前言第一节已讲述了selenium的基本用法、如何定位元素等,这一节将继续围绕selenium进行展开。注:建议按顺序浏览:《Selenium自动化入坑指南一》一、鼠标控制既然是模拟浏览器操作,自然也 2022-8-22 17:10:55 Author: Tide安全团队(查看原文) 阅读量:30 收藏
前言
第一节已讲述了selenium的基本用法、如何定位元素等,这一节将继续围绕selenium进行展开。注:建议按顺序浏览:《Selenium自动化入坑指南一》一、鼠标控制
既然是模拟浏览器操作,自然也就需要能模拟鼠标的一些操作了, 在webdriver 中,鼠标操作都封装在ActionChains类中,常见方法如下
| 方法 | 描述 |
| click() | 单击左键 |
| context_click() | 单击右键 |
| double_click() | 双击 |
| drag_and_drop() | 拖动 |
| move_to_element() | 鼠标悬停 |
| perform() | 执行所有ActionChains中存储的动作 |
1.1 单击左键 click()
button = wd.find_element_by_xpath('//*[@id="toolbar-search-button"]/span') # 定位搜索按钮button.click() # 执行单击操作
1.2 单击右键 context_click()
鼠标右击的操作与左击有很大不同,需要使用 ActionChains 。
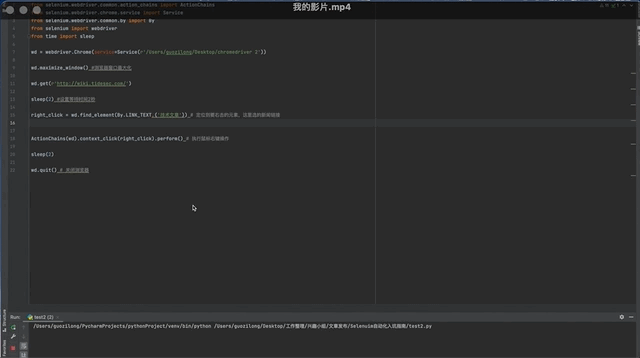
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))wd.maximize_window() #浏览器窗口最大化
wd.get(r'http://wiki.tidesec.com/')
sleep(2) #设置等待时间2秒
right_click = wd.find_element(By.LINK_TEXT,('新闻')) # 定位到要右击的元素,这里选的新闻链接
ActionChains(wd).context_click(right_click).perform() # 执行鼠标右键操作
sleep(2)
wd.quit() # 关闭浏览器
1.3 双击 double_click()
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))wd.maximize_window()
wd.get(r'http://wiki.tidesec.com/')
sleep(5)
# 定位到要双击的元素
double_click = wd.find_element(By.CSS_SELECTOR,('body .manual-list .list-item .manual-item-standard .author'))
# 双击
ActionChains(wd).double_click(double_click).perform()
sleep(3)
# 关闭浏览器
wd.quit()
1.4 拖拽 actions.drag_and_drop(start,end)
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))wd.maximize_window()
wd.get(r'https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
sleep(2)
wd.switch_to.frame('iframeResult')
# 开始位置
source = wd.find_element(By.CSS_SELECTOR,("#draggable"))
# 结束位置
target = wd.find_element(By.CSS_SELECTOR,("#droppable"))
# 执行元素的拖放操作
actions = ActionChains(wd)
#鼠标拖拽
actions.drag_and_drop(source, target)
#立即执行
actions.perform()
sleep(2)
# 关闭浏览器
wd.quit()
1.5 悬停 move_to_element()
为方便大家浏览,我将设立3个悬停点,每个悬停点等待时间为1秒
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))wd.maximize_window()
wd.get(r'http://poc.tidesec.com/')
# 定位悬停的位置
move = wd.find_element(By.CSS_SELECTOR,('body .contentbox .timelinebox .timeline_ul li:nth-child(4)'))
# 悬停操作
ActionChains(wd).move_to_element(move).perform()
sleep(1)
move = wd.find_element(By.CSS_SELECTOR,('body .contentbox .timelinebox .timeline_ul li:nth-child(5)'))
ActionChains(wd).move_to_element(move).perform()
sleep(1)
move = wd.find_element(By.CSS_SELECTOR,('body .contentbox .timelinebox .timeline_ul li:nth-child(6)'))
ActionChains(wd).move_to_element(move).perform()
sleep(1)
# 关闭浏览器
wd.quit()
二、模拟键盘操作
selenium中的Keys()类提供了大部分的键盘操作方法,通过send_keys()方法来模拟键盘上的按键。
第一步:引入Keys类
from selenium.webdriver.common.keys import Keys第二步:编写脚本执行操作
| 键盘操作 | 表达方式 |
| send_keys(Keys.BACK_SPACE) | 删除键(BackSpace) |
| send_keys(Keys.SPACE) | 空格键(Space) |
| send_keys(Keys.TAB) | 制表键(TAB) |
| send_keys(Keys.ESCAPE) | 回退键(ESCAPE) |
| send_keys(Keys.ENTER) | 回车键(ENTER) |
| send_keys(Keys.CONTRL,'a') | 全选(Ctrl+A) |
| send_keys(Keys.CONTRL,'c') | 复制(Ctrl+C) |
| send_keys(Keys.CONTRL,'x') | 剪切(Ctrl+X) |
| send_keys(Keys.CONTRL,'v') | 粘贴(Ctrl+V) |
| send_keys(Keys.F1) | 键盘F1 |
| ..... | ..... |
| send_keys(Keys.F12) | 键盘F12 |
简单实例演示:
以百度为例,下图将打开百度首页自动化获取第一条热搜,并执行键盘选定、复制、粘贴等操作
代码如下:
wd = webdriver.Chrome(service=Service(r'/Users/guozilong/Desktop/chromedriver 2'))
wd.maximize_window()
wd.get('http://www.baidu.com')
element = wd.find_element(By.CSS_SELECTOR,'.title-content-title')
ele = element.text
print(ele)
input = wd.find_element(By.CSS_SELECTOR,'#kw')
input.send_keys(ele)
input.send_keys(Keys.ENTER)
sleep(1)
input2 = wd.find_element(By.CSS_SELECTOR,'#kw')
input2.send_keys(Keys.COMMAND, 'a')
sleep(1)
input2.send_keys(Keys.COMMAND, 'c')
sleep(1)
input2.clear()
sleep(3)
input2.send_keys(Keys.COMMAND, 'v')
sleep(1)
input2.send_keys(Keys.ENTER)wd.quit()
注意:windows和mac的复制粘贴键盘热键不同,表格中是在windows下的书写格式,mac的直接将CONTRL替换成COMMAND就可以了,代码中展示的是在mac环境下运行的脚本
三、延时等待
现在部分web应用加载方式的选择,页面会需要一定时间逐渐加载完毕,也就是说有的页面元素先加载出来,有的元素后加载出来。如果直接定位所查找的元素的话,可能会由于此元素尚未加载完毕找不到元素从而报错,由于网络不稳定这种情况出现的几率会大很多。因此,为了解决这一问题,我们可以通过设置延时等待一段时间,来确保节点全部加载。
延时等待有三种方式:强制等待、隐性等待和显示等待
3.1 强制等待
强制等待的话,就像上文运用的那样,其两种书写格式如下
import time #插入模块
time.sleep(n) #强制等待n秒,在执行get方法后执行from time import sleep
sleep(n)3.2 隐性等待
implicitly_wait(),隐性等待设置了一个时间,在一段时间内网页是否加载完成,如果完成了,就进行下一步;在设置的时间内没有加载完成,则会报超时加载。
wd.implicitly_wait(n) #在开头设置过后,,整个的程序运行过程中都会有效3.3 显示等待
我们通过设置一个等待时间和一个判断条件,每隔一段时间就去检验一次该条件是否成立,如果成立就继续执行该程序,否则就会抛出超时异常(TimeoutException)。显示等待需要使用WebDriverWait,同时配合until或not until。格式如下
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)WebDriverWait的参数说明
•
driver:浏览器驱动•
timeout:超时时间,单位秒•
poll_frequency:每次检测的间隔时间,默认为0.5秒•
ignored_exceptions:指定忽略的异常,如果在调用until或until_not的过程中抛出指定忽略的异常,则终端代码,默认忽略的只有NoSuchElementExceptionuntil(method, message=’ ‘)
until_not(method, message=’ ')•
until_not:until_not 与until相反,until是当某元素出现或什么条件成立则继续执行,until_not是当某元素消失或什么条件不成立则继续执行•
message: 如果超时,抛出TimeoutException,并显示message中的内容•
method:指定预期条件的判断方法,在等待期间,每隔一段时间调用该方法,判断元素是否存在,直到元素出现。• 像
method中的预期条件判断方法是由expected_conditions提供,下面列举常用方法。
|方法|描述| |:--:|:--:| title_is(‘标题’)|判断当前页面的 title 是否等于预期 title_contains(‘字符串’)| 判断当前页面的 title 是否包含预期字符串| presence_of_element_located(locator)|判断元素是否被加到了 dom 树里,并不代表该元素一定可见| visibility_of_element_located(locator)|判断元素是否可见,可见代表元素非隐藏,并且元素的宽和高都不等于0| visibility_of(element)|跟上一个方法作用相同,但传入参数为 element| text_to_be_present_in_element(locator , ‘字符串’)|判断元素中的 text 是否包含了预期的字符串| text_to_be_present_in_element_value(locator , ‘某值’) |判断元素中的 value 属性是否包含了预期的字符串| frame_to_be_available_and_switch_to_it(locator)|判断该 frame 是否可以 switch 进去,True 则 switch 进去,反之 False| invisibility_of_element_located(locator)|判断元素中是否不存在于 dom 树或不可见| element_to_be_clickable(locator)|判断元素中是否可见并且是可点击的| staleness_of(element)|等待元素从 dom 树中移除| element_to_be_selected(element)|判断元素是否被选中,一般用在下拉列表| element_selection_state_to_be(element, True)|判断元素的选中状态是否符合预期,参数 element,第二个参数为 True/False| element_located_selection_state_to_be(locator, True)|跟上一个方法作用相同,但传入参数为 locator| alert_is_present()|判断页面上是否存在 alert
下面举个简单例子:
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))
wd.get('http://www.baidu.com')
element = WebDriverWait(wd,5,0.5).until(
EC.presence_of_element_located((By.ID,'kk')),message='已超时')
wd.quit()四、截图
selenium的截图操作,看了下网上的利用方式,大多数利用方式是在跑脚本过程中,在发生报错时对报错页面进行截图,从而更好进行分析。但在selenium更新4.0版本后,新增了元素截图的功能,使截图操作的功能使用还是很多样化的。其截图方法分为两种:页面截图和元素截图
4.1 页面截图
页面截图,顾名思义就是对其打开的浏览器页面进行截屏,就其利用方式就可以分为四种
•
wd.get_screenshot_as_base64(): 获取截屏的base64编码数据,在HTML界面输出截图时使用。•
wd.get_screenshot_as_png():获取获取二进制数据流•
wd.save_screenshot(filename/full_path):获取截屏png图片,参数是文件名称,截屏必须是.png图片, 如果只给文件名,截图会保存在项目的根目录下面。•
wd.get_screenshot_as_file(filename/full_path):获取截屏png图片,参数是文件的绝对路径,截屏必须是.png图片。如果只给文件名,截屏会存在项目的根目录下。
以百度为例:
from selenium import webdriver
from time import sleepwd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))
wd.get("https://www.baidu.com/") # 跳转至测试页面
sleep(1)
element = wd.find_element(By.ID,"kw") # 定位输入框
element.send_keys("自动化测试") # 输入内容
sleep(1)
wd.save_screenshot("baidu.png") # 截屏
sleep(2)
wd.quit() # 关闭浏览器
注意:save_screenshot的文件后缀名只能是png。get_screenshot_as_flie("文件路径"),与save_screenshot(‘filename’)功能相似。不过get_screenshot_as_flie("文件路径")可以指定文件路径,而save_screenshot(‘filename’)是默认在项目目录下生成图片。
4.2 元素截图
元素截图,可以实现有针对性的实施截取我们所需要的部分区域,并生成图片。
第一步:环境搭建
windows环境下,需要安装第三方pillow库,安装命令是
pip install pillow代码中,需要导入Image模组
from PIL import Image第二步:编写脚本
下面列举示例:wd = webdriver.Chrome(service=Service(r'/User/Desktop/chromedriver 2'))# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址
wd.get('http://app.sdsecurity.org.cn:8181')
sleep(2)
td =wd.find_element(By.ID,'container')
td.click()
sleep(2)
element =wd.find_element(By.CSS_SELECTOR,'#highcharts-0') #定位风险概况元素
print(element.location) # 打印元素坐标
print(element.size) # 打印元素大小
#wd.get_screenshot_as_file('/Users/Desktop/1.png')
#location方法获取元素坐标x,y,且以字典的方式返回
left = element.location['x']/0.2
top = element.location['y']/1.4
#size方法获取元素发的高度和宽度,以字典方式返回
right = (element.location['x'] *11+ element.size['width']-250)
bottom = (element.location['y']*1.3 + element.size['height']-200)
an =wd.find_element(By.CSS_SELECTOR,'[fill="url(#highcharts-4)"]')
sleep(2)
an.click()
sleep(2)
an.click()
ac = ActionChains(wd)
# 鼠标移动到 元素上
ac.move_to_element(
wd.find_element(By.CSS_SELECTOR, '[name="search-input"]')
).perform()
sleep(2)
png = wd.get_screenshot_as_png() #获取截图
im = Image.open(BytesIO(png)) #打开截图
mg =im.crop((left, top, right, bottom)) #获取风险概况模块截图
mg.save('/User/Desktop//TideSpire.png')
wd.quit()
print('截图成功')
五、文件上传&文件下载
5.1 文件上传
常见的 web 页面的上传,一般使用input标签或是插件(JavaScript、Ajax),对于input标签的上传,可以直接使用 send_keys(路径)来进行上传。我们先写个测试页面
<!DOCTYPE html>
<html lang="en"><head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<input type="file" name="">
</body>
</html>
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))
file_path = Path(Path.cwd(), 'upload.html') #获取终端所在的位置
wd.get('file:///' + str(file_path)) # 跳转至测试页面
sleep(2)
upload = wd.find_element(By.TAG_NAME,'input') #定位input标签
sleep(2)
upload.send_keys(str(file_path)) #注意:Path.cwd()是获取当前终端所在的工作目录,而不是文件所在路径。也可以直接调用send_keys(r'文件路径'),例如:
send_keys(r"d:\test.txt")有时候,javascript控制页面控件也会对input的标签进行隐藏,让我们无法进行事件点击,我们可以加上这段代码,更改其元素属性,让他正常显示。
wd.execute_script('arguments[0].style.visibility="visible"',ele2)
#arguments[0]表示第一个参数 #style.visibility="visible" 表示显示这个控件5.2 文件下载
文件下载的实现原理也很简单,无非也是锁定元素,执行点击操作。不同的是加上了指定下载路径这一环节。需要注意的是需要通过add_experimental_option添加prefs参数
•
download.default_directory:设置下载路径。•
profile.default_content_settings.popups:0禁止弹出窗口。以百度为例,示例代码:
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium import webdriver
from pathlib import Path
from time import sleepoptions = webdriver.ChromeOptions()
prefs = {'profile.default_content_settings.popups': 0, 'download.default_directory': '/Users/Desktop/'}
options.add_experimental_option('prefs', prefs)
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'),options=options)
wd.get(r'https://image.baidu.com/search/index?ct=201326592&z=&tn=baiduimage&ipn=r&word=%E5%A3%81%E7%BA%B8&pn=1&spn=0&istype=2&ie=utf-8&oe=utf-8&cl=2&lm=-1&st=-1&fr=&fmq=1526269427171_R&ic=0&se=&sme=&width=&height=&face=0&cs=3026382541%2C1862483045&os=1457557812%2C816750426&objurl=https%3A%2F%2Fgimg2.baidu.com%2Fimage_search%2Fsrc%3Dhttp%3A%2F%2Fup.enterdesk.com%2Fedpic%2Fdf%2F55%2F37%2Fdf5537f964e539b1596ec059a67fffa5.jpg%26refer%3Dhttp%3A%2F%2Fup.enterdesk.com%26app%3D2002%26size%3Df9999%2C10000%26q%3Da80%26n%3D0%26g%3D0n%26fmt%3Dauto%3Fsec%3D1661320478%26t%3Db562cc9dc42c06ae3c8cff2be42ae1c4&di=7108135681917976577&tt=1&is=0%2C0&cg=wallpaper&adpicid=0&gsm=3c') #随机挑选一张百度图片
sleep(1)
ele = wd.find_element(By.CLASS_NAME,'btn-download') #定位下载元素
ele.click()
sleep(3)
wd.quit()
六、窗口切换
我们很多时候都会用到窗口切换,比如:当我们点击注册按钮时,它一般会打开一个新的标签页,但实际上代码并没有切换到最新页面中,如果你要定位其新页面的标签,就会发现定位不到。handles =[]
handles.append(wd.current_window_handle) #获取当前窗口的句柄。这些信息的保存顺序是按照时间来的,最新打开的窗口放在数组的末尾,这时我们就可以定位到最新打开的那个窗口了。
# 切换到当前最新打开的窗口
wd.switch_to.window(windows[-1])示例代码:
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium import webdriver
from pathlib import Path
from time import sleep
handles = []
wd = webdriver.Chrome(service=Service(r'/Users/Desktop/chromedriver 2'))
wd.get(r'https://www.baidu.com')
sleep(1)
handles.append(wd.current_window_handle)
ele = wd.find_element(By.LINK_TEXT,'hao123')
ele.click()
sleep(3)
wd.switch_to.window(wd.window_handles[-1])
ele2 = wd.find_element(By.LINK_TEXT,'新华网')
ele2.click()
sleep(2)
handles.append(wd.current_window_handle)
print(handles) #返回
print(wd.window_handles) #返回当前浏览器的所有窗口的句柄,并输出结果
wd.quit()wd.switch_to.window(windows[-1]),其当前句柄也切换成了当前窗口句柄,这样也从而解决了进入新窗口而无法定位元素的苦恼七、总结
以上就是本节所有内容了,全是些入坑基础内容,方便小白快速入手,当然selenium的姿势还有进阶,入门的小伙伴在掌握了这些后,慢慢就会发现selenium的真正强大之处。
E
N
D
关
于
我
们
Tide安全团队正式成立于2019年1月,是新潮信息旗下以互联网攻防技术研究为目标的安全团队,团队致力于分享高质量原创文章、开源安全工具、交流安全技术,研究方向覆盖网络攻防、系统安全、Web安全、移动终端、安全开发、物联网/工控安全/AI安全等多个领域。
团队作为“省级等保关键技术实验室”先后与哈工大、齐鲁银行、聊城大学、交通学院等多个高校名企建立联合技术实验室,近三年来在网络安全技术方面开展研发项目60余项,获得各类自主知识产权30余项,省市级科技项目立项20余项,研究成果应用于产品核心技术研究、国家重点科技项目攻关、专业安全服务等。对安全感兴趣的小伙伴可以加入或关注我们。
如有侵权请联系:admin#unsafe.sh