作者:tayroctang,腾讯 PCG 后台开发工程师本文从 5W1H 角度介绍了分库分表手段,其在解决如 IO 瓶颈、读写性能、物理存储瓶颈、内存瓶颈、单机故障影响面等问题的同时也带来如事务性、主 2022-12-20 18:2:21 Author: 腾讯技术工程(查看原文) 阅读量:26 收藏
作者:tayroctang,腾讯 PCG 后台开发工程师
本文从 5W1H 角度介绍了分库分表手段,其在解决如 IO 瓶颈、读写性能、物理存储瓶颈、内存瓶颈、单机故障影响面等问题的同时也带来如事务性、主键冲突、跨库 join、跨库聚合查询等问题。anyway,在综合业务场景考虑,正如缓存的使用一样,本着非必须勿使用原则。如数据库确实成为性能瓶颈时,在设计分库分表方案时也应充分考虑方案的扩展性,或者考虑采用成熟热门的分布式数据库解决方案,如 TiDB。
阅读此文你将了解:
什么是分库分表以及为什么分库分表 如何分库分表 分库分表常见几种方式以及优缺点 如何选择分库分表的方式
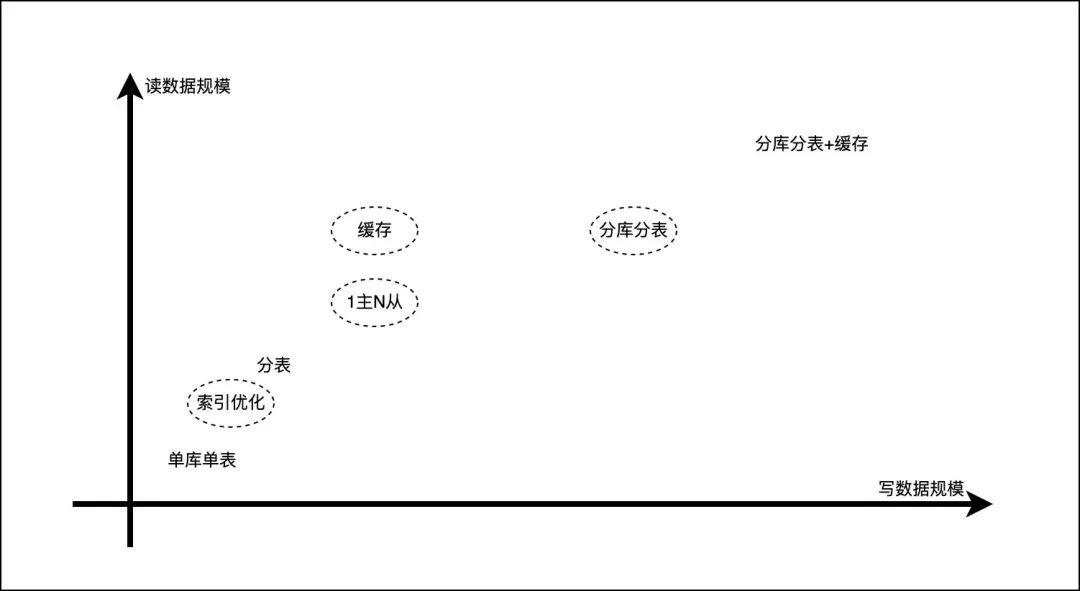
数据库常见优化方案
对于后端程序员来说,绕不开数据库的使用与方案选型,那么随着业务规模的逐渐扩大,其对于存储的使用上也需要随之进行升级和优化。
随着规模的扩大,数据库面临如下问题:
读压力:并发 QPS、索引不合理、SQL 语句不合理、锁粒度 写压力:并发 QPS、事务、锁粒度 物理性能:磁盘瓶颈、CPU 瓶颈、内存瓶颈、IO 瓶颈 其他:宕机、网络异常
面对上述问题,常见的优化手段有:
索引优化、主从同步、缓存、分库分表每个技术手段都可以作为一个专题进行讲解,本文主要介绍分库分表的技术方案实现。
什么是分库分表?
对于阅读本文的读者来说,分库分表概念应该并不会陌生,其拆开来讲是分库和分表两个手段:
分表:将一个表中的数据按照某种规则分拆到多张表中,降低锁粒度以及索引树,提升数据查询效率。 分库:将一个数据库中的数据按照某种规则分拆到多个数据库中,以缓解单服务器的压力(CPU、内存、磁盘、IO)。
为什么分库分表?
性能角度:CPU、内存、磁盘、IO 瓶颈
随着业务体量扩大,数据规模达到百万行,数据库索引树庞大,查询性能出现瓶颈。 用户并发流量规模扩大,由于单库(单服务器)物理性能限制也无法承载大流量。 可用性角度:单机故障率影响面
如果是单库,数据库宕机会导致 100%服务不可用,N 库则可以将影响面降低 N 倍。
分库分表带来的问题?
事务性问题
方案一:在进行分库分表方案设计过程中,从业务角度出发,尽可能保证一个事务所操作的表分布在一个库中,从而实现数据库层面的事务保证。 方案二:方式一无法实现的情况下,业务层引入分布式事务组件保证事务性,如事务性消息、TCC、Seata 等分布式事务方式实现数据最终一致性。 分库可能导致执行一次事务所需的数据分布在不同服务器上,数据库层面无法实现事务性操作,需要更上层业务引入分布式事务操作,难免会给业务带来一定复杂性,那么要想解决事务性问题一般有两种手段:
主键(自增 ID)唯一性问题
在数据库表设计时,经常会使用自增 ID 作为数据主键,这就导致后续在迁库迁表、或者分库分表操作时,会因为主键的变化或者主键不唯一产生冲突,要解决主键不唯一问题,有如下方案: 方案一:自增 ID 做主键时,设置自增步长,采用等差数列递增,避免各个库表的主键冲突。但是这个方案仍然无法解决迁库迁表、以及分库分表扩容导致主键 ID 变化问题 方案二:主键采用全局统一 ID 生成机制:如 UUID、雪花算法、数据库号段等方式。 跨库多表 join 问题
首先来自大厂 DBA 的建议是,线上服务尽可能不要有表的 join 操作,join 操作往往会给后续的分库分表操作带来各种问题,可能导致数据的死锁。可以采用多次查询业务层进行数据组装(需要考虑业务上多次查询的事务性的容忍度) 跨库聚合查询问题
分库分表会导致常规聚合查询操作,如 group by,order by 等变的异常复杂。需要复杂的业务代码才能实现上述业务逻辑,其常见操作方式有:
§ 方案一:赛道赛马机制,每次从 N 个库表中查询出 TOP N 数据,然后在业务层代码中进行聚合合并操作。
§ 假设: 以2库1表为例,每次分页查询N条数据。
§
§ 第一次查询:
§ ① 每个表中分别查询出N条数据:
§ SELECT * FROM db1_table1 where $col > 0 order by $col LIMITT 0,N
§ SELECT * FROM db2_table1 where $col > 0 order by $col LIMITT 0,N
§ ② 业务层代码对上述两者做归并排序,假设最终取db1数据K1条,取db2数据K2条,则K1+K2 = N
§ 此时的DB1 可以计算出OffSet为K1 ,DB2计算出Offset为K2
§ 将获取的N条数据以及相应的Offset K1/K2返回给 端上。
§
§ 第二次查询:
§ ① 端上将上一次查询对应的数据库的Offset K1/K2 传到后端
§ ② 后端根据Offset构造查询语句查询分别查询出N条语句
§ SELECT * FROM db1_table1 where $col > 0 order by $col LIMITT $K1,N
§ SELECT * FROM db2_table1 where $col > 0 order by $col LIMITT $K2,N
§ ③ 再次使用归并排序,获取TOP N数据,将获取的N条数据以及相应的Offset K1/K2返回给 端上。
§
§ 第三次查询:
依次类推.......
§ 方案二:可以将经常使用到 groupby,orderby 字段存储到一个单一库表(可以是 REDIS、ES、MYSQL)中,业务代码中先到单一表中根据查询条件查询出相应数据,然后根据查询到的主键 ID,到分库分表中查询详情进行返回。2 次查询操作难点会带来接口耗时的增加,以及极端情况下的数据不一致问题。
什么是好的分库分表方案?
满足业务场景需要:根据业务场景的不同选择不同分库分表方案:比如按照时间划分、按照用户 ID 划分、按照业务能力划分等
方案可持续性:
何为可持续性?其实就是:业务数据量级和流量量级未来进一步达到新的量级的时候,我们的分库分表方案可以持续灵活扩容处理。 最小化数据迁移:扩容时一般涉及到历史数据迁移,其扩容后需要迁移的数据量越小其可持续性越强,理想的迁移前后的状态是(同库同表>同表不同库>同库不同表>不同库不同表)
数据偏斜:数据在库表中分配的均衡性,尽可能保证数据流量在各个库表中保持等量分配,避免热点数据对于单库造成压力。
最大数据偏斜率:(数据量最大样本 - 数据量最小样本)/ 数据量最小样本。一般来说,如果我们的最大数据偏斜率在 5%以内是可以接受的。
如何分库分表
垂直拆分:
垂直拆表
即大表拆小表,将一张表中数据不同”字段“分拆到多张表中,比如商品库将商品基本信息、商品库存、卖家信息等分拆到不同库表中。 考虑因素有将不常用的,数据较大,长度较长(比如 text 类型字段)的拆分到“扩展表“,表和表之间通过”主键外键“进行关联。 好处:降低表数据规模,提升查询效率,也避免查询时数据量太大造成的“跨页”问题。 垂直拆库
垂直拆库则在垂直拆表的基础上,将一个系统中的不同业务场景进行拆分,比如订单表、用户表、商品表。 好处:降低单数据库服务的压力(物理存储、内存、IO 等)、降低单机故障的影响面
水平拆分:
操作:将总体数据按照某种维度(时间、用户)等分拆到多个库中或者表中,典型特征不同的库和表结构完全一下,如订单按照(日期、用户 ID、区域)分库分表。
水平拆表
将数据按照某种维度拆分为多张表,但是由于多张表还是从属于一个库,其降低锁粒度,一定程度提升查询性能,但是仍然会有 IO 性能瓶颈。 水平拆库
将数据按照某种维度分拆到多个库中,降低单机单库的压力,提升读写性能。
常见水平拆分手段
range 分库分表
顾名思义,该方案根据数据范围划分数据的存放位置。
思路一:时间范围分库分表
举个最简单例子,我们可以把订单表按照年份为单位,每年的数据存放在单独的库(或者表)中。
时下非常流行的分布式数据库:TiDB 数据库,针对 TiKV 中数据的打散,也是基于 Range 的方式进行,将不同范围内的[StartKey,EndKey)分配到不同的 Region 上。
缺点:
需要提前建库或表。 数据热点问题:当前时间的数据会集中落在某个库表。 分页查询问题:涉及到库表中间分界线查询较复杂。
例子:交易系统流水表则是按照天级别分表。
hash 分库分表
hash 分表是使用最普遍的使用方式,其根据“主键”进行 hash 计算数据存储的库表索引。原理可能大家都懂,但有时拍脑袋决定的分库分表方案可能会导致严重问题。
思路一:独立 hash
对于分库分表,最常规的一种思路是通过主键计算 hash 值,然后 hash 值分别对库数和表数进行取余操作获取到库索引和表索引。比如:电商订单表,按照用户 ID 分配到 10 库 100 表中。
const (
// DbCnt 库数量
DbCnt = 10
// TableCnt 表数量
TableCnt = 100
)// GetTableIdx 根据用户 ID 获取分库分表索引
func GetTableIdx(userID int64) (int64, int64) {
hash := hashCode(userID)
return hash % DbCnt, hash % TableCnt
}
上述是伪代码实现,大家可以先思考一下上述代码可能会产生什么问题?
比如 1000? 1010?,1020 库表索引是多少?
思考一下........
思考一下........
思考一下........
思考一下........
思考一下........
思考一下........
答:数据偏斜问题。
非互质关系导致的数据偏斜问题证明:
假设分库数分表数最大公约数为a,则分库数表示为 m*a , 分表数为 n*a (m,n为正整数)某条数据的hash规则计算的值为H,
若某条数据在库D中,则H mod (m*a) == D 等价与 H=M*m*a+D (M为整数)
则表序号为 T = H % (n*a) = (M*m*a+D)%(n*a)
如果D==0 则T= [(M*m)%n]*a
思路二:统一 hash
思路一中,由于库和表的 hash 计算中存在公共因子,导致数据偏斜问题,那么换种思考方式:10 个库 100 张表,一共 1000 张表,那么从 0 到 999 排序,根据 hash 值对 1000 取余,得到[0,999]的索引,似乎就可以解决数据偏斜问题:
// GetTableIdx 根据用户 ID 获取分库分表索引
// 例子:1123011 -> 1,1
func GetTableIdx(userID int64) (int64, int64) {
hash := hashCode(userID)
slot := DbCnt * TableCnt
return hash % slot % DbCnt, hash % slot / DbCnt
}
上面会带来的问题?
比如 1123011 号用户,扩容前是 1 库 1 表,扩容后是 0 库 11 表
扩展性问题证明。
某条数据的hash规则计算的值为H,分库数为D,分表数为T扩容前:
分片序号K1 = H % (D*T),则H = M*DT + K1 ,且K1 一定是小于(D*T)
D1 = K1 % D
T1 = K1 / D
扩容后:
如果M为偶数,即M= 2*N
K2 = H% (2DT) = (2NDT+K1)%(2DT) = K1%(2DT) ,K1 一定小于(2DT),所以K2=K1
D2 = K2%(2D) = K1 %(2D)
T2 = K2/(2D) = K1 / (2D)
如果M为奇数,即M = 2*N+1
K2 = H%(2DT) = (2NDT +DT +K1)%(2DT) = (DT+K1)%(2DT) = DT + K1
D2 = K2 %(2D) = (DT+K1) % (2D)
T2 = K2 /(2D) = (DT+K1) / (2D)
结论:扩容后库序号和表序号都变化
思路三:二次分片法
思路二中整体思路正确,只是最后计算库序号和表序号的时候,使用了库数量作为影响表序号的因子,导致扩容时表序号偏移而无法进行。事实上,我们只需要换种写法,就能得出一个比较大众化的分库分表方案。
func GetTableIdx(userId int64){
//①算Hash
hash:=hashCode(userId)
//②分片序号
slot:=hash%(DbCnt*TableCnt)
//③重新修改二次求值方案
dbIdx:=slot/TableCnt
tblIdx:=slot%TableCnt
return dbIdx,tblIdx
}
从上述代码中可以看出,其唯一不同是在计算库索引和表索引时,采用 TableCnt 作为基数(注:扩容操作时,一般采用库个数 2 倍扩容),这样在扩容时,表个数不变,则表索引不会变。
可以做简要的证明:
某条数据的hash规则计算的值为H,分库数为D,分表数为T扩容前:
分片序号K1 = H % (D*T),则H = M*DT + K1 ,且K1 一定是小于(D*T)
D1 = K1 / T
T1 = K1 % T
扩容后:
如果M为偶数,即M= 2*N
K2 = H% (2DT) = (2NDT+K1)%(2DT) = K1%(2DT) ,K1 一定小于(2DT),所以K2=K1
D2 = K2/T = K1 /T = D1
T2 = K2%T = K1 % T = T1
如果M为奇数,即M = 2*N+1
K2 = H%(2DT) = (2NDT +DT +K1)%(2DT) = (DT+K1)%(2DT) = DT + K1
D2 = K2 /T = (DT+K1) / T = D + K1/T = D + D1
T2 = K2 %T = (DT+K1) % T = K1 %T = T1
结论:
M为偶数时,扩容前后库序号和表序号都不变
M为奇数时,扩容前后表序号不变,库序号会变化。
思路四:基因法
由思路二启发,我们发现案例一不合理的主要原因,就是因为库序号和表序号的计算逻辑中,有公约数这个因子在影响库表的独立性。那么我们是否可以换一种思路呢?我们使用相对独立的 Hash 值来计算库序号和表序号呢?
func GetTableIdx(userID int64)(int64,int64){
hash := hashCode(userID)
return atoi(hash[0:4]) % DbCnt,atoi(hash[4:])%TableCnt
}
这也是一种常用的方案,我们称为基因法,即使用原分片键中的某些基因(例如前四位)作为库的计算因子,而使用另外一些基因作为表的计算因子。
在使用基因法时,要主要计算 hash 值的片段保持充分的随机性,避免造成严重数据偏斜问题。
思路五:关系表冗余
按照索引的思想,可以通过分片的键和库表索引建立一张索引表,我们把这张索引表叫做“路由关系表”。每次查询操作,先去路由表中查询到数据所在的库表索引,然后再到库表中查询详细数据。同时,对于写入操作可以采用随机选择或者顺序选择一个库表进入写入。
那么由于路由关系表的存在,我们在数据扩容时,无需迁移历史数据。同时,我们可以为每个库表指定一个权限,通过权重的比例调整来调整每个库表的写入数据量。从而实现库表数据偏斜率调整。
此种方案的缺点是每次查询操作,需要先读取一次路由关系表,所以请求耗时可能会有一定增加。本身由于写索引表和写库表操作是不同库表写操作,需要引入分布式事务保证数据一致性,极端情况可能带来数据的不一致。
且索引表本身没有分库分表,自身可能会存在性能瓶颈,可以通过存储在 redis 进行优化处理。
思路六:分段索引关系表
思路五中,需要将全量数据存在到路由关系表中建立索引,再结合 range 分库分表方案思想,其实有些场景下完全没有必要全部数据建立索引,可以按照号段式建立区间索引,我们可以将分片键的区间对应库的关系通过关系表记录下来,每次查询操作,先去路由表中查询到数据所在的库表索引,然后再到库表中查询详细数据。
思路七:一致性 Hash 法
一致性 Hash 算法也是一种比较流行的集群数据分区算法,比如 RedisCluster 即是通过一致性 Hash 算法,使用 16384 个虚拟槽节点进行每个分片数据的管理。关于一致性 Hash 的具体原理这边不再重复描述,读者可以自行翻阅资料。
其思想和思路五有异曲同工之妙。
总结
本文从 5W1H 角度介绍了分库分表手段,其在解决如 IO 瓶颈、读写性能、物理存储瓶颈、内存瓶颈、单机故障影响面等问题的同时,也带来如事务性、主键冲突、跨库 join、跨库聚合查询等问题。anyway,在综合业务场景考虑,正如缓存的使用一样,非必须使用分库分表,则不应过度设计采用分库分表方案。如数据库确实成为性能瓶颈时,在设计分库分表方案时也应充分考虑方案的扩展性。或者说可以考虑采用成熟热门的分布式数据库解决方案,如 TiDB。
左下角阅读原文也可直达
如有侵权请联系:admin#unsafe.sh