每周文章分享2022.08.29-2022.09.04标题: Multi-Agent Deep Reinforcement Learning Based Cooperative Edge Cachin 2022-9-3 17:24:13 Author: 网络与安全实验室(查看原文) 阅读量:39 收藏
每周文章分享
2022.08.29-2022.09.04
标题: Multi-Agent Deep Reinforcement Learning Based Cooperative Edge Caching for Ultra-Dense Next-Generation Networks
期刊: IEEE Transactions on Communications, Vol. 69, no. 4, pp. 2441-2456, 2021.
作者: Shuangwu Chen, Zhen Yao, Xiaofeng Jiang, Jian Yang, Lajos Hanzo.
分享人: 河海大学——张帆
01
研究背景
BACKGROUND
研究背景
随着智能设备普及率的提高,移动数据流量呈爆炸式增长,这给蜂窝网络和主干网带来了沉重的流量负担。根据思科的报告,2017年至2022年,全球移动数据流量预计将增长7倍。为了适应不断飙升的流量需求,可以在下一代网络(NGN)中超密集部署小蜂窝基站(BS),使用户设备(UE)能够使用毫米波载波进行通信,这大大提高了无线信道容量,降低了功耗。然而,随着BS数量的增加,异构BS(如微微小区基站(PBS)、毫微微小区接入点(FAP))到主干网络之间的回程链路变得拥塞,给回程带宽带来了巨大压力。大部分回程带宽被一些流行内容的多次传输所占用。因此,移动边缘缓存正在成为一种很有前途的技术,它通过将一些流行内容缓存到网络边缘来减轻回程上的流量负担。因此,边缘缓存可以直接为请求相同内容的UE提供服务,这缩短了内容传输距离并减少了服务延迟。
然而,边缘缓存节点的大规模部署给分布式缓存的协作带来了额外的挑战。由于每个用户的独特偏好,不同BS中的内容流行度会呈现出一些时空差异,这要求每个BS运行唯一的流行度评估算法,该算法能够学习并做出其自身的缓存决策。然而,由于单个BS的存储容量有限,并且一些流行内容可能被多个BS冗余地缓存,从而降低缓存利用率。实际上,缓存的内容可以通过5G中的Xn接口在不同的BS之间共享,从附近的BS中获取内容的成本比从远程内容服务器中获取内容的成本低得多。此时,BS倾向于不缓存可以在附近BS中找到的流行内容,以便利用有限的存储容量来缓存一些其他内容,增强缓存多样性。然而,由于决策的同步性,每个BS只知道它自己的缓存决策,而不知道其他BS的决策。此外,不仅要决定在边缘缓存节点中缓存什么,还要决定在哪里缓存。因此,缓存动作的维度随着BS的数量和内容的增加而增加,这增加了问题的复杂性,使得在超密集下一代网络中协调海量BS以有效利用分布式边缘缓存资源变得更加困难。
现有的协作式边缘缓存的研究大多采用一种集中式算法来进行缓存决策,并且假设内容流行度分布是已知的。集中式缓存决策需要收集所有BS的信息,因此不适用于具有大量BS和内容的协作式边缘缓存问题。受人工智能(AI)领域最新进展的推动,最近的研究采用深度强化学习(DRL)方法来解决协作式缓存问题。然而,随着BS的数量和内容数量的增加,上述解决方案的计算复杂度急剧增加,BS之间的信息交换开销也急剧增长。
02
关键技术
TECHNOLOGY
关键技术
本文设计了一种分布式协作缓存算法来协调BS的缓存决策,降低了信息交换开销。由于UE的移动性,UE在穿越小区时可能无法完全下载整个内容。因此,可以采用一种编码缓存系统来解决这个问题,其中每个视频被分成多个数据段,必须决定在边缘缓存系统中缓存什么数据段、在哪里缓存数据段以及缓存多少个数据段。由于每个BS只知道其本地观测,因此将该问题表示为一个部分可观测马尔可夫决策过程(POMDP),该问题联合优化了从本地BS、从附近BS和从远程服务器中获取内容的成本。为了协调海量BS的缓存决策,设计了一个多智能体actor-critic框架,该框架提取了部分环境状态并在BS之间共享,而不是环境的全部状态。为了处理较大的状态和动作空间,提出了一种协作式边缘缓存算法,每个BS根据局部状态和全局状态做出自身的缓存决策。
本文的主要贡献包括:
1)将协作式边缘缓存问题描述为一个部分可观测马尔可夫决策过程(POMDP),优化目标是最大化所有边缘缓存器的累计折扣奖励;
2)设计了一个多智能体的actor-critic框架,引入了一个通信模块来提取和共享所有BS的动作和观察信息,而不是处理整个全局环境,这大大减少了智能体之间的数据交换;
3)考虑到内容流行度的时空动态特性,提出了一种基于变分递归神经网络(VRNN)的内容流行度估计算法,该算法无需任何用户偏好的先验知识即可进行学习。为了处理BS覆盖区域内UE的时变地理位置分布,提出了一种基于长短期记忆(LSTM)的接入状态估计模型;
5)在多智能体深度强化学习的基础上,考虑到每个智能体的分布式决策既依赖于局部状态又依赖于全局状态,提出了一种协作式边缘缓存算法,该算法的分布式决策降低了问题求解的复杂性。
03
算法介绍
ALGORITHMS
算法介绍
1. 网络模型
图1 网络模型
如图1所示,网络包括B个小小区,每个小小区包含一个BS,小小区中的UE以毫米波频率通信,它提供了高信道容量,但覆盖范围较短,所有BS都通过回程链路连接到NGN,每个BS都配备了存储设备,具有一定的存储容量,可以将一些热门内容缓存到BS上。UE可以通过核心网络从远程内容服务器中获取内容,或者从BS中获取内容。由于单个BS的存储空间有限,因此缓存的内容可以通过Xn接口在BS之间共享,即采用协作式边缘缓存。
2. 内容交付成本
图2 三种交付方式
如图2所示,主要有三种内容交付方式:
(a)如果所请求的内容已经缓存在本地BS中,则可以将它们直接递送到UE。设αb表示将一个数据段从本地BS b传输到UE的成本。假设BS b在时隙t期间已经缓存了rbb(t)个数据段。由此,本地BS的服务成本为αb* rbb(t);
(b)如果本地BS没有缓存所请求的内容,但是附近的BS缓存了,则可以通过在BS之间共享内容来满足用户请求。设βkb表示从附近BS k向本地BS b的UE发送一个数据段的成本。由于在BS之间传输内容需要消耗回程带宽,因此βkb>αb,假设在时隙t BS b已经中从BS k中提取了rkb(t)个数据段。因此,附近BS的服务成本为
(c)如果请求的内容没有缓存在BS中,则用户将从远程内容服务器获取它。假设θb表示将一个数据段从内容服务器传输到BS b的UE的成本,由于回程和核心网的资源消耗,因此θb>βkb。假设内容服务器的索引为0,在时隙t期间从内容服务器中提取了r0b(t)个数据段,则内容服务器的服务成本是θb* r0b(t)。
因此,在时隙t的总内容交付成本为:
此外,在决定更新其本地缓存之后,BS删除一些不太受欢迎的内容,并添加更受欢迎的内容。假设所有内容都是从内容服务器下载的。缓存替换可能会对核心网络施加额外的回程要求。因此,内容交付的总成本不仅应该包括从本地BS、附近的BS和内容服务器向UE传输数据的成本,而且还应该包括更新内容缓存放置的成本,即
其中δb表示更换BS b中的数据段的成本,[ ]+表示取绝对值。
3. 问题描述
由于下一个时刻的状态(包括内容缓存、内容请求和用户接入)只与当前时刻的状态和缓存决策有关,而与之前的状态无关,因此将该缓存问题描述为一个POMDP问题,其中,每个BS在时隙t开始时可以知道它的本地缓存放置cb(t)。然而,由于内容请求状态xb(t)和用户接入状态vb(t)是两个统计量,它们分别反映了在时间间隔[t, t+1]期间的内容流行度和用户分布,所以需要在时隙t结束时才能观察到它们。POMDP包括状态、动作、观察和奖励:
(1)状态:BS b在时隙t的局部状态sb(t)包括本地缓存状态、用户接入状态和内容请求状态;
(2)动作:BS b在时隙t决定分配给每个内容f的缓存大小(即数据段的数量),表示为ab,f;
(3)观察:在时隙t,BS不知道当前内容请求状态和用户接入状态,但是可以通过计算在时间间隔[t−1,t)期间的每个内容的请求数量、接入UE的数量和平均接入时间来获取它们在上一时刻的状态xb(t−1)和vb(t−1)。由于状态的时间依赖性,可以基于历史状态序列来估计用户接入和内容请求的当前状态。因此,观察值定义为在时隙t的本地缓存状态、用户接入状态估计和内容请求状态估计;
(4)奖励:通过将内容缓存在更接近用户的位置,可以降低内容交付的成本,降低的成本越高,边缘缓存就越有效。因此,可以将BS b的即时奖励定义为通过边缘缓存实现的成本节约,即:
4. 多智能体actor-critic协作式边缘缓存框架
图3 多智能体actor-critic协作式边缘缓存框架
如图3所示,本文提出了一种多智能体actor-critic协作式边缘缓存框架,该框架由三个模块组成:
(1)actor:每个智能体都有一个actor网络,该网络负责将状态(包括本地状态或由通信模块共享的全局状态)映射到动作。然而,本地接入状态和本地请求状态在作出缓存决策时并不知道。由于状态变化的时间相关性,可根据历史状态序列来估计当前状态。如图4所示,基于时间序列{xb(t−1), xb(t−2),.....}和{vb(t−1), vb(t−2),.....},设计了用于估计当前内容请求状态和当前用户接入状态的内容请求估计模型以及用户接入估计模型。根据这些状态,缓存决策模块将决定在本地BS中缓存哪些特定内容和多少个数据段。
(2)critic:一个集中式critic网络用于估计动作值函数,可以将critic网络部署在NGN的核心网络中,从而更容易地收集所有智能体的观察和动作。此外,采用critic网络的输出与实际奖励之间的误差来更新actor网络的参数;
(3)通信:由于智能体需要进行协作,因此,某个智能体的决策不仅要考虑其本地状态,而且要考虑全局状态,即其他智能体的观察和动作。本文设计了一个通信模块,用于收集和共享所有智能体之间的全局状态。然而,由于全局状态和动作空间的大小会随着智能体和内容的数量的增加而急剧增加,因此,通信模块必须对智能体的观察和动作进行编码来降低维数,此外,该通信模块也可以部署在NGN核心网中。
图4 每个actor网络的架构
图5 基于VRNN的内容请求预测
5. 内容请求状态估计
由于内容请求通常在时间上是连续的,因此内容请求状态的转移遵循一定的时间依赖性。因此,可以基于先前的状态序列来预测当前的内容请求。在本文的系统中,虽然内容请求xb(t)的当前状态在时隙t不是完全可观察的,但是先前时隙的状态,即{xb(t−1),xb(t−2),···}是确切已知的。然而,内容请求状态的维度与内容的数量成正比,因此难以采用标准RNN对高维序列数据的复杂可变性进行显式建模,因为标准RNN的条件输出概率模型通常基于简单的单峰分布。幸运的是,由于变分自动编码器(VAE)能够对包含多峰条件分布的数据进行建模,并且可以将VAE扩展为递归框架,因此VRNN能够对不同时间步下的输出变量之间的复杂关系进行建模。因此,采用了VRNN模型来估计请求状态。
如图5所示,在时隙t中,VAE可以将高维状态xb(t)的变化编码成一组潜在随机变量zb,从而提取xb的结构特征。然后,将相邻时隙上的潜在随机变量zb之间的时间相关性集成到RNN的隐藏层状态hb中。该模型主要包括四个步骤:(a)对观察到的状态进行编码;(b)更新隐藏层状态;(c)生成下一个潜在变量;(d)预测内容请求。
6. 用户接入状态估计
由于用户随机分布在BS的覆盖区域内,因此接入状态呈现出地理上的变化,每个BS使用一个学习模型来获得其唯一的接入状态变化。用户的位置和移动通常是基于他们的历史轨迹来预测的,这使得可以基于先前的状态序列{vb(t−1),vb(t−2),···}来估计当前接入状态vb(t)。考虑到接入状态只是二维的,可以采用简单的LSTM网络来对用户接入状态的动态变化进行建模,并捕捉状态转换中存在的时间依赖关系。
与传统的RNN一样,典型的LSTM网络具有由输入层、多个隐藏层和输出层组成的链式结构。不同的是,隐藏层是由输入门、遗忘门、多个记忆单元和输出门组成的记忆块。在LSTM中,输出值由神经网络的隐含状态所表示的当前输入和先前输入共同决定。在时隙t,先前的接入状态vb(t−1)被用作LSTM网络的输入,并且输出是对当前接入状态的估计。使用由BS收集的历史接入状态序列来预先训练LSTM模型,实际状态和预测状态之间的误差可用于更新权重参数W和U。
7. 基于多智能体actor-critic的协作式缓存决策
图6 多智能体actor-critic框架的训练过程
如图6所示,为了加快训练过程,通常使用历史数据集对模型进行训练,然后再将其部署到网络中。在时隙t中,智能体将其本地观察o(t)与每个actor所采取的动作a(t)一起发送给critic。在执行完动作之后,即时奖励R(t)和随后的观察结果o(t+1)将被反馈给critic。然后,通过最小化最小二乘时间差分来更新critic网络的参数;然后,通过最大化期望的长期回报来更新actor网络的参数;然后,通过最小化损失函数来更新通信模型的参数。
用于协作式边缘缓存的多智能体actor-critic网络的训练过程如下:首先,在给定历史用户请求轨迹的情况下,可以训练内容请求的VRNN模型和用户接入的LSTM模型;然后,生成E个样本轨迹,每个轨迹都有T个样本;最后,采用经验重放技术来更新critic网络、actor网络和通信网络的参数;当完成训练阶段后,在在线执行阶段,NGN核心网络采用训练好的通信网络,每个BS采用训练好的actor网络来做出决策。
04
实验结果
EXPERIMENTS
实验结果
1. 仿真设置
表1 仿真参数
本文的仿真参数如表1所示,本文的对比算法有三种:
1)最近最少使用(LRU):LRU算法将替换在最近时隙期间请求频率最低的缓存内容。每个BS独立运行一个LRU,用于其自身的内容替换,假设LRU一次可以为单个内容替换10个数据段;
2)深度强化学习(DRL):每个BS使用DDPG网络,并基于本地观察独立地做出缓存决策。为了适应分布式边缘缓存场景,将DRL模型的状态、动作和奖励定义为本文的actor网络的状态、动作和奖励;
3)多智能体actor-critic(MAAC):在MAAC中,每个BS的actor网络仅根据局部观察来决定内容放置,而critic网络用于估计动作的总回报。与本文提出的协作式多智能体actor-critic模型相比,智能体之间没有通信,因此actor网络的输入不包括全局状态。此外,actor网络仅仅是一个完全连接的神经网络,没有考虑内容请求和用户接入的时间动态。
2. 仿真结果
图7 所提出算法的收敛性能
图7展示了本文所提出算法的训练过程的收敛性能,其中(a)展示了critic网络的损失值,由图可知,损失值在1200回合之前迅速衰减,然后逐渐稳定下来。(b)展示了critic网络的输出值,随着训练的进行,输出值逐渐接近实际奖励,这与损失值曲线的变化是一致的。这表明算法在大约1200回合时收敛。
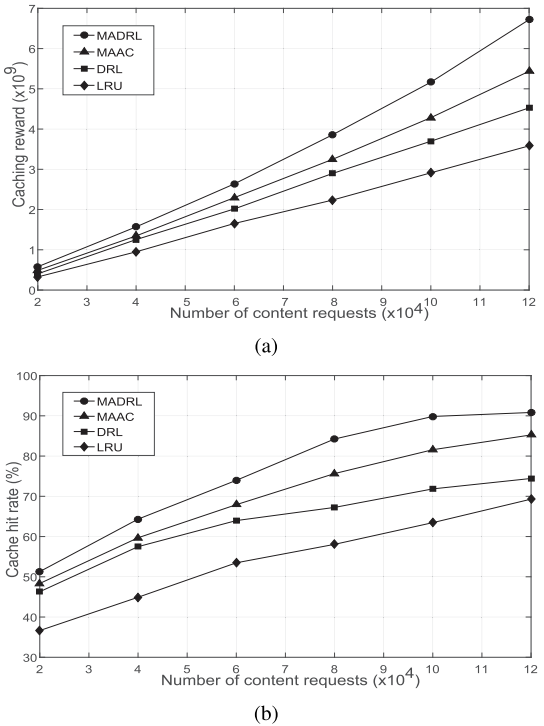
图8 在测试阶段四种算法的缓存奖励
图9 四种算法的平均缓存命中率
图8展示了在测试阶段四种算法的缓存奖励,由图可知,MADRL获得了最高的奖励,这表明MADRL可以很容易地协调BS,充分利用分布式的边缘缓存资源,从而为所有BS获得更高的奖励。与MADRL相比,MAAC也采用了多智能体的actor-critic框架,但各智能体之间没有通信。此外,MAAC使用一个简单的全连接神经网络作为actor网络,它不能显式地对观测状态的时变性进行建模。然后,通过将DRL与MADRL相比,可以发现边缘缓存之间的协作可以显著提高奖励,因为在DRL中每个BS的决策是完全独立的。此外,LRU的奖励保持不变,而其他算法的奖励略有变化,原因是基于学习的算法使用ε-贪婪策略来探索新的动作,这可能会导致奖励的微小扰动。
图9展示了在不同回合下四种算法的平均缓存命中率,由图可知,MADRL实现了最高的缓存命中率,这是因为MADRL可以通过在BS之间共享缓存的内容来使BS协同工作,避免了相同内容在不同BS中的冗余缓存,节省了边缘存储空间。相反,DRL和LRU独立地做出它们的缓存决策,因此BS会缓存重复的内容。它们可以在有限的边缘存储器中缓存比MADRL少得多的内容。同时,由于深度学习模型比启发式模型更好地刻画了内容流行度的变化,因此DRL比LRU具有更高的缓存命中率。此外,MAAC的缓存命中率略低于MADRL,这是因为MAAC中每个BS不考虑其他BS的决策,导致BS的冗余缓存,浪费有限的存储空间。
图10 从(a)本地BS, (b)附近BS, (c)内容服务器处发送的内容数据段比例
图10展示了四种算法从(a)本地BS, (b)附近BS, (c)内容服务器处发送的内容数据段比例,由图可知,在MADRL中,只有大约21%的数据段是从内容服务器传输的,这远远低于其他算法的56%、43%和34%,这意味着MADRL可以最大限度地利用边缘缓存资源来减少通过核心网络的内容检索。尽管MADRL(43%)从本地BS获取数据段的比例略低于DRL(45%),但使用MADRL从附近的BS获取数据段的比例(36%)远远高于使用DRL(12%)。这是因为在DRL中,每个BS在做出缓存决策时只考虑满足来自其本地用户的请求。相比之下,MADRL还考虑了BS之间的合作。
图11 在不同的BS缓存大小下四种算法的缓存奖励和缓存命中率
图12 在不同的内容请求数量下四种算法的缓存奖励和缓存命中率
图11展示了在不同的BS缓存大小下四种算法的缓存奖励和缓存命中率,由图11(a)可知,在增加BS的缓存大小时,四种算法的缓存奖励均增加,这是因为更大的边缘存储容量使BS能够缓存更多的内容,用户的请求更有可能由边缘缓存来满足。由图11(b)可知,在增加BS的缓存大小时,缓存命中率降低,这是因为较小的缓存大小只允许BS保留最流行的内容,因此缓存的内容更容易被用户请求,从而导致较高的缓存命中率。此外,随着缓存大小的增加,MADRL算法与其他算法之间的性能差距变得越来越大,具有较大缓存大小的BS可以保留更多的内容给其他BS,这促进了BS之间的内容共享。
图12展示了在不同的内容请求数量下四种算法的缓存奖励和缓存命中率,由图12(a)可知,缓存奖励随着内容请求数量的增加而增加,并且这些算法之间的性能差距变得更大,这是由于缓存奖励是所有内容请求的累计成本节约,因此请求的增加可能会导致成本节约的增加。由图12(b)可知,缓存命中率也随着内容请求的数量而增加,这是由于内容请求的生成服从流行度分布,因此,随着请求的数量增加,更有可能发生对具有低流行度的内容的请求。
05
总结
CONCLUSION
总结
本文将协作式缓存问题描述为一个POMDP,联合优化了从本地BS、附近BS和内容服务器获取内容的成本。为了解决这个问题,设计了一个多智能体actor-critic框架,该框架引入了通信模块来提取和共享BS之间的全局状态信息。考虑到内容流行度的时空动态特性和UE的移动性,提出了基于VRNN的内容请求估计模型和基于LSTM的用户接入估计模型。然后,提出了一种基于多智能体深度强化学习的协作式边缘缓存算法,每个BS根据局部状态和全局状态做出自己的缓存决策。实验结果表明,该算法促进了BS之间的协作,从而降低了回程链路上的流量负载,同时提高了边缘缓存的命中率。
END
扫描二维码关注我们
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh