off"></p><p data-line="377" class="sync-line" style="margin:0;"></p># / _----=> need-resched<p class="mume-header " id="_-need-resched"></p><p data-line="378" class="sync-line" style="margin:0;"></p># | / _---=> hardirq/softirq<p class="mume-header " id="_-hardirqsoftirq"></p><p data-line="379" class="sync-line" style="margin:0;"></p># || / _--=> preempt-depth<p class="mume-header " id="_-preempt-depth"></p><p data-line="380" class="sync-line" style="margin:0;"></p># ||| / delay<p class="mume-header " id="delay"></p><p data-line="381" class="sync-line" style="margin:0;"></p># TASK-PID CPU# |||| TIMESTAMP FUNCTION<p class="mume-header " id="task-pid-cpu-timestamp-function"></p><p data-line="382" class="sync-line" style="margin:0;"></p># | | | |||| | |<p class="mume-header " id="-2"></p>test-7958 [006] .... 34213.780750: p_test_0x764: (0x6236218764)
test-7966 [006] .... 34229.054039: p_test_0x764: (0x5f586cb764)<p data-line="385" class="sync-line" style="margin:0;"></p>
关闭监控:
$ echo 0 > /sys/kernel/debug/tracing/tracing_on
$ echo 0 > /sys/kernel/debug/tracing/events/uprobes/p_test_0x764/enable
$ echo > /sys/kernel/debug/tracing/uprobe_events<p data-line="393" class="sync-line" style="margin:0;"></p>
上面关闭监控的接口是基于 debugfs(在较新的内核中使用 tracefs),即读写文件的方式去与内核交互实现 uprobe 监控。其中写入 uprobe_events时会经过一系列内核调用:
probes_writecreate_trace_uprobekern_path:打开目标ELF文件alloc_trace_uprobe:分配uprobe结构体register_trace_uprobe:注册uproberegiseter_uprobe_event:将 probe 添加到全局列表中,并创建对应的uprobe debugfs目录,即上文示例中的p_test_0x764
当已经注册了 uprobe的 ELF 程序被执行时,可执行文件会被 mmap 映射到进程的地址空间,同时内核会将该进程虚拟地址空间中对应的 uprobe 地址替换成断点指令。当目标程序指向到对应的 uprobe 地址时,会触发断点,从而触发到 uprobe 的中断处理流程 (arch_uprobe_exception_notify),进而在内核中打印对应的信息
与 kprobe 类似,我们可以在触发 uprobe 时候根据对应寄存器去提取当前执行的上下文信息,比如函数的调用参数等。同时 uprobe 也有类似的同族:uretprobe。使用 uprobe 的好处是我们可以获取许多对于内核态比较抽象的信息,比如 bash中 readline函数的返回、SSL_read/write的明文信息等
拓展阅读:
Linux uprobe: User-Level Dynamic Tracing
Documentation/trace/uprobetracer.rst
Linux tracing - kprobe, uprobe and tracepoint
2.3 tracepoints
tracepont是内核中提供的一种轻量级代码监控方案,可以实现动态调用用户提供的监控函数,但需要子系统的维护者根据需要自行添加到自己的代码中
tracepoint 的使用和 uprobe 类似,主要基于 debugfs/tracefs的文件读写去进行实现。一个区别在于 uprobe 使用的的用户自己定义的观察点(event),而tracepoint使用的是内核代码中预置的观察点
查看内核(或者驱动)中定义的所有观察点:
$ cat /sys/kernel/debug/tracing/available_events
sctp:sctp_probe
sctp:sctp_probe_path
sde:sde_perf_uidle_status....random:random_read
random:urandom_read...
在 events对应目录下包含了以子系统结构组织的观察点目录:
$ ls /sys/kernel/debug/tracing/events/random/add_device_randomness credit_entropy_bits extract_entropy get_random_bytes mix_pool_bytes_nolock urandom_read
add_disk_randomness debit_entropy extract_entropy_user get_random_bytes_arch push_to_pool xfer_secondary_pool
add_input_randomness enable filter mix_pool_bytes random_read$ ls /sys/kernel/debug/tracing/events/random/random_read/enable filter format id trigger
以 urandom为例,这是内核的伪随机数生成函数,对其开启追踪:
$ echo 1 > /sys/kernel/debug/tracing/events/random/urandom_read/enable
$ echo 1 > /sys/kernel/debug/tracing/tracing_on
$ head -c1 /dev/urandom
$ cat /sys/kernel/debug/tracing/trace_pipe
head-9949 [006] .... 101453.641087: urandom_read: got_bits 40 nonblocking_pool_entropy_left 0 input_entropy_left 2053
其中trace_pipe是输出的管道,以阻塞的方式进行读取,因此需要先开始读取再获取/dev/urandom,然后就可以看到类似上面的输出。这里输出的格式是在内核中定义的
关闭trace 监控:
$ echo 0 > /sys/kernel/debug/tracing/events/random/urandom_read/enable
$ echo 0 > /sys/kernel/debug/tracing/tracing_on
根据Linux 内核文档介绍,子系统的维护者如果想在他们的内核函数中增加跟踪点,需要执行两步操作:
定义跟踪点
使用跟踪点
内核为跟踪点的定义提供了TRACE_EVENT宏。还是以 urandom_read这个跟踪点为例,其在内核中的定义在 include/trace/events/random.h:
#undef TRACE_SYSTEM#define TRACE_SYSTEM randomTRACE_EVENT(random_read,
TP_PROTO(int got_bits, int need_bits, int pool_left, int input_left),TP_ARGS(got_bits, need_bits, pool_left, input_left),
TP_STRUCT__entry(
__field( int, got_bits )
__field( int, need_bits )
__field( int, pool_left )
__field( int, input_left )
),TP_fast_assign(
__entry->got_bits = got_bits;
__entry->need_bits = need_bits;
__entry->pool_left = pool_left;
__entry->input_left = input_left;
),TP_printk("got_bits %d still_needed_bits %d "
"blocking_pool_entropy_left %d input_entropy_left %d",
__entry->got_bits, __entry->got_bits, __entry->pool_left,
__entry->input_left));
其中:
random_read:trace事件的名称,不一定要内核函数名称一致,但通常为了易于识别会和某个关键的内核函数相关联。隶属于random子系统(由TRACE_SYSTEM宏定义)TP_PROTO:定义了跟踪点的原型,可以理解为入参类型TP_ARGS:定义了”函数“的调用参数TP_STRUCT__entry:用于fast binary tracing,可以理解为一个本地 C 结构体的定义TP_fast_assign:上述本地 C 结构体的初始化TP_printk:类似于 printk 的结构化输出定义,上节中trace_pipe的输出结果就是这里定义的
TRACE_EVENT宏并不会自动插入对应函数,而是通过展开定义了一个名为 trace_urandom_read的函数,需要内核开发者自行在代码中进行调用。上述跟踪点实际上是在 drivers/char/random.c文件中进行了调用:
static ssize_turandom_read_nowarn(struct file *file, char __user *buf, size_t nbytes,
loff_t *ppos){
int ret;nbytes = min_t(size_t, nbytes, INT_MAX >> (ENTROPY_SHIFT + 3));
ret = extract_crng_user(buf, nbytes);
trace_urandom_read(8 * nbytes, 0, ENTROPY_BITS(&input_pool)); // <-- 这里
return ret;}static ssize_turandom_read(struct file *file, char __user *buf, size_t nbytes, loff_t *ppos){
unsigned long flags;
static int maxwarn = 10;if (!crng_ready() && maxwarn > 0) {
maxwarn--;
if (__ratelimit(&urandom_warning))
pr_notice("%s: uninitialized urandom read (%zd bytes read)\n",
current->comm, nbytes);
spin_lock_irqsave(&primary_crng.lock, flags);
crng_init_cnt = 0;
spin_unlock_irqrestore(&primary_crng.lock, flags);
}return urandom_read_nowarn(file, buf, nbytes, ppos);}<p data-line="541" class="sync-line" style="margin:0;"></p>
值得注意的是实际上是在urandom_read_nowarn函数中而不是urandom_read函数中调用的,因此也可见注入点名称和实际被调用的内核函数名称没有直接关系,只需要便于识别和定位即可。根据上面的介绍我们可以了解到,tracepoint相对于 probe来说各有利弊:
优缺点:
优点:对于参数格式有明确定义,并且在不同内核版本中相对稳定,
kprobe跟踪的内核函数可能在下个版本就被改名或者优化掉了缺点:需要开发者自己定义并且加入到内核代码中,对代码略有侵入性
另外,tracepoint除了在内核代码中直接定义,还可以在驱动中进行动态添加,用于方便驱动开发者进行动态调试,复用已有的 debugfs最终架构。这里有一个简单的自定义 tracepoint示例,可用于加深对 tracepoint使用的理解
拓展阅读:
LWN: Using the TRACE_EVENT() macro (Part 1)
Documentation/trace/tracepoints.rst
Taming Tracepoints in the Linux Kernel
2.4 Userland Statically Defined Tracing
Userland Statically Defined Tracing也称为USDT,即用户静态定义追踪。最早源于 Sun 的 Dtrace 工具,因此 USDT probe也常被称为 Dtrace probe。可以理解为 kernel tracepoint的用户层版本,由应用开发者在自己的程序中关键函数加入自定义的跟踪点,有点类似于 printf 调试法(误)
一个简单的示例:
#include "sys/sdt.h"int main() {
DTRACE_PROBE("hello_usdt", "enter");
int reval = 0;
DTRACE_PROBE1("hello_usdt", "exit", reval);}
DTRACE_PROBEn是 UDST (systemtap) 提供的追踪点定义+插入辅助宏,n表示参数个数。编译上述代码后就可以看到被注入的 USDT probe信息:
readelf -n表示输出 ELF 中 NOTE 段的信息
$ apt-get install systemtap-sdt-dev
$ gcc hello-usdt.c -o hello-usdt
$ readelf -n ./hello-usdt...Displaying notes found in: .note.stapsdt
Owner Data size Description
stapsdt 0x0000002e NT_STAPSDT (SystemTap probe descriptors)
Provider: "hello_usdt"
Name: "enter"
Location: 0x0000000000001131, Base: 0x0000000000002004, Semaphore: 0x0000000000000000
Arguments:
stapsdt 0x00000038 NT_STAPSDT (SystemTap probe descriptors)
Provider: "hello_usdt"
Name: "exit"
Location: 0x0000000000001139, Base: 0x0000000000002004, Semaphore: 0x0000000000000000
Arguments: -4@-4(%rbp)<p data-line="591" class="sync-line" style="margin:0;"></p>
在使用 trace 工具(如 BCC、SystemTap、dtrace) 对该应用进行追踪时,会在启动过程中修改目标进程的对应地址,将其替换为 probe ,在触发调用时候产生对应事件,供数据收集端使用。通常添加 probe 的方式是 基于 uprobe 实现的
使用 USDT 的一个好处是应用开发者可以在自己的程序中定义更加上层的追踪点,方便对于功能级别监控和分析,比如 node.js server 就自带了 USDT probe 点可用于追踪 HTTP 请求,并输出请求的路径等信息。由于 USDT 需要开发者配合使用,不符合我们的需求
注:USDT 不算是一种独立的内核监控数据源,因为其实现还是依赖于 uprobe
总结:如上所述了几种当今内核中主要的监控数据来源,基本上可以涵盖所有的监控需求。不过从易用性上来看,只是实现了基本的架构,使用上有的是基于内核提供的系统调用/驱动接口,有的是基于 debugfs/tracefs,对用户而言不太友好,因此就有了许多封装再封装的监控前端
拓展阅读:
Exploring USDT Probes on Linux
LWN: Using user-space tracepoints with BPF
2.5 ftrace
ftrace 是内核中用于实现内部追踪的一套框架,这么说有点抽象,但实际上我们前面已经用过了,就是 tracefs 中的使用的方法
在旧版本中内核中(4.1 之前)使用 debugfs,一般挂载到/sys/kernel/debug/tracing;在新版本中使用独立的 tracefs,挂载到/sys/kernel/tracing。但出于兼容性原因,原来的路径仍然保留,所以我们将其统一称为 tracefs
ftrace 通常被叫做function tracer,但除了函数跟踪,还支持许多其他事件信息的追踪:
hwlat:硬件延时追踪irqsoff:中断延时追踪preemptoff:追踪指定时间片内的 CPU 抢占事件wakeup:追踪最高优先级的任务唤醒的延时branch:追踪内核中的likely/unlikely调用mmiotrace:追踪某个二进制模块所有对硬件的读写事件……
Android 中提供了一个简略的文档指导如何为内核增加 ftrace支持,详见: Using ftrace
2.6 perf
perf 是 Linux 发行版中提供的一个性能监控程序,基于内核提供的 perf_event_open 系统调用来对进程进行采样并获取信息。Linux 中的 perf 子系统可以实现对 CPU 指令进行追踪和计数,以及收集kprobe、uprobe 和 tracepoints的信息,实现对系统性能的分析。
在 Android 中提供了一个简单版的 perf 程序 simpleperf,接口和 perf 类似
虽然,可以监测到系统调用,但缺点是无法获取系统调用的参数,更不可以动态地修改内核。因此,对于渗透测试而言作用不大,更多是给 APP 开发者和手机厂商用于性能热点分析。值得一提的是,perf 子系统曾经出过不少漏洞,在 Android 内核提权史中也曾经留下过一点足迹
2.7 eBPF
eBPF 为 extended Berkeley Packet Filter的缩写,BPF 最早是用于包过滤的精简虚拟机,拥有自己的一套指令集,我们常用的 tcpdump 工具内部就会将输入的过滤规则转换为 BPF 指令,比如:
$ tcpdump -i lo0 'src 1.2.3.4' -d(000) ld [0](001) jeq #0x2000000 jt 2 jf 5(002) ld [16](003) jeq #0x1020304 jt 4 jf 5(004) ret #262144(005) ret #0<p data-line="642" class="sync-line" style="margin:0;"></p>
该汇编指令表示令过滤器只接受 IP 包,并且来源 IP 地址为1.2.3.4。其中的指令集可以参考 Linux Socket Filtering aka Berkeley Packet Filter (BPF)
eBPF 在 BPF 指令集上做了许多增强(extend):
寄存器个数从 2 个增加为 10 个 (
R0 - R9)寄存器大小从 32 位增加为 64 位
条件指令
jt/jf的目标替换为jt/fall-through,简单来说就是 else 分支可以默认忽略增加了
bpf_call指令以及对应的调用约定,减少内核调用的开销… …
内核存在一个 eBPF 解释器,同时也支持实时编译(JIT)增加其执行速度,但很重要的一个限制是 eBPF 程序不能影响内核正常运行,在内核加载 eBPF 程序前会对其进行一次语义检查,确保代码的安全性,主要限制为:
不能包含循环,这是为了防止 eBPF 程序过度消耗系统资源(5.3 中增加了部分循环支持)
不能反向跳转,其实也就是不能包含循环
BPF 程序的栈大小限制为 512 字节
… …
具体的限制策略都在内核的eBPF verifier中,不同版本略有差异。值得一提的是,最近几年 Linux 内核出过很多 eBPF 的漏洞,大多是 verifier 的验证逻辑错误,其中不少还上了 Pwn2Own,但是由于权限的限制在 Android 中普通应用无法执行 bpf(2) 系统调用,因此并不受影响
eBPF 和 perf_event类似,通过内核虚拟机的方式实现监控代码过滤的动态插拔,这在许多场景下十分奏效。对于普通用户而言,基本上不会直接编写 eBPF 的指令去进行监控,虽然内核提供了一些宏来辅助 eBPF 程序的编写,但实际上更多的是使用上层的封装框架去调用,其中最著名的一个就是 BCC
2.7.1 BCC
BCC (BPF Compiler Collection) 包含了一系列工具来协助运维人员编写监控代码,其中使用较多的是其 Python 绑定。一个简单的示例程序如下:
from bcc import BPF
prog="""int kprobe__sys_clone(void *ctx) {
bpf_trace_printk("Hello, World!\\n");
return 0;}"""BPF(text=prog).trace_print()<p data-line="677" class="sync-line" style="margin:0;"></p>
执行该 python 代码后,每当系统中的进程调用 clone 系统调用,该程序就会打印 “Hello World” 输出信息。可以看到这对于动态监控代码非常有用,比如我们可以通过 python 传入参数指定打印感兴趣的系统调用及其参数,而无需频繁修改代码
eBPF 可以获取到内核中几乎所有的监控数据源,包括 kprobes、uprobes、tracepoints等等,官方 repo 中给出了许多示例程序,比如 opensnoop 监控文件打开行为、execsnoop 监控程序的执行
2.7.2 bpftrace
bpftrace 是 eBPF 框架的另一个上层封装,与 BCC 不同的是 bpftrace 定义了一套自己的 DSL 脚本语言,语法(也)类似于 awk,从而可以方便用户直接通过命令行实现丰富的功能,截取几条官方给出的示例:
<p data-line="691" class="sync-line" style="margin:0;"></p># 监控系统所有的打开文件调用(open/openat),并打印打开文件的进程以及被打开的文件路径<p class="mume-header " id="监控系统所有的打开文件调用openopenat并打印打开文件的进程以及被打开的文件路径"></p>bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'<p data-line="694" class="sync-line" style="margin:0;"></p># 统计系统中每个进程执行的系统调用总数<p class="mume-header " id="统计系统中每个进程执行的系统调用总数"></p>bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'<p data-line="696" class="sync-line" style="margin:0;"></p>
官方同样也给出了许多.bt脚本示例,可以通过其代码进行学习和编写
拓展阅读:
LWN: A thorough introduction to eBPF
Extending the Kernel with eBPF
https://www.opersys.com/downloads/cc-slides/android-debug/slides-main-211122.html#/
eBPF on Android
2.8 SystemTap
SystemTap (stab) 是 Linux 中的一个命令行工具,可以对各种内核监控源信息进行结构化输出。同时也实现了自己的一套 DSL 脚本,语法类似于awk,可实现系统监控命令的快速编程
使用 systemtap 需要包含内核源代码,因为需要动态编译和加载内核模块。在 Android 中还没有官方的支持,不过有一些开源的 systemtap 移植
注:还有许多开源的内核监控前端,比如 LTTng、trace-cmd、kernelshark等,内核监控输出以结构化的方式进行保存、处理和可视化,对于大量数据而言是非常实用的
拓展阅读:
Comparing SystemTap and bpftrace
那么Android 系统中,是否能直接套娃Linux 的一些解决方案,来对系统命令执行来做实现呢?笔者浅见,觉得应该可行,但不一定所有适用于Android,比如日志存储这块,Android 是阉割过的Linux系统,没有历史命令等日志存储的功能,除非定制化系统或Hook后将执行的命令转储路径保存
想实时对执行的命令进行监控,分析异常或入侵行为,有助于安全事件的发现和预防。命令执行的一些检测方法:
遍历
/proc目录,但无法捕获瞬间结束的进程Linux kprobes调试技术,并非所有Linux都有此特性,需要编译内核时配置修改
glic库中的execve函数,但是可通过int 0x80绕过glic库修改
sys_call_table,通过LKM(loadable kernel module)实时安装和卸载监控模块,但是内核模块需要适配内核版本
应用级:
So preload(用户态):
在ring3通过
/etc/ld.so.preload劫持系统调用二次开发
glibc加入监控代码基于调试器思想通过
ptrace()主动注入总结:在应用层做Hook的好处是不受内核版本影响,通用性较好,而且技术难度相对较低,但是缺点更明显,因为ring3层的Hook都是针对
glibc库做的监控,只要直接陷入int 0x80中断,即可绕过glibc库直接调用系统调用
内核级:
API Inline HookSyscall(sys_call_table) hookIDT Hook利用LSM (
Linux Security Module)Audit
Netlink Connector
API Inline Hook以及IDT Hook操作难度较大,而且兼容性较差,利用LSM监控API虽然性能最好,但是必须编译进内核才能使用,不可以实时安装卸载,而sys_call_table的Hook相对易于操作,作为防守方也可以直接从” /boot/System.map-uname -r”中直接获取sys_call_table地址,也可以利用LKM(loadable kernel module)技术实现实时安装卸载。如果选择修改sys_call_table中的execve系统调用来监控命令执行的入侵检测,虽然要适配内核版本,但能百分之100%检测到调用系统调用的命令执行,除非没有调用系统里面execve,而是用自行编写类似的程序
详情内容请移步「驭龙」Linux执行命令监控驱动实现解析:https://www.anquanke.com/post/id/103520#h2-1
2.9 内核模块介绍
模块是内核的一部分,但是并没有被编译到内核里面去。它们被分别编译并连接成一组目标文件, 这些文件能被插入到正在运行的内核,或者从正在运行的内核中移走。内核模块至少必须有2个函数:
int_module:第一个函数是在把模块插入内核时调用的cleanup_module:第二个函数则在删除该模块时调用
需要注意,由于内核模块是内核的一部分,所以能访问所有内核资源。根据对linux系统调用机制的分析,如果要增加系统调用,可以编写自己的函数来实现,然后在sys_call_table表中增加一项,使该项中的指针指向自己编写的函数,就可以实现系统调用
为什么要使用内核模块的方式添加系统调用?
编译内核的方式比较花费时间
不方便调试
注:编译内核,如果投入到Android 系统批量运营,定制化系统,要不然只是把其中一台Android系统编译好的内核模块在一个机子上运行成功后,如果移植到另外一个机子上马上就会出现错误,为什么呢?因为每个机子上sys_call_table的地址可能不一样。可以使用如下命令查看系统调用表sys_call_table的地址(虚拟地址)
cat /proc/kallsyms | grep sys_call_tables
需要注意,还有一个需要关注的就是预留的系统调用号,可以使用预留的系统调用号(my_syscall_num),如下(arch/x86/include/asm/unistd.h文件中查看预留的系统调用号,该预留的系统调用号为223):
#define my_syscall_num 223code
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/unistd.h>
#include <asm/uaccess.h>
#include <linux/sched.h>#define my_syscall_num 223
//如下的这个值要到你机子上查。cat /proc/kallsyms | grep sys_call_table
#define sys_call_table_adress 0xc1511160unsigned int clear_and_return_cr0(void);
void setback_cr0(unsigned int val);
asmlinkage long sys_mycall(void);int orig_cr0;
unsigned long *sys_call_table = 0;
static int (*anything_saved)(void);unsigned int clear_and_return_cr0(void)
{
unsigned int cr0 = 0;
unsigned int ret;
asm("movl %%cr0, %%eax":"=a"(cr0));
ret = cr0;
cr0 &= 0xfffeffff;
asm("movl %%eax, %%cr0"::"a"(cr0));
return ret;
}void setback_cr0(unsigned int val) //读取val的值到eax寄存器,再将eax寄存器的值放入cr0中
{
asm volatile("movl %%eax, %%cr0"::"a"(val));
}static int __init init_addsyscall(void)
{
printk("hello, kernel\n");
sys_call_table = (unsigned long *)sys_call_table_adress;//获取系统调用服务首地址
anything_saved = (int(*)(void)) (sys_call_table[my_syscall_num]);//保存原始系统调用的地址
orig_cr0 = clear_and_return_cr0();//设置cr0可更改
sys_call_table[my_syscall_num] = (unsigned long)&sys_mycall;//更改原始的系统调用服务地址
setback_cr0(orig_cr0);//设置为原始的只读cr0
return 0;
}asmlinkage long sys_mycall(void)
{
printk("This is my_syscall!\n");
return current->pid;
}static void __exit exit_addsyscall(void)
{
//设置cr0中对sys_call_table的更改权限。
orig_cr0 = clear_and_return_cr0();//设置cr0可更改//恢复原有的中断向量表中的函数指针的值。
sys_call_table[my_syscall_num] = (unsigned long)anything_saved;//恢复原有的cr0的值
setback_cr0(orig_cr0);printk("call exit \n");
}module_init(init_addsyscall);
module_exit(exit_addsyscall);
MODULE_LICENSE("GPL");
如下内容来自:https://www.freebuf.com/column/208928.html
2.10 So preload
基础知识:
Linux 中大部分的可执行程序是动态链接的,常用的有关进程执行的函数例如 execve均实现在
libc.so这个动态链接库中Linux 提供了一个
so preload的机制,它允许定义优先加载的动态链接库,方便使用者有选择地载入不同动态链接库中的相同函数
结合上述两点不难得出,我们可以通过 so preload来覆盖 libc.so中的 execve等函数来监控进程的创建
Demo
创建文件 hook.c ,内容如下:
#define _GNU_SOURCE#include <stdio.h>#include <unistd.h>#include <dlfcn.h>typedef ssize_t (*execve_func_t)(const char* filename, char* const argv[], char* const envp[]);static execve_func_t old_execve = NULL;int execve(const char* filename, char* const argv[], char* const envp[]) {printf("Running hook\n");printf("Program executed: %s\n", filename);old_execve = dlsym(RTLD_NEXT, "execve");return old_execve(filename, argv, envp);}
该文件的主要部分就是重新定义了 execve函数,在原始的 execve执行之前打印可执行文件的名字。
生成动态链接库:
gcc hook.c-fPIC-shared-o hook.so将上面生成的动态链接库注册成 preload :
echo'/path/to/hook.so'>/etc/ld.so.preload退出当前 shell 并重新登录(下面会讲原因),执行命令即可看到我们编写的代码已被执行:
使用条件
该方法没有什么条件限制,只需有 root 权限即可(做入侵监控程序 root 权限是必需的,后面的几种方法默认也都是在 root 权限下)
优点:
轻量级,只修改库函数代码,不与内核进行交互
缺点:对于使用方法的第四步,可能大家会有疑问:为什么一定要重新获取 shell 才可以看到效果呢?这是因为其实在当前 shell 下执行命令(也就是执行 execve)的实际上是当前的 shell 可执行程序,例如 bash ,而 bash 所需的动态链接库在其开始运行时就已确定,所以我们后续添加的 preload 并不会影响到当前 bash ,只有在添加 preload 之后创建的进程才会受 preload 的影响
只能影响在 preload 之后创建的进程,这就需要检测 Agent 安装得越早越好,尽量在其他应用进程启动之前就完成安装
无法监控静态链接的程序:目前一些蠕虫木马为了降低对环境的依赖性都是用静态链接,不会加载共享库,这种情况下这种监控方式就失效
容易被攻击者发现并篡改:目前一些蠕虫木马本身也会向
/etc/ld.so.preload中写入后门,以方便其对机器的持久掌控,这种情况下这种监控方式也会失效攻击者可通过 int80h绕过 libc 直接调用系统调用,这种情况下这种监控方式也会失效
2.11 Netlink Connector
Netlink 是什么,Netlink 是一个套接字家族(socket family),它被用于内核与用户态进程以及用户态进程之间的 IPC 通信,我们常用的 ss命令就是通过 Netlink 与内核通信获取的信息。
Netlink Connector是一种 Netlink ,它的 Netlink 协议号是 NETLINK_CONNECTOR,其代码位于 https://github.com/torvalds/linux/tree/master/drivers/connector中,其中connectors.c和 cnqueue.c是 Netlink Connector的实现代码,而 cnproc.c是一个应用实例,名为进程事件连接器,我们可以通过该连接器来实现对进程创建的监控
系统架构:
具体流程:
图中的 ncp 为 Netlink Connector Process,即用户态就是我们需要开发用来检测的程序
Demo
在 Github 上已有人基于进程事件连接器开发了一个简单的进程监控程序:https://github.com/ggrandes-clones/pmon/blob/master/src/pmon.c,其核心函数为以下三个:
nl_connect:与内核建立连接set_proc_ev_listen:订阅进程事件handle_proc_ev:处理进程事件
其执行流程正如上图所示,我们通过gcc pmon.c-o pmon生成可执行程序,然后执行该程序即可看到效果:
获取到的 pid 之后,再去 /proc/<pid>/目录下获取进程的详细信息即可
使用条件:
内核支持
Netlink Connector版本
> 2.6.14内核配置开启:
cat/boot/config-$(uname-r)|egrep'CONFIG_CONNECTOR|CONFIG_PROC_EVENTS'
优缺点:
优点:轻量级,在用户态即可获得内核提供的信息
缺点:仅能获取到 pid ,详细信息需要查
/proc/<pid>/,这就存在时间差,可能有数据丢失
2.12 Audit
Linux Audit 是 Linux 内核中用来进行审计的组件,可监控系统调用和文件访问
用户通过用户态的管理进程配置规则(例如图中的
go-audit,也可替换为常用的 auditd ),并通过 Netlink 套接字通知给内核内核中的 kauditd 通过 Netlink 获取到规则并加载
应用程序在调用系统调用和系统调用返回时都会经过 kauditd ,kauditd 会将这些事件记录下来并通过 Netlink 回传给用户态进程
用户态进程解析事件日志并输出
架构图如下:
Demo
从上面的架构图可知,整个框架分为用户态和内核态两部分,内核空间的 kauditd 是不可变的,用户态的程序是可以定制的,目前最常用的用户态程序就是 auditd ,除此之外知名的 osquery 在底层也是通过与 Audit 交互来获取进程事件的。下面我们就简单介绍一下如何通过 auditd 来监控进程创建
首先安装并启动 auditd :
apt update && apt install auditd
systemctl start auditd && systemctl status auditd<p data-line="973" class="sync-line" style="margin:0;"></p>
auditd 软件包中含有一个命名行控制程序 auditctl,我们可以通过它在命令行中与 auditd 进行交互,用如下命令创建一个对 execve这个系统调用的监控:
auditctl -a exit,always -F arch=b64 -S execve<p data-line="978" class="sync-line" style="margin:0;"></p>
再通过 auditd 软件包中的 ausearch来检索 auditd 产生的日志:
ausearch -sc execve | grep /usr/bin/id<p data-line="983" class="sync-line" style="margin:0;"></p>
整个过程的执行结果如下:
至于其他的使用方法可以通过man auditd和man auditctl来查看
使用条件:
内核开启 Audit:
cat/boot/config-$(uname-r)|grep^CONFIG_AUDIT
优缺点
优点:
组件完善,使用 auditd 软件包中的工具即可满足大部分需求,无需额外开发代码
相比于
Netlink Connector,获取的信息更为全面,不仅仅是 pid缺点:
性能消耗随着进程数量提升有所上升,需要通过添加白名单等配置来限制其资源占用
2.13 Syscall hook
Netlink Connector和 Audit 都是 Linux 本身提供的监控系统调用的方法,如果我们想拥有更大程度的可定制化,我们就需要通过安装内核模块的方式来对系统调用进行 hook
目前常用的 hook 方法是通过修改 sys_call_table( Linux 系统调用表)来实现,具体原理就是系统在执行系统调用时是通过系统调用号在 sys_call_table中找到相应的函数进行调用,所以只要将 sys_call_table中 execve对应的地址改为我们安装的内核模块中的函数地址即可
YSRC 的这篇关于驭龙 HIDS 如何实现进程监控的文章:
https://www.anquanke.com/post/id/103520#h2-5
关于 Syscall hook的 Demo ,我在 Github 上找了很多 Demo 代码,其中就包括驭龙 HIDS 的 hook 模块,但是这些都无法在我的机器上( Ubuntu 16.04 Kernel 4.4.0-151-generic)正常运行,这也就暴露了Syscall hook的兼容性问题
最后,决定使用 Sysdig 来进行演示,Sysdig 是一个开源的系统监控工具,其核心原理是通过内核模块监控系统调用,并将系统调用抽象成事件,用户根据这些事件定制检测规则。作为一个相对成熟的产品,Sysdig 的兼容性做得比较好,所以这里用它来演示,同时也可以方便大家自己进行测试,具体步骤如下:
通过官方的安装脚本进行安装:
curl-s https://s3.amazonaws.com/download.draios.com/stable/install-sysdig | sudo bash
检测内核模块是否已经安全:
lsmod|grep sysdig启动对 execve的监控:
sysdig evt.type=execve
最终的执行效果如下:
有关于 Sysdig 的更多信息可以访问其 wiki 进行获取,另外,Sysdig 团队推出了一个专门用于安全监控的工具 Falco ,Falco 在 Sysdig 的基础上抽象出了可读性更高的检测规则,并支持在容器内部署,同样,大家如果感兴趣可以访问其 wiki 获取更多信息
使用条件
可以安装内核模块
需针对不同 Linux 发行版和内核版本进行定制
优缺点:
优点:
高定制化,从系统调用层面获取完整信息
缺点:
开发难度
兼容性差,需针对不同发行版和内核版本进行定制和测试
2.13.1 四种方式总结
So preload:Hook 库函数,不与内核交互,轻量但易被绕过Netlink Connector:从内核获取数据,监控系统调用,轻量,仅能直接获取 pid ,其他信息需要通过读取/proc/<pid>/来补全单纯地看监控进程创建这方面,推荐使用
Netlink Connector的方式,此方式在保证从内核获取数据的前提下又足够轻量,方便进行定制化开发Audit:从内核获取数据,监控系统调用,功能多,不只监控进程创建,获取的信息相对全面单纯地看监控进程创建这方面,推荐使用
Netlink Connector的方式,此方式在保证从内核获取数据的前提下又足够轻量,方便进行定制化开发Syscall hook:从内核获取数据,监控系统调用,最接近实际系统调用,定制度高,兼容性差
2.14 小实验
【待补充,后面有空再补充一个实际案例的检测(其实主要是太菜了,不会弄 O(∩_∩)O哈哈~)】
下面命令中的路径在不同系统可能不同,即有些系统只有其中一个或两个都有,两个都有的话,功能其实都是一样的,如下:
/sys/kernel/tracing/sys/kernel/debug/tracing
博主这里用树莓派4做的测试,环境如下:
Android 10
如何刷树莓派为Android 10的教程,之前文章有发
树莓派4
root权限
adb shell 进入设备中,首先查看是否支持syscall调用的追踪,如果出现CONFIG_HAVE_SYSCALL_TRACEPOINTS=y那就说明支持,如下:
zcat /proc/config.gz | grep TRACEPOINT
执行下面两个命令,对系统调用之前的状态进行追踪,其中第一个需要root权限
echo 1 > /sys/kernel/debug/tracing/events/raw_syscalls/sys_enter/enable
echo 1 > /sys/kernel/debug/tracing/tracing_on
如果不想对系统调用之前的状态进行追踪的话,只需要改为0 即可,避免消耗系统性能,命令如下:
echo 0 > /sys/kernel/debug/tracing/events/raw_syscalls/sys_enter/enable
echo 0 > /sys/kernel/debug/tracing/tracing_on
相关的输出会保存到/sys/kernel/debug/tracing/trace,而默认有一个格式,执行命令查看:
head /sys/kernel/debug/tracing/trace
执行命令展示的结果表示会打印PID信息,可以过滤下PID,减少输出的日志信息。然后就是日志信息会实时输出到/sys/kernel/debug/tracing/trace_pipe中
查看指定PID的系统调用,下图中NR后面的数字就是系统调用号,命令如下:
cat /sys/kernel/debug/tracing/trace_pipe | grep 2351
上图中日志输出的格式,发现系统提供的比较简单,开发人员可以自行编写eBPF程序来解析参数来自定义自己想打印的系统调用详细情况日志格式。上图中日志输出的格式,可通过如下命令查看,:
cat /sys/kernel/debug/tracing/events/raw_syscalls/sys_enter/format
注:除了sys_enter,还有sys_exit,是系统调用结束后的状态,我们可以使用sys_enter开启的方式来开启sys_exit的系统调用追踪,执行如下命令即可开启sys_exit系统调用追踪的功能:
echo 1 > /sys/kernel/debug/tracing/events/raw_syscalls/enable
需要注意:
在
/sys/kernel/debug/tracing/events下面会有许多类型的事件,它们都可以通过向对应的enable管道写入配置,开启tracing_on,实现对应信息的追踪/sys/kernel/debug/tracing/events下面有许多文件夹,每个文件夹下可能还有文件夹如果向更高层级的文件夹的enable写入1,那么文件夹下的子文件夹的对应事件也会被开启记录,而
/sys/kernel/debug/tracing/events/enable则是最顶层的控制开关,如果向其中写入1,那么将记录所有内置的事件,此时就会输出非常多内容
2.15 基于 Patch Shell解释器的命令监控
如下内容来自:https://mp.weixin.qq.com/s/fx3ywEZiXEUStbrtzbpwrQ
基于 Patch Shell解释器的命令监控是基于execve的系统命令监控的补充方案,因为通过监控execve系统调用的方式,理论上可以完全覆盖系统命令的调用,那为什么还要 Patch Shell解释器呢?
大家别忘了,shell不仅可以调用外部系统命令,自身还有很多内置命令。内置命令是shell解释器中的一部分,可以理解为是shell解释器中的一个函数,并不会额外创建进程。因此监控execve系统调用是无法监控这部分的,当然能用作恶意行为的内置命令并不多,算是一个补充
如何判断是否是内置命令呢?通过type指令,示例如下:
[[email protected] ~]# type cd
cd is a Shell builtin[[email protected] ~]# type ifconfig
ifconfig is/sbin/ifconfig
完整的内置命令列表,请参考 shell内置命令:http://c.biancheng.net/view/1136.html
如何Patch Shell解释器 ? 原理很简单,对shell解释器的输入进行修改,将输入写入到文件中,进行分析即可。shell解释器很多,以bash举例:
通过
-c参数输入命令通过
stdin输入命令
在这两个地方将写文件的代码嵌入进去即可
2.16 绕过Patch Shell检测方法
对抗命令监控:
绕过Shell命令监控方法,使之收集不到命令执行的日志
无法绕过命令监控,但是能篡改命令执行的进程和参数,使之收集到假的日志
无法绕过监控,也无法篡改内容,猜测命令告警的策略并绕过(例如通过混淆绕过命令静态检测)
注:上面说的第一种和第二种方法算是比较根本的方法,没有真实的数据,策略模型就无法命中目标并告警,第三种方法需要较多的经验,但是通过混淆命令绕过静态检测策略,也是比较常见的
2.6.1 无日志-绕过Shell命令监控
已知的绕过命令监控的方案:用户态glibc/libc exec劫持,Patch Shell解释器,内核态的execve监控,均可被绕过
2.16.2 绕过glibc/libc exec劫持
方法1:
glibc/libc是linux中常用的动态链接库,也就是说在动态链接程序的时候才会用到它,那么我们只需要将木马后门进行静态编译即可,不依赖系统中的glibc/libc执行,就不会被劫持方法2:
glibc/libc是对linux系统调用(syscall)的封装,我们使用它是为了简化对系统调用的使用,其实我们可以不用它,直接使用汇编sysenter/int 0x80指令调用execve系统调用,下面是使用int 0x80调用execve syscall的简写代码:
mov byte al, 0x0b # 好了,现在把execve()的系统调用号11号放入eax的最下位的al中
mov ebx, esi # 现在是第一个参数,字符串的位置放入ebx
lea ecx, [esi+8] # 第二个参数,要点是这个参数类型是char **, 如果/bin/sh有其它参数的话,整个程序写法就又不一样了
lea edx, [esi+12] # 最后是null的地址,注意,是null的地址,不是null,因为写这是为了shellcode做准备,shellcode中不可以有nullint 0x80
或重写LD_PRELOAD环境变量,但这样的动作较大,容易被发现
2.16.3 绕过Patch Shell解释器
方法1:不使用shell解释器执行命令,直接使用execve
方法2:不使用被Patch的shell解释器,例如大家常用的bash被patch,那你可以使用linux另一个 tcsh解释器来执行命令
[[email protected]_0_13_centos ~]# tcsh -c
"echo hello"hello
2.16.4 绕过内核态execve syscall
只要使用了execve执行了命令,就绝对逃不过内核态execve syscall的监控,除非你把防御方的内核驱动给卸载了。既然如此,那怎么绕过呢?
方法1:不使用execve系统调用,自己写一个类似功能程序的代码来执行命令
方法2:假日志 - 混淆进程名与进程参数
混淆进程名
混淆进程参数
方法3:无"命令"反弹shell
2.16.4.1 方法2中的混淆进程名
在linux中有个syscall,名字叫做memfd_create (http://man7.org/linux/man-pages/man2/memfd_create.2.html)
memfd_create()会创建一个匿名文件并返回一个指向这个文件的文件描述符.这个文件就像是一个普通文件一样,所以能够被修改,截断,内存映射等等.不同于一般文件,此文件是保存在RAM中。一旦所有指向这个文件的连接丢失,那么这个文件就会自动被释放
这就是说
memfd_create创建的文件是存在与RAM中,那这个的文件名类似/proc/self/fd/%d,也就是说假如我们把ls命令bin文件使用memfd_create写到内存中,然后在内存中使用execve执行,那看到的不是ls,而是执行的/proc/self/fd/%d,从而实现了进程名称混淆和无文件
详细内容请前往该地址:http://www.polaris-lab.com/index.php/archives/666/
2.16.4.2 方法2中的混淆进程参数
使用的是linux中另一个syscall: ptrace。ptrace是用来调试程序用的,使用execve启动进程,相对于自身来说是启动子进程,ptrace的使用流程一般是这样的:
父进程
fork()出子进程,子进程中执行我们所想要trace的程序,在子进程调用exec()之前,子进程需要先调用一次ptrace,以PTRACETRACEME为参数。这个调用是为了告诉内核,当前进程已经正在被traced,当子进程执行execve()之后,子进程会进入暂停状态,把控制权转给它的父进程(SIGCHLD信号), 而父进程在fork()之后,就调用wait()等子进程停下来,当wait()返回后,父进程就可以去查看子进程的寄存器或者对子进程做其它的事情了
假如我们想执行ls-alh,在上文中ls已经可以被混淆了。接下来使用ptrace对 -alh进行混淆。大体的操作流程如下:
第一步:首先我们
fork出来一个子进程,然后在子进程中先调用ptrace,接着执行execve("ls xxxxxx"),这个时候基于execve监控到的就是一个假参数第二步:既然传入的是假参数,那肯定是是无法执行到想要的结果,这个时候父进程等待子进程
execve后停下来,然后修改传入参数的寄存器,将其修改为-alh,最后接着让子进程继续运行即可
详细内容请前往该地址:http://www.polaris-lab.com/index.php/archives/667/
Linux 内核分析的一些实操作业,某:https://.csdn.net/ts/
参考链接:
https://sq.sf.163.com/blog/article/311384915510648832
https://www.cnblogs.com/ronny/p/7789057.html
http://www.embeddedlinux.org.cn/html/jishuzixun/201101/06-1062.html
https://docs.huihoo.com/joyfire.net/6-1.html#Content
https://www.cnblogs.com/LittleHann/p/3854977.html
https://cloud.tencent.com/developer/article/1939486
http://blog.chinaunix.net/uid-27033491-id-3245321.html
https://www.anquanke.com/post/id/103520#h2-5
https://www.freesion.com/article/1205184276/
https://blog.csdn.net/youzhangjing_/article/details/124178417
https://evilpan.com/2022/01/03/kernel-tracing
https://blog.seeflower.dev/archives/88/
https://sniffer.site/2021/11/26/理解android-ebpf/
商务合作、进群添加官方微信
如有侵权请联系:admin#unsafe.sh