2022-10-3 00:36:7 Author: bbs.pediy.com(查看原文) 阅读量:24 收藏
在线看glibc源码:https://elixir.bootlin.com/glibc/glibc-2.23/source/libio/
如果没有特别说明,下面涉及的源码和例子均是基于2.23版本。
1.1 结构体
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 |
|
1.2 关键函数分析
强烈推荐阅读下面几篇文章:
- fopen:
- fread:
fwrite:
fclose:
对 IO_FILE 相关几个关键函数的分析可见上面列出的文章。我在此做一点可能是对做题无关紧要的补充及疑问:
前面分析了
JUMP_FIELD,知道结构体_IO_jump_t中都是函数指针,但是这些函数指针在哪里被赋值去和它们对应的函数实现绑定的?是在做什么初始化的时候?在分析fread函数的时候,走到
fread -> _IO_sgetn -> _IO_XSGETN的时候,应该是因为这对做题可能关系不大,我看文章都没有分析宏_IO_XSGETN。- 在gdb中调试的时候,
_IO_sgetn -> _IO_XSGETN这一步仅三行汇编,而后跳转到_IO_file_xsgetn,但是对应的汇编却显示函数名是__GI__IO_file_xsgetn,我在后面静态分析代码的时候没有发现这是为什么,希望有知道的大佬告诉本菜鸡。
- 在gdb中调试的时候,
gdb调试走到调用宏
_IO_XSGETN的地方:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
- 静态分析
_IO_XSGETN宏
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
|
最后,总结一下上面提到的《IO FILE之fxxxx详解》四篇文章:
IO FILE结构体包括两个堆结构,一个是保存IO FILE结构体的堆,一个是输入输出缓冲区的堆。
- fopen调用链
1 2 3 4 5 6 7 8 9 10 11 12 |
|
- fread调用链
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
- fwrite调用链:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
- fclose调用链:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
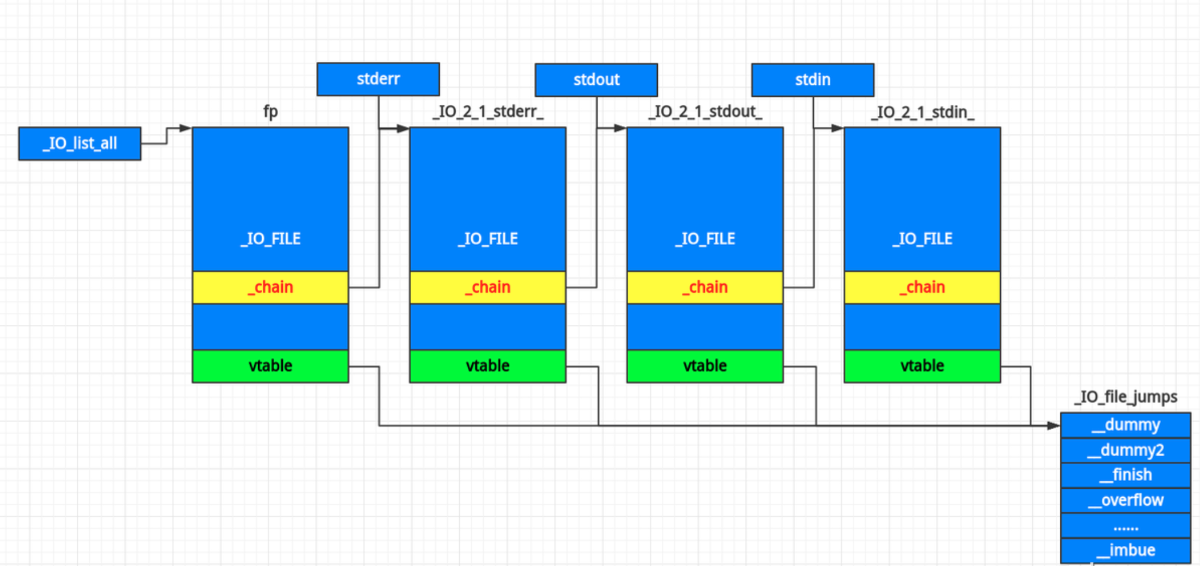
1.3 文件链表
通过_IO_FILE *_chain实现链表结构,头部是全局变量_IO_list_all

2.1 虚函数表vtable劫持
如果能够控制_IO_FILE_plus结构体,实现对vtable指针的修改,使得vtable指向可控的内存,在该内存中构造好vtable,再通过调用相应IO函数,触发vtable函数的调用,即可劫持程序执行流。
劫持最关键的点在于修改IO FILE结构体的vtable指针,指向可控内存。一般来说有两种方式:一种是只修改内存中已有FILE结构体的vtable字段;另一种则是伪造整个FILE结构体。当然,两种的本质最终都是修改了vtable字段。
- 攻击条件
- 有可控内存(视情况而定) -> 伪造FILE结构体
- 任意地址写 -> 修改vtable指针
例子可参考:
2.2 FSOP
FSOP(File Stream Oriented Programming)的核心思想就是劫持_IO_list_all 的值来伪造链表和其中的_IO_FILE 项,但是单纯的伪造只是构造了数据,还需要某种方法进行触发。FSOP 选择的触发方法是调用_IO_flush_all_lockp,这个函数会刷新_IO_list_all 链表中所有项的文件流,相当于对每个 FILE 调用 fflush,也对应着会调用_IO_FILE_plus.vtable 中的_IO_overflow。
_IO_flush_all_lockp被系统调用的时机当 libc 执行 abort 流程时
当执行 exit 函数时
当执行流从 main 函数返回时
_IO_flush_all_lockp中调用_IO_OVERFLOW的条件,根据短路原理可知需满足:fp->_mode <= 0fp->_IO_write_ptr > fp->_IO_write_base
1 2 3 4 5 |
|
- FSOP攻击条件
- 能泄露出libc的基址 -> 泄露出
_IO_list_all的地址 - 有可控内存 -> 伪造
_IO_FILE和vtable - 任意地址写 -> 将
_IO_list_all的内容改为指向可控内存的指针
- 能泄露出libc的基址 -> 泄露出
2.2.1 ctf实例 - ciscn_2019_n_7
1 2 3 4 5 6 7 8 9 10 |
|
ida分析
- main
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
|
- main开头的sub_CA0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
- add - 溢出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
- edit - 在add溢出后可任意地址写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
- show
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
- exit_
1 2 3 4 5 6 |
|
1 2 3 4 |
|
- 如果输入666,sub_C50打印puts函数的地址
1 2 3 4 5 6 |
|
fsop攻击思路:
exit_ 函数关闭 stdout、stderr 后执行 exit() ,exit() 时系统会调用
_IO_flush_all_lockp;或者随意输入一个不在菜单上的选项,让程序走main函数的return 0,也会调用_IO_flush_all_lockp(我用后一种思路成功了,前一种未找到原因,就是不成功)。修改article指针到
_IO_2_1_stderr_,布置绕过需要的数据;在适当位置写入 system ,将 vtable 劫持到这个空间上,完成劫持_IO_flush_all_lockp为 system 。- 写入
_IO_2_1_stderr_时将/bin/sh写到_IO_FILE的头部,调用虚函数时 _IO_FILE 是第一个参数。
因为 vtable 中的函数调用时会把对应的
_IO_FILE_plus指针作为第一个参数传递,因此这里我们把 "sh" 写入_IO_FILE_plus头部。调试查看结构体:
1
p*((struct [结构体类型]*) [地址])
调试分析
step1:泄露地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|

step2:通过add覆盖article指针
1 2 3 4 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
step3:通过edit修改_IO_2_1_stderr_的内容
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
- 修改前
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|
- 修改后
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
|
_IO_FILE结构体里_flags和_IO_read_ptr之间相差8字节,结构体会地址对齐
1
2
3
4
pwndbg> p &(stderr->_flags)
$8=(int*)0x7f9d0bb2b540<_IO_2_1_stderr_>
pwndbg> p &(stderr->_IO_read_ptr)
$9=(char**)0x7f9d0bb2b548<_IO_2_1_stderr_+8>
步骤4:触发exit ->_IO_flush_all_lockp -> __overflow
1 2 3 4 |
|
exp
- 人工计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
|
- 利用pwn_debug构造fake_file
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
|
< 2.26
原理为:堆溢出 + size(top chunk)<size(request) + unsorted bin attack + fsop
house of orange攻击的主要思路是利用unsorted bin attack修改_IO_list_all指针,并伪造_IO_FILE_plus结构体及其vtable(虚函数表)来劫持控制流。
利用过程
通过堆溢出漏洞把top chunk的size改小
通过申请一个比溢出修改后top chunk的size更大的chunk,使得top chunk进入unsorted bin,泄露出libc基址
通过
unsorted bin attack将_IO_list_all内容从_IO_2_1_stderr_改为main_arena+88/96(实则指向top chunk)在
old_top_chunk伪造_IO_FILE_plus结构体及其vtable(虚表)来劫持控制流
在
_IO_FILE_plus结构体中,_chain的偏移为0x68,而top chunk之后为0x8单位的last_remainder,接下来为unsorted bin的fd与bk指针,共0x10大小,再之后为small bin中的指针(每个small bin有fd与bk指针,共0x10个单位),剩下0x50的单位,从smallbin[0]正好分配到smallbin[4](准确说为其fd字段),大小就是从0x20到0x60,而smallbin[4]的fd字段中的内容为该链表中最靠近表头的small bin的地址 (chunk header),因此0x60的small bin的地址即为fake struct的_chain中的内容,只需要控制该0x60的small bin(以及其下面某些堆块)中的部分内容,即可进行FSOP。
- 利用条件
- 堆溢出漏洞
- 能修改top chunk的size
- 分配的chunk大小小于0x20000,大于top chunk的size
- top chunk大小大于MINSIZE
- top chunk的inuse等于1
- top chunk的大小要对齐到内存页
- 能修改bk ->unsortedbin attack -> 任意地址写 -> 修改
IO_list_all的内容 - 能在top chunk伪造
IO_FILE和vtable
- 能修改top chunk的size
- 能泄露chunk的内容 -> 泄露libc某个地址 -> 泄露出
_IO_list_all的地址
- 堆溢出漏洞
3.1 how2heap
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
|
调试分析
泄露_IO_list_all的地址
1.分配一个chunk
1 2 |
|
1 2 3 4 5 6 7 8 |
|
2.溢出修改top chunk的size
1 2 3 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
3.malloc一个更大的chunk时,将top chunk释放到unsortedbin中
1 2 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
heap的变化如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
4.泄露出_IO_list_all的地址
1 2 |
|
1 2 |
|
为unsortedbin attack作准备
回顾unsortedbin attack,从unsorted bin中取出chunk时,会执行以下代码:
1
2
3
4
5
6
7
8
9
10
11
for(;; )
{
intiters=0;
while((victim=unsorted_chunks (av)->bk) !=unsorted_chunks (av))//将最后一个chunk(victim)取出
{
bck=victim->bk;//bck为倒数第二个chunk
......
/*removefromunsortedlist*/
unsorted_chunks (av)->bk=bck;//若发生攻击,则unsortedbin的bk设置成了改写的victim->bk
bck->fd=unsorted_chunks (av);//把倒数第二个chunk的fd设置为unsorted_chunks(av)
......所以,如果将victim的bk改写为某个地址,则可以向这个地址+0x10(即为bck->fd)的地方写入unsortedbin的地址(&main_arena+88)
5.为unsortedbin attack作准备,将old top chunk的bk指针为 io_list_all - 0x10
1 2 |
|
1 2 3 |
|
为fsop作准备
回顾fsop:
_IO_flush_all_lockp中调用_IO_OVERFLOW的条件,根据短路原理可知需满足:
fp->_mode <= 0fp->_IO_write_ptr > fp->_IO_write_baseFSOP攻击条件
- 能泄露出libc的基址 -> 泄露出
_IO_list_all的地址(满足)- 有可控内存 -> 伪造
_IO_FILE和vtable(无法控制main_arena中的数据)- 任意地址写 -> 将
_IO_list_all的内容改为指向可控内存的指针(满足)
6.为fsop作准备
前面unsortedbin attack可将_IO_list_all指针的值修改为main_arena+88。但这还不够,因为我们很难控制main_arena中的数据,并不能在mode、_IO_write_ptr和_IO_write_base的对应偏移处构造出合适的值。
所以将目光转向_IO_FILE的链表特性。_IO_flush_all_lockp函数会通过fp = fp->_chain不断的寻找下一个_IO_FILE。
所以如果可以修改fp->_chain到一个我们伪造好的_IO_FILE的地址,那么就可以成功实现利用了。
巧妙的是,_IO_FILE结构中的_chain字段对应偏移是0x68,而在main_arena+88对应偏移为0x68的地址正好是大小为0x60的small bin的bk,而由于我们能通过溢出漏洞改old top chunk的size,所以在将其链入smallbin[0x60]之后,就可以实现如下图所示的攻击链。

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
|
发起攻击
1 2 3 4 5 6 7 8 9 |
|
7.unsortedbin attack实施
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
|
8.查看修改top[1] = 0x61;的结果:unsortedbin所在地址 + 0x68(smallbin[0x60]->bk)变成&old_top_chunk
前面通过溢出将位于unsorted bin中的chunk(old top chunk的部分)的size修改为0x61。那么在这一次malloc的时候,因为在其他bin中都没有合适的chunk,malloc进入大循环,把unsorted bin中的chunk插入到对应的small bin或large bin中。第7步是将old_top_chunk从unsortedbin脱下来,接下来就是将其插入0x60大小的smallbin中了。同时,该small bin的fd和bk都会变为此chunk的地址。
大循环里将从unsortedbin脱下来的chunk插入smallbin的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
接着步骤7,单步调试,走到mark_bin (av, victim_index);:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
继续单步调试,走完bck->fd = victim;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
|
此时,IO_list_all、IO_FILE(main_arena+88)、IO_FILE(old_top_chunk)三者已经链接起来了,接下来就只需要触发_IO_flush_all_lockp -> __overflow就可以了。
9.触发_IO_flush_all_lockp
for循环结束一次,接着进行第二次循环。由于unsortedbin attack的时候破坏了unsorted bin的链表结构,所以接下来的分配过程会出现错误,系统调用malloc_printerr去打印错误信息,从而被劫持流程,执行到winner,然后由winner执行system函数:
1 2 3 4 5 6 7 8 9 10 |
|
调试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
|
victim的size为0,不满足要求,触发异常,调用malloc_printerr (check_action, "malloc(): memory corruption", chunk2mem (victim), av);, 从而调用_IO_flush_all_lockp,进而fsop攻击成功。
3.2 ctf实例 - house of orange
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
ida分析
- main
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
|
- input_number
1 2 3 4 5 6 7 8 9 |
|
- build_house:build一个house,会创建三个chunk
- 最多能build4个house
- 每个house包含一个orange和一个name
- 每个orange包含price和color
- 创建chunk的顺序:house、house_name、orange

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
|

- input_string
1 2 3 4 5 6 7 8 9 10 11 12 |
|
- see_house:打印house的信息
- 打印house name
- 打印 orange price
- 打印橘子

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
- upgrade_house:更新house的信息
- 可以更新house name
- 可以更新orange 的price和color
- 最多只能更新3次

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
漏洞
- input_string函数中存在信息泄露漏洞
- 创建chunk的顺序:house、house_name、orange
- 因为input_string是用在house_name_chunk上的,所以调用see_house函数的时候可以泄露出name后面的内容
- upgrade_house函数中存在堆溢出漏洞
- 同样,是在输入house_name的时候存在溢出漏洞,所以可以溢出修改house_name_chunk后面的数据
思路
- 没有free
- 存在任意长度的堆溢出,能泄露chunk的内容
- 观察一下house of orange的利用条件:
- 堆溢出漏洞
- 能修改top chunk的size(满足)
- 分配的chunk大小小于0x20000,大于top chunk的size
- top chunk大小大于MINSIZE
- top chunk的inuse等于1
- top chunk的大小要对齐到内存页
- 能修改bk ->unsortedbin attack -> 任意地址写 -> 修改
IO_list_all的内容(满足) - 能在top chunk伪造
IO_FILE和vtable(满足)
- 能修改top chunk的size(满足)
- 能泄露chunk的内容 -> 泄露libc某个地址 -> 泄露出
_IO_list_all的地址(满足)- 能泄露哪里的内容?
- name字符串后面的内容
- name后面是否可能有libc中某个地址?
- 当从unsortedbin里的old top chunk切割一个fastbin/smallbin大小的chunk给name的时候,name的fd/bk指向unsortedbin(main_arena+88)
- 当从unsortedbin里的old top chunk切割一个largebin大小的chunk给name的时候,name的fd/bk指向largebin头,fd_nextsize/bk_nextsize指向name本身
- 能泄露哪里的内容?
- 堆溢出漏洞
调试分析
泄露_IO_list_all的地址
1.溢出修改top chunk的size
1 2 3 4 5 6 7 8 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
2.malloc一个更大的name chunk时,将top chunk释放到unsortedbin中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
|
总结一下此时heap的变化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
3.再build一个house,泄露出_IO_list_all的地址:
- 先malloc一个house_chunk(固定为0x20大小),先unlink old_top_chunk(很大,属于largebin),其fd和bk为unsortedbin的地址,然后切割一部分出来给用户。但是fd和bk后来会被覆盖为orange和name的地址;
- 接着malloc一个name_chunk,同样先unlink old_top_chunk(很大,属于largebin),其fd和bk为对应largebin的地址,fd_nexesize和bk_nexesize指向old_top_chunk,然后切割一部分出来给用户。如果name_chunk足够大,输入的name字符串足够小,那么切割以后就会保留bk、fd_nextsize和bk_nextsize。
- 如果输入name字符串的时候为8个字节(包括回车符),那么在打印name的时候,就可以把此largebin链表头的地址给泄露出来,从而可计算得到libc基址,进而得到
_IO_list_all/system等的地址。
1 2 3 4 5 6 7 8 9 10 11 |
|
当分配name3的时候,若申请的大小为largebin范围,由于old top chunk属于largebin范围,所以会先将其插入到largebin中,如下代码所示:
- victim(old top chunk)的
fd_nextsize和bk_nextsize指向本身(切割后要变成name3) - victim(old top chunk)的fd和bk指向此largebin链表头
- 下面这段代码结束以后,会从largebin将victim(old top chunk)unlink下来,并切割,但是不会再对切割下来的name3的fd/bk/fd_nextsize/bk_nextsize再做操作了,所以只要输入的name字符串够短,就会保留
bk/fd_nexesize和bk_nextsize,然后在后面泄露出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
|
由上面的分析可知,当要分配的chunk属于smallbin大小范围(包括fastbin和smallbin)的时候,走完if (in_smallbin_range (nb) &&...这个判断的时候,就会切割old top chunk并返回给用户,name3不会有指向自身fd_nextsize/bk_nextsize。所以需要name3申请的大小为largebin大小。
当分配name3的时候,单步调试上面代码,走到bck->fd = victim;的时候看一下各变量的值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
|
再总结一下此时heap的变化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
泄露heap地址
由于fd_nextsize保留下来了,所以利用upgrade输入0x10个字符,并调用see,也就可以泄露出name3的地址,从而计算heap的地址。为后面修改vtable作准备。
1 2 3 4 5 6 7 8 9 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
|
unsortedbin attack和fsop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 |
|
[2022冬季班]《安卓高级研修班(网课)》月薪两万班招生中~
最后于 11小时前 被ztree编辑 ,原因:
如有侵权请联系:admin#unsafe.sh