1.1.1. 交换机/路由器
交换机用于二层通信(不跨网段),路由器用于三层通信(跨网段)。
我之前有过这样的疑惑:交换机既然用于二层通信,发送方只要知道接收方的mac地址即可通信,为什么还要要求接收方的ip地址和自己在同一个网段?
后来想想,如上图所示,PC1既然是使用ip地址访问PC3,那就得遵守三层通信的规则,PC1发现自己和PC3不在一个网段,就会转去和路由器二层通信,期望路由器到别的网段找到PC3,所以说PC1只是没有和PC3二层通信,而不是不能和PC3二层通信。
1.1.2. 交换机级联
多台交换机的普通口或trunk口之间,通过网线直连在一起,等效于多台交换机合并成了一台交换机,称为“级联”,其中,通过trunk口级联,每台交换机上id相同的vlan,也会被合并。

1.1.3. Overlay二层通信
交换机之间,还可以通过TEP口(Tunnel EndPoint,隧道端点)级联,合并成一台Overlay交换机。TEP口之间是三层网络,如图所示,只要能理解,它是如何如同网线直连一样,将PC1构造的报文,原封不动的发送到PC2,那么它就没有什么神秘的:
① PC1构造“mac1 : 192.168.1.6 -> mac2 : 192.168.1.7”报文,发送到直连交换机;
② 直连交换机根据自己的mac表,找不到mac2,就将报文复制到TEP口;
③ TEP口将PC1构造的报文,作为负载,构造udp报文,发送到跟它相连的TEP口;
④ udp报文到达对方TEP口后,解析得到其负载,还原出“mac1 : 192.168.1.6 -> mac2 : 192.168.1.7”报文,并查询mac表,将其发送给PC2。

从上面的过程可以看出,隧道两端的封装和解封装过程,对于PC1与PC2之间的二层通信是透明的,它相比普通级联,可以突破地域的限制,比如,相隔十万八千里的2台交换机,通过网线级联是不现实的,只能通过隧道进行级联。
1.2.1. 交换机
通信实质上就是,将数据从发送方复制到接收方,因此很容易理解,一台设备要与多台设备通信,就必须跟多台设备之间存在传输介质(无线通信设备之间也不例外,只不过肉眼看不见而已),所以诞生了交换机,它提供一对多连接的功能,使得设备只要跟交换机相连,就能跟其它多台设备相连。
1.2.2. mac地址
单台交换机的端口数量是有限的,所以交换机与交换机之间必须支持级联,才能将全世界的设备联系在一起,所以,要指明一台设备的位置,其实就是要指明“交换机:端口号”,比如“switch2:端口2”。

但是,ip报文中,使用的却是“ip:mac”地址,因此可以推测,ip地址与交换机之间存在映射,先锁定一个较大的范围,mac地址与端口号之间存在映射,进一步锁定精确位置。

交换机支持同一网段的设备通信,所以交换机地址其实等效于网段的地址,ip地址中的“网络号,其实是非常直白的指明了交换机地址。关于个人对ip地址的理解,稍后再详细介绍,暂且只关注mac地址:报文中为什么不直接写明端口号,而是使用mac地址,非要由交换机查询mac表,经过一次映射才能得到端口号?
根据个人理解,mac地址的设计意图,包括2个方面:
(1) 跟最后一跳路由器连接的,可能不是单台交换机,而是级联在一起的多台交换机,那么,就必须对这些交换机的所有端口,进行统一编号,保证每个口的编号都是唯一的;
(2) 让设备具体连接在交换机的哪个端口,对通信对端透明,比如,将设备从一个端口拔掉,连接到另一个端口,只需要修改mac表,就可以保证它仍然对外可见。
想到这里就明白了,地址的分层缘于地址映射,ip地址在路由器层,映射到某个路由器端口(连接着目标交换机),mac地址在交换机层,映射到某个交换机端口(连接着目标设备)。相应也就能理解,具体的交换机端口其实就是一层地址,它是物理上存在,但对通信双方透明的,因此报文中只有三层ip地址和二层mac地址,而没有一层地址。
另外,mac地址跟设备必须是强绑定的,如果是可以修改的,就很难保证唯一性,就像ip冲突一样,因此mac地址在设备出厂时,就固定设置好了,所以也很好理解,mac地址必须由专门的组织管理分配,从而保证每个已分配的地址都具备全球唯一性。其中,mac地址长度被设计为6字节,即地址空间大小为2^48,按每年消耗100亿个计算,可以使用28000多年。
1.2.3. 路由器
根据1.1.2、1.1.3节可以知道,交换机之间可以通过普通口、trunk口、TEP口相连,这些连接方式,流量在连接口之间都是全量转发,相比之下,个人习惯将路由器理解为交换机之间的另一种连接方式,并且它的作用是,使流量在连接口之间有选择的转发,而选择的依据就是,各种路由协议在路由器中生成的路由表。

对比图中的2种连接方式,并假设发送方在switch1交换机,接收方在switch2交换机,就可以很好的理解这一点:
(1) 网线直连(交换机级联)
发送报文到达switch1之后,switch1在自己的mac表上找不到接收方mac地址,就会向switch2和switch3都转发(这是因为switch1无法预知接收方到底在哪个交换机上),switch3在自己 mac表上没找到,也会继续向switchN转发(因为它无法知道接收方会在switch2上被找到)。
(2) 通过路由器相连
从左图可以看出,报文其实是没有必要沿着红色线路白走一圈的,而路由器有选择的转发,就可以避免这个情况。
个人理解,路由器的设计意图仅此而已,对于“路由器可以隔离广播域”的说法,曾经让我误以为,路由器就是为隔离广播域而设计,确实,不管是链路层广播报文,还是网络层广播报文,路由器都不会继续转发,效果上的确可以隔离广播域,但是,“可以”和“设计意图”是两个概念,好比大炮的两头可以导电,并不代表设计大炮就是用于导电。
所以,不知道有没有人和我一样存在这个误解,存在这个误解,也会存在这样的疑惑:既然广播ARP请求包的目的,是查询目的ip主机的mac地址,那么“广播”和“ip地址”就是一对共生的概念,而“ip地址”又是伴随“路由器”的概念产生,也就是说,没有“路由器”也就不会有“广播”,为什么反而说,路由器的作用是隔离广播域?
1.2.4. ip地址
1.2.2节已经提到,ip地址包含网络号,用于在路由器层穿梭,实际上,ip地址还包含主机号。很显然,主机号必须跟mac地址之间存在映射关系,比如,通过ssh连接一个ip地址,其中的网络号,只能找到目标设备所在的交换机,要进一步找到设备所在的端口,还需要mac地址。
个人猜测,这大概是针对使用体验的一个设计,假设ip地址没有设计成“网络号+主机号”,而是“网络号+mac地址”的话,一方面,ip地址会非常长,实际上,根据网络号找到目标设备所在的交换机后,就已经将目标设备锁定在一个很小的范围了,也就是说,使用很小的地址空间,就可以对这些主机编码,另一方面,ip作为三层地址,里面还掺和着mac地址的话,概念上也会相对混乱。
1.2.5. ARP
ip主机号与mac地址的映射关系,不是集中在一张表里,而是分散在每台设备上,因此,如果发送方的ARP表找不到目的设备的mac地址,就要广播ARP请求,询问目标设备的mac地址,具体过程就不详述了。

- ESXi/KVM
虚拟化系统,提供虚假化能力和接口,支持安装在物理机中,使得可以在物理机中创建设备,也支持嵌套,安装到虚拟机中,使得虚拟宿主机中可以进一步创建虚拟机。 - vCenter
一套封装ESXi主机接口和资源的平台,它可以添加多台ESXi主机,然后间接提供给用户,比如用户通过vCenter创建VM,实际上在某台ESXi主机中创建了VM。 - NSX-t
一套封装ESXi/KVM主机接口和资源的平台,它侧重于封装通信虚拟设备的操作接口,比如交换机和路由器的创建、连接、删除等,使主机中创建的VM,可以相互通信。并且,它支持和vCenter结合使用,vCenter注册到NSX-t之后,其中添加的ESXi主机就会对NSX-t也可见,由于vCenter不支持添加KVM主机,所以KVM主机必须直接添加到NSX-t。 - 虚拟交换机
ESXi系统安装后,默认会创建一台VSS(虚拟标准交换机),因为将ESXi主机添加到vCenter的过程中,vCenter会在其中安插几台VM,从而可以对它进行管理,而这几台VM就是通过VSS接入管理网段,和vCenter进行通信的。另外,通过vCenter,可以创建VDS(vSphere分布式交换机),通过NSX-t,可以创建NVDS(NSX-t虚拟分布式交换机)。 - 虚拟路由器
通过NSX-t,可以创建T1(东西向路由器)和T0(南北向路由器)。
2.2.1. 概念
NSX-t虚拟交换机(NVDS)
通过NSX-t创建,它可以借助宿主机的通信能力,建立宿主机内部VM与宿主机外部通信的桥梁。传输节点(Transport Node,简称:TN)
可以将NVDS与TN,理解为面向对象编程语言中“类-对象”的关系,NVDS只是一个概念,也可以将它理解为一种虚拟交换机类型,TN则是指一台会被真实创建的NVDS实例。另外,目前查看到的资料,都将每台ESXi/KVM主机看作一个TN,个人猜测,这可能跟NSX-t上支持“将主机添加到TZ”的操作有关,这容易让用户在直觉上,认为是将主机加入了TZ,从而认为主机就是TN,但是实际是在主机中创建了TN,然后主机随着TN加入到了TZ,就是说主机与TN之间有对应关系,但是TN≠主机。传输区域(Transport Zone,简称:TZ)
个人认为:TZ = 多台TN的级联交换机。网段(Segment)
可以进行二层通信的一组交换机端口,所以也称端口组(port group,简称:PG),有些资料也称为vSwitch,比如一个vlan,或者基于vxlan隧道建立的Overlay交换机上,VNI相同的端口集合。
- 上行口(Uplink)

物理世界中,通信设备之间是通过物理介质相连,比如网线,然而虚拟通信设备上是没有办法插网线的,只能通过软件模拟连接。在每个宿主机内部,VM要能和交换机连接,所以要实现进程间的数据共享,另外,宿主机中的任何通信程序,都要借助宿主机网卡收发流量,虚拟交换机组件也不例外,所以要实现交换机组件的网卡读写功能,使其逻辑上存在一个端口,即“上行口”,可以借助宿主机网卡跟外部通信。
2.2.2. 配置
理解了以上概念,就很容易理解NSX-t二层网络的配置的过程了:
创建IP地址池
1
2
3
4
5
6
7
创建IP地址池|-NSX-t manager->Networking->IP Management->IP Address Pools->ADD|-Name: VTEP-IP-Pool|-SetSubnets|-IP Ranges:172.20.11.151-172.20.11.170|-CIDR:172.20.11.0/24|-Gateway IP:172.20.11.10目的:后续操作,在每台主机中创建PROD-Overlay-NVDS交换机(TN)时,需要从VTEP-IP-Pool地址池,为交换机的TEP口分配ip地址。
创建TZ
1
2
3
4
5
6
7
8
9
10
创建PROD-Overlay-TZ|-NSX-t manager->System->Fabric->Transport Zones->ADD|-Name: PROD-Overlay-TZ|-Switch Name: PROD-Overlay-NVDS|-TrafficType: Overlay创建PROD-VLAN-TZ|-NSX-t manager->System->Fabric->Transport Zones->ADD|-Name: PROD-VLAN-TZ|-Switch Name: PROD-VLAN-NVDS|-TrafficType: VLAN目的:描述TZ(多台TN的级联交换机),包括:TZ名称、加入该TZ需要创建的TN名称及Traffic Type。
Overlay主要优势:
(1) 相比vlan-id最大值只有4094,VNI接近16M个,极大的增加了一个二层区域可以容纳的设备数;
(2) 只要主机之间能三层通信,就可以将其中创建的VM放在同一个二层区域,二层区域不再限制于一个机房的范围,极大的提高了VM部署和迁移的灵活性。
实验环境中,如果所有ESXi/KVM主机,都在同一个二层区域,创建TZ的时候,无论选择哪种Traffic Type,其实都可以满足VM之间二层通信,但是如果不满足这个条件,那就必须选择Overlay,本文实验中,选择的是PROD-Overlay-TZ。而这里同时还创建了PROD-VLAN-TZ,是为了后续实现南北向三层通信时,将T0路由器和物理路由器接入同一个网段。- 将ESXi/KVM主机加入TZ
目的:在主机中创建TN,并级联到现有的TZ中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
主机加入TZ|-NSX-t manager->System->Fabric->Nodes->Host Transport Nodes->ADD|-选择主机| |-sa-vcsa-01.vclass.local| | |-ESXi04| | |-ESXi05| |-None: Standalone Hosts| |-kvm-01| | |-Name: sa-kvm-01.vclass.local| | |-IP Address:172.20.10.151| | |-Username:*****| | |-Password:*****| |-kvm-02| |-Name: sa-kvm-02.vclass.local| |-IP Address:172.20.10.152| |-Username:*****| |-Password:*****|-CONFIGURE NSX|-选择Transport Node Profile (没有先创建)|-Name: ESXi-TN-Profile|-New Node Switch|-Type: N-VDS|-Mode: Standard|-Name: PROD-Overlay-NVDS|-Transport Zone: PROD-Overlay-TZ|-Uplink Profile: nsx-default-uplink-hostswitch-profile|-IP Assignment: Use IP Pool|-IP Pool: VTEP-IP-Pool|-Teaming Policy Switch Mapping|-uplink-1(active): vmnic4/eth1
根据目的就不难理解,配置中除了指定TZ,为什么还要指定一堆TN描述信息,包括:Name、Type(N-VDS)、Mode、IP Pool(为PROD-Overlay-TZ的TEP口提供ip地址)、Uplink Profile(uplink策略,后续如果为TN设置2个上行口,则为主备模式)、uplink-1(由于是实验环境,对高可用性要求不高,不配uplink-2可以理解为备用上行口天然就是坏的,主备只要有一个是好的,就不会影响通信)。 - PROD-Overlay-TZ添加segment
目的:相当于在PROD-Overlay-TZ级联交换机上,划分了3个vlan:Web-Segment、App-Segment、DB-Segment。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
添加Web-Segment|-NSX-t manager->Networking->Segments->ADD|-Segment Name: Web-Segment|-Connectivity: 暂时不选 (将来选择T1-GW-01|Tier1)|-Transport Zone: PROD-Overlay-TZ|-subnets: 暂时不填 (将来填:172.16.10.1/24)添加App-segment|-NSX-t manager->Networking->Segments->ADD|-Segment Name: App-Segment|-Connectivity: 暂时不选 (将来选择T1-GW-01|Tier1)|-Transport Zone: PROD-Overlay-TZ|-subnets: 暂时不填 (将来填:172.16.20.1/24)添加DB-segment|-NSX-t manager->Networking->Segments->ADD|-Segment Name: DB-Segment|-Connectivity: 暂时不选 (将来选择T1-GW-01|Tier1)|-Transport Zone: PROD-Overlay-TZ|-subnets: 暂时不填 (将来填:172.16.30.1/24) - VM接入segment
目的:将VM接入不同的Segment,不过以上只是描述了接入的方法,实验环境中,具体连接见2.2.3节逻辑拓扑和物理拓扑:1
2
3
4
5
6
7
8
9
10
11
12
ESXi主机中的vm连接到segment (vcenter: 右键vm->Edit Settings)|-Network adapter: Web-Segment/App-Segment/DB-SegmentKVM主机中的vm连接到segment|-ssh连接KVM主机| |-virshlist--all| |-virsh start T1-DB-01| |-virsh dumpxml T1-DB-01| grep interfaceid|-NSX-t manager->..->SEGMENTS|-编译Web-Segment/App-Segment/DB-Segment->点击Ports列中的Set|-ID: vm网卡的uuid
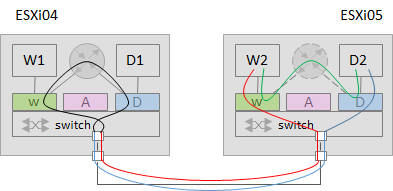
(1) ESXi04主机中的T1-web-01(172.16.10.11/24)、ESXi05主机中的T1-web-02(172.16.10.12/24)、kvm-02主机中的T1-web-03(172.16.10.13/24),3台VM接入Web-Segment;
(2) ESXi04主机中的T1-App-01(172.16.20.11/24),1台VM接入App-Segment;
(3) kvm-01主机中的T1-DB-01(172.16.30.11/24),1台VM接入DB-Segment。
2.2.3. 二层通信流程
2.3.1. 概念
T1(东西向)/ T0(南北向)路由器

T1和T0,都是指路由器,区别在于T1用于转发单个租户的内部流量(东西向),就是说,它的端口仅仅会跟单个租户的不同segment相连,T0用于租户内部跟外部网络之间的流量(南北向),它一方面连接着多个租户的T1,另一方面与通往外部网络的物理路由器,连接在同一个网段。
比如,公司A的web服务器,要对外开放就必须跟T0路由器之间有连接,而DB服务器不希望暴露到外网,只要能与web服务器内部通信即可,那么它们之间仅用T1路由器连接即可。同理,假设公司B的2个部门使用不同的网段,仅通过T1路由器连接,就可以实现内部通信,如果还希望他们都能访问公司A的web服务,就必须还要将T1接到T0上。
虚拟路由器和虚拟交换机一样,也是由软件实现,其中,T1与TN是一一对应存在的,但不同的是,交换机是级联的关系,而路由器是重复的关系,理论上,在任意一台TN所在主机中安装T1路由器,就可以满足单个租户的东西向流量转发。
比如,如下物理拓扑中,仅ESXi04主机中安装了T1路由器,则:
(1) ESXi04内部,任意2个网段之间可以路由;
(2) ESXi04与ESXi05中的任意2个网段,也可以路由(ESXi04内部的Web-Segment网段与DB-Segment网段之间,可以通过T1路由器转发,剩下的就是Overlay二层转发过程,这已经在2.2.3节详细介绍过);
(3) SXi05内部,任意2个网段之间,也可以路由。
但是,对于情况(3),即使W2和D2两台虚拟机在同一宿主机,相互发给对方的报文,却要从外部绕一个大圈子,为此,在创建T1路由器时,NSX-t会在所有TN所在主机中安装(路由表会由NSX-t Controller集中同步),一方面避免了绕圈的情况,另一方面也起到容错的效果(比如情况(3), ESXi05主机会优先使用自己内部的T1,如果自己的T1出现故障,利用ESXi04中的T1,仍然可以路由)。Edge Node
上述内容已经提到过,T0路由器需要连接的对象有2种:一是不同租户希望连接到外网的T1路由器,二是通往外部网络的物理路由器。根据这样的连接需求,NSX-t要求,必须将T0安装在一台独立的主机中,这种主机就是“Edge Node”,也就是说,“Edge Node”实际上就是一台主机,通常也是某台ESXi/KVM主机中的一台VM,只不过它专门用于安装T0路由器。
个人认为,这样是为了将T0路由器及其需要连接的网段,与宿主机系统中的业务资源隔离开,否则,原本要在Edge Node中添加的物理路由器所在网段,就得直接在宿主机中添加,直接暴露给T1路由器。DR(分布式路由器)/ SR(服务路由器)
T1/T0路由器,都可以再继续细分为DR/SR路由器。
以上对T1的介绍,实际上只是T1-DR,NSX-t会为每台TN对应创建一个T1-DR,每台TN优先使用与自己在同一主机的T1-DR,进行三层转发,这样就不能对东西向流量进行集中的控制,比如像情况(2)那样,可以让所有东西向流量,只经过一台路由器。因此,NSX-t还可以创建T1-SR,从而可以为租户内部流量,提供负载均衡等服务,这也正是“服务路由器”这个名称的由来,不过,它和情况(2)对应的拓扑不同,首先,T1-SR不直接接入网段,而是和T1-DR相连,另外,它也不是直接在ESXi/KVM主机中创建,而是在Edge Node中创建。
T1-DR、T1-SR(可选)、T0-DR、T0-SR的安装位置:
建议对照这个规则,提前看一下2.3.5节中的物理拓扑图,了解一下两种实例场景中,4种路由器的具体安装位置。
根据拓扑可以看出,T0-DR是T1与T0-SR之间的桥梁,如果没有创建T1-SR,NSX-t会为每台T1-DR对应创建一台T0-DR,否则为每台T1-SR对应创建一台T0-DR,并且通过内部网段,建立它们到T0-SR的通信链路(我目前还没理解T0-DR存在的意义,总觉得它是多余的,不知道T1直接跟T0-SR接在同一个网段,会有什么问题)。而T0-SR很好理解,就是一边可以跟业务网段通信,一边可以跟外部网络通信。
最后需要特别了解的一点是,多台实际的DR,逻辑上相当于一台DR,所有端口的mac地址相同,每份路由表也是一样的。
2.3.2. T1网关配置
创建T1网关
1
2
3
4
创建T1网关 (分布式的,直接存在于ESXi/KVM/Edge等主机中)|-NSX-t manager->Networking->Connectivity->Tier-1Gateways->ADD TIER-1GATEWAY|-Tier-1Gateway Name: T1-GW-01|-Linked Tier-0Gateway: 暂时不选 (将来选择T0-GW-01)目的:用于东西向流量转发。
T1路由器接入segment
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
T1路由器接入Web-Segment|-NSX-t manager->Networking->Connectivity->Segment|-Web-Segment->Edit|-Connectivity: T1-GW-01|Tier1|-subnets:172.16.10.1/24T1路由器接入App-segment|-NSX-t manager->Networking->Connectivity->Segment|-App-Segment->Edit|-Connectivity: T1-GW-01|Tier1|-subnets:172.16.20.1/24T1路由器接入DB-segment|-NSX-t manager->Networking->Connectivity->Segment|-DB-Segment->Edit|-Connectivity: T1-GW-01|Tier1|-subnets:172.16.30.1/24目的:使Web-Segment、App-Segment、DB-Segment网段上的VM,可以跟T1二层通信。
2.3.3. 东西向三层通信流程
2.3.4. T0网关配置
创建Edge Node
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
创建Edge虚机|-NSX-t manager->System->Fabric->Nodes->Edge Transport Nodes->ADD EDGE VM|-NameandDescription| |-Name: sa-nsxedge-01, sa-nsxedge-02| |-Host name/FQDN: sa-nsxedge-01.vclass.local| |-Form Factor: Medium|-Credentials| |-CLI User Name:*****| |-CLI Password:*****| |-System Root Password:*****|-Configure Deployment| |-Compute Manager: 选择sa-vcsa-01.vclass.local| |-Cluster: 选择SA-Management-Edge| |-Datastore: 选择SA-Shared-02-Remote|-Configure Node Settings| |-IP Assignment: static| |-Management IP:172.20.10.61/24| |-Default Gateway:172.20.10.10| |-Select Interface| | |-pg-SA-Management| |-Search Domain Names: vclass.local| |-DNS Servers:172.20.10.10| |-NTP Servers:172.20.10.10|-Configure NSX|-New Node Switch| |-Edge Switch Name: PROD-Overlay-NVDS| |-Transport Zone: 选择PROD-Overlay-TZ| |-Uplink Profile: 选择nsx-edge-single-nic-uplink-profile| |-IP Assignment: 选择Use IP Pool| |-IP Pool: 选择VTEP-IP-Pool| |-Teaming Policy Switch Mapping| |-uplink-1(active): 选择pg-SA-Edge-Overlay|-New Node Switch (点击ADD SWITCH)|-Edge Switch Name: PROD-VLAN-NVDS|-Transport Zone: 选择PROD-VLAN-TZ|-Uplink Profile: 选择nsx-edge-single-nic-uplink-profile|-Teaming Policy Switch Mapping|-uplink-1(active): 选择pg-SA-Edge-Uplinks目的:为T0-SR提供安装场所(T1-SR、T0-DR也有可能安装在Edge Node中)。
创建Edge Node集群
1
2
3
4
5
6
7
创建Edge集群|-NSX-t manager->System->Fabric->Nodes->Edge Cluster->ADD|-Name: Edge-Cluster-01|-Edge Cluster Profile: 选择nsx-default-edge-high-availability-profile|-选择要添加到集群中的Edge|-sa-nsxedge-01|-sa-nsxedge-02目的:相当于将多个Edge Node“打包”在一起(实验环境不考虑高可用,创建一个Edge Node即可,所以可以跳过这步操作)。
PROD-VLAN-TZ添加segment
1
2
3
4
5
6
7
8
9
10
11
12
13
14
添加T0-GW-01-Uplink-1|-NSX-t manager->Networking->Segments->ADD|-Segment Name: T0-GW-01-Uplink-1|-Connectivity: 不填|-Transport Zone: 选择PROD-VLAN-TZ|-subnets: 不填|-VLAN:0添加T0-GW-01-Uplink-2|-NSX-t manager->Networking->Segments->ADD|-Segment Name: T0-GW-01-Uplink-2|-Connectivity: 不填|-Transport Zone: 选择PROD-VLAN-TZ|-subnets: 不填|-VLAN:0目的:相当于在PROD-VLAN-TZ交换机上,划分了2个vlan:T0-GW-01-Uplink-1、T0-GW-01-Uplink-2(这两个网段,最终会和物理路由器所在网段级联,T0接入后,就可以和物理路由器二层通信)。
创建T0网关
1
2
3
4
5
创建T0网关 (集中式的,需要先创建Edge虚拟机)|-NSX-t manager->Networking->Connectivity->Tier-0Gateways->ADD GATEWAY->Tier-0|-Tier-0Gateway Name: T0-GW-01|-HA Mode: 选择Active-Active|-Edge Cluster: 选择Edge-Cluster-01目的:用于南北向流量转发。
连接T1路由器与T0路由器
1
2
3
T1路由器连接到T0路由器|-NSX-t manager->Networking->Connectivity->Tier-1Gateways->Edit(T1-GW-01)|-Linked Tier-0Gateway: T0-GW-01目的:以T0路由器为桥梁,间接连接到物理路由器,或者其它T1路由器(T0与T1之间的接口连接、ip配置,由NSX-t自动完成)。
T0-SR路由器添加接口,并与物理路由器接入同一网段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
给T0-SR添加int1接口|-NSX-t manager->Networking->Connectivity->Tier-1Gateways->Edit (T1-GW-01)|-INTERFACES->ExternalandService Interfaces->Set->ADD INTERFACES|-Name: int1|-IP Address/Mask:192.168.100.2/24|-Connected To(Segment): T0-GW-01-Uplink-1|-Edge Node: sa-nsxedge-01给T0-SR添加int2接口|-NSX-t manager->Networking->Connectivity->Tier-1Gateways->Edit (T1-GW-01)|-INTERFACES->ExternalandService Interfaces->Set->ADD INTERFACES|-Name: int2|-IP Address/Mask:192.168.110.2/24|-Connected To(Segment): T0-GW-01-Uplink-2|-Edge Node: sa-nsxedge-02目的:使T0路由器,可以跟物理路由器二层通信。
同步路由表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
将T1内部直连的业务网段路由通告给T0|-NSX-t manager->Networking->Connectivity->Tier-1Gateways->Edit (T1-GW-01)|-Route advertisement|-AllConnected Segment & Service Ports: 开启T1路由器添加int1/int2接口设置邻居|-NSX-t manager->Networking->Connectivity->Tier-0Gateways->Edit (T0-GW-01)|-BGP|-Local AS:100|-BGP Neighbors->Set|-ADD BGP NEIGHBOR| |-IP Address:192.168.100.1| |-Remote AS number:200| |-Source Addresses:192.168.100.2|-ADD BGP NEIGHBOR|-IP Address:192.168.110.1|-Remote AS number:200|-Source Addresses:192.168.110.2将T1内部的业务网段路由通告给物理路由器|-NSX-t manager->Networking->Connectivity->Tier-0Gateways->Edit (T0-GW-01)|-ROUTE RE-DISTRIBUTION->Set->ADD ROUTE RE-DISTRIBUTION|-Nmae:123|-Set|-Connected Interfaces & Segment: 选中目的:更新T1、T0、物理路由器中的路由表。
2.3.5. 南北向三层通信流程
- 逻辑拓扑

AA:active-active
AS:active-standby
T1-DR与T1-SR、T1-DR与T0-DR、T1-SR与T0-DR、T0-DR与T0-SR之间,路由接口的创建、连接、ip分配,由NSX-t自动完成。 - 物理拓扑
2.3.4节的配置过程,没有包含:
(1) Edge-Overlay和Edge-uplink网段的创建(参照2.2.2节:PROD-Overlay-TZ添加segment);
(2) Edge Node的pg-SA-Edge-Overlay和pg-SA-Edge-Uplinks网卡的创建(Edge Node也是VM,右键选择“编辑虚拟机”,即可设置);
(3) pg-SA-Edge-Overlay和pg-SA-Edge-Uplinks网卡,分别连接到Edge-Overlay和Edge-uplink网段(参考2.2.2节:VM接入segment)。 - 实例1:T1-DR + T0-DR + T0-SR

实例2:T1-DR + T1-SR + T0-DR + T0-SR

路由表
实例1中各个路由器中的路由表如下(实例2略):
2.3.5.4. 报文传送过程
假设:W1(172.16.10.11)-> PC(172.20.10.80)
这里仅以实例1拓扑举例,实例2相比实例1,仅仅是三层转发过程中,多经过一下T1-SR(active-standby)路由器。
Step1:W1发现PC和自己不在一个网段,所以构造“W1 mac : 172.16.10.11 -> T1-DR mac : 172.20.10.80”报文(忽略ARP获取T1-DR mac地址的过程),通过交换机发送到T1-DR;
Step1.5:T1-DR查找路由表,命中“0.0.0.0/0 -> 100.64.32.1”,并根据ARP表或发送ARP请求,查询100.64.32.1的mac(AA);
Step2:T1-DR构造“T1-DR mac : 172.16.10.11 -> AA : 172.20.10.80”报文,发送到T0-DR;
Step2.5:T0-DR查找路由表,命中“0.0.0.0/0 -> 169.254.0.2 / 169.254.0.3”等价路径,假设本次选择169.254.0.2,并根据ARP表或发送ARP请求,查询其mac(BB);
Step3:T0-DR构造“AA : 172.16.10.11 -> BB : 172.20.10.80”报文;
Step4:T0-DR构造的报文穿过Overlay隧道,转发Edge Node中的交换机;
Step5:“AA : 172.16.10.11 -> BB : 172.20.10.80”报文,到达T0-SR1路由器;
Step5.5:T0-SR1查找路由表,命中“172.20.10.0/24 -> 192.168.100.1”,并根据ARP表或发送ARP请求,查询192.168.100.1的mac为CC;
Step6:T0-SR1构造“BB : 172.16.10.11 -> CC : 172.20.10.80”报文,发送到物理路由器;
Step7:物理路由器转发给外部PC。
参考:
https://space.bilibili.com/405480256?spm_id_from=333.905.b_7570496e666f.3
https://space.bilibili.com/618114154/?spm_id_from=333.999.0.0
如有侵权请联系:admin#unsafe.sh