每周文章分享2022.11.14-2022.11.20标题: Energy-Efficient Online Path Planning of Multiple Drones Using Reinfo 2022-11-19 18:23:47 Author: 网络与安全实验室(查看原文) 阅读量:42 收藏
每周文章分享
2022.11.14-2022.11.20
标题: Energy-Efficient Online Path Planning of Multiple Drones Using Reinforcement Learning
期刊: IEEE Transactions on Vehicular Technology, vol. 70, no. 10, pp. 9725-9740, Oct. 2021.
作者: Dooyoung Hong, Seonhoon Lee, Young Hoo Cho, Donkyu Baek, Jaemin Kim, and Naehyuck Chang.
分享人: 河海大学——祝远波
壹
背景介绍
随着现代工业和人工智能技术的快速发展,军事、物流、医疗和救援等许多领域都将多无人机 (Multiple unmanned aerial vehicles, multi_UAV) 作为下一代运输工具。长期在复杂的环境中工作,multi_UAV系统需要考虑完成任务的目标下,尽可能的提高系统能效。为此,目前已经开发了大量先进的群智能算法和机器学习方法用于多智能体协同问题。
深度Q学习理论(Deep Q Network,DQN)在多智能体协同领域取得了长足的进步,极大地推动了复杂环境中的多机协同技术的成熟。然而,现有的基于优化DQN方法的多智能体协同方法存在以下不足。首先,DQN只能解决含有离散和低维度的动作空间的问题。而一般的物理问题或控制问题中,动作空间是连续的。其次,DQN的收敛性较差。
贰
关键技术
在本文中,提出了优化后的双延迟的深度确定性策略梯度算法(Advanced Twin-Delayed Deep Deterministic Policy Gradient, Adv. TD3),利用强化学习引入多无人机两步路径规划框架,克服集中路径规划的局限性,使用策略梯度算法、帧叠加、动态观察范围变化和离线RL技术,以实现的多无人机路径规划。
该方法的创新和贡献如下:
1)改进了现有的策略梯度算法,以适应多无人机路径规划问题中大而连续的动作空间。
2)采用了帧叠加技术和动态观测范围扩展技术,实现了RL模型的快速稳定收敛。
3)采用离线方式训练RL模型,以减少RL模型训练过程中硬件损坏、与人或物体碰撞等风险。通过配置无人机的仿真环境和认知条件,使其更加真实,从而提高了可靠性。
叁
算法介绍
本部分首先介绍了Adv. TD3算法框架,然后叙述Adv. TD3算法的优化方式,最后详细说明整体框架的构成部分。
1. Adv. TD3框架
本文提出的多智能体协同算法是复杂环境下的多机路径规划系统;能效性是给出的多无人机完成所有任务后消耗的总能量,作为算法的性能度量;系统的最大目标是最大化多智能体协同系统中,无人机集群的能效。
本文符号定义如下:
1)状态S:
图1 状态空间
图1展示了将无人机工作的环境信息分为无人机的状态信息和认知信息。状态信息包括无人机的物理参数和影响无人机操作的外力,如无人机的当前位置、目的地、速度和特定状态下的风信息。认知信息为使用RGB-D摄像机和超声波传感器设置了障碍物识别范围。模拟实验中的无人机使用3D CNN来识别周围的环境。
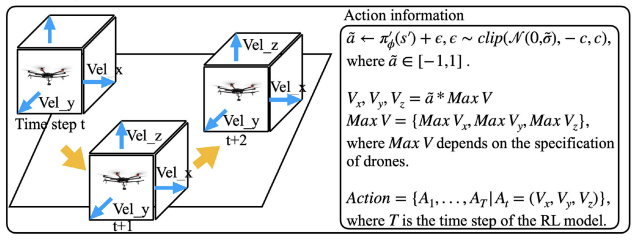
2)动作空间:
图2 动作空间
图2展示了将无人机在连续空间中的三轴速度设置为动作空间,并得到了在RL的每次迭代(无人机的每一个时间间隔)上控制无人机的新动作。Adv. TD3采用帧叠加技术,通过将演员网络的输出范围(˜a∈[−1,1])乘以无人机的最大速度来确定无人机的速度范围。基于DJI Matrice 600(大疆无人机型号),我们设其最大水平速度为15 m/s,垂直速度为3 m/s。无人机以4 Hz的采样率获取帧堆叠的状态,并在此工作中每秒钟执行一次动作。将无人机的速度纳入状态,推导出无人机在不同步骤之间移动的加速度,以便功率模型精确地预测功率消耗。
3)奖励函数:
图3 奖励函数
图3展示了RL中的奖励功能模仿了人类的学习过程,它决定了无人机在执行行动后获得的奖励。Agent想要实现的目标的变化取决于奖励的设置方式。我们设置了一个奖励功能,以尽量减少无人机的能量消耗,直到它们到达最终目的地并安全执行任务。
(4)能耗模型
图4 能耗建模
图4展示了能耗建模。该模型直接从无人机的实际飞行数据生成。还使用了无人机的直观数据,包括其速度(Vx,Vy,Vz),加速度(Ax,Ay,Az),风速ws,风向wd,有效载荷重量Pw,和有效载荷体积Pv。具体公式如下
2. Adv. TD3的截断双Q学习
该方法解决了DDPG中的偏差高估,就像DDQN通过双q学习解决了DQN中的偏差高估一样。该方法选择两个参与者网络之间的低值函数,如双q学习作为目标值y,公式如下所示
3. Adv. TD3的目标网络和策略网络的延迟更新
在正确学习批评网络后,该技术缓慢更新策略和目标网络,为不正确的值函数做准备。一般当评论家网络更新两次,目标网络和策略网络更新一次。
4. Adv. TD3的目标策略平滑
当actor网络推导策略时出现峰值时,DDPG很可能会高估策略的值函数。针对Q函数的平滑正则化策略可以防止策略网络的过拟合。Adv. TD3通过添加到目标动作上的噪声来适当地平滑目标策略,从而缓解了这个问题。具体公式如下
5. 整体框架
图5 RL路径规划
本文提出的Adv.TD3框架有两个主要组成部分:离线的RL训练和在线的路径规划问题。在离线的RL训练中,通过使用外部计算设备,解决了RL训练过程的巨大计算开销。批约束的深度q学习(Batch-Constrained Deep Q-Learning,BCQ)是一种离线RL算法,训练变分自动编码器(Variational AutoEncoder,VAE),是生成模型之一。它创建了一个扰动模型,扰动一些样本的抽取。然后,模型选择值函数值中结果最大的。
肆
实验结果
1. 仿真参数
表1 Adv. TD3模型的超参数和仿真环境信息
仿真环境:
图6 不同环境下的仿真环境
对比算法:1、Dijkstra 2、RRT 3、Adv. DDPG 4、Adv. TD3
评价指标:不同风向下的:1、收敛性2、路径规划能耗 3、是否碰撞
2. 仿真结果
1.收敛性
图7 算法收敛性比对图
多无人机的训练模型通过替换每次迭代的风图来模拟风环境的变化。还通过逐渐增加从起点和目的地的距离来训练模型。最终结果如图所示,相较于其他算法,Adv. TD3收敛速度更高。
2.路径规划能耗
(1)北风情况下,多无人机路径规划算法的路径比较
图8 北风情况下,多无人机路径(a) Dijkstra;(b) RRT;(c) Adv.DDPG;(d) Adv.TD3。
表2 路径规划能耗对比表
表2展示了多无人机路径规划结果,并从无人机的能量消耗、飞行时间展示了能效。Adv. TD3算法有着优秀的表现,最大减少7.59%的能量消耗。其中,Dijkstra算法得到的路径并不能保证是最优解。
(2)风向和无人机数量引起的路径及其能耗变化
表3 方案1中集中化的RL路径规划仿真结果
表3展示了给出了在不同条件下(风向:北风、西北风和东南风;无人机数量:4架、6架和8架)的场景的仿真结果。在不同的示例中,Adv. TD3算法都有着优秀的表现,最小减少2.88%的能量消耗,最大减少7.73%的能量消耗。
(3)风速和无人机数量引起的路径及其能耗变化
表4 方案2中集中化的RL路径规划仿真结果
表4展示了给出了在不同条件下(风速:3m/s、6m/s和9m/s)的场景的仿真结果。在不同的示例中,Adv. TD3算法都有着优秀的表现,最小减少8.43%的能量消耗,最大减少9.22%的能量消耗。
3.路径规划中的碰撞信息
表5 碰撞信息表
表5总结了在飞行期间出现干扰的地方。由于多条路径之间的相互干扰,会影响规划结果的能量消耗。但是这个问题需要通过重复计算来解决冲突,在给定的极端的时间内找到解决方案几乎是不切实际的。结果表明,Adv. TD3更接近实际的最优能量路径。
伍
总结
针对多无人机路径规划问题中存在的路径和障碍干扰,以及无人机连续的动作空间,本文提出了Adv.TD3,实现了算法的快速收敛,减小了路径规划的能效。随后使用两步式框架(离线训练,在线规划),减小了多无人机对边缘计算的依赖,使无人机能够实时执行路径规划成为可能。
-END-
==河海大学网络与安全实验室==
微信搜索:Hohai_Network
联系QQ:1084561742
责任编辑:何宇
如有侵权请联系:admin#unsafe.sh