云时代已经来临,云上很多场景下都需要数据的迁移、备份和流转,各大云厂商也大都提供了自己的迁移工具。本文主要介绍京东云数据库为解决用户数据迁移的常见场景所提供的解决方案。
数据迁移上云是最常见的一类场景,目前京东云提供了两个DTS(Data Transformation Service)迁移工具供选择,一个是数据迁移,一个是数据同步:
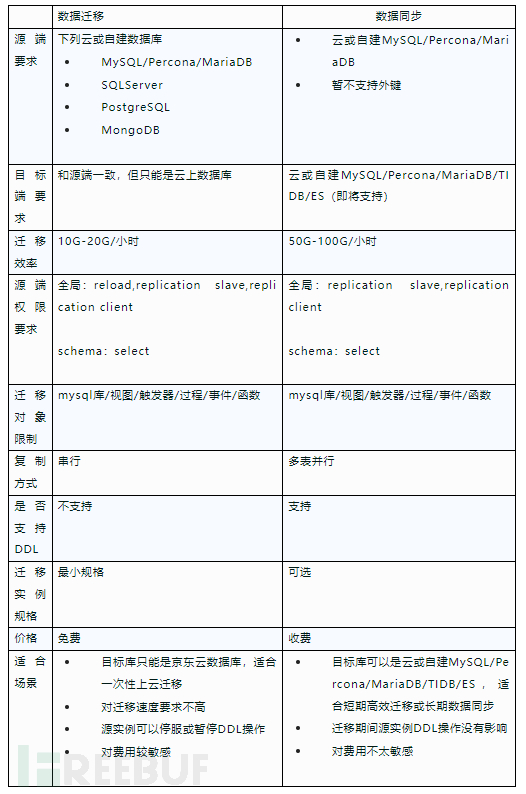
二者的主要区别如下:
下面是这两个工具使用中的一些常见问题:
01 两个迁移工具的原理是什么?
以MySQL为例,两个工具都有全量迁移/增量迁移/数据校验三个阶段,这三个阶段的主要原理如下:
全量阶段:
数据迁移使用mysqldump --single-transaction来取得一致性快照,但无法保证非事务引擎表的数据一致性,加上增量才可以保证数据的最终一致性,这个过程是串行操作;
数据同步使用多表并行的select方式,根据主键顺序分批获取记录,循环执行,如果没有主键,则进行全表查询。为了最大限度减少对源实例的影响,这个过程不加锁,也不用开启事务获得一致读,因此全量期间迁移的数据是不一致的,通过增量阶段可以达到最终一致性。所以数据同步只提供了‘全量+增量’和‘增量’两种选项,不提供单独的‘全量’选项。
增量阶段:
数据迁移和数据同步一样,都是通过迁移启动前记录的gtid点位,抓取对应binlog同步apply到目标端,二者区别在于迁移是串行的,同步会将同一个表的事务合并后一次提交,效率更高。
数据校验:
将源库的数据分块计算crc,每个块的元数据和校验信息记录到目标实例_jdts_check为前缀的库下checksum表中。目标库同步完成后根据同样算法进行计算,比较对应块号的crc值是否一致来判断校验是否成功。
02 迁移速度可以调整吗?
数据迁移不可以,数据同步可以选择更大的迁移实例和增加更多的并发来调整,但由于并发机制是基于表粒度的,对于少量大表的情况,增加并发并不会有明显作用。
03 迁移进度为什么显示超过100%?
为了效率更高,迁移显示的进度是根据已经迁移的记录数除以数据字典记录的记录数显示,数据字典的值并不完全准确,因此理论上会出现进度超过100%的现象。
04 迁移延时为什么很长?
大多情况是源库写操作压力大导致目标库binlog apply进度赶不上源库的写入速度,也有可能是目标库读写压力大或者迁移实例压力大,具体需要联系京东云技术服务及时介入。
05 迁移期间目标库是否可以读写数据?
理论上可以读写,但不建议在迁移期间操作,主要有两个弊端:
- 写入脏数据会导致校验不一致。
- 读写数据会导致目标库压力增大,减缓数据同步速度。
06 目标端如果有同名库表是否会被覆盖?
不会的,如果目标库库表有数据,预检的时候会报错不通过;如果是空的库表,则可以直接写入。
07 自检提示源或目标库网络不通怎么办?
检查源库和目标库的白名单限制,需要加上dts迁移实例的ip,在迁移任务配置的时候会在页面提示。
08 目标库中的_jdts为前缀的库可以删除吗?
迁移完成可以删除。
09 可以从只读实例同步吗?
只要源实例是gtid方式复制的,都可以通过主实例或只读实例同步。
10 数据迁移选择内网时,为啥只能用json格式,不能图形化选择库表?
因为数据迁移创建任务的时候,迁移实例还未创建,无法判断内网连通性;数据同步已经做了改进,内外网均可以通过图形化方式选择库表。
11 迁移期间对源实例有影响吗?
无论数据迁移还是数据同步,都需要对源实例库表做select,会有一定的读IO压力,建议尽量在业务低峰期同步或从只读实例同步。对于数据同步任务, 可通过控制台暂停任务,待源库负载降低,再启动数据同步任务。
12 mysql系统库应该如何迁移?
目前不支持迁移MySQL库,建议用户迁移时提前在目标库创建配置好对应的用户和权限。或者通过mysqldump等工具从源库导入。
13 迁移过程出现Got fatal error 1236 ... 的报错怎么办?
这个报错可能会在增量迁移过程出现,主要原因是增量需要的binlog在源端被删除所致,因此迁移期间尽量将源端binlog保留较长的时间。如果出现此类报错,如果无法找回被删binlog,只能重新开始迁移。
14 源端目标端版本必须一致吗?
数据迁移要求两边版本一致;数据同步目前支持低->高版本迁移。
用户经常会对数据有异地灾备的需求,京东云目前提供了两种方式,一种是可以配置跨地域备份同步,如下图:
这种方式简单免费,会定期将最新备份同步到异地,缺点是数据是非实时的,如果灾备恢复会有数据丢失。
另外一种方案是灾备同步(目前暂只支持MySQL),可以在京东云控制台创建一个异地灾备实例,然后利用DTS的数据同步功能将灾备实例和源实例进行数据同步,同步方式选择灾备同步。和普通同步机制不同,灾备同步利用的是MySQL的原生复制,因此灾备实例和源实例是完全一致的,相当于一个异地的只读实例,这样就可以达到异地灾备的目的。
对于灾备实例,有几点需要注意:
- 灾备实例目前只支持和京东云MySQL进行同步,暂不支持自建或第三方云实例。
- 灾备实例无法进行变配/重启/主从切换等操作,需要提前选好规格。
- 灾备实例也是主从实例,可以读但无法进行写操作,类似异地只读实例,可以手工提升为主备实例。
- 灾备实例是基于dts同步的,一旦手工结束同步,灾备实例将自动提升为普通主备实例。
很多业务场景都会用到数据订阅,比如订阅数据到ES扩展搜索、上下游订阅价格变更/服务通知、多业务库数据合并/构建宽表等。京东云提供了数据订阅功能来满足类似需求,目前源端支持
MySQL/Percona/MariaDB/PostgreSQL,目标端仅支持Kafka。
目标端使用json格式记录订阅信息,下面是一个update操作的例子:
{
"version": "0.1",
"database": "dbtest",
"table": "t1",
"type": "update",
"ts": 1582617997,
"time_zone": "Asia/Shanghai",
"host": "mysql-internet-cn-north-1-c52cb616874d4d29.rds.jdcloud.com",
"data": {
"created": "2020-02-25 16:01:46",
"flag": "10691",
"info": "dts_test",
"pkid": "11663",
"uuid": "11cae53d-57a5-11ea-98a6-fa163ea31339"
},
"old": {
"created": "2020-02-25 16:01:46",
"flag": "10691",
"info": null,
"pkid": "11663",
"uuid": "11cae53d-57a5-11ea-98a6-fa163ea31339"
},
"pks": {
"pkid": "11663"
}
}
数据订阅有几点需要注意:
- 订阅的消息长度如果超过中间件的最大消息长度,消息将被丢弃,因此理论上会有丢失数据风险。
- 目标端接受的数据起点默认为订阅的实时时间点,如果需要全量订阅可以联系京东云技服人员。
用户经常有这样的需求,是否可以用自建MySQL来同步云上MySQL?或者反过来,是否可以云上MySQL作为自建MySQL的从库来满足某些场景?
- 从MySQL复制机制来看,理论上应该都是可以的,但京东云的账号不支持赋予super权限,无法执行change master操作,所以云上MySQL无法作为自建MySQL的从库。
- 反过来,自建MySQL可以有super权限,是可以作为云上MySQL的从库。但这个是非标准操作,并不建议用户使用。主要原因是在某些情况下,会造成复制中断。比如云上MySQL配置变更后需要主从切换,而此时自建从库和切换前的源主库有复制延迟,部分binlog还未传递到自建从库,此时主从切换后复新主库由于没有这些binlog,会造成自建从库报1236的错误。针对这种情况,用户可以在扩容时选择延迟切换,可以避开业务高峰,在一定程度上避免类似问题。
作者:翟振兴
如有侵权请联系:admin#unsafe.sh