
About - v2.0
This is a tool used to discover endpoints (and potential parameters) for a given target. It can find them by:
- crawling a target (pass a domain/URL)
- crawling multiple targets (pass a file of domains/URLs)
- searching files in a given directory (pass a directory name)
- get them from a Burp project (pass location of a Burp XML file)
- get them from an OWASP ZAP project (pass location of a ZAP ASCII message file)
The python script is based on the link finding capabilities of my Burp extension GAP. As a starting point, I took the amazing tool LinkFinder by Gerben Javado, and used the Regex for finding links, but with additional improvements to find even more.
Installation
xnLinkFinder supports Python 3.
$ git clone https://github.com/xnl-h4ck3r/xnLinkFinder.git
$ cd xnLinkFinder
$ sudo python setup.py install
Usage
| Arg | Long Arg | Description |
|---|---|---|
| -i | --input | Input a: URL, text file of URLs, a Directory of files to search, a Burp XML output file or an OWASP ZAP output file. |
| -o | --output | The file to save the Links output to, including path if necessary (default: output.txt). If set to cli then output is only written to STDOUT. If the file already exist it will just be appended to (and de-duplicated) unless option -ow is passed. |
| -op | --output-params | The file to save the Potential Parameters output to, including path if necessary (default: parameters.txt). If set to cli then output is only written to STDOUT (but not piped to another program). If the file already exist it will just be appended to (and de-duplicated) unless option -ow is passed. |
| -ow | --output-overwrite | If the output file already exists, it will be overwritten instead of being appended to. |
| -sp | --scope-prefix | Any links found starting with / will be prefixed with scope domains in the output instead of the original link. If the passed value is a valid file name, that file will be used, otherwise the string literal will be used. |
| -spo | --scope-prefix-original | If argument -sp is passed, then this determines whether the original link starting with / is also included in the output (default: false) |
| -sf | --scope-filter | Will filter output links to only include them if the domain of the link is in the scope specified. If the passed value is a valid file name, that file will be used, otherwise the string literal will be used. |
| -c | --cookies † | Add cookies to pass with HTTP requests. Pass in the format 'name1=value1; name2=value2;' |
| -H | --headers † | Add custom headers to pass with HTTP requests. Pass in the format 'Header1: value1; Header2: value2;' |
| -ra | --regex-after | RegEx for filtering purposes against found endpoints before output (e.g. /api/v[0-9]\.[0-9]\* ). If it matches, the link is output. |
| -d | --depth † | The level of depth to search. For example, if a value of 2 is passed, then all links initially found will then be searched for more links (default: 1). This option is ignored for Burp files because they can be huge and consume lots of memory. It is also advisable to use the -sp (--scope-prefix) argument to ensure a request to links found without a domain can be attempted. |
| -p | --processes † | Basic multithreading is done when getting requests for a URL, or file of URLs (not a Burp file). This argument determines the number of processes (threads) used (default: 25) |
| -x | --exclude | Additional Link exclusions (to the list in config.yml) in a comma separated list, e.g. careers,forum |
| -orig | --origin | Whether you want the origin of the link to be in the output. Displayed as LINK-URL [ORIGIN-URL] in the output (default: false) |
| -t | --timeout † | How many seconds to wait for the server to send data before giving up (default: 10 seconds) |
| -inc | --include | Include input (-i) links in the output (default: false) |
| -u | --user-agent † | What User Agents to get links for, e.g. -u desktop mobile |
| -insecure | † | Whether TLS certificate checks should be disabled when making requests (delfault: false) |
| -s429 | † | Stop when > 95 percent of responses return 429 Too Many Requests (default: false) |
| -s403 | † | Stop when > 95 percent of responses return 403 Forbidden (default: false) |
| -sTO | † | Stop when > 95 percent of requests time out (default: false) |
| -sCE | † | Stop when > 95 percent of requests have connection errors (default: false) |
| -m | --memory-threshold | The memory threshold percentage. If the machines memory goes above the threshold, the program will be stopped and ended gracefully before running out of memory (default: 95) |
| -mfs | --max-file-size † | The maximum file size (in bytes) of a file to be checked if -i is a directory. If the file size os over, it will be ignored (default: 500 MB). Setting to 0 means no files will be ignored, regardless of size.. |
| -replay-proxy | † | For active link finding with URL (or file of URLs), replay the requests through this proxy. |
| -ascii-only | Whether links and parameters will only be added if they only contain ASCII characters. This can be useful when you know the target is likely to use ASCII characters and you also get a number of false positives from binary files for some reason. | |
| -v | --verbose | Verbose output |
| -vv | --vverbose | Increased verbose output |
| -h | --help | show the help message and exit |
† NOT RELEVANT FOR INPUT OF DIRECTORY, BURP XML FILE OR OWASP ZAP FILE
config.yml
The config.yml file has the keys which can be updated to suit your needs:
linkExclude- A comma separated list of strings (e.g..css,.jpg,.jpegetc.) that all links are checked against. If a link includes any of the strings then it will be excluded from the output. If the input is a directory, then file names are checked against this list.contentExclude- A comma separated list of strings (e.g.text/css,image/jpeg,image/jpgetc.) that all responsesContent-Typeheaders are checked against. Any responses with the these content types will be excluded and not checked for links.fileExtExclude- A comma separated list of strings (e.g..zip,.gz,.taretc.) that all files in Directory mode are checked against. If a file has one of those extensions it will not be searched for links.regexFiles- A list of file types separated by a pipe character (e.g.php|php3|php5etc.). These are used in the Link Finding Regex when there are findings that aren't obvious links, but are interesting file types that you want to pick out. If you add to this list, ensure you escape any dots to ensure correct regex, e.g.js\.maprespParamLinksFound† - Whether to get potential parameters from links found in responses:TrueorFalserespParamPathWords† - Whether to add path words in retrieved links as potential parameters:TrueorFalserespParamJSON† - If the MIME type of the response contains JSON, whether to add JSON Key values as potential parameters:TrueorFalserespParamJSVars† - Whether javascript variables set withvar,letorconstare added as potential parameters:TrueorFalserespParamXML† - If the MIME type of the response contains XML, whether to add XML attributes values as potential parameters:TrueorFalserespParamInputField† - If the MIME type of the response contains HTML, whether to add NAME and ID attributes of any INPUT fields as potential parameters:TrueorFalserespParamMetaName† - If the MIME type of the response contains HTML, whether to add NAME attributes of any META tags as potential parameters:TrueorFalse
† IF THESE ARE NOT FOUND IN THE CONFIG FILE THEY WILL DEFAULT TO True
Examples
Find Links from a specific target - Basic
python3 xnLinkFinder.py -i target.com
Find Links from a specific target - Detailed
Ideally, provide scope prefix (-sp) with the primary domain (including schema), and a scope filter (-sf) to filter the results only to relevant domains (this can be a file or in scope domains). Also, you can pass cookies and customer headers to ensure you find links only available to authorised users. Specifying the User Agent (-u desktop mobile) will first search for all links using desktop User Agents, and then try again using mobile user agents. There could be specific endpoints that are related to the user agent given. Giving a depth value (-d) will keep sending request to links found on the previous depth search to find more links.
python3 xnLinkFinder.py -i target.com -sp target_prefix.txt -sf target_scope.txt -spo -inc -vv -H 'Authorization: Bearer XXXXXXXXXXXXXX' -c 'SessionId=MYSESSIONID' -u desktop mobile -d 10
Find Links from a list of URLs - Basic
If you have a file of JS file URLs for example, you can look for links in those:
python3 xnLinkFinder.py -i target_js.txt
Find Links from a files in a directory - Basic
If you have a files, e.g. JS files, HTTP responses, etc. you can look for links in those:
python3 xnLinkFinder.py -i ~/Tools/waymore/results/target.com
NOTE: Sub directories are also checked. The -mfs option can be specified to skip files over a certain size.
Find Links from a Burp project - Basic
In Burp, select the items you want to search by highlighting the scope for example, right clicking and selecting the Save selected items. Ensure that the option base64-encode requests and responses option is checked before saving. To get all links from the file (even with HUGE files, you'll be able to get all the links):
python3 xnLinkFinder.py -i target_burp.xml
NOTE: xnLinkFinder makes the assumption that if the first line of the file passed with -i starts with <?xml then you are trying to process a Burp file.
Find Links from a Burp project - Detailed
Ideally, provide scope prefix (-sp) with the primary domain (including schema), and a scope filter (-sf) to filter the results only to relevant domains.
python3 xnLinkFinder.py -i target_burp.xml -o target_burp.txt -sp https://www.target.com -sf target.* -ow -spo -inc -vv
Find Links from an OWASP ZAP project - Basic
In ZAP, select the items you want to search by highlighting the History for example, clicking menu Report and selecting Export Messages to File.... This will let you save an ASCII text file of all requests and responses you want to search. To get all links from the file (even with HUGE files, you'll be able to get all the links):
python3 xnLinkFinder.py -i target_zap.txt
NOTE: xnLinkFinder makes the assumption that if the first line of the file passed with -i is in the format ==== 99 ========== for example, then you are trying to process an OWASP ZAP ASCII text file.
Piping to other Tools
You can pipe xnLinkFinder to other tools. Any errors are sent to stderr and any links found are sent to stdout. The output file is still created in addition to the links being piped to the next program. However, potential parameters are not piped to the next program, but they are still written to file. For example:
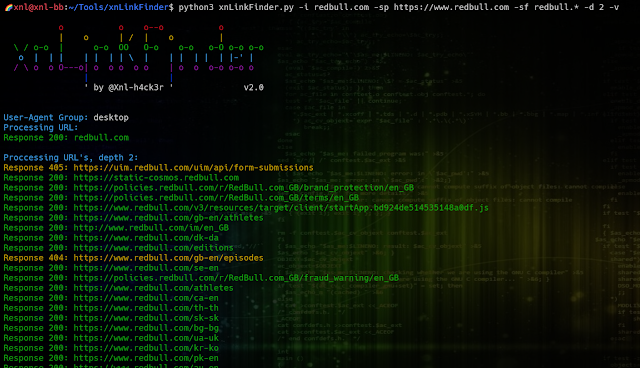
python3 xnLinkFinder.py -i redbull.com -sp https://redbull.com -sf rebbull.* -d 3 | unfurl keys | sort -u
You can also pass the input through stdin instead of -i.
cat redbull_subs.txt | python3 xnLinkFinder.py -sp https://redbull.com -sf rebbull.* -d 3
NOTE: You can't pipe in a Burp or ZAP file, these must be passed using -i.
Recommendations and Notes
- Always use the Scope Prefix argument
-sp. This can be one scope domain, or a file containing multiple scope domains. Below are examples of the format used (no path should be included, and no wildcards used. Schema is optional, but will default to http):If a link is found that has no domain, e.g.http://www.target.com
https://target-payments.com
https://static.target-cdn.com/path/to/example.jsthen giving passing-sp http://www.target.comwill result in teh outputhttp://www.target.com/path/to/example.jsand if Depth (-d) is >1 then a request will be able to be made to that URL to search for more links. If a file of domains are passed using-spthen the output will include each domain followed by/path/to/example.jsand increase the chance of finding more links. - If you use
-spbut still want the original link of/path/to/example.js(without a domain) additionally returned in the output, the pass the argument-spo. - Always use the Scope Filter argument
-sf. This will ensure that only relevant domains are returned in the output, and more importantly if Depth (-d) is >1 then out of scope targets will not be searched for links or parameters. This can be one scope domain, or a file containing multiple scope domains. Below are examples of the format used (no schema or path should be included):THIS IS FOR FILTERING THE LINKS DOMAIN ONLY.target.*
target-payments.com
static.target-cdn.com - If you want to filter the final output in any way, use
-ra. It's always a good idea to use https://regex101.com/ to check your Regex expression is going to do what you expect. - Use the
-voption to have a better idea of what the tool is doing. - If you have problems, use the
-vvoption which may show errors that are occurring, which can possibly be resolved, or you can raise as an issue on github. - Pass cookies (
-c), headers (-H) and regex (-ra) values within single quotes, e.g.-ra '/api/v[0-9]\.[0-9]\*' - Set the
-ooption to give a specific output file name for Links, rather than the default ofoutput.txt. If you plan on running a large depth of searches, start with 2 with option-vto check what is being returned. Then you can increase the Depth, and the new output will be appended to the existing file, unless you pass-ow. - Set the
-opoption to give a specific output file name for Potential Parameters, rather than the default ofparameters.txt. Any output will be appended to the existing file, unless you pass-ow. - If using a high Depth (
-d) be wary of some sites using dynamic links so will it will just keep finding new ones. If no new links are being found, then xnlLinkFinder will stop searching. Providing the Stop flags (s429,s403,sTO,sCE) should also be considered. - If you are finding a large number of links (especially if the Depth (
-dvalue is high), and have limited resources, the program will stop when it reaches the memory Threshold (-m) value and end gracefully with data intact before getting killed. - If you decide to cancel xnLinkFinder (using
Ctrl-C) in the middle of running, be patient and any gathered data will be saved before ending gracefully. - Using the
-origoption will show the URL where the link was found. This can mean you have duplicate links in the output if the same link was found on multiple sources, but it will suffixed with the origin URL in square brackets. - When making requests, xnLinkFinder will use a random User-Agent from the current group, which defaults to
desktop. If you have a target that could have different links for different user agent groups, the specify-u desktop mobilefor example (separate with a space). Themobileuser agent option is an combination ofmobile-apple,mobile-androidandmobile-windows. - When
-ihas been set to a directory, the contents of the files in the root of that directory will be searched for links. Files in sub-directories are not searched. Any files that are over the size set by-mfs(default: 500 MB) will be skipped. - When using the
-replay-proxyoption, sometimes requests can take longer. If you start seeing moreRequest Timeouterrors (you'll see errors if you use-vor-vvoptions) then consider using-tto raise the timeout limit. - If you know a target will only have ASCII characters in links and parameters then consider passing
-ascii-only. This can eliminate a number of false positives that can sometimes get returned from binary data.
Issues
If you come across any problems at all, or have ideas for improvements, please feel free to raise an issue on Github. If there is a problem, it will be useful if you can provide the exact command you ran and a detailed description of the problem. If possible, run with -vv to reproduce the problem and let me know about any error messages that are given.
TODO
- I seem to have completed all the TODO's I originally had! If you think of any that need adding, let me know
落
Example output
Active link finding for a domain:

...

Piped input and output:

Good luck and good hunting! If you really love the tool (or any others), or they helped you find an awesome bounty, consider BUYING ME A COFFEE! ☕ (I could use the caffeine!)
落
/XNL-h4ck3r
