
WAL(Write Ahead Log)预写日志
先简单描述下 WAL LOG 的作用,不管使用 b+tree 或者 lsm tree,不建议直接原地修改数据,离散写的场景下会造成过多的随机写,更合理的方式是顺序 io 写到一个日志文件里,然后等待时机把数据进行合并后变更数据文件,这个日志就是 wal ( write ahead log) 预写日志.
另外还有一点,直接修改数据文件的话,如果写到一半发生了 crash,那么该页就损坏了.
如果 DB 关了或者挂了,但还有部分数据在内存和 wal 日志中,还未变更到 db 文件中. 那没关系,只需在启动后从 wal 日志中重放日志做还原即可.
想像一下这个流程:
- 找到 WAL LOG
- 按照写入顺序,一个一个地把 WAL LOG 重放一遍
- DB 恢复完成
rocksdb wal
再聊 golang wal 实现之前,先过一下 rocksdb wal 的一些设计.
默认最多有三个 memtable,每个 memtable 为 64MB,当 memtable 落盘到 L0 时,就可以删掉对应的 wal 预写日志了.
options.write_buffer_size = 67108864; // 64MB
options.max_write_buffer_number = 3;
golang wal 的设计实现
golang 有不少 wal 的实现,tidwall 的实现相对不错.
github 地址: https://github.com/tidwall/wal
下图为 tidwall wal 的设计,把数据分到连续的 segment 数据段里,每个 segment 文件大小为 20MB,每次写数据都写在最后 segment 文件的后面. 为了避免服务在启动阶段,花费大量时间重做日志,通常 wal 不会太大,中间会做 checkpoint 操作,就是把 wal 的数据回写到 db 文件中,然后清理已持久化的 segment,并记录当前的清理点.
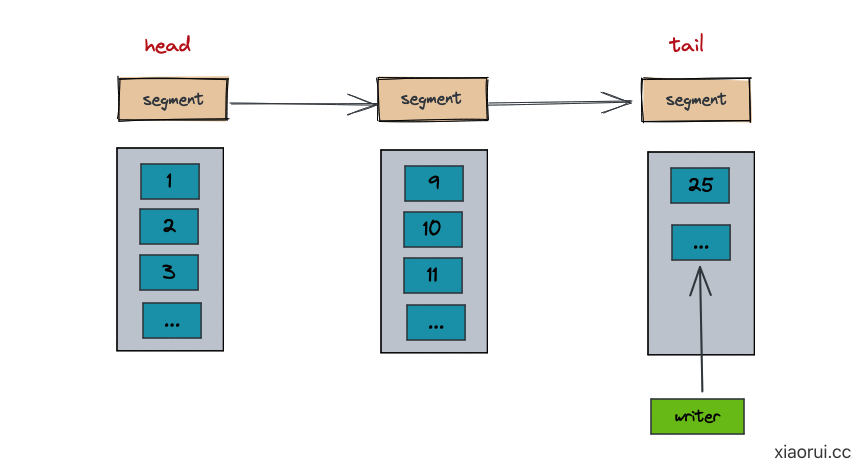
wal 代码解读
初始化阶段
启动时需要扫描所有的 segments 文件,由于 wal 是 append 时间顺序写入,文件名又是递增的,所以直接读取目录拿到的文件也是顺序的, 文件名含有 index 信息及 start, end 后缀,通过这类信息组装内存 segments 数组.
再后面打开最后的 segment 文件, 内存中设置当前 lastIndex 大小.
l.lastIndex = lseg.index + uint64(len(lseg.epos)) - 1
下面为 segment 输出的文件名样式,其实就是当前 segment 里第一个 entry 的 index, 只是打印的格式做了宽补零操作.
00000000000000002
00000000000000010
00000000000000050
00000000000000080
00000000000000111
...
00000000000000222
00000000000000333
00000000000000555
...
那么 golang 如何补位输出?
func segmentName(index uint64) string {
return fmt.Sprintf("%020d", index)
}
wal 数据结构
// Log represents a write ahead log, seo xiaorui.cc
type Log struct {
mu sync.RWMutex
path string // wal 的目录
opts Options // log options
closed bool // log is closed
corrupt bool // log may be corrupt
segments []*segment // all known log segments
firstIndex uint64 // 开始的 index
lastIndex uint64 // 最后的 index
sfile *os.File // 已经打开的最后 segment 文件描述符
wbatch Batch // reusable write batch
scache tinylru.LRU // segment entries cache
}
// segment represents a single segment file.
type segment struct {
path string // segment 文件名
index uint64 // 当前 segment 的 first index
ebuf []byte // cached entries buffer
epos []bpos // cached entries positions in buffer
}
type bpos struct {
pos int // byte position, 一条日志在 ebuf 的开始位置.
end int // one byte past pos, 一条日志在 ebuf 的结束位置.
}
如何获取当前最大的 Index
前面有说, wal 启动阶段会扫描所有的 segment, 拿到最后一个 segment 的最后一个 entry 的 index,这个 index 就是当前的 index.
注意 index 是单调递增的,每次写日志时,都会对 index 加一.
定义每条日志的边界
如果是 binary 的格式,采用类似 TLV 的设计,写入时每条消息前面加个二进制编码过的 uvarint 可变长数值. 读取时先拿到 uvarint ,然后再读取该数值后面的字节.
func (l *Log) appendEntry(dst []byte, index uint64, data []byte) (out []byte,
epos bpos) {
if l.opts.LogFormat == JSON {
return appendJSONEntry(dst, index, data)
}
return appendBinaryEntry(dst, data)
}
func appendBinaryEntry(dst []byte, data []byte) (out []byte, epos bpos) {
// data_size + data
pos := len(dst)
dst = appendUvarint(dst, uint64(len(data))) // 写入 length 长度
dst = append(dst, data...) // 写入 data 数据
return dst, bpos{pos, len(dst)}
}
func appendUvarint(dst []byte, x uint64) []byte {
var buf [10]byte
n := binary.PutUvarint(buf[:], x)
dst = append(dst, buf[:n]...)
return dst
}
json 的格式在编码上显得奇怪,不明白 tidwall 为什么会设计 json 格式的 wal.
Read 读流程
- 先从 segment lru 缓存中查找, 哪些 segment 包含该 index
- 继续从 segments 数组中确认 index 在哪一个 segment 上
- 读取 segment 文件里面的数据, 装载到内存中
- 找到 index 对应的数据,并使用
binary.Uvarint解码 entry 的 length.
Write 写流程
wal 的写倒是简单,就是 append 追加写.
- 获取尾节点,如果空间大则实例化一个新的.
- 把 batch 里面的数据写到 file 里, 如果写入的过程中,发现 segment 大于阈值,也进行 segment 重分配.
- 通过 binary 或者 json 进行编码后写入.
- 写入的过程中判断 segment 是否过大,触发阈值则进行重分配.
- 把数据写到 segment file 里.
- 如果开启了 sync 同步选项,则每次写完数据后调用 sync 同步.
清理日志
wal 提供了 TruncateFront(index) 方法来删除日志,但需要注意的是,在清理之前,一定需要先把 wal 对应内存里的数据进行持久化到 db 文件中,再清理 wal 日志.
err = l.TruncateFront(350)
清理日志流程如下:
- 通过 index 寻找 segment.
- 删掉 index 之前的那些 segment 对应的文件
- 如果 index 在 segment 的前面位置,那么首先在内存中清理该 segment index 之前的数据,然后再把数据写到一个临时文件里.
- 然后修改下临时文件的文件名.
- 更新内存中的各个指标.
这里没有使用类似 mysql checkpoint lsn 的概念,而是直接删除数据. 如果删除 segment 失败,或者删除 segment 一段数据数据失败,也没大关系. 按照 tidwall wal 的恢复设计,重启后会找到当前最老的数据进行重做.
一般 wal 的日志在设计上都是支持幂等的,重做多遍也不受影响的,但日志的格式需要是原始格式才可幂等,val ++ 操作改为记录 val 最后的值,这样的话,重做多遍也不影响的.
FAQ
segment 为什么存放完整的 []byte 数组, 而不是一段段的 []byte ?
应该是为了性能,持久化时直接使用该 []byte 数组,无需拼凑. 另外 append 时无需每次都 alloc,另外对于 gc 也相对友好.
