2022-8-13 21:15:16 Author: Ots安全(查看原文) 阅读量:29 收藏
关于漏洞
此漏洞允许网络相邻攻击者在多个 NETGEAR 路由器的受影响安装上执行任意代码。利用此漏洞不需要身份验证。该特定缺陷存在于 httpd 服务中,该服务默认侦听 TCP 端口 80。解析字符串文件时,该过程在将用户提供的数据复制到固定长度的基于堆栈的缓冲区之前未正确验证其长度。攻击者可以利用此漏洞在 root 上下文中执行代码。
( www.zerodayinitiative.com )
看完描述后,尝试使用 Bindiff,结合漏洞描述,在 http_d() 函数处撤销作用域。
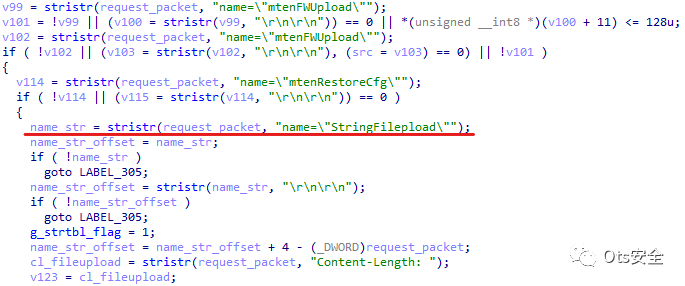
通过bindiff的流程图和IDA上的反编译代码,我发现String Table Upload的参数解析段被去掉了。
易受攻击的版本
补丁版本
我可以确定漏洞在字符串文件表上传中。经过一段时间的搜索,我发现了 Create_Hashtable() 函数中的漏洞。该漏洞发生在 gui_region 被复制到堆栈上的数组而没有事先检查大小时。
新创建错误
首先我将简单地谈谈字符串文件表上传。String File Table Upload用于上传语言、版本等配置文件,该函数提交的文件内容将由http_d()函数处理。
字符串文件表上传的内容
http_d() 函数将接收来自套接字的请求。检查请求是否针对文件上传功能。如果为true,将执行文件上传函数,否则将调用sub_10764() 函数。sub_10764() 负责解析 HTTP 请求、执行身份验证、调度请求等。
虽然这个版本已经去掉了strtblupload.cgi,但是我发现String File Table Upload的参数和其他上传文件函数的参数在同一个地方执行,没有检查URL是否正确。
看了httpd()函数的http请求的参数解析,发现可以利用upgrade_check.cgi函数进入String File Table Upload的参数解析。
我将编辑请求的某些部分,以便 http_d() 跳转到字符串文件表上传函数。
解析请求参数后,文件内容将分为header和body。标头包含 file_size 和校验和。
正文部分被复制到文件 /tmp/strtbl 然后重命名为 /tmp/strtbl.bz2 并通过文件检查。
完成后,文件被解压缩并带有 2 个主要参数:语言和版本。语言参数将被传递给 reloadHashTable()。
然后将调用 reloadHashTbl() 函数。该函数的主要功能是解析文件,为文件中的语言、版本等参数创建一个hash,创建一个单独的内存区域,并将这些参数的内容保存在相应的内存区域中。但是 reloadHashTbl() 函数在将参数内容保存到内存时不会检查大小,因此我可以通过语言参数将有效负载发送到 gui_region。
reloadHashTbl() 函数完成后, stringOut() 函数将用于获取存储在语言和版本的哈希字符串区域中的内容,然后将内容传递给 langSaveNvram() 函数以将语言的内容复制到 gui_region ,并将版本的内容放入 str_tbl_non_en_ver。现在我们的有效载荷位于 gui_region 中。
现在回到 reloadHashTbl() 函数。该函数将调用 Create_Hashtable() 函数。要到达漏洞位置,我将不得不发送另一个字符串文件表上传请求以重新进入此函数,然后我们的有效负载将从 gui_region 复制到堆栈,从而导致基于堆栈的缓冲区溢出。但在进入漏洞位置之前,我必须满足条件“multiLanguageReadLangTblMTD(v2) == -1”。
因为Create_Hashtable()函数调用了multiLanguageReadLangTblMTD()函数来检查条件来判断是创建默认的String File Table,还是使用我发送的文件。为了检查条件,mtdn_lang_name 中的内容将与传递给 reloadHashTable() 的语言参数进行比较以检查。
调用 Create_Hashtable() 之前的 reloadHashTbl() 函数会先调用 checkStringTblInMTD()。该函数将读取我们文件的内容,并将每种语言的 64 字节内容、版本参数分别复制到 mtd9_lang_name 和 mtd9_lang_version。
因此,为了满足我想要的条件,我只需要传输超过 64 个字节的任何字符。我终于确定了错误的位置和条件,现在让我们开始利用吧。
写作漏洞
由于以下几个因素,利用此堆栈溢出有点复杂:
+ httpd 的 NX 位已设置。
+ 设备 ASLR 设置为 1,表示栈和库地址不固定。
+ 溢出堆栈的副本是字符串副本。因此,如果遇到 NULL 字符,它将停止复制字符。因此,漏洞利用不能包含具有 NULL 字节的小工具。
首先,由于已经设置了 NX 位,我将不得不执行其他漏洞利用技术,例如 ret2libc。但是由于 ASLR 的存在并且没有堆栈地址泄漏,我们将更加难以找到正确的 ROP。Create_Hashtable()函数是一个漏洞函数,所以我会在这个函数刚刚执行完之后得到栈地址作为计算的基础。调试了一会,找到了我们发送文件时保存请求的地址。
我继续找出是否有一个 ROP 可以帮助我将 sp 寄存器调整到存储请求的内存区域。最初在解析请求期间,直到请求结束的文件内容将被 fwrite() 复制,所以我可以在这里传递任何字节。
搜索后我会得到地址 0x 009C640 作为 ROP1。
现在堆栈已经到了我想要的位置。接下来我会想办法利用sp寄存器的地址作为系统的参数。经过一段时间的搜索,我找到了地址0x009FB74,它可以帮助我将sp传递给r0并调用系统,这将是ROP2。
我无法像往常一样将语言参数与有效负载一起传递。如果内容长于64字节,就会进入错误位置,但是我们的String File Table会被替换为默认文件,导致gui_region包含了默认文件的内容。也就是说,我必须想办法让语言参数既包含有效载荷又满足小于65字节的条件。
正如我之前提到的,传递给 reloadHashTable() 函数的语言参数将在第一次解包后被解析。在查找语言参数的解析过程中,程序一直读取到文件末尾。所以我可以利用这一点来创建另一个包含 64 字节任意字符的语言参数。此外,对于包含有效负载的语言参数,我将删除字符字节 ' ' ',以便 stristr() 函数忽略包含有效负载的语言参数。
所以在解析时,会读取包含 64 字节字符的语言参数并将其传递给语言变量,我可以确定 Create_Hashtable() 函数将使用用户文件。但是还有一个问题,有两个这样的语言参数会导致为这两个参数创建两个内存区域。所以我需要查看将返回哪个参数的内容。在查看了 insertMultiLangugeHashTable() 函数后,我发现该函数将创建一个单链表来包含具有相同参数的内容。
在函数 getMultiLanguageStrByKey() 中,我可以很容易地看到列表的第一个参数将被检索。
因此,我会将带有有效负载的语言参数放在前面,然后将带有 64 字节字符的参数放在后面。所以我确保你提交的文件会被使用,并且payload仍然被写入gui_region。
由于会先读取gui_region,然后再写入新的内容,因此只有在发送第一个请求时才会将payload保存到gui_region。为了触发漏洞,我将发送第二个请求,这次读取 gui_region 时,它将包含我们的有效负载,导致基于堆栈的缓冲区溢出。另外因为我必须发送 2 个请求,所以包含请求的内存区域会发生变化,加上导致错误的函数是 strcpy()。所以我会在发送request1时将ROP1放在文件中,而ROP2将放在request2的末尾。
用户上传的字符串文件表中的ROP1
请求 2 中的 ROP2
用request2除了把ROP2放在请求的末尾外,我会留下大于64字节的语言参数的内容才能触发漏洞。
完成所有步骤后,我现在将继续编写 Python 脚本并运行它。
文章翻译自:
https://blog.viettelcybersecurity.com/netgear-r6700v3-1day-analysis-cve-2021-34982-buffer-overflow-rce-vulnerabiliy-2/
如有侵权请联系:admin#unsafe.sh