每周文章分享2022.10.03-2022.10.09标题: Cooperative Multi-Agent Reinforcement Learning Based Distributed Dyna 2022-10-8 16:26:13 Author: 网络与安全实验室(查看原文) 阅读量:33 收藏
每周文章分享
2022.10.03-2022.10.09
标题: Cooperative Multi-Agent Reinforcement Learning Based Distributed Dynamic Spectrum Access in Cognitive Radio Networks
期刊: IEEE Internet of Things Journal, vol. 9, no. 19, pp. 19477-19488, 1 Oct.1, 2022.
作者: Xiang Tan, Li Zhou, Haijun Wang, Yuli Sun, Haitao Zhao, Boon-Chong Seet, Jibo Wei, and Victor C. M. Leung.
分享人: 河海大学——郭依萍
01
研究背景
BACKGROUND
研究背景
未来的网络将涉及到万物互联。无线设备,如智能手机、可穿戴健身记录仪、智能家居设备和各种传感器,都在争夺无线频谱,而且它们的数量正在激增。根据思科预测,到2023年,连接IP网络的设备数量将达到293亿。到2030年,对无线接入的需求可能会增加到比现在大250倍。然而,频谱资源几乎已被充分分配,频谱管理机制缺乏效率。有限的可用频谱很难满足无线应用日益增长的需求。
然而,在一定时期内,一些已分配的频段利用率不高,而另一些频段利用率过高,浪费了大量的频谱容量,加剧了频谱的稀缺。因此,开发一种灵活、高效的无线频谱接入模式来满足日益增长的海量无线设备的需求是未来无线通信的关键问题。动态频谱接入技术(DSA)使用户可以根据自己的需求灵活地访问可用的频谱,是解决当前频谱效率低下问题的一种有前景的技术。鉴于机器学习的潜在优势,本文尝试提出一种智能DSA技术。
02
关键技术
TECHNOLOGY
关键技术
本文研究了一个典型的多信道认知无线电网络中多用户的分布式DSA问题。该问题被描述为一个分散的部分可观测马尔可夫决策过程(Dec-POMDP),本文提出了一个基于协作多智能体强化学习(MARL)的集中离线训练和分布式在线执行框架。本文采用DRQN来解决每个认知用户状态的部分可观测性。最终目标是学习一种合作策略,该策略可以在不需要认知用户之间交换信息的情况下,以分布式方式最大化认知无线网络的总吞吐量。
该方法的创新和贡献如下:
1)本文将多用户的多通道访问问题建模为一个马尔可夫过程。即本文将多用户的DSA构造为一个分布式可观测马尔可夫决策过程(Dec-POMDP)。为了使网络的成功接入率最大化,本文将协作频谱接入建模为一个合作博弈,并采用MARL来解决分布式多用户频谱接入问题。
2)为了解决分布式访问策略的不稳定性和不合理性,本文提出了一种集中式的训练和分散执行(CTDE)体系结构,在集中训练阶段根据全局状态信息评估联合动作价值,认知用户仅根据部分观测信息做出访问决策条件。CTDE体系结构可以利用新兴移动边缘计算技术的优势进行。
3)本文提出了一种基于协同多智能体强化学习的多用户分布式频谱接入算法,即CoMARL-DSA。通过该算法,每个认知用户都可以根据自己的局部观测进行访问决策,不需要与其他认知用户进行信息交换,大大减轻了通信开销,保证了动作的实时性。
03
算法介绍
ALGORITHMS
算法介绍
1. 系统模型
图1 系统模型
本文研究了一种基于OFDM的认知无线网络,它与具有K个正交信道的主网络共存。认知用户会利用频谱漏洞。将整体可用频率带宽划分为K个大小相等的正交子信道,OFDM信道所跨越的带宽小于信道相干带宽。本文认为认知网络是一个完全同步的时隙系统,时间用t进行时隙和索引,每个时隙有一个固定的持续时间。将时隙长度设计为与信道相干时间相匹配,使信道状态信息在时隙内保持不变。每个认知用户都会在时隙的开始访问这些通道,并一直坚持到时隙结束。如图1所示。系统由初级层和认知层组成,其中初级层由初级基站及其关联的PUs组成,而认知层包括次级接入点(AP)及其关联的认知用户,即认知Tx-Rx对。认知用户分散在初级BS的传输范围内,所有认知用户都位于地理位置接近的区域,彼此之间具有感知距离(即全连接无线网络)。
为了保证系统的可扩展性和鲁棒性,本文假设认知无线网络中不存在中央控制器。为了提供集中的离线培训,本文在认知无线网络的边缘(即无线AP或认知基站)部署了一个参数服务器。参数服务器是专门用于训练的,不参与频谱访问决策。
2. 问题构想
在上述系统模型的基础上,将分布式多用户DSA问题建模为合作马尔可夫决策过程。考虑到认知用户感知能力有限,且不具备网络动态的先验知识,可以将协作频谱访问建模为一个由元组给出的Dec-POMDP模型, G =⟨N, S, {An}n∈N, P, {rn}n∈N, {Zn}n∈N, {On}n∈N, γ⟩。
图2 信道占用的双态马尔可夫模型
图3 时隙结构
1)状态切换模式:在多用户协同共享可用信道的认知无线网络中,每个认知用户在每个时隙首先从K个信道中选择M(0≤M≤K)个信道进行感知,然后选择一个空闲信道进行接入。每个通道有两种状态:空闲(1)或繁忙(0),其状态转换遵循双状态马尔可夫链,记为Pk = [p00 p01 p10 p11],如图2所示。信道状态在每个时隙开始切换,并在该时隙持续时间内保持不变。
认知用户采用LBT (Listen-Before-Talk)机制访问频谱。在每个时间段的最开始,每个认知用户选择M个通道进行感知。如果感知信道中有多个空闲信道,则认知用户选择一个空闲信道来传输数据包。在该时隙结束时,如果认知用户收到了来自相应接收方的ACK,则表示传输成功,否则将发生碰撞。时隙结构如图3所示。
2)认知用户的观察空间:考虑到网络动态对认知用户来说不是先验的,认知用户只有通道状态的部分局部信息。本文将多用户的DSA建模为Dec-POMDP,在每个时隙,每个认知用户从K个信道中选择M个信道进行感知,所选择的信道的状态被透露给认知用户,其他未被选择的信道的状态则是未知的。
3)认知用户行为空间:每个认知用户从K个通道中选择M个通道在一个时隙中感知,其中0≤M≤K,构成认知用户的动作空间。因此,作用空间A的大小为 。在每个时隙开始时,每个认知用户根据学习到的策略从动作空间中选择一个动作,然后获取感知到的通道状态。
4)合作奖励:在每个时隙,认知用户感知到所选择的M个信道后,学习所感知信道的状态。如果感知信道中没有空闲信道,则认知用户在该时隙结束时不传输数据,并收到奖励(0)。如果感知信道中存在空闲信道,则认知用户选择一个空闲信道发送数据包,并在该时隙末接收到相应接收方的ACK。通过测量对应接收端反馈的SINR,可以推断是否存在碰撞。如果传输成功,认知用户获得奖励(+2)。如果发生碰撞,认知用户获得奖励(−1)。
3. 提出的基于CoMARL的动态频谱接入算法
1)集中培训,分散执行:MARL能够以分布式的方式建模和解决多智能体系统问题,即使认知用户只观察自己的局部信息。本文提出了一种CTDE架构,在认知无线电网络的网络边缘使用一个中央训练器,如图4所示。CTDE体系结构对网络拓扑变化是健壮的,并促进了可伸缩性。
在集中训练阶段,本文采用边缘计算服务器作为离线训练的中心训练器。中央训练器收集所有认知用户的交互经验元组(状态、观察、行动、奖励)进行合作策略训练。训练完成并获得合作策略后,认知用户不需要内部信息交换,在执行阶段根据局部观测情况单独进行频谱访问决策。
图4 CoMARL-DSA的集中训练和分布式执行(CTDE)架构
2)提出的CoMARL-DSA算法:
价值分解算法适用于解决协作博弈问题。VDN直接将所有agent的Q值函数相加得到联合作用值函数,即,Qtot =∑NN =1 Qn(τn, an;θn),其中Qtot表示联合作用值函数,Qn(τn, an;θn)表示第n个agent的Q值函数,τ = (τ1,τ2,…,τN)表示联合观测-动作历史,τnt = (ont−l, ant−l,…,ont−1,ant−1,ont, ant)表示第n个agent到步骤t为止的长度为l的观测-动作历史,a = (a1, a2,…,aN)表示联合动作,θn为第n个代理网络的参数。QMIX也是一种集中学习和分布式执行强化学习算法,采用混合网络集成agent的所有单独Q值函数,同时合并全局状态信息来辅助训练,有助于提高算法的性能和收敛速度。因此,在认知无线电网络中,本文提出了基于QMIX的CoMARL-DSA算法,该算法将多用户DSA问题定义为一个合作博弈。因为认知用户是同构的,所以他们的DRQN网络是相同的,并且有相同的参数。
04
实验结果
EXPERIMENTS
实验结果
为了验证本文所提协议的性能,提出了数值实验来验证所提出的CoMARL-DSA算法的有效性和效率。具体而言,本文提出的算法与目前最先进的DQSA算法进行了比较。我们考虑一个具有K = 16个带宽相等的正交信道的认知无线电网络,每个信道由相应的PUs按照双态马尔可夫链模式占用。
1. 仿真设置
CoMARL-DSA算法由混合网络、超网络和N个智能体网络组成。混合网络由32个神经元组成的隐藏层组成,利用ELU作为激活函数。为混合网络产生非负权的超网络也是由32个神经元组成的隐层,以ReLU作为激活函数。每个智能体网络是一个DRQN,有一个有64维隐藏状态的GRU组成的循环层,。在训练阶段,每个认知用户采用ε-贪心策略来探索动作空间。在整个训练过程中,ε在10000步后从0.4衰减到0.05,并一直保持不变直到结束。折扣因子为γ = 0.98,使用RMSprop优化器训练神经网络,学习率为α = 5e−4。每次我们从回放缓冲区中采样16个 episode,每个 episode包含20个步骤。目标网络每40个训练步骤更新一次。为了加快训练速度,所有认知用户共享相同的智能体网络结构。
2. CoMARL-DSA算法性能分析
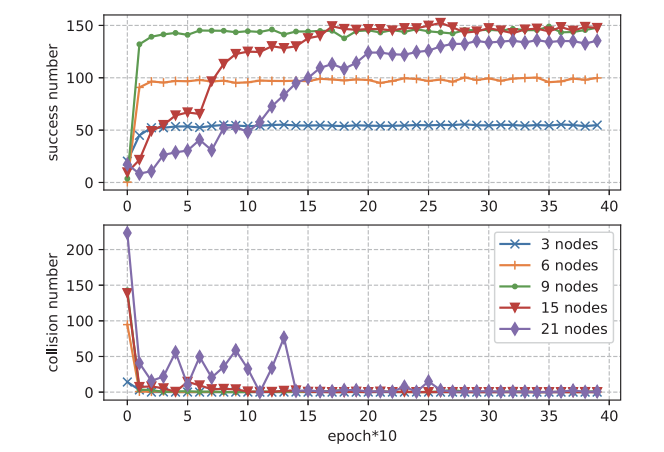
1) 感知信道数量固定,认知用户数量变化:从图5可以看出,对于不同数量的认知用户,提出的CoMARL-DSA算法在经过一定的训练步骤后,能够以较低的碰撞率收敛。从图5可以看出,当N≤9(即N = 3,6,9)时,随着认知用户数量的增加,收敛速度加快。N为认知用户数量)。因为认知用户已经学会了一种合作策略,所以他们能够合作感知和访问渠道。每个认知用户选择两个通道进行感知,当N≥8时,他们可以协调地获得所有通道的状态。然而,当K > 9(即K = 15,21)时,随着认知用户数量的增加,收敛速度降低。这是由于随着认知用户数量的增加,协调变得更加困难,合作策略更难学习。结果表明,该算法具有良好的可扩展性。
图5 有两个感知信道的不同数量认知用户
2) 认知用户数量固定,感知通道数量变化:经统计计算,16个正交通道平均每个时隙有7.42个空闲通道。每集由20个时隙组成,每集可释放148.4个空闲时隙供重复利用。对于3个持续传播的认知用户,他们需要60个空闲时隙在一集内访问。从图6中可以看出,当认知用户感知到更多通道时,本文算法收敛速度更快,性能更好,同时碰撞率更低。3个认知用户分别有4个和5个感知通道,他们在一个 episode中访问了近57个空闲时隙,访问成功率超过95%。
图6 有不同数量的感知信道的三个认知用户vs DQSA
3) 周期性的信道: 在该场景中,我们针对三个认知用户和每个用户的两个感知通道实现了CoMARL-DSA算法。在一个由20个时隙组成的episode中,三个持续传输的认知用户需要60个空闲时隙来访问。从图7可以看出,所提出的CoMARL-DSA算法在经过一定的训练步骤后会收敛,并且达到了接近最优的性能。这意味着认知用户已经学会了信道切换模式,并采用了一种协作访问策略。
图7 在一个周期信道中,三个认知用户有两个感知信道
4)相关信道:在该场景中,我们实现了三个认知用户的CoMARL-DSA算法,在相关通道中有两个感知通道。在一个由20个时隙组成的episode中,三个持续传输的认知用户需要60个空闲时隙来访问。从图8中可以看出,所提算法在经过一定的训练步骤后会收敛,并且达到了接近最优的性能。这意味着合作访问策略是在相关信道设置中学到的。
图8 三个认知用户在相关信道中有两个感知信道
5)对各种环境的适应性:为了说明所提框架的自适应性,本文在时变环境中实现了所提的CoMARL-DSA算法。本文针对三个认知用户和两个感知通道实现了CoMARL-DSA算法。从图9中可以看出,当认知用户在第150次遇到性能突然下降时,所提算法能够快速收敛并达到接近最优的性能。
图9 有两个感知信道的三个认知用户,在第150次训练从周期信道切换到相关信道
6)现实世界的信道:本文使用网站下载的真实数据跟踪来训练和评估提出的CoMARL-DSA算法。真实世界的数据轨迹是由南加州大学(USC)部署的室内低功率无线网络试验台产生的。我们在同样的无线设置中实现了DQSA算法。在一个由20个时隙组成的episode中,三个持续传输的认知用户需要60个空闲时隙进行传输。从图10中可以看出,在经过一定的训练步骤后,本文所提出的CoMARL-DSA算法与DQSA算法都收敛,但CoMARLDSA算法的性能优于DQSA算法。实验结果表明,所提出的CoMARL-DSA算法在实际无线设置中是有效的。
图10 在现实世界的信道中,有两个感知信道的三个认知用户
05
总结
CONCLUSION
总结
本文研究了多通道认知无线电网络中多用户的分布式DSA问题。本文将该问题建模为Dec-POMDP问题,认知用户通过与无线环境的持续交互来学习网络动态信息,并通过自身的局部观测和动作的历史反馈来推断环境状态。每个认知用户都被建模为独立的agent用户,学习在不与其他认知用户交换协调信息的情况下,通过观察本地环境状态自主制定最优访问策略。目标是学习多用户认知无线电网络中具有高信道利用率但低碰撞率的分布式多信道访问策略。
为了克服多智能体系统的维数爆炸和不稳定性问题,本文提出了一种基于MARL的分布式DSA问题的CTDE框架。在训练阶段,认知用户将其观察-动作功能发送给部署在边缘计算服务器上的中央训练器学习合作策略。在执行阶段,认知用户根据自己的局部观测自主做出访问决策。认知用户之间不进行协同信息交换,大大降低了通信开销。本文在不同的环境设置中验证了提出的CoMARL-DSA算法,并与最先进的DQSA算法进行了比较。从仿真结果可以看出,该算法在收敛速度和性能上都优于DQSA算法。
END
扫描二维码关注我们
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh