-
-
[原创]自动化提取恶意文档中的shellcode
-
2022-12-16 20:15 3736
-
该shellcode提取器的应用对象是Maldoc,通过将市面上存在的相关分析工具进行组合,形成工具链,达到自动化定位及提取shellcode的目的。
- 语言:python + javascript
- 环境:REMnux docker + win7 (注:不使用RTF中的动态方法,可以摒弃win7,但面对一下经混淆的RTF文件可能无法正确提取shellcode)
- The docker image(g0mx/remnux-shellcode_extractor) created by myself for extracting shellcode from maldoc based on REMnux
- 项目地址:https://github.com/g0mxxm/shellcode_extractor_for_maldoc
实现并不复杂,本人认为该工具的实现思路是它的闪光点。实现思路,即将分析人员手动定位并提取shellcode的步骤自动化。
整体流程主要由解包、定位、提取这三个环节组成,后续的优化并不会改变整体流程。
- 解包:针对RTF文件中OLE对象的定位和提取,本工具采用了动态和静态两种方式来解决此问题,二者也各有利弊。静态方式主要轮子取自Didier Stevens工具集,动态方式是本人基于frida hook框架编写了几个脚本来实现的,后文会进行详细阐述;针对OOXML文件的解包,主要轮子取自Didier Stevens工具集;针对OLE对象的解包,主要轮子取自Didier Stevens工具集。此外,该阶段会对文档类型及是否加密进行判断,主要轮子取自于oletools工具集,若加密则进行解密,随后进入下一环节;若未加密,则直接进入下一阶段。
- 定位:主要轮子取自Didier Stevens工具集,其主要思想为遍历及暴力破解,首先对OLE对象进行解包,随后对其每个子stream进行暴力破解,特征匹配,以达到定位shellcode的目的。
- 提取:主要轮子取自于Didier Stevens工具集,很简单的一步,定位后尝试对目标位置进行解码,随后dump即可得到最终的shellcode。
解包
判断文件类型
通过oleid检查maldoc的基本信息,并根据其中Container format字段的键值判断该文件的具体类型,根据类型进入不同的分支,但最终都会走入OLE对象处理分支。
检查该文档是否被加密
通过oleid检查maldoc的基本信息,根据其中的Encrypted字段的键值判断该文件是否被加密。
若该文件被加密,可以通过msoffcrypto-crack对密码进行爆破,并保存完成解密的文件。
文件类型
RTF文件
本人对RTF文件的处理主要分为静态和动态两种形式,其中静态的优点在于可以不依赖于Windows环境,直接基于REMnux来完成OLE对象及其中shellcode的提取操作,但面对一些经过特殊混淆的RTF文件时,可能不能有效识别其中的OLE对象,因而本人基于frida实现了一个动态定位并获取OLE对象的工具,该工具的灵感来源于Denis O'Brien大佬的一篇文章(Reference中最后一项)。
静态方法
静态方法主要利用Didier Stevens的rtfdump工具中最新更新的“-F”选项,其在blog中说到,该选项是由“-H”和“-S”演变过来的,简单根据源码说一下本人对这两个选项功能的理解。
“-H”和“-S”主要由HexDecode这个函数来实现,其功能是对字节流进行处理,并将其转换为十六进制的形式,其中包含判读奇偶和补零操作(“-S”)。虽然一个正常的hex流其肯定应该是偶数位的,这样才有正确解析的可能,但由于一些RTF解析器会对hex流为奇数位(有些maldoc构造者为了逃避检测会在hex流最后的位置额外添加一个十六进制字符)的问题进行处理,以完成解析,因此该函数中的判断奇偶和补零操作,应该就是为了正确解析进行了这种混淆操作的字节流;同样其也可以对抗在hex流中添加了大量空白字符这种混淆手法。本人对RTF的混淆方式了解还不是很全面,难免会有纰漏,欢迎指正和补充。
具体源码如下:
通过“-F”选项找到所有OLE对象后,将所有OLE对象的标识保存下来,为后续提取做准备。
将所有找到的OLE对象,根据标识定位并保存下来,传给OLE对象处理模块,进行后续处理。
动态方法
通过运行与hook相结合的方式,可以让我们不去考虑去混淆的问题,直接找到OLE对象并将其进行保存就可以,而Denis O'Brien大佬的Silver Bullet方法给我了用运行和hook解决该问题的灵感和方法论。
本人所实现的hook是基于frida的,整体实现十分简洁,准备部分是由python实现的,hook部分是用js实现的,python部分没啥可说的,很容易理解,可以看一下frida官方给出的例子,以及DarunGrim的Using Frida For Windows Reverse Engineering这篇文章,且这篇文章写的非常精彩,它为我们提供了基于frida hook对office宏指令进行有效处理的方法,值得学习。那我们来看一下hook的实现吧。
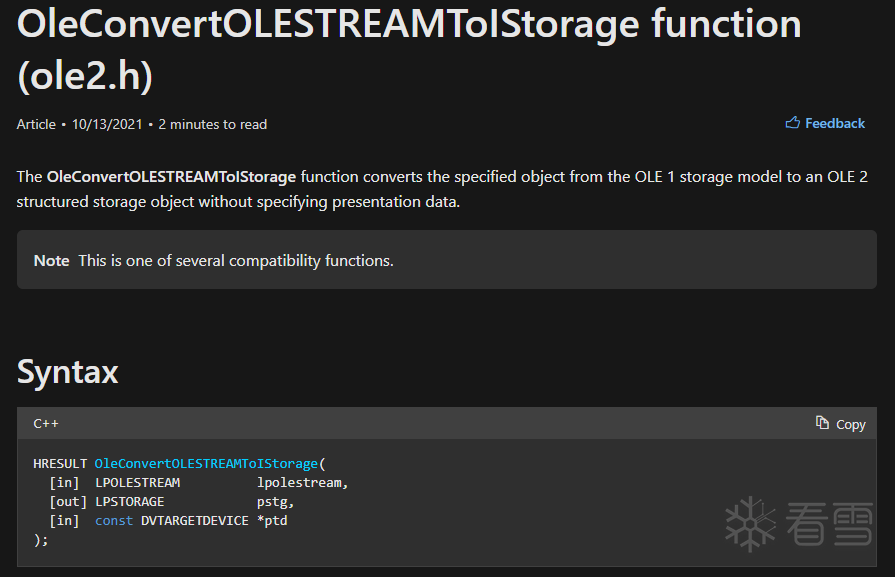
要想获取到OLE对象,OleConvertOLESTREAMToIStorage是关键API,我们来看一下Microsoft给出的详细解释,该API功能是将OLE对对象的格式从OLE1转换到OLE2,其中一定包含了我们想要的OLE对象信息。
因而我们可以hook该API,并通过该API的第一个参数lpolestream(其是指向包含OLE1格式的OLE对象的指针)找到OLE对象,再根据存储结构找到OLE对象的具体位置及OLE对象的整体长度即可,具体操作请看Silver Bullet方法,大佬写的十分清晰且详细,复现非常简单,本文也不再进行过多赘述,hook的具体实现请看本人写的js代码,主要就是进行了获取并保存OLE地址和OLE长度的工作。
js代码如下:
通过复现Silver Bullet,我也发现了一个小问题,即通过API参数获取到的OLE对象地址(0x0A6A5B28),并未直接指向OLE对象的标识头(红框中十六进制字节),若直接根据地址和长度对该块内存进行dump,所获取的文件并不能直接传入本人所写的shellcode提取器,这是由于文件头的问题,导致oledump无法对该OLE对象进行正确解析,后续的操作也就无从谈起。
通过查阅frida文档,我发现可以用frida提供的内存数据匹配来实现精确拷贝,将OLE对象头作为匹配所用的模式串即可解决该问题。
js代码如下:
OOXML文件
OOXML文件其实是个压缩包,若其中存在OLE文件也仅能存在于activeX1.bin文件中,因而我们可以通过由Didier Stevens编写的zipdump来判断目标OOXML文件中是否包含.bin文件,若包含.bin文件则直接进入处理OLE对象流程中。
OLE对象
获取stream
先通过oleid获取所有maldoc的所用stream标签,该处实现还有优化的空间,可以将一维list改为二维list来存储stream标签,这样当maldoc中存在多级stream的情况时,结构更为清晰,不优化的话也可以,结果上不会存在太多差异。
检查stream
再根据获取到的stream标签,对maldoc中的每一个子stream都进行检查,通过xorsearch输出中的Socre值来判断对应子stream中是否包含shellcode,目前只去得分最高者进行后续操作。该处可以优化为:有得分即保留,都进入到下一阶段。
定位
这次我们将目光转向xorsearch输出结果的偏移值上,将出现的所有偏移值进行保存。
再利用偏移值和scdbg进行测试,确定shellcode的具体开始位置。
提取
若scdbg可以判断出shellcode的具体位置,那我们通过cut-bytes对其进行精确切割,并将结果保存成文件。
若scdbg不能确定shellcode的具体位置,则将整个子stream保存为文件,作为最终的shellcode。
动态获取RTF中OLE文件
提供word路径,样本文件路径,以及hook脚本文件即可。
shellcode提取器
提供maldoc文件或OLE文件即可,以刚刚动态获取到的OLE文件为例。
对得到的shellcode(final_shellcode_file)进行一下简单的验证。
静态:可以看到其中有LoadLibraryW和GetProcAddress,看到这俩函数可以确定,其在获取目标函数的地址,方便后续使用;又看到ExpandEnvironmentStringsW,可以确定其是将其中的“%APPDATA%”进行扩展;随后再调用URLDownloadToFileW来下载后续文件,写入指定路径中。
动态:选择scdbg进行模拟执行来获取更加准确的信息,通过shellcodedbg执行后的结果,可以更加清晰地看到,其调用了哪些函数,参数是什么,整体流程与上文通过静态分析得到的结果基本一致,但模拟执行向我们展示了准确的URL,以及从远端下载了什么。
可以看到通过两者结合我们快速且精确的得到了maldoc中的shellcode,并通过静态或模拟执行来获取到其主要行为,快速结束maldoc的前戏,将主要精力放在分析后续的主体行为上,提高效率,愉悦心情,哈哈。
该工具目前只是一个雏形,逻辑较为简单,且可能存在不严谨之处,亦存在一定问题和优化空间,主要是提供一种从特例中提取特征,从而向普适化转变的思路,在此也十分感谢这些原始工具的创作者,在提供基础功能的同时,也给我了我很多向前的思路,希望可以像这些大佬一样,持续、高效的输出成果,做一点想做的事情出来。
一晃也正式工作快半年了,这个小工具也算是给我这段生活和2022交一份答卷了,想做的事情很多,也做了很多尝试,但因能力和精力原因有许多问题无法解决,导致了卡在半途难以向前,幸运的是有了做这个小工具的契机,也十分幸运的解决了大部分问题,并最终完成了它。也希望未来有机会和能力把那些没研究明白的东西整明白,再产出一些成果。
最后,青春不过几届世界杯,从08奥运会上的初识,到如今的卡塔尔,真是岁月匆匆啊,祝愿我梅老板今年可以梦圆卡塔尔。
- 运行环境基于 Remnux docker
- Didier Stevens 大佬的工具集及博客
- oletools 工具集
- frida-python github
- frida 官方文档
- Denis O'Brien 大佬的 Silver Bullet
- DarunGrim 的 Using Frida For Windows Reverse Engineering
[2022冬季班]《安卓高级研修班(网课)》月薪两万班招生中~
最后于 5天前 被g0mx编辑 ,原因: 新增基于Remnux docker构建的portable运行环境
如有侵权请联系:admin#unsafe.sh