每周文章分享2022.08.22-2022.08.28标题:Feature Trend Extraction and Adaptive Density Peaks Search for Intelli 2022-8-27 14:40:14 Author: 网络与安全实验室(查看原文) 阅读量:34 收藏
每周文章分享
2022.08.22-2022.08.28
标题:Feature Trend Extraction and Adaptive Density Peaks Search for Intelligent Fault Diagnosis of Machines
期刊:IEEE Transactions on Industrial Informatics, vol. 15, no. 1, pp. 105-115, Jan. 2019.
作者:Yanxue Wang; Zexian Wei; Jianwei Yang
分享人:河海大学——郑朝辉
01
研究背景
BACKGROUND
研究背景
机器在现代工业过程中发挥着重要作用,因此,机器的可靠性对整个工业过程至关重要。基于工业过程监控的不同有用信息,开发了各种方法来保证机器运行,如振动分析、声发射、温度趋势分析和磨损碎屑监控。然而,这些传统方法通常需要专业技能和丰富经验,这是劳动密集型的,非专家很难使用。因此,对能够自动、可靠和快速识别工业过程中的故障的智能故障诊断技术有着巨大的需求。
为了快速处理大量工业数据并自动检测有用的故障特征,在智能故障诊断领域进行了大量聚类或分类研究。然而,机械设备的故障样本有时实际上非常稀少。此外,标记错误数据样本是一项成本高昂的任务,通常需要经验和过程的先验知识。因此,仍然需要构建一个更加可靠、智能和自动化的机器状态监测和诊断程序。
02
关键技术
TECHNOLOGY
关键技术
本文提出了一种适用于工业过程监控的三阶段智能故障诊断方法。为提高识别精度和减少计算量,提出了一种基于变分模式分解的趋势检测和自重算法的特征处理方法。在此基础上,提出了一种自适应密度峰值搜索(ADPS)算法用于自适应聚类。本文的主要idea和关键技术:
1. 传统方案基于工业过程监控的不同有用信息来保证机器运行,例如振动分析,声发射,温度趋势分析和磨损碎片监视。然而,这些传统方法通常需要专业技能和丰富经验,这是劳动密集型的,并且非专业人员难以使用。
2. 针对迅速处理大量的工业数据并自动检测有用的故障特征,提出了一些方案,例如,k-means聚类,遗传算法,模糊c均值聚类算法,径向基函数网络。为了减少故障诊断中的人为介入操作并提高工业智能水平,基于改进的密度峰值搜索(DPS)算法开发了一种用于智能故障诊断的新技术。DPS使用局部密度最大的模式作为聚类中心,而不是使用常规权重。因此,它可以用于对不规则形状的数据集进行分类。
3. 本文采用变分模式分解(VMD)来提取特征样本的趋势。VMD是一种新的非递归信号分解算法,具有坚实的理论基础,可以将一个多分量信号自适应地分解为多个拟正交固有模态函数。
03
算法介绍
ALGORITHMS
算法介绍
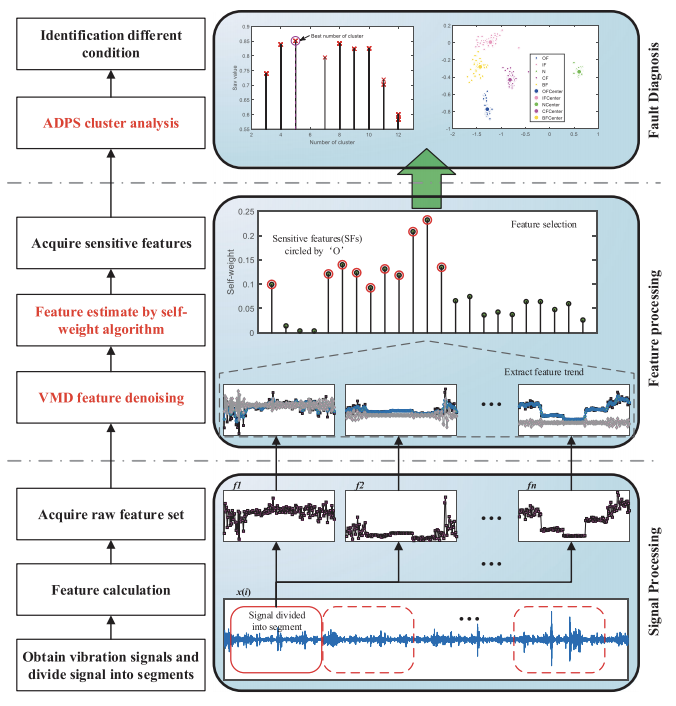
1. 整体步骤
(1)首先,将振动信号分为一系列段进行特征提取。
(2)在第二阶段,VMD和自加权算法分别用于减少离群特征的影响并提高计算效率。
(3)本文的ADPS用于第三阶段,可以自动识别故障类别。
图1 整体流程
2. DPS算法基于两个观察
(1)集群中心通常被局部密度较低的邻居包围,
(2)集群中心与局部密度较高的任何点的距离都比较大。
实际上,DPS为每个数据点计算两个度量:一个是局部密度分配,另一个是与其他密度更高的点的距离分配。DPS使用这两个度量来定位密度峰值或称为集群中心。
图2 DPS算法说明
3. 改进的ADPS算法
提出的新型ADPS算法是原始DPS的改进版本,可以自适应地搜索dc的合适值并返回最佳聚类结果。因此,可以自动进行定量分析以识别聚类中心,而不是定性分析。参数仍在ADPS算法中计算,但截止距离在ADPS算法中已由dc的函数代替,后者不再是常数。在此方法中,引入了Silhouette Validity Index 以使用不同的值评估每个相应的聚类结果。此外,可以通过软阈值识别邻居,如高斯核函数或简单硬阈值截止核函数。本文利用高斯核函数计算局部密度,以提高故障诊断的计算精度。
ADPS算法也是PAM方法之一,不需要任何训练过程,并且与基于监督学习的那些分类技术显著不同。因此,如果给出一个新样本,则所有样本(包括旧样本和新样本)都应使用ADPS算法再次进行聚类。然后,可以自动将新样本的标签分配给旧类别或成为新类别。
4. 基于VMD的特征趋势提取
为了提高聚类性能并减少计算负担,开发了一种新的特征处理技术,包括基于VMD的特征趋势提取和自加权算法。
本文采用VMD提取特征趋势。一方面,可以通过VMD极大地消除噪声或异常数据,另一方面,可以尽可能保留特征之间的差异。
图3 基于VMD的特征趋势提取过程
图4 使用ADPS的聚类分析
尽管通过基于VMD的特征提取增强了原始特征集,但特征数量并未减少。为了进一步减轻计算负担,应该选择那些主要的故障相关特征。自加权算法是先前开发的一种功能评估技术。它可以自适应地自我评估每个属性的贡献而无需类标签。因此,本文还采用自加权算法用于提取敏感特征。
04
实验结果
EXPERIMENTS
实验结果
1. 数据描述
1) 轴承故障数据集:振动信号是在MFS-MG试验台上获得的。在这种情况下,分别获取了外圈(OF),内圈(IF),保持架(CF)和球(BF)以及正常状态(N)上有缺陷的轴承的振动信号。由于此处使用五个不同条件来验证所提出技术的性能,因此群集数为5(NC = 5)。每个条件的原始振动信号首先被分为50个片段,其中包含4096个样本。
图5 MFS-MG试验台
图6 五种不同条件下的振动信号
2)齿轮故障数据集:进行齿轮的智能故障诊断以证明ADPS方法在风力涡轮机排水模拟器(WTDS)平台上的鲁棒性。收集四个故障情况下的齿轮振动信号,这些情况包括齿裂(Chip),齿根裂纹(Crack),齿缺(Missing)和齿面磨损(Surface)。
图7 WTDS实验平台
图8 齿轮的原始振动信号
2. 仿真结果
1)轴承故障数据集
由于阈值θ是ADPS算法中提到的最重要的参数,因此应首先对其进行研究。θ值太大会降低类别的区分度,因此在极端条件下所有数据点都将被分类为一个簇。但是,太小的θ值也不适合,特别是由于精细的区分,每个数据点都可以归类为一个簇。
图9 使用不同θ值的平均精度
根据实验,在本文的研究中,阈值θ被设置为1.5×10^-3。
由于阈值θ已经在前一步骤中确定,因此可以随后确定SF的数量。ADPS中使用的SF数量不合适会最终导致不良结果并影响聚类精度。但是,平均耗时也随着SF数量的增加而增加。
图10 使用不同SFs编号的平均精度
图11 通过α值确定SFs的数量
因此,可以将这些SF选为最大的前12个实体。然后将拟议的ADPS的群集性能与原始DPS ,AP群集和K-medoids 进行比较。
图12 使用四种方法对轴承数据集进行聚类分析
2)齿轮故障数据集
图13 使用不同θ值的平均精度
图14 使用四种方法对齿轮数据集进行聚类分析
按照与上一个仿真一样的步骤,先获取阈值θ,然后选取敏感特征的数量,最后将本文的ADPS算法与其他算法进行对比,体现了本文算法的优势。
表1 案例一和案例二的结果比较
05
总结
CONCLUSION
总结
1. 本文针对工业实际应用提出了一种新颖的三阶段智能故障诊断方法。开发了基于VMD的趋势检测技术和自加权算法相结合,以处理从原始振动信号中提取的时域和频域特征,以提高故障诊断性能并减轻计算负担。此外,提出了ADPS算法进行聚类,可以自适应地确定截止距离参数。
2.优点:本文主要针对故障检测提出了一种新的方案,本文的方案的重点就在于自适应的聚类算法中,本文通过聚类算法训练模型,然后将特征分类来进行故障诊断。本文的自适应的密度聚类算法能够适应不同的数据分布,也不局限于聚类形状,是一个比较好的算法,可以用于方案中。
3.缺点:本文的整体创新点就在于密度聚类算法,但是这个密度聚类算法是否可能出现集群数量多于故障类别的情况,该如何解释。并且如果出现类别数量不均衡的问题,是否会极大地影响聚类算法的精度。
END
扫描二维码关注我们
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh