你见过这么能“唠嗑”的AI么?
你想了解李白,它能告诉你李白的称号、代表作品,还告诉你李白去过哪些地方、最喜欢的山、随口给你一句李白的经典诗句……
这是一个被“喂养”了许多数据的AI,TA可以以一当十,可以在零样本或少样本的情境下完成多种 NLP 任务(包括多语言任务)。TA便是 WeLM,一个学富五车 (well-read) 的 10 Billion 的中文模型,除了具备强大的中文理解和生成能力,还拥有处理跨多语言(中英日)任务的能力,进一步微调后,WeLM 可以拥有更好的零样本学习能力。
WeLM 能做到什么?有多厉害?
可以说,TA好像什么都知道(只要你有高超的提问技巧),语数英政史地物化生统统拿捏,还可以从语数英,给你贯连到物化生,再融汇到政史地。
先举个简单的,问答题/简答题:
或者,改写题,它甚至会给你多个回答,喜欢哪个任君挑选:
亦或是,翻译题,中英日三国语言混合也不在话下:
当然,WeLM 可以做到的远不止此,对话-采访、阅读理解、翻译、改写、续写、多语言阅读理解……都不在话下。我们为 WeLM 做了一个交互式网页(点击文末“阅读原文”直达),欢迎你来找TA“唠嗑”,发掘TA的更多本领。
同时,我们还为有需要的开发者提供了 API 接口,开发者可通过体验网页的“开放文档”页面申请获取 API Token 并调用接口。
近年来,随着 GPT3 大规模预训练模型的出现,自然语言处理领域迎来了新的“解题思路”,相比小模型,大模型表现出的“零样本/少样本”学习能力众所瞩目,并且,在多语言/多任务等角度的探索也正在谱写大模型百家争鸣的新篇章。接下来,我们将介绍预训练模型 WeLM 的实践经验以及围绕该模型做的一些探索工作。
1
方法
主流的 NLP 模型路径包含纯 Encoder(Bert),纯 Decoder(GPT) 以及 Encoder-Decode(T5) 结构。GPT3 和 Google PaLM 均在自回归模型的路线上殚智竭力。WeLM 同样选择了 GPT 风格的结构,因为我们认为自回归模型更容易在海量数据中掌握无穷范式。不同的技术路径除了体现项目设计者个人倾向的品味,也有其对结构优劣的深度思考。
考虑到不同的用户对于模型效果和推理延迟会有考量或者取舍(trade-off),我们训练了 1.3B,2.7B 以及10B 三个版本的模型,让用户在调用时可丰俭由人。
model | Layers | Heads | 输入长度 |
1.3B | 24 | 16 | 2048 |
2.7B | 32 | 32 | 2048 |
10B | 32 | 40 | 2048 |
模型层面我们做如下改动:
● 使用 RoPE 位置编码:利用三角函数的恒等变换优化相对位置编码。
● 使用 62k 个 token 的 SentencePiece,保留空格、tab 会更有利于下游任务。
相比传统模型,大模型的训练难度更高。不仅体现在需要更多的训练资源,在硬件上会遇到类似网络问题,挂载方式变更等IO问题,或者直接机器故障,当问题发生后需要耐心和运维沟通并重启训练。“软件”问题上,例如并行策略的选择、各类参数的设置如micro batch size, hidden size 大小等、模型训练过程中混合精度信息、dynamic loss scaling 变化、learning rate 变化等也需要经常观察并果断决定是否干预。
WeLM 以完全可原地复现的形式训练。换句话说,不管训练中发生了任何问题,我们都能从最近的保存的 checkpoint 中恢复并复现下一个 batch 的问题。以大模型的一个常见问题为例, batch loss 突然爆增但随后又回落为正常值,这称之为 loss spike(模型 size 小的情况并不常见),这会导致训练耗时且加重不稳定。而正因为 WeLM 可原地复现,我们直接跳过在 pipeline 中会导致 loss spike的这段数据。
参数越大,对应的训练数据量也需要越大,多数现有的大模型训练是不够充分的。我们将 10B WeLM 训练了 300B tokens(已经等同于GPT3的训练量),在 128 张A100 上训练需要大概 24 天时间。
如果对更多 WeLM 的训练细节感兴趣,可以参考技术报告的 Method 章节。
2
训练数据
数据之于模型,如水之于鱼也。对于大模型的训练,数据的重要性不言而喻。
我们构建数据集的目标是:
1、足够丰富:不仅是数据量大,数据的主题来源也要丰富多样。我们从 Common Crawl 下载了近两年的中文网页数据,同时搜集了大量的书籍、新闻。为了增强专业能力还补充了知识密集的论坛数据和一些学术论文。搜集完成后的全量数据10TB,其中包含了750G的英文数据,还有部分日韩文为了语义的连贯我们也全部保留。
2、足够干净:我们需要保证语料的纯净,不仅是去除本身的重复性,也要防止噪声数据、“有害”的脏数据影响训练。搜集的原始数据包含太多的噪声和脏数据。除了常规的规则过滤外,我们也额外训练了一个二分类 fasttext 模型检测数据是否需要清洗。最终通过规则结合模型我们过滤掉了超过87%的数据。接着,我们利用 SimHash 去除数据内部的重复,这一步有效的过滤掉40%的数据。
3、足够公平:去除一切和测评相关的数据,我们希望测试的指标能够真实反应模型的强弱面,如果混入了测试数据或者同源数据对于后续的评测是不公平的,训练完成后也可以进一步验证模型是否利用了测试数据训练。我们以 17-gram 为检测重复粒度,这一步再次过滤了 0.15% 的数据。
数据来源 | 过滤比例 | 剩余tokens |
Common Crawl | 92% | 198.5B |
书籍 | 40.9% | 61.9B |
新闻 | 7.5% | 1.91B |
论坛 | 6.7% | 1B |
学术论文 | 2.5% | 0.39B |
最终处理完的数据量为 262B tokens。为了更好的平衡各个数据源的比重,也要对数据进行不同比重的采样。最终整体数据集的Topic 分布相比 Common Crawl 更加平滑。
3
Benchmark
为了进一步量化效果,我们与业界同级别的 CPM、华为 Pangu 和百度 Ernie3.0 在 14 项 NLP 任务上进行了对比,WeLM 在绝大多数任务上取得了最佳,甚至比肩和 WeLM 25 倍大的模型。值得注意的是,以 Closed-Book QA 任务的测试结果为例,该任务是在没有上文的情况下裸答问题,换句话说 WeLM 的知识储备非常领先。而阅读理解的大幅领先则证明了 WeLM 极其优秀的长文本理解能力。
4
微调
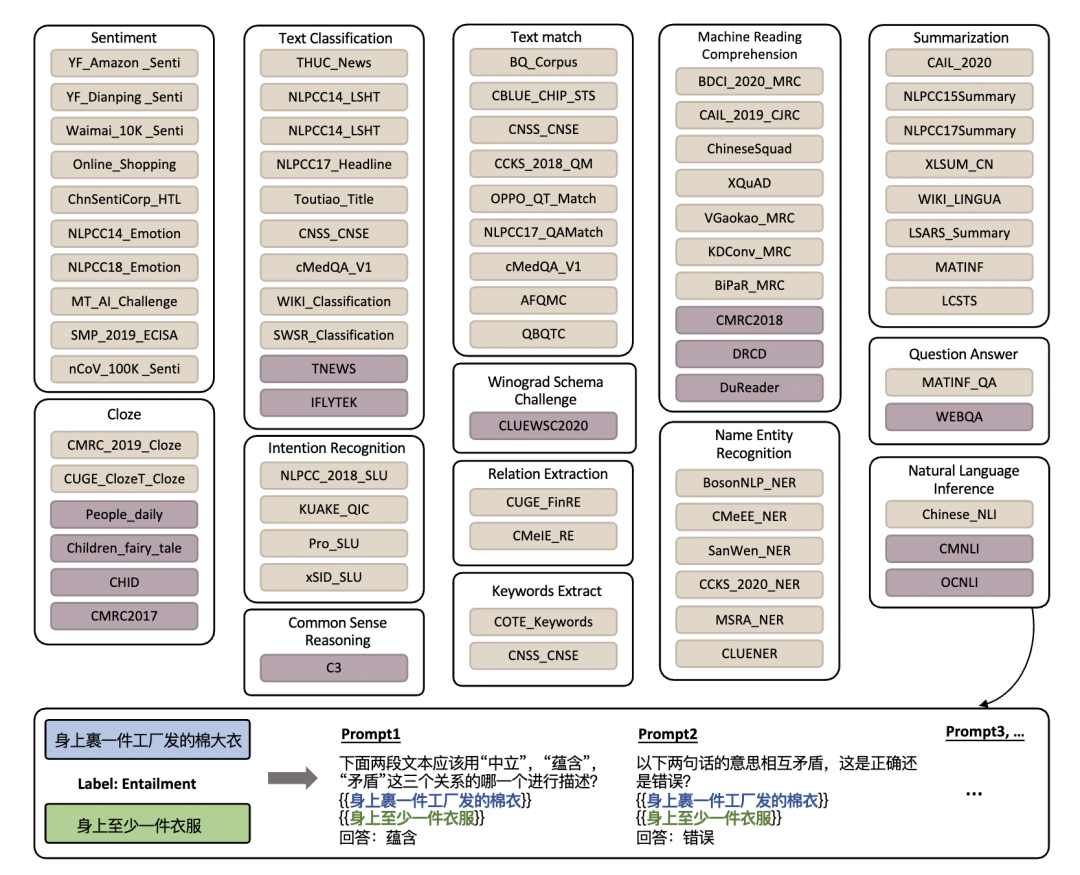
GPT结构(自回归)的模型在微调时需要针对任务撰写 prompt, 为了让后续的微调不再困难,我们预先标注了针对76个不同数据集的 prompt,对于每个数据集都人工撰写了10-20个 prompt。
如上图所示,以NLI任务为例,原任务中的文本关系的标签和输入信息被转化为流畅通顺的自然语言形式,更符合自回归语言模型的训练形式。
如果需要对新的任务进行微调,可以先从标注的 prompt 池中选择最为接近的来较为方便的构造新的训练数据。
进一步,我们结合 prompt 对这76个数据集微调,通过实验证明在全量数据上微调后的模型在新的 NLP 任务上具备更优秀的零样本迁移能力。这也使得微调变为一项一劳永逸的工作。我们也在尝试 parameter-efficient 的微调方式,后续将为大家持续报道。
5
总结
本文介绍了我们推出的 WeLM 语言模型。一个学富五车,拥有在多种任务上进行零样本或少样本学习能力且尺寸合理的中文模型。WeLM 除了具备强大的中文理解和生成能力,还拥有处理跨多语言(中英日)任务的能力。我们也在 WeLM 上对大量任务进行微调以获得更好的泛化能力。更多其他功能期待您的发现。
目前,该模型的论文我们已经上传至arXiv,对更多技术细节感兴趣的朋友可前往arXiv搜索“WeLM: A Well-Read Pre-trained Language Model for Chinese”
(或复制https://arxiv.org/abs/2209.10372至浏览器)进行查阅。
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。
如有侵权请联系:admin#unsafe.sh