分享独立开发、产品变现相关内容,每周五发布。
目录
1、Automa: 可视化设定模块使浏览器自动化插件2、Versoly: No-code在线创建产品页面3、Directual: No-code构建Web3 app平台工具4、ScrapingBee: 一个爬虫类产品,4个月做到月收入3000美元
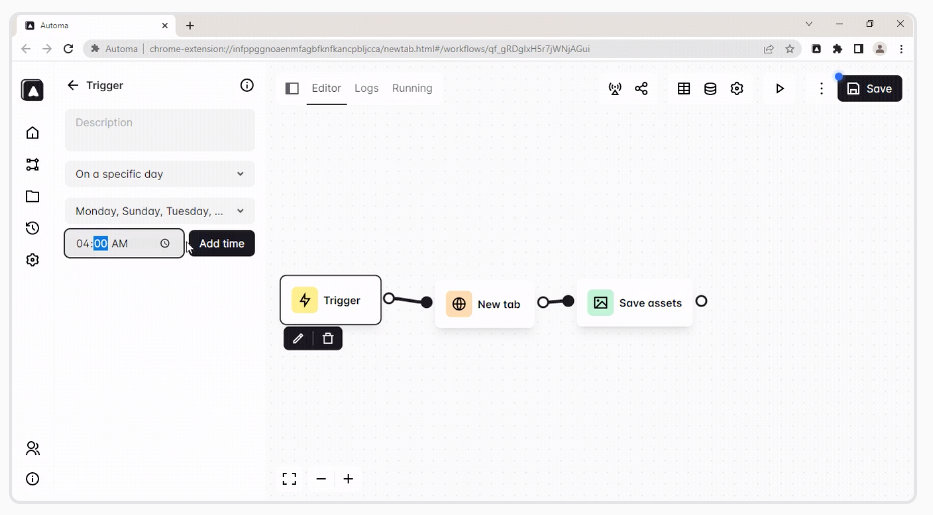
1、Automa: 可视化设定模块使浏览器自动化插件
通过连接块级自动化的浏览器的扩展插件。自动填写表格,做一个重复的任务,截取屏幕,或抓取网站数据,可以安排自动化执行的时间! 通过拖拽设定自动化任务。
这是一个开源软件,可以查看源码进行研究学习。

2、Versoly: No-code在线创建产品页面
No-code方式创建产品落地页,在线可视化编辑。10+现成模板,300+组件,通过在线拖拽即可,30分钟构建自己的网站产品页面页。更快的加载速度,支持响应式设计。 产品定价模式有免费和付费模式。

3、Directual: No-code构建Web3 app平台工具
Directual是一个无代码构建Web3的Dapp平台。允许构建惊人的web3-应用程序(与区块链集成)!
一个全栈的无代码平台:后端和前端。你完全不需要依赖第三方服务,通过拖拽方式构建业务逻辑。
- web3平台的一部分包括获取交易历史、执行交易、去中心化认证、与MetaMask集成、管理钱包等基本功能。
- Directual非常适合构建和扩展mvp到一个完整的产品,构建内部应用,创建数据库逻辑和聊天机器人。

4、ScrapingBee: 一个爬虫类产品,4个月做到月收入3000美元
Pierre是一个生活在法国的独立开发者,在过去的几个月里,他一直在和他的终身朋友Kevin一起构建产品。在两次产品尝试失败后,创建了ScrapingBee,这是一个web抓取API,为用户处理代理、chrome无头和验证码。如今,该工具每个月可以赚到3千美元,而且还在增加。

到2021年3月份的时候,月收入已经达到了约3万美金。

总收入也达到了1百万美金

大家好,我叫Pierre,今年27岁,住在法国巴黎。18个月前,我辞去了全职数据工程师的工作,和我的朋友 Kevin 一起做独立开发。
在尝试了很多东西之后,我们建立了ScrapingBee,一个处理代理、chrome无头和验证码的web抓取API。在此之前,我们尝试了许多不同的事情和业务。

ScrapingBee对于那些需要快速大规模抓取网络的人或公司特别有用,他们不想花太多的时间和精力处理这部分,而是专注于从数据中提取价值。它可能是某个需要为下一篇关于航空航天业的博客文章收集数据的人,或者是一家需要监控数千家餐厅在线评论的大公司。
起初,我们的API只返回你传递给它的任何URL的HTML,但最近我们推出了一个API存储,从特定的服务(如Instagram或谷歌)提取结构化数据。
我和Kevin都是全职的,而且是远程的。我们都有技术背景,一开始,我们都同样处理市场营销和产品任务。最近,Kevin负责销售/市场和运营方面的业务,而我负责技术/产品方面的工作。
你是如何想到这个想法的?
可以说,整个“ScrapingBee”的故事实际上开始于大约3年前,当时我和Kevin决定一起创建这个有趣的业余项目。我认识凯文已经15年了,早些时候,他通过向我展示他喜欢的网站和书籍,向我介绍了整个Startup和Indie Hacking生态系统。这激起了我的兴趣,我和Kevin经常谈论我们的创业想法。

问题是,我们只是在这里或那里谈论或编写一些小的东西,但我们从来没有真正推出什么东西。但三年前,我的女朋友给了我一个我觉得很有趣的想法:一种产品,可以让你把所有你想在网上购买的产品保存在一个地方,一旦它们打折,就会收到通知。我真的很喜欢这个想法,像往常一样,我和Kevin讨论了这个想法,我们决定把它做出来,这一次我们不会再犯我们在之前未完成的项目中犯的错误:
- 我们决定这次使用一个现成的模板代码,这样我们就不必从头开始处理代码登录、电子邮件验证和用户管理。
- 我们只实现了两个重要的功能:从网页上保存产品的Chrome扩展,一旦价格下降,就收到通知
- 即使并不完美,但还是要尽早发布。
那时,我在巴黎全职工作,Kevin正在写一本关于Java网页抓取的书。我们花了大约1个月的时间创建了ShopToList这个小产品,主要是在周末,并决定简单地将其发布在3个不同的Reddit子版块上。我记得这是一个专注于男性时尚折扣的reddit版块,我们很快达到了1000个赞,在大约4小时内我们就有了近600个用户。我们欣喜若狂,因为我们第一次创造了人们喜欢的东西,但更重要的是,人们会使用的东西!
接下来的一周是一些内容营销。我们还做了一个ProductHunt的发布,结果很顺利,但很快我们就意识到,虽然这款应用可能是个好主意,但靠它谋生是非常困难的,而靠我们的项目谋生一直是我们的目标。困难主要有三个原因:
- 产品是免费的,所以盈利将来自合作或广告,而这两种解决方案都需要庞大的用户基础才能盈利。
- ShopToList是一款B2C应用,我们还需要创造一款手机应用,并添加许多社交功能。
- 获取用户非常昂贵且困难,特别是在免费应用B2C市场,你的每新用户边际收益几乎为0。
许多ShopToList相似产品已经存在或曾经存在过,但似乎只有少数能够赚钱。
上线3个月后,我们决定搁置ShopToList。即使这不是一个百万美元的项目,我们也认为它是一个成功的项目,因为它向我们展示了Kevin和我都有能力合作,给了我们建立其他产品的信心。
几个月过去了,出于好奇,我们查看了ShopToList生产数据库,以了解我们的用户。我们想知道,平均来说,人们添加了多少产品,最著名的网站是什么……我们很快发现,在3000个用户中,几乎有12个用户各自添加了大约1000个产品!这是巨大的,特别是考虑到我们没有提供一种方式来“批量”添加的功能。这些用户实际上是电子商务所有者,他们在监视竞争对手的定价。我们和Kevin一起想,为什么不建立一个价格监控系统呢?这个想法在纸上看起来很不错,原因有很多:
- B2B比B2C更容易赚钱。
- 现在有很多价格监控工具,这意味着它有市场。
- 这些工具使用起来都非常非常复杂。
- 我们可以利用ShopToList用户找到我们的第一批客户。
我们的做法和往常一样,我们先建立一个登陆页面,然后在Facebook上的十二个群组中分享。我们在2个月的时间内创造了一款MVP,很快便在免费测试中吸引了150名用户。
在1月份,我们决定结束测试,并强制用户为产品付费。我仍然清楚地记得,在发送这封邮件10分钟后,我们迎来了第一批付费用户,一切都很顺利。
接下来的一个月,我们将通过测试不同的营销策略(主要是内容营销)来获得尽可能多的用户。我们的主要问题是转化率,它非常非常低,大约为1%(试验->客户)。从第一天开始,我们就知道营销是关键,让用户访问我们的网站是非常具有挑战性的。但我认为我们的一个错误是忽视了将用户转变为客户的难度。
我们尝试了很多方法来提高转化率,我们重新构建了平台,写了很多内容,打了很多电话,但都不起作用。我们看到了三个主要原因:
- 我们没有解释价格监控的价值。我们不太了解电子商务,这方面的知识匮乏是我们未能向用户解释PricingBot价值的关键原因。
- 由于用户必须将他们的产品与竞争对手进行匹配,所以使用过程漫长而乏味。我们提出收费,但没人愿意付钱。
- 我们一直不知道目标是谁。我们一直无法理解什么样的电子商务需要我们的工具。
- 所以基本上这都归结于我们对电子商务和电子商务知识的缺乏。今年6月,我们发现PricingBot永远不会取得我们希望的成功,于是决定做其他产品。
现在我要讲的是ScrapingBee。

Kevin和我都是技术人员,我们喜欢写代码和做东西。我们之前所有公司工作和业余项目的共同点都是网页抓取。我们做了很多,看到了许多需要解决的痛点。我们决定建立一个API来为你处理无头浏览器、代理和人机验证问题。
我们认为这是个好主意,因为:
- 网络抓取是一个竞争激烈的市场,如果你对它有疑问,只需在谷歌输入“网络抓取”,然后计算广告的数量,因为这意味着对它的需求很大。
- 这一次,我们知道了我们的客户是谁,以及如何接触到他们。
- 因为我们在抓取方面了解很多,所以我们有很多东西可以讲,而且我们对自己向潜在客户解释产品价值的能力很有信心。
你是如何创建ScrapingBee的?
在开发 ScrapingBee 的最初版本时,我们必须牢记两件重要的事情。首先,解决方案应该从第一天起就具有扩展性和成本效益。我们是一家100%白手起家的公司,我们承受不起亏损。其次,我们必须快速建立ScrapingBee,之前的项目PricingBot没有取得成功,我们不能在没有现金收入的情况下再花9个月。

考虑到这一点,我们利用我们的知识和过去的经验做出了最具成本效益和时间效率的选择。我们在应用的前端和账单管理部分复用了 PricingBot 应用程序代码。
我们把所有东西都部署在Heroku上,网络应用和数据库,唯一外部化的是Redis,因为我们需要很多并发连接,这在Heroku上是非常昂贵的。
这样做可以让我们在几天内得到一个可用的版本。但是我们有一个大问题,那就是在不花费大量资金的情况下,我们无法处理超过10个并发连接。原因是我们的API通过真正的Chrome浏览器请求URL,以便能够使用大量JavaScript抓取web应用。这些计算是非常消耗CPU的。我们基本上部署了一个Chrome无头类固醇在AWS lambda。我们现在可以随意扩展,因为AWS lambda可以授权多达1000个并发连接。AWS lambda的问题是它非常昂贵。为了缓解这一问题,我们向ProductHunt的支付了750美元的Pro年度计划,从而获得了5000美元的AWS积分。当然,这种解决方案只能工作一段时间,但它给我们留下了足够的时间来构建定制的可伸缩系统。

在代理方面,我们将自己的私有IP池与来自世界各地的几家代理提供商混合。
这是我们的主要产品。对于登陆页,感谢Landen,一个非常棒的登陆页构建器,我们只花了1个小时。在内部,我们大量使用Slack来进行Kevin和我之间的所有同步沟通,并将concept作为知识库+ CRM +项目管理工具+财务。这两种工具的通用性和质量都非常好用。
你的营销策略是什么?
我们的策略可以归结为:我们非常了解网页抓取和开发者的“世界”,所以让我们和他们谈谈网页抓取。当然,一开始,我们在几十家创业公司的网站上发布了ScrapingBee,但我们的核心战略是这样的。
我们把CTA放在我们的博客上,将流量重定向到ScrapingBee,还写了3篇(从我们的角度来看)非常成功的内容,每篇都有超过1万的浏览量:
- 一个关于如何抓取单页应用程序的小教程
- 关于网页抓取而不被阻塞的一般指南
- 使用Python进行web抓取的完整介绍
我们不相信为了内容营销而进行的内容营销。当然,写东西或花钱雇人帮你写东西很容易,每周写三篇没人读但谷歌会喜欢的内容。我们不想这么做,我们真的相信我们可以教给我们的读者一些东西,并希望把ScrapingBee卖给他们。这就是为什么我们每次写一篇文章都要花30个小时,这很耗时,但我们认为这是非常值得的,因为它提高了我们的SEO,带来了巨大的流量,并建立了我们的社区。

我们认为在这方面做得很好的一家公司是Ahref。如果你读他们的博客,你会学到很多关于SEO的东西,它实际上是有趣和深刻的内容,而不是营销的废话。
我们没有钱在Facebook或谷歌广告上做广告,如果你在谷歌中输入网页抓取,然后计算广告的数量,你可以想象每次点击的成本有多高。相反,我们在Facebook、Reddit、Dev.to、Hacker News和一些更小众的论坛上大量讨论网页抓取。我们并不总是提到“ScrapingBee”,但当我们提到它时,就能带来比较好的转化。
你未来的目标是什么?
截至目前,ScrapingBee的月收入为2900美元。但现在谈论成功还为时过早。我们的首要目标是能够以ScrapingBee为生。我们的目标是尽快达到这一点。对我们来说,这意味着达到5000美元。
我们的第二个目标是真正写出许多关于网页抓取的优秀内容,并在年底前完成我们的整个Python指南。我们也想建立一个关于网页抓取的社区。

我们也有一个API商店,我们希望通过支持越来越多的网站来开发,但在第二季度之前我们不会关注这一部分。基本上,我们希望专注于尽可能少的事情,并尽可能正确地完成它们。我们有太多的事情想要尝试和探索,但在一天结束的时候,只有24小时。因此,从现在开始,我们将只专注于内容营销和构建社区。
从个人的角度来说,Kevin和我都想证明自己,几年前离开公司是正确的选择。
你遇到的最大挑战和克服的障碍是什么?
到目前为止,我们在ScrapingBee上遇到的第一个最大的麻烦是一个法律问题。在早期,“ScrapingBee”被称为“ScrapingNinja”。我们在ProductHunt上发布了这个名字。在《PH》发行1个月后,我们收到了来自一家法国公司的电子邮件,声称拥有这个名称,并要求我们立即更改。这给我们带来了很大的压力,让我们失去了很多时间,以及大量的法律费用,因为我们必须在不到一个月的时间内完成整个品牌重塑。我们不得不告别我们所有的SEO努力,找到一个全新的名字,做好关于它的法律研究,找到一个新的标志和关于它的沟通。

我们是唯一要为这个错误负责的人,如果我们在发行前进行更彻底的品牌研究,我们就不会选择 ScrapingNinja。我们绝对不会再犯同样的错误。
第二个是积极方向的,我们在PricingBot上工作了8个月,发现什么都不管用,我们真的快要放弃了。我们认识一些人,他们无法很快放弃一个糟糕的商业想法,最终在公司呆了5年之久。我们最大的恐惧之一就是成为那些人中的一员。另一方面,我们知道创建一家新企业需要时间,你不应该指望一夜成名,因为这几乎不会发生。所以我们当时不知道是否要放弃也不知道我们是否会推出新产品。我们最终创建了ScrapingBee,我们最好从这种不确定性中构建一些东西,而不是仅仅是好奇。
你会推荐哪些学习资源?

关于市场营销,我极力推荐Gabriel Weinberg和Justin Mares的《Traction》。他们的基本观点是,在一开始,我们很容易浪费大量的时间和精力去尝试各种不同的获取渠道(搜索引擎优化、广告、内容营销等等)。你应该做的是找到一个有效的,或者足够有效的渠道,在探索其他解决方案之前,坚持使用它,充分利用它。我们尝试在ScrapingBee上做到这一点,它给了我们很大的帮助。
以上,本次周刊结束,欢迎留言交流,我们下周见!
如有侵权请联系:admin#unsafe.sh