区块链技术起源于比特币开源项目,比特币这个独具神秘色彩的项目自2009年起已经稳定运行十余年,在没有任何机构和个人进行专职运维的情况下没有出现过一次服务暂停,现今已经创造出千亿市值。区块链技术正是比特币一切传奇和辉煌背后的底层核心支撑技术。
区块链技术始于比特币,但不止于比特币,它博取经济学、密码学、博弈论、分布式系统等众多领域之长,背后带来的高可信、高可靠、高可用特性蕴藏着巨大的社会及商业价值,被认为是第四次工业革命浪潮中最重要且具有代表性的技术之一。
区块链概念
区块链概念起源于“神秘人物”中本聪于2008年发布的比特币白皮书,但10余年过去了,区块链仍没有一个标准的定义,然而这并不妨碍大家对区块链技术心驰神往,其对于技术的创新及商业社会的变革吸引着越来越多的人加入区块链的浪潮。
(1)区块链技术概述
1、区块链与信任
货币和文字都是人类文明历史长河中最具特色的伟大发明,二者之间存在着千丝万缕的关系,最早诞生的楔形文字就是当时苏美尔人用来记录商业交易信息的手段(当时的流通货币为大麦,称为“大麦货币”)。
文字承载信息,而货币承载信任,信任是一切商业行为的基础。
货币是有史以来最普遍也最有效的互信系统,其形态从实物货币、金属货币等实体货币逐渐演变为电子货币、数字货币等虚拟货币,从最开始作为既有实际价值又有信任价值的双向承载者演变为纯粹的信任承载者,货币体系的内核,就体现在信任上。
在经济学领域,信任被定义为一个主体评估另一个主体将采取某种特殊行为的主观概率水平。简单来说,对方在具有投机取巧的风险机会之下的策略就是信任的展现,而如何通过这种行为策略“计算”信任一直是各类学者重点研究的问题,鉴于人是有限理性的社会动物这一客观事实,目前还未构建出精确计算信任的环境和系统。
区块链技术的出现给信任的计算带来了新的方向,它的精妙之处在于不是计算人或参与主体的信任,而是计算信任过程中行为的可信度,即如果一个行为的违约性越低,则其可信度越高,反之亦然。这样无须在第三方进行背书的条件下就可以用风险成本和收益成本的设计模型重新定义信任,区块链开创了一种在不可信的竞争环境中低成本建立信任的新型计算范式和协作模式。
区块链作为一种新型可信协作模式,有望对新型生产关系的促进和经济社会的发展产生深远影响,国家对该项技术也极为重视。2016年,国务院印发的《“十三五”国家信息化规划》将区块链纳入新技术范畴并当作前沿布局。2019年10月,***在主持中共中央政治局第十八次集体学习时强调,“区块链技术的集成应用在新的技术革新和产业变革中起着重要作用。我们要把区块链作为核心技术自主创新的重要突破口,明确主攻方向,加大投入力度,着力攻克一批关键核心技术,加快推动区块链技术和产业创新发展。”2020年4月,国家发改委召开例行在线新闻发布会,明确将“区块链”纳入新型基础设施的信息基础设施中。区块链蕴含巨大的变革潜力,有望发展为数字经济信息基础设施的重要组件。
2、区块链定义
区块链目前尚未形成行业公认的定义,但对其定义解读的角度多种多样。
- 中本聪论文定义:中本聪的论文Bitcoin:A Peer-to-Peer Electronic Cash System指出,区块链是用于记录比特币交易账目历史的数据结构,每个区块的基本组成都由上个区块的散列值、若干条交易及一个调节数等元素构成,矿工通过工作量证明(PoW)来维持持续增长、不可篡改的数据信息,这是对于区块链最早的描述。论文中虽然介绍了区块链技术的要点和原理,但并未直接出现“Blockchain”(区块链)一词,给大家留下了丰富的想象和讨论空间。最终区块链这一命名由相关机构组织公开投票选出。
- 维基百科定义:区块链是凭借密码学算法串接起来并对内容进行保护的串联文字记录(区块)。每个区块都包含上个区块的加密散列、时间戳及交易数据(通常用默克尔树(Merkle Tree)计算的散列值表示),这样的设计使得区块中的内容具有不可篡改的特性。用区块链技术串接的分布式账本能让双方有效记录交易,且可永久查验此交易。
- 机构及专家定义:区块链是一种利用块链式数据结构验证与存储数据,利用分布式节点共识算法生成和更新数据,利用密码学手段保证数据传输和访问的安全,利用由自动化脚本代码组成的智能合约编程和操作数据的全新分布式基础架构与计算范式;区块链是大家共同参与记账的分布式账本,其通过单节点发起,全网广播、交叉审核、共同记账;区块链是建立信任的机器等。
3、区块链结构
区块链技术体系剥离了中心化的权威机构,通过分布式共识机制和加密算法来解决分布式系统中的信任和安全问题,区块链记录不可篡改,无须第三方机构进行信任担保,适合多个机构在区块链网络中相互监督并实时对账。区块链通过智能合约提高经济活动与契约的自动化程度,从而在多方协作的业务场景下提高业务效率、降低业务成本。其数据组织如下。
- 交易(Transaction):类比传统金融的交易定义。区块链中的交易是使底层数据状态发生变化的操作请求,每笔交易都对应唯一的交易哈希值。在使用过程中,多笔交易在一段时间内会被打包,形成一个区块,供多方查验。
- 区块(Block):一段时间内交易和底层数据状态结果打包的集合。系统在一次共识之后通常会生成一个区块,生成区块的时间间隔可以动态改变。
- 链(Chain):区块按照时间顺序向后追加形成一个串联的链,记录整个账本的状态变化,每个区块都会记录上个区块的哈希值,区块交易是否合法可以通过计算哈希值快速校验。
- 账本(Ledger):交易是由分布式系统中的多个节点共同记录的。每个节点都记录完整的交易信息,因此它们都可以监督交易的合法性并验证交易的有效性。不同于传统的中心化技术方案,区块链中任何一个节点都没有单独记账的权限,避免了因单一记账人或节点被控制而造假的可能。另外,由于全网节点都参与记账,因此除非绝大部分节点(数量由系统容错性决定)被破坏,否则交易记录不会丢失,保证了数据的安全。
(2)区块链技术来源
1、技术来源
上文提到的“中本聪”是一个具有神秘色彩的人物,其真实身份至今无从得知,2008年,他(她)在密码学邮件组中发表了论文Bitcoin:A Peer-to-Peer Electronic CashSystem(《比特币:一种点对点的电子现金系统》),提出了一种全新的、完全点对点的、可抛弃可信第三方的电子现金系统;2009年,比特币正式上线并发布创世区块,发行比特币2100万个,将在2040年全部发行完毕。比特币的诞生并不是一蹴而就的,任何一个现象级的技术出现,必然有一个深远而漫长的前序。
区块链技术起源于比特币,集密码学算法、分布式共识机制、点对点网络、时间戳等技术之大成,是一种基于零信任基础、去中心化的分布式系统。早在比特币以前,上述技术就有了很长的发展历史。在20世纪80、90年代,有一个想通过密码学算法改变世界的神秘联盟“密码朋克”(Cypherpunk),该联盟成员发现当时社会个人隐私和权限的侵蚀相当严重,在数字时代,保护隐私对于维持社会的开放性是至关重要的,于是这些热衷于加密算法的联盟成员每天都通过邮件进行技术交流,实现自己改变世界的想法,他们是数字货币最早的传播者。在其成员之中,密码破译专家大卫·乔姆在1981年的研究奠定了匿名通信的基础,并创建了数字化货币Ecash(Electronic Cash,电子现金)系统,作为以数据形式流通的货币;英国密码学家亚当·贝克在1997年发明了哈希现金(HashCash),采取PoW共识算法,通过一些额外的工作成本解决互联网上散布垃圾信息的问题;同年,哈伯和斯托尼塔提出了用时间戳保证数字文件安全的协议,后续发展为比特币协议的基础;戴维在1998年发明了数字货币系统B-Money,强调点对点交易及不可篡改的交易记录,也为比特币协议奠定了基础。
2、比特币
比特币之所以会引起广泛的热捧与讨论,是因为它是首个完全通过技术方式实现、无须中心化机构管理运维、安全可靠的数字货币系统。
传统货币,如纸质货币、电子货币,大家都比较熟悉,但是和比特币对比,二者具有很大的差别,如下表所示。

可以看到,同样是资产交易的流转,比特币没有依靠第三方机构进行担保管控,而寻求分布式共识机制、密码学算法自给自足、组织管理。这样相对于传统中心化系统的好处在于以下两点。
- 避免了中心化系统被攻击、交易成本高的问题:中心化顾名思义只有一个中心化系统进行统一管理,如果这个中心化系统被攻击或无法连接,那么整个系统将会瘫痪,造成不可逆的损失;除此之外,第三方机构交易会存在额外的手续费,这是第三方机构提供交易服务而产生的必然成本,这部分成本需要用户自己承担;用户还需要防范诈骗、盗刷、伪造等资产骗局,承担安全风险。
- 适用于“无强势中心”的场景:最典型的就是跨境贸易场景,由于发生贸易的两国的外汇储备不足,汇率变化导致两国意见不统一,每个国家都会更倾向于相信本国的银行系统,那么由谁来定夺将会是一个棘手的问题。
基于上述愿景,比特币设计了一套合理的货币发行机制,建立了一套可靠的交易记录系统,可以跨境交易,全球任何地方的用户都可以访问,这相对于每个国家独立、自成体系的银行系统具有更高的普适性,可以准确、可追溯地记录每笔在比特币系统中发生的交易,并且保证交易记录无法被恶意篡改。
基于上述目标,比特币通过分布式共识机制、密码学算法、块链式数据结构等技术完成了系统的构建,具有点对点传播、匿名性、交易可追溯、记录不可篡改等特性。
从技术层面上讲,区块链本质上是一个基于点对点网络(peer-to-peer)的分布式账本,数据由一串串相连的区块数据构成,相邻区块数据之间相互链接,其链接指针是采用密码学和哈希算法对区块头进行处理所产生的区块头哈希值。每个区块数据中都记录了一组采用哈希算法组成的树状交易状态信息,保证了每个区块内的交易数据都不可篡改,区块链里链接的区块也不可篡改。比特币的具体交易记录会保存在区块数据中,比特币系统大约每10分钟产生一个区块,如下图1-1所示,每个区块一般都包含区块头(Header)和区块体(Body)两部分,区块头封装当前的父区块哈希(Prev-Block)、版本号(Version)、默克尔根(Merkle Root)、时间戳(Timestamp)、难度(Target)、随机数(Nonce)信息。

区块头字段说明如表1-2所示。

比特币中采用PoW共识算法选择谁来记录交易并获得奖励(这个过程通常称为矿工“挖矿”),上述过程中的区块就是在挖矿过程中产生和确认的。挖矿是一种穷举随机数的算法,把上个区块的区块哈希加上10分钟内的全部交易打包,再加上一个随机数,计算出一个哈希值,规则需要随机数生成的哈希值满足一定条件(如00000开头),就可以获得这个区块的交易记账权。新产生的区块需要快速地广播出去,以便其他节点对其进行验证,防止造假。当记账成功时,获得区块奖励,也就是挖到了比特币。
(3)区块链技术特点
1、去中介化
去中介化是区块链技术最突出的技术特性,不同于传统应用的中心化数据管理,区块链技术不依赖额外的第三方机构或硬件设施,抛开基于中心化机构的信任评估、授权与担保,通过“机器信任”,即技术手段的方式,实现各个节点信息的自我验证、传递和管理。去中介化主要体现在网络架构和处理执行层面。
- 网络架构层面,不同于传统的星形拓扑网络,网络中存在一个中心网络节点,区块链拓扑网络为P2P(Peer-to-Peer,点对点)网络,其特点是任何一个节点的失效都不会影响其他节点之间的连接通信,极大地提高了网络容错性。
- 处理执行层面,区块链网络中不存在中心决策节点,即“中央节点”,所有节点承担的功能都是对等的,每个节点都可以独立处理、执行、决策、存储,最终通过分布式共识机制达成整个系统的统一。
2、不可篡改
记录在区块链上的数据会永远存在区块链上,一旦上链不可删除且极难篡改,这增强了链上信息的可信、可靠性。不可篡改主要体现在两个层面。
- 一是架构层面,区块链采取分布式全冗余存储,相当于区块链中的每方(每个节点)都有全量的数据,如果一方被篡改,那么所有方在共识过程中就会发现一方数据不一致从而进行错误处理,除非本次篡改得到了多方的同意。例如,比特币掌握51%及以上的算力,联盟链掌握1/3以上的投票权(该系统采用拜占庭容错算法)。这种掌握多数话语权的方式在分布式系统中极难实现,成本极高。
- 二是数据存储结构层面,区块链采用区块结构链式存储,每个区块中都保存着独一无二的区块哈希,并且该区块哈希会存储到下个区块中,下个区块哈希会存储到下下个区块中,从而形成链,当区块中的数据被篡改时,区块哈希会随之进行变化,造成本区块的区块哈希和下个区块的区块哈希记录的值不一致,除非后续区块中的区块哈希全部更改,这需要掌握区块链网络中的大多数算力或投票权,显然这很难实现。
综上所述,区块链通过分布式全冗余架构及密码学算法保证区块链上数据的不可篡改。
3、可追溯
区块链通过在块链式结构上标记时间戳的方式,达到可验证、可追溯的效果。交易的每次变更都会按照时间顺序记录在区块链上,并且将交易记录前后关联,最终形成一个完整的链,用户可以检索从源头到最终的所有交易信息,并且整个链的信息不可篡改和伪造,这样的特性可以很好地用于法律公证、知识产权等时间敏感的领域。
- 已上链的信息不可篡改
- 所有修改都可追溯
4、可信任
除了上述去中介化、不可篡改和可追溯特性,区块链还通过密码学算法对链上敏感的交易数据进行加密,用户需要具有相关权限才能访问,并且无须第三方机构,能够很好地解决不信任的问题。
区块链发展
2009年至今,区块链技术经历了10余年的发展,从在“极客圈”小部分人的爱好,到社会上万千大众对数字货币的狂热,再到回归技术本质的冷静。整体从乱象丛生到回归秩序,区块链的发展可谓是跌宕起伏。区块链的诞生并不是一蹴而就的,技术发展和产业应用是两个互相促进正向反馈的因子,在内部因子和外部因子的双重驱动下,区块链技术迸发出了持续的生机和活力,奋勇发展。下面将介绍区块链的发展历程,大致可以分为3个阶段:区块链1.0、2.0、3.0。
(1)区块链1.0——“可编程货币”
在区块链1.0阶段(2008—2013年),区块链技术的核心在于数字货币领域,以比特币为代表的加密数字货币主要解决了行业内长期存在的“双花问题”和“拜占庭将军问题[”。
- 双花问题主要研究在没有中心化或第三方机构的存在下,如何确保一笔交易的数字货币不被多次消费,不同于纸质货币,数字货币具有无限复制性
- 拜占庭将军问题主要研究在存在欺骗和错误的通信环境下,多个分布式参与方如何就同一决策达成一致
区块链通过点对点网络、密码学算法、分布式共识机制、区块结构链式存储等底层技术很好地解决了上述问题。后来出现的数字货币,如莱特币、狗狗币等的底层技术都是基于比特币区块链进行优化实现的,其架构一般可分为三层。
- 区块链层:区块链层是整体架构的核心,包括共识过程、消息传递、数据存储等核心功能。
- 协议层:协议层提供一些软件服务、规则制定等。
- 货币层:货币层主要作为价值表示,在用户之间传递价值,相当于一种货币单位。
可能有人会想,在有了银行、支付宝、Visa、PayPal等便捷又好用的服务设施后,为何还需要加密数字货币?在区块链1.0阶段,基于区块链技术构建了很多去中心化的数字支付系统,一笔交易可以直接由两个单独的个体发起和完成,很好地解决了货币、汇兑、支付手段等方面的信任、流通、风险问题,给传统的金融体系带来了一定的冲击。
但是,区块链的思想始于货币但不止于货币,其有望用一种完全分布式、全球化的方式在个体之间分配和交易各种资源和价值信息,成为一个全球性的可编程开放式网络。
(2)区块链2.0——“可编程金融”
承载着成为全球性的可编程开放式网络的愿景,伴随着图灵完备的智能合约系统的出现,区块链走进了2.0阶段。区块链1.0阶段的加密数字货币,在区块链网络中交易处理脚本语言只能完成货币资产交换的简单操作,但现实社会中不仅有货币资产的交易,还有股票、债券、产权、合同等各式各样、有形无形的资产需要进行转移和交换等复杂逻辑操作,简单的脚本语言无法发挥出区块链技术的潜在能量。所以业界逐渐将关注点转移到运行在区块链上的模块化、可重用、完备的自动执行脚本语言:智能合约。
从此,区块链的应用范围从数字货币领域延伸到金融交易、证券清算和结算、身份认证等商业领域,涌现出很多新的应用场景,如金融交易、智能资产、档案登记、司法认证,DApp(去中心化应用)、DAC(去中心化自治企业)等。
以太坊是区块链2.0阶段的代表性平台,其主要提供一个图灵完备的智能合约系统,通过编写以太坊独立研发的Solidity智能合约,开发者可以编程开发任何DApp,如投票、域名、金融交易、众筹、知识产权、智能财产等。根据以太坊白皮书所述,以太坊平台应用有三种类型。
- 金融应用:为用户提供更强大的资产管理和参与智能合约的方法。包括子货币、金融衍生品、对冲合约、遗嘱等涉及金融交易和价值传递的应用,甚至一些种类全面的雇佣合约。
- 半金融应用:既涉及金钱方面也涉及非金钱方面。例如,为解决计算问题而设的自我强制悬赏。
- 非金融应用:如在线投票、DAO(去中心化自治组织)等不涉及金钱方面的应用。
在区块链2.0阶段,以智能合约为主导,逐渐形成区块链强大的生态系统:各式各样的协议和与钱包相关的项目(瑞波币、SoinSpark)、开发平台和API(blockchain.info)、基于区块链的存储通信与计算(Storj、IPFS)、DApp、DAO、DAC、DAS(去中心化自治社会)。越来越多的金融机构、初创公司和研究团体加入区块链技术的探索行列,推动区块链技术的迅猛发展。
(3)区块链3.0——“可编程社会”
随着区块链技术的不断发展,其不仅可以重塑货币、支付、金融及经济形态等方面,更广泛地看,还可以超越货币和经济,走向政务、科学、社交、文化、工业、艺术等更广大的舞台,这就是区块链3.0阶段。
- 区块链技术从根本上成为低成本、低摩擦、高信任、高效率的新范式,过去大数据应用的核心瓶颈如“数据隐私”“数据孤岛”“数据确权”等,都可以通过区块链加密技术和智能合约技术解决
- 技术信任机制保障资源和价值可以在更大范围内有序流动,实现全球资源和资产的优化配置、
- 政府与市场、政府与社会的关系在新的信息基础设施平台上得以重构
“数字治理”成为国家治理现代化的底层支撑。在物联网、医疗、供应链管理、社会公益等行业不断有新的应用涌现。例如,在智能化物联网应用中,汽车可以自动订购汽油、预定检修服务或清洗服务,冰箱可以自动订购商品,甚至空调和冰箱可以谈判如何错峰用电。我们可以大胆构想,区块链技术将广泛而深刻地改变人们的生活方式,重构整个社会,成为促进社会经济发展的理想框架。
但同样要注意的是,区块链技术虽然有许多潜在的用途和发展方向,但就像互联网没有渗透到生活的所有角落一样,并不是所有的场景都需要点对点交易、公共记录、去中心化等区块链模式,如无须公开的个人信息存储。我们应该理性地看待区块链技术,根据实际的用途和类别有的放矢,才能让区块链技术更好地发展。
区块链分类
区块链技术经历了三次大的技术演进,产生了较为典型的区块链平台,如2009年的比特币、2013年的以太坊、2015年的Hyperledger Fabric和趣链区块链平台。
区块链按照开放程度可分为
- 公有链(Public Blockchain)
- 联盟链(Consortium Blockchain)
- 私有链(Private Blockchain)
三类,这是目前行业内最常见的分类方式。
按照节点准入权限可分为
- 许可链(Permissioned Blockchain)
- 非许可链(Permissionless Blockchain)
其中,联盟链和私有链属于许可链,公有链属于非许可链。其主要特点和区别如下表所示。


公有链是完全开放且去中心化的区块链系统,没有节点准入权限,任何人都可以选择参与链上的事务运作,如链上数据读写、验证和创建区块等。公有链内的网络节点地位平等,不存在中心节点或权限优势的节点,节点无须授权便可自由加入或退出,因此公有链属于非许可链。公有链的典型代表有比特币、以太坊等,它们将共识算法、加密验证与激励机制结合起来,构建节点间的信任,完成区块链数据的验证与读写。公有链的共识算法支持大规模网络和数据扩展,并对算法容错性提出较高要求,如比特币的PoW、PoS等。同时,公有链的稳定运行离不开经济激励,一般通过发行比特币、以太币等Token(代币)来吸引大量节点主动合作,共同维护链上数据的安全。
公有链的优点在于所有数据公开透明、不可篡改,并且链上账户不会与现实身份进行绑定,具有较高的匿名性;但与此同时,由于公有链的共识过程需要大量网络节点共同参与完成,因此造成了其交易吞吐量低且交易速度缓慢的问题,如比特币每秒只能处理7笔交易。基于上述特点,公有链通常适用于完全去中心化、全民监督、全网自治的应用场景,如数字加密货币。同时可以促进DApp发展,有助于推动“可信数字化”时代进步。
联盟链是多中心化的区块链系统,通常由若干实体机构形成一个组织或联盟,并按照一定的规则共同参与记账。联盟链具有严格的节点准入权限,只有经过授权的节点才能加入,其系统维护规则和数据读写权限通常由联盟成员共同协商制定。联盟链的共识过程由预先确定的节点控制,一般不采用资源浪费型的PoW共识算法,而采用分布式一致性算法,如PBFT(Practical Byzantine Fault Tolerant,实用拜占庭容错)、RAFT等。此外,与公有链相比,联盟链通过多中心化的互信达成共识,因而激励机制不是必要选项。
联盟链属于许可链的一种,在交易成本、性能效率、隐私保护、监管审计等方面具有更大的优势,适用于机构间共享数据服务的应用场景,如资产清算、数据可信存证、去中介交易等。典型的联盟链代表有Linux基金会超级账本(Hyperledger)项目、R3区块链联盟Corda项目、趣链区块链平台项目等,目前,基于这些联盟链底层平台开发的应用已经涉及金融、医疗、政务、能源、IoT等领域,并且仍在不断拓展。
私有链是完全中心化的区块链系统,仅对单独的个人、实体或私有组织开放,其数据读写权限由中心机构控制,根据实际需求赋予特定机构,或者选择性地对外开放。和联盟链一样,私有链也是许可链的一种,区别在于私有链的节点准入权限只掌握在单一机构手中。由于私有链的信任机制是由中心机构自行背书的,因而不需要激励机制,私有链在三者中拥有最优的性能表现和最低的交易成本。私有链需要依赖掌控绝对权限的中心机构,其本质和中心化的数据库系统无异,因而面临高权限节点易受攻击、信任缺失等风险,但由于其不可篡改、可追溯的特性,私有链在机构内部的数据库管理、财务审计、办公审批等方面具有较高的应用价值。
对于不同种类的区块链选择,应视具体应用场景而定,
- 侧重于可信度与开放性,对交易速度不苛求的应用场景,公有链更有发展潜力
- 对于更加注重隐私保护、权限控制,对系统性能和监管审计等有较高要求的应用场景,联盟链或私有链更加适用
区块链架构
如下图所示,整体来看,区块链体系技术架构分为基础协议、扩展协议和生态组件。
区块链是融合了分布式存储、点对点网络、分布式一致性算法、密码学算法等多领域、多学科的新型技术,这些技术构成了区块链的技术内核,因此,基础协议包括
- 数据结构与账户体系
- 网络通信
- 共识算法
- 安全体系
- 智能合约
随着区块链应用和技术的不断发展,基础的区块链架构在可扩展性、监管合规化、互操作性等方面的问题逐渐凸显,无法支撑大规模商业应用,由此区块链技术也逐渐发展和裂变,各类技术和机制不断出现,丰富区块链基础内核,这类基于区块链基础内核延伸的技术我们将其归为扩展协议,主要包含
- 针对可扩展性提出的一系列区块链扩容协议
- 针对监管合规提出的治理与审计
- 针对互操作性提出的跨链互操作
- 区块链与物联网
- 大数据等产业融合创新的区块链+
另外,为了加强全景区块链生态构建能力,相应的工具与组件也是必不可缺的,目前,相应的生态组件可以分为
- 方便区块链应用、测试、扩展的工具
- 服务及安全管理。

(1)基础协议
区块链是建立在可信存储机制、点对点网络、共识算法、安全机制、智能合约等基础技术之上的分布式系统,基础协议主要是实现区块链基础功能的组件,包括数据结构与账户体系、网络通信、共识算法、安全体系、智能合约。
1、数据结构与账户体系
根据数据类型和技术架构的不同,区块链底层的存储模型也各有所异。底层的存储涵盖区块数据结构与组织形式、账户体系及账本数据组织形式。
其中,区块数据结构往往大同小异,分为包含一系列校验哈希值的区块头及包含交易的区块体,而区块数据组织形式却各不相同,从最开始的块链式逐步发展到树、图等复杂模式。
除基础的区块数据结构与组织形式之外,账户体系也是区块链底层一种重要的数据结构,常见的有比特币的UTXO模型及以太坊的账户余额模型。
除基础的区块数据结构与组织形式、账户体系之外,能支撑复杂业务的区块链平台往往还涉及账本数据组织形式,账本数据需要通过特殊的组织形式如默克尔树,进行组织和存储,以便快速校验数据的正确性。
2、网络通信
网络通信包含P2P网络、区块链网络模型、区块链网络协议。
区块链网络是典型的P2P网络,涵盖节点验证、节点发现、数据收发等功能。
随着区块链架构的复杂化,逐渐演变出验证节点、SPV节点等节点类型,形成相应的分层区块链网络模型。
同时,针对网络节点自发现、大规模组网等需求,区块链网络相应适配了各种不同的网络协议,如Gossip、Whisper、Libp2p等。
3、共识算法
共识算法是用于保证分布式系统一致性的算法。区块链是典型的分布式系统,所有节点都独立完成数据计算和存储,需要共识算法来确保各节点的一致性。这里的一致性可以是交易顺序一致性、账本一致性、节点状态一致性等。共识算法往往由传统分布式一致性算法演变而来,如RAFT、PBFT等,也有针对区块链架构提出的典型共识算法,如PoW、PoS、DPoS等,随着区块链技术的不断发展,新型共识算法不断被提出,如Casper、Algorand、Hotstuff等。
4、安全体系
区块链系统有着很高的安全性要求,所涉及的身份认证、节点连接、通信传输、数据存储等方面都需要相应的核心安全技术;同时对隐私性有一定的要求,可以概括为身份隐私保护技术和数据隐私保护技术。其中,核心安全技术涵盖哈希算法、数字签名、密钥协商、对称加密及PKI证书体系,身份隐私保护技术包括盲签名、环签名、群签名等;数据隐私保护技术涉及账本隔离、账本加密、密态计算与验证等多种机制。
5、智能合约
智能合约是区块链业务逻辑的载体,完成编译部署后,可按照智能合约预设的条件和逻辑完成业务执行。
智能合约包含承载区块链业务逻辑的智能合约脚本、智能合约执行引擎及分布式应用。
(2)扩展协议
随着区块链技术与应用的快速发展,区块链基础架构在性能、安全性、可扩展性等方面的瓶颈逐渐凸显,由此涌现出一系列新的技术机制,作为基础架构的扩展,丰富区块链的落地能力。
- 针对区块链的性能和存储瓶颈,演化出链上扩容和链下扩容
- 针对安全合规问题,相应提出治理与审计
- 针对互操作难题,提出跨链互操作
- 针对区块链与现有技术和应用的可信增强与融合,相应提出区块链+
1、扩容协议
区块链扩容最终是为了解决性能瓶颈(交易吞吐量)和存储容量瓶颈。
扩容一直以来都是区块链行业亟待解决的难点问题,相应涌现了一系列技术手段,以提升其可扩展性。
目前,扩容方案整体上分为链上扩容和链下扩容。其中,
- 链上扩容包括区块扩容、并行扩容和架构扩容。
- 区块扩容通过提高区块大小上限,增加写入单个区块的交易数量,从而提高交易吞吐量,常用于比特币等公有链场景
- 并行扩容在原有架构的基础上,增加子链、并行链分担部分交易处理,通过并行执行的形式,提高交易吞吐量,支付通道、分片等都是并行扩容的技术手段
- 架构扩容通过新型的区块链架构达到交易扩容的目的。例如,基于DAG(Directed Acyclic Graph,有向无环图)的区块链架构可以有效提高交易吞吐量
- 链下扩容也称为第二层扩容。区别于链上扩容,链下扩容的主要思想是在不改变主链本身架构的情况下新增一层通道,实现功能与性能的扩展,主要包括侧链技术、状态通道和链下协同。
- 侧链技术将一条具有更好性能的侧链与主链连接起来,实现跨链资产转移,同时将复杂的业务逻辑在侧链中执行,主链承担结算任务,从而分担主链压力,提高区块链整体的交易速度,侧链的主要模式有中间人托管模式、驱动链模式和SPV模式
- 状态通道是一种将部分事务处理逻辑转移到链下进行的技术,与侧链技术不同的是,状态通道的实现更轻量级,在链上打开一条通道即可进行逻辑处理,不需要额外搭建一条侧链,主要模式有闪电网络、雷电网络
- 链下协同的主要思想是将链上不方便存储和计算的数据放到链下进行存储和计算,通过映射关系保证链上链下的协同和一致性,主要模式有链下存储、链下计算,可以有效提高主链的性能。
2、治理与审计
与中心化应用不同,区块链去中心化、不可篡改等特性与实际工程友好性存在矛盾,缺乏有效的运维管理及完善的治理模式,同时面对难以监管的困境。
在区块链治理方面,公有链基本维持通过开源社区来对区块链进行维护的现状;而联盟链的用户多用区块链即服务(BaaS)平台,通过将云计算和区块链进行结合,采用容器、微服务及可伸缩的分布式云存储技术等创新方案简化区块链系统的部署和运维管理,同时,自动化运维和自治治理成为区块链行业研究的重点方向。中国人民银行于2020年2月发布《金融分布式账本技术安全规范》,在业内被视为区块链在金融行业应用的重要标准。如何通过有效审计来保障链上资产的安全性及业务运行的合法、合规性是区块链行业发展的重点问题。
治理与审计的整个实施路径涵盖权限体系、治理模型、审计和Baas运维治理。其中,
- 权限体系可以针对链级权限、节点权限、用户权限等维度进行权限控制
- 治理模型可以分为链上治理、链下治理及链上链下协同治理
- 审计则针对节点共识历史、账本数据校验/同步/变更事件、用户访问操作记录、用户身份变更记录、隐私保护策略、智能合约安全、审计管理员操作记录及业务数据本身内容等展开精确有效的审计工作
- BaaS运维治理是使上述治理过程更加易于管理及可视化操作封装的一层服务,方便业务人员执行区块链权限管理、联盟治理、链上数据审计等操作
3、跨链互操作
随着区块链技术的广泛应用,涌现出各种区块链平台。每条链的共识算法、加密机制等各不相同,导致区块链间的异构性。而异构性使得链与链之间很难做到信息和价值互通,形成区块链生态中的“价值孤岛”效应。
为了打通价值孤岛,需要相应的跨链机制实现跨链互操作。常见的跨链机制有以Ripple为代表的公证人机制,以闪电网络为代表的哈希锁定机制,以BTCRelay为代表的侧链机制,以及以Cosmos、Polkadot、BitXHub为代表的中继机制。
4、区块链+
区块链具有去中心化特性、身份验证功能及可靠的链式存储结构,可以通过区块链+赋能众多分布式系统的使用场景,解决它们之间面临的问题。
- 在区块链+物联网行业,区块链可以解决物联网设备管理困难、数据传输成本过高、隐私保护不完善,以及设备间数据安全共享等问题
- 在区块链+大数据行业,区块链的账本不可篡改存储机制、共识算法和密码学算法可以为大数据的存储、计算及数据资产化流通提供增信功能
- 在区块链+工业互联网行业,随着工业4.0时代的逐步推进、智能制造的日渐兴起、工业化与信息化的日益融合,工业互联网正在全球范围内进行人、机、物间高度互联的新一轮技术革命,而区块链技术可以帮助提升工业互联网的适用性、安全性及智能性。
(3)生态组件
为了加强区块链生态构建能力,需要为应用、测试、扩展服务提供相应的生态工具与服务,如促进链上链下信息交互的消息队列MQ、支撑数据可视化的大数据分析、统一的区块链测试框架、运维操作、IoT云平台等。
辅助区块链系统进行安全管理的组件也必不可少,如基础的密钥管理、证书管理、漏洞检测及适用于监管的舆情检测等。
区块数据结构与组织形式
不同主流区块链系统中的数据结构不尽相同,但思路上大体类似,本节将对区块数据结构与组织形式进行介绍。
(1)区块数据结构
交易是区块链中最基本也最重要的数据结构。每笔交易中都封装了参与方之间的一次转账操作,经过验证的合法交易将被执行,并保存在区块链中,交易的执行是驱动区块链系统发生状态迁移的唯一途径,而区块是存储交易及相关元数据的数据结构。
如下图所示,一般来说,区块可以分为区块头和区块体两部分,区块头存储该区块的元数据,区块体存储所有实际的交易结构。

1、区块头
在区块头(Block Header)中,区块哈希是对区块头进行两次SHA256(Secure HashAlgorithm,安全散列算法)运算得到的结果,区块哈希可以唯一地标识一个区块。父区块哈希为当前区块的前驱区块的哈希值,通过在区块头中存储该字段形成一种区块间的链式结构。
除区块哈希外,区块高度(Block Height)也可以用来标识区块,之所以称为“高度”,是因为我们往往将区块链视为一个垂直的栈式结构,栈底为0号区块,挖矿产生的新区块将不断加入栈顶,截止到2020年5月18日,比特币的区块高度已经到达630778。不同于区块哈希,区块高度有时无法唯一地标识某一个区块,出现这种情况表明区块链产生了分叉(Fork)。
在比特币中,默克尔根是通过特定算法对区块内所有交易进行计算得到的哈希值,以太坊和Hyperledger Fabric的区块头中除了包含交易的默克尔根,还包含一个针对账本状态的默克尔根。此外,以太坊还包含一个针对交易回执的默克尔根。
在比特币与以太坊这类基于PoW共识算法进行共识的公有链中,区块头还包含如难度、随机数等与共识过程相关的字段,此外,以太坊为了支持智能合约的执行,在区块头中加入了与Gas相关的字段,
2、创世区块
区块链中的第一个区块称为创世区块(Genesis Block),我们可以通过查找高度为0的区块或以下区块哈希值定位到比特币的创世区块
000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f
由于创世区块不存在任何的前驱区块,因此创世区块的结构总被静态编码在比特币客户端中,比特币创始人中本聪在创世区块的第一条交易(CoinBase)中隐藏了如下信息:“The Times 03/Jan/2009 Chancellor on brink of second bail‐out for banks.”,这是创世区块产生当天《泰晤士报》的头条报道,也是中本聪对当时脆弱的金融系统的暗讽。
(2)区块数据组织形式
1、链式
链式结构是最常见的一种区块数据组织形式,任意一个区块(除了创世区块)都可以通过区块头中的父区块哈希索引到上个区块,从而回溯到创世区块,如下图所示。当新区块被矿工发送至网络时,节点会验证该区块的父区块哈希是否与本地最新区块的区块哈希一致,若一致则将其加入本地区块链。
由于区块头中包含默克尔根,因此通过哈希算法可快速验证某个区块是否遭受了篡改;又因为区块头中包含父区块哈希,因此区块链中任意一个区块的篡改都会导致后续所有区块的改变。

2、DAG式
在IOTA区块链项目中使用DAG或新型区块链结构Tangle。
Tangle摒弃了区块的概念,用交易作为DAG的节点,DAG以创世交易(Genesis Transaction)为起点展开,每当有新交易发布到网络中时,网络参与方都会尝试验证DAG中至少一个末端节点(Tip)交易的合法性,并在验证通过后将新交易指向末端节点,由于除创世交易外的每笔交易都遵循这样的验证逻辑,因此可以确保从创世交易开始一直到最新交易路径上的所有交易都是经过验证的。
如下图所示,在加入6号交易时,选择4号和5号交易进行验证,若验证通过,则证明1~5号交易都是经过验证的。

账户体系
区块链中的账户体系主要分为以资产为核心建模的UTXO模型和以用户为核心建模的账户余额模型两类,本节将对这两种账户体系进行介绍。
(1)UTXO模型
UTXO(Unspent Transaction Output)模型是比特币引入的模型,本节首先通过一个例子对UTXO流程进行介绍,随后对相关概念进行详细介绍。
下述例子仅展示UTXO的思想,其中的比特币金额不与实际情况对应。如下图所示,
- 张三通过挖矿成功获得了10个比特币的奖励
- 随后张三准备向李四转账5个比特币,因此张三构建了一笔包含1个输入和2个输出的交易(如交易A所示),其中,输入来自张三的挖矿所得,一个输出进入李四的账户,另一个输出作为找零回到张三的账户,交易A执行完成后,张三和李四各拥有5个比特币的UTXO
- 在交易B中,张三向李四转账2个比特币,向王五转账3个比特币
- 在交易C中,李四使用来自张三的输出,向王五转账5个比特币,在这两笔交易执行完成后,张三花光了所有的比特币,李四与王五分别拥有2个和8个比特币的UTXO
- 在交易D中,王五使用张三与李四转给自己的3个和5个比特币的输出,进行后续的花费,交易D执行完成后,张三、李四与王五分别拥有0个、2个和0个比特币的UTXO

1、CoinBase
在比特币中,挖矿成功的矿工将得到一笔奖励,这笔奖励一部分来自打包交易的手续费,另一部分就是来自CoinBase。区块中的第一笔交易称为CoinBase交易,该交易以CoinBase为输入,以矿工的比特币地址为输出,这笔交易的执行将使该矿工的比特币地址凭空多出若干个比特币。在上述示例中,张三便是通过CoinBase交易获得的挖矿奖励。
2、输入和输出
交易中的每个输出都是一定数量的不可分割的比特币,这些输出由全网共同验证,并且可能被其持有者用作后续交易的输入。
比特币全节点(Full Node)会追踪和统计网络中所有可用的交易输出,我们称这些交易输出为UTXO集合,即所有“未花费的交易输出”。当我们称一位用户拥有多少比特币时,实际上指的是比特币网络中有多少UTXO可以被该用户控制的密钥使用,而这些UTXO可能分散在成千上万的区块和交易中,比特币钱包帮我们做收集和计算的工作,将这些UTXO的总额以账户余额的形式呈现给用户。
在上述示例中,交易B、C执行完成后,张三、李四和王五分别拥有0个、2个和8个比特币的UTXO,这样的账户余额呈现是比特币钱包对这三位用户可花费的交易输出进行全网追踪和统计后的结果。
交易的输出可以是任意数量的Satoshi(比特币的最小计量单位),值得注意的是,每个输出都是离散且不可分割的,这意味着输出一旦生成,只能作为一个整体被使用。在使用UTXO时,若某个UTXO金额大于这次交易应付的价格,那么该UTXO将作为一个整体被使用,并且产生两部分输出:一部分支付给交易接收方,另一部分作为找零支付给自己,如上图中的交易A;若该用户没有单独的UTXO支付这笔交易,那么比特币钱包将以一定的策略对用户的UTXO进行挑拣和组合,共同作为这笔新交易的输入。
通过使用比特币网络中现存的交易输出,不断生成可被后续交易使用的新输出,比特币系统在消耗和生成UTXO的过程中实现了在不同参与方之间转移的价值。
值得注意的是,在CoinBase交易中并不存在实际的输入,因此可以认为比特币网络是先有输出,再有输入的。从经济学层面理解,CoinBase是凭空产生的货币,它可以理解为为了支撑上层价值/信用社会的必要成本。
(2)账户余额模型
相对于UTXO模型,账户余额模型更符合我们的直观理解,因为账户余额模型与现实生活中的银行账户类似。银行系统直接记录每个账户的余额,在进行交易时,首先判断发起方的余额是否充足,若充足则进行交易双方的余额变动。
下图展示了基于账户余额模型的转账流程,我们可以看到,交易中记录了发起方地址、接收方地址与转账金额,因此每方的账户余额都是一个全局变量,交易的执行直接对转账双方的余额进行操作。

以太坊(Ethereum)是使用账户余额模型的典型代表,其账户类型可以分为外部账户与智能合约账户两种。
1、外部账户
外部账户(External Owned Account,EOA)是由用户创建的账户,用户通过一组密钥对来控制外部账户,拥有了私钥即拥有了账户的拥有权。在发送以太坊交易时,用户需要使用其私钥对交易进行数字签名,以证实交易的有效性。
2、智能合约账户
智能合约是一段可执行代码,而智能合约账户是存储这段代码的账户。智能合约账户不存在相关的密钥对,无法主动发起交易,所以外部账户是与以太坊交互的唯一媒介。当外部账户向智能合约账户发起交易时,执行该智能合约账户中的智能合约,由于以太坊使用图灵完备(Turing Complete)的虚拟机EVM来执行智能合约,因此用户可以引入足够复杂的逻辑来实现各种丰富的功能,如多重签名、权限控制等。
(3)模型对比
上文对现阶段广泛采用的两种账户体系进行了介绍,本节将对混合模型进行介绍,随后进行模型之间的对比。
1、混合模型
有些区块链项目提出将UTXO模型与账户余额模型进行结合。以量子链(Qtum)为例,其在负责智能合约执行的虚拟机层与负责转账操作的UTXO层之间加设了一层账户抽象层(Account Abstract Layer,AAL),通过AAL对UTXO账户与智能合约账户进行适配和转换,实现UTXO模型与账户余额模型的优势互补。
2、优劣对比
下表给出了UTXO模型与账户余额模型在建模对象、适用场景、隐私性与并行度这几个角度的优劣对比。

- 建模对象。UTXO模型首先构建“代币”的概念,再为代币赋予所有权,用户可以自由、直接地操作其拥有的代币。因此,UTXO模型是以资产为基础进行建模的;而在账户余额模型中,用户的余额背后并不存在真实的代币进行支撑,用户只能对账户进行操作。因此,账户余额模型是以账户为基础进行建模的。
- 适用场景。UTXO模型中并不存在“账户当前状态”的概念,所有状态都以UTXO的形式保存在交易中,我们称UTXO模型是无状态(Stateless)的。因此,难以基于UTXO模型构建转账、货币发行等数字货币领域之外的复杂应用(如智能合约);而在账户余额模型中,外部账户拥有账户余额等状态数据,智能合约账户拥有智能合约变量等状态数据,我们称账户余额模型是有状态(Stateful)的。因此,基于账户余额模型可以进行丰富的编程应用。
- 隐私性。在UTXO模型中,如果用户为每笔收到的交易都使用新的地址,那么这些交易将很难关联到该用户上,提高了用户的隐私性。不过由于区块链应用往往需要追踪某一用户的各种状态,因此这种隐私性可能只在电子货币领域有用武之地;而在账户余额模型中,账户的各种状态与账户地址直接关联,其隐私性相对较弱。
- 并行度。在UTXO模型中,交易的输出都是不可分割的独立UTXO,因此比特币持有者可以选择不同的UTXO构建交易,这些交易是互不影响、可并行执行的;而在账户余额模型中,账户余额是一个全局的世界状态,因此若多条交易涉及同一个账户的改变,那么这些交易将无法并行执行。
账本数据组织形式
在区块链中,数据主要分为两大类:区块数据和账本数据,之前已经介绍了区块数据组织形式,本节将介绍账本数据组织形式。
(1)默克尔树
默克尔树(Merkle Tree)又称为二叉哈希树(Binary Hash Tree),是一种用来快速计算摘要和验证一批数据完整性的数据结构。在比特币中,通过默克尔树对区块中的所有交易进行计算、汇总,可以得到一个唯一标识这批交易的哈希值,该哈希值为默克尔根(Merkle Root)。比特币采用连续两次的SHA-256运算作为基本的哈希计算,本节将通过一个例子来介绍默克尔树的工作流程。
如下图所示,假设在某个区块中,有A~G七条交易,首先,分别对这些交易进行哈希计算,得到Hash-A~Hash-G七个哈希值,这些哈希值将作为默克尔树的叶子节点。值得注意的是,由于默克尔树又称为二叉哈希树,其必须拥有偶数个叶子节点,因此我们将重复使用最后一笔交易的哈希值,即Hash-G。
随后,对相邻叶子节点的哈希值进行字符串拼接,对拼接后的结果进行一次哈希计算,将计算的结果作为该相邻叶子节点的父节点。在下图中将Hash-A与Hash-B进行字符串拼接,对拼接后的结果进行两次哈希计算,可得到Hash-AB。重复这一过程,直到默克尔树的最顶层只剩下单个节点,即默克尔根。
默克尔根是一个长度为32的字节数组,无论区块中有多少笔交易,任何一笔交易的篡改都会造成默克尔根的变动,因此默克尔根总能唯一地标识每笔交易。

默克尔树能够快速验证一笔交易是否存在于某一批交易中,因此被广泛应用于简单支付验证(Simple Payment Verification,SPV),即正向验证准确性
若不使用默克尔树,则验证一笔交易是否存在于某一批交易中的直接做法是直接遍历、一一比较(确认该批交易没有遭到篡改、确认存在于该批交易中),这会带来与交易数目呈正比的时间复杂度;若使用默克尔树,则时间复杂度会降低至交易数目的对数级别。
如下图所示,若要验证TX-F是否存在于这批交易当中,只需要提供Hash-E、Hash-GG、Hash-ABCD三个哈希值,通过三次哈希计算判断默克尔根是否一致,我们称由TX-F一直到默克尔根的这条路径为默克尔路径(Merkle Path)。

通过默克尔树,我们将存在性证明的复杂度降低到了log级别,极大地优化了存在性证明的计算性能。
默克尔树能够快速查找到两个区块的merkle treee中不同的交易,即逆向定位错误
已上图为例,假设A和B机器中,TX-F不一样,这个比较检索过程如下:
- Step1:首先比较Hash-ABCDEFG是否相同,如果不同,检索其孩子Hash-ABCD和Hash-EFGG.
- Step2:Hash-ABCD相同,Hash-EFGG不同。检索Hash-EFGG的孩子Hash-EF和Hash-GG;
- Step3:Hash-EF不同,Hash-GG相同,检索比较Hash-EF的孩子Hash-E和Hash-F
- Step4:Hash-E不同,Hash-F相同。Hash-E为叶子节点,获取其目录信息。
- Step5:检索比较完毕。
以上过程的理论复杂度是Log(N)。
之所以要逐层走完所有节点,进行哈希验证,目的是为了找到导致默克尔树根变化的根节点(problem root cause),因为根节点的哈希发生变化,可能存在以下几种情况:
- 待检测的叶子节点遭到篡改,即待验证的交易不在该批交易中
- 包括待检测的叶子节点在内,还有其他的叶子节点也遭到篡改
- 待检测叶子节点之外的其他节点遭到篡改
通过逐层二叉分治的原因定位,可以完整筛查出存在错误的所有交易节点。
默克尔树能够快速验证整批交易在传输过程中是否遭到篡改和数据损坏,即进行完整性校验
 在构造Merkle树时,首先要对数据块计算哈希值,通常,选用SHA-256等哈希算法。但如果仅仅防止数据不是蓄意的损坏或篡改,可以改用一些安全性低但效率高的校验和算法,如CRC。然后将数据块计算的哈希值两两配对(如果是奇数个数,最后一个自己与自己配对),计算上一层哈希,再重复这个步骤,一直到计算出根哈希值。
在构造Merkle树时,首先要对数据块计算哈希值,通常,选用SHA-256等哈希算法。但如果仅仅防止数据不是蓄意的损坏或篡改,可以改用一些安全性低但效率高的校验和算法,如CRC。然后将数据块计算的哈希值两两配对(如果是奇数个数,最后一个自己与自己配对),计算上一层哈希,再重复这个步骤,一直到计算出根哈希值。
在分布式环境下,从多台主机获取数据,怎么验证获取的数据是否正确呢,只要验证Merkle树根哈希一致,即可。
例如,下图中L3数据块发生错误(比如数据被修改了),错误会传导到计算hash(L3),接着传导到计算hash(Hash1-0+Hash1-1),最后传导到根哈希,导致根哈希的不一致,可以说,任何底层数据块的变化,最终都会传导到根哈希。另外如果根哈希不一致,也可以通过Merkle树快速定位到导致不一致的数据。

(2)MPT
MPT(Merkle Patricia Tree,默克尔帕特里夏树)即默克尔树与帕特里夏树(PatriciaTree)结合的数据结构。MPT是以太坊采用的账本数据组织形式,以太坊中的状态数据、交易数据、交易回执数据会被组织成相应的三棵MPT,这三棵MPT的根节点哈希值(StateRoot、TransactionRoot、ReceiptRoot)会被保存在区块头中。
本节首先介绍Patricia树的概念,随后以一个具体的例子对MPT的构建流程进行介绍。
1、Patricia树
Patricia树是Trie树的升级版本,Trie树又称为前缀树或字典树,Trie树中的数据不是直接保存在某个节点中,而是通过共享公共前缀的方式进行组织,即任何一个节点的子孙节点都拥有相同的前缀。如下图(a)所示,Trie树中以7个节点存储了“team”“to”“so”“stop”4个单词,但这似乎并不是一种空间友好型数据结构,Trie树的最大优点是可以最大限度地减少查找过程中的字符串比较。若数据集中存在大量相同前缀的数据,那么Trie树可以在节省大量存储空间消耗的同时,带来相当高的数据查询效率;若数据集中的数据几乎没有共同前缀,那么Trie树的数据查询效率将变得非常差。

Patricia树对没有共同前缀的数据进行优化组织,若一个节点只拥有一个子节点,那么该节点将与子节点进行合并。对于相同的数据集,Patricia树的结构如图(b)所示。
2、MPT节点类型
MPT中包含扩展节点、叶子节点与分支节点三类,这三类节点内都包含一个“节点标识”字段,用于存储与计算节点哈希值,以及节点在内存中的淘汰策略。除此之外,这三类节点拥有以下特性。
- 扩展节点(Extension Node):存储本节点所属的Key的范围,以及一个指向其他节点的Value字段。
- 叶子节点(Leaf Node):与扩展节点的结构基本相同,只不过叶子节点不指向其他节点,其Value字段存储的是一个数据项的内容。
- 分支节点(Branch Node):用于表示MPT中拥有超过一个子节点的非叶子节点。为了防止Key的范围过大,MPT首先通过某种编码方式使Key的每位都通过十六进制进行标识,从而一个分支节点最多可以拥有十六个子节点,也可以拥有一个存储自身数据的字段。
3、MPT的构建
我们通过向一棵空MPT插入4个Key-Value对来看MPT是如何构建的。首先,插入一条Key为“a711355”,Value为“45.0”的记录,此时的MPT结构如下图所示。由于MPT中只有一个节点,因此这个节点为叶子节点。

其次,插入一条Key为“a77d337”,Value为“1.0”的记录,如下图所示。显然,这条记录与上一条记录拥有共同的前缀“a7”,因此MPT在此处出现了分支,并且由两个叶子节点分别存储两条记录无法共享的后缀。

然后,插入一条Key为“a7f9365”,Value为“1.1”的记录,同样,该记录与上两条记录拥有共同的前缀“a7”,因此可以直接成为现有分支节点下的一个新叶子节点,如下图所示。

最后,插入一条Key为“a77d397”,Value为“0.12”的记录,该记录与MPT中“a77d337”记录拥有最长的共同前缀“a77d3”,因此,上图中的第二个叶子节点就成为一个扩展节点,代表这两条记录在第六位上产生的分叉,最终的MPT结构如下图所示。

(3)增量哈希
使用树形结构对区块链数据进行组织固然能带来许多优势,但在读写操作的性能及存储表现上,树形结构显然不是那么优秀,因此一些区块链项目摒弃了树形结构,直接将数据以Key-Value对的形式进行存储。
这种方法带来的最主要的问题是如何验证当前区块链状态的正确性。直接方法是遍历数据库中所有账户数据,并对这些数据依次进行哈希计算,最后得到一个代表当前区块链的状态哈希值,然而若每次出块都遍历整个数据库,则会带来巨大的磁盘IO开销,因此这种方法并不可取。
所谓增量哈希,其实就是对上个区块的增量哈希值加上新区块执行过程中产生的修改集进行哈希计算,将其结果作为新区块的状态哈希值。
举例来说,若在创世区块中创建了50个账户,则创世区块的状态哈希值就是这50个账户的哈希值,记为H0;在1号区块中,20个账户的余额或智能合约变量发生了变动,则1号区块的状态哈希值为

运行流程
交易是区块链系统对外界业务场景进行响应和处理的最小单元。一般来说,区块链中的交易会导致区块链系统中的价值转移。另外,在目前的企业级区块链系统中,交易可以通过对智能合约的部署和调用,进行复杂业务逻辑的部署和执行。
(1)运行流程概述
目前,主流区块链系统采用的交易流大体上可分为两类,
- 一类为以太坊、趣链区块链平台中的先定序后执行模式
- 一类为Hyperledger Fabric中的先执行后定序模式
这里的交易定序指的是由共识模块对交易进行排序和打包。
1、先定序后执行
下图为以太坊交易运行流程。一般来说,交易生命周期包含如下步骤。
- 交易生成。由用户在客户端(SDK)构建一笔区块链交易,附上可证明交易正确性的私钥签名,向某个区块链节点发送这笔交易。
- 交易广播。节点在收到上述交易并验证私钥签名的正确性后,向全网节点广播这笔交易。
- 交易共识。共识节点(挖矿节点)在收集了一定数量的交易,或者收集了一段时间的交易后,将交易按照手续费高低进行排序并打包,随后进行挖矿。挖矿成功的节点将广播这批交易。
- 交易执行。节点在收到这批交易后,依次执行其中的交易。值得一提的是,以太坊不仅支持直接的转账操作,还支持智能合约的部署与调用,后者的执行过程将在节点的虚拟机中进行。
- 交易存储。在这批交易全部执行完成后,节点对执行结果进行构造,并将相应的区块数据、账本数据写入数据库。

2、先执行后定序
如下图所示,Hyperledger Fabric交易运行流程大致可以分为以下几个步骤。
- 交易提案。用户在客户端生成一笔交易提案,提案中包含本次需要执行的链码(Hyperledger Fabric中的智能合约)信息,用户对提案进行私钥签名后将其发送给一个或多个Peer(背书)节点。
- 交易背书与执行。Peer节点对提案进行以下验证:(1)格式完整;(2)该提案未被执行过;(3)提案私钥签名正确;(4)提案发起方有足够的操作权限。在验证通过后,基于当前账本状态对相应的链码进行交易执行,生成一个读写集(本次交易执行读取了哪些数据,更新了哪些数据),但此时区块链账本状态并不会被更新。最后将提案的执行结果,连同节点自身的私钥签名一起返回给客户端,完成本节点对这次提案的交易背书。
- 背书检查。客户端在收到一定数量的提案结果后,对它们的合法性进行检查,并判断本次交易提案是否满足背书策略(有来自足够数量的Peer节点的背书),随后根据提案结果生成一笔交易发送至Order(排序)节点。
- 交易定序。Order节点监听网络中来自不同客户端的交易,并按照一定的规则将其打包成区块,在收集了一定数量的交易,或者收集了一段时间的交易后,将区块广播至所有Peer节点。
- 交易提交。Peer节点在收到区块后,依次应用每条交易中的读写集到世界状态,在这之前,Peer节点还需要验证交易背书是否满足背书策略。
- 交易存储。Peer节点在提交完区块后,将相应的区块数据、账本数据写入数据库。

值得一提的是,Hyperledger Fabric并不是将交易的执行结果直接应用于状态机,而是以读写集(Read-Write Set)的形式记录这些执行结果。如下图所示,HyperledgerFabric的每笔交易都会记录其对状态数据的读取情况和即将对状态数据造成的修改,这里对状态数据的读取情况指在预执行过程中,访问到的每条数据对应的版本信息,即产生于哪个区块的第几笔交易,所有状态数据的读取情况的总和构成这笔交易的读集;而即将对状态数据造成的修改指即将写入数据库的数据信息,一旦这笔交易验证通过,写集中的数据在持久化到数据库时就会附带上版本信息。这些修改信息的总和构成这笔交易的写集。
简单来说,读集和写集组成了一笔交易的读写集。Hyperledger Fabric会将交易发送给Peer节点,Peer节点在收到该交易后会访问数据库,根据交易指定的逻辑完成对交易的预执行,得到该交易对应的读写集,并将读写集返回给客户端,客户端接收到读写集后可完成交易的生成。

(2)交易的生成
一般来说,用户通过区块链生产厂商提供的客户端进行交易的生成与发送,下表展示了以太坊交易字段及其含义。

- From字段标识了一笔交易的发起方地址,一般一个以太坊客户端会管理多个账户,From字段在以太坊中主要用于使客户端明确发起交易的账户,而不会被真正写入交易并发送到以太坊网络中,这是因为发起方地址可以通过签名方的公钥进行恢复。
- To字段标识了转账的目标账户,或者要操作的智能合约对应的智能合约账户,若该字段为空,则意味着智能合约被部署。
- Nonce字段是一个连续增长的整数,用于标识特定账户已经发送到以太坊网络中的交易数目。一方面,Nonce字段的存在可以保证矿工在打包交易时能够确定来自相同账户的交易顺序,考虑如下场景:张三计划发起两笔交易,并希望第一笔交易可以先于第二笔交易被打包,由于区块链网络的异步性,此时若没有Nonce字段的存在,则张三只能先发送第一笔交易,等到确认这笔交易被打包后再发送第二笔交易,否则无法确定矿工收齐这两笔交易的先后顺序,而事实上张三只需要递增这两笔交易的Nonce值,矿工即可对交易进行正确排序;另一方面,Nonce字段可以解决数字货币中著名的“双花问题”,即若没有Nonce字段,则矿工无法判断自己是否打包过某笔交易,从而导致恶意用户可以不断复制一笔交易并发送至网络中,使这笔交易被反复执行。
- 以太坊出于矿工激励策略与系统稳定性的考虑设置了Gas机制,根据以太坊黄皮书,一次账户余额的变更、一次哈希计算、任何智能合约的执行等都需要消耗一定量的Gas,如果Gas消耗超出这笔交易发起方指定的数目,则撤销这笔交易,且其造成的所有对区块链状态的改变都将被回滚。一方面,交易执行中消耗的Gas都将为矿工所得,激励矿工为网络的良好发展不断贡献算力;另一方面,防止用户在智能合约潜在的漏洞中对区块链系统造成有意或无意的破坏(如智能合约中的死循环造成全网节点的瘫痪)。具体来说,Gas在交易结构中体现为GasPrice与GasLimit,前者指明了Gas与以太币之间的转换比例,后者为交易发起方愿意为这笔交易的执行支付的Gas上限。当然,对矿工来说,越“值钱”的交易会越早被打包。
- Data字段一般和智能合约有关。一般来说,智能合约调用交易中的Data字段包含调用方法的标识和需要传入的参数,智能合约部署交易中的Data字段主要包含智能合约经编译后的字节码。以太坊虚拟机会按照交易特点解析Data字段中的内容,并进行相应的操作。
- 交易签名可以保证交易的完整性与真实性。交易签名的一般流程是对交易整体计算摘要后,使用交易发起方账户的私钥对交易摘要进行签名。交易签名采用非对称加密算法,如传统椭圆曲线签名算法,许多国产区块链系统也支持国密算法SM2
(3)交易传播与验证
每个节点在收到一笔交易后都会进行有效性验证。一般来说,这一步是验证交易签名是否合法,以保证交易在整个生成到传播的过程中没有被篡改过。交易签名验证的方式与在其他场景下签名的验证方式基本没有区别,首先,计算交易摘要;然后,使用交易发起方账户的公钥对签名进行解密,得到发送方发送时的交易摘要,若二者相等,则交易验证通过。
以比特币为代表的基于UTXO模型的区块链平台一般采用锁定脚本和解锁脚本的方式保证交易的有效性,其将一系列操作数和指令以脚本的形式附在交易中,若这些脚本执行得到期望的结果,则验证通过。
接收到这笔交易的节点会将这笔交易广播到区块链系统中的每个节点上。对于大规模网络,区块链系统一般不与全网节点建立全连接,而采用Gossip等P2P协议,将交易广播给逻辑或物理上的“邻居”,然后由“邻居”完成进一步的交易广播;相反,对于小规模、节点较少的私有链或联盟链场景,可以采用全连接的P2P网络,每个节点都可以一次性完成所需信息的广播任务。
区块链节点在接收到来自客户端或其他节点的交易后,会将交易暂存到本地交易池(Transaction Pool),用于后续的共识定序和区块生成。一般来说,区块链节点会提供两种交易池,一种用于暂存可供用户生成区块的交易(Pending Pool),另一种用于暂存用户暂时无法生成区块的交易(Queued Pool)。为保证执行效率,区块链系统的交易池都是一段内存空间,不会占用持久化存储设备的空间和IO。
在前面对Nonce字段的介绍中提到,矿工需要依照Nonce值按序打包同一用户的所有交易,由于区块链网络存在异步性,无法对交易到达矿工的先后顺序做出假设,因此,对于未按序到达的交易,矿工先将其暂存到Queued Pool,而对于按序到达的交易,则将其暂存到Pending Pool。
Pending Pool中的交易会被进一步打包用于生成区块,区块的生成规则遵循区块链底层采用的共识算法。
- 在采用PoW共识算法的比特币或以太坊中,矿工为了最大化自己的利益,会优先挑选交易池中手续费更高的交易进行打包,为防止手续费低的交易“饿死”,随着交易的等待时间不断变长,交易的优先级会得到提升;在完成交易的打包且成功解出PoW共识算法之后,矿工将这批交易广播至全网节点,并由全网节点进行验证和执行。
- 在采用BFT类算法的趣链区块链平台中,由于不存在任何激励机制,因此往往由一个事先选举的节点进行交易的打包,打包时按照先来先服务等较为公平的策略进行交易的选择。在完成交易打包后,将这批交易广播至全网节点进行后续的共识流程。
打包好的交易将用于区块的生成。在目前常用的企业级区块链系统中,一般有专门的主节点对内存中的交易进行排序和打包,随后将打包结果同步给其他参与方,各个参与方进行必要的执行等操作获取其他区块的相关信息(例如,交易执行过程完成对世界状态的修改后,会生成最新的世界状态哈希)后,即可成功生成区块。对于这样的区块链系统,所有正常工作的节点均会生成一致的区块,不会出现相同区块高度的区块不一致的情况。
而在以比特币为代表的公有链中,不同的矿工可能会产生不同的打包结果,生成不同的区块,即出现分叉,比特币网络的节点根据共识机制解决分叉问题。
(4)交易的执行
节点在接收到一批交易并验证其合法性之后,便开始依次执行其中的交易。节点根据交易中的To字段判断这笔交易是转账交易还是智能合约交易。若为后者,则取出交易中的Payload字段,交由虚拟机进行智能合约的执行。
在采用BFT类算法的联盟链中,由于同一时刻只有一个节点在打包,因此所有正常节点在任意区块高度都执行相同顺序的交易,这保证了这些节点的状态总是发生一致的变迁。
区块链的网络层封装了区块链系统的组网方式,包括节点间的组织形式、数据传输方式等。本章将重点介绍区块链网络层的拓扑结构、网络协议及网络中不同的节点类型。
P2P网络
P2P是“peer-to-peer”的缩写,peer在英语里一般是同伴、同事的意思,因此P2P网络通常被称为对等网络,网络中的每个节点被称为对等节点。在P2P网络中,每个节点的地位都是对等平权的,既能作为服务的请求者又能为其他节点提供服务。
P2P网络打破了互联网中传统的客户端/服务器端结构,使每个节点都具有不依赖中心服务器,自由、平等通信的权利。
P2P网络的发展到目前为止经历了四个阶段:
- 集中式
- 纯分布式
- 混合式
- 结构化
每个阶段都代表一种P2P网络模型,主要的区块链平台大多采用混合式和结构化P2P网络模型来构建。
目前,在学术界和工业界对P2P网络没有一个统一的定义,不同的研究学者和机构分别给出了P2P网络不同的定义,这些定义之间并不矛盾,均从不同角度反映了P2P网络的内在特点。一般来说,P2P网络具有如下特点。
- 去中心化。信息的传输和服务都直接在节点间进行,无须中心化服务器的介入。
- 可扩展性。虽然节点的加入增加了对服务的需求,但同步扩充了系统资源的供给和服务能力。
- 健壮性。P2P网络具有高鲁棒性、高容错性的特点,同时,网络拓扑结构可以根据部分节点失效自动调整。
- 负载均衡。在P2P网络中,每个节点既是服务器端又是客户端,同时,资源分布在多个节点上,能够更好地实现网络的负载均衡。
- 隐私保护。节点信息的传输无须经过某个中心节点,降低了隐私泄露的风险,同时增加了消息的匿名性。
惠普实验室(Hewlett-Packard Laboratories)的Milojicic将P2P网络定义为一类采用分布式方式、利用分布式资源完成关键功能的系统。其中,分布式资源包括算力、存储空间、数据、网络带宽等各种可用资源,关键功能是分布式计算、数据内容共享、通信与协作或平台服务。
(1)P2P网络模型
1、集中式P2P网络
集中式P2P网络结构最为简单,一个节点保存其他节点的索引信息,而索引信息又包括节点IP、端口、节点资源等。节点之间互连的路由信息需要向中心节点查询,如果和对等节点建立连接则不再依赖中心节点。集中式P2P网络结构简单、容易实现,但是由于其所有路由信息都在中心节点中存储,因此当节点数量不断增长时容易出现性能瓶颈,也容易出现单点故障。
集中式P2P网络拓扑结构如下图所示。

2、纯分布式P2P网络
纯分布式P2P网络移除了中心节点,在P2P网络之间建立了随机网络,一个新加入的节点和P2P网络中的某个随机节点建立连接,形成一个随机的拓扑结构,如下图所示。新节点和邻居节点建立连接后需要全网广播,让整个网络感知到新节点的存在。
全网广播的方式是,新节点向自己的邻居节点广播,邻居节点在接收到广播后向自己的邻居节点广播,以此类推,从而广播到整个网络。这种广播机制也称为泛洪机制。
纯分布式P2P网络不存在集中式P2P网络的单点故障和中心节点性能瓶颈,具有较好的扩展性,但是泛洪机制又引入了新的问题,一是容易形成泛洪循环,节点A发出的消息经过节点B到节点C,节点C再广播到节点A,形成了一个消息循环;二是响应消息风暴,如果节点A想请求的资源被很多节点拥有,那么在短时间内就会有大量的节点向节点A发送响应消息,可能会让节点A崩溃。

3、混合式P2P网络
混合式P2P网络就是混合了集中式P2P网络和纯分布式P2P网络的结构,混合式P2P网络中存在多个超级节点组成分布式P2P网络,而每个超级节点又与多个普通节点组成局部的集中式P2P网络,如下图所示。相对于普通节点,超级节点在处理能力、带宽、存储方面具有一定的优势。一个新的普通节点加入网络时,需要先选择一个超级节点进行通信,该超级节点推送其他超级节点列表给新加入的普通节点,然后,新加入的普通节点再根据超级节点列表中的状态选择一个超级节点作为父节点。
这种混合式P2P网络拓扑结构限制了泛洪机制广播的范围,避免了大规模的泛洪循环。在实际应用中,混合式P2P网络拓扑结构是相对灵活且比较有效的网络结构,容易实现。

4、结构化P2P网络
结构化P2P网络综合了集中式P2P网络的快速查找和纯分布式P2P网络的去中心化特点,对二者进行了权衡,结构化P2P网络是目前P2P网络的主流结构。
结构化P2P网络也是一种分布式P2P网络,但其与纯分布式P2P网络有所区别。纯分布式P2P网络是一个随机网络,而结构化P2P网络可以将所有节点按照某种结构有序地组织起来,形成一个环形网络或树形网络。
结构化P2P网络在具体实现上普遍基于DHT(Distributed Hash Table,分布式哈希表)算法。具体的实现方案有Chord、Pastry、CAN、Kademlia等算法,其中,Kademlia算法是以太坊P2P网络所采用的算法。下图展示了一个简单Kademlia网络的拓扑结构。在Kademlia算法中,通过对节点按照二叉树的结构进行组织,可以达到对节点高效路由和索引的目的。

(2)P2P网络协议
1、BitTorrent协议
BitTorrent(全称比特流,简称BT)协议是一个网络文件传输协议,依赖P2P网络,采用BT协议的节点作为数据下载者在下载的同时不断向其他下载者上传已下载的数据。BT协议充分利用了用户的上行带宽,通过一定的策略保证上传速度越快,下载速度也越快。
BT协议是架构于TCP/IP协议之上的一个P2P网络文件传输协议,处于TCP/IP协议的应用层。BT协议本身包含很多具体的内容协议和扩展协议,并且还在不断扩充。如果有多个下载者并发地下载同一个文件,则每个下载者同时为其他下载者上传文件,这样,文件源可以支持大量的用户进行下载,而只带来适当的负载增长。
BT协议把提供下载的文件进行拆分,这种拆分并不是将文件实际拆分,而是按照固定大小拆分成逻辑上的小块,逻辑分块后硬盘上并不产生各个块文件,而把每个块的索引信息和哈希值写入torrent文件(种子文件,简称“种子”),作为被下载文件的索引和校验依据。下载者要下载文件内容,首先需要得到相应的torrent文件,然后使用BT客户端进行下载。下载时BT客户端首先解析torrent文件,得到Tracker服务器地址,然后连接Tracker服务器。Tracker服务器回应下载者的请求,提供拥有资源节点的IP地址。BT客户端也可解析torrent文件,得到节点路由表,然后连接节点路由表中的有效节点,由网络中的有效节点提供其他下载者的IP地址。
下载者再连接其他下载者,根据torrent文件,分别告知对方自己已经拥有的数据块,然后向对方获取自己没有的数据块。这种方式不需要其他服务器或网络节点的参与,分散了单条线路上的数据流量,减轻了服务器的负担。下载者每得到一个块,都需要算出下载的数据块的哈希验证码,与torrent文件中的进行对比,如果一致则说明数据块正确,不一致则需要重新下载这个数据块。下载者越多,提供的带宽越多,torrent文件也越多,下载速度就越快。
从BT客户端角度考虑,下载原理分为以下几步。
- 根据BT协议,文件发布者会根据要发布的文件生成一个torrent文件。BT客户端可从Web服务器上下载该torrent文件,并从中得到Tracker服务器地址等信息。
- 根据Tracker服务器地址与Tracker服务器建立连接,并从Tracker服务器上得到拥有torrent文件的节点的信息,或者根据这些信息与网络中其他节点建立连接,或者从对等节点中得到拥有torrent文件的节点的信息。
- 根据节点信息与多个节点建立连接,依据对应协议完成握手,并从连接的对等节点中下载数据文件,同时监听其他节点的连接,以便将自己拥有的数据分享出去。
在这个发展阶段的BT协议使用Tracker服务器作为torrent文件提供索引,同样面临着集中式P2P网络遇到的问题,随着P2P网络的发展,出现了DHT这样不依赖中心索引服务器(如Tracker服务器)的结构化网络模型,BT协议也随之更新,支持无Tracker服务器模式。
DHT是一种分布式存储方法。在不需要中心索引服务器的情况下,每个BT客户端负责一个小范围的路由,并存储一小部分数据,从而实现整个DHT网络的寻址和存储。使用支持该技术的BT客户端,用户无须连接Tracker服务器就可下载,因为BT客户端会在DHT网络中寻找下载同一文件的其他用户,并与其进行通信,开始下载。这种技术优势非常明显,极大地减轻了Tracker服务器的负担,甚至可以不使用Tracker服务器,用户之间可以更快速地建立连接。
2、Kademlia协议
Kademlia是一种通过分散式杂凑表实现的协议,它是由Petar Maymounkov和DavidMazières为P2P网络设计的一种结构化网络协议。Kademlia协议规定了网络的结构,也规定了通过节点查询进行信息交换的方式。节点间依赖自身ID作为标识,同时依赖自身ID进行节点路由和资源定位。
相对于纯分布式P2P网络泛洪式地查询数据,Kademlia网络为了更加快速地搜索节点,采用基于两个节点ID的异或来计算距离。需要注意的是,同一网络中的节点ID格式必须一致,并且得到的距离只是在Kademlia网络中的虚拟距离,与现实中节点的物理距离没有关系。一个具有2n个节点的Kademlia网络在最坏的情况下只需要n步就可以找到被搜索的节点。
在Kademlia网络中,所有节点都被当作一棵二叉树的叶子节点,并且每个节点的位置都由其ID前缀唯一确定。任意一个节点都可以按照自己的视角把这棵二叉树分解为一系列连续的、不包含自己的子树。
- 最高层的子树,由整棵不包含自己的二叉树的另一半组成
- 下一层子树则由剩下部分中不包含自己的二叉树的另一半组成
- 以此类推,直到分割完整棵二叉树
下图展示了节点0011对子树的划分。

虚线包含的部分就是各子树,从节点0011的视角一共划分为四棵子树。Kademlia协议确保每个节点都知道其各非空子树的至少一个节点。在这个前提下,每个节点都可以通过节点ID找到任何一个节点。这个路由的过程是通过异或节点ID,不断缩短节点间距离得到的。
下图演示了节点0011是如何通过连续查询找到节点1110的。节点0011通过在逐层的子树间不断学习,并查询最佳节点,获得越来越接近的节点,最终收敛到目标节点。

- 首先,假设查询的目标节点是1110
- 按照节点0011的视角划分子树,在第一棵子树中,假设节点0011知道其节点是101,节点0011首先向节点101发起请求。向节点101发起请求是因为根据与节点101计算异或距离后发现其与目标节点距离最近,为了得到目标节点需要向离目标节点更近的节点查询。
- 然后,节点101也会按照自己的视角将整棵树进行划分,它同样知道每棵非空子树中的至少一个节点,这时返回目标节点所在的对应子树中节点101知道的节点
- 以此类推,找到目标节点。后续的每步查询都是上步查询的返回值,并且每步都越来越接近目标节点。
在Kademlia网络保存的每个子树的节点列表都被称为K桶,其中,K标识了一个桶中存放节点的数量。每个节点都保存了按自己视角划分子树后子树中节点的信息,如果只保存单个节点,则鲁棒性不足,为了解决这个问题,需要多保存几个节点。在上图中可以看到,有些子树的节点多,有些子树的节点少。Kademlia协议为平衡系统性能和网络负载设置了一个常数,但该常数必须是偶数,如K=20。在BT协议的实现中,K=8。
网络中的节点并不是一成不变的,随时有节点加入也有节点退出,为了维护网络的稳定性需要实时更新K桶,剔除已经退出网络的节点,增加新加入网络的节点。
基于对网络上大量用户行为习惯的研究结果,节点的失效概率和在线时长呈反比,也就是说,在线时间长的节点继续保留在K桶列表中更有利于网络的稳定性。
由于每个K桶覆盖距离的范围都呈指数增长,因此形成了离自己近的节点的信息多,离自己远的节点的信息少的情况,保证了路由查询过程是收敛的。这种方式也意味着有更多可能连接到离自己近的节点,一方面是因为距离近的子树的节点少,另一方面是因为自己可以更多地包含距离近的节点。
区块链网络
区块链网络是按照P2P协议运行的一系列节点的集合,这些节点共同完成特定的计算任务,共同维护区块链账本的安全性、一致性和不可篡改性。
区块链系统为了适应不同的应用场景或解决单一节点性能瓶颈,衍生出了不同类型的节点,这些节点有不同的分工,共同维护整个区块链网络的健壮性。除了P2P协议,区块链网络还包含其他协议。
(1)节点类型
虽然P2P网络中的各个节点相互对等,但在区块链网络里根据提供的不同功能,不同区块链系统会对节点类型进行不同的划分。
区块链技术发展早期,主要以公有链为主,根据节点存储内容的不同,节点类型划分为以下两种。
- 全节点:全节点指的是节点同步全量区块链数据,负责交易的广播和验证,维护整个区块链网络的稳定运行。
- 轻节点:轻节点也被称为简单支付验证(SPV)节点,指的是节点只同步区块头数据,依赖全节点,通过默克尔路径验证一笔交易是否存在于区块中,不需要下载区块中的所有交易。存储容量有限的IoT设备可以通过运行一个轻节点参与到区块链网络中。
随着区块链技术的快速发展和普及,区块链应用呈现爆发式增长,各种应用场景层出不穷。为了解决传统企业业务上的痛点,企业级联盟链应运而生,这也对区块链技术提出了更高的要求,相对于公有链,联盟链中的节点类型更加多样化。例如,由大中企业组成的联盟链,其核心企业具有最优厚的计算资源和最高的数据管理权限,而小企业只有数据访问权,它依赖核心企业提供的数据来运行自己特定的业务。核心企业节点间通过运行共识协议决定区块链账本的内容,而小企业节点同步这些账本内容,当收到一条客户端发送过来的交易时,转发给核心企业节点处理。
因此,根据节点是否参与共识,节点类型又可划分为以下两种。
- 共识节点/验证节点:共识节点在某些系统中也被称为验证节点,主要负责对交易排序,并打包成块,与其他验证节点达成一致的共识,然后执行交易,将交易和执行结果进行存储。
- 非共识节点/非验证节点:非共识节点在某些系统中也被称为非验证节点,主要负责同步验证节点生成的区块,执行交易,将交易和执行结果进行存储。
下图为趣链区块链平台多种类型节点组成的网络拓扑。

其中,VP为共识节点,NVP和CVP均为非共识节点,每个VP节点都可以部署一个由CVP节点组成的灾备集群,在VP节点发生故障时,自动切换接替VP节点的工作。
在某些联盟链系统中,为了突破单一节点系统资源的限制,将区块的共识、执行和存储功能进行拆分,分别交由不同节点完成。
- VP节点运行共识协议,决定交易的排序,并打包成区块,因为VP节点不存储区块链账本内容,因此不执行区块只广播区块。
- NVP节点接收到VP节点广播过来的区块后,首先对区块进行合法性校验,校验通过后,按照区块内交易的顺序执行交易,并存储交易和执行结果。
Hyperledger Fabric联盟链就是一个典型的拆分节点共识、执行和存储的例子,共识交由Order节点完成,执行和存储交由Peer节点完成,下图为Hyperledger Fabric联盟链多种类型节点组成的网络拓扑,为了简化复杂度,图中没有画出多通道的Hyperledger Fabric联盟链网络,仅描述只有一个通道的Hyperledger Fabric联盟链网络,组织A和组织B在一个通道内。

在由多个组织参与组成的Hyperledger Fabric联盟链网络中,每个组织都可以是一个集群,不同的组织集群连接起来形成一个区块链网络。
在整个网络中,节点主要分为客户端节点、CA节点、Order节点和Peer节点。
- 客户端节点为通过客户端发送提案、提交交易的节点
- CA节点负责为网络中的节点提供基于数字证书的身份信息
- Order节点负责对Peer节点签名并对满足签名策略的交易提案进行排序和出块,广播给Peer节点
- Peer节点可担任不同角色,角色如下。
- 记账节点(Committing Peer):所有的Peer节点都可以称作记账节点,负责对区块及区块交易进行验证,验证通过后写入账本。
- 背书节点(Endorsing Peer):负责执行客户端节点发送过来的交易提案,并根据背书策略对交易进行签名背书后再返回给客户端节点。
- 主节点(Leader Peer):一个组织集群中有多个Peer节点,为了提高通信效率,需要一个主节点作为代表负责与Order节点通信,接收Order节点广播过来的区块,并同步给组织集群内其他Peer节点。主节点可以通过动态选举或静态指定产生。一个组织集群内可以有一个或多个主节点。
- 锚节点(Anchor Peer):负责与其他组织集群的Peer节点通信,即负责跨组织集群的通信,确保不同组织集群内的Peer节点相互知道对方组织集群的节点信息。锚节点不是Hyperledger Fabric联盟链网络的必选项,一个组织集群可以有零个或多个锚节点。
综上所述,在不同的区块链系统里,根据节点职能的不同对节点类型有不同的划分,不同类型的节点分工协作,维护整个区块链网络的健壮性和稳定性。通过对节点类型进行划分,一方面,可以满足业务应用场景的需求,比如,前文提到的中小企业联盟链的例子;另一方面,突破单一节点系统资源限制,便于日后节点横向扩展,构建更大规模的区块链网络。
(2)区块链网络模型
区块链的网络结构继承了计算机通信网络的一般拓扑结构,可以分为如下图左边和右边所示的完全去中心化网络结构和多中心化网络结构。


完全去中心化指网络里所有节点都是对等的,各个节点自由加入或退出网络,不存在中心节点。采用PoW共识算法的公有链就是一种完全去中心化网络。在这种网络中,所有节点都有权限生成新区块,并写入区块链账本,节点只要解出PoW数学难题就能获得记账的权利,在经济激励机制下,越来越多的节点参与到记账权的竞争中,整个网络得以稳定运行,这种稳定运行不依赖某些中心节点,任何节点的退出都不会对区块链网络造成影响。但是,完全去中心化网络维护成本高、共识效率低、交易确认延迟高。随着互联网技术的发展,人们对交易吞吐量的要求越来越高。据统计,全球知名信用卡支付公司平均每秒可处理大约2000笔交易,其峰值维持在每秒上万笔交易。
站在“区块链不可能三角”(可扩展性、去中心化、安全性)的角度,区块链要想应用到实际业务场景中,可扩展性和安全性缺一不可。而去中心化作为区块链技术兴起的一大亮点,也不可缺失。因此,人们想到,可以牺牲部分去中心化来提升整个网络的可扩展性,但这种牺牲并不是说网络就此变成了中心化网络架构,而是演变成一种叫作“弱去中心化”的网络架构,也称为多中心化网络结构。
多中心化网络结构指网络里存在特定数量的中心节点和其他节点,只有中心节点拥有记账权。如上图右边所示,黑色圆点表示中心节点,灰色圆点表示其他节点,中心节点负责共识和出块,它的加入和退出受到严格控制,往往需要经过全网节点投票同意后方可加入或退出;其他节点虽然没有记账权,但可以共同监督中心节点的行为,如果中心节点存在作恶行为,则可以将其投出。其他节点也可以竞争成为中心节点。
不同区块链系统采用的网络连接方式不同,主要划分为如下图左边和右边所示的全连接网络和自发现传播网络,这两种网络连接方式各有优缺点。
- 全连接网络,即节点间两两建立可互相收发消息的网络连接,消息的发送不需要经过中间节点传播,直接到达对端,具有实现简单、通信高效的优点,但是网络扩展性不高
- 自发现传播网络,即节点只与部分节点建立网络连接,但总有一条链路可以到达网络里的各个节点,因此,理论上网络可无限扩展,但是实现起来较复杂且通信可能有一定的延迟。


(3)区块链网络协议
区块链网络在对等网络的基础上,还包括其他协议。本节将介绍区块链系统网络层常用的协议。
1、Gossip
Gossip协议最早是在1987年由Demers Alan,Dan Greene等在ACM上发表的论文Epidemic Algorithms for Replicated Database Maintenance中提出的。它是一种去中心化、可扩展、可容错,并保证最终一致性的消息传播通信协议,用来实现节点间信息同步,解决分布式架构中的一致性问题。
Gossip协议的基本原理是当一个节点想要把自己的消息同步给组织集群内其他节点时,先周期性地随机选择几个节点,并把消息传播给这些节点。收到消息的节点重复同样的过程,即把消息再传播给随机选择的其他节点,直至组织集群里的所有节点都收到了该消息。随机选择目标传播节点的数量N是一个指定的常量,这个N称为fanout参数。由于整个收敛过程需要一定的时间,因此无法保证在某一时刻所有节点都收到了消息,但理论上最终所有节点都会收到消息。因此,Gossip协议是一个最终一致性协议,其不要求任何中心节点,允许节点任意加入或退出组织集群,组织集群里的所有节点都是对等的,任意一个节点不需要知道整个组织集群里的所有节点信息就可以把消息散播到全网,即使组织集群中任何节点宕机或重启也不会影响消息的传播。
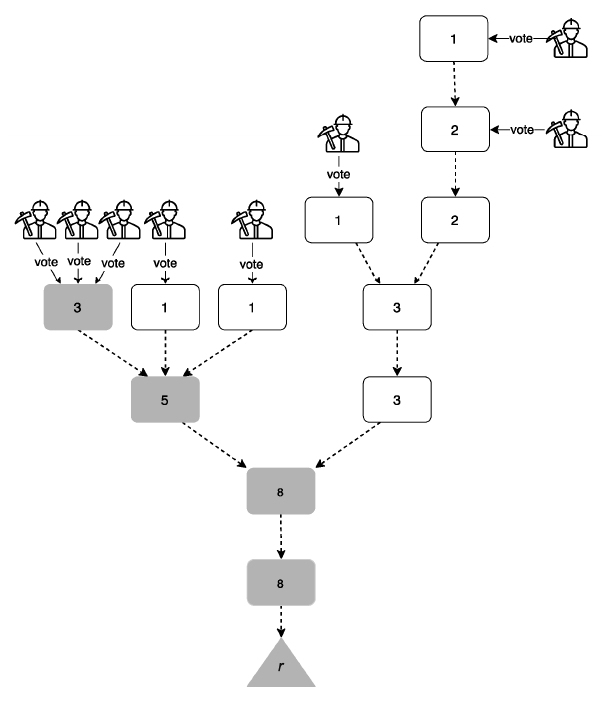
下图为Gossip协议在由16个节点组成的网络里的数据传播示意图,
- 首先,图(a)中节点1更新数据,并想广播给其他节点
- 图(b)所示,节点1随机选择了节点2和节点7进行数据传播
- 然后,如图(c)所示,节点1、节点2和节点7继续随机选择节点进行数据传播。
- 以此类推,最后,网络里的所有节点都更新了数据

总结一下,节点传播消息是周期性的,并且每个节点都有自己的周期。节点传播消息的目标节点数量由fanout参数决定。至于往哪些目标节点传播消息,则是随机选择的。所有节点都重复同样的过程,直至整个网络从不一致的状态收敛到一致的状态。
一般来说,Gossip网络中两个节点间的通信方式有以下三种。
- Push-based方式:节点A将数据及版本号(Key,Value,Version)推送给节点B,节点B更新节点A中比本地新的数据。
- Pull-based方式:节点A仅将(Key,Version)发送给节点B,节点B将本地比节点A新的数据(Key,Value,Version)推送给节点A,节点A更新本地数据。
- Push-Pull混合方式:在Pull-based方式的基础上,节点A将本地比节点B新的数据推送给节点B,节点B更新本地数据。
理论上,使用Gossip协议进行通信的组织集群的节点数量无上限,网络收敛速度快,因此,Grossip协议在区块链领域得到了广泛应用。
面向企业级联盟链的Hyperledger Fabric采用Gossip协议作为其P2P网络的消息传播协议。其主要作用有:
- 区块传播:避免为了同步区块,所有的Peer节点都与Order节点连接的情况。仅需要主节点与Order节点相连,负责与Order节点通信。主节点在获取到新区块以后,通过Gossip网络的Push-based方式将新区块传播给随机选择的预定数量的其他Peer节点,收到新区块的Peer节点重复该过程,直到每个Peer节点都收到了新区块。通过Gossip协议进行区块传播在一定程度上缓解了Order节点的压力
- 区块同步:当Peer节点由于宕机、重启或新加入导致区块落后时,通过Gossip网络的Pull-based方式可以从其他Peer节点处拉取新区块,直至账本数据同步到最新状态,此过程不需要Order节点的参与
- 节点发现:Peer节点周期性地通过Gossip网络的Push-based方式随机选择预定数量的节点传播心跳消息,表示自身存活状态。因此,每个组织集群的Peer节点都可以维护组织集群内所有Peer节点的存活状态信息。若每个组织集群中至少有一个Peer节点访问锚节点,则锚节点就可以知道通道内所有不同组织集群的Peer节点的信息,进而网络里的所有Peer节点都可以知道通道内所有不同组织集群的节点信息,维护通道内的节点关系视图(组织集群关系视图)。
同样采用Gossip协议的还有Facebook研发的面向稳定币的区块链系统Libra,Libra仅使用Gossip网络中的Push-based方式实现区块链节点发现功能。节点周期性地随机选择预定数量的节点向其传播自己当前的网络视图,收到消息的节点如果检查到对端发送过来的信息更新,则更新本地维护的节点地址信息,重复该过程,直到网络里的所有节点都有一个完整的节点关系视图。如果节点关系视图里有未建立连接的节点,则与其建立连接。因此,Libra仅使用Gossip协议实现节点发现功能,而整个网络还是一个全连接网络,节点间两两相连。
2、Whisper
Whisper起源于以太坊,是以太坊里的一个网络子协议,子协议指的是构建在以太坊P2P网络之上的协议,虽然各个子协议都有自己的协议名称、协议版本号和协议消息定义,但是,所有子协议的底层通信都使用同一个以太坊P2P网络。
Whisper是一个基于身份的消息传递系统,其设计目的是为DApp提供一种高隐私性、防网络嗅探的通信服务。一个以太坊节点可以自行选择是否开启Whisper服务,如果开启,那么这个节点被称为Whisper节点。
Whisper节点周期性地向其他节点广播自己收到的Whisper消息,因此,所有的Whisper消息都会发送给每个Whisper节点。为了降低网络负担,防止恶意客户端向节点发送大量垃圾消息对节点造成DDoS攻击,以太坊使用PoW来提高Whisper消息发送的门槛,即每次发送Whisper消息,节点都需要进行一次PoW,仅当消息的PoW值超过特定阈值时,节点才会处理该消息,并转发给其他Whisper节点,否则将其丢弃。本质上,如果节点希望网络将Whisper消息存储一段时间(TTL),那么计算PoW值的成本可视为为该消息分配资源所支付的价格,因此,所需PoW值与消息大小和TTL呈正比。
由于所有的Whisper消息都会被加密且通过加密网络传输,只有持有对应密钥的人才能对消息解密,所以Whisper消息传递具备安全性。
Whisper对外暴露了一套订阅—发布模型的API,客户端通过这套API,可以向Whisper节点发送与某个Topic相关的消息,节点将消息分发给所有与该Topic相关的过滤器,并在到达广播时间时将消息广播给其他Whisper节点。客户端也可以向Whisper节点订阅自己感兴趣的Topic,节点将返回一个过滤器ID给客户端,如果过滤器里有与该Topic相关的消息,则客户端使用过滤器ID向节点查询得到Topic消息。客户端也可以在向Whisper节点发送消息时指定这个Topic消息要转发给哪个Whisper节点,由接收发送请求的节点将消息转发给指定节点,指定节点收到Topic消息以后,将消息分发给所有与该Topic相关的过滤器,并在到达广播时间时将消息广播给其他Whisper节点。
3、libp2p
libp2p是协议实验室(Protocol Labs)研发的IPFS项目里相当重要的一个组件,主要负责节点发现、数据路由、安全传输等,后来被提升为独立的开源社区项目。如今,已经有多个项目使用libp2p作为网络传输层,如IPFS、Filecoin、Polkadot和以太坊2.0等。
libp2p支持各种各样的传输协议,如TCP、UDP、QUIC等,它使用自描述(Multiaddr)来标准化一个节点的地址,而不仅是IP地址和端口号。自描述地址包括IP地址类型、IP地址、网络传输协议、端口号、应用协议ID和节点ID等信息,通过地址解析和协议协商,libp2p知悉使用什么协议才能连接到目标节点。这使得libp2p在网络协议繁多、协议升级频繁的大环境下,可以很方便地实现各种协议的扩展。
libp2p作为一种专门为点对点应用设计的模块化、易扩展、集多种传输协议和点对点协议为一体的通用P2P解决方案,具有成为未来点对点传输应用、区块链和物联网基础设施的潜力,它高度抽象了主流的传输协议,使得上层应用开发不必关注底层网络的具体实现,最终实现跨环境、跨协议的设备互联。
本章将介绍用于保证区块链系统一致性的核心算法——共识算法。共识问题在区块链系统出现之前就已经有非常长时间的研究了,传统分布式一致性算法可以解决组织集群部署下由于节点出现宕机错误导致的不一致问题,通常用于多机灾备容错方案,如分布式数据库管理。但是,区块链系统上承载的是价值传输,因此典型的区块链共识算法必须考虑到恶意节点的存在,保证区块链上的价值不会被恶意节点操纵。随着区块链技术的不断发展,区块链共识算法逐渐呈现百花齐放的态势,近年来也出现了许多新型的共识算法,它们大都在前人的研究基础上进行了一定的结合与改良,往往能够很好地解决许多现实中的问题,达到非常好的效果。
共识算法概述
(1)共识问题
共识问题指的是如何让处在分布式系统中的一系列节点就某一个决策达成一致。一个好的共识算法可以让分布式系统中的所有节点运行得像一个节点实体一样,其中每个节点都有完全一致的操作记录。但是,这样一个听起来很简单的问题却成为近几十年来分布式系统理论研究的核心。究其原因,主要可以总结为如下三点。
- 首先,实践证明共识问题是一个难以解决的问题。FLP不可能定理从理论上证明了如果一个分布式系统中存在任意一个故障节点,那么共识问题在异步系统中是不可解的,只有在同步系统中才有解。因此,共识问题的难易程度在很大程度上依赖通信模型中的时序假设。
- 其次,设计一个正确的共识算法是很难的。简单的协议往往不能应付所有场景,如2PC协议、3PC协议,在遇到网络分区之后都无法保证系统的一致性。Chubby的发明者MikeBurrows曾经说过:“只有一种共识协议,那就是Paxos,其他共识协议都是Paxos的变种。”由Leslie Lamport构思的Paxos以设计精妙著称,但是由于其难以理解,因此在很长一段时间里都不曾被人知晓。
- 最后,随着分布式系统的发展,共识算法变得愈发重要。分布式数据库、复制状态机等一系列分布式系统都在极大程度上依赖共识算法。
(2)正确性定义
共识算法的正确性定义如下。
在一个由N个节点组成的分布式系统中,一个正确的共识算法必须满足如下四个特性。
- 一致性(Agreement):所有节点都同意某个决策值,这就要求共同决策的结果是可以被所有结点很容易、不存在分歧地进行快速验证。
- 有效性(Validity):最终决定的决策值必须由这N个节点中的某个节点提出,即共识达成的过程是异步的。
- 终止性(Termination):所有节点最终都能完成决策,即共识达成的步骤一定是有限状态机。
- 容错性:所有节点需要假设网络中存在错误节点的前提下,依然能够达成最终的共识
一致性比较好理解,即如果不同节点最终选定的决策值不一致,那么共识就无法达成。当然,在某些情况下,可以稍微减弱这个条件,即只要系统中大多数(Majority)节点同意某个决策值,就认为共识已经达成了。
有效性可能看起来不太直观,但是如果仅保证一致性,则可能存在如下问题:所有节点最终都会选择一个系统的默认值。例如,在一个数据库提交协议的过程中,如果每次决策都是“不提交”,虽然不会破坏一致性,但是所有合法的事务提交都会被拒绝,这显然是不合理的。
终止性也是一个非常重要的特性。一致性可以定义系统如何选择一个决策值,却没有定义何时进行这样的选择。因此,共识算法需要通过终止性来保证系统始终不停地向前运转,而不是一直停留在一个决策中迟迟无法结束,这样的共识算法是不实用的
最后是容错性,设计一个能够容忍节点出错的共识算法更加困难。事实上,共识问题最典型的应用场景就是容错系统,如状态机复制(StateMachine Replication)问题。容错系统中往往存在一组连续的共识问题,任何一个节点都有可能出现异常,有可能是良性的宕机停止错误(Crash Stop),也有可能是恶意的拜占庭错误(Byzantine Fault),如何保证在存在错误节点的同时达成连续的共识是一个实用的共识算法必须考虑的问题。
(3)通信模型
分布式系统建立在许多通过网络连接或其他方式进行消息通信的节点之上,而网络通信的不确定性会限制共识算法的设计。通信模型定义了不同消息的延迟对于分布式系统的限制能力。总的来说,一共存在三种类型的通信模型,分别是同步模型、异步模型与部分同步模型。
1、同步模型(Synchronous Model)
在同步模型中,所有节点之间的消息通信都存在一个已知的延迟上界∆,并且不同节点处理事务的相对速度差值有一个已知上界ϕ。因此,在同步模型中,每轮共识中的任何一个节点都必须在一定的时间差内执行完成本地事务,并能够在给定时间内向其他节点传输完成任意大小的消息。在同步模型中,任何节点的请求都应该在一个可预估的时间内得到响应,否则,可将对端节点视为故障节点。
同步模型是一个非常理想的通信模型,在现实生活中几乎不可见,但是在分布式系统的理论研究中却发挥着极其重要的作用,许多早期的分布式一致性算法都是在同步模型的假设下设计的。
2、异步模型(Asynchronous Model)
在异步模型中,上述的延迟上界∆与ϕ都不存在,即节点间消息传递的延迟无上界(但是可以保证消息最终能够传递完成),节点的处理速度也未知。
异步模型比较符合现实的互联网环境,节点无响应可能是网络断开造成的,也可能是节点处理速度过慢,无法通过简单的超时检测判断节点是否失效。异步模型与同步模型相比更通用。一个适用于异步系统共识的算法,也适用于同步系统,但是反过来并不成立。
在异步模型中设计一个正确的共识算法已经被证明是不可能的。
3、部分同步模型(Partial Synchrony Model)
部分同步模型是介于同步模型与异步模型之间的一种通信模型,于1988年由Dwork、Lynch、Stockmeyer在论文中提出。
该模型假设存在一个全局稳定时间(GlobalStabilization Time,GST),在GST之前,整个系统可能处于异步状态,即消息的传递无延迟上界,但是在GST之后,整个系统可以恢复到同步状态。然而,该模型中的GST是未知的,即无法预知何时到达GST从而恢复到同步状态。部分同步模型的时序假设比较贴合现实世界中对共识算法的需求,即共识总可以在同步状态下完成,然而一旦网络出现问题,共识可能会进入一段时间的阻塞,直至网络恢复正常。因此,部分同步模型中的共识算法设计首要保证的就是安全性(就算系统进入了异步状态),仅需要在GST之后保证系统的可终止性(活性)。
该模型其实是许多共识算法的模型基础(虽然有些并没有显式地提及),如Paxos、ViewStamp Replication、PBFT共识算法等。
4、共识算法简史
最早的分布式一致性算法可以追溯到Leslie Lamport在1978年发表的论文。虽然在论文中并没有显式地提及一致性的概念,但是Lamport在摘要中明确指出了一种用于定义分布式事件发生前后关系(偏序关系)的算法,该算法最终可用于同步分布式系统的逻辑时钟(也称为Lamport Clock),从而确定系统中所有事件的全序关系。Lamport在论文中通过一个状态机的例子展示了全序关系如何用来解决分布式系统中的同步问题,这也是首篇将同步问题与分布式状态机问题结合到一起的论文,按照Lamport的说法,这篇论文实际上描述了一种如何实现任意分布式状态机的算法,这也正是分布式一致性算法的来源。
同年,JimGray在论文中提出了两阶段提交(2PC),首次尝试解决分布式数据库中的一致性问题,但是2PC存在严重的阻塞问题。
1981年,Dale Skeen在论文中提出了三阶段提交(3PC),可以解决2PC的阻塞问题,但是3PC在发生网络分区时会有严重的不一致问题。事实上,2PC满足了安全性却牺牲了活性,而3PC恰恰相反,它满足了活性却牺牲了安全性。
1982年,Leslie Lamport在论文中提出了著名的拜占庭将军问题,引入了拜占庭错误,将一致性问题的复杂度又提升了一个档次。与此同时,Lamport也给出了两种在同步模型下拜占庭将军问题的解法,虽然此时人们对同步网络与异步网络还没有非常清晰的定义。
直到1985年,Fischer、Lynch和Paterson在论文中提出并证明了FLP不可能定理,直截了当地告诉人们在异步网络中,只要有一个节点出现故障,就不可能存在一种完美的共识算法可以正确地终止。在此后的共识算法设计过程中,人们大都会避开异步网络的假设,但是异步网络才是现实生活中真实的网络模型。
直到1988年,Dwork、Lynch、Stockmeyer在论文中提出了部分同步模型,该模型旨在提出一种介于同步网络与异步网络之间的网络模型。在该模型中,FLP不可能定理的限制可以被部分打破,即当系统处于异步状态时,共识可以阻塞,而现实中总有恢复到同步网络的时候,此时共识就可以继续推进了。
1990年,Lamport在论文中提出了Paxos,这是首次被提出的一个能够在异步网络中保证安全性并在网络进入同步状态后保证活性的共识算法,其后很大一部分共识算法都是Paxos的变体,包括后来的RAFT。但是Paxos最大的问题在于它只能安全运行在非拜占庭网络的环境中,一旦有节点进行恶意攻击,那么整个系统将会崩溃。
1999年,MiguelCastro和Barbara Liskov在论文中提出了PBFT共识算法,该算法大大降低了拜占庭容错算法的网络复杂度,成为第一个实用的拜占庭容错算法。
2008年,中本聪发表了比特币白皮书,首次提出了比特币的概念,同时将PoW共识算法应用到区块链。此后,各类证明类的共识算法相继出现,如PoS、PoA等,共识算法也从传统分布式一致性算法慢慢演化成独特的区块链共识算法。
拜占庭将军问题
1982年,Leslie Lamport、Robert Shostak和Marshall Pease三位科学家发表了论文,该论文提出了著名的拜占庭将军问题。拜占庭将军问题首次假设了分布式系统中存在恶意节点的情况,并给出了在同步模型下的解法(虽然在此之前,同步模型与异步模型还没有明确的定义)。在拜占庭将军问题中,节点不仅会出现宕机或断网等良性错误,还有可能出现任意情况的拜占庭错误。例如,硬件或软件故障导致的节点不按程序逻辑运行,甚至节点程序被人恶意操纵,等等。总之,拜占庭错误更加贴近实际生活中面临的故障模型,也是分布式系统中最难解决的故障模型。
Leslie Lamport、Robert Shostak和Marshall Pease三位科学家在上述论文的摘要中,指出了一个可靠的计算机系统必须能够处理故障组件向其他组件发送不一致消息的恶意情况,并提出了一种更加抽象的描述方式:一组驻扎在敌军周围的拜占庭将军之间如何就攻击还是撤退达成一致。在该假设中,将军们只能通过信使进行沟通。与此同时,将军之间可能存在叛徒,叛徒企图混淆忠诚将军的视线,即向不同将军发送不一样的消息。叛徒的存在使问题变得更加复杂,因为叛徒不仅有可能投反对票,还有可能向不同将军投不一致的票。最终的问题就是在上述假设下,能否找出一种可以保证忠诚将军之间达成一致的算法。该算法需要满足如下两个条件。
- A. 所有忠诚将军最终会同意相同的决策,并且该决策是一个合理的决策。
- B. 少数叛徒不能使忠诚将军最终选择一个错误的决策。
条件A与条件B保证了最终所有忠诚将军行动一致,并且他们的决策不会被少数叛徒影响。
上述条件是站在全局视角来看的,为了简化问题的描述,可以从单个将军的视角进行分析。如果从每个将军的视角来看,都满足如下条件,那么整个系统将按照上述的条件A、条件B进行运转,下面给出拜占庭将军问题在单个将军视角下的描述(司令—副官模型)。假设一共有n个将军,任何一个将军作为司令都必须向其他n-1个副官(将军)发送一条指令,所有将军的行为需要满足两个条件,即
- IC1. 所有忠诚的副官最终会选择相同的指令。
- IC2. 如果司令是忠诚的,那么每个忠诚的副官都必须同意他的指令。
需要注意的是,如果司令是忠诚的,那么显然条件IC2可以推导出条件IC1。但是,司令不一定是忠诚的,如果司令是叛徒,那么所有忠诚的副官也应该协商选择一个相同的指令决策。
最终,Leslie Lamport、Robert Shostak和Marshall Pease给出了两种不同的解法,分别是基于口头消息的协议和基于书面消息的协议。
- 基于口头消息的协议
在基于口头消息的协议中,需要有至少3m+1个将军才能容忍m个叛徒的存在。
首先定义“口头消息”(口头消息协议的网络模型假设)。
- A1. 每个发送出去的消息都能够被成功地传递。 A2. 消息的接收方能准确地知道消息的发送方是谁。
- A3. 消息丢失可以被检测到。
可以看出,上述三点其实定义了一个较为严格的同步网络。A1和A2保证了叛徒不能干扰任意两位将军之间的网络通信。A1保证了叛徒不能干扰消息通道,A2保证了叛徒不能直接伪造其他将军的消息(但是叛徒可以伪造转发第三方将军的消息);A3阻止了叛徒企图通过不发送消息来阻止决策的达成。同时,基于口头消息的协议要求所有将军之间都可以直接发送消息(对应于分布式系统中的点对点网络)。
最终,证明在包含m个叛徒的情况下,至少需要3m+1个将军才能给出一个基于口头消息的解法,具体的算法及证明在此不做赘述,可以通过如下的例子来简单地理解其中的思想。
(1)当一共有n=3个将军时,如果有m=1个叛徒,则问题无解。
如下两个图所示,考虑两种情况,副官是叛徒及司令是叛徒,观察副官1的视角。
① 如果副官(副官2)是叛徒,此时司令发出一条指令(攻击),那么副官1将会收到一条来自司令的攻击指令和一条来自副官2的撤退指令(副官2故意欺骗副官1说自己收到的指令是撤退)。最终,在副官1的视角下,他收到了{攻击,撤退}的指令集合。

② 如果司令是叛徒,此时司令故意向副官1发出攻击指令,向副官2发出撤退指令,随后,副官2如实地将自己收到的指令(撤退)转发给副官1。最终,在副官1的视角下,他还是收到了{攻击,撤退}的指令集合。

上述两种情况中,在副官1的视角下,他收到的始终是{攻击,撤退}的指令集合,因此他无法辨别出到底司令是叛徒还是副官(副官2)是叛徒,这将导致副官1无法做出最终决策,违背了条件IC2(如果司令是忠诚的,那么忠诚的副官必须同意司令的指令)。
(2)当一共有n=4个将军时,如果其中有m=1个叛徒,则问题可解。
如下两个图所示,依然考虑两种情况,副官是叛徒及司令是叛徒。
①如果副官(副官3)是叛徒,此时司令给出一条指令(v),那么副官2将会收到一条来自司令的指令v、一条来自副官1的指令v(副官1如实转发自己收到的指令)、一条来自副官3的指令x(副官3故意欺骗副官2说自己收到的指令是x)。最终,在副官2的视角下,他收到了{v,v,x}的指令集合,由于v有2票,x只有1票,因此副官2可以直接判断出副官3是叛徒,并最终选择指令v作为自己最终的选择。同理,副官1将会做出相同的选择,即指令v,最终司令、副官1与副官2这3位忠诚的将军将会选择一致的指令v(满足条件IC1、条件IC2)。

②如果司令是叛徒,此时司令故意向副官1发出指令x,向副官2发出指令y,向副官3发出指令z,随后,每位副官都如实地转发自己收到的指令给其他两位副官。最终,在任何一位副官的视角下,他们收到的指令集合都是{x,y,z},可以判断司令为叛徒。在司令是叛徒的情况下,所有忠诚副官的行为必然是一致的(满足条件IC1)。由于司令是叛徒,因此无须考虑是否满足条件IC2。

- 基于书面消息的协议
上述第一个例子指出:仅通过口头消息,不存在一个解法使得小于3m+1个将军的军队中能够容忍m个叛徒,此处问题的难点在于叛徒可以伪造第三方将军的消息,从而混淆其他将军的视线。如果能够限制叛徒的这种伪造能力,那么问题就会变得简单,这就是基于书面消息的解法。这里的“书面”指的是所有消息都会带上将军的签字,从而变得不可伪造。对应到实际的计算机系统中,即所有的网络消息都需要带上节点的私钥签名,其他节点可以通过公钥进行验证。具体来说,在基于书面消息的协议中,需要对基于口头消息的协议的网络模型增加一个额外的假设条件。
- A1. 每个发送出去的消息都能够被成功地传递。 A2. 消息的接收方能准确地知道消息的发送方是谁。
- A3. 消息丢失可以被检测到。
- A4.(a)忠诚将军的签名不可伪造,任何对于已签名消息的篡改都可以被检测出;(b)任何人都可以验证将军签名的真实性。
需要注意的是,这里并没有对叛徒的签名做任何假设,即任意叛徒的签名都可以被另外的叛徒伪造,形成叛徒之间的共谋,这是可以容忍的。基于书面消息的协议的本质是引入签名消息,使得所有消息都可以追本溯源。在这种条件下,算法能够处理n
个将军中至多有m个叛徒的情况,其中,n≥m。
FLP不可能定理
1985年,Fischer、Lynch和Patterson三位科学家发表了论文,提出了著名的FLP不可能定理。作为分布式系统领域中最重要的定理之一,FLP不可能定理给出了一个非常重要的结论:在一个异步通信网络中,只要存在一个故障节点,就不存在一种完美的共识算法可以正确地终止。
FLP不可能定理实际上是在一个比异步通信网络更强的通信模型下得出的结论,如果在这样一个更强的通信模型下都无法保证共识算法的终止性,那么在现实中更弱的通信模型下也不可能达到这种保证。FLP不可能定理假设系统中不存在拜占庭错误,并且消息传递是可靠的,即消息传递的延迟未知,但是所有消息最终都会被成功传递且只会被传递一次。也就是说,FLP不可能定理假设网络消息可能出现延迟,但是不会出现丢包、重复包的情况,这是一个比现实网络更可靠的网络假设,但即便是在这种网络假设下,FLP不可能定理也证明了在任意时间停止单个节点进程,会导致任何一个共识算法都无法达成最终一致,更不要说现实网络中还存在网络分区与拜占庭错误等问题了。因此,如果不对通信模型做更进一步的假设,或者对容错类型做更大的限制,那么该问题就不存在一个完美的解决方案。
FLP不可能定理解决了此前五到十年间在分布式系统领域一直存在争议的问题。在此之前,已经有能够在同步网络中解决一致性问题的算法了(如拜占庭将军问题的两种解法),甚至在同步网络中还可以容忍节点出错。事实上,在同步模型中,可以通过等待一段已知的上限时间来检测对端节点是否出现故障,但是这在异步模型中是行不通的。直至FLP不可能定理的出现,才从理论的角度告诉人们可以不用再想方设法地设计一个在异步网络中始终能够达成一致的共识算法。因此,后续的共识算法设计通常会在某些方面做出妥协。例如,网络假设不再是异步模型而是部分同步模型,即允许存在一定时间的异步网络状态,在此期间无法达成共识,但是只要网络恢复到同步状态,就可以立即完成共识,虽然这样对于系统的活性有一定的影响,但是只要能够保证系统的安全性,依然是一个可接受的共识算法。例如,Paxos理论上也会出现活锁,但其能够保证即使出现活锁整个算法也是安全的,那么在实际场景中,只要活锁结束了,就可以继续推进共识了。
CAP理论
2000年,加州大学伯克利分校的Eric Brewer教授在ACM PODC会议上提出了CAP猜想。两年后,麻省理工学院的Seth Gilbert和Nancy Lynch从理论上证明了CAP猜想。此后,CAP理论正式成为分布式领域公认的定理。一个分布式系统最多只能同时满足如下三种特性中的两种。
- 一致性。这里的一致性(Consistency)指的是强一致性(Linearizability Consistency),即一旦完成了一次写操作,那么从任何一个节点处读取出来的结果要么是最新结果(最近一次写的结果),要么读取失败返回错误信息。强一致性是目前能够实现的最高级别的一致性模型,但是它的实现代价通常是非常大的,因此,在实际的工程实践中,通常将其放宽至较弱的一致性,如最终一致性(Eventual Consistency)。
- 可用性。可用性(Availability)指客户端每次的请求都会在一定时间内收到一个有效的响应,即服务一直可用。可用性一直是CAP理论中最有歧义的特性。从工程角度来说,可用性指的是系统能够成功处理请求的比例,或者客户端能够成功收到有效响应的比例。有效响应指的是该响应是正确的且能够在一定时间内返回。从这个角度来说,可用性是系统运行过程中通过人为观测得出的一个指标,因此,不能简单地说某种共识算法是“可用的”还是“不可用的”,只能说系统在一个运行时段内的观测结果是可用的还是不可用的。
- 分区容错性。分区容错性(Partition tolerance)指就算节点之间出现了网络分区问题,系统仍然能够对外提供服务。如果一个共识算法是在假设没有网络分区的情况下设计的,那么一旦出现网络分区,整个系统可能会出现任意错误,违背一致性或失去可用性。例如,RabbitMQ在出现网络分区后,不同的网络分区内可能出现各自的master进行各自独立的读写,此时就算恢复网络,整个系统也将进入不一致的状态。
CAP理论告诉人们,在设计一个分布式系统时,不必奢求同时满足上述三种特性,在实际的工程实践中,必须选择性地做出取舍,才能设计出一个实际可用的、高效的系统。
在分布式系统尤其是区块链系统中,营造一个高可用甚至永远不会出错的网络环境需要付出高昂的代价。因此,区块链系统必须满足分区容错性这一特性。那么对于区块链系统来说,就只能在一致性与可用性之间做出权衡与让步了。
例如,比特币系统中有成千上万的节点运行在世界的各个角落,几乎不可能设计出一个强一致性的共识算法保证所有节点同时对外提供一致的读写服务。因此,比特币系统选择通过牺牲强一致性来满足最终一致性、可用性与分区容错性。尽管比特币网络随时都有分叉的可能,即已经上链的区块有可能被回退,但是随着时间的推移,靠前的区块得到越来越多的确认,其被回退的可能性越来越低,以至于达到一种几乎不可能被回退的最终一致性。在此期间,每个节点都可以正常地对外提供读写服务。
共识算法分类
从传统分布式一致性算法的缓慢发展到现如今区块链共识算法的百花齐放,共识算法的发展已经走过了四十年左右的时光。不同共识算法的侧重点不同,它们所面临的问题、环境也不同。本节将从如下几个角度对共识算法进行分类。
- 容错类型。根据是否能够容忍拜占庭错误,可以将共识算法分为两类。是否能够容忍拜占庭错误标志着该算法是否能够应用到低信任的网络。通常来说,在公有链环境中必须使用拜占庭容错算法,而在联盟链中可以根据联盟参与方之间的信任程度进行选择。
- 拜占庭容错共识算法:PBFT、PoW、PoS、DPoS。
- 非拜占庭容错共识算法:Paxos、RAFT。
- 算法确定性。根据算法确定性,可以将共识算法分为两类。确定性共识指共识决策一旦达成,就不存在回退的可能,这一类共识算法通常是传统分布式一致性算法及其改进版本;概率性共识指已经达成的共识决策在未来有一定的概率会被回退,这个概率随着时间的推移会趋于0,这一类共识算法通常是应用在公有链上的区块链共识算法。
- 确定性共识算法:Paxos、RAFT、PBFT。
- 概率性共识算法:PoW、部分PoS。
- 选主策略。根据选主策略,可以将共识算法分为两类。选举类共识指通过投票选择出块节点,同一个节点可以连续多轮作为出块节点存在,这一类共识算法通常是传统分布式一致性算法及其改进版本;证明类共识指出块节点需要通过某种方式证明自己具备某种能力,从而获得出块权,这一类共识算法通常每轮的出块节点都不相同,从而保证出块权的公平性,通常应用在公有链上。
- 选举类共识算法:RAFT、PBFT。
- 证明类共识算法:PoW、PoS。
分布式一致性算法
分布式一致性算法主要研究在不考虑拜占庭错误,只假设节点发生宕机、网络故障等错误时,如何让多个节点达成一致。比较著名的分布式一致性算法包括:2PC、3PC、Paxos、ViewStamp Replication、Zab、RAFT等。本节主要介绍其中的2PC、3PC、Paxos及RAFT。
(1)2PC
2PC(Two-phase commit),即两阶段提交,是一种在分布式系统中为了协调所有节点进行统一提交或回滚从而保证所有节点在事务提交过程中能够保证一致性的算法,常用于分布式数据库管理。由于2PC能够处理许多临时的系统故障(如进程宕机、网络断开等),因此得到了较为广泛的应用。但是,2PC并不总能成功地恢复系统的故障,在极少数情况下,还是需要人为手动地干预才能补救。
在传统的数据库管理中,完成数据更改称为提交(Commit);撤销数据更改称为回滚(undo),用于保证事务的原子性;重新执行数据更改称为重做(redo),用于保证事务的持久性。单个数据库服务器可以通过事务日志实现回滚与重做,从而保证数据库的ACID特性。但是,在分布式数据库中,不同节点的服务器部署在不同地点,并且服务器之间只能通过网络进行通信,因此需要通过某种协议来协调不同节点进行统一的提交或回滚,这就是2PC设计的初衷。
1、协议流程
顾名思义,2PC将分布式事务的提交分为了两个阶段,分别是投票阶段和提交阶段。同时,为了进行分布式事务的统一调度,2PC中引入了协调者(Coordinator)节点的概念,协调者节点负责向所有参与方(Participants)节点发送统一的决策指令,并收集所有参与方节点的反馈进行下一步决策。2PC假设每个参与方节点都有一个稳定的、带有预写日志(Write-ahead Log)的存储介质,即所有参与方节点都不会无限宕机,宕机重启之后可以从预写日志中恢复正确的状态。
- 阶段一:投票阶段(Vote),投票阶段也称为请求阶段,在该阶段,协调者节点会请求所有参与方节点一致执行最新事务,并同步等待所有参与方节点进行投票表决,协调者节点将根据所有参与方节点的表决结果来决定是否进行后续的提交操作。
- ① 协调者节点向所有参与方节点发送一个包含最新事务的询问提交请求,询问参与方节点是否可以进行最新事务的提交,并等待所有参与方节点的响应。
- ② 参与方节点在收到询问提交请求后,本地执行最新事务(协调者节点询问是否可以提交的事务),并将undo日志与redo日志写入本地的稳定存储介质,但不进行真正的提交。
- ③ 每个参与方节点都根据自身执行情况反馈给协调者节点同意提交响应Yes或终止提交响应No。具体来说,当参与方节点本地执行成功时,反馈Yes;当参与方节点本地执行失败时,反馈No。
- 阶段二:提交阶段(Commit),在阶段二中,协调者节点会根据所有参与方节点的反馈结果决定进入事务提交流程或事务终止流程。
- 事务提交流程。当所有参与方节点的反馈都是Yes时,执行事务提交流程。
- ① 协调者节点向所有参与方节点发送提交请求。
- ② 参与方节点在收到提交请求之后,真正完成事务提交,释放事务期间占用的锁资源。
- ③ 参与方节点在完成事务提交之后,向协调者节点发送Ack响应。
- ④ 协调者节点在接收到所有参与方节点的Ack响应之后,完成事务提交流程。
- 事务提交流程。当所有参与方节点的反馈都是Yes时,执行事务提交流程。
-
- 事务终止流程。当有任何一个参与方节点超时未反馈或反馈为No时,执行事务终止流程。
- ① 协调者节点向所有参与方节点发送回滚请求。
- ② 参与方节点在收到回滚请求之后,根据阶段一中记录的undo日志进行本地事务的回滚,释放事务期间占用的锁资源。
- ③ 参与方节点在完成事务回滚之后,向协调者节点发送Ack响应。
- ④ 协调者节点在接收到所有参与方节点的Ack响应之后,完成事务终止流程。
- 事务终止流程。当有任何一个参与方节点超时未反馈或反馈为No时,执行事务终止流程。
提交阶段也称为执行阶段,在该阶段,协调者节点会根据阶段一中参与方节点的表决结果进行下一步决策。需要注意的是,2PC中并没有假定节点间的消息通信是同步通信,因此,阶段一中有可能出现某些参与方节点反馈超时的情况,而反馈超时不一定表明反馈的参与方节点执行失败,也有可能该参与方节点在本地执行成功了但是在反馈过程中消息传递失败了,而协调者节点为了尽量保证不被一个节点阻塞住,只能假定该参与方节点“执行出错”,从而进入事务终止流程。这是一种比较保守的应对策略,但是也是一种比较安全的策略,因为让执行正确的节点因为某些可能出错的节点进行一次回滚是没有问题的,但是让执行失败的节点因为某些可能成功的节点进行一次提交则是会出错的。
2、优缺点
2PC的优点在于易于理解、实现简单,可以在最优情况下以最小的成本保证数据的一致性,即要么所有节点一起提交,要么所有节点一起回滚。
2PC的缺点也非常明显,具体如下。
- 同步阻塞。在整个事务提交过程中,所有节点都处于阻塞状态,每个阶段都需要等待所有节点的响应,这是2PC的实际效率低的原因。同时,在整个事务提交过程中,所有节点持有的公共资源(如数据库资源)都处于抢占状态,第三方应用想要访问公共资源时会陷入阻塞状态。
- 单点故障。在整个事务提交过程中,协调者节点都是至关重要的,它负责向所有节点统一发送决策指令并收集所有节点的反馈消息,从而推进整个流程的前进。一旦协调者节点不可用,则整个集群将会一直处于阻塞状态,必须等到协调者节点恢复或选举出新的协调者节点才能继续推进。
- 数据不一致。
- 在阶段二中,如果协调者节点因为宕机或网络断开不能够将“提交”请求成功地发送给所有参与方节点,则会导致部分节点在收到提交请求后完成最终提交,而其他节点无法提交的情况。整个系统陷入不一致的状态,必须等到协调者节点恢复或选举出新的协调者节点才有可能重新进入一致的状态。
- 更致命的是,阶段二中出现协调者节点与参与方节点同时不可用的情况。例如,最先收到提交请求的参与方节点在完成提交之后宕机了,那么此时就算协调者节点恢复了或选举出了一个新的协调者节点,协调者节点也无法确定事务提交的状态。系统将进入一个“不确定状态”,必须等待所有的参与方节点都恢复之后,才能确定事务是否真正被提交了。
(2)3PC
2PC的优势在于在最优情况下(没有节点宕机或断网)的系统延迟是非常小的,但是任何一个节点不可用,会导致整个系统超时,从而导致延迟大大增加。
3PC(Three-phase commit),即三阶段提交,通过引入一个新的阶段消除2PC中因为某些节点故障导致的“不确定状态”,因此,3PC是非阻塞的。
1、协议流程
3PC是对2PC的扩展。3PC同样假设每个参与方节点都有一个稳定的、带有预写日志的存储介质,从而保证节点在宕机重启之后可以从预写日志中恢复出正确的状态。相比2PC,3PC主要有以下两个改进点。
- 引入超时机制。在3PC中,协调者节点与参与方节点都有各自的超时器。
- 增加“准备提交”阶段。3PC将2PC的阶段二(提交阶段)分为两个阶段,预提交阶段(PreCommit)与最终提交阶段(DoCommit)。
下面介绍3PC的流程。
- 阶段一:询问提交阶段。3PC的询问提交阶段(CanCommit)与2PC的投票阶段类似,参与方节点根据自身情况反馈Yes或No,但是该阶段参与方节点不执行事务。
- ① 协调者节点向所有参与方节点发送一个包含最新事务的CanCommit请求,询问参与方节点是否可以进行最新事务的提交,并等待所有参与方节点的响应。
- ② 参与方节点在收到CanCommit请求后,判断自身是否准备好了进行最新事务的提交,如果准备好了,则反馈Yes;否则反馈No。
- ③ 参与方节点在反馈响应之后,本地启动超时器等待协调者节点的阶段二请求(预提交或回滚)。
在阶段一中,协调者节点会询问所有参与方节点当前是否可以进行最新事务的提交,并同步等待所有参与方节点进行投票表决,协调者节点将根据所有参与方节点的表决结果来决定是否进行后续的提交操作。
- 阶段二:预提交阶段(PreCommit)。在阶段二中,协调者节点会根据所有参与方节点的反馈结果决定进入事务预提交流程或事务终止流程。需要注意的是,参与方节点在阶段二的事务预提交流程中才会开始真正地执行事务。
- 事务预提交流程。当所有参与方节点在阶段一的反馈都是Yes时,执行事务预提交流程。
- ① 协调者节点向所有参与方节点发送PreCommit请求。
- ② 参与方节点在收到PreCommit请求之后,本地执行最新事务,并将undo日志与redo日志写入本地的稳定存储介质,但不进行真正的提交。
- ③ 每个参与方节点都根据自身执行情况反馈给协调者节点,同意提交响应Yes或终止提交响应No。具体来说,当参与方节点本地执行成功时,反馈Yes;当参与方节点本地执行失败时,反馈No。
- ④ 参与方节点在反馈响应之后,本地启动超时器等待协调者节点的阶段三请求(提交或回滚)。
- 事务终止流程。当有任何一个参与方节点在阶段一超时、未反馈或反馈为No时,执行事务终止流程。
- ① 协调者节点向所有参与方节点发送回滚请求。
- ② 参与方节点在收到回滚请求或等待协调者节点阶段二请求超时之后,根据阶段一中记录的undo日志进行本地事务的回滚,释放事务期间占用的锁资源,完成事务终止。
- 事务预提交流程。当所有参与方节点在阶段一的反馈都是Yes时,执行事务预提交流程。
与2PC的不同点在于,3PC的阶段二中每个参与方节点不是同步阻塞式地等待协调者节点的请求,而是主动地根据自身超时器的情况做出下一个决策。如果按时收到协调者节点的请求,则根据协调者节点的请求进行后续操作;如果超时还未收到协调者节点的请求,则直接终止事务。
- 3)阶段三:最终提交阶段(DoCommit)。在阶段三中,协调者节点会根据所有参与方节点的反馈结果决定进入事务最终提交流程或事务终止流程。只有在事务最终提交流程中,节点才会进行真正地提交。
- 事务最终提交流程。当所有参与方节点在阶段二的反馈都是Yes时,执行事务最终提交流程。
- ① 协调者节点向所有参与方节点发送DoCommit请求。
- ② 参与方节点在收到DoCommit请求之后,真正完成事务的提交,释放事务期间占用的锁资源。
- ③ 参与方节点在完成事务提交之后,向协调者节点发送Ack响应。
- ④ 协调者节点在接收到所有参与方节点的Ack响应之后,完成事务。
- 事务终止流程。当有任何一个参与方节点在阶段二超时、未反馈或反馈为No时,执行事务终止流程。
- ① 协调者节点向所有参与方节点发送回滚请求。
- ② 参与方节点在收到回滚请求之后,根据阶段二中记录的undo日志进行本地事务的回滚,释放事务期间占用的锁资源。
- ③ 参与方节点在完成事务回滚之后,向协调者节点发送Ack响应。
- ④ 协调者节点在接收到所有参与方节点的Ack响应之后,完成事务终止。
- 事务最终提交流程。当所有参与方节点在阶段二的反馈都是Yes时,执行事务最终提交流程。
需要注意的是,在阶段三中,协调者节点有可能出现宕机或网络不可用的情况,从而导致某些参与方节点收到了DoCommit请求,某些没有收到DoCommit请求。对于收到DoCommit请求的参与方节点,可以直接进行本地提交,而对于超时未收到DoCommit请求的参与方节点,也可以继续进行事务的提交。
2、优缺点
3PC的优点在于引入了PreCommit阶段,解决了2PC的阻塞问题,即协调者节点可以在任意时刻发生异常。系统可以选出一个新协调者节点,而新协调者节点总是可以通过询问参与方节点的方式来获知当前系统的状态。
- 若事务在旧协调者节点发生异常之前就已经达到最终提交状态,那么所有参与方节点必然已经接收到PreCommit请求(否则旧协调者节点不可能进入最终提交状态),因此,新协调者节点可以获知当前所有节点已经发送过PreCommit请求,从而继续事务的提交。
- 若事务在旧协调者节点发生异常之前还没有达到最终提交状态,那么某些参与方节点必然还没有接收到PreCommit请求,从而新协调者节点也可以获知当前系统还未达到最终提交状态,可以选择终止提交或重新运行一遍完整的3PC。
但是,在上述场景中,所有参与方节点必须运行正常才能保证新协调者节点可以获知正确的状态。如果出现网络分区,则3PC仍然有可能出现数据不一致的问题。例如,在阶段二中发生了网络分区,所有接收到PreCommit请求的参与方节点处在网络分区1中,所有未接收到PreCommit请求的参与方节点处在网络分区2中,那么网络分区1中的参与方节点最终会因为超时自行进行最终提交,而网络分区2中的参与方节点在阶段二中会因为超时终止事务提交,从而导致整个系统不一致,此时就算网络恢复,新协调者节点也无法确定应该进行事务的提交还是回滚。
(3)Paxos
3PC解决了2PC的主要问题——单点阻塞问题,但是无法解决网络分区带来的数据不一致问题,即3PC保证了系统的活性,但是却牺牲了系统的安全性。与此不同的是,2PC虽然存在阻塞问题,但是在阻塞结束之后,总能恢复系统的一致性,即2PC保证了系统的安全性,但是却牺牲了系统的活性。那么是否存在一个算法能够同时保证系统的安全性与活性呢?答案是肯定的,它就是Paxos。
Paxos是第一个在异步模型下能够保证正确性且容错的共识算法。在此之前,FLP不可能定理明确指出,在异步模型中,只要存在节点故障,就不可能存在一个可终止的共识算法。因此,Paxos也做出了一定的牺牲:Paxos牺牲了一定的活性从而保证了系统的安全性,即在系统处于异步状态时暂停共识的推进,只要有半数以上的节点恢复至同步状态,就可以推进共识,完成终止。
总的来说,Paxos有如下三点特性。
- 安全性(Safety)
- 如果决策已经达成,那么所有节点都会同意相同的决策。
- 最终的决策值必须是由某些节点提出的。
- 无保证的终止性(No Guaranteed Termination)。Paxos不保证收敛到一个最终决策,但只有在非常极端的场景下才会出现。
- 容错性(Fault Tolerance)。可以容忍系统中少于半数的节点宕机,此时其他节点也可以达成一致。
1、协议流程
Paxos代表了一类分布式一致性协议,包括Basic Paxos、Multi Paxos、CheapPaxos、Fast Paxos等协议及其变体。其中,Basic Paxos主要描述了如何就一个值达成一致的决策,而Multi Paxos则针对分布式系统中如何就一系列的值达成一致的决策,RAFT其实是Multi Paxos的一种变体。
本节主要介绍Basic Paxos的协议流程。以下若无特殊说明,Paxos代指Basic Paxos。
Paxos协议流程类似于2PC,但是又存在一些不同点。在Paxos中,存在一个或多个节点同时想要竞选成为协调者节点(也叫作提案者,Proposer)的情况,而每轮共识最终只会选出一个Proposer进行最终提案值的选择。Proposer提出一个决策值,并收集其他参与方节点(也叫作接受者,Acceptor)的投票。最终,Proposer会宣布选定的最终决策值。如果能够达成一个最终决策,则该决策值会被传递到对此感兴趣的节点(也叫作学习者,Learner)中。可以看出,Paxos是一个保证公平性的协议,即所有节点都可以竞选成为Proposer,没有哪个节点拥有特殊的权利。
为了便于理解,本节忽略Learner的存在,仅通过参与共识的Proposer与Acceptor的视角来描述Paxos的共识流程。Paxos分为两阶段共识,如下图所示,分别是准备阶段(Prepare)与接受阶段(Accept)。所有的参与方节点在运行时都必须持久化如下几个值,以保证算法的安全性。
- Na,Va:本节点接受的最大提案号及其对应的值。
- Nh:本节点响应过的最大提案号。
- MYn:本轮共识中本节点提出的提案号。

- 阶段一:准备阶段
- 如果某节点想要发起提案,则直接选定一个提案号MYn(MYn> Nh),并向集群中的大部分节点发送包含MYn的Prepare(N)请求,其中N=MYn。
- 每个Acceptor在收到一条Prepare(N)请求后,首先判断其中的提案号N是否大于本节点响应过的Prepare请求中的Nh。
- ① 如果N≤Nh,则直接发送Propose-Reject拒绝消息给Proposer。
- ② 否则,发送一个承诺响应Promise(Na,Va)给Proposer,并更新Nh=N,承诺本节点不会再接受任何提案号小于N的提案。其中,(Na,Va)是本节点接受的最大提案号及其对应的值,如果本节点未接受过任何提案,则Na与Va均为空值NULL。
- 阶段二:接受阶段
- 如果Proposer收到了大部分(超过半数)节点关于Prepare(N)请求的响应,则Proposer找出这些响应中提案号最大的Promise(Nn,Vn),并向这些Acceptors发送Accept(N,Vn)请求;如果所有节点的响应都是NULL,那么Proposer就任意选择一个本地想要提出的提案值V,向这些Acceptors发送Accept(N,V)请求。
- 当Acceptor接收到一条Accept(N,V)请求时,判断Nh是否大于当前Accept请求的N。
- ① 如果N<Nh,则直接发送Accept-Reject拒绝消息给Proposer。
- ② 否则,发送一个同意响应给Proposer,并更新Na=Nh=N,Va=V。
2、活锁
Paxos看似实现了一个完美的异步共识算法,但是它无法逃脱FLP不可能定理的限制。在若干个Proposer相继提出包含更大提案值的提案时,Paxos有一定的可能性进入活锁(Live Lock)状态,从而无法达成共识。例如,在一个由2个Proposers及3个Acceptors组成的共识网络中。
- Proposer1提出Prepare(N)请求。
- 3个Acceptors都能接收到Prepare(N)请求,从而响应Promise(N)请求并更新本地的Nh=N。
- Proposer1陆续收到来自3个Acceptors的Promise(N)请求并发出Accept(N)请求。
- 但是,3个Acceptors在接收到Proposer1的Accept(N)请求之前先接收到了来自Proposer2提出的Prepare(N+1)请求,从而先响应Promise(N+1)请求并更新本地的Nh=N+1。
- 随后,3个Acceptors才接收到Proposer1的Accept(N)请求,此时本地的Nh已经变成N+1,大于Proposer1请求的N,因此拒绝Proposer1的Accept(N)请求。
- 随后,Proposer1立马提出Prepare(N+2)请求。
- 同样地,3个Acceptors在接收到Proposer2的Accept(N+1)请求之前先接收到了来自Proposer1提出的Prepare(N+2)请求,从而先响应Promise(N+2)请求并更新本地的Nh=N+2。
- 随后,3个Acceptors才接收到Proposer2的Accept(N+1)请求,此时本地的Nh已经变成N+2,大于Proposer2请求的N+1,因此拒绝Proposer2的Accept(N+1)请求。
- 如此往复,可能永远处在这种交替发出提案的循环中无法终止。
由此可见,Paxos仍然无法避开FLP不可能定理的限制,在一定条件下有可能进入无法达成共识的死循环。常见的解决思路是选择一个固定的Proposer,或者给不同的Proposer设置不同的超时时间(如设置为一个随机数)来尽可能减小上述情况出现的可能性,但是在异步网络中依旧无法避免上述情况的出现。
3、优缺点
Paxos相比2PC与3PC的最大优点就在于其同时保证了系统的安全性与一定的活性(最终一致性),Paxos能够达成最终一致性的原因在于其实现了如下两个机制。
- 平等共识与特殊的排序规则:在Paxos中,没有一个节点拥有特权,任何节点都可以主动发起提案,因此一旦Proposer发生故障,另外的节点可以立马接管Proposer的角色。同时,Paxos中特殊的排序规则保证了就算存在多个Proposer同时提出不同的提案值,最后也能收敛到一个最终值。Prepare阶段仅用来确认“提案权”,Accept阶段才确认“最终值”,而这个最终值是目前为止第一个收到大多数节点投票的提案值,不一定是当前Proposer提出的提案值。
- 绝大多数(Majority)共识:Paxos中不再要求每轮共识都等待所有节点的一致投票,而仅需要半数以上的节点投票,因此Paxos也是一个容错的共识算法。同时,由于任意两个“绝大多数共识”之间必然存在交集,因此在不考虑节点作恶的情况下,Paxos在出现网络分区之后依然能够保证系统的安全性。
Paxos在一定程度上给出了一种在异步网络下分布式一致性问题的解决范式,但是其本身的算法过于晦涩难懂,以至于Lamport本人也在Paxos发表之后又写了一篇论文来重新解释Paxos的共识流程。同时,一个Paxos的正确实现被证实是非常有难度的挑战,有兴趣的读者可以阅读Chandra、Griesemer、Redstone的实践论文来理解实现过程中的一些权衡与考量。
(4)RAFT
Paxos诚然是一个非常有影响力的共识算法,可以说奠定了分布式一致性算法的基础,但是由于其难以理解且实现难度大,沉寂了很长一段时间。直到后来Chandra、Griesmer、Redstone将其用到Chubby中实现了一种分布式锁服务,Paxos才渐渐为人所知并名声大噪。直到今天,想要实现一个完整的Paxos依旧非常困难。因此,出现了非常多的Paxos变体,其中最著名的当属RAFT。
RAFT是一种用来管理日志复制的一致性算法,旨在易于理解。它具备Paxos的容错性和性能,不同之处在于它将一致性问题分解为相对独立的三个问题,分别是
- 领导选取(Leader Election)
- 日志复制(Log Replication)
- 安全性(Safety)
这使得RAFT更好理解,并且更容易应用到实际系统的建立中。此外,RAFT还推出了一种新的机制以支持动态改变集群成员。相比Paxos,RAFT有如下几个特性。
- 强领导者:RAFT使用一种比其他算法更强的领导形式。例如,日志条目只从领导者(Leader)发送给其他服务器,从而简化对日志复制的管理。此外,RAFT对Leader(主节点)选举的条件做了限制,只有拥有最新、最全日志的节点才能够当选Leader,这减少了Leader数据同步的时间。
- 领导选取:RAFT使用随机定时器来选取Leader。这种方式仅在所有算法都需要实现的心跳机制上增加了一点变化,使得解决选举冲突更加简单和快速。
- 成员变化(Membership Change):RAFT为了调整集群中的成员关系,使用了新的联合一致性(Joint Consensus)方法,让大多数不同配置的机器在转换关系时进行交叠(Overlap)。这使得在配置改变时,集群能够继续运转。
1、基本概念
在RAFT中,每个节点一定会处于以下三种状态中的一种:
- Leader(主节点)
- Candidate(候选节点)
- Follower(从节点)
在正常情况下,只有一个节点是Leader,剩下的节点都是Follower。Leader负责处理所有来自客户端的请求(如果一个客户端与Follower进行通信,那么Follower会将信息转发给Leader),生成日志数据(对应在区块链中即负责打包)并广播给Follower。Follower是被动的,它们不会主动发送任何请求,只能单向接收从Leader发来的日志数据。Candidate是在选举下一任Leader的过程中出现的过渡状态,任何一个节点在发现主节点故障之后都可以成为Candidate,并竞选成为Leader。
RAFT将时间划分为任意不同长度的term(任期)。任期用连续的数字表示。每个任期的开始都是一次选举。如果一个Candidate赢得了选举,那么它就会在该任期的剩余时间内担任Leader。如果选票被瓜分,没有选出Leader,那么另一个任期将会开始,并且立刻开始下一次选举。
每台服务器都存储着一个数字作为当前任期的编号,这个数字单调递增。当节点之间进行通信时,会互相交换当前任期号,若一个节点的当前任期号比其他节点小,则更新为较大的任期号。如果一个Candidate或Leader的任期号过时了,则会立刻转换为Follower。当一个节点收到过时任期号的请求时,会直接拒绝这次请求。
2、主节点选举(Leader Election)
RAFT使用一种心跳机制(Heartbeat)来触发Leader的选举。当节点启动时,它们会初始化为Follower。若节点能够收到来自Leader或Candidate的有效消息,则它会一直保持Follower的状态。Leader会向所有Follower周期性地发送心跳信息来保证其Leader地位。如果一个Follower在一个周期内没有收到心跳信息,那么它会开始选举,以选出一个新的Leader。
在开始选举之前,一个Follower会自增它的当前任期号,并转换为Candidate。随后,Candidate会给自己投票并向集群中的其他节点发送RequestVote请求。一个节点会一直处于Candidate状态,直到发生下列三种情况之一。
- 它赢得了选举。
- 另一个节点赢得了选举。
- 一段时间后没有任何一个节点赢得选举。
有如下几种情况可能发生:
- 情况1:一个Candidate如果在一个任期内收到了来自集群中大多数(超过一半)节点的投票就会赢得选举。在一个任期内,按照先到先服务原则(First-Come-First-Served),一个节点将选票投给它收到的第一个RequestVote请求相对应的Candidate。大多数原则使得在一个任期内最多有一个Candidate能赢得选举。如果有一个Candidate赢得了选举,则它会成为Leader。然后向其他节点发送心跳信息,从而建立自己的领导地位,并阻止新的选举。
- 情况2:当一个Candidate等待其他节点的选票时,它有可能会收到来自其他节点发来的声明其为Leader的心跳信息。如果这个Leader的任期号比当前Candidate的任期号大,则Candidate认为该Leader合法,并转换自己的状态为Follower。如果在这个Leader的任期号小于Candidate的当前任期号,则Candidate会拒绝该心跳信息,并继续保持Candidate状态。
- 情况3:一个Candidate既没有赢得选举也没有输掉选举。如果许多Follower在同一时刻成为了Candidate,则选票会被分散,可能没有Candidate获得大多数选票。当这种情况发生时,每个Candidate都会超时,并且通过自增任期号和发起另一轮选票请求来开始新的选举。然而,如果没有其他方式分配选票,那么这种情况可能会无限地重复下去。
RAFT采用随机选举超时时间来尽可能地避免情况3的发生。为了防止在一开始选票就被瓜分,选举超时时间是在一个固定的间隔内随机选出来的(如150~300ms)。这种机制使得在大多数情况下只有一个节点会率先超时,它会在其他节点超时之前赢得选举,并向其他节点发送心跳信息。每个Candidate在开始一次选举时都会重置一个随机的选举超时时间,在进行下一次选举之前一直等待。这能够减小在新的选举一开始选票就被瓜分的可能性。
3、日志复制(Log Replication)
Leader一旦被选出,它就开始接收客户端请求。每个客户端请求都包含一条需要被复制状态机执行的命令。Leader把这条命令作为新的日志条目加入日志记录,然后向其他节点广播AppendEntries请求,要求其他节点复制这个日志条目。当这个日志条目被安全复制之后,Leader会将这个日志条目应用到它的状态机中,并向客户端返回执行结果。如果Follower崩溃了或运行缓慢,或者网络丢包了,那么Leader将会无限重发AppendEntrie请求(甚至在它向客户端响应之后),直到所有的Follower最终都存储了所有的日志条目。
在RAFT中,日志如下图所示进行组织。每个日志条目都存储着一条被状态机执行的命令和这条日志条目被Leader接收时的任期号。日志条目中的任期号用来检测不同节点上的日志的不一致性。每个日志条目也包含一个整数索引,来表示它在日志中的位置。
当Leader创建的日志条目已经复制到大多数服务器上时,这个日志条目就称为可被提交的Committed状态(见下图中的7号日志条目)。RAFT保证已被提交的日志条目是持久化的,且最终会被所有可用的状态机执行。Leader跟踪记录它所知道的被提交日志条目的最大索引值,然后将这个索引值添加在之后的AppendEntries请求中(包括心跳信息),从而让其他服务器知道这个日志条目已被提交。一旦一个Follower知道了一个日志条目已被提交,就会将该日志条目应用至本地的状态机(按照日志顺序)。

典型共识算法
前文描述的分布式一致性算法通常基于如下假设:分布式系统中不存在拜占庭节点,即只考虑节点出现宕机、网络故障等问题,不考虑节点篡改数据、向不同节点发送不一致消息等恶意情况。
因此,分布式一致性算法通常被应用在数据库管理中实现多机备份。在实际应用中,这些备份机器往往分布在一家机构的不同机房中,即备份机器之间是相互信任的,不会出现节点作恶的情况。
但是,区块链系统上承载的是价值传输,且参与方的身份多变。在联盟链中可能是多个利益参与方,而在公有链中,则是任意一个可以连入区块链网络的个体,区块链节点完全有可能为了自身利益而发送错误的信息。因此,在设计区块链共识算法的时候,不可避免地要考虑节点作恶的情况,如双花攻击、51%算力攻击等,这种由节点主动发起的恶意行为是典型的拜占庭行为。
在区块链共识算法中,为了应对拜占庭行为,有如下两种不同的解决思路:
- 一种是通过设计在理论上容忍拜占庭错误的共识算法来解决,如经典的PBFT共识算法、新型的HotStuff等
- 一种则是通过增加作恶成本来尽可能避免拜占庭行为。例如,比特币系统中使用的PoW共识算法需要51%及以上的算力才能作恶。拥有51%及以上的算力是很难达到的,并且相比作恶,每个区块的区块奖励也是不菲的,因此绝大多数节点不会想要浪费巨大的资源去作恶,最终保证比特币系统几乎能够完全避免拜占庭行为。
在将共识算法应用到区块链系统中时,通常需要考虑算法实现的复杂度与实用度。在公有链与联盟链的设计中,考虑的侧重点不同,最终的算法选择也有所差异。
- 公有链侧重节点规模与安全性,因此考虑使用证明类共识算法来提升系统的规模,使用经济激励机制来保证系统的安全性
- 联盟链/私有链侧重高性能和低延迟,因此考虑使用确定性共识算法来快速达成最终一致性,并根据需求选择拜占庭容错或非拜占庭容错算法。
(1)PoW共识算法
PoW最早在1993年由Cynthia Dwork与Moni Naor在学术论文中提及,并于同年由Markus Jakobsson与Ari Juels正式提出。起初,PoW主要用于防止垃圾邮件的产生。2008年,PoW作为共识算法应用在比特币系统中。
1、基本概念
数学难题
PoW共识算法设计了一个数学难题(Mathematical Puzzle),要求节点在生成新区块之前,需要消耗一定的计算资源才能获得难题的解,从而将区块广播到网络,并且其他节点可以轻易验证这个解的有效性。
哈希算法
哈希算法(Hash Algorithm)是一种能够把任意长度的输入变换成固定长度的输出的算法,记为y=Hash(x),不同的输入x得到的输出y各不相同。除此之外,在已知x时可以快速计算得到y,但是在已知y的情况下,通常只能通过穷举法才能逆推出x。
由于哈希算法具有正向快速、逆向困难的特性,因此常使用哈希算法来设计PoW共识算法的数学难题。
挖矿与矿工
在一轮区块生成中,系统通过对输出值设定条件来调整数学难题的难度,节点在成功解出难题且通过验证上链后,将会获得相应的比特币奖励。这个过程被形象地称为“挖矿”(Mining),而参与挖矿的节点被称为“矿工”(Miner)。
2、共识流程
在生成新的区块之前,PoW共识算法会预设目标值htarget,要求矿工计算出的哈希值小于该目标值,以此来表示PoW共识算法的难度。为了生成区块并获得比特币奖励,矿工首先收集一组交易打包成一个区块,并尝试解决数学难题进行挖矿。在此期间,矿工需要生成随机数nonce,同当前区块数据datacurrent与上个区块的哈希值hprev进行多轮哈希计算,当前区块的哈希值hcurrent为
 直到当前区块哈希值hcurrent满足条件
直到当前区块哈希值hcurrent满足条件

此时的nonce为本次数学难题的解,矿工将作为区块头数据加入当前区块,如下图所示。然后将该区块广播到区块链网络,等待验证通过后,矿工就可得到相应的比特币奖励。

htarget越小,PoW共识算法的难度越大,生成满足要求的区块难度越高。通过调整区块难度,可以控制节点生成区块的大致时间,从而要求节点达到一定的工作量。
在比特币系统中,所有节点同时挖矿,最先计算出有效区块的节点将获取记账权,可以将区块加入网络。但是,系统内存在传播延迟,如果生成区块的速率过快,可能会使部分节点在没有收到最新区块消息的情况下,同时完成区块计算,生成多个有效区块,从而导致区块链产生分叉(Fork),如下图所示。

网络传输存在延迟,区块的生成速度越快,在同一时刻生成多个有效区块的概率越大,区块链产生分叉的可能性越高。这不但浪费计算资源,还使系统更容易被攻击。在最初的设计中,为了在保障一定交易吞吐量的同时降低分叉的概率,比特币限制矿工生成区块的平均时间在10分钟左右。PoW共识算法的难度会根据当前区块的生成情况进行调整,将生成区块的平均时间控制在10分钟左右。
3、最长链原则
上文提到,当有多个矿工同时生成新区块,并在网络中广播时,区块链会产生分叉。如果发生了这种情况,通常以最长链原则来应对,即选择一条最长的链作为主链,矿工挖矿与数据同步都以最长链为标准。如果存在长度相同的链,那么就从中随机选取一条进行挖矿。
如下图所示,当区块链产生分叉时,逻辑上会形成两条子链:A—B—C—D1—E,A—B—C—D2。矿工在生成新区块时将选取其中一条进行挖矿,在完成挖矿后会产生一条最长链。此时,A—B—C—D1—E将作为主链,A—B—C—D2会被舍弃,D2中的交易将被回滚,重新放回交易池,等待重新被打包。

最长链原则作为识别主链的方式,被大部分共识算法采用,如PoW、PoS、DPoS等,都将最长链作为主链,信任其中记录的数据。
在比特币系统中,交易即使被打包进一个区块,也有可能产生分叉,导致交易被回滚,因此通常需要等待额外几个区块生成以后,才可以认为当前交易已经不可回滚,进入相对确定的状态。一般来说,在连续生成六个区块后,第一个区块里的交易就很难被篡改,可以被认为完成确认,所以一笔交易在比特币系统中的确认时间大约为1小时。
4、算法应用问题
51%攻击问题
在比特币最初的设计思路中,中本聪计划使用一CPU一票的机制实现公平的去中心化决策。对于使用PoW共识算法的区块链系统来说,保证去中心化的方式就是将算力分散到所有参与方手中,每个参与的矿工都有生成新区块的机会。而单个节点的算力有限,其生成区块的速度无法超越整体,也就无法破坏区块链系统,攻击者也就无法通过注册多个账号来提高自己完成挖矿的效率,从而有效地抵抗女巫攻击,保证去中心化决策的正常进行。
但是,如果攻击者掌握的算力超过系统整体的一半,就可能垄断区块的生产,从而掌握整个系统,这就是51%攻击(51% Attack,Majority Attack)。攻击者可以主动对区块链进行分叉,并忽略其他矿工生成的新区块。由于其算力占系统的绝大部分,因此攻击者生成区块的速率更快,最终攻击者生成的区块链长度会超过正确的主链长度。按照最长链原则,攻击者生成的区块链会作为主链,而真正的主链会被拒绝。
不过,51%攻击并不是一种经济的做法,它需要攻击者付出大量的算力成本,并且在51%攻击行为被发现后,有可能会引发整体币值下降,从而导致财产缩水,增高发起攻击的代价。
算力集中问题
随着计算机技术的进步,挖矿手段也产生了很大的变化,大致经历了CPU挖矿、GPU挖矿、GPU集群挖矿、FPGA矿机、ASIC矿机、矿池(ASIC集群)阶段,GPU运算能力是CPU的几百倍,FPGA是GPU的数十倍,ASIC是FPGA的数千倍,多个ASIC矿机又可以组成矿池。
单个节点的算力飞速提升,需要使用更加专业化的设备才能有效参与挖矿竞争。这使得挖矿的成本提高且难以控制,只有计算资源高度集中的矿池才能负担得起这种成本投入。如下图所示,世界上规模排名前五的矿池掌握的计算资源占据全部比特币网络计算资源的一半以上。计算资源的集中,导致理想状态下的去中心化形式越来越难以满足,PoW共识的公平性、去中心化程度开始被破坏。

资源消耗问题
在一轮挖矿过程中,矿工需要消耗大量的资源来解决数学难题,但是,这些数学难题除了满足PoW共识算法的要求,对于其他领域没有太多价值。加密货币信息网站Digiconomist的数据显示,截至2017年,我国投入到比特币和以太坊挖矿的电力已经超过约旦、冰岛、利比亚等国家,在所有国家和地区电力消耗中排名第71位,造成了巨大的资源浪费。
吞吐量问题
使用PoW共识算法的系统,为了尽可能降低分叉概率,区块生成速率相对较慢,交易确认时间较长。在比特币系统中,平均需要10分钟才能完成出块,并经过约1小时才能完成交易确认,交易吞吐量非常低,很难满足实际应用需求。
(2)PoS共识算法
区块链共识算法可以被看作一种选举机制,通过集体参与的方式选出领导者,由领导者进行本轮区块的生成,从而避免单个用户或集团长期控制账本,并维持区块链系统整体的一致性。
前面提到的PoW共识算法是通过算力来争夺领导者资格的,但是PoW过程中的大量资源浪费,导致其很难被更大规模的应用接受。对此,有人开始尝试直接使用“股份”(Stake)作为标准进行领导者资格的竞选,并随之产生了权益证明(Proof of Stake,PoS)共识算法。
PoS的思想起源于企业的股份制:一个人拥有的股份越多,其获得的股息和分红就会越高。如果区块链系统也采用这种方法进行维护,则不需要过多的资源消耗,也能够使区块链资产有自然的通胀。节点通过投入一定量的虚拟货币参与共识,根据持币情况获得打包新区块的权利,并获得奖励。
1、基本概念
验证者
在PoS共识算法中,将参与共识的节点称为验证者节点(Validator)。任何拥有虚拟货币的节点都可以通过发送特殊交易的方式,将部分虚拟货币转为“股份”,从而成为验证者节点。完整的验证者节点集合(Validator Set)由区块链系统负责维护。
币龄
为了描述持币情况,PoS共识算法引入了“币龄”的概念。币龄(Coinage)表示节点持有部分虚拟货币的时长,当节点将虚拟货币作为股份投入后,这部分虚拟货币就开始积累币龄,币龄的计算方式如下

在使用了这部分虚拟货币后,无论是用来进行区块生成还是简单的交易,这部分虚拟货币对应的币龄都将被销毁。在最初的PoS共识算法中,币龄是进行评判的重要标准,节点在区块生成时所使用的币龄越大就越容易生成区块,如点点(Peercoin),这可以在一定程度上制约短期投机行为。
2、共识流程
PoS共识算法在进行区块生成时,将同时考虑币龄与哈希计算难度,使得节点只需要消耗很少的计算资源就可以完成区块生成,流程如下。
与PoW共识算法类似的是,PoS共识算法同样需要生成随机数nonce,同当前区块数据datacurrent与上个区块的哈希值hprev进行多轮哈希计算,得到当前区块哈希值hcurrent,使计算的结果满足难度要求。
与PoW共识算法不同的是,PoS共识算法的难度要求加入币龄的影响,只要计算得到的结果满足如下条件,就可以完成区块生成

在这种情况下,节点更容易获得满足需求的哈希值,拥有币龄越高的节点越容易获得区块,从而节省这部分计算资源的支出。在区块生成时,这部分币龄对应的货币会随之广播到全网进行验证。在通过验证后,这部分货币将被赎回,同时对应的币龄归零,出块者也会获得一定的奖励。
3、与PoW共识算法相比的优势
PoW共识算法需要消耗大量的资源进行算力认证,以此来保证区块链系统的安全性,以太坊与比特币作为PoW共识算法最常见的应用,每天需要消耗大量电力用于完成共识,这部分资源除了完成共识任务,并没有其他贡献,无疑是巨大的资源浪费。而PoS共识算法的出块权取决于验证者节点拥有的股份,并不需要节点支付过多的算力,更加经济。
4、实际应用问题
Nothing at Stake
Nothing at Stake(无利害关系,[email protected])问题[17],本质为“无成本作恶”问题。在PoW共识算法中,节点需要花费算力来争取出块机会,如果产生了分叉,则无法分出多余的计算资源在多个链上出块,只能选择自己认可的链进行挖矿,也就能够在有限时间内决出最长链,从而达成区块链节点之间的共识。而在PoS共识算法中,如果产生了分叉,则节点可以在无任何损失的情况下同时为多条链出块,从而获得所有收益,整个系统可能无法达成共识。
由于无法对分叉进行有效制约,因此无利害关系问题会让双花攻击变得更加容易。在PoW共识算法中,节点需要获取51%及以上的算力才有可能对系统发起攻击。而在PoS共识算法中,攻击者只需要支付很少的算力就可以生成区块,轻易地对区块链进行分叉,并利用无利害关系问题达成双花攻击的目的。
Long Range Attack
Long Range Attack(长程攻击)指的是从创世区块开始,创建一条比当前主链还要长的区块链,并篡改交易历史,用它来代替当前主链。因此,长程攻击也被称为历史覆盖攻击。
新节点或长期离线的节点在同步新的区块数据时,并不能清楚地分辨出主链。而且在PoS共识算法中,区块的生成与计算资源关系不大,节点可以通过某种方式篡改历史区块,私自制作一条最长链。根据最长链原则,很有可能出现真正的主链被替代的情况,典型的长程攻击共有三种。
- 简单攻击(Simple Attack),指的是攻击者通过缩短区块生成时间,从而在单位时间内尽可能多地在分叉链上生成区块,以此超过原主链长度发起攻击。这种攻击行为相对简陋,可以通过查询异常时间戳进行过滤。
- 变节攻击(Posterior Corruption),指的是分叉链验证人通过获得旧验证人的私钥,在分叉链上加速完成超过主链长度的一种攻击方式。发展较长的区块链项目,可能已经更换了几轮验证人,旧验证人的私钥依旧可以签署以前的旧区块,分叉链验证人通过购买、行贿或破解的方式获得旧验证人的私钥,从而签署合理的区块,达到加速的目的。
- 权益流损(Stake Bleeding),指的是分叉链验证人通过延长在主链的区块生成时间,同时通过累计分叉链权益,以加快分叉链出块速度的攻击方式。一般分叉链上的验证人也是原主链上的验证人,当验证人在原主链上获得出块机会时,验证人会通过某种方式延迟出块或不出块,为分叉链争取出块时间,从而逐渐超过主链长度。
冷启动问题
由于PoS共识算法中币龄越大的节点越容易获得记账权,所以参与方节点更希望囤积更多的代币,而很少进行交易,这就造成了纯粹的PoS公有链系统无法进行冷启动。因此,在实际运行时,一般采用PoW共识算法启动整个区块链系统,再切换到PoW+PoS方式,最后才使用纯粹的PoS共识算法运行系统。
目前,以太坊正处于由PoW共识算法向PoS共识算法转型的阶段。
(3)DPoS共识算法
在委托权益证明(Delegated Proof of Stake,DPoS)共识算法中,持币者通过选举产生代表,由代表进行直接的区块生成,持币者通过选举代表间接行使竞争出块的权利。DPoS共识算法实际上通过一系列选拔规则对候选人进行制约,并制定一套投票规则。普通参与方节点通过投票的方式从候选人中选举见证人,并由见证人进行出块,不满足要求的见证人将被取消权限,并重新选举产生新的见证人。
DPoS共识算法保留了一定的中心化特性,因此能够保证高效率的交易吞吐,速率可以比肩常见的中心化机构,如Visa、Mastercard等。在该共识算法中,去中心化特性主要体现在对于生成区块的权利可控方面,即股东通过投票,选择自己信任的代表节点,并由代表节点进行区块链数据的维护。
1、基本概念
候选人
只要满足了基本条件,就可以成为候选人,
参与见证人竞选,申请成为候选人需要遵循一定的规则。在竞选见证人之前,候选人需要注册独有的身份,这个身份将被用于节点选举。在与身份信息相关的结构中,将保留个人的状态信息及详细介绍,以供投票人参考。
投票人
只要节点持有货币,就可以作为投票人。
根据自身设置的条件向自己认可的候选人投票。
见证人
见证人(Witness)为直接负责区块链维护的节点,通常具有以下特征:
- 能够直接生成和广播区块
- 能够收集网络中的交易并打包
- 能够对区块进行签名
见证人的位置由上个区块的最后部分随机指定。
受托人
在早期的DPoS项目BitShares中,还有受托人(Delegates),其主要功能为维护系统各项参数,如打包区块的时间间隔等。在后期的DPoS项目EOS.io中,只保留了能够生成区块的见证人。无论是见证人还是受托人,都是由投票人投票产生的,而系统的去中心化,也是由这种投票机制进行体现的。
2、共识流程
DPoS共识算法的共识流程,实际上就是选举出见证人,并由见证人轮流进行区块生成的循环流程。投票人可以适时更新自己的选票,然后在每轮循环中,区块链系统都会重新统计候选人得票,并选择出N个见证人。把见证人的排序打乱后,见证人轮流生成区块,在一个生产周期结束后,进入下一个生产周期,重新进行见证人选举。
候选人注册
候选人注册时,需要提供必要的信息标识。信息标识是否在线,如果已经下线,则不再计算票数,在这种状态下即使收到选票,在重新登入时也不会被统计在内;提供接口,使得外界可以获取到当前候选人的状态。其中,候选人需要提供个人介绍、网站等额外信息,以供投票人参考。
此外,候选人在注册时,需要支付一定的注册费用,一般这笔费用为生成单个区块平均奖励的上百倍。由于需要支付高额的注册费用,因此候选人在成为见证人后,通常需要生成上千个区块才能达到收支平衡,这防止候选人不认真履行维护区块链数据的责任。
投票
为了对候选人进行投票,每个投票人都会记录部分必要的信息,包括可信代表、非可信代表等。
- 可信代表(Trusted Delegates)用于记录投票人信任的代表节点
- 非可信代表(Distrusted Delegates)用于记录投票人不信任的代表节点
投票人在进行投票时,会从尚未成为见证人的可信代表中,选择最有可能成为见证人的投出支持票;或者从已经成为见证人的非可信代表中,选择其中一个进行反对。此外,投票人还会根据候选人成为见证人后的表现对其评分,维护可见代表(Observed Delegates)列表,统计分数进行排名。对于一个DPoS区块链系统,由系统负责记录当前见证人的顺序,后续每轮区块产生的顺序都与此相关。同时,社区会维护当前候选人的排名(Ranked Delegates),这个排名根据每个候选人收到的投票情况产生。
区块生成
区块链系统的所有参与方都可以查询到当前的见证人顺序,每当候选人的排名更新时,见证人列表也会随之更新,并在更新后进行乱序。根据当前的见证人顺序及当前时间,可以计算每个见证人生成下一个区块的时间表。当达到某个时刻时,对应的见证人进行区块签发,其他节点也可以根据这个时间表进行验证,区块生成时间的计算过程大致如下。
- 根据UTC时间与区块生成间隔,计算当前时间:

- 根据当前时间,计算当前轮次:

- 根据当前轮次、当前代表的位置(RANK)、区块生成间隔,计算区块生成时间:

- 如果计算得到的区块生成时间小于当前时间,那么通过再增加一轮时间间隔,计算区块生成时间:

- 当区块有效性验证通过后,该区块将加入区块链,代表节点将获取相应的手续费。
3、同PoW共识算法和PoS共识算法的关系
由于挖矿对于算力的要求,因此以PoW共识算法运行的系统,加入矿池才是普通用户参与挖矿最保险的方式。在这种运行方式中,散户矿工类似DPoS共识算法中的投票人,矿池的运营者类似见证人,通过这种方式组织起来的区块链维护模式,就是一种类似DPoW共识算法的共识形式。
在当前的运营模式下,如果存在系统的管理者,其更希望用户能够在矿池间切换以保证系统不过度中心化,这种方式类似选票的切换。然而,较大的矿池已经拥有了超过10%的算力,前五名的矿池已经控制了整个网络。如果其中任何一个矿池出现问题,区块生成效率就会瞬间下降,并且需要手动干预对其中的用户进行切换或恢复,系统维护相对困难。
而在PoS系统中,如果希望更高效率地进行区块维护,参与挖矿的节点可以选择委托制的方式,集合更多的股份来争取打包区块的机会,从而共同获取更多的手续费。
因此,DPoS共识算法的设计者认为,从规模化角度看,PoW共识算法与PoS共识算法都有走向委托制的倾向,存在中心化风险。因此,在系统建设初期就设计好如何进行权益分配与权利制约,有利于用户更好地控制系统,从而避免被动演化导致的不可预期的结果。
4、实际运行时的问题
采用DPoS共识算法的区块链系统,如EOS.io、BitShares,能够达到上千级甚至上万级的交易吞吐量,满足绝大部分日常应用的需求。但是,这种运行方式在诞生之初就在一定程度上削减了去中心化程度。在实际运行过程中,许多投票人并没有履行投票的职责,从而造成这种运行方式的中空。
(4)PBFT(实用性拜占庭容错,Practical Byzantine Fault Tolerance)共识算法
上述提到的共识算法大多用于公有链场景。例如,应用了PoW、PoS共识算法的系统,其由于交易吞吐量普遍较低及交易确认延迟较高等问题,无法在实时性要求较高的场景中使用。
在企业级场景下,节点数量不会非常多,但是对于交易吞吐量及最终确定性要求较高,因此常用联盟链来进行建设,从而满足企业级需求。
在实际应用场景中,根据不同的需要可以选择不同的共识模型。
- 在拜占庭的联盟链环境下,可以优先考虑使用PBFT共识算法及其变体
- 在信任程度比较高的环境下,如果不考虑拜占庭容错,则优先考虑RAFT、PBFT等确定性共识算法,其优势在于在算法层面保证了交易的最终确定性,即已经提交的交易不存在回退的可能。
- 此外,PBFT等确定性共识算法的交易交易吞吐量通常远高于证明类共识算法,因此非常符合联盟链高交易吞吐量、低延迟的需求。
实用性拜占庭容错(Practical Byzantine Fault Tolerance,PBFT)共识算法是一种在信道可靠的情况下解决拜占庭将军问题的实用算法。
拜占庭将军问题最早由Leslie Lamport等在1982年发表的论文中提出,论文中证明了在将军总数n大于3f,叛徒为f或更少时,忠诚的将军可以达成命令上的一致,即n≥3f+1,算法复杂度为O(nf+1)。随后,MiguelCastro和Barbara Liskov在1999年发表的论文中首次提出了PBFT共识算法,该共识算法的容错数量也满足n≥3f+1,算法复杂度降低至O(n2)。
1、基本概念
最大容错节点数
在前面的章节中,我们已经对拜占庭将军问题进行了讲解。PBFT共识算法同样需要遵循这个基本要求:在节点总数为n的集群中,为了保证在有最多f个拜占庭节点时共识算法的活性与安全性,需要满足关系n≥3f+1。在一轮共识过程中,可能会有f个拜占庭节点故意不响应,为了满足算法活性的要求,我们需要在收到最多来自n-f个节点的响应后做出判断。不过,当我们收到n-f条响应时,实际上无法判断其他f个节点是否为拜占庭节点,因此在收到的响应中,依然可能包含最多f个拜占庭节点的响应。为了满足算法安全性的要求,我们需要保证:在收到的响应中正确节点响应的数目应当高于拜占庭节点,即n-2f≥f。
综上所述,我们可以获得节点总数与拜占庭节点数目上限的关系:n>3f,即n≥3f+1。
quorum机制
在明确最大容错节点数与节点总数的关系后,我们需要关注PBFT共识算法中另外一个重要的概念——quorum机制。这是一种在分布式系统中常用的,用于保证数据冗余和最终一致性的投票机制,其主要数学思想源于鸽巢原理。
为了更好地理解quorum机制,我们先来了解一种与之类似,但是更加极端的投票机制——WARO(Write All Read One)机制。在使用WARO机制维护节点总数为n的集群时,节点执行写操作时的quorum值应当为n,而执行读操作时的quorum值可以设置为1。也就是说,在执行写操作时,需要保证全部节点完成写操作才可视该操作为完成,否则写入失败;相应地,在执行读操作时,只需要读取一个节点的状态,就可以对该系统状态进行确认。
我们可以看到,使用WARO机制的集群在执行写操作时非常脆弱:只要有一个节点写入失败,这次操作就无法完成。不过,WARO机制牺牲了写操作的可用性,使读操作变得简单。
quorum机制就是对读写操作的折中考虑。在有冗余数据的分布式存储系统中,冗余数据对象会在不同的机器之间存放多份副件。但是在同一时刻,一个冗余数据对象的多份副件只能用于读或写操作。quorum机制可以保证,同一份冗余数据对象的每份副件都不会被超过两个访问对象读写,具体读写策略如下。
分布式存储系统中的每份冗余副件都被赋予了一票,假设系统中有V票,也就意味着一个冗余数据对象有V份冗余副件,每个读操作获得的票数必须大于最小读票数Vr(readquorum)才可以成功读取,每个写操作获得的票数必须大于最小写票数Vw(writequorum)才可以成功写入。那么,最小读写票数应满足如下限制

- Vr+Vw>V保证了一个冗余数据不会被多个访问对象同时读或写。当一个写操作请求传入时,它必须获得Vw个冗余副件的许可,而剩下的数量是V-Vw,小于Vr,因此不会再处理读操作请求。同理,当读操作请求已经获得了Vr个冗余副件的许可时,写操作请求就无法获得许可了。
- Vw-V/2保证了数据的串行化修改,一份冗余副件不可能同时被两个写操作请求修改。
通过上面描述的两种最小票数关系,我们可以计算出系统正确完成某项工作时所需节点数目的最小值,也可以称为quorum值,从而让分布式存储系统能够正确运行。
那么,在PBFT这类拜占庭容错共识算法集群中,要怎样确定quorum值的大小呢?
PBFT共识算法所要做的就是在容纳一定拜占庭节点的同时,对分布式集群进行写操作,因此,这里主要考虑的是最小写票数的计算,PBFT共识算法中的quorum值通常也指最小写票数。
假设,集群中有n个节点,其中有f个错误节点,写票数设置为m。在进行共识时,我们能够保证,在全部节点中,一共有n-f个节点的行为正常;同样地,当节点收到m条响应时,我们只能够保证其中有m-f条响应来自正常节点。将前面最小写票数的限制Vw-V/2类比到PBFT共识算法集群中,为了保证正确节点的写操作串行,可以求出写票数的要求

在实际进行共识时,为了进一步提高共识效率,加快写操作执行速率,可以取用最小值 作为写票数,可以更快地完成写票数的共识。
作为写票数,可以更快地完成写票数的共识。
当然,为了集群不会因为节点拒绝响应而不能运行,保证系统的活性,写票数还需要满足一定的上限要求:m≤n-f。可以验证,当节点总数满足拜占庭容错的条件n≥3f+1时,最小写票数的取值也能满足这一上限要求。
在一些场景下,根据实际需要,我们也可以牺牲一些共识的性能,取其他满足上下限要求的数值作为写票数,如直接使用n-f。
为了表达简洁,后文将直接以节点总数为3f+1的场景对PBFT共识算法进行描述,在该场景下,quorum值取2f+1即可满足最小写票数的要求。
节点角色与视图
在PBFT共识算法中,主要存在两种节点角色,分别为主节点与从节点。在每轮共识过程中,主节点将起引导作用,并在从节点的共同参与下完成三阶段的共识流程。
主节点不是一成不变的,集群整体会在一系列的主从配置中进行连续切换,其中,每轮主从配置都被称为视图(view),并对应一个视图编号,通常记为v。
在PBFT共识算法中,每个节点都会被分配一个序号,如果系统一共由m个节点组成,系统整体从0开始编号,那么集群编号可以记为 。
。
当处于视图v时,主节点编号的计算方式为 。
。
例如,当前一共有4个节点,序号分别记为0、1、2、3,当视图v=31时,主节点序号为3,也就是第四个节点。
共识通信
在PBFT共识算法集群中,节点在发送消息时会附加自身的签名,保证该消息的来源可信。在进行点对点消息传递时,双方会进行会话密钥协商,保证点对点通信的安全性。
2、共识流程
PBFT共识算法的共识流程主要有以下三步。
- Step1:请求阶段。客户端发送请求到主节点,或者通过从节点转发到主节点。
- Step2:共识阶段。集群执行PBFT共识算法的核心共识流程。
- Step3:执行阶段。节点确认共识完成并执行请求,将执行结果反馈给客户端。
对客户端来说,在收到来自f+1个不同节点的相同执行结果后,确认共识已经正确完成,并将该执行结果确认为操作结果。
核心共识流程
下面介绍PBFT共识算法的核心共识流程,如下图所示。

在请求阶段,客户端发起请求,主节点在收到客户端的请求后,触发核心共识流程。
PBFT共识算法的核心共识流程分为三个阶段:
- pre-prepare阶段
- prepare阶段
- commit阶段
其中,节点在prepare阶段和commit阶段各进行了一轮投票,分别对消息的合法性与待执行进行了确认。在上图中,c代表客户端,0、1、2、3代表节点的编号,在视图为0(v=0)的情况下,节点0是主节点,节点1、2、3为从节点。打叉的节点3代表拜占庭节点,这里表现的恶意行为就是对其他节点的请求无响应。
核心共识流程如下。
- pre-prepare阶段:
- 主节点在收到客户端的请求后,主动向其他节点广播pre-prepare消息,其中,v为当前视图编号,n为主节点分配的请求序号,D(m)为消息摘要,m为消息。在主节点完成pre-prepare消息的广播后,主节点对于该请求进入pre-prepared状态,表示该请求已经在主节点处通过合法性验证。
- 从节点在收到pre-prepare消息之后,对该消息进行合法性验证,若通过验证,则该节点对于该请求进入pre-prepared状态,表示该请求在从节点处通过合法性验证。否则,从节点拒绝该请求,并触发视图切换流程。一种典型的从节点拒绝的情况是,v和n曾经出现在之前收到的消息中,但是对应的消息摘要D(m)却和之前的不一致,或者请求编号不在高低水位之间,这时候从节点就会拒绝该请求。
- prepare阶段:当从节点对于该请求进入pre-prepared状态后,向其他节点广播prepare消息,其中,v为当前视图编号,n为主节点分配的请求序号,D(m)为消息摘要,i为当前节点的标识。如果节点对于该请求进入pre-prepared状态,并且收到2f条来自不同节点对应的prepare消息(包含自身发出的),那么该节点就对于该请求进入prepared状态。其中,pre-prepared状态对应的pre-prepare消息可以视为主节点对该请求的合法性验证,它与另外2f条prepare消息一同构成了大小为2f+1的合法性验证集合,表示该请求已经在全网通过合法性验证。
- commit阶段:实际上,如果不考虑视图变更的问题,当请求在全网通过合法性验证,即该节点对于该请求进入prepared状态后,该请求就在当前视图中确定了执行顺序,可以执行。但是,如果发生视图变更,则只通过pre-prepare、prepare阶段不足以对视图变更过程中的交易进行定序(在视图变更时,节点有可能会获取到来自不同视图但拥有相同序号的不同消息)。因此,PBFT共识算法中额外增加了commit阶段对请求的执行进行验证,确保已经执行的请求在发生视图变更时能够在新视图中被正确保留。在当前节点对于该请求进入prepared状态后,当前节点会向其他节点广播commit消息
 ,其中,v为当前视图编号,n为当前请求序号,i为当前节点标识。如果当前节点对于该请求进入prepared状态,并且收到2f+1条来自不同节点对应的commit消息(包含自身发出的),那么当前节点就会对于该请求进入committed状态,并执行。执行完毕后,节点会将执行结果反馈给客户端进行后续判断。
,其中,v为当前视图编号,n为当前请求序号,i为当前节点标识。如果当前节点对于该请求进入prepared状态,并且收到2f+1条来自不同节点对应的commit消息(包含自身发出的),那么当前节点就会对于该请求进入committed状态,并执行。执行完毕后,节点会将执行结果反馈给客户端进行后续判断。
上述就是PBFT共识算法的核心共识流程。
checkpoint机制
PBFT共识算法在运行过程中会产生大量的共识数据,因此需要执行合理的垃圾回收机制,及时清理多余的共识数据。为了达成这个目的,PBFT共识算法设计了checkpoint流程,用于进行垃圾回收。
checkpoint即检查点,是检查集群是否进入稳定状态的流程。在进行检查时,节点广播checkpoint消息,n为当前请求序号,d为消息执行后获得的摘要,i为当前节点标识。当节点收到来自不同节点的2f+1条有相同<n,d>的checkpoint消息时,认为当前系统对于序号n进入了稳定检查点(stable checkpoint)。此时,将不再需要stablecheckpoint之前的共识数据,可以对其进行清理。
不过,如果为了进行垃圾回收而频繁执行checkpoint,那么将会对系统运行带来明显负担。所以,PBFT共识算法为checkpoint流程设计了执行间隔,每执行K个请求,节点就主动发起一次checkpoint,来获取最新的stable checkpoint。
除此之外,PBFT共识算法引入了高低水位(High-Low Watermarks)的概念,用于辅助进行垃圾回收。在进行共识的过程中,由于节点之间的性能差距,可能会出现节点间运行速率差异过大的情况。部分节点执行的序号可能会领先其他节点,导致领先节点的共识数据长时间得不到清理,造成内存占用过大的问题,而高低水位的作用就是对集群整体的运行速率进行限制,从而限制节点的共识数据大小。
在高低水位系统中,低水位记为h,通常指的是最近一次的stable checkpoint对应的高度。高水位记为H,计算方式为H=h+L,其中,L代表共识缓存数据的最大限度,通常为checkpoint间隔K的整数倍。当节点产生的checkpoint进入stable checkpoint状态时,节点将更新h。当执行到H时,如果h没有被更新,则节点会暂停执行更大序号的请求,等待其他节点的执行,待h更新后重新开始执行更大序号的请求。
如下图所示,设置checkpoint间隔K为10,系统每执行10个请求,就进行一次checkpoint;设置L为30,即允许节点最多缓存30次请求的共识数据。节点1、2、3的当前请求编号是109,而节点0的当前请求编号为130。那么,此时系统的stable checkpoint为100,对应的h也为100。计算可得,H=h+L=130。此时,节点0已经执行到了最高水位130,那么它将暂停并等待其他节点执行。当其他节点执行完110号请求后,系统将进行一次checkpoint,从而将stable checkpoint更新到110,高/低水位随之更新为H=140/h=110。此时,110号请求之前的共识数据就可以回收了。

视图变更流程
当主节点超时无响应或从节点集体认为主节点是问题节点时,就会触发视图变更(view-change)。视图变更完成后,视图编号将加1,主节点也会切换到下一个节点。如下图所示,节点0发生异常,触发视图变更流程,变更完成后,节点1成为新的主节点

当发生视图变更时,节点会主动进入新视图v+1,并广播view-change消息,请求进行主节点切换。此时,集群需要保证在旧视图中已经完成共识的请求能够在新视图中得到保留。因此,在视图变更请求中,一般需要附加部分旧视图中的共识日志,节点广播的请求为 。其中,
。其中,
- i为发送方节点的身份标识
- v+1表示请求进入的新视图编号
- h为当前节点最近一次的stable checkpoint的高度
- C、P、Q分别对应三类共识数据的集合,用于帮助集群在进入新视图后保留必要的共识结果
- C:当前节点已经执行过的checkpoint的集合,在该集合中,数据按照<n,d>的方式进行存储,表示当前节点已经执行过序号为n、摘要为d的checkpoint,并发送过相应的共识消息。
- P:当前节点已经进入prepared状态的请求的集合,即当前节点已经针对该请求收到了1条pre-prepare消息与2f条prepare消息。在集合P中,数据按照<n,d,v>的方式进行存储,表示在视图v中,摘要为d、序号为n的请求已经进入prepared状态,说明至少有2f+1个节点拥有并认可该请求,只差commit阶段即可完成一致性确认。因此,在新的视图中,这一部分消息可以直接使用原本的序号,无须分配新序号。
- Q:当前节点已经进入pre-prepared状态的请求的集合,即当前节点已经针对该请求发送过对应的pre-prepare或prepare消息。在集合Q中,数据同样按照<n,d,v>的方式进行存储。由于请求已经进入pre-prepared状态,所以该请求已经被当前节点认可。
集合P、Q中的请求都在高低水位之间,在没有发生视图变更时,集合P、Q均为空,也就是说,不包含已经进入commit状态并执行的请求。
但是,视图v+1对应的新主节点pnew在收到其他节点发送的view-change消息后,无法确认view-change消息是否是拜占庭节点发出的,也就无法保证一定可以使用正确的消息进行决策。PBFT共识算法通过view-change-ack消息让所有节点对它收到的所有view-change消息进行检查和确认,然后将确认的结果发送给pnew。pnew统计view-change-ack消息,辨别哪些view-change消息是正确的,哪些是拜占庭节点发出的。
节点在对view-change消息进行确认时,会对其中的集合P、Q进行检查,要求集合中的请求消息小于或等于视图编号v,若满足要求,则发送view-change-ack消息 。其中,
。其中,
- v+1表示请求进入的新视图编号
- i为发送view-change-ack消息的节点标识
- j为要确认的view-change消息的发送方标识
- d为要确认的view-change消息的摘要
不同于一般消息的广播,这里不再使用数字签名标识消息的发送方,而采用会话密钥保证当前节点与主节点通信的可信度,从而帮助主节点判定view-change消息的可信性。
pnew维护了一个集合S,用于存放验证正确的view-change消息。当pnew获取到一条view-change消息及合计2f-1条对应的view-change-ack消息时,就会将这条view-change消息加入集合S。当集合S的大小达到2f+1时,证明有足够多的非拜占庭节点发起视图变更。pnew会按照收到的view-change消息,产生new-view消息并进行广播,<view-change,v+1,V,X>,其中,
- v+1为新的视图编号
- V为视图变更验证集合,按照<i,d>方式进行存储,表示节点i发送的view-change消息摘要为d,均与集合S中的消息相对应,其他节点可以使用该集合中的摘要及节点标识,确认本次视图变更的合法性
- X为包含stablecheckpoint及选入新视图的请求
新主节点pnew会按照集合S中的view-change消息进行计算,根据其中的集合C、P、Q,确定最大stable checkpoint及需要保留到新视图中的请求,并将其写入集合X。
从节点会持续接收view-change消息及new-view消息,并根据new-view中的集合V与自身收到的消息进行对比,如果发现自身缺少某条view-change消息,则主动向pnew请求view-change消息与view-change-ack的集合,以证明至少有f+1个非拜占庭节点对该view-change消息进行过判定。否则,判定pnew为拜占庭节点,当前节点进入视图v+2,并发送view-change消息,进入新一轮的视图变更。
从节点在进行new-view验证后,会和主节点一起进入集合X的处理流程。先根据集合X中的checkpoint数据,恢复到其中标定的最大的stable checkpoint,然后将其中包含的请求设置为pre-prepared状态,按照核心共识流程在新视图中恢复必要的共识数据,从而完成视图变更流程,进入正常的共识过程。
3、算法复杂度
PBFT共识算法的核心过程有三个阶段,分别是pre-prepare、prepare和commit阶段。
- pre-prepare阶段,主节点广播pre-prepare消息给其他节点,因此总通信次数为n-1
- prepare阶段,每个节点在同意请求后,都需要向其他节点广播prepare消息,所以总通信次数为(n-1)(n-1)
- commit阶段,每个节点在进入prepared状态后,都需要向其他节点广播commit消息,所以总通信次数为n(n-1),即n2-n
因此,PBFT共识算法的核心共识流程算法复杂度为O(n2)。通过类似的方式,我们可以计算PBFT共识算法的视图切换流程的算法复杂度为O(n3)。
4、实际应用
PBFT共识算法能够在抵抗拜占庭行为的同时,以高交易吞吐量进行出块,并且不可能出现分叉,因此非常适用于区块链系统的架构。但是,PBFT共识算法本身并不能防止身份伪造问题,即无法抵抗女巫攻击,因此需要其他模块协助进行身份过滤。
所以,PBFT共识算法最常见的应用范围在于联盟链。目前,大部分联盟链项目的共识算法都是在PBFT共识算法的基础上进行优化的,应用范围广阔。不过,相较于前面的共识算法,PBFT共识算法的实现难度相对较高,且对于主节点有较高的负载压力,如果不考虑拜占庭行为,则可以优先考虑使用RAFT等轻量级的共识算法。
随着区块链技术的不断发展及愈加复杂的应用场景的出现,共识算法迎来了新的需求和挑战,包括更高的安全性和可用性,更好的共识效率,更大的节点规模(可扩展性)等。为了解决这些问题,业界进行了一系列探索和尝试,一些新型共识算法也随之扩展而出。
新型共识算法
最早的公有链(如比特币和以太坊)一般采用PoW共识算法。众所周知,PoW共识算法存在以下几个主要缺陷。
- 严重的资源浪费:针对不同的区块链平台,矿工需要购买专用的挖矿硬件,还需要不定期地对这些硬件进行更新换代,以保持良好的算力竞争能力。此外,大量的哈希计算还会消耗海量的电力。
- 共识效率不高:确认时间长(需要等待多个区块确认),容易产生分叉。
- 网络呈中心化趋势:大部分算力掌握在大矿池手中。
2011年7月,Bitcointalk论坛首次提出了PoS(Proof of Stake)共识算法。发展至今,PoS共识算法大致分为两类。
- 基于链的权益证明(Chain-Based Proof of Stake,Chain-Based PoS)共识算法,在每个时间段(如每10秒)都通过伪随机的方式选取区块提议者来生成区块,该区块必须指向链上已有的区块(通常指向最长链的尾块),随着时间的推移,区块会收敛到单个不断增长的链中。采用这种模拟采矿的方式可以避免资源的浪费,同时可以提高共识的效率。这类PoS共识算法的代表包括Peercoin、Blackcoin、Iddo Bentov等。
- 基于拜占庭容错的权益证明(Byzantine Fault Tolerant Based Proof of Stake,BFT-Based PoS)共识算法。该PoS共识算法保留了PBFT算法共识的核心特性,包括如下内容。
- 极短的最终确定(Finality)时间,延续了经典的PBFT共识算法的两轮共识投票机制来达成最终共识。一旦完成共识,新区块立即获得最终确定性,这意味着该区块将不可逆转地安全上链。
- 可以从数学上证明,只要有2/3的资产掌握在诚实的协议参与方手中,那么不论网络延迟如何,该算法都能保证最终确定的区块没有冲突。
随后一系列BFT-Based PoS共识算法被提出,包括Casper、Ouroboros和Algorand等知名公有链的共识算法。
(1)Casper共识算法
随着PoS共识算法的出现,以太坊逐渐将目光转向该类共识算法。Casper共识算法最早由以太坊核心研究员Vlad Zamfir提出,该名字源于20世纪90年代的一部喜剧电影Casper。2017年10月,以太坊创始人Vitalik Buterin提出了另一种Casper共识算法。为了区分二者,前者被称为Casper the Friendly GHOST: Correct-by-Construction(CBC),后者被称为Casper the Friendly Finality Gadget(FFG),在以太坊内部有两个团队分别研究这两种Casper共识算法。
Casper CBC是一个共识协议族(Consensus Protocols Family),其目标在于构建一个抽象但足够灵活的框架,以支持在它的基础上逐步增加和构建协议框架的定义,并无缝继承所有理论证明和保证(如安全性和活性)。Vlad称这种方式为“建构中修正”(Correct-by-Construction),新协议的正确性由其建构过程来保证。
除了浪费资源和共识效率不高的问题,PoW共识算法还存在一个隐含的问题,即不存在明确的最终确定时间。具体地说,PoW共识算法并不能为任何非创世区块提供严格的数学证明以论证其正确性,只能提供一定的概率保证已经上链的交易不会发生双花问题。为了解决这个问题,Vitalik提出了Casper FFG,它是一种BFT-Based PoS共识算法。Casper FFG可与任一具有树形结构的区块链协议一起使用,后者充当共识出块的基础协议,前者用来完成显式的区块最终确定工作,那些被最终确定的区块将不可逆转地上链且保证没有冲突。
为了更加安全和平稳地切换共识算法,以太坊2.0初期采用了更加温和的Casper FFG方案,由PoW共识算法逐步过渡到完全的PoS共识算法。下文将介绍Casper FFG的具体设计。
1、基本概念
本节将预先介绍若干与Casper FFG相关的概念,以帮助读者理解后续协议内容。
- 验证者(Validator):Casper FFG引入了一种新的节点角色,即验证者。要成为验证者必须通过智能合约在系统中存入最低限度的保证金,在目前的测试网络中为1500ETH(以太坊1.0代币)。活跃的验证者不能将这笔存款用于其他目的,要想拿回保证金,必须通过智能合约发出注销命令。验证者参与共识,系统会增加其存款作为奖励,同样,如果被系统发现有恶意行为,打破了Casper FFG规定的惩罚条件(SlashingConditions),那么系统将通过减少其存款来对其进行惩罚。
- 最终确定性(Finality):达到最终确定性的交易或区块都将不可逆转地上链,不存在回滚(Rollback)和冲突的可能。
- 世代(Epoch):为了降低PoS共识算法的checkpoint数量,Casper FFG将若干区块划分成一个Epoch(一个Epoch由100个区块组成),验证者就Epoch边界的区块进行投票验证。
- checkpoint:在PBFT共识算法中,为了节省内存,系统需要一种将日志中无异议的消息删除的机制。然而在每个日志执行后都做垃圾回收是非常消耗资源的,因此在PBFT共识算法中只会周期性(如每执行100条日志进行一次)地进行该操作,称为checkpoint。在Casper FFG中,checkpoint具有不同以往的含义。具体地说,验证者会定期地就Epoch边界的区块进行投票,最终确定的区块将被虚拟机执行并写入账本,这些被选中的区块就称作checkpoint,由这些checkpoint构建的树被称为checkpoint tree(检查点树)。
2、共识流程
下图是Casper FFG架构图,虚线代表中间隔了若干区块或checkpoint。

Casper FFG可与任一具有树形结构的区块链协议一起使用,如上图所示,基础链呈树形结构,每100个区块组成一个Epoch。Casper FFG的验证者节点负责在Epoch边界构造和共识checkpoint,以达到显式的最终确定作用。
值得一提的是,在网络延迟或攻击的情况下,基础链可能会产生分叉,即一个父区块同时对应多个子区块。Casper FFG假定基础链的共识协议具有自己的分叉选择规则(Fork-Choice Rule),所有验证者节点在每个Epoch边界都会运行一次分叉选择规则,以确定checkpoint该构建在哪个区块之上。如上图所示,区块99有2个兄弟区块,验证者节点最终选择了区块99来构建checkpoint。
由于网络延迟、攻击甚至恶意验证者节点等问题,不同验证者节点运行基础链的分叉选择规则结果可能不同,造成同一高度的基础链具有多个不同的checkpoint。如下图所示,创世区块对应一个checkpoint,此后高度是100的倍数的区块也对应一个checkpoint。验证者节点A和验证者节点B分别就第100个区块发布不同的checkpoint:checkpoint A和checkpoint B。
显而易见,这些checkpoint最终可以构成一棵checkpoint tree。

需要注意的是,为了提高效率,Casper FFG并不是针对每个区块都达成PoS共识,而是每隔固定长度的区块来生成checkpoint。拉长checkpoint之间的距离可以减少PoS的开销,但也增加了达成一致的时间,即区块最终确定的时间会变长。
上文提到的Casper FFG是一个BFT-Based PoS共识算法,它延续了PBFT共识算法的核心特性,围绕其两阶段范式构建了Casper FFG的解决方案。具体来说,每个checkpoint都必须经历两轮投票共识才能进入最终确定状态,在Casper FFG中,这两个阶段为合理化(justified)阶段和最终确定(finality)阶段,完成finality阶段的checkpoint指向的区块及其父区块都将进入最终确定状态。
为了成为验证者节点,节点必须通过智能合约存入一笔大于最低限度的保证金,每个验证者节点的存款都会随着奖励和罚款而变化。PoS安全性的保证源于诚实验证者节点存款的规模,而不是验证者节点的数量。下文出现的“2/3个验证者节点”指的是存款加权分数,即一组验证者节点的总存款数等于整个验证者节点集合的总存款数的2/3。
验证者节点根据基础链提供的分叉选择规则定期地选择和构建自己的checkpoint,并广播投票消息vote <V,s,t,h(s),h(t)>。如下表所示,Casper FFG的投票消息包含两个checkpoint的哈希值s和t,该投票生成时,s和t在checkpoint tree中的高度为h(s)和h(t),V是验证者节点用私钥对上述四个信息的签名。投票消息由验证者节点广播给其他所有验证者节点。

Casper FFG要求s是t在checkpoint tree中的祖先,否则该投票将视为无效。如果验证者节点ν的公钥不在验证者节点集合中,则也认为该投票无效。合法的s和t可以构成一个连接(link),记为一对有序的checkpoint(s, t)。
下面将介绍几个Casper FFG的核心定义。
绝对多数连接(Supermajority link)
- 在Casper FFG中,绝对多数连接指一对有序的checkpoint(a,b)(也可以写成a→b)取得了超过2/3验证者节点的投票和同意。绝对多数连接可以跳过中间的checkpoint,即h(b)>h(a)+1是合法的。下图显示了三个不同的绝对多数连接:r→checkpoint1、checkpoint1→checkpoint2和checkpoint2→checkpoint3。其中,虚线代表checkpoint中间隔了99个区块,圆角矩形代表一个checkpoint,h表示checkpoint在checkpoint tree中的高度,根节点记为r。

- 当且仅当两个checkpoint a和b是不同分支中的节点,即它们都不是彼此的祖先或后代时,才称为冲突(Conflict)的checkpoint。
- 一个checkpoint c进入justified状态必须满足以下条件之一:
- 它是checkpointtree的根节点
- 存在一个绝对多数连接c'→c,其中,c'已经进入justified状态。上图显示了由4个已进入justified状态的checkpoint组成的链,r→checkpoint1→checkpoint2→checkpoint3。
- 一个checkpoint c进入finality状态必须满足以下条件之一:
- 它是checkpointtree的根节点
- 该checkpeint已经进入justified状态,并且存在一个绝对多数连接c→c',其中,c'是c的直系子代,即

安全性原则
CasperFFG能保证两个冲突的checkpoint不会同时进入finality状态,除非系统存在超过1/3的验证者节点是拜占庭节点。
上文提到,如果验证者节点被发现有恶意行为,则系统将通过减少其存款来对其进行惩罚。Casper FFG存在以下两种惩罚条件(Slashing Conditions)。
- 验证者节点不能同时广播两个投票<V,s1,t1,h(s1),h(t1)>和<V,s2,t2,h(s2),h(t2)>,其中,h(t1) = h(t2),即验证者节点不得就相同高度的区块广播两个不同的投票。
- 验证者节点不能同时广播两个投票<Ν,s1,t1,h(s1),h(t1)>和<Ν,s2,t2,h(s2),h(t2)>,其中h(s1) < h(s2) < h(t2) < h(t1),即验证者节点不得在一条连接范围s1→t1内投票另一条连接s2→t2。
如果发现验证者节点违反了其中任何一种惩罚条件,则可以将违反证据作为交易提交到网络中。此时,将罚完有恶意行为的验证者节点的全部存款,而提交证据的一方会收获少量的奖励。
由下图可知,
不同验证者节点在同一区块高度可能会发布不同的checkpoint,造成Casper FFG链分叉。由于长程攻击等问题的存在,传统的最长链原则不再适用于PoS共识,Casper FFG引入了GHOST协议来解决checkpoint的分叉。
Casper FFG的验证者节点将遵循LMD GHOST(Latest Message Driven GreediestHeaviest Observed SubTree)分叉选择规则来选取主链。具体来说,在每个Epoch结束后,验证者节点都将基于自己观察到的区块采用贪心算法选取最重(指资产权重)的子树作为主链。LMD GHOST具体流程如下伪代码所示。
procedure LMD-GHOST(G) B ← Bgenesis //将B赋值为创世区块 M ← the most recent votes of the validators //M为一个验证者节点收到的投票集合 while B is not a leaf block in G do //如果B不是Epoch G的叶子区块则继续 B ← argmax w(G, B′, M) //B赋值为其权重最大的孩子区块B′ return B
结合上述LMD GHOST具体流程和下图可知,假设每个投票(vote)的权重均为1,运行该协议后,阴影checkpoint所构成的链将成为验证者节点选择的主链,左侧权重为3的阴影checkpoint将成为Casper FFG的链头区块(圆角矩形中的数字代表该checkpoint的权重)。

3、实际应用
Casper FFG在尽可能提供一致性的同时保证系统的活性,目前已在以太坊2.0中上线,其最终目标是过渡到完全的PoS共识算法。
(2)Algorand共识算法
Algorand是图灵奖得主Silvio Micali及其团队在2017年提出的一种新型公有链共识算法。
Algorand是一种BFT-Based PoS共识算法。每个用户对出块选择的影响与其持有的资产呈正比。Algorand会随机选择用户来提议区块和投票共识。所有在线用户都有机会被选择为区块提议者和共识节点。用户被选择的概率及其提议的区块和投票的权重与用户所持有的资产呈正比。
Algorand将整个系统的安全性与大多数诚实用户联系在一起,它将PBFT共识算法至少2/3的诚实节点的前提条件转化为至少2/3的资产掌握在诚实用户手中,从而避免分叉和双花问题的产生。一小部分资产的持有者不能损害整个系统的安全,而大多数资产的持有者也不会发生作弊行为,因为这会削弱系统的可信度,最终使自己的资产贬值。故当大多数资产都由诚实用户掌握时,系统是安全的。
Algorand的核心在于其使用了一种称为快速拜占庭协议(Fast Byzantine AgreementProtocol,BA*)的共识协议,这使得Algorand能够在低延迟内达成共识,并且不会产生分叉。BA*适用于Algorand的一种关键技术——可验证随机函数(Verifiable RandomFunction,VRF),VRF以私有和非交互的方式随机选择区块提议者和共识节点。
1、基本概念和假设前提
基本概念
- 轮次(Round):Algorand按照时间顺序将共识划分为不同轮次,每轮都会有唯一一个区块达成共识。
- 区块提议者(Block Proposer):每轮共识都会随机选出若干区块提议者,负责打包交易、生成区块,并广播给其他共识节点。
- 委员会成员(Committee Member):通过选取委员会节点来达成共识,减少共识节点的数量,从而加强共识的可拓展性。委员会成员是在全体用户中随机挑选出的具有代表性的小集体,由他们来达成每轮共识。
- 可验证随机函数:vrf,proof=VRF(sk,seed),其中,sk为用户私钥,seed为随机种子。随机函数的输出由两部分组成:随机结果vrf(通常是一个哈希值)和证明信息proof。通过Verify(proof,pk,seed)可验证vrf的合法性,其中,pk是对应用户的公钥。
基本假设
- 所有诚实用户运行的软件都是没有错误的(bug-free),并且他们持有的资产占比高于某个阈值h(h大于平台资产总量的2/3)。
- 攻击者可以腐蚀(Corrupt)和破坏部分诚实用户,但不能同时破坏拥有大部分资产的大量用户,即诚实用户所拥有的资产必须保持在阈值h之上。
- 为了保证系统活性(Liveness),Algorand必须满足强同步假设(StrongSynchrony),即大多数(如95%)诚实用户发送的信息会在一个已知的时间范围内被大多数诚实用户接收。
- 为了保证协议的安全性(Safety),Algorand必须满足弱同步假设(WeakSynchrony),即允许网络在一个定长时间内(如一天或一周)是异步的(如完全被恶意节点控制),但在异步阶段后,网络会有一段时长合理的强同步阶段(如几小时或一天),以保证协议的安全性。
- 为了在弱同步假设下恢复共识,节点需要进行本地时钟同步(如使用NTP),即各节点的本地时钟应当足够接近,以便大多数诚实用户可以在同一时间恢复共识。
2、共识流程
Algorand的核心算法包括两个:
- 加密抽签算法(Cryptographic Sortition)
- BA*
前者用于保证每轮的区块提议者和共识节点几乎是完全随机的,后者是区块共识的核心协议。
为了防止攻击者定位到区块提议者或委员会成员,Algorand采用一种私密的和非交互的方式来选取目标节点。具体地说,每个节点在提议区块和运行BA*之前都需要进行一次加密抽签运算,以确定自己是否被选为区块提议者或委员会成员。如果被选中则提议自己的区块或参与BA*共识,否则等待并收集网络中的共识消息,以跟进共识进度。
加密抽签算法主要包括种子选取和选举验证两个过程。
种子选取
抽签需要一个公开的随机种子(seed),为了限制攻击者操控选举,Algorand每轮都会公布一批随机种子,第r轮的随机种子由第r-1轮区块的随机种子决定,其计算方式如下

种子seedr和证明信息π被保存在用户提议的区块中。其中,sku是用户u提前选好的私钥。若第r-1轮的提议区块无效(可能是恶意节点提议的区块或包含无效交易),则使用密码哈希函数(Cryptographic Hash Function)重新计算该轮种子节点<seedr,π>←H(seedr-1||r)。在同一轮中,需要保证seedr的一致性,即所有用户在选取区块提议者或委员会成员时,所用的seedr完全一致。
节点选举和验证
Algorand共识具体分为两个步骤:区块提议和BA*,下图是Algorand第r轮共识流程图。

下面将介绍Algorand共识的核心流程,可结合上图的共识流程图来理解。
1)区块提议阶段
- 选取区块提议者和广播区块。为了确保每轮都有区块被提议,Algorand设定每轮区块提议者的数量都大于1,并且保证最多就一个区块达成共识。Algorand利用VRF选出τproposer个区块提议者(τproposer的范围被限制在区间[1,70]中,实验证明,τproposer是一个比较合理的数值)。在本阶段开始时,每个节点都会遍历该节点所管理的每个账户,每个在线账户都运行VRF,以确定该账户是否被选为区块提议者。若节点发现该账户有若干子用户被选为本轮的区块提议者,则可自行选择优先级最高的子用户向全网广播提议的区块信息及VRF输出的证明信息π,π可用于证明该账户是有效的区块提议者。用户的优先级越高,其提议的区块的优先级就越高,该区块被共识出块的概率就越高。
- 等待区块提议。网络中的每个用户都会等待一段固定时间来收集区块提议,当节点收到区块提议消息时,会先验证证明信息π的合法性,随后再比较区块提议者的优先级,丢弃优先级较低的节点传来的区块。若超时未收到任何区块,则将本轮的区块提议置为空块。
2)BA*阶段
BA*包括两个阶段,分别是
- 区块Reduction
- 二元拜占庭协议(BinaryBA*)
在第一个阶段,BA*将每轮有且仅有一个区块达成共识的问题简化为二选一问题;在第二个阶段,BA*就以下选项之一达成协议(提议的区块或空块)。
为了加强共识的可拓展性,Algorand通过VRF随机选取τstep个委员会成员(CommitteeMember)来达成每轮共识,以减少共识节点的数量。
(1)区块Reduction。
在区块提议阶段,不同的节点因为网络延迟等因素,会收集到不同优先级的区块,其所观察到的最高优先级区块可能不同。因此,在进入BinaryBA*共识之前,应先对区块的优先级进行投票并达成共识,选出优先级最高的区块,将若干个潜在的区块收敛为至多一个非空块或一个空块。具体分为4步。
- Step1:每个节点都运行VRF,检查自己是否为委员会成员,若是则广播投票消息,包括VRF输出的证明信息π和本地优先级最高的区块信息。
- Step2:等待一段固定的超时时间,收集全网用户的投票。一旦某区块的投票数超过Tτstep的阈值,则认为全网大部分诚实节点在该区块达成共识,为了方便,下文将该区块记为hblock1。节点再次发起投票,消息中附带hblock1信息。值得一提的是,为了避免女巫攻击和双花攻击,必须保证全网至少有2/3的用户是诚实的,故此处的T≥2/3。
- Step3:若Step2超时,则对空块投票。
- Step4:等待一段固定的超时时间,收集全网用户投票。同Step2,一旦某区块的投票数超过Tτstep的阈值,则认为全网大部分诚实节点在该区块达成共识,记为hblock2。若超时未达成共识,则本次区块Reduction的结果为空块。
第一次投票就优先级最高的区块达成共识。第二次投票对第一次投票的结果进行共识,以确保大多数委员会成员已知晓该区块的存在。细心的读者可能已经发现,此处遵循的是PBFT共识算法的两轮共识投票规则。
(2)BinaryBA*。
经过区块Reduction阶段,目标区块已经收敛为hblock2或一个空块,将该目标区块的哈希值记为block_hash。BinaryBA*将对目标区块进行多次投票。BinaryBA*将重复以下几个基本步骤,直到达成共识。
在本阶段开始时,每个节点都运行VRF,若发现自己是委员会成员,则初始化三个参数:
- step置为1
- 共识目标哈希值r置为block_hash
- 利用密码哈希算法重新计算一个空块哈希值,记为empty_hash。
随后进入Step1
- Step1:对r进行投票并收集投票结果。若超时,则step加一后进入Step2。若在规定时间内对r达成了共识且r≠empty_hash,则进行如下操作。
- ① 另外发送三次对r的投票。考虑以下问题:部分诚实节点由于网络延迟,在给定的时间内没有收到2/3以上的票数,从而超时进入下一轮。在接下来的step中可能没有足够的委员会成员进行投票(大部分节点已经完成本轮共识),导致这些延迟节点始终无法对区块达成共识。达成共识的节点在退出共识之前对r进行三次投票,这一行为对延迟节点来说,相当于继续参与了后三个step的投票。
- ② 若step=1,则投出final状态的票,随后返回r(共识结束)。
- Step2:继续对r进行投票并收集票数。若在规定时间内达成了共识且r=empty_hash,则另外发送三次投票(原因同上)并返回r;若超时,则将r置为empty_hash,step加一后进入Step3。
- Step3:对r进行投票,若在规定的时间内达成共识,则step加一后进入Step1。若超时,则运行CommonCoin算法(抛硬币算法),随机将r置为block_hash或empty_hash,使得攻击者只有1/2的概率命中该目标,随后step加一进入Step1。
综上所述,一次BinaryBA*共识有且仅有一个区块会被最终确定上链。

结束BinaryBA*共识后(将其共识结果记为hblock),节点会等待一段固定的超时时间,收集全网用户对final状态的投票信息。若在规定时间内达成共识(记为r)且r=hblock,则结束本轮共识并将该区块写入账本,即最终上链。若在规定时间内未收到足够针对区块final状态的投票,则将其标记为tentative状态,标记为tentative状态的区块需要等待后续区块的共识结果才能最终确定是否上链,本文不再赘述。
3、实际应用
通过上一章节的分析可知,Algorand的主要突破点在以下三个方面。
- 具备抵抗女巫攻击的能力。Algorand不是纯粹的PBFT共识算法,攻击者可以控制的有效节点数量与其拥有的资产息息相关。Algorand通过赋予用户资产不同权重的方式,避免攻击者伪造多个身份,以试图增加其被选中的概率。
- 具备抵抗拒绝服务攻击(DoS)的能力。每轮共识Algorand都会通过加密抽签算法随机选择区块提议者和共识节点,使个人身份得到隐藏,让攻击者无从下手。
- 可拓展性较好。因为加密抽签算法的VRF具有较高的效率,并且通过加密抽签算法选取委员会成员达成共识可以缩小共识节点的数量,在一定程度上解决过去拜占庭容错算法无法拓展至大规模节点场景的问题。
目前联盟链系统对共识节点的数量、交易吞吐量和网络带宽消耗提出了更高的要求,业界纷纷探索新的PBFT共识算法。近年来,出现了包括HotStuff、MirBFT、BFT-SMART等新型联盟链共识算法。其中,HotStuff被Facebook推出的加密货币项目Libra采用。
(3)HotStuff共识算法
HotStuff是一个建立在部分同步模型(Partial Synchrony Model)上的拜占庭容错算法。HotStuff具有线性视图变更(Linear View Change)特性,把切换主节点融入常规共识流程,切换主节点无须增加其他协议和代价,并且系统在此期间还能继续对外提供服务。该特性解决了PBFT共识算法最棘手的视图变更问题,如实现复杂度高、完成时间不确定,以及整个过程系统不能正常对外提供服务等。此外,HotStuff还将共识流程的算法复杂度降低至O(n)。
1、基本概念
- 门限签名(Threshold Signatures):一个(k,n)门限签名方案指由n个成员组成一个签名群体,所有成员共同拥有一个公钥,每个成员都拥有一把独一无二的私钥。只要其中至少k个成员为一条消息提供签名,这k个成员的签名就可以生成一个完整的签名,该签名可以通过公钥进行验证。
- 节点角色:在HotStuff中,节点分为两种角色(主节点和从节点)。在每个视图内,有且仅有一个主节点负责打包交易、收集和转发消息。从节点是普通的共识节点,负责接收来自主节点的提案消息并投票。
- 积极响应(Optimistic Responsiveness):HotStuff具有积极响应的特性,具体地说,在全局稳定时间(Global Stabilization Time,GST)之后,任何正确的主节点一旦被指定,只需要等待最早的n-f个节点返回投票消息就可以发起有效的提案和主节点变更。在HotStuff中,一个节点不需要等待足够多的节点发起视图变更,便可以直接切换到新视图。
- 证书(Quorum Certificate,QC):主节点在收到n-f个节点对同一个提案的投票消息(带节点签名)后,利用门限签名将其合成一个QC,其结构如下,QC{type,viewNumber,node}。其中,type代表证书所处的阶段,viewNumber代表视图编号,node代表一个提案消息,其格式为node { parent,cmds,qc},其中,parent为父节点,其类型同为node,cmds表示来自客户端的交易请求列表,qc为本提案对应的QC。
2、共识流程
HotStuff的基础共识流程围绕一个核心的三轮共识投票展开。
基础共识流程
基本共识协议(Basic HotStuff)是HotStuff的基本过程,在该过程中,视图以单调递增的方式不断切换。在每个视图内,都有唯一一个主节点负责打包区块、收集和转发消息并生成QC。
整个过程包括5个阶段,
- 准备(prepare)阶段
- 预提交(pre-commit)阶段
- 提交(commit)阶段
- 决定(decide)阶段
最终(finally)阶段主节点想要提交(达成最终共识)某个分支,需要在准备、预提交、提交三个阶段收集n-f个共识节点的带签名的投票消息,并利用门限签名算法将其合成一个QC,随后广播给从节点。

由上图可知,从节点之间不再相互广播共识消息,而经由主节点进行处理、合并和转发,因此其算法复杂度由PBFT共识算法的O(n2)降至O(n)。
(1)准备阶段。
① 主节点。
- Step1:主节点在收到n-f条new-view消息后,根据new-view消息计算出highQC。在计算highQC时,主节点会选择视图编号最大的prepareQC(new-view消息中附带了每个节点当前的prepareQC)作为highQC。
- Step2:主节点使用createLeaf方法(见下伪代码)创建一个新的提案(以下表示为node),该node将扩展由highQC.node引导的分支,即最新创建的node,其父节点是highQC.node。
Procedure createLeaf(parent, cmd) b.parent ← parent //highQC.node为最新node的父节点 b.cmd ← cmd //选择若干来自客户端的请求作为最新node待共识的交易 return b
- Step3:主节点将一条prepare消息(PREPARE, qc, node)广播给其他从节点,其中,PREPARE表示消息类型,qc赋值为highQC,node赋值为新创建的提案。
② 从节点。
- Step1:收到主节点发来的prepare消息m后,检查消息的合法性(包括qc中的签名是否合法,消息中的视图编号是否等于本地视图编号,消息类型是否为PREPARE),若合法则进入Step2。
- Step2:如果m.node是一个安全节点(由safeNode方法进行判断,见下伪代码),则向主节点发送投票信息。
Function safeNode(node,qc) return(node extends fromlockedQC.node) ‖ //安全性条件 (qc.viewNumber > lockedQC.viewNumber) //活性条件
安全节点的判断指标有两个,满足其一即可:
- m.node是本地lockedQC.node的扩展节点(孩子节点)
- m.qc的视图编号大于本地lockedQC的视图编号
从节点只会对满足安全性条件的提案进行投票,其中,lockedQC将在提交阶段投票决定,并由主节点合成。
- Step3:将带有签名的投票消息vote(PREPARE, m.node)发送给主节点。
(2)预提交阶段。
① 主节点。
- Step1:主节点在收到n-f个合法的vote消息后,根据投票消息生成一个prepareQC。QC合成方法如下伪代码所示(其中,V为合法投票信息集合)。
Function QC(V) //type为消息类型: PREPARE、PRE-COMMIT、COMMIT、DECIDE和NEW-VIEW qc.type ← m.type : m ∈ V qc.viewNumber ← m.viewNumber : m ∈ V //本QC所对应的提案node qc.node ← m.node : m ∈ V //合并n-f个节点的签名 qc.sig ←tcombine(<qc.type, qc.viewNumber, qc.node>,{m.partialSig |m∈V}) return qc
- Step2:将节点当前的prepareQC更新为最新生成的prepareQC。
- Step3:主节点广播pre-commit(PRE-COMMIT, qc)消息给从节点,其中,PRE-COMMIT为消息类型,qc赋值为prepareQC。
② 从节点。
- Step1:收到主节点发来的pre-commit消息m,通过合法性检查后进入Step2。
- Step2:将本地的prepareQC更新为m.qc消息。
- Step3:将带有签名的投票消息vote(PRE-COMMIT, m.qc.node)发送给主节点。
(3)提交阶段。
① 主节点。
- Step1: 主节点在收到n-f个合法的vote消息后,合成一个pre-commitQC(合成方法同预提交阶段),并将本地的lockedQC更新为pre-commitQC。
- Step2: 主节点广播commit(COMMIT, qc)消息给所有从节点,其中,COMMIT为消息类型,qc赋值为pre-commitQC。
② 从节点:
- Step1:收到主节点发来的commit消息m,通过合法性检查后进入Step2。
- Step2:将节点本地的lockedQC更新为m.qc。
- Step3:将带签名的投票消息vote(COMMIT, m.qc.node)发送给主节点。
(4)决定阶段。
① 主节点。
- Step1:主节点在收到n-f个合法的vote消息后,合成一个commitQC。
- Step2:主节点广播decide(DECIDE, qc)消息给其他从节点,其中,DECIDE为消息类型,qc赋值为commitQC。
- Step3:执行commitQC.node.cmd(客户端请求),将执行结果返回给客户端。
② 从节点。
- Step1:收到主节点发来的decide消息m,通过检查后进入Step2。
- Step2:执行commitQC.node.cmd,返回执行结果给客户端。
(5)最终阶段。
任何一个进入下个视图的节点,都会发送一个NEW-VIEW消息给下个视图的主节点,该消息会附带节点本地的prepareQC。下个视图的主节点可根据这些prepareQC计算出highQC,至此形成一个闭环。
为了加入线性视图变更特性,HotStuff由PBFT共识算法的核心三阶段两轮共识拓展为五阶段三轮共识,新加入的一轮共识可保障系统加入该特性后的活性。
Chained HotStuff
由上文可知,Basic HotStuff各阶段的流程高度相似,HotStuff作者便提出用ChainedHotStuff来简化Basic HotStuff的消息类型,并允许Basic HotStuff的各阶段进行流水线(Pipelining)处理。
Chained HotStuff流程如下图所示。其中,v表示视图view,一个圆角矩阵表示一个node。

由上图可知,在每个prepare阶段都会更改视图,因此每个提案都有自己的视图。一个节点可以同时处于不同的视图中,prepare阶段的投票被当前视图的主节点合成一个QC,并转发给下个视图的主节点,即将自己下个阶段的责任委托给下个视图的主节点。
下个视图的主节点在启动新的prepare阶段(提议自己的提案)时,也在进行上个视图的pre-commit阶段。
以此类推,因为所有阶段都具有类似的结构,所以
- 视图v+1的prepare阶段同时用作视图v的pre-commit阶段
- 视图v+2的prepare阶段同时用作视图v+1的pre-commit阶段和视图v的commit阶段
- 视图v1中提出的提案cmd1的prepare、pre-commit和commit阶段分别在视图v1、v2、v3中进行,提案cmd1将在视图v4结束时被提交,即达成最终确定性。视图v2中提出的提案cmd2将在视图v5结束时被提交并执行。
上图的虚线箭头表示本轮合成的QC指向的祖先提案。例如,视图v5合成的QC是针对视图v4提议的提案cmd4;实线箭头表示本轮node指向的父节点。例如,视图v5中的node的父节点是视图v4中的node。
当一个共识节点收到视图v7的提案后,视图v4、v5、v6中的node就会形成一个连续的3-chain,视图v4中的node便进入最终确定状态,该共识节点可执行node中的cmd请求。

Pacemaker
活性是保证系统在给定的GST内能够一直向前运转的关键,也是所有共识算法在设计之初必须考虑的关键因素。HotStuff的活性组件称为Pacemaker,它主要负责以下两件事情。
- 选择及校验每个视图的主节点。
- 帮助主节点生成提案。
每次节点在进入一个新的视图后,都会判断自己是否为当前视图的主节点,如果是,则调用createLeaf方法创建提案,并广播给其他从节点。从节点只需要等待来自主节点的提案消息。主节点的切换机制可根据需求自定义,最简单的策略是根据节点编号进行轮换。
在HotStuff中,每个共识节点都拥有一个Pacemaker,负责定期选举主节点和打包交易,以推动共识进程,从而保障系统活性。
3、实际应用
LibraBFT以HotStuff为基础协议,并在HotStuff上做了若干工程上的优化,具体如下。
- 更加完备的活性机制:LibraBFT共识算法为共识中每个步骤的处理时间都加了一个上限值,并允许对实际交易确认进行活性分析。原生HotStuff的Pacemaker作为一个工作模块,独立于共识协议的安全模块,这极大地降低了LibraBFT系统根据自身应用场景来定制活性机制的难度,无须修改协议安全性保证的内容便可获取更多活性保障。
- 预执行:共识节点不仅对交易序列签名,还对整个区块的状态进行签名,更能抵抗非确定性错误。
- 不可预测的领导选举机制:由于HotStuff线性视图变更的特性,即切换主节点无须花费更多代价,因此LibraBFT加入VRF成为可能,进一步限制了攻击者针对主节点发起的拒绝服务攻击(DoS)的时间窗口。
- 经济激励机制:为共识节点加入了激励和惩罚机制。
总结
本章从共识算法的概述谈起,介绍了共识问题的定义、共识算法的定义、共识算法中的通信模型等,随后简要概述了共识算法的发展历史,以及其中最重要的3个问题/理论:拜占庭将军问题、FLP不可能定理与CAP理论。拜占庭将军问题对共识算法的研究内容进行了扩充,将其从简单的容忍宕机错误扩展到容忍任意恶意行为的拜占庭错误,使得共识算法更加适用于现实的拜占庭容错系统,尤其是区块链系统。
传统分布式一致性算法只能容忍宕机等良性错误,通常适用于内部系统(私有链)或信任度较高的系统(联盟链);而区块链共识更加注重拜占庭错误的处理,通常适用于信任度较低的系统(联盟链)或公开网络的系统(公有链)。
近年来出现的若干新型共识算法通常在容错能力、交易吞吐量、复杂度、延迟等方面做出了一定的权衡,从而设计出符合特定需求的定制化共识算法。纵观共识算法的发展历史,区块链系统的出现无疑极大地促进了共识算法的应用与发展。
区块链安全体系
区块链应用是为某种应用目的编写的软硬件系统,可以分为区块链部分和非区块链部分,
- 区块链部分是指应用在区块链节点或网络上执行的部分,如为本应用编写的一系列智能合约、区块链本身的共识模块、存储模块等
- 非区块链部分指本应用其他部分,可能是为了处理和外部数据的交互、用户友好的人机接口及其他不适合或不能在区块链上处理的业务逻辑
下图是区块链安全架构图,

主要可以分为五部分,分别是数据安全、网络安全、共识安全、合约安全和应用安全。
- 数据安全主要是指区块链数据的存储安全,包括隐私保护等方面
- 网络安全是指区块链网络的安全,包括通信安全和节点准入等内容
- 共识安全是指共识算法本身的安全
- 合约安全是指执行引擎和智能合约本身设计的安全
- 应用安全是指区块链DApp设计和实现时需要考虑的安全
(1)网络层安全
网络层安全是区块链网络安全的关键之一,如果没有安全可信的传输信道,那么区块链节点和节点之间任何通信的信任都无从谈起。特别是在有准入要求的联盟链和私有链网络中,身份鉴定和链接建立是一个整体,因此节点准入机制也依赖网络层安全。部分共识算法依赖节点数量,如果不能保证网络中的节点都是合法节点,那么共识算法的安全也不能保证。总而言之,网络层安全在区块链安全架构中占据重要的地位。
网络层安全的重点在于区块链节点和节点之间能够通过某种网络握手协议认证对方的身份,并且建立加密安全的信道,保证传输数据的完整性、机密性和防抵赖性。
安全信道的建立和通信往往是公钥密码学和对称加密算法的综合应用。对称加密算法有较高的加密效率,但是其难以解决身份认证和密钥协商的难题。双方为了拥有相同的密钥,不得不提前在不安全信道上传输对称密钥,或者提前线下分发对称密钥。但是,一方面,密钥在不安全信道上传输容易受到拦截,导致在之后的通信过程中泄露数据;另一方面,线下分发对称密钥效率低下、成本高昂。因此,这两种方法都不可行。公钥密码学的加密密钥和解密密钥有不同的特点,可以很好地解决分发对称密钥的问题,但是公钥密码学的实现包含广泛针对大特征有限域上元素的运算,其加密效率远不及对称加密算法。
综合二者的长处,使用公钥密码学完成身份认证和密钥协商后,再使用协商的会话密钥保护上层应用数据安全的方案是极为推荐的。
(2)共识层安全
区块链使用共识算法来维护自身的有序运行。相互间未建立信任关系的区块链节点可共同对数据写入等行为进行验证,以大多数节点达成一致的信任构建方式,摆脱对传统中心化网络中信任中心的依赖。这里要强调的是,即便是成熟完备的共识算法,其安全也不是无条件的,而是有严格的条件要求,只有遵守这些条件,共识算法才能正确工作,从而避免恶意节点控制整个网络。
区块链应用场景可以分为公有链场景和联盟链场景,从这个角度来看,目前,共识算法可以分为基于激励机制的共识算法和拜占庭容错类算法,前者多用于公有链场景,后者多用于联盟链场景。
- 基于激励机制的共识算法通过对正确执行协议者进行奖励和对作恶者进行惩罚来保证共识安全。例如,PoW共识算法通过对各个节点进行打包交易并提供PoW来完成记账,算力竞赛下个区块的记账权,诚实节点在正确生成区块后可以得到一定的奖励,而作恶节点会白白损失自己挖矿所得的算力。
- 典型的拜占庭容错类算法如实用拜占庭容错算法,通过交互式的协议来保证共识安全。将共识协议划分为request、pre-prepare、prepare和commit四个阶段,保证在大于或等于3f+1个节点组成的网络中有对f个节点的容错能力,从而保证共识安全。
(3)合约层安全
智能合约是和业务逻辑紧密相关的链上代码,智能合约参与方将约定好的协议写入智能合约,然后部署到区块链上自动执行。
所谓在链上执行,就是智能合约运行于区块链节点之上,不同的节点为了验证交易的正确性都会执行一次智能合约代码。为了保证在不同的节点上仍然能得到相同的运算结果,智能合约必须运行于一个隔离外部因素的沙箱环境下。也就是说,智能合约既不能随意获取外部数据,也不能拥有一般意义上的随机数模块。合约层安全主要指在编写智能合约过程中需要注意的安全。
任何稍微复杂的代码中都可能有缺陷,这些缺陷需要在之后的测试、使用和不断迭代中才能逐渐减少。即便是看似逻辑较为简单的智能合约,也可能因为设计问题或开发者缺少对智能合约执行引擎的了解而编写出会被攻击者攻击的代码。
这里我们以以太坊为例,分析最典型的智能合约漏洞,旨在说明编写智能合约代码时特别需要注意的关键点。下图为对大量智能合约进行分析、统计后得到的智能合约常见缺陷类型及其占比,占比较高的有无限制写入(45%)、错误使用随机数(17%)、缺少输入验证(15%)、触发不安全地调用(10%)、条件竞争(4%)和除法精度类(3%),这几种类型占了样本总数的90%以上。

1、权限验证类缺陷
无限制写入(45%)和缺少输入验证(15%)可以分类到权限验证类缺陷,总占比高达60%,是最为常见的智能合约漏洞。该类漏洞可以归因于智能合约逻辑的缺陷。开发者在刚开始接触智能合约开发时,因为没有意识到以太坊等公有链的开放性(任何人都可以调用该智能合约),往往容易出现此类漏洞。
在对智能合约字段可以无限制写入的这种情况下,对字段的修改不做限制意味着任何人都可以更改智能合约状态,几乎没有攻击成本。一般来说,至少应该检查调用者的地址,设定只有特定地址的账户才能调用,或者根据账户地址对权限进行分级管理。
对输入缺少进行必要的验证非常危险,对输入不加检查至少在两方面可能出现问题:第一,大大增加测试的难度和攻击者的攻击面,而这在很多时候根本没有必要;第二,在不同的执行引擎上执行智能合约时,对极端值的处理依赖执行引擎的具体实现,其表现可能未经定义。
2、错误使用随机数
当以太坊将智能合约这一区块链划时代的特性引入后,涌现出大量的博彩智能合约。其原因不难分析,首先,智能合约的自动化和区块链的透明不可篡改性十分适合开发博彩游戏;其次,以太币本身拥有一定的价值,价值转移可以随着博彩游戏的进行顺畅地完成,游戏结果能够立即自动结算,不会有人抵赖;最后,以太坊公有链的匿名性使得这样的博彩游戏很容易规避各国对博彩行业的法律规定。
这里我们不讨论这种场景的社会价值和意义,只关注这里面对的技术问题,博彩游戏或多或少都借助于随机性,那么如何在智能合约中获取到随机数呢?
这并不是一个简单的问题,为了让智能合约在不同节点执行后结果一致,其设计时主要考虑的就是消除不确定因素对执行结果的影响。例如,不能在智能合约中直接访问外部网络,或者获取当前的精确时间,但是仍然有一些上下文能够提供帮助。在智能合约中能够访问上个区块的区块哈希值、出块时间等。这些值在智能合约执行之前是难以预测的,很适合作为随机数种子,而且引入这些值仍能够保证智能合约在不同节点执行后结果一致。
当前,在计算机系统中生成随机数一般都依赖硬件的随机数源,如采集热噪声或环境噪声等。在一个完全确定的系统中是无法生成真正的随机数的。那么在智能合约执行引擎这样的沙箱环境中,能够依赖的不确定因素有两个,一个是当前的执行上下文,也就是一些链上信息,如区块哈希值等,另一个是用户输入的参数。
利用区块哈希值看似是一个不错的主意,密码学安全的哈希函数输出基本很均匀,这里所谓的均匀,我们使用下图直观地呈现。可以看到sha3这种密码学安全算法的图像基本上和二维的随机噪声类似。但是现实是,同一个区块中的交易在执行时,能获取上个区块的区块哈希值。使用区块哈希值作为随机数的关键之一就是区块哈希值难以预测,但在这里,攻击者不需要预测就能获取这个随机数。

在智能合约中获取随机数比较好的方法是调用一些专门为生成随机数编写的智能合约,如开源项目RANDAO。这些智能合约基本上让全部有利益关系的或有其他必要原因的参与方在随机数生成前提供输入,收集完成后,根据这些输入通过sha3等算法计算出一个最终结果。
3、除法精度类
以太坊虚拟机中数字的表示都是256位的整数,计算除法时结果会被舍入成为整数,如果不加注意难免产生精度问题。特别是在计算除法之后紧跟乘法,结果有时会出乎意料。计算除法之后的结果直接作为金额进行代币转账,也可能会造成损失。因此,在计算除法之前应该进行算数逻辑的仔细检查,确保不会出现类似的问题。
减少智能合约漏洞不是仅依赖智能合约编写者就能完成的,经验丰富的开发者能够避免很多漏洞的产生,对编码规范的尊重和遵循,以及对语言本身和计算机系统的充分理解都能避免漏洞产生。但是一栋房屋的质量不能仅依赖某个施工工人的高超技巧——那将迟早导致灾难,更应该依赖前期成熟的建筑设计、高质量的原材料保障、科学合理的施工工期、后期测试和质量检测人员及伴随项目整个生命周期的成熟的项目管理方法。减少智能合约漏洞更应该有工程级别的保障。
这里我们仅简单探讨减少智能合约漏洞的技术手段。对于技术人员来说,学习智能合约执行引擎的相关设计细节或博览常见的漏洞清单都能避免在自己编写的智能合约中发生低级错误。除此之外,形式化验证也是保证智能合约代码安全的重要手段。形式化验证利用数学建模的方法,对智能合约内容逻辑的安全性进行证明。相比白盒或黑盒测试,形式化验证更能完整和系统地保障智能合约代码安全。
(4)应用层安全
应用层位于一个区块链应用的顶层,一般是和业务逻辑紧密相关的代码模块。
应用层代码处理和用户交互的人机界面,以及一些不适合放于链上执行的逻辑代码。这里需要注意的是,其安全问题和传统的应用开发需要处理的安全问题大同小异,拥有一些传统的安全实践经验对这一部分开发是有利的。
核心安全技术
身份隐私保护技术
数据隐私保护技术
智能合约(Smart Contract)是一套以数字形式定义的承诺,智能合约参与方节点可以在智能合约上执行相应的协议。
智能合约的运行环境是智能合约执行引擎。智能合约执行引擎需要满足两个条件:
- 执行过程可终止
- 执行过程结果一致性
从智能合约执行引擎架构来看,目前典型的设计包括栈式执行引擎、解释型执行引擎和容器化执行引擎三类,不同的执行引擎具有不同的设计原理、运行机制和应用。
区块链智能合约执行引擎为智能合约的运行提供了一个封闭的、确定性的沙箱环境,在运行智能合约时无法向外界请求获取新数据,所以智能合约需要使用预言机来搭建智能合约运行时的封闭环境与外部数据源之间的桥梁。
智能合约概述
智能合约是一种特殊的计算机协议,其本质是一段存在于区块链网络中的代码。智能合约拥有确定性、有限性、规范性的特点。
智能合约作为区块链中重要的一部分,其核心功能是让用户能够定义对于账本操作的逻辑,提供丰富的数据类型和工具方法,让区块链用户能够灵活多样地对账本数据进行操作。
智能合约的生命周期是一个智能合约在不同阶段的体现,智能合约所有者可对智能合约的生命周期进行管理。智能合约的生命周期从一个智能合约被创建开始,直至该智能合约被销毁结束,主要分为部署、调用、升级、冻结、解冻和销毁等阶段。
(1)概念和定义
1、智能合约定义
智能合约最早是由美国计算机科学家Nick Szabo于1994年提出的,他在1998年发明了一种名叫“Bit Gold”的货币,该货币比比特币早发行了十年。Szabo将智能合约定义为执行智能合约的计算机化交易协议,他想把电子交易方法的功能扩展到数字领域。区块链智能合约支持创建无须信任关系的协议,这代表智能合约参与方节点可以通过区块链智能合约做出承诺,而无须对其了解或互相信任,从而通过智能合约消除对公证机构的需求,降低运营成本。
从协议上来说,智能合约是一种旨在以信息化方式传播、验证或执行合同的计算机协议。智能合约允许在没有第三方机构的情况下进行可信交易,这些交易可追溯且不可逆。
从本质上来说,智能合约是一段计算机逻辑代码,区块链用户之间的协议条款直接写入代码,这段代码及代码所达成的共识都存在于一个分布式的、去中心化的区块链网络中。当智能合约参与方节点发起对智能合约的调用交易时,智能合约逻辑会被执行引擎执行,最终保存智能合约执行产生的数据和结果,并生成一条可追溯且不可逆的交易记录。
2、智能合约特性
智能合约具有确定性、有限性和规范性,这些特性保证了区块链网络中各个参与方节点执行智能合约的过程是安全的,并且智能合约执行结果是一致的。
确定性
确定性即执行结果确定,在输入相同的情况下输出一定相同。
对于一段确定的智能合约逻辑,智能合约的确定性需要确保无论什么时候,一个确定的智能合约方法在输入相同参数的情况下,产生的执行结果输出是相同的(不考虑智能合约状态数据对执行结果的影响),此处的执行结果包括智能合约方法执行逻辑、对区块链账本的修改和结果返回值。确定性确保运行在不同区块链节点上的同一个智能合约的执行结果是相同的。假设一个智能合约是非确定性的,不同节点的执行结果有可能不一致,则区块链节点共识不一致。
造成一个智能合约是非确定性的因素有很多,如获悉系统时间戳、并发运行程序、生成一个随机数等非确定性执行结果的函数,智能合约在不同的时刻运行这些函数都可能造成执行结果的不一致;对于非确定性数据源,如访问外部URL获取查询结果,不同节点IP地址访问到的数据可能不同,也会造成执行结果的不一致。类似上述情况,在智能合约中都应该被禁止调用。
有限性
有限性即执行过程有限,一次智能合约执行占用的资源有限,包括时间和空间资源。
智能合约在设计时就应该考虑其在执行过程中对于资源占用情况的计算,此处资源占用主要从时间和空间两个角度考虑,时间指执行时间,空间指内存或磁盘的占用。智能合约在执行过程中不能让一次执行占用太多的资源,这样会影响整个区块链网络的运行。具体的限制措施在不同的智能合约执行引擎上有所不同。
例如,
- 以太坊采用Gas计费的方式,对智能合约执行的每条指令和申请的存储空间都进行定量计费,在限制执行Gas消耗上限的同时,智能合约执行者需要为产生的Gas费用付费
- Fabric使用容器化的执行引擎,模拟执行交易,将空间资源从区块链节点上剥离出去,通过限制执行时间来达到智能合约执行过程的有限性。
如果某次智能合约执行过程占用了大量的资源,那么节点系统资源将被大量消耗,从而导致系统性能下降,甚至整个区块链网络进入停滞状态。
规范性
规范性即智能合约编写规范,智能合约需要满足一定的编写规范,以满足执行引擎的运行条件,减少智能合约漏洞。
在“The DAO”事件发生后,智能合约的规范性和安全性得到了重视。最著名的规范性检查当属ERC20接口标准检查。
ERC20是以太坊智能合约的标准接口说明,如果智能合约的开发者没有完全按照这个规范来实现,那么将对开发的DApp带来不可估量的损失。例如,开发者在使用transfer函数的时候未声明返回值,有可能导致智能合约无法完成正常的交易与转账,所以开发者需要在实现转账操作的同时,增加目的地址非零检查等。
HVM智能合约会通过一系列接口的限定来规范智能合约的编写,否则智能合约将无法运行。
(2)智能合约架构
如下图所示,区块链智能合约架构一般包含以下几个部分:共识、执行和存储模块。
- 共识模块主要将交易进行定序后发送给执行模块
- 存储模块则保存智能合约执行产生的账本数据和区块数据
- 执行模块不仅需要串联共识模块和存储模块,还需要负责智能合约的执行。通常来说,执行模块包含智能合约执行引擎,为智能合约执行提供上下文环境和账本数据的读写支持。

智能合约需要先部署到区块链平台上,将智能合约和某个账户地址进行绑定,后续对于该智能合约上的数据改动最终都会保存到账本中对应的地址下。
区块链用户可以通过区块链平台的SDK发起智能合约交易,指定要调用的智能合约地址和智能合约方法参数,经过SDK编码后将交易发送给区块链平台。区块链节点在收到交易以后通过共识模块进行广播和定序,之后交由智能合约执行引擎进行交易验证。
智能合约执行引擎为智能合约构造了执行的上下文环境,提供了智能合约执行的参数和账本访问的接口;同时能够让智能合约管理者对智能合约的生命周期进行管理,智能合约的生命周期包括但不限于升级、冻结、解冻和销毁。智能合约执行引擎将智能合约逻辑交由智能合约执行器,并输入用户在交易中指定的智能合约方法名和参数。
智能合约执行器的实现相对多样,最常见的是栈式虚拟机,通过将智能合约编译为字节码的形式来执行智能合约逻辑。在智能合约执行过程中,可能会产生对区块链账本数据的读取和写入,以及通过Oracle预言机服务对外部可信数据源的访问,最终产生智能合约执行结果,进入提交区块阶段。在区块完成提交后,对应的账本数据修改将落盘,此时用户可以通过SDK查询智能合约执行结果,智能合约执行结果主要包括智能合约方法的返回值,可能还包括智能合约执行消耗的Gas、交易的哈希值等数据。
上述描述了智能合约架构的一种常见形式,不同的区块链平台在具体实现上有所出入。例如,
- 智能合约执行引擎可以有多种不同的架构,支持不同的智能合约语言。不同架构的执行引擎和账本的交互也有所不同。例如,EVM和HVM是两种支持不同智能合约语言的执行引擎,它们对于指令的定义也是不同的
- 同样地,智能合约中的执行模块也并非一定要包含智能合约执行引擎。例如,Fabric将智能合约执行引擎独立为背书节点(Endorser),执行模块只对执行结果的读写集进行冲突检查和合并。
(3)智能合约生命周期管理
1、生命周期概述
智能合约生命周期是从一个智能合约被创建开始,直至该智能合约被销毁结束。在智能合约存活的生命周期期间,智能合约管理者可以对智能合约进行升级、冻结、解冻等操作。
2、生命周期管理
智能合约生命周期管理需要一定的权限,在智能合约被部署后,一般智能合约所有者才拥有对智能合约生命周期管理的权限。对智能合约生命周期进行不同的管理操作,会对区块链节点产生对应的变更,最终体现在世界状态中,包括但不限于部署、调用、升级、冻结、解冻、销毁等。
部署
智能合约的部署就是创建一个智能合约账户,并将智能合约保存到区块链账本的智能合约账户中,只有用户将智能合约部署到链上之后,这个智能合约才可以被用户使用或被其他智能合约调用,如下图所示,在部署智能合约成功之后,智能合约状态将变为初始的正常状态。

调用
调用者角度的不同,可以将调用分为以下两种。
- 调用已经部署的智能合约:本质上就是调用部署在链上智能合约的某个函数。
- 跨智能合约调用:从一个智能合约中调用另一个智能合约的某个功能。
如上图所示,调用智能合约需要保证智能合约处于正常状态。
升级
升级智能合约就是在某一个特定的智能合约地址上,用新的智能合约替换旧的智能合约。如上图所示,升级智能合约需要保证智能合约处于正常状态,在升级之后,部署地址上的智能合约会被替换为新的智能合约。
在升级过程中也要注意一些问题。开发者在升级智能合约时需要遵循一定的升级规范,确保旧的智能合约的数据在新的智能合约中仍然能被访问到。
冻结
冻结智能合约后将禁止这个智能合约被调用,该行为一般是智能合约管理者才可以触发的。如上图所示,当智能合约被冻结之后,智能合约状态将转入冻结状态,无法再进行正常的智能合约调用和升级等操作。
解冻
解冻智能合约用于恢复冻结智能合约的正常状态,该行为一般是智能合约管理者才可以触发的。如上图所示,解冻智能合约后,智能合约状态将恢复为正常状态,可以进行正常的智能合约调用和升级等操作。
销毁
销毁智能合约即删除某个智能合约,在销毁智能合约之后,用户不能调用智能合约方法,也无法访问在账本中记录的智能合约状态数据,该行为只有智能合约管理者才能触发。如上图所示,在销毁智能合约后,该智能合约会从区块链中抹去,用户不能访问该智能合约,也不能调用其方法。
典型地智能合约执行引擎
智能合约执行引擎作为智能合约的运行环境,其主要职责是准确地运行用户编写的智能合约逻辑,一般智能合约执行引擎需要满足以下两个条件。
- 执行过程可终止,智能合约不能无限占用执行引擎资源而不释放。一般会通过智能合约执行的指令来计算Gas消耗,或者限制智能合约执行的时间。
- 安全执行环境。保证智能合约的执行不会导致程序崩溃,屏蔽执行过程中的随机因素,保证相同的输入会有相同的输出。
智能合约执行引擎还为智能合约执行提供上下文环境,包括账本数据的访问、外部数据的获取,最终将执行结果交由区块链共识模块进行全网一致性验证。
从智能合约执行引擎的架构来看,目前典型的智能合约执行引擎主要包括栈式执行引擎、解释型执行引擎和容器化执行引擎三类,不同架构的执行引擎有各自的优缺点,以下将分析不同执行引擎的设计原理、运行机制和典型应用。
(1)栈式执行引擎
1、设计原理
栈式执行引擎顾名思义,其核心概念就是通过栈数据结构来实现智能合约的执行流程。一般来说,栈式执行引擎会将智能合约编译成字节码指令的形式,而字节码指令记录的就是针对栈数据的操作,配合程序计数器,通过不断地操作数据入栈和出栈,最终执行出智能合约方法逻辑所返回的结果。
部分栈式执行引擎还会引入局部变量表和栈帧的概念,其目的也是辅助字节码指令的栈式执行过程。
- 局部变量表是一个能暂时存储数据的列表,可以保存智能合约方法参数或栈数据计算的中间结果
- 栈帧主要用于保存智能合约方法调用的调用栈信息和当前执行智能合约方法的上下文环境
当然这两个结构并不是必需的,单纯使用栈数据也能实现相应的功能。
2、运行机制
为解释栈式执行引擎的运行机制,我们以一段伪代码来解释字节码指令的运行过程。
func int add(int a, int b) { int c = a + b; return c; }
同时我们定义一系列字节码指令并规定其行为,如下表所示。

根据上表中对于指令行为的定义,上述伪代码经过编译器编译后最终会表现为如下指令行为。
load 1 // 将参数a加载到栈顶; load 2 // 将参数b加载到栈顶; add // 将栈顶的a和b出栈,a+b后将结果存入栈顶; store 3 // 将a+b的结果出栈,并将结果赋值给变量c; load 3 // 将变量c加载到栈顶; return // 将栈顶元素c作为结果返回。
假设执行上述伪代码输入参数为1和2,那么执行add(1, 2)的过程如下图所示。

栈式执行引擎通过程序计数器记录当前正在执行的指令,最终根据智能合约编译后的指令做出相应的指令操作。当然,不同的栈式执行引擎会有不同的栈式结构和指令定义,但是基本原理与上述执行过程相同。
栈式调用在智能合约停机和安全控制方面比较容易,可以通过指令执行的次数和指令对应的权值计算出智能合约执行的复杂度,定量控制智能合约的执行“时间”,从而保证在多个不同的执行环境下执行相同的智能合约,其执行复杂度一致;安全控制方面则可以通过禁用系统调用指令和方法的形式来控制,包括去除可能造成随机因素的调用,从而保证执行结果的一致性。
3、典型应用
EVM
Solidity是一门图灵完备的智能合约语言,需要被编译器编译成字节码指令,运行在EVM(以太坊虚拟机)上。Solidity和EVM的出现,使得编写智能合约变得十分容易,让很多基于区块链的DApp大放光彩,推动了区块链智能合约的发展。
Solidity通过solc编译器可以编译输出两种格式的文件:bin和abi。
- bin文件为智能合约的字节码文件,用户将智能合约对应的bin文件部署到区块链上,通过abi文件编码参数进行智能合约的调用。
- EVM执行引擎会解析出用户调用的智能合约方法,逐条执行bin文件中的指令,整个执行过程基于一个操作数栈进行,同时在EVM中采用一个Memory结构来存储操作数栈执行过程的中间执行结果,即上述原理描述中的局部变量表的作用。
Solidity从设计初期就作为智能合约语言来考虑,其在账本操作上有较大优势。智能合约中需要进行的账本操作可以在编译阶段将其翻译为账本操作指令SSTORE和SLOAD,分别存储和读取账本数据。在EVM中的最小slot(数据槽,用来存储数据的字节组合)为32字节,因此,对于Solidity中的静态类型,如int、uint和byte32等,其最多只会占用一个数据槽,获取完整数据只需要进行一次账本操作;而对于动态类型,如string、bytes和map等,其会将数据进行拆分,并依据数据大小建立索引,一次完成的数据读取涉及多次账本操作,需要从多个数据槽中恢复原始数据。
WASM
WASM(WebAssembly)是一种新的字节码格式,最初是为了解决JavaScript在浏览器上复杂逻辑执行效率不高的问题,从而在浏览器变得越来越重要的时代使WASM支持更多的功能,如网页端游戏和图像处理。WASM字节码简短高效,使得主流语言如C/C++、rust和Go开始支持编译为WASM字节码,将原代码编译成WASM字节码,并且在WASM字节码解释器上执行。WASM字节码解释器既能做到高效执行,又能支持多种主流语言,越来越受到区块链项目的青睐,拓展区块链使用高效多智能合约语言的可能性。而WASM执行引擎本质上还是一个栈式虚拟机,典型实现包括操作数栈、局部变量表和程序计数器。WASM字节码执行器通过程序计数器获取当前指令,当前指令定义一系列对操作数栈的操作,同时使用局部变量表保存产生的中间数据。
由于WASM不像Solidity一样能够通过编译器增加账本访问指令,以支持对区块链账本的访问,所以为了能够将WASM字节码和区块链系统整合起来,需要为WASM编写的智能合约提供能访问区块链网络的账本数据接口。WASM字节码提供导入模块功能,通过自定义账本访问模块,使用native方式实现模块内容,从而将账本接口和WASM执行引擎结合起来。在智能合约中引入账本访问模块即可在智能合约执行过程中操作账本数据,具体的智能合约账本模块接口的定义形式可以根据不同的区块链平台进行修改,具有较大的灵活性。
HVM
HVM(HyperVM虚拟机)是基于趣链区块链平台开发的智能合约执行引擎,其实现基于《Java虚拟机标准规范》开发的JVM执行引擎,能够运行用Java编写的智能合约。Java智能合约在经过javac编译后会形成class字节码文件,每个Java类文件都将被编译成一个class文件,多个class文件经过压缩可形成智能合约jar包,智能合约jar包通过趣链区块链平台SDK部署到链上。当调用智能合约时,HVM按《Java虚拟机标准规范》解释执行智能合约方法的字节码,使用栈帧来记录Java智能合约方法的调用关系,每个栈帧中都记录局部变量表和操作数栈,局部变量表保存智能合约方法参数和操作数栈执行过程的中间执行结果;操作数栈为智能合约方法指令执行提供必要的场所。
HVM和WASM执行引擎面临一样的问题,需要能够让Java编写的智能合约访问区块链账本,依赖Java提供的native方法机制(JNI接口),HVM可以将部分Java的智能合约方法通过JVM虚拟机底层实现,而不是直接通过JDK实现。通过native实现的JVM虚拟机底层实现方法,实现封装对区块链账本访问的接口。进一步地,HVM为了让智能合约编写者能够更方便地访问区块链账本,将区块链账本操作封装成HyperTable、HyperMap和HyperList结构,使智能合约中对于账本的访问方式如同访问Java的集合类型。
(2)解释型执行引擎
1、设计原理
基于解释型执行引擎的智能合约区别于传统的区块链智能合约,其最大的特点是每笔交易都包括一个执行脚本,执行脚本内指定了当前交易的账户对象和对应的操作逻辑,而不是在交易结构中指定交易的账户对象。一笔交易的交易脚本每次都可以被修改,并且可以在交易脚本中操作多个账户对象,解释型执行引擎将根据交易脚本中定义的逻辑执行,而不是执行某个智能合约账户下的智能合约逻辑。交易脚本大大增加了交易执行的灵活性,可以为每笔交易自由制定逻辑。
2、运行机制
解释型执行引擎按照区块链平台要求编写对应的交易脚本后,将其作为payload(交易执行逻辑),由交易发送方对自定义的交易脚本进行签名,发送至区块链平台,最终解释型执行引擎会依据交易脚本中的逻辑进行交易验证,不同的解释型执行引擎有不同的实现,对应的交易脚本编写也有不同的形式。
3、典型应用
Move语言是Facebook的区块链平台Libra上定义的交易脚本语言,旨在为Libra区块链提供安全可编程的基础。Libra区块链中的账户是一个容器,它包含任意数量的Move资源和Move模块(Modules)。提交到Libra区块链的智能合约执行交易包含用Move语言编写的交易脚本,交易脚本可以调用模块声明的过程来更新区块链的全局状态。
对于Move语言,其主要特点如下。
- Move交易脚本启用可编程的交易。
- 每笔Libra区块链上的交易都包含一个Move交易脚本,这个脚本用来验证客户端编码的执行逻辑(例如,将Libra币从Alice的账户转到Bob的账户)。
- Move交易脚本通过调用一个或多个Move模块与Libra区块链全局状态中发布的Move资源进行交互。
- Move交易脚本不存储在区块链的全局状态中,其他Move交易脚本也无法调用它。这是一次性使用的程序。
- Move模块是可组合的智能合约。
- Move模块定义了更新Libra区块链全局状态的规则,其等价于其他区块链系统中的智能合约。
- Move模块声明可以发布在用户账户下的资源类型。Libra区块链中的每个账户都是一个容器,可以容纳任意数量的Move资源和Move模块。
- Move模块同时声明了结构类型(如资源,这是一种特殊的结构)和过程。
- Move模块声明的过程定义了创建、访问和销毁其声明类型的规则。
- Move模块可重复使用。一个Move模块中声明的结构类型可以使用另一个Move模块中声明的结构类型;一个Move模块中声明的过程可以调用另一个Move模块中声明的公开过程;Move模块可以调用其他Move模块中声明的公开过程;Move交易脚本可以调用一个已发布Move模块的任何公开过程。
- Move模块有一等资源。
- Move模块的关键特性是能够自定义资源类型。资源类型用于对具有丰富可编程性的安全资产进行编码。资源是Move语言中的普通类型值。其可以作为数据结构用于存储、作为参数传递给过程、从过程中返回等。
- Move运行系统为资源提供特殊的安全性保证。Move资源永远不会被复制、重用或丢弃,资源类型只能由定义类型的模块创建或销毁,这些保证是由Move虚拟机通过字节码验证器静态执行的。Move虚拟机拒绝运行未通过字节码验证的代码。
- Libra货币由名为Libra::T的资源类型实现。Libra::T在语言中没有特殊的地位,每个Move资源都享有相同的保护。
总的来说,Move模块相当于传统区块链上的智能合约,在Move模块下可以自定义资源,一个账户可以有多个Move模块,Move虚拟机通过字节码验证器保证Move资源的安全性。用户编写Move模块后将其编译,再通过交易的形式将其发布到区块链账户地址上。Move交易脚本可以调用Move模块中声明的公开过程。
如下图所示,Move交易脚本组合了一个或多个Move模块调用的逻辑,经过编译后将逻辑发送到链上虚拟机执行,在Move交易脚本中指定要调用的已发布在某个账户下的Move模块中的公开过程,而非传统区块链在交易中指定要执行的智能合约地址。执行之前,Move执行引擎将对Move交易脚本进行反序列化,解析为Move虚拟机的字节码,Move虚拟机通过操作数栈Stack来完成Move交易脚本字节码中定义的数据操作,使用CallStack(调用栈)来记录Move交易脚本的方法调用过程,同时通过计算执行指令的Gas定量计算智能合约的复杂度,用户需要为Move交易脚本执行过程付费。

(3)容器化执行引擎
1、设计原理
容器化执行引擎最大的特点是逻辑和数据隔离,其实现相对比较简单,不需要实现虚拟机来执行智能合约逻辑,取而代之使用容器作为智能合约执行环境。容器化执行引擎可以提供一个安全的沙箱环境作为容器,直接在容器中运行用户编写的智能合约,而不同的智能合约语言只需要提供不同的容器和对应语言的账本操作API。由于整个过程在容器中运行,因此执行过程不会影响到区块链网络,用户只需要收集在容器中执行的模拟操作账本读写集。
2、运行机制
容器化执行引擎一般接收客户端发送的智能合约执行请求,通过容器化环境直接将智能合约逻辑放入容器,通过对应语言的账本操作API在容器中访问账本,此时一般不会将智能合约执行结果直接写入账本,而是执行模拟操作账本的读写集后将结果返回客户端,客户端需要再次发起将模拟交易产生读写集写入账本的请求。由于容器化执行引擎执行智能合约逻辑一般native化,所以不能采用定量分析智能合约复杂度的形式,而是采用超时机制来限制智能合约复杂度。
3、典型应用
容器化执行引擎最具代表的就是Fabric链码(Chaincode),如下图所示,Fabric的执行引擎核心组成主要包括
- SDK(Soft Develop Kit,软件开发工具)
- 排序节点
- 背书节点(Endorser)
- 容器化执行引擎
- 账本
首先,由客户端(Application)生成一个提案(Proposal),提案指的是一个调用智能合约功能函数的请求,用来确定哪些数据可以读取或写入账本(一般应用程序会借助目前Hyperledger Fabric提供的一系列SDK生成Proposal),将提案发送至背书节点进行模拟执行并背书,背书节点会进行相应的校验,然后将提案交由对应的链码进行模拟执行,之后背书节点会对执行结果进行背书,将背书的提案响应(Proposal Response)返回客户端,随后,客户端收集符合背书策略的提案响应,将其封装成一个交易(Transaction),调用排序节点的Broadcast接口,发送交易至排序节点。排序节点对交易进行排序后通过主节点将交易转发给其他节点,最终每个提交节点在收到交易之后都会对交易进行校验,包括签名、背书策略及链码模拟执行产生的读写集的校验,在校验无误的情况下将结果提交到账本,同时更新世界状态。
容器化执行引擎虽然能够做到逻辑和账本隔离,并且支持多智能合约语言,但是其缺点也是很明显的。
- 首先,由于容器化执行导致智能合约逻辑的复杂度无法定量控制,依赖超时机制,因此很有可能导致多个背书节点的容器化执行引擎受到系统环境的影响,出现部分背书节点超时、部分背书节点不超时的情况
- 其次,采用Fabric链码模拟执行产生读写集,通过读写集冲突校验判断,抛弃产生冲突的交易,可能导致用户执行的智能合约结果最终无法生效
- 最后,对于客户端来说,需要收集多个背书节点的提案响应才能构成交易,导致客户端与服务器端交互逻辑复杂,使用体验不够友好。

智能合约与分布式应用
(1)DApp
1、DApp概述
DApp全称是Decentralized Application,即去中心化应用。
很多人,包括一些区块链开发者一直以来都对DApp有一个误区,那就是认为DApp将彻底取代App,这是对DApp从根本上的一个认知错误,没有搞清楚DApp与App的区别和优劣势。区别于App,DApp以区块链为基础设施,不依赖任何中心化服务,其最大优势就是去中心化、完全开源、自由运行。在引入这些优势的同时,DApp相较于App也有一些不可忽视的劣势。例如,基于区块链开发DApp需要开源智能合约源码,黑客能够获取DApp背后的智能合约的具体逻辑,这加大了DApp被攻击的风险,使代码面临更大的安全威胁。同样地,去中心化、自由运行的特点在一定程度上提高了监管、审查的难度,还有许多其他问题。
二者并不是谁替代谁,谁淘汰谁的互斥、取代关系,而是针对不同场景发挥各自优势,共同促进互联网繁荣的并存关系。简单来说,DApp是对App的丰富与完善。
区块链开发者要把握好DApp的优势,解决App无法解决的市场与技术矛盾。目前,市场高热度的DApp主要有去中心化交易所(Exchange)、游戏(Game)等与交易数据、交易资产有直接关联的应用,DApp本身具有不可篡改、去中心化存储的特性,用户不需要担心交易资产的安全性,可以完全信任DApp进行交易。
2、DApp应用
截止到2020年第一季度,根据权威网站统计,共有约3500款DApp,Game、High-risk的DApp数量分别以22%、21%的高占比位列前三。其中,Game的日活跃DApp数量排名第二,High-risk稍微落后占据第三位。Exchange和Finance的DApp虽然在数量上占比只有4%,但Finance的DApp日活跃用户量排名第一、日交易量排名第二,而Exchange的DApp日交易量则排名第一,可以推断,这两类也是DApp目前较为活跃的市场领域。根据这份报告我们可以看到,目前DApp能够大展身手的领域大部分集中在与交易资产有关联的领域,如上文提到的High-risk、Exchange、Finance,这几类DApp从名字上就能看出涉及交易资产的交换和获取,而Game中最为出名的就是CryptoKitties(以太坊养猫),在保证游戏趣味的基础上,用户通过对猫咪进行短期或长期投资来赚取代币,与交易资产依然有不可分割的联系。
下面简单介绍几款比较知名的DApp。
- CryptoKitties(Game,以太坊)。CryptoKitties是一款虚拟养猫游戏,于2017年11月28日正式上线。用户可以通过购买、培育、繁殖,得到并收藏拥有不同特征和属性的猫咪,也可以通过交易卖出猫咪获取以太币,猫咪的价格会随市场需求而变化,当游戏热度高时价格随之升高,当用户流失时价格不断降低。
- Oasis(Exchanger,以太坊)。Oasis是一款Exchanger DApp。2019年下半年,Oasis正式上线Oasis Trade交易所,推出Dai——和美元保持1:1汇率的去中心化的稳定币,Oasis Trade交易所支持Dai和多种数字货币、虚拟货币进行交易,支持去中心化借贷存款。用户想要使用Oasis上的资产,只需要通过以太坊钱包。Dai的发行由链上资产进行抵押,经过严格的形式化验证和审计,具有非常高的安全标准。
- 飞洛印(Others,趣链区块链平台)。飞洛印是一款基于高性能的企业级联盟链——趣链区块链平台开发的可信存证DApp,其主要目标是做好强司法保障、提高司法效率、构建线上司法生态。从细节功能上划分,飞洛印制定了证据获取、证据固定、证据管理、证据调用一整套证据的生命周期管理方案,提前保护了数据,实现了数据证据确权、不可篡改。此外,飞洛印还支持数据公示,网页、手机取证,确保数据实时有效。
- 供应链金融(Finance,趣链区块链平台)。中小企业融资贵、融资难已经成为世界性问题。融信链项目团队以区块链技术赋能供应链金融,独创CreditToken核心技术,在供应链金融应用场景下,保证多层交易可追溯、交易风险全隔离,实现融资票据可拆分、可验证、可多级转让,大力创建安全、透明、可信的供应链金融生态。融信链项目集企业运营监控和票据融资于一体,普遍降低中小企业6%的融资成本,开发企业资产,强化社会征信网络,以金融科技赋能实体企业。
(2)预言机
1、预言机概述
什么是预言机?预言机是区块链这个封闭环境与外部数据源的纽带,其需要满足两个功能:
- 获取外部数据
- 确保获取到的数据不被篡改
从不同的角度来看,预言机又有不同的定义,
- 从计算机的角度出发,预言机是一个图灵机,能够解决任何决定性和功能性问题。
- 从区块链的角度来看,预言机是一个数据组件模块,扮演中间件的角色,负责区块链和外部数据源交互。
为什么区块链需要预言机?虽然区块链有去中心化、不可篡改、可追溯等优势,但其有一个本质的缺陷,那就是区块链是一个封闭的、确定性的沙箱环境。在这个环境中,区块链只能获取链上的数据,链上的数据都是被动输入得到的,并且区块链在运行智能合约的过程中无法对外部请求获取新数据,只能基于已有数据以一种确定性方式产生新数据,不能有与网络相关或涉及硬件相关的调用。
根据这个描述可以发现,区块链和外部是一种隔绝的状态,然而区块链上的智能合约和DApp对外部数据又有强烈的交互需求,这与智能合约的执行环境产生了矛盾。预言机就是为解决这个矛盾所诞生的,通过预言机,智能合约可以主动获取外部数据,如追踪快递信息、获取机票实时价格等,并对此类数据做相应的处理、存储,并且整个过程有可靠保证,无法被篡改。
预言机有何价值?
- 预言机的出现打破了区块链封闭的运行环境,打通了其与外部数据源的交互通道,提高了区块链对于外部数据的感知度,为区块链建立了新的赋能方式。
- 预言机确保数据不会被篡改,在打通交互通道的基础上维护了区块链的一致性、安全性,真正实现并建立了数据获取、组织、管理、存储与交互这一条完整的生态链。
- 通过将预言机引入区块链,可以增强区块链应用的可移植性,支持更多、更丰富的业务场景或数据操作,保障区块链应用真正落地,实现智能合约的利益价值最大化。
综上所述,预言机作为一个可信的第三方数据中间件模块,和区块链共同发力,解决了区块链无法与外部数据交互这一发展痛点,提升了区块链的价值转化。我们有理由相信,在未来,预言机将会加速区块链技术的发展,并与区块链技术一同摸索,构建更完善的DApp和生态。
2、架构模型
区块链的安全性、确定性源于它的封闭环境,而预言机打破了这一封闭环境。在分布式场景下,预言机如何保证获取的外部数据仍是可信且一致的呢?另外,区块链执行引擎如何与预言机交互并对外部数据源进行数据请求?预言机又如何将其获取的数据返回区块链执行引擎?
本节先通过一个通用的架构模型图为读者朋友展示预言机和区块链执行引擎的基本交互流程,再分别讲述预言机内部的架构技术。
下图为预言机架构模型图,以帮助读者理解预言机如何与区块链执行引擎通力合作,打通与外部数据源的交互通道。

如上图所示,预言机一般会作为区块链的一个独立模块或第三方服务与区块链执行引擎进行交互。预言机只负责数据的可信获取,不直接参与交易的执行。
- 首先,用户通过智能合约调用的形式(也可以通过特殊的API服务等其他方式发起预言机服务请求)发起预言机服务请求,通过调用某个内置智能合约接口,告知区块链执行引擎,用户想要执行一笔含预言机服务的交易。
- 区块链执行引擎在执行过程中检测到对预言机的服务请求,通过内部通信组件将该请求转发给预言机,这个请求里会封装请求外部数据源的一些信息,如一个Web数据请求、常见的URL、HTTP Headers等信息。
- 预言机在收到服务请求后,向外部数据源发起数据获取请求,获取数据后利用交易生成器生成一笔新的回调交易,并对其进行签名(这一过程使用TEE等硬件技术保障安全性及不可篡改)。
- 最后,预言机将这笔回调交易发向区块链执行引擎,对获取的数据执行组织、管理、存储等一系列操作,至此,一个完整的含预言机服务的区块链交易执行流程结束。
根据上述生命周期流程可以得知,预言机在设计过程中最需要考虑的两个要素分别是数据获取和可靠保证。
1)数据获取
预言机需要提供获取外部数据的功能。预言机本身应该拥有能够获取链上和链下(外部)数据的能力,由于预言机的提出就是为了打通区块链与外部数据源的交互通道,因此这里主要阐述预言机对外部数据的获取。
在实际的数据获取过程中,开发者开发预言机时需要满足以下几点。
- 对外部数据源的选取和可信认证。预言机需要谨慎选择外部数据源,必须保证对每个选取的外部数据源,都可以验证其是可信的,如对于Web的数据获取,选取的外部数据源需要持有证书。
- 制定外部数据获取的标准流程。开发者必须明确执行引擎、用户、外部数据源与预言机的数据交互流程,对于不同的外部数据源类型要能够统一或明确区分数据的交互流程,确保交互方案可执行、可落地。
- 统一定义数据获取过程中的数据交互格式。不同的外部数据源类型有不同的数据交互格式,以传感器为外部数据源和以Web为外部数据源获取的数据交互格式是不一样的,针对这两种情况,预言机需要有明确、统一的数据编解码层,以对不同外部数据源的数据进行请求和解释。
2)可靠保证
预言机需要提供一种可靠保证机制保证自己的数据未经过篡改。针对不同的外部数据源,预言机需要提供不同模式的可靠保证机制。例如,网络连接时需要使用TLS协议,与安卓应用交互数据需要SafetyNet技术提供保障。
预言机需要分别对两个阶段做数据的可靠保证。
- 第一个阶段为数据从网上到本地,普遍采用HTTPS协议(底层采用TLS协议)保障连接和数据的正确性、完整性
- 第二个阶段为数据从本地到链上,预言机采用TEE,TEE是CPU内的一块安全区,它从硬件入手,和操作系统独立运行,同时使用硬件和软件技术确保数据的机密性、可靠性。
3、技术分类
在最底层的技术基础和安全设施上,不同的预言机实现之间比较相似,大多都采用TEE,但根据区块链应用场景和市场的不同,预言机上层的技术架构和模型也会有非常大的差异,主要分为中心化预言机和去中心化预言机两类。
其中,中心化预言机由于其中心化思想,必须引入第三方机构,如国家或能提供背书的大型企业,验证方式也通过第三方机构独立验证。以Oraclize为例,作为一个中心化预言机,Oraclize通过TLS协议实现Web数据的可靠传输,并结合Intel SGX确保数据在本地不可篡改,Oraclize给用户提供了API,用户只需要调用预先设计的智能合约接口,就可以使用预言机服务获取Web数据。Oraclize是中心化预言机,作为一个独立的单点模块,这样的实现具有高性能的优势,但同样有单点故障、难以拓展的风险,并且中心化思想与区块链的去中心化理念背道而驰。
相反地,去中心化预言机秉持着与区块链相同的去中心化理念,使用多重签名或分布式算法保证数据的正确性、一致性,不需要引入第三方机构,但其在实现上更困难,性能也成为瓶颈。以Chainlink为例,它是一个去中心化的分布式预言机,建立了一个去中心化的数据网络,每个预言机都是网络中的一个节点,其架构分为链上组件和链下组件。链上组件负责和用户交互,收集、响应用户请求,而链下组件是之前提到的数据网络,用于处理数据获取和传输。在这个架构中,由于Chainlink是一个分布式数据网络,所以可以避免单点故障的问题,但同样地,因为增加了分布式的数据一致性需求,所以其性能和实现难度成为了新的难题。
由上面的介绍可以得出,中心化预言机和去中心化预言机最大的差异在于中心化预言机由单机负责数据获取,需要引入第三方机构;而去中心化预言机是多机并行,通过互相验证保证一致性。因此,中心化预言机适用于对实时性要求高、对可用性要求没那么高的场景;而去中心化预言机适用于对实时性要求没那么高、对可用性要求高的场景。
小节
本章介绍了区块链中智能合约的概念,以及不同的智能合约执行引擎之间的差异。智能合约作为区块链账本的表现形式,为区块链用户提供了多样化的账本操作逻辑,让区块链账本的表现形式不再单调,拓展了在区块链上可发展的业务场景。同时,通过接入预言机服务为智能合约提供了获取外部数据的功能,打通了链上和链下的数据交互通道,进一步提升了区块链的应用价值。
扩容问题概述及分析
区块链扩容问题一直是近年来区块链领域最热门的问题之一,引起了区块链社区广泛的讨论和研究,目前,区块链业界和学术界都密切关注此问题,从共识算法、系统架构、网络组织形式等多个方向出发,提出了许多解决方案。
一开始,区块链扩容问题指的仅是区块扩容问题。在比特币最初的设计中,并未对区块大小设置上限,而且当时参与挖矿的节点多为个人计算机,网络带宽和机器性能有限,比特币的使用场景与使用人数也有限,实际上并不需要过大的区块容量。当时比特币价格低廉,在不设置区块容量上限的情况下,恶意攻击者只需要付出微不足道的代价,就可以创建大量交易对比特币系统进行DDOS攻击。在多方考虑下,中本聪为比特币的区块容量加上了1MB的上限。随着比特币用户的增加,交易量不断上升,区块大小不断逼近1MB上限。为了让交易能尽快得到确认,用户付给矿工的交易费也日益增加。自然地,使用比特币进行小额交易已经不再合适了,因此,区块链扩容问题被顺势提起。
尽管比特币是一个较为完善的去中心化电子现金系统,但其仍然有很多局限性,无法将区块链与现实生活中复杂的实际业务场景相结合。2014年,以太坊的出现改变了这一现状,随着账户结构模型和智能合约的提出,区块链能够执行更为复杂的业务逻辑,大大拓展了区块链的应用场景,使得以去中心化区块链应用为代表的区块链2.0阶段正式到来。随着区块链技术的进一步发展,区块链根据开放程度的不同,细分为公有链、联盟链及私有链,而联盟链与私有链对于区块链的应用场景需求比起公有链更加多样化,对区块链系统的整体性能提出了更高的要求。区块链系统也需要从单纯的电子现金系统转变,向成为“去中心化超级计算机”这一目标努力。
目前,区块链系统的性能和容量不足以支撑如此复杂的业务场景。因此,区块链扩容问题的边界越来越大,现在已经成为一个更加广义的问题——如何使区块链系统的性能和容量得到显著提升,从而成为一个大容量、高交易吞吐量的基础设施。通俗地说,就是怎么让区块链系统“跑得更快,存得更多”。具体到区块链系统的实际指标上,最能体现扩容问题的为两项指标:
- 交易吞吐量
- 存储容量
(1)交易吞吐量
交易吞吐量最主要的性能指标为TPS(Transactions Per Second,每秒事务处理数量)。TPS通常用来描述计算机系统每秒钟能够处理的事务或交易的数量,是衡量系统处理能力的重要指标,也是软件性能测试的重要测量单位之一。在区块链场景中,TPS被用来描述区块链系统的交易处理速率,显而易见,TPS越高,系统处理交易的能力就越强。
目前,比特币、以太坊这两个最具有代表性的公有链项目的TPS仍远低于100,以Hyperledger Fabric、趣链区块链平台为代表的联盟链项目,在实际应用场景中也仅有千级TPS。而在数年前,支付宝、Visa等成熟的支付工具就已经达到万级甚至十万级TPS,至于成熟的数据库系统如阿里云自研数据库POLARDB,更是在2019年的“双11”活动中达到了8700万TPS的峰值。虽然区块链系统的优势并不在于交易吞吐量,但是过低的交易吞吐量毫无疑问会对区块链应用场景造成非常大的限制。
在公有链场景中,低交易吞吐量的情况实际上是很难改善的。在传统的链式结构区块链系统中,所有节点数据都需要与主链数据保持一致,而公有链目前采用的PoW或PoS等共识算法,需要由全网的出块节点竞争出块,但由于整个区块链系统内存在网络的传播延迟,区块数据不能及时到达全网。因此,如果共识算法设定的出块速度过快,则可能有部分节点在还未收到主链更新信息的时候就完成了相同区块号的计算,此时区块链网络便会对同一个区块号生成多个有效区块,从而导致主链分叉。因此,如果出块速度过快,则会增加系统分叉率,直接对系统的安全性造成影响,既浪费了算力,又使系统的安全性受损。因此,通过增大出块速率或区块容量来提高交易吞吐量的区块链扩容方案,通常来说并不能解决根本问题。
目前,业界有如以太坊二次方分片等方案对区块链进行架构上的变更,以解决交易吞吐量问题,但如何在交易吞吐量、系统安全性和去中心化之间保持平衡是一个非常重要的课题;也有如Conflux等方案,采取完全异构的区块链架构尝试解决这一问题;链下扩容也是近年来许多解决方案尝试的方向,在不改动区块链本身规则的基础上,建立第二层交易网络,对区块链性能与功能进行扩展。
而联盟链或私有链对节点准入进行了限制,节点数量有限,目前普遍采取拜占庭容错类算法。然而传统拜占庭容错算法复杂度极高,在出块的过程中需要经过大量协作,涉及大量数据通信,算法复杂度至少为O(n2),限制了此类算法的出块速度。近期提出的HotStuff算法将算法复杂度从O(n2)降至O(n),但是其每个验证节点都增加了许多签名与验证签名的负载,将网络通信压力转移至单节点性能压力。不过,相对于公有链,联盟链共识算法的效率已大大提升,此时交易吞吐量的瓶颈已从共识算法向单节点性能转移。
在目前的系统架构中,所有节点都需要进行全部交易的签名验证、按序执行及存储。为进一步提升交易吞吐量,联盟链/私有链系统需要对这三点进行优化。
- 签名验证的主要瓶颈在于计算资源有限,尝试将签名验证并行化,或者通过硬件进行验签加速都是可行的方案
- 按序执行为目前区块链系统架构所限制,可以通过交易并行执行、分片执行等方式进行执行加速
- 存储主要是由目前区块链系统存储结构简单、使用单一数据库造成的,此问题实际上与交易执行架构密切相关,以上两个问题通常要在一起思考。
(2)存储容量
目前,存储容量这一问题的社区关注度远远小于交易吞吐量,主要是因为当前主流的公有链系统受限于交易吞吐量,使得存储容量这一问题还未暴露。
在目前的以太坊网络中,一个全节点的整体存储容量根据客户端类型的不同在270~360GB之间,而为了保证出块性能,一个需要出块的节点通常需要在内存中存储5~10GB的账本数据。一旦以太坊的交易吞吐量问题得以解决,那么全节点存储容量将以极快的速度膨胀,使互联网上大部分服务器无法部署一个全节点,大大抬高全节点的参与门槛,直接导致去中心化程度的降低,直接影响区块链的根本特性。因此,如何扩展存储容量是未来公有链必须解决的问题。目前,以太坊展开了二次方分片等方案,希望通过状态分片可以同时解决交易吞吐量与存储容量问题。
而联盟链或私有链系统,如趣链区块链平台,在共识算法出块速率得以提升之后,遭遇过存储容量这一问题。现阶段区块链的基础结构较为简单,通常在底层采用单机数据存储引擎,如LevelDB,进行持久化存储,但是联盟链或私有链通常作为企业级商用系统,整体数据量极大,数据库存储读写性能将随着数据量的膨胀受到严重影响。此外,由于使用单机数据存储引擎,因此,在数据量不断增大的情况下,只能通过机器升级缓解存储压力,无法进行横向分布式扩展。
因此,对区块链数据进行一定的分析,将区块链数据分库、分表进行存储并接入分布式数据库势在必行。
链上扩容
链上扩容作为一种技术手段,主要是解决上述区块链交易吞吐量低、存储容量受限的问题。很多区块链系统或产品在“链上扩容”方面进行了积极的尝试。目前,主流的链上扩容设计思路可以归纳为以下三类:
- 区块扩容。区块扩容通过增大区块的交易或系统出块速率提高交易吞吐量,是一种最为直观的链上扩容方案
- 并行扩容。并行扩容的思路是尽可能使系统中的交易并行执行,打破交易按序串行执行带来的系统性能瓶颈,最终提高系统的交易吞吐量
- 架构扩容。架构扩容主要指使用有别于主流“单节点执行全量交易、存储全量数据,最终形成一条区块链”的设计思路,设计新型块链架构模型和存储模型,为区块链系统提供较强的横向拓展能力,最终达到扩容的目的。
(1)区块扩容
区块扩容是一种最为直观的扩容方案,根据交易吞吐量的计量方式,在相同时间内,区块中的交易量越大,生成的区块越多,交易吞吐量越高。区块扩容就是基于这样的思路产生的一种链上扩容方案。在不更改当前任何架构和逻辑的情况下,通过调整系统的出块速率提高交易吞吐量。
1、增大区块
在目前的区块链系统中,区块的大小由系统内规定的一些协议确定。例如,系统中明确配置指明区块中交易量的大小上限或区块的大小上限,或者通过节点投票等形式决定区块的大小上限等。增大这些“上限值”,可以在一定程度上实现区块扩容。但是这种类似区块大小、区块交易总量等系统级别的限制,是不可能无限增大的,过大的区块会增大参与出块的节点执行、验证交易的压力,当压力增大到一定程度后,交易吞吐量反而呈减小的趋势。此外,数据量越大的区块在网络中的传输延迟越大,当区块数据量增加到一定程度后,网络传输能力会成为新的系统瓶颈。因此,这种方案虽然比较直观,也很方便实践,但其扩容能力有限。
在区块扩容方面,比特币系统做过很多尝试。随着比特币网络的关注量日渐升高,以及矿池技术的发展,比特币网络中逐渐出现了交易拥堵的现象,因此,比特币的扩容需求日渐迫切。比特币网络希望以区块扩容的方式解决该问题。2016年的“香港共识”会议、2017年的“纽约共识”会议都提出了将比特币区块容量上限调整至2MB的建议,但最终都被BitcoinCore拒绝。
2017年8月1日,通过在比特币网络上产生硬分叉,诞生了比特币现金,比特币现金在分叉链上将区块容量上限提升为8MB;2018年5月,比特币现金又通过硬分叉将区块容量上限提升至32MB,等等。类似的尝试还有很多,这里不再一一列举。
总体上看,关于比特币网络的区块扩容方案已经有很多提案,如BIP100-BIP107、BIP109等。但区块的大小会直接影响矿工的实际利益,同时直接关系网络中全节点的存储资源,各方的利益冲突使得比特币网络的扩容问题至今仍然是一个争论不休的话题。
2、增大出块速率
增大出块速率也是一种直观的链上扩容方案。如果系统在相同时间内可以打包更多的区块,那么交易吞吐量自然可以得到提升。但是这种方案同样存在问题。
- 首先,对联盟链场景而言,在不考虑区块链分叉的情况下,当出块速率增大到一定程度以后,网络带宽会被区块传输、共识过程中的频繁网络交互占满,网络传输能力会成为新的系统性能瓶颈。
- 同时,增大出块速率,必然会增加区块验证过程的计算资源消耗,交易的执行与验证容易成为系统性能瓶颈。
因此,在联盟链场景下,增大出块速率,实质上是一种将系统性能瓶颈由共识模块向执行或网络模块转移的思路,并不能从根本上解决问题,交易吞吐量最终还是会达到上限。
而在以太坊等公有链场景下,使用降低挖矿难度等手段来增大出块速率,虽然看起来可以提升系统的瞬时交易吞吐量,但是,在网络传输延迟不改变的情况下,降低挖矿难度必然会由于矿工竞争出块,增加系统分叉概率;而分叉概率的增加,又必然会降低最长链的增长速度,因此,区块的最终确认时间会延长。更重要的是,当出块速率增大后,更多的诚实节点会由于网络传输延迟等因素,不能及时发现系统中最新的区块,而继续挖出导致区块链分叉的区块,导致系统的算力并不能有效地向最长链集中,恶意矿工通过构造分叉链来夺取系统的最长链也变得更加容易。
考虑一种极端场景,当挖矿难度极低以至于矿工挖矿耗时低于网络传输区块的延迟时,每个矿工都会在自己挖出区块后不断挖出新区块,区块链系统收敛到“最长链”的延迟将极高,此时,恶意矿工夺取最长链将变得十分轻松。因此,在公有链场景下,增大出块速率不是一种合适的扩容方案。
3、小结
为了从根本上实现区块链系统的扩容,越来越多的系统选择更改执行架构、共识方案、存储模型,甚至整个系统架构的思路,针对自身系统面临的交易吞吐量瓶颈,提出有效的扩容方案。下文将通过一些具体的案例,介绍和分析并行扩容、架构扩容这两种比较主流的链上扩容设计思路。
(2)并行扩容
在传统的区块链网络中,交易由共识模块定序,执行模块严格按序执行。因此,执行过程很容易成为整个区块链系统的交易吞吐量瓶颈。
并行扩容是为了解决区块链系统中执行过程耗时长的问题,并提高区块链系统交易吞吐量而提出的方案。其基本思路是保持原有的系统架构,打破交易严格串行的规则,实现交易在一定程度上并行执行,以此来减少执行过程的耗时。在系统资源没有达到瓶颈的情况下,交易的并行程度越高,执行过程的耗时就越少。也就是说,通过分配更多的资源给交易执行过程,可以有效地减少执行过程的耗时,消除执行过程导致的区块链系统的交易吞吐量瓶颈。
并行扩容设计思路,其根本目的在于解决执行过程导致的区块链系统交易吞吐量瓶颈,而交易执行导致的交易吞吐量瓶颈多出现在联盟链场景中。因此,并行扩容设计思路一般在联盟链场景中更为适用。
1、分片执行
分片执行是一种典型的并行扩容案例,其基本设计思路是,共识定序后的交易列表可以通过依赖性分析等手段划分为多个不相关的交易列表。这些交易列表仍保留原交易列表中的交易顺序,被分发到不同的下层执行器中各自执行,以实现交易并行。
节点架构
系统的架构设计为,区块链上的共识(master)节点由一个master-slave模式的集群组成,master节点参与共识网络,各个slave(执行)节点只与master节点交互,负责接收交易列表,执行并返回执行结果。在各个区块链节点中,各自的slave节点数目可以不同。
分片执行网络架构图如下图所示。

存储架构
在上述架构中,master节点需要存储区块、回执等数据,这些数据仅由master节点进行读写,而master节点和slave节点都需要访问与世界状态相关的数据。因此,出于性能和简化交互逻辑的角度考虑,这部分数据从master节点的存储中拆分出来,独立存储于外部数据库。
分片执行节点存储架构图如下图所示。

执行流程
假设一个区块链节点上有1个master节点和N个slave节点,那么典型的区块执行流程如下。
- master节点在拿到共识定序后的交易列表后,进行静态的相关性分析,将其打散成不超过N个的不相关交易列表,分发到不同的slave节点上执行。
- 各个slave节点首先对交易进行并行验签,然后按序执行交易。这里介绍账本的“读写集”概念:在交易的执行过程中,可能会涉及账本数据的新增、访问、修改或删除,这些账本数据的操作可以统一抽象为账本数据的读(访问)写(新增、删除或修改)集。当一笔交易执行完成后,slave节点会生成一份与该笔交易对应的账本数据的读写集,以及一份执行结果,slave节点需要缓存读写集数据,等待交易列表中所有交易执行完成后,一同返回给master节点。
- master节点在收全各个slave节点返回的当前区块的执行结果后,进行读写集冲突检测和合并。如果检测到冲突,则调整交易列表的分发策略,以确保不会冲突的形式,重新分发至slave节点,进行重新执行。
- 完成后,master节点将读写集合并结果应用到账本数据库,以得到最新的世界状态,并持久化区块、回执等数据。当前区块的执行至此全部完成。
并行执行流程图如下图所示

根据上述简要步骤概述可以看出,slave节点是一种无状态节点,负责交易验签、按序执行并返回执行结果。因此,增大交易并行程度,可以通过增加slave节点的数量实现。交易并行程度增大后,交易执行流程的耗时会减少。在读写集冲突较少的场景下,系统的横向拓展能力很强,交易吞吐量可以通过增加slave节点数量得到提高。
2、预执行
在上述分片执行架构中,交易执行发生在共识定序之后,即执行前,交易顺序就已经确定了。本节所讨论的预执行架构,是在共识定序前,预执行交易得到读写集结果;在共识定序后,将这些交易按照顺序合并读写集;剔除冲突交易后,形成区块并提交。
Hyperledger Fabric执行架构
预执行的一种典型案例就是Hyperledger Fabric。在Hyperledger Fabric-v2.0架构中,共识模块和执行模块是完全解耦的,可以各自运行在独立的进程中。一笔交易从发起至最后落盘,至少需要背书节点、排序节点、记账节点、主节点和客户端五种角色参与。
执行流程
Hyperledger Fabric中一笔交易从生成到最终上链过程如下图所示。

下文只关注Hyperledger Fabric中的交易执行、定序和提交流程,其他流程与执行架构关联不大,这里不详细展开。在一个通道内,一笔交易的上链过程大致如下。
- 首先,客户端生成一个交易,并将交易发送到背书策略指定的背书节点上。背书节点在收到交易后,基于当前的世界状态,执行其中的链码逻辑,得到读写集和执行结果,附上自己的签名后,返回给客户端。
- 接着,客户端在收全背书结果后,将装配了背书结果的交易广播给排序节点。排序节点按照时间顺序,将交易信息打包成区块。
- 在Hyperledger Fabric中,存在一个主节点的角色,主节点会持续地从排序节点处拉取区块,并将区块转发到背书节点和记账节点,各个节点验证背书信息、检测读写集冲突、标记区块中的合法和非法交易列表,并将合法交易的“写集”应用到本地存储的世界状态中,至此,可以认为该区块完成了提交上链。
- 区块提交后,客户端将接收到节点推送的最新提交的区块信息。
扩容效果
在这样的执行架构下,客户端将持续向背书节点发送交易,每笔交易仅在其背书策略指定的背书节点上执行,这就使得在整个背书节点集群上,同一时刻,不同节点间执行的可能是不同的交易,也就意味着,交易在一定程度上是并行的。同时,各个背书节点都基于相同的世界状态执行交易,即同一笔交易只要在一个区块周期内,无论发送到哪一个背书节点,其执行结果都是相同的。因此,增加背书节点的数量,可以有效提高交易的并行程度,进而提高交易吞吐量。
3、总结
上述两种并行执行架构最大的区别在于执行的时机和读写集的冲突解决策略,不同的设计思路相应地存在不同的优劣势。
- 首先,在分片执行设计思路中,执行模块接收共识定序交易列表,交易列表中的交易一定会被执行,所有合法交易一定会被打包成区块。这种方案的优势在于,进入执行模块时,交易就有了确定的全序,也就意味着,所有被系统接收的交易都会以合法交易或非法交易的形式被最终确认,不存在交易被抛弃的情况。但是,这样的设计需要考虑读写集冲突的情况,一旦发生冲突,则只能将整个交易列表重新分配、执行。这必然会带来额外的资源开销,同时会降低系统的执行效率。
- 而在预执行设计思路中,执行是先于共识定序的,并且执行结果不会立刻应用于账本数据。同一区块中的每笔交易在执行时的世界状态都是相同的。这会导致在一个区块内交易冲突的概率不可控,被预执行过的交易虽然执行过程正确,但是最终可能因为与前序交易冲突而成为非法交易。虽然这样的设计不会引起上述读写集冲突导致的“重执行”,但在部分业务场景中,可能会导致系统的实际交易吞吐量达不到预期效果。
上述并行扩容的设计思路,希望打破“交易严格按序串行”的限制,尽可能实现执行模块的并行化,以此来提高系统的交易吞吐量。对于交易吞吐量瓶颈处于交易执行阶段的系统,这种设计思路可以很好地解决问题,同时可以使系统具有优秀的横向拓展能力。但是,对于某些交易吞吐量瓶颈不在交易执行阶段的系统,这并不是一种合适的设计思路。
(3)架构扩容
如上文所述,目前存在很多区块链系统,其交易吞吐量瓶颈并不在交易执行阶段,而在共识模块达成一轮共识的耗时阶段。这样的问题在公有链场景如以太坊、Harmony等系统中尤为常见。除系统的交易吞吐量瓶颈之外,传统区块链系统的存储模式存在固有的问题:单节点存储容量上限为整个系统的数据量上限。随着系统的运行,链上数据不断积累,存储容量问题逐渐引起很多成熟区块链系统的重视。
基于上述两点,目前有很多区块链系统尝试提出适合自身的扩容方案,如
- 以太坊2.0提出的二次方分片方案
- Harmony-one提出的beacon/shard chain架构
- Conflux提出的基于有向无环图(Directed Acyclic Graph,DAG)模型的异构区块链
- Trifecta提出的拆分区块角色形成多链的系统架构等
这些扩容方案都从修改传统“系统运行和维护单条有效的区块链”架构的设计思路出发,寻求提高交易吞吐量和存储容量的最终方案,本节将这一类方案统称为架构扩容。
1、异构区块链
传统区块链系统基本遵循“多笔交易成区块,区块按序形成一条有效区块链”的架构模式。但类似Conflux系统等众多公有链系统,为了寻求更高的交易吞吐量,打破传统的架构模式,提出使用DAG模型来组织块链结构,打破“矿工竞争挖出的区块必有一方被回滚”的公有链分叉选择规则,提高并行区块的处理效率,增大系统运行过程中消耗的计算资源的有效部分比例,最终提高交易吞吐量。
下文以Conflux系统为例,介绍引入DAG模型的异构区块链系统的具体架构设计和实现方案。
Conflux系统基于公有链只有少数交易会产生冲突的现状,通过提高并发区块的处理效率,最终提高交易吞吐量。Conflux系统提出使用DAG模型来组织块链结构,通过对主链的共识确定最终的交易顺序。这种设计思路可以有效突破公有链网络中的共识瓶颈。
Conflux系统整体块链架构图如下图所示。

下文将从块链组织形式、交易定序形式、扩容效果和安全性四个方面详细介绍Conflux系统的设计思路。
- 块链组织形式。Conflux系统以DAG模型组织块链结构,每个区块都包含1条“父边”,指向其父区块,同时,包含N条“引用边”,指向所有先于自己生成的区块。在DAG模型中,为了确定交易的最终顺序,Conflux系统引入主链的概念,每个区块生成时,都会向主链上添加,而确定主链的方式是,当前主链上的最后一个区块的孩子区块中,拥有最大子树的孩子区块将成为主链上的区块。新加入的区块将添加到主链的最后一个区块之后,同时,这个区块会向网络中所有未被其他区块引用的区块建立“引用边”。
- 交易定序形式。Conflux系统主链上的每个区块都代表一个Epoch,而分叉链上的区块所属的Epoch等于第一个产生在它后面的主链上的区块的Epoch。按照这样的思路,所有的区块一定属于一个确定的Epoch。每个Epoch都可以按照区块哈希值排序来确定顺序,使系统中的所有区块构成一个全序列表。
- 扩容效果。基于DAG模型的块链组织,网络中的区块可以认为是有效区块,除冲突和非法交易之外,区块中的交易最终都会被链上确认和记录。显然,相比传统的“最长链”规则只保留主链,回滚分叉链的模式,矿工有效计算的比例大大增加。因为矿工挖出的区块最终都会成为有效的区块,因此矿工在并发挖矿的同时,实现了交易执行的并行化,并且执行结果最终是有效的,系统的交易吞吐量显著提升。又由于Conflux系统对主链上的一个区块达成了共识,本质上确定的是一个Epoch内所有区块。因此,其共识效率相比传统的PoW或PoS等共识算法有了一定程度的提升。
- 安全性。按照Conflux系统的出块策略和区块定序策略,主链上的每个区块都是该Epoch中的最后一个区块,因此,想要逆转当前可见的Epoch中的交易,只能通过夺取主链的方式来实现。上文提到,矿工决定主链的方式是拥有最大子树的区块会添加到主链上。其中,“最大子树”代表系统当前时刻的最大算力。后续的诚实节点也会向最大子树继续添加区块,也就意味着,只要恶意节点达不到全网51%的算力,就无法成功夺取主链,也就无法完成双花攻击。
上述系统提出的基于DAG模型的块链组织架构,相比传统区块链系统的块链组织架构,大大减少了区块回滚的概率,显著提高了并发区块的处理效率,相应提高了系统整体的交易吞吐量。对于性能瓶颈在于共识模块的区块链系统,是一种有效的、新颖的设计思路。
2、状态分片
上述基于DAG模型的方案,其着眼点是解决共识模块导致的区块链系统交易吞吐量瓶颈,适用于公有链场景。但是仍然没有解决存储容量问题。上文提到,按照传统的区块链存储模型,区块链网络中一定存在需要存储全量数据的节点,这类节点的存储容量上限决定了系统的存储容量上限。
为了从根本上解决这一问题,最直观的思路就是打破“单节点存储全量数据”的模式,将系统中的数据分散地存储到不同节点上。基于这样的思路,以太坊、Harmony-one及Trifecta等系统提出了各自的分片方案。
虽然这些系统的分片方案和架构模型各不相同,但它们都存在一些共同点。
- 将传统的一条区块链转化为多条区块链,每条区块链仅存储系统中的部分数据。
- 为了保证整个系统的完整性和一致性,在这样的多条链中,一般都会有一条基准链,这条基准链反应了整个系统的运行状态,其他链(下文称为分片链)都以某种形式向这条基准链锚定。
- 各条分片链除“需要向基准链锚定”之外,彼此间相互独立,不同的分片链维护各自链上的世界状态,甚至可以拥有独立的共识算法,分片链间几乎是完全隔离的。
基于上述三点共同点可以看出,在这样的架构下,每条链都可以独立处理各自的交易、自主出块且数据独立存储。一方面,这样的架构极大地提高了交易的并行程度;另一方面,各个节点只需要存储参与链的数据,整个系统的数据被分散存储在不同节点上,整个系统的存储容量不再受单节点存储容量的影响。最重要的是,这样的架构模型具有很强的横向拓展能力,当交易吞吐量达到上限时,可以通过新增物理计算资源或分片链来帮助提高。
在传统区块链架构中,通常将某一时刻的区块数据、账本数据统称为这一时刻区块链系统的世界状态,在上述架构中,世界状态数据被分散存储在各个分片上,但不会破坏系统的最终一致性。这些类似的架构模型称为“状态分片”。但是,状态分片在解决了交易吞吐量、存储容量等问题的同时,引入了新的问题。例如,因为各条分片链上的账本数据是相互独立的,因此,当一笔交易涉及多个分片上的账本数据时,交易的事务性难以保证。
有很多系统进行了尝试并实践了状态分片,下文将介绍以太坊2.0二次方分片、Harmony-one分片和Trifecta分片的三种设计,简要分析各自的架构设计、相应的优势及可能存在的问题。
以太坊2.0二次方分片
(1)整体架构。
在以太坊2.0中,整个以太坊系统分为两层,第一层是当前的主链,在分片架构下称为beacon链,beacon链不需要硬分叉来实现向以太坊2.0的过渡,而通过部署一个校验者管理合约(VMC)来实现对分片链的管理。这个合约会定义分片数量,注册所有的验证者节点,并提供不可预测的、随机的方式决定验证者节点负责在何时、何分片上出块。同时,该合约暴露了将分片上产生的区块锚定到beacon链的接口,验证者节点完成了在分片链上出块后,使用这个接口将区块头传输给beacon链。为了保证随机性,上层的验证者节点和分片的对应关系仅在指定连续N个区块的时间窗口内有效,过期后将自动重新分配。借助VMC,beacon链可以很方便地管理各条分片链的状态。
二次方分片整体架构图如下图所示。

(2)扩容效果。
本节将分析这种架构模型带来的存储容量和交易吞吐量两个方面的扩容效果。首先,因为一个节点只需要存储其参与的分片内的数据,所以整个系统的存储容量几乎是无限制的,这从根本上实现了存储容量的无限制扩展;其次,在只有一条链的架构下,假定每个节点的算力为x,那么系统的整体出块速率基本是O(x)级别,二者基本上呈正比。在分片架构下,无论是主链还是分片链,其出块速率都可以认为是O(x)级别。又因为各条分片链上的区块互相隔离,各自独立地向主链锚定,因此,对于分片数目为N的系统,其出块速率可以认为是N×O(x)级别。
上文提到了N是由VMC内部定义的,当N的选择能够达到O(x)级别时,可以认为整个系统的出块速率增加到O(x2)级别。每条分片链都是通过调用一次VMC将产生的区块向主链锚定的,因此,主链可以管理的分片链数目等同于主链在单位时间内能处理的VMC调用次数,也就是和节点算力直接相关。这就是“二次方分片”名称的由来。
(3)分片链与主链的交互。
首先介绍几个二次方分片架构中的概念。
- 周期:连续的N个区块的时间窗口。
- collation:分片链上产生的交易块,包含区块头(header)和区块体(body)。collation有分值的概念,分值会被应用于分片链上的collation-header选择和分叉选择时确定最长链。
首先,beacon链上会运行VMC,利用一个指定的区块哈希值,如上周期的最后一个区块的区块头哈希值为入参,在一个指定的周期内,为每个分片分配一个验证器。这个验证器只在指定周期内有效,并且其签名的分片链上的collation的序列号只有在当前周期对应的区块号范围内才有效。
其次,当分片链上生成了一个有效的交易块后,验证器会向beacon链发起一笔合约调用,内容为调用VMC的addHeader,尝试将当前的collation-header锚定到beacon链上。最后,当这笔addHeader对应的交易在beacon链上被打包成区块时,意味着collation向主链锚定成功。
关于区块的最终确认,对于beacon链,最长链上的区块是有效的,区块的分叉选择规则是最长链规则;对于分片链,其分叉选择规则是,以最长有效主链上的最长有效分片链为主分片链。如下图所示,有效主链为B链,虽然A链上打包的分片链更长,但是当前分片链上最新的collation是B链中的C2。

(4)无状态客户端。
伴随着上述分片架构,以太坊2.0还提出了一个“无状态客户端”的概念。网络中的验证者节点,无论是作为出块的矿工,还是希望完成区块合法性验证,都需要本地存储全量的状态数据。而无状态客户端颠覆了这一思想,因为状态数据的组织形式是MPT,是可通过默克尔根验证的。因此,如果每笔交易都能够给出其使用到的所有状态数据,并且这些状态数据是可验证的,那么矿工节点或验证者节点可以不存储全量的状态数据,也就是说,矿工节点不一定是全节点。如果每次执行交易都携带本次交易涉及的所有状态数据的值,并为这些值提供相应的默克尔根,那么矿工节点只需要知晓交易执行前的状态数据的MPT根哈希值,就可以安全地执行和校验交易,并且给出交易执行结束后的MPT的最终状态根哈希值。
基于无状态客户端的设计原理,无论是beacon链还是分片链,每条链上的全节点数目都可以大大减少,其状态数据的备份数量也相应大幅减少。配合上述二次方分片的思路,可以进一步节约整个系统的存储资源。
(5)跨分片交易。
以太坊2.0的二次方分片,出于公网环境和协议安全性考虑,现阶段设计暂不支持跨分片交易。但目前已经有很多关于跨分片交易的思路和方案,其中比较被多数人接受的一种方案是类比UTXO交互模型。将一笔跨分片交易拆分为两笔交易,两笔交易间通过一个中间状态的receipt保证跨分片交易的事务性。
下面举一个简单的例子,假设账户A向账户B转账10BTC,而账户A和账户B分属于两个分片,交互流程大致如下。
- 对账户A扣款,生成receipt,构造一笔交易发送到账户B所在的分片。
- 账户B确认receipt合法后,增加自己的账户余额,然后生成receipt,构造一笔交易发送到账户A所在的分片。
- 账户A所在的分片收到交易后清账。
上述方案通过一种类似2PC的思路,解决跨分片交易的事务性问题。但上述方案只描述了一个在理想状态下的常规流程,对于网络延迟、区块回滚等异常情况的处理没有相关描述。例如,传输过程中因为网络原因导致receipt丢失、延迟或重传等问题。考虑到这些问题,有些改善思路中提到了使用共享内存等方案使上述2PC更具鲁棒性,首先,在公网环境下,共享内存的方案很难真正实施。其次,对于恶意构造跨分片交易的receipt等针对指定分片进行攻击的恶意行为,没有完备的抵御策略。
综上所述,目前二次方分片架构中还没有成熟的跨分片交易方案。
整体来说,以太坊2.0的二次方分片架构在不使主链出现硬分叉的前提下,通过将单条区块链转换为两层链的架构,可以实现交易吞吐量平方级的大幅度提升。同时,这种架构带来了链与链之间交易并行的优势,解决了全节点单点存储容量限制整个系统存储容量的问题,是一种较为成熟的链上扩容方案。
Harmony-one
(1)整体架构。
在Harmony系统的分片架构中,存在一条信标链和多条分片链,在每条分片链上,只存储一部分账本信息,由随机选择的节点参与维护,各条分片链自主出块。信标链可以认为是一条特殊的分片链,主要运行分布式随机数协议(用于随机选择一定数量的节点维护分片链),并且负责维护和管理系统中的资产信息。
Harmony系统的每条分片链内部都使用了FBFT(Fast Byzantine Fault Tolerance)共识算法进行共识,该算法是融合了BLS签名算法和经典PBFT的一种共识算法,共识效率很高。各条分片链出块后,最终需要把分片链的区块向信标链锚定。相应地,信标链负责资产管理和接收分片链向自己发送的锚定信息。
Harmony系统使用了新型的有效资产抵押机制,将资产打散成多个相等的小块,随机分配到各个分片中,配合定时的Resharding机制,保证了资产分配的安全性和随机性。这里随机数的选择机制、共识算法的实现思路及涉及的一些系统概念虽然与分片架构没有直接的关联,但是这些概念在DRG协议中都有涉及,而DRG协议又在整个系统运行过程中扮演着重要的角色,因此,这里挑选了部分相关的系统概念进行简单描述。
- Epoch:Epoch是一个定长周期,这个周期是一个全局概念,目前默认是24小时,在每个Epoch内,系统的分片结构都是确定的。
- EPoS:EPoS是Harmony系统使用的新型的有效资产抵押机制。其基本思路为,将所有资产持有人的资产全部打散为相同大小的slot,信标链会为这些slot装配内置的公钥地址,而后将这些slot随机分配到各个分片中,这些slot在分片内扮演区块验证者的角色。这里的随机性是通过DRG协议体现的,下文将进行详细描述。在一个Epoch内,分片内的slot集合是确定的,这些slot会参与出块投票,每个slot都有一票投票权。slot参与投票的方式为,在分片内部运行FBFT共识算法出块的过程中,通过参与FBFT共识算法中的prepare阶段和commit阶段的BLS签名给认可的区块投票。当区块被信标链最终确认时,共识过程中的leaderslot和参与BLS签名的所有slot都可以得到出块奖励。EPoS中还有更细节的资产划分、调整和转让的逻辑,具体细节与分片架构无关,不再展开介绍。
- FBFT共识算法:FBFT共识算法本质上是PBFT共识算法的一种优化。假设网络中有N个节点,FBFT共识算法要求非诚实节点数量f满足N≥3f+1。通过引入BLS签名算法,其prepare阶段和commit阶段的算法复杂度都降至O(n)级别,同时,每个区块都具有自验证能力。
- DRG协议:DRG协议仅运行在beacon链上,其职责是负责Resharding过程。一轮DRG协议作用于一个Epoch周期。DRG协议的整体流程如下图所示。
- 首先,在Epoch开始时,本轮共识中的leader会使用上个Epoch的最后一个区块哈希值作为种子构建一个“Init信息”,并广播给所有分片内的节点
- 每个节点都会根据“Init信息”生成一个随机数并附带上VRF(Verifiable random function)证明,返回给leader。
- leader在本Epoch内收集到至少f+1个随机数后,整合计算出一个“pRnd值”,并将“pRnd值”在下个区块中提交。这个“pRnd值”会被用作种子进行VDF(Verifiable Delay Function)计算,得到最终的“Rnd值”。VDF的延迟时长为k个区块周期,最终结果“Rnd值”会在本Epoch内最后一个区块中提交。下个Epoch会将这个“Rnd值”作为Resharding过程中随机分配资产slot时的随机数。

Harmony系统的整体架构和以太坊2.0二次方分片架构相似,都包含一条beacon链和多条分片链,每条分片链都维护独立的账本数据。因为分片链的账本数据和区块数据彼此完全隔离,所以理论上,Harmony系统的存储容量可以自由扩展。
虽然架构类似,但Harmony系统相比以太坊2.0二次方分片架构具有一定的优势:
- 首先,Harmony系统的各条分片链上运行的是FBFT共识算法,这使得分片链几乎没有分叉的可能
- 其次,Harmony系统的有效资产抵押机制、DRG协议和安全随机Resharding协议保证了各条分片链上验证者分配的随机性,系统可以抵御类似“1%攻击”“贿赂攻击”“最后发布者攻击”等针对分片架构的攻击。
但是,Harmony系统采用定期进行Resharding的设计思路,这样会带来一些效率上的影响。因为资产持有人的资产是被打散后随机分配到各个分片上的,所以在不同分配周期内,资产持有人负责出块的分片可能不同。又因为各分片维护独立的账户空间,所以希望参与出块的资产持有人必须能够通过某种方式获得任一分片的全量状态数据。类似的协议设计必然会降低Resharding的效率,同时会带来额外的网络或存储开销。
(2)信标链与分片链的交互逻辑。
首先,信标链上存在一个管理所有资产持有人的智能合约,智能合约内容包括所有资产持有人的地址和资产金额。该智能合约对外提供账户增、删接口及资产质押、提现接口。每次Resharding都由信标链完成账户数据的整合,然后重新拆分成slot,并给每个slot分配公钥地址(这个公钥列表是在genesis账户列表中设定好的)。所有和资产持有人或资产相关的交易都在信标链上执行。
完成Resharding后,系统进入正常运行阶段。在这个阶段,每个分片都独立地运行FBFT共识算法并出块。因为FBFT共识算法中融合了BLS签名算法,所以每个区块的区块头都是可以自校验的。每个分片在生成一个区块以后,都需要向beacon链发送一个“CrossLink信息”,这个信息是一个区块头列表,该列表包括beacon链认为的该分片上的最新区块到当前刚刚生成的区块。这个“CrossLink信息”用于beacon链更新其维护的各条分片链的高度信息。beacon链在收到“CrossLink信息”后,会根据区块头中的BLS签名,验证每个区块头的合法性。在beacon链完成了对“CrossLink信息”的校验后,“CrossLink信息”将被打包到beacon链的区块中。每当beacon链生成新区块,beacon链就会主动将新区块信息向全网所有节点广播。
整体上,beacon链上区块和分片链区块的锚定关系如下图所示。

基于这样的交互模式,beacon链可以实时获得各个分片的信息。同时,各条分片链能实时感知到beacon链的信息。虽然这样的交互协议方便了链之间的协同和beacon链对整个系统的管理,但是会给网络传输带来额外的负担。
(3)跨分片交易逻辑。
Harmony系统中跨分片交易的处理也是通过将一笔跨分片交易拆分成两个阶段来实现的。在执行交易的过程中,如果分片链节点识别出这是一笔跨分片交易,则节点会先在本地生成一份CXReceipt。这份CXReceipt会在当前区块在本分片提交以后,被发送到目标分片,并提供相应的默克尔证明,同时附带commit阶段的BLS签名。接收方首先将CXReceipt缓存到本地,等收到beacon链广播的新区块且发现新区块中包含该分片、该区块头后,再处理CXReceipt。
CXReceipt的接收方可以通过默克尔证明确认CXReceipt数据的正确性,同时可以通过信标链广播的区块和commit阶段的BLS签名确认CXReceipt对应的交易确实在特定分片上被执行且打包进区块。但是,如果接收方在使用CXReceipt执行交易时出现了异常,并且系统并没有提供相应的回滚机制,那么,虽然该设计思路解决了CXReceipt的真实性问题,但仍然不能在异常情况下保证跨分片交易的事务性。
Harmony系统的分片设计方案使用了新型的EPoS算法定时重构资产持有人的投票比重,且通过融合VRF、VDF的安全随机数生成手段,以及BLS签名算法,虽然分片链处于公有链环境,但其仍可以安全地使用BFT式共识协议。这种设计直接大幅度提高了分片内的共识效率,同时减少了分片内的区块回滚概率,整体的交易吞吐量相比二次方分片有了较大的提升。
不过,Harmony系统内链与链之间的消息通信协议大多采用“广播”的模式。考虑其运行在公有链环境下,这会给网络I/O带来更大的压力。此外,其Resharding协议的设计虽然保证了分片内的系统安全性,但可能造成数据大量迁移或分片链数据冗余存储,这会给网络或存储带来额外的开销。
Prism项目与Trifecta项目
(1)Prism项目整体架构与扩容效果。
在存在分叉可能的区块链系统中,区块以树形结构组织。而根据某种分叉选择策略选择出来的“主链”,其链上的区块有三种职责:
- 一是向区块链上添加交易
- 二是担任同层区块中的Leader角色
- 三是为自己的父区块投票
Prism项目提出了一种多链的架构,将区块的上述三种职责解耦,相应地定义了三种区块:
- proposer块
- transaction块
- voter块
Prism项目使用两种链将这三种区块整合在一起,一种是proposer链,另一种是voter链。
- proposer链决定了整个系统的全局逻辑时钟,是一条最基本的链。proposer链由proposer块构成,遵循最长链原则,每个proposer块都包含了父区块哈希值和多个transaction块。
- voter链的数目由系统参数设定,一般有多个。每条voter链都遵循最长链原则,voter块的职责是为proposer块投票。
Prism项目整体块链架构示意图如下图所示。Prism项目中有1条proposer链和m条voter链。proposer链上的最长链原则决定了诚实矿工如何向proposer链上添加区块。而voter链则通过投票选出proposer链上每层的Leader,Leader决定哪些交易会被上链,也就是决定系统中交易的最终顺序。
 Prism项目中矿工打包出块的规则是,
Prism项目中矿工打包出块的规则是,
- 首先,构建一个超级块,超级块中包含1个proposer块、m个voter块(一条voter链产生一个voter块)及至少1个transaction块。
- 其次,矿工根据超级块内的所有内容计算超级块的区块头。系统根据区块头所处的范围确定本次出块的类型,其余信息失效。因此,矿工最终能产生什么样的区块是完全随机的。
在传统区块链系统中,只有最长链上的区块才是有效区块。试图通过降低挖矿难度来增大出块速率的做法必然会增大分叉的可能性,而分叉的存在不仅会降低最长链的收敛速度,还会影响交易的最终确认时间和系统的安全性。而在Prism项目中,transaction块本身并不具有链式结构。如果期望提升系统的交易吞吐量,可以通过降低transaction块的挖矿难度或允许transaction块打包更多的交易来实现。因为最终确定系统全局逻辑时间的是proposer链,所以在保证proposer链和voter链的分叉概率较低的情况下,降低transaction块的出块难度并不会增大系统的分叉概率。
从上述分析可以看出,Prism项目拆分了传统区块链网络中区块的三种角色,将区块链系统的安全性、交易最终确认时间和系统交易吞吐量解耦。系统交易吞吐量可以单方面自由拓展。
(2)Trifecta项目的分片思路。
Trifecta项目基于Prism项目提出了新型分片架构。Trifecta项目整体块链架构示意图如下图所示。其根本思想是,将transaction块划分到不同分片中存储,每个分片仅处理和自身相关的transaction块。

Trifecta项目的特点如下。
- proposer链和voter链仍然在全网所有节点上存储。
- 网络中的分片数目和节点数目呈正比,分片仅维护和自身相关的transaction块。各分片的账本相互独立。
- 系统中存在一个beacon分片,这个分片内会存储系统级别的交易。这类交易一般与分片无关,如矿工的激励合约等。这个分片是全网节点都参与的分片。
因为proposer链和voter链是对全网可见的,但是每个transaction块只对特定分片可见,所以如果分片内节点希望验证其他分片产生的proposer块,则该节点必须从矿工所在的分片上下载proposer块中包含的transaction块。这是Trifecta项目的分片架构引入的“数据可获得性”问题。虽然,通过直接在网络中传输完整的transaction块可以直观地解决问题,但是这样的设计会给Trifecta项目带来高昂的网络开销。因此,Trifecta项目提出了“区块验证”协议来高效地解决“数据可获得性”问题。
(3)区块验证。
Trifecta项目的区块验证协议包含如下两个前置条件。
- 每个proposer块在出块时,其区块证明数据中都需要包含相关的transaction块的Coded Merkle Tree(CMT)根哈希值。
- 每个节点至少与每个分片中的一个诚实节点连接。
在这样的假设下,想要获得一个不在本分片内的transaction块,不需要在网络中传输全量数据。以分片2向分片1下载一个transaction块为例,分片1中的出块节点A,通过“纠删码”技术将整个transaction块划分为k块内容(这里的k是纠删码技术中预设的常量参数)。然后出块节点A将这k块内容编码成2k个样本。接着,分片2的请求节点B在向其下载transaction块时,该出块节点A可以随机地选择2个样本返回给请求节点B。请求节点B本地不做验证,而将样本传输给自己连接的分片1上的诚实节点C。而后,诚实节点C在收集了至少k个不同的样本后,可以根据样本恢复出完整的transaction块。然后,诚实节点C再将transaction块编码成2k个样本,并构建CMT,计算出样本块的CMT根哈希值。最后,诚实节点C将这个CMT根哈希值交给各个向其转发了样本的节点(包括请求节点B)。请求节点B可以通过校验这个CMT根哈希值与proposer块中提供的transaction块的CMT根哈希值是否一致来确定proposer块中是否真正包含这个transaction块。
(4)账本一致性验证。
Trifecta项目每间隔N个区块就会验证一次状态数据的一致性。每次验证开始时的区块高度称为验证点。状态数据的验证发生在分片内部。每到达一个验证点(假设这一批区块的范围是l, l+1, l+2,…,L),proposer块的出块节点都会将一份state-commit信息提交到beacon分片上,state-commit信息中包含每个区块中的账本根哈希值。验证流程如下图所示。

具体的验证和交互流程如下。
- state-commit信息被提出后需要全网广播,最终会被包含在beacon分片中。beacon分片是一个所有节点都可以加入的分片,在某些协议中可以被用作分片间信息交互的媒介。state-commit信息可表示为。
- state-commit信息被提出后,分片中的其他验证节点可以对其发起挑战,即当发现自己本地的执行结果和上述state-commit信息不一致时,给出Disagreement1消息。Disagreement1消息中包含最早的一个执行结果不一致的层数和自己本地计算出的该层的state-commit信息。
- state-commit信息提出者接收到Disagreement1消息后,假设其给出的层数为li,那么,提出者需要给出li至li+1两层间的所有交易执行后的账本根哈希值,作为Defense。
- 挑战者针对Defense,找出执行过程中第一笔导致不一致的交易T,向全网广播Disagreement2消息。Disagreement2消息中包括
 。
。 - Disagreement2消息会被分片内的所有节点验证,来决定是否回滚到上一个state-commit信息。
(4)Trifecta项目的跨分片交易。
Trifecta项目的跨分片交易是通过将一笔交易拆分为两笔交易,并以中间状态的receipt为媒介实现的。其设计思路复用了部分上述state-commit信息的思路,简要流程如下。
以涉及分片1与分片2的跨分片交易T为例。
- 首先,交易T会被拆分成分片1中的交易T1和分片2中的交易T2。
- 分片1中执行T1,产生回执Tr1。
- 在T1所在的区块被包含到proposer链,下一次分片1给出state-commit信息时,同分片内的节点会针对T1发起挑战。
- 提出挑战的节点可以得到一系列的state-commit信息验证数据。同时,state-commit信息及挑战过程中生成的与T1相关的证明数据会被发布到beacon分片中。
- 又因为beacon分片中的数据是全网感知的,所以分片2可以通过这些证明数据快速地验证T1的正确性,然后依据Tr1执行T2。
(5)小结。
Trifecta项目的分片方案在Prism项目提出的多区块角色的设计思路基础上,实现了线上交易按照分片存储的机制,解决了单节点存储全量交易导致的系统存储容量问题。在其解决方案中,通过纠删码和CMT技术,实现了验证其他分片的transction块的完整性和正确性的功能,同时,避免了在网络中传输整个transaction块带来的开销。
从上面的分析中可以看出,无论是区块验证还是账本一致性验证,协议复杂度都很高,交互轮次较多,其中,账本一致性验证还需要借助beacon分片辅助完成。这样的设计思路一方面给系统带来了一定的负担,另一方面增大了交易的最终确认延迟。
而Trifecta项目的跨分片交易依赖一套完整的挑战机制。抛开其复杂度不谈,Trifecta项目并没有给出应对区块回滚、交易非法等异常情况的解决思路。因此,其跨分片交易的设计也是不具备鲁棒性的。
链下扩容
前面章节讨论的链上扩容,大多会对主链本身的架构进行更改,对于已经大规模运行的区块链网络来说,更改主链架构的代价很大,需要对大量已经在运行的节点进行升级。
链下扩容也称为第二层扩容。区别于链上扩容,链下扩容的主要思想是在不改变主链本身架构的情况下,另外增设一层通道,实现功能与交易性能的扩展。在公有链场景中,目前规模最大,也最受用户认可的还是比特币与以太坊。这两个区块链网络存在的普遍问题是交易速度慢、交易费用高,因而侧链技术及状态通道的链下扩容方案最初也是在此基础上诞生的。
而在联盟链场景中,虽然交易的处理速度相比公有链大大提高了,但是仍然无法满足现实场景中庞大的数据量、低延时上链及隐私数据保护等要求。因此,在联盟链场景中,链上与链下协同是扩容的关键,目前已有的方案是在链下进行存储与计算。
(1)侧链技术
侧链技术最初的诞生是由于比特币网络上交易的处理速度过慢、交易费用过高,使用者的体验很差。使用者想要有更高的交易处理速度、更低的交易费用,但是又想使用比特币这样一种被大家认可的数字货币作为价值的锚定。因此,侧链技术应运而生。
侧链技术的根本思路是将一条具有更好性能的子区块链网络与主链连接起来,实现跨链资产转移,同时将复杂的业务逻辑在侧链中执行,主链承担结算任务,从而提高区块链整体的交易速度,分担主链压力。
1、原理
侧链技术的基础是双向锚定,即将一定的资产在主链中锁定,将等价的资产在侧链中释放。同理,当资产在侧链中锁定时,主链的资产也能相应释放。
这个过程在实现上的最大难点是如何保证资产在链间的转移是可信的。根据资产的转移过程由谁来监管与执行,分成了三类技术方案。
中间人托管
最简单的资产转移方式是信任一个托管方,类似我们平时转账依赖银行这一中心化机构。侧链将需要锁定的资产发送给托管方在主链上的账户,托管方收到资产后,在侧链上激活相应的资产;同理,侧链上的资产锁定后,托管方将在主链上的资产解锁,返回给侧链。这种方案的缺点是过于中心化,强信赖于托管方,不符合区块链系统去中心化理念。
为此,在此基础上,又提出将单一托管方改为联盟,联盟各成员通过多重签名对资产转移进行确认。这样可以在一定程度上减少单一托管方的作恶风险,但依然取决于联盟中各成员的诚实度。
驱动链模式
在驱动链模式中,矿工本身成为资产的托管方,实时监测侧链的状态。当收到来自侧链的资产转移请求时,矿工进行投票决定是否解锁资产,以及将资产转移到何处。在这种模式下,矿工的数量及诚实度决定了侧链资产转移的安全性。
SPV模式
主侧链间资产安全转移的最佳方案当然是无信任模式,即资产在主链与侧链间转移时,无须依赖外部的可信方,参与方自己即可验证资产转移是否有效。这就要求主侧链需要有一种验证对方交易的机制。最初的比特币侧链白皮书提出了SPV模式的验证方法,能够根据区块头快速确定交易的存在性。
当一笔资产要从主链往侧链转移时,侧链通过主链提供的SPV,确认该笔资产确实已在主链上被锁定,从而解锁侧链上的资产。
2、优缺点
优点
- 分担主链压力。将更多的交易在侧链上进行,可以有效缓解主链的运行压力。主链可以连接多个侧链,多个侧链运行也不会造成主链负载增大。
- 提高交易速度。侧链相比主链更轻量级,有更高的交易速度。
- 功能扩展。侧链支持智能合约、隐私交易等功能,可以提供主链支持不了的功能。
- 独立性强。侧链虽然与主链进行锚定,但是侧链就算发生安全事故,也不会对主链的运行造成影响。
缺点
- 成本高、难度大。侧链本身也是一条区块链,也需要众多的节点和算力资源支持。
3、应用场景
RootStock
RootStock是第一个与比特币网络进行双向锚定的侧链,其内部使用了一个可以和BTC互相转化的代币。RootStock实现了一套图灵完备的虚拟机,因而可以处理更复杂的业务逻辑。该项目的双向锚定机制采用中间人模式,比特币业界的领导型企业组成了一个联盟,由联盟来控制两个区块链之间资产的安全转移。
RootStock相比比特币网络具有更高的交易处理速度和更低的交易费用,因此可以缓解比特币主链上的压力。
BTC Relay
BTC Relay由ConsenSys团队推出,其主要目的是将以太坊网络与比特币网络连接起来。BTC Relay采用SPV模式,其在以太坊中部署了一个BTC SWAP智能合约,不断向该智能合约推送BTC的区块头数据,以达到在以太坊中验证BTC交易的目的。
如下图所示,以Alice用1个BTC交换Bob的10个ETH为例。
- 首先,Bob在以太坊网络将10个ETH转入BTC Swap智能合约,Alice将1个BTC转到Bob在比特币网络中的账户
- 其次,Alice将比特币网络中的交易信息发送给BTC Relay,BTC Relay验证这笔交易并向BTCSwap智能合约推送区块头
- 最后,Alice发送Relay Tx交易至BTC Swap智能合约,BTCSwap智能合约用之前接收到的区块头对Alice的交易进行验证,通过后将Bob的10个ETH转给Alice。

(2)状态通道
状态通道也是一种将部分事务处理逻辑移到链下进行的技术。与侧链技术不同的是,状态通道的实现更轻量级,只需要在链上打开一条通道进行逻辑处理,不需要额外搭建一条子链。
之前以太坊上的加密猫游戏直接导致了以太坊的网络阻塞,说明在以太坊上直接运行游戏这种频繁调用、即时性要求高的程序是不可行的。但是通过状态通道,可以将过程在通道中处理,链上只计算最终的结果,大大提高了区块链的可扩展性。
1、原理
状态通道的生命周期包括打开通道、使用通道和关闭通道。其中,区块链只能感知到打开通道与关闭通道两个阶段,因此,参与方在使用通道进行交互时,不会依赖区块链网络。
首先,参与方在区块链中就初始状态达成共识,打开一条状态通道。此后,参与方对状态的更新均向状态通道进行提交,每条状态的更新都包含参与方的签名,直到达到最终状态。任何一个参与方都可以提交结算,即要求关闭状态通道,并将状态通道中发生的交易集合提交到区块链上。区块链验证通过后该交易生效。
在整个过程中,可能会遇到以下问题。
- 双花问题。由于参与方可能同时打开多个状态通道,因此,后结算的状态通道可能会因为余额不足而出错。为了解决上述问题,在开启状态通道的时候,要求参与方锁定一定的资产,状态通道中转账的最大数额不能超过参与方锁定的资产,在状态通道关闭的时候进行结算和解锁。
- 参与方伪造状态通道交易结果。虽然在状态通道中的每笔交易都需要参与方共同的签名,即可以保证每笔交易的有效性。但是由于状态通道的关闭可以由任意一个参与方提出,因此,参与方可以提交一个对自己更有利的状态,而不是最终的状态。例如,在一个状态通道中,Alice先给Bob转1个BTC,Bob再给Alice转2个BTC,Bob在提交关闭状态通道的请求时,因为想要获利只提交了第一笔交易。为了防止这种情况的发生,状态通道关闭时会等待一个质疑期,在此期间,任意一个参与方都可以提交交易集合,状态通道最终会以最新的交易集合为准。对于Bob这种作恶行为,可以进行惩罚,如罚完他的保证金。
2、优缺点
- 优点
- 缩短交易延时。由于状态通道独立于区块链网络,不会受区块链的交易速度影响,交易延时极低。
- 隐私性高。在状态通道中的交易过程不会保存在区块链网络中,仅对参与方可见,隐私性高。
- 交易费用低。在状态通道中的交易不需要消耗费用,只有打开状态通道和关闭状态通道阶段需要支付交易费用。
- 缺点
- 要求参与方保持在线。如果一个状态通道在关闭的质疑期内,某一方掉线,则另一方有可能提交一个非最终状态。
- 使用范围有限。一个状态通道打开后,仅允许参与方进行状态更新,非参与方无法参与。
3、应用场景
闪电网络
由于比特币网络的交易速度过慢,有人在2015年2月通过论文“The Bitcoin LightningNetwork: Scalable Off-Chain Instant Payments”提出了闪电网络的设想。闪电网络的中心思想便是状态通道。在闪电网络中,通过RSMC(Recoverable Sequence MaturityContract)和HTLC(Hashed Timelock Contract)机制保证状态通道的可靠性。
RSMC指可撤销的顺序成熟度合同,实质上是一种保证金机制。该机制要求参与方在打开状态通道时,需要预先锁定一定的资产。参与方每次在状态通道中更新状态时,都需要双方的签名,同时将旧的状态作废。由于任何一方都可以在任何时候提出关闭状态通道的请求,但提交的状态未必是最新的,一方有可能作恶提交更利于自己的状态,在一定时间内,如果另一方可以拿出这份状态已经被作废的证明,则系统将以后者提交的状态为准,并对前者进行惩罚。
HTLC是一种有条件支付的机制。交易双方可以达成一个协议,如果A在指定时间内能拿出B需要的哈希证明,则A可以获得由B锁定的资产。如果超过指定时间,则该部分资产自动解锁,归还B。该机制的实现可以让两个参与方通过其他状态通道的串联实现转账。
如下图所示,Alice要给Carol转1个BTC,他们之间并没有支付通道,但是Alice与Bob之间,Bob与Carol之间有支付通道。
- Carol选择一个密码S生成一个Hash(S),并将该哈希值告诉Alice。
- Alice与Bob约定一个HTLC合约,只要Bob能在一天内提供S,就给他转1个BTC。同理,Bob与Carol也约定一个HTLC合约,只要Carol能在一天内提供S,就给他转1个BTC。
- 约定好后,Carol向Bob提供S,获得了Bob的1个BTC。然后Bob将拿到的S提供给Alice,也获得了一个BTC。至此实现了Alice向Carol的转账。

雷电网络
雷电网络Raiden与比特币网络的闪电网络基本一致,是以太坊上用于代币转移的一种解决方案。
(3)链下协同
链下协同的概念更为广泛,其主要思想是将链上不方便计算的数据放到链下计算,链上不方便存储的数据放到链下存储,通过映射关系保证链上链下协同和一致性。尽管联盟链系统的交易吞吐量高于公有链,但是要想真正适应现实中庞大的数据量和极低的交易延时场景,联盟链也需要通过链下协同,支持更多的功能。
1、链下存储
在区块链系统中,每个节点都存储全量数据,长期运行的全节点最终会面临存储资源耗尽的问题。而如果链上需要存储类似媒体文件、长文本文件等大数据量的文件,则存储资源会更早耗尽。因此,链下存储是减轻区块链本身存储压力的有效手段。
下图展示了最基本的链下存储手段——哈希存证。这种方式将文件本身保存在链下文件系统中,而将文件的哈希值保存在链上。用户在下载文件时,通过比对链下文件系统中文件的哈希值与链上存储的文件哈希值,来校验文件是否被篡改。

在这种方式下,文件系统与区块链系统是完全分离的,且需要中心化部署。在联盟链场景中,有些节点并不想把文件分享给所有节点,因此,中心化的文件系统不被联盟链节点信任。
故有人提出了一种将文件系统与区块链节点相结合的链下存储方案,该链下存储方案的总体架构如下图所示。每个区块链节点都接入一个自定义的文件系统。用户向某一个区块链节点发送文件与文件哈希值,节点校验文件哈希值后将文件保存在节点自身的文件系统中,然后把文件哈希值广播上链。

当其他用户想要下载文件时,节点首先根据文件哈希值查询链上数据,确定文件位置后向目标节点索取文件,校验后返回给用户。
在这个方案中,每次文件的上传都伴随着一笔区块链交易。在区块链交易中定义该文件的权限来保证文件的隐私性;记录文件保存的位置,以方便向目标节点获取文件。
该方案既避免了文件的冗余存储,又通过在区块链节点上进行文件校验的方式保证了文件的完整性和正确性。
2、链下计算
在现实业务场景中,众多机构都拥有海量数据,这其中也包括机构的隐私数据。然而,多个机构间又有数据共享的需求。例如,想要获取一个用户的信用情况,需要各大银行提供该用户的信用记录。区块链是一个适合多方参与的安全可信的数据共享平台,但是如果直接将全量数据通过区块链存储,则会暴露机构的隐私数据。因此,如何在保障数据隐私的情况下使用区块链成为一个亟待解决的问题。
区块链开发者提出了区块链+安全多方计算的模型,能够在数据源不出库的情况下,实现计算结果的共享。安全多方计算架构如图7-17所示。

以获取用户信用评级为例,区块链系统通知各机构进行该用户的信用评级计算。各机构根据该用户在本地数据库中的信用记录,在TEE中计算该用户在本机构的信用评级,连同计算证明信息一同返回给区块链系统。区块链系统收集各机构给出的计算结果,综合得出该用户的信用评级。
在这种模式下,TEE保证了链外计算过程可靠,区块链保证了最终的计算结果真实有效、不可篡改。另外,区块链只存储计算结果而不存储数据源,从而在保障数据隐私的情况下,实现数据的协同共享。
作为一种去中心化的分布式系统,区块链系统在生产环境中会受到网络条件、节点规模、监管政策等多方面因素的影响,因此,需要解决运维与合规问题,以保证分布式系统线上运行的安全与稳定。本章主要从区块链权限体系、治理模型、审计及BaaS(Blockchainas a Service,区块链即服务)运维治理四个方面出发,说明区块链系统解决运维与合规问题采用的理论模型与工程实践方案。
区块链权限体系
在计算机系统中,广义上的权限体系一般包括三个部分:
- 授权。授权指的是用户主动或被动获取访问受保护资源能力的过程,如文件拥有者给予其他用户组进行文件读、写及执行的能力。
- 鉴权。鉴权指的是用户访问受保护资源时通过特定机制和凭证校验用户是否具有访问能力的过程。例如,用户在读取文件系统中的某一文件时,操作系统会根据文件中的权限信息、用户名及用户所在的用户组,判断用户是否具有文件读的能力。
- 受保护资源。受保护资源指的是受到一定条件约束的资源。这里的资源是广义上的概念,可以是应用接口,也可以是文件或特定格式的数据等。
总的来说,计算机系统通过授权、鉴权及受保护资源三个部分共同构成的权限体系,限制不同用户的行为。
在去中心化的区块链系统中,权限体系根据受保护资源对系统的影响范围,可以划分成若干层级。每个层级又可以细分出不同的受保护资源。不同的受保护资源具有截然不同的权限管理机制。本节首先介绍在区块链系统中处在不同层级的权限体系及其保护的资源,再介绍区块链上授权与鉴权使用的权限管理模型。
(1)权限层级
总体上,在区块链系统中,权限体系用于保护资源,一般可以从受保护资源对区块链系统的影响层级范围的维度,将权限层级划分成四类:
- 对整个区块链运转产生影响的链级权限
- 对单个智能合约运行产生影响的合约权限
- 对区块链上单个账号产生影响的账号权限
- 对区块链系统中单个节点产生影响的节点权限
本节将系统性地介绍上述四类权限,包括权限体系保护的资源及保护的大致方式。
1、链级权限
链级资源指的是区块链系统中需要所有节点保持一致的参数配置集合。链级资源的访问指的是在区块链系统中对上述配置进行统一变更的操作。链级权限就是保护链级资源的权限机制。链级资源一般在区块链系统创世时就稳定地存在于区块链系统中。区块链系统创世之后,需要所有节点保持一致的参数配置集合,一般不可以扩大或缩小,否则容易导致区块链系统分叉。链级资源一般需要通过特殊的交易访问,保证节点间的一致性;链级资源的访问必须在一定程度上受限,不可以轻易被访问,链级资源一旦随意被访问,很容易导致功能的混乱,进而使整个系统受到不可逆的损害。
一般来说,公有链系统都会通过系统内置智能合约实现投票机制的方式,进行链级权限的保护。目前主要有两种方式,
- 一种是直接基于公投的方式进行链级权限的访问。
- 一种是通过公投的方式选出可以访问链级资源的代理人。而在联盟链中,往往通过一定的机制授予特定管理员账号访问受限接口的权限。
现有系统中链级资源的范例很多,一般可以根据其影响区块链系统的阶段分为如下两类。
- 一类是共识参数配置。一般是影响共识打包交易过程中所有可以在链上进行动态修改的参数,不同的链采用不同的共识算法,因而可变更的参数各不相同。从区块链系统创世时开始,在不断出块的过程中,参与区块链系统的节点、系统网络架构及在链上运行的业务都可能会发生变更。共识参数配置这类资源存在的意义,就是使区块链系统的共识打包拥有线上调节能力,让系统能够在一定程度上适应变化带来的影响,从而更平稳地运行。当前,共识参数的配置主要包括区块打包时间、区块大小、共识节点选择及共识算法等,如EOS柚子币使用DPoS共识算法中的超级节点选取、NEO小蚁币使用dBFT共识算法中的验证者节点选取、区块交易数量上限设置、区块大小上限设置,以及Hyperledger Fabric的区块打包时间配置、区块大小上限设置、共识算法配置等。
- 一类是执行参数配置。一般是区块执行过程中所有可以在链上进行动态修改的参数,不同的链往往具有不同的执行引擎,执行引擎中可调整的参数也各不相同。在区块链系统的执行引擎中,会为交易执行提供一些通用服务,如进行状态数据存取、智能合约名称到地址的转换等。随着区块链系统上运行的业务智能合约不断发展迭代、用户数量变化及账本数据量不断积累,为了业务智能合约能更好地运转,这些服务的配置同样需要合理的调整。而执行参数配置这类资源存在的意义,就是使区块链系统的执行引擎具有线上调整的能力,从而更好地满足业务需求。当前,执行参数配置范围主要包括执行计费参数、存储计费参数、黑白名单、智能合约名称与智能合约地址的转换表及哈希算法等。如Hyperledger Fabric的哈希算法配置、FISCO BCOS的智能合约域名服务等。
总的来说,如果将区块链系统看作处在不同物理机上的状态机,那么链级共识参数配置用于保证所有状态机的动作可以发生一定程度的变更,且在发生变更时其动作也能保持一致;而链级执行参数配置用于保证状态机执行动作的方式可以发生一定程度的变更,且发生变更时其执行动作的方式也能保持一致。
二者结合,保证区块链系统能够在上线后进行一定程度的调整,进而适应其网络环境和业务场景。
2、合约权限
合约权限指的是业务智能合约操作接口的访问控制。受保护的操作包括智能合约的维护与调用。智能合约的维护一般指的是智能合约的更新、状态变更等,相当于一般Web系统的后台操作接口。大多数区块链系统都将智能合约的维护权限默认赋予智能合约的部署者。而智能合约的调用指的是区块链平台的用户以发起交易的方式访问智能合约接口。
不论是智能合约的维护还是调用,都需要通过特定的标识符指向所访问的智能合约,一般来讲,这个特定的标识符是系统分配的智能合约地址。对于一些提供智能合约命名服务的区块链系统来说,该标识符还可能是智能合约名称。基于智能合约的标识符,在区块链执行引擎层面可以提供黑白名单机制,对智能合约接口进行整体保护。
如果需要进行细粒度的智能合约方法级的权限控制,通常有两种方法,
- 一种是侵入式方法
- 一种是非侵入式方法
首先介绍侵入式方法。顾名思义,以侵入式方法进行细粒度的智能合约方法级的权限控制,需要侵入智能合约对外暴露的可调用接口,一般在需要进行权限控制的智能合约方法头部注入与权限控制相关的代码。这种方式实现的权限控制需要在编写智能合约时考虑好权限控制的整体设计并完成编码。如果智能合约部署之后需要更改权限控制方式,那么就需要通过更新智能合约的方式更改权限控制方式。
相比侵入式方法,非侵入式方法的智能合约权限控制不需要侵入智能合约,但是其要求区块链系统提供智能合约接口权限控制组件。该组件需要为智能合约运维人员提供智能合约接口权限细粒度控制规则的维护接口,在智能合约执行前预先解析交易的内容,然后根据智能合约运维人员设置的规则进行过滤。
基于上述两种方法实现的智能合约接口的细粒度权限控制,可以分成几种常见机制:
- 第一种是单一账号权限,仅允许某个账号访问特定接口
- 第二种是黑白名单
- 第三种是链上投票授权
从系统整体的角度来说,区块链系统是智能合约的运行框架,每份智能合约都是运行在系统上的业务逻辑。因此,从区块链系统的角度来说,侵入式方法实现的智能合约权限控制侵入了业务逻辑,并不是一个好的设计思路。区块链系统中的交易需要区块链账号签名发起,而且权限检查机制一般也要求输入区块链账号标识符进行检查,因此,理论上所有的区块链系统都可以提供通用的智能合约接口权限控制组件,以非侵入式方法支持智能合约权限检查。
相比保护影响所有交易共识打包和执行参数的链级权限,智能合约权限的保护范围仅限单份智能合约,其影响范围较小。某份智能合约的权限控制变化并不会影响不使用该智能合约的用户。
3、账号权限
在区块链账本上的主体,除智能合约外,一般还包括区块链账号。用户从客户端向区块链系统发送以特定方式构造的交易后,区块链系统检查交易发送方是否可以操作指定区块链账号进行某些动作,如转账或智能合约调用。账号权限核心就是保护区块链账本上的账号,使其不会被随意使用。
根据不同区块链系统中账号模型的不同,账号权限也会有一定区别,但是总的来说,区块链系统中的账号权限基本还是基于公钥密码学实现的,只是具体实现方式会有一定区别。一部分区块链系统的实现方式是区块链账号和密钥对一一对应的权限控制方式,另一部分区块链系统的实现方式是区块链账号和密钥一对多的多重签名权限控制方式。
4、节点权限
上述三类权限受保护的主体,不论是链级参数、智能合约接口还是区块链账号,都是一个区块链系统中全局的概念,因此,上述三类权限控制机制在区块链系统的所有节点上,都是以相同的方式运作的。
节点权限相比上述三类权限,是一个单点的概念。理论上,一个区块链系统中的节点只需要满足特定的协议,就可以用不同的方式来实现,也可以对客户端提供不同的接口。节点权限所保护的资源是实现区块链节点协议的服务器端对其客户端暴露的接口,确保接口不可以被随意访问。
如果站在用户的角度观察客户端和服务器端的交互过程,就会发现如果屏蔽区块链节点之间的交互细节,那么区块链节点对客户端提供服务的模式和其他Web系统并没有太大区别,因此,区块链节点权限的设计思路和其他Web系统基本类似。一般将访问节点的用户按照一定规则分组,用户访问节点接口时需要事先访问节点提供的登录系统,登录获取令牌之后,再使用令牌访问节点的其他受保护接口。通常来说,Web系统会实现一套RBAC(Role-Based Access Control,基于角色的访问控制)子系统来完成上述过程,各类Web系统开发框架一般也会提供相应的接口。对区块链节点来说,因为存在天然的区块链账号系统,因此,节点权限可以基于区块链账号的RBAC子系统进行接口保护,也可以自己实现一套独有的账号系统。
(2)权限管理模型
访问权限体系保护的资源,必须经过一定的授权、鉴权过程,本节将目前在区块链系统中使用的主要权限的授予与鉴别体系整理为几类权限管理模型,并对其一一进行介绍。在实际区块链系统设计和实现中,往往会使用多个权限管理模型组合形成权限体系。
1、基于公钥密码学的权限管理模型
对区块链系统来说,基于公钥密码学的权限管理模型是必备的。主流的区块链系统都是以直接或间接的方式基于公钥密码学来实现其账号系统权限控制的。其他权限管理模型往往要在基于公钥密码学构建的账号系统上进行构建。
基于公钥密码学的权限管理模型包含的要素有公钥密码学算法、密钥对、由公钥计算得到的地址、数字签名。在区块链系统中,公钥密码学所解决的问题是一个“如何证明我是我”的问题。
简单来说,基于公钥密码学的权限管理模型主要由密钥生成、数字签名、验证签名三个过程组成。
- 密钥生成指的是根据公钥密码学算法随机生成密钥的过程
- 数字签名指的是使用私钥对一段文本使用签名算法生成数字签名的过程
- 验证签名指的是通过验证数字签名证明生成数字签名的实体拥有特定密钥对的过程
现在广泛用于区块链系统权限管理模型中的主要公钥密码学算法是椭圆曲线算法,其授权鉴权流程如下图所示。

用户在客户端基于椭圆曲线算法,使用特定工具生成密钥对。生成密钥对的工具一般来说没有具体限制,既可以是软实现的钱包等软件工具,又可以是实现密码学算法的硬件工具,如银行U盾、加密芯片等。私钥只能永远保存在客户端本地,由用户使用专门的软件自行管理。特别地,对使用硬件生成的密钥来说,私钥通常是无法传输到硬件以外的。一旦用户持有密钥对,那么用户就会持有该密钥对指向的链上资源的控制权,这里的链上资源不一定指区块链账号。生成密钥对之后,用户需要自行管理密钥对,以供后续使用。
当用户希望操作链上资源时,需要通过密码学手段证明自己对链上资源的控制权。这依赖用户和区块链系统使用相同的数字签名协议,即使用相同的数字签名算法和签名算法入参的构造方法。证明方式是在操作请求中附带公钥信息;将请求中的部分参数按照约定好的数字签名协议拼接成字符串,使用特定摘要算法生成消息摘要;将消息摘要输入钱包,由钱包根据私钥生成数字签名;用户将数字签名附加在请求中发送给区块链系统,等待返回。对大多数区块链系统来说,上述公钥信息一般指的是根据公钥使用特定算法计算得到的一个定长的字符串,也就是所谓的地址。
密钥对生成和请求构造,合起来看就对应权限管理模型中的授权。
- 权限的管理者是密钥对的持有者
- 授权的对象是操作请求
- 授权的过程是生成数字签名
区块链系统在收到请求之后,在服务器端的API层解析请求中的各项参数;在验签组件中,按照数字签名协议将参数拼接成字符串,并计算出消息摘要,基于椭圆曲线算法的特性从消息摘要和数字签名中恢复出公钥;验签组件验证公钥信息与公钥是否匹配,若不匹配则返回错误;通过公钥信息验证之后,验签组件再根据参数中的数字签名及前置步骤中计算出的消息摘要和公钥,基于密码学算法验证公钥对应的私钥是否被请求发送方持有,这个过程称为验签,也就是基于公钥密码学的权限管理模型的鉴权过程;如果通过验证,则将解析出来的其他参数输入到其他内部组件,完成用户希望执行的操作并返回,反之则返回错误。因为签名的验证除公开的算法与协议之外,请求所输入的参数都是由用户输入的,所以这也是一个零知识证明。
以著名的公有链项目以太坊为例,以太坊用户只需要在客户端根据椭圆曲线算法ECDSA-secp256k1生成密钥对,在交易中携带根据公钥计算出的区块链账号地址、其他交易参数及对整个交易体使用私钥生成的数字签名,并将交易发到区块链上,区块链系统就能够进行密码学验签,以验证交易发送方拥有地址所标识的区块链账号的操作权限。
总的来说,在这类权限管理模型中,授权对应的是密钥生成与数字签名,鉴权对应的是数字签名的验证。整体通过一种零知识证明手段,完成区块链系统外的授权与区块链系统内的鉴权。这类权限管理模型的特点是单签名,密钥对与其控制的区块链资源是一一对应关系。如果密钥遗失,且区块链系统没有提供特殊挂失机制进行资源的迁移,那么密钥指向的资源就会变成一个黑洞,再没有人可以控制。通过这种密码学手段,以太坊等区块链系统实现了账号的权限控制。
2、基于链下多重签名的权限管理模型
基于链下多重签名本质上是基于公钥密码学的扩展。这类权限管理模型与基于公钥密码学的权限管理模型最大的不同在于密钥与受保护资源的比例关系。
基于链下多重签名的权限管理模型往往具有这样的特点:受保护资源与密钥的比例关系是一对多,当访问受保护资源时,需要其对应的密钥集合中的若干密钥对操作请求进行签名,才能通过权限检查,进行受保护资源的访问。
在这类权限管理模型下的操作,又称为M-of-N交易。其中,M表示操作生效所需要收集的不同密钥产生的签名集合,N表示所有控制受保护资源的密钥集合。M定义中的签名必须由可以控制所有操作受保护资源的大小为N的密钥集合的某个大小为M的子集生成。其他部分与基于公钥密码学的权限管理模型大致相同。
一般来说,可以给操作请求授权的所有密钥的公钥集合及最低授权阈值,都需要在资源被初始化的时候就预先记录在区块链账本上,与受保护资源一一对应。这样,区块链系统才可以鉴别访问目标资源的通过条件。
基于链下多重签名的权限管理模型的授权鉴权流程如下图所示。用户访问目标资源时,需要先构造出操作请求,通过链下系统将请求转发给可以进行授权的其他用户。其他用户在收到请求之后对其进行解析,并判断是否同意操作,如果同意则在返回给生成操作请求的返回消息中附加自己对请求的签名。生成请求的用户在收集到足够多的签名之后,可以将所有签名和对应的公钥信息附加在请求中,发给区块链系统。区块链系统在收到请求之后,解析请求并按照基于公钥密码学的权限管理模型的验签流程对所有签名逐一验签,判断是否有足够多的控制资源的密钥对为操作生成签名。满足上述条件之后才执行操作。

通过链下多重签名技术,比特币实现了支付通道与闪电网络等扩展功能,这里通过介绍比特币使用的多重签名机制来说明这类权限管理模型实现的具体方式。
在比特币中,资源通过地址进行标识,常见的包括
- P2PKH(Pay-to-Pub Key Hash,向公钥哈希支付):单签名,由公钥直接生成地址,也就是基于公钥密码学的权限管理模型所说的公钥信息。
- P2SH(Pay-to-Script Hash,向脚本哈希支付):比特币实现多重签名的基础,P2SH地址是多重签名机制所保护的资源的标识符。P2SH提供赎回脚本的机制,以定制使用权限。当代币被转入P2SH地址时,想要动用代币就需要满足赎回脚本所设置的条件。如果赎回脚本所设置的条件是输入N个公钥与M个密钥对产生的签名,那么这种赎回脚本也被称为多重签名脚本。
关于P2SH,举一个更具体的例子,2-of-3多重签名脚本常被用于施行有仲裁人介入的三方交易,多重签名脚本操作码样例如下所示。
OP_2 [pub0] [pub1] [pub2] OP_3 OP_CHECKMULTISIG
其中,
- OP_2表示需要2个人的签名
- pub0、pub1、pub2分别表示参与交易的三方的公钥
- OP_3表示输入3个公钥
- OP_CHECKMULTISIG表示执行多重签名验证
当代币被转入P2SH地址时,用户需要收集交易三方中至少两方的数字签名作为输入,才能够将代币转出,完成多重签名脚本的使命。
在上述比特币的例子中,
- 受保护资源是多重签名脚本的P2SH地址中的代币
- 授权是在多重签名脚本指定的密钥集合中,有满足要求数量的密钥对交易签名的过程
- 鉴权则是在多重签名脚本中验证签名的过程
值得注意的是,签名的收集一般是在区块链系统外完成的。相比基于公钥密码学的权限管理模型,也就是单签名模型,基于链下多重签名的权限管理模型的好处在于实现了资源管理权限的去中心化,允许有不超过N~M个密钥的丢失,但是也给受保护资源的操作引入了额外的复杂度。在使用该模型的系统中,用户构造访问受保护资源的操作请求时,需要依赖外部的机制来收集足够多的签名,以构造符合要求的操作请求。这类权限管理模型一般用于账号权限控制和侵入式的智能合约权限控制。
3、基于提案投票的权限管理模型
基于提案投票的权限管理模型指的是通过在内置智能合约或业务合约中设计一套提案投票机制来保护特定资源的机制。
在整个模型中包含两方面要素,
- 参与方管理:参与方管理指的是管理有哪些用户可以参与提案投票管理
- 提案投票管理:提案投票管理指的是访问受保护资源必须以提案的形式发起交易,然后由参与方发起投票交易,通过投票来决定提案是否能够执行。
这类模型的目的同样是实现资源管理权限的去中心化。虽然一些区块链系统也将这类模型称为多重签名,但是这类模型和基于链下多重签名的权限管理模型是有一定区别的。
- 首先,在该模型下,签名的收集并不需要依赖其他系统在一笔交易中附加所有签名,而在区块链系统中直接记录签名收集的情况,将多个签名分散到多次交易中输入
- 其次,该模型通过记录参与方的投票状态,提供反悔机制,即允许某密钥对持有方先授权后拒绝授权的操作
- 最后,该模型通过合理的设计可以灵活扩展,一方面,提案机制可以与RPC(RemoteProcedure Call,远程过程调用)结合,灵活地扩展提案可执行的逻辑;另一方面,可以对提案机制进行嵌套组合,形成一个类似现实生活中的代议制度的多级投票系统。
通用的基于提案投票的权限管理模型一般是按照如下思路设计的。
在该模型初始化时,需要初始化投票系统的状态,并记录在区块链账本上。首先,进行参与方的初始化,包括所有可以参与投票的参与方的标识符和投票权重;然后,进行投票机制参数的初始化,包括同意票阈值、反对票阈值、提案失效条件等。一般来说,提案需要一个最长有效期,这个有效期可以通过区块高度或交易打包时间来规定,也就是说,一个提案在账本上成功创建之后,在区块高度小于一定值或交易打包时间小于一定值的区块内才被允许投票或执行;最后,进行资源访问接口的初始化,一般来说,最通用的做法是将资源访问接口以类似RPC接口注册的方式注册为一个可以通过提案投票机制调用的接口。值得注意的是,通常可以将参与方与提案投票的参数变更接口注册为提案可访问的资源,实现系统的自维护。
基于提案投票的权限管理模型的授权鉴权流程如下图所示,访问系统资源主要有以下三个需要用户操作的环节。

- 提案。在提案环节一般需要结合数字签名来证明提案的发起方在参与方列表中。此外,发起提案需要将资源访问接口调用所需要的参数全部包含在交易参数中,发给区块链系统。当提案交易执行时,一般会嵌入检查条件来检查是否能够进行提案创建。通过检查后,调用参数将包含在提案数据中,存放在区块链账本上,以供后续使用。提案产生之后,可以通过多种交互机制来通知所有参与方,如消息队列或客户端轮询等。
- 投票。当提案创建之后,参与方可以通过各自的手段获取提案信息,并根据自己对调用的认可情况来选择是否使用密钥签署投票交易,对提案发起同意票或反对票。区块链系统执行时会在账本上记录参与方的投票信息。
- 执行。当提案的同意票达到要求的阈值之后,参与方就可以使用密钥签署执行交易来使提案生效了。具体方法是从账本上读出资源调用参数,然后进行调用。
上述环节描述了基于提案投票的权限管理模型初始化和运作的一般机制,具体在区块链系统实现中,一般基于该模型做一定程度的简化或扩展。例如,可能会合并其中的投票和请求执行的步骤,以实现自动执行;还可以根据对提案执行顺序的要求引入一些顺序保障机制等。在该模型中,授权涉及初始化、提案、投票三个过程;鉴权则通过执行提案时检查同意票是否达到阈值来进行。
基于该模型,区块链系统可以实现相对灵活的去中心化权限管理模型。例如,公有链项目EOS基于提案投票的权限管理模型设计了其账号权限机制与超级节点选举机制。
4、基于角色的权限控制模型
基于角色的权限控制模型是在计算机系统中常见的一种权限控制模型。其核心思想是在权限与账号之间增加一层角色的概念,将权限赋予角色,再将角色赋予账号,建立权限、角色、账号之间的多对多对多关系。基于角色的权限控制模型以账号体系为基础,因此,该模型需要结合前文所述的三类权限管理模型所实现的区块链账号体系才得以构建,无法单独存在。
在区块链系统中,构建基于角色的权限控制模型通常需要在账本上存储三张权限表。
- 一张白名单表用于资源访问接口与角色的多对多关系存储,记录哪些角色可以访问接口
- 一张黑名单表用于资源访问接口与角色的多对多关系存储,记录哪些角色禁止访问接口
- 一张角色表用于角色与账号的多对多关系存储,记录账号具有哪些角色。
授权的过程就是权限表维护的过程,因此,授权操作本身也是一种对资源的访问,可以使用各种权限控制模型进行保护。如果需要使用模型自身进行保护,则需要在初始化时创建一个可以对权限表进行更改的角色,并赋予该角色一些特定账号。
鉴权的过程就是查表。首先,根据发起操作的账号标识符查询所有角色,然后,在白名单表和黑名单表中查询其角色是否具有相应权限,不同的系统会制定不同的检查策略。比较普遍的设计如下图所示。当账号具有的角色中至少有一个在白名单表中,且没有任何一个在黑名单表中时,账号可以通过鉴权执行资源访问,否则拒绝访问。

区块链治理模型
随着区块链系统的运行,人们逐渐意识到现有的区块链系统无法满足需求,需要加以升级、变更来满足实际的需求。然而,区块链系统如何变更、朝着哪个方向变更,以及变更哪些内容等问题需要做出决策。例如,当需要对整个区块链系统的配置、链上的数据甚至各个节点提供的接口、访问区块链系统的用户等进行变更时,如何能够让整个区块链系统都知道这个变更,并最终达成一致。为了满足上述需求,需要对区块链进行治理。
为了实现去中心化的区块链治理,需要对区块链系统的管理预先制定好规则、协议。对于需要整个区块链同步的管理,由具有对区块链管理权限的用户表决同意后,管理策略才会生效。根据如何对管理策略达成一致性结果及管理策略的生效方式,将区块链治理模型分为链上治理和链下治理两种。
(1)链上治理
1、链上治理
链上治理,即将治理规则、协议写入代码,通过交易与区块链系统的交互来完成对区块链的治理。
通过链上治理,区块链管理员可以通过向区块链系统发起交易的方式,对区块链的管理变更进行提议、表决等操作,表决通过后自动进行变更。
为了实现链上治理,区块链系统需要提供相应的接口,并允许具有区块链管理权限的用户通过特殊的形式,基于预先制定好的规则、协议对区块链进行管理。通过区块链系统提供的接口可以查询当前区块链系统处于一个什么样的状态;这种特殊的形式可以是一种特殊的交易,即配置交易;预先制定好的规则、协议可以写入智能合约,在系统启动或执行配置交易时将智能合约部署到区块链上。
链上治理流程图如下图所示。

- 创建提案。由具有区块链管理权限的用户,根据当前区块链系统的实际运行情况创建提案,修改区块链的相应参数,区块链系统能够在提案生效后,按照用户期望的参数配置运行。
- 投票。具有区块链管理权限的用户,需要知道提案的具体内容,并对提案的内容进行评估,决定自己是否同意当前提案中的内容。如果同意则投赞同票,不同意则投反对票。
- 提案是否生效。当同意此提案的用户数或总权重数达到一定阈值后,此提案投票通过。系统会根据投票通过的提案进行相应的变更,变更完成之后,提案生效,后续交易等操作将按照此配置执行。如果提案投票来通过,如被否决、取消或超时,则提案无效。
从上述流程可以看到,一个修改区块链相应配置参数的提案是否生效,是由具有区块链管理权限的用户投票决定的。现有的投票模型多种多样,不同的投票模型适用于不同的场景。例如,Futarchy投票模型旨在使价值最大化,即“对价值投票,对信仰投票”;民主投票模型中每个人都有投票的权力;二次方投票模型中每次投票的成本都是递增的。
随着链上治理模型的提出,越来越多的人在不断尝试将其应用到实际的区块链系统中。
- Tezos。Tezos是最早提出在链上进行治理的区块链项目,其支持持币方通过投票的方式进行技术升级和迭代。在Tezos中,持币方为具有区块链管理权限的用户,货币使用股份授权证明机制(DPoS)奖励区块创造者。投票模型采用民主投票模型,每个持币方都可以进行投票,也可以委托他人进行投票,投票的权重与持币量相关。
- Hyperledger Fabric。Hyperledger Fabric是一个开源的企业级区块链项目,其通过权限管理和背书策略实现链上治理。Hyperledger Fabric使用权限管理机制,按照不同的角色区分区块链系统用户,具有特定角色的用户才具有区块链管理权限;Hyperledger Fabric使用背书策略实现投票的功能,当需要修改配置时,通过发送配置交易来修改相应配置,配置交易需要满足系统中配置链码智能合约的背书策略中指定的背书条件,才能被打包进区块,等待执行。
2、配置交易
配置交易是用于修改区块链配置的交易,如共识算法、共识参数、节点管理等。在配置交易之后打包执行的交易都需要按照配置交易修改后的配置执行,因此,在打包交易时需要单独打包,与普通交易区分开。
通过执行配置交易,可以实现动态修改配置文件。没有配置交易的区块链网络若想要修改配置文件,则需要先把节点停机,手动修改节点的配置项,然后重启配置项才会生效。支持配置交易的区块链网络可以通过执行配置交易动态修改配置文件,不用停机重启;通过执行配置交易,可以实现链上治理区块链网络。对联盟链而言,没有配置交易的区块链网络若想要对节点网络拓扑进行管理,则需要线下协商拿到相应的许可,然后才能对节点网络拓扑进行管理。支持配置交易的区块链网络可以通过执行配置交易对节点网络拓扑进行管理,使管理更加高效。
由于执行配置交易会对整个区块链网络产生影响,因此,需要对配置交易的执行进行权限控制。另外,执行配置交易的过程会涉及区块链级别的相关配置变更,配置交易之后的交易都需要按照此变更执行,因此,需要对配置交易单独打包。
配置交易的运行流程和普通交易的运行流程有些差异。例如,配置交易打包时需要单独打包,配置交易需要投票通过后才能执行生效等。配置交易的运行流程如下图所示。

- 节点在对交易进行打包时,若发现当前需要打包的交易中包含配置交易,则需要将配置交易之前的交易打包排序放在一个区块中分发出去,再将配置交易单独打包到一个区块中分发出去。
- 节点在收到区块后,根据区块中打包的交易顺序一笔一笔地将交易应用到自己的账本中。对于配置交易,具体的操作如下。
- 验证配置交易参数的合法性。验证配置交易参数合法性时,首先验证配置交易的签名、投票结果等信息,验证通过后再验证配置交易中变更配置项的合法性,当上述信息都验证通过后,进入下一阶段。
- 当配置交易参数的合法性都验证通过后,尝试根据智能合约将配置交易中新的配置项变更到内存中。
- 对于配置发生了变化的相应配置项,需要通知其他依赖此配置项的模块进行相应的配置同步,并根据最新的配置依照各自的情况判断是否需要进行相应的变更调整。
- 当与变更的配置项相关的模块都完成配置同步后,将内存中的配置变更落盘。
3、基于智能合约的分布式治理
基于智能合约的分布式治理指基于特定的智能合约,每个节点都按照相应的规则执行智能合约,完成相应的配置变更,最后整个区块链网络处于一致的状态。
基于智能合约的分布式治理可以将治理时使用的投票模型编码到智能合约中,配置交易中修改区块链配置的提案由智能合约进行记录,提案是否通过由智能合约自动化裁决,并由智能合约进行配置的变更。基于智能合约的分布式治理可以将配置项变更的规则编码到智能合约中,配置交易中修改的配置项将根据智能合约中的规则进行变更。
基于智能合约的分布式治理以管理提案的提案智能合约为入口,根据对提案的管理完成对分布式系统的治理变更。
提案智能合约提供创建提案、投票及执行提案接口。在执行提案中,根据配置智能合约提供的相应接口,完成相应配置的修改。其结构如下图所示。

基于智能合约的分布式治理运行流程图如下图所示。

- 具有区块链管理权限的用户在发送交易时,通过提案智能合约提供的创建提案接口来创建提案,提案中包含此次提案变更的内容。
- 提案创建完成后,由其他具有区块链管理权限的用户根据各自的情况对此提案变更的内容进行投票,同意此变更投赞同票,不同意此变更投反对票。当赞同票达到一定数量后,此提案通过,进入下一步执行提案阶段。当反对票达到一定数量或在一定时间内没有收集到足够多的赞同票时,此提案未通过且到此结束,提案中提出的相应变更也不会生效。
- 在执行提案时,根据提案的内容,通过配置智能合约提供的配置修改接口完成相应的变更。
(3)链下治理
1、概述
链下治理指链的开发者、用户在真实世界中围绕链的治理问题,成立了一些组织、基金会,以这些组织或基金会为代表与社区进行互动,决定对链上一些问题的处理方案及链的功能、参数等的调整,后续通过特定的手段将这些决定传到链上。
2、运行流程
链下治理与链上治理相比,决策的达成不在链上进行,当只有部分相关人员同意此决策时会产生分叉。其运行流程如下图所示。
- 具有区块链管理权限的相关人员通过链下的方式,如邮件、社区等,对区块链系统的升级变更进行协商,最终得到一个变更方案。
- 同意此变更方案的相关人员将此方案中的内容升级同步到其管理的区块链节点中。
- 如果所有相关人员都同意此方案,那么最终所有的区块链节点都会升级到同一状态,不会出现分叉。
- 如果只有部分相关人员同意此方案,这部分相关人员将此方案中的内容升级同步到其管理的区块链节点中,但是其他不同意此方案的相关人员没有将此方案中的内容升级同步到其管理的节点中,那么此时将产生分叉。
分叉分为硬分叉和软分叉两种。
- 硬分叉指区块链发生永久性分歧,在新共识规则发布后,部分未升级的节点无法验证已升级的节点生成的区块。
- 软分叉是指区块链或去中心化网络中向前兼容的分叉。当新共识规则发布后,在去中心化网络中,节点不一定要升级到新的共识规则,因为软分叉的新规则仍符合旧规则,所有未升级的节点仍能接受新规则。
最终升级后出现硬分叉还是软分叉取决于区块链系统的实际情况。

链下治理虽然容易产生分叉,但是也广泛存在使用链下治理的区块链系统。
以太坊的治理就使用了链下治理。当需要对区块链系统的相关协议进行变更时,以太坊的开发者就在社区中创建相应的issue,通过发邮件等方式通知相关人员在社区中就此issue进行讨论协商。最后,将协商的结果应用到相应节点。
区块链审计
对于一个重要的信息系统,保证其正确性与安全性是必不可少的。随着互联网的蓬勃发展,通过计算机犯罪和信息系统攻击的事件不断出现,因此,通过审计确保信息系统的正确性和安全性有着极大的意义。由于大多数区块链系统都会运行“资产”,因此,系统的安全性显得愈加重要。虽然区块链系统本身通过共识算法和密码学算法可以在一定程度上保证其运行的安全性,但是对大多数区块链系统而言,很难完全保证系统按照预期运行下去。另外,在受到外部攻击时,区块链系统很难在不经改造的情况下完全依靠自身追踪攻击过程,这时就需要给区块链系统插上审计的“翅膀”。
(1)审计概述
审计是对系统安全、数据合规的一种有力保障,一般对一个信息系统的运行状况进行检查与评价,以判断信息系统能否保证资产的安全、数据的完整,信息系统能否有效率地利用组织的资源、有效果地实现组织目标。审计往往处在系统的高层次,作为系统的最后一道管控防线。
区块链本质上是一个分布式数据库。分布式系统的执行环境往往是异常复杂的,很多情况都涉及多节点间的消息通信。在区块链系统中,存在许多影响系统状态变更的事件,这些事件导致系统产生各种行为。例如,区块链系统大多通过交易进行事件触发,交易在执行过程中可能会产生预期结果,也可能会触发系统异常行为。对在区块链系统上进行的业务而言,对整个系统的过程做到可追溯、可验证,无疑能在极大程度上保障业务的进行。因此,通过对区块链系统中的系统活动过程进行记录、分析,实现对区块链系统的审计,具有十分重要的意义。
(2)区块链审计的内容与形式
1、区块链审计的内容
对于不同区块链系统的用户,其审计需求包含不同程度的内容。一般而言,区块链审计的内容包含以下几个部分。
- 外部操作。外部操作是外部对于区块链系统输入的事件。这些事件包括:用户对于区块链系统接口的调用请求,用户或管理员通过命令行等对区块链系统发起的操作请求。这些操作或调用请求应当包含发起方的信息、具体操作的信息,同时,这些事件应包含系统对于请求响应的信息。对于区块链系统,其状态的改变基本都是由外部操作触发的,最基本的事件就是交易请求。当前区块链系统虽然在一定程度上能进行交易及状态的追溯,但是基本都限于业务层面。而通过系统层面更加详细地记录,可以更加清晰地确定外部操作,从而更好地管控业务。
- 内部事件。区块链系统本身包含多种技术,如共识算法、密码学算法、P2P网络等。系统的复杂性使得系统在运行过程中会产生许多事件,包括节点内部与区块链节点之间的事件。这些事件会影响系统运行的安全性与稳定性,如同步区块事件、共识算法异常事件、交易执行事件等。这些事件应当包含事件的发起方、事件的具体内容、事件的响应结果等详细信息。通过对内部事件的审计分析,可以对整个系统的运行过程进行追溯还原,从而更好地管控系统的安全性与稳定性。
- 账本内容。区块链本质上是一个分布式账本,一切重要的变更本质上都是对账本的变更。对账本内容的变更进行审计能更加清晰地掌控业务的活动状况。同时,账本数据包含与业务相关的数据,对账本数据的直接审计能更方便地完成对业务的审计。
2、区块链审计的形式
日志审计
日志审计是指通过采集与分析程序运行日志的一种审计形式,对于程序运行,日志的生成与留存是很重要的,通过程序运行的日志,能够方便地得到整个系统的运行轨迹,进而得出用户及系统的行为。对于区块链系统,由于系统中每个节点都是对等的,每个节点都可以同等地接受外部交易与操作,因此,通过详细的日志记录与审计能够更加清晰地得到系统从输入到输出的整个运行过程,以达到审计的目的。
日志审计主要包含以下四个部分。
- 审计日志的生成。审计日志的生成是日志审计的前提,一般情况下需要系统开发者在系统的相应地方添加审计代码,审计代码包括审计内容的详细信息。审计日志的生成过程可以根据需求进行一定程度的范围及粒度控制。
- 审计日志的收集。审计日志的收集是指通过技术手段获取需要的审计日志的过程。审计日志的收集方式根据收集的手段、范围等有所差异。
- 审计日志的存储。在一般情况下,审计日志数量的量级可能很大,因此,需要考虑存储的扩展。审计日志通常会涉及区块链上的业务数据信息,因此,对审计日志进行加密存储,以及对审计日志的访问进行权限控制都是十分有必要的。
- 审计日志的分析与展示。对审计日志进行分析是审计的核心工作。区块链系统内部多模块及多节点交互的复杂性,对审计日志的分析提出了一定的挑战。审计日志的分析需要从审计日志中分析出系统运行的关键过程,更进一步,对于审计日志的分析可以实时进行。通过将分析结果以报告、图表等可视化的形式展示,更清晰地体现审计的结果与效果。由于日志审计用已经生成的日志进行审计,所以生成、获取日志的数量及详细程度是影响审计的关键。
数据审计
除可以通过生成审计日志来进行审计之外,还可以直接对区块链上的数据进行审计,以达到审计数据合规性的效果。审计区块链上的数据可以是账本数据。
由于账本数据直接存储于区块链节点上,因此,对于数据审计一般可以通过查询的方式,将所有账本数据取出后再进行审计。另外,也可以直接通过读取区块链账本数据库的方式进行审计。同样,读取数据之后,需要依据审计的需求对数据进行分析及展示,最终达到审计的目的。
由于数据审计直接作用于区块链节点上,因此,也会存在一些问题。以直接查询节点账本的方式获取数据会对区块链上运行的业务有一定的性能影响,同时,直接读取区块链账本可能会有节点停机的问题。因此,进行数据审计时需要根据审计的具体要求及业务的状况采用合理的方式。
就审计的效果而言,数据审计可以直接针对实际的数据,确定性更强,但是灵活性没有日志审计好。因此,也可以采用数据审计与日志审计相结合的方式,将账本数据以日志的形式另外记录分析,以完成审计。
(3)审计的展示与分析
审计的展示与分析是进行审计的关键,通过分析区块链产生的审计日志或区块链数据,能够得到审计的结果,如区块链系统接收到的所有交易及其内容、结果的正确性,区块链节点异常的次数与原因等,可以对这些数据进行直接展示与分析,以形成审计的结果。
下图为审计的一般处理流程图。审计的处理对象可以是区块链日志,也可以是数据。审计的第一步是对这些数据进行收集,首先,需要将日志尽量集中化,对于数据,一般是获取数据的访问权限或将数据集中化(区块链系统分布式的特点);接着,对这些日志或数据进行相应的流转过程或关联分析,这时可以借助一些查询分析工具,如搜索引擎等,帮助我们快速甚至自动化地进行分析过滤,得到想要的数据;最后,对得到的分析数据进行汇总、记录,形成可视化报告或图表,更好地进行展示。

BaaS运维治理
随着需求演化和业务发展,区块链底层和应用系统越来越需要合理的运维治理来保障服务的可拓展性、安全性和可靠性。BaaS作为区块链云服务平台,承担着区块链治理审计的责任。BaaS通过可视化的运维管理工具,实现如区块链权限体系、治理模型、审计分析等功能,使区块链的治理和审计更加高效、便捷和自动化。
(1)BaaS运维治理概述
1、BaaS的定义
BaaS的全称为Blockchain as a Service(区块链即服务),是一种新型的云服务。在企业级区块链发展初期,微软、IBM基于自己的云服务,推出了BaaS,为企业提供区块链云服务。
- 从云计算层次来看,由于区块链是分布式数据库,因此,针对区块链的云服务属于PaaS(Platform as a Service,平台及服务)层
- 从功能角度来看,BaaS主要提供区块链的生命周期管理、智能合约的研发管理、区块链的监控运维等功能,在降低企业上链门槛的同时,进一步助力企业更高效、安全、稳定地管理区块链业务
- 从平台未来发展来看,在区块链3.0阶段,联盟链凭借有限许可节点、高交易吞吐量等适配企业场景需求的特性,成为产业革新的重要着力点,而与联盟链深度融合的BaaS有望成为产业变革中的基础设施,助力产业变革安全、稳定推进。
2、BaaS的价值
从区块链治理角度而言,BaaS提供联盟链生命周期能力及联盟组网工具,帮助企业高效、统一管理联盟链,实现联盟成员自动化、可视化的准入准出;通过RBAC账户体系,帮助企业实现BaaS的多层级权限管控,避免人为事故的发生;另外,BaaS还提供全面完善的监控运维能力,可以快速定位系统故障,及时挽回业务损失。
从区块链审计角度而言,BaaS提供可视化的区块链交易浏览器及智能合约数据可视化功能,对链上的业务数据做类SQL查询和可视化分析,提高区块链审计的工作效率。
3、BaaS的通用架构
下图为通用BaaS架构图,从下至上分别是资源层、区块链平台层、BaaS服务层和应用层。

- 资源层。为区块链底层提供计算资源、存储资源和网络带宽资源,BaaS支持区块链底层部署物理机、虚拟机及容器集群。
- 区块链平台层。区块链平台层是通过自适应共识算法、点对点网络、混合型存储、多语言智能合约执行引擎等技术手段实现账本分布式一致性的系统。BaaS兼容不同的区块链底层,部署不同的服务资源。
- BaaS服务层。提供BaaS平台主体服务,如联盟链管理、监控运维、智能合约管理、智能研发。
- 应用层。通过BaaS,基于区块链底层研发的上层业务应用,包括存证溯源、供应链金融、公益慈善、数字积分。
4、运维治理
联盟链运维治理,包含
- 联盟链管理
- 联盟链运维
- 智能合约管理
三部分。联盟链管理实现联盟链的自动化部署、可视化管理,以及增强联盟链的可配置性和扩展性。在此基础上,为保障联盟链运维的稳定性,一套高效定位处理系统异常的监控运维组件同样不可或缺。而作为区块链业务落地环节的枢纽,智能合约的研发和管理是提升联盟链运维治理能力和效率的关键。
(2)联盟链管理
联盟链管理是指通过可视化、自动化的功能组件,对联盟链进行标准化、集中式、综合性的管理。联盟链管理功能的覆盖程度决定了联盟链的可扩展性和可维护性,是BaaS运维治理的核心和基础。
联盟链管理功能通常分为
- 联盟链配置
- 联盟链生命周期管理
- 节点生命周期管理
- 联盟组网
4个部分。
1、联盟链配置
联盟链配置对联盟链关键参数进行动态配置,以达到保障业务正常运行的目的。在联盟链业务的运行过程中,交易TPS(Transaction Per-Second,每秒交易数量)会随业务规模的扩大而增加,联盟链的区块生成策略需要动态更新;区块数据会逐渐积累,增大服务器的存储负担,存储空间存在动态扩容的必要。因此,联盟链配置是保障业务正常稳定运行的必要手段。以下是两种常见的联盟链配置类型。
- 联盟链参数配置,包括链名、节点名等业务参数,以及区块最大交易数、打包超时时长等链参数的可视化配置。
- 联盟链资源配置,包括服务资源的动态扩容、弹性伸缩等资源动态配置方式。
2、联盟链生命周期管理
联盟链生命周期是指联盟链从创建、启动、停止、重启到销毁的整个过程。联盟链生命周期管理是指对上述过程进行可视化操作的功能模块。联盟链生命周期管理的灵活度,直接影响联盟链上层业务的健壮性和可靠性,因此,联盟链生命周期管理是联盟链管理的核心。
由于联盟链生命周期管理中的操作都属于高危操作,因此对联盟链生命周期管理的管控同样必要。BaaS通常通过RBAC保障操作的严谨性和安全性,同时,对于拥有完善的联盟链管理机制的区块链底层,BaaS可引入联盟治理投票机制,联盟链生命周期管理中的操作只有在符合联盟成员投票策略时才能执行,以此避免误删、误停等事故的发生。
3、节点生命周期管理
节点生命周期是指节点从创建、启动、停止、重启到销毁的整个过程。节点生命周期管理是指对上述过程进行可视化操作的功能模块。节点生命周期管理与联盟链紧密联系、不可分割。与联盟链生命周期管理类似,在对节点生命周期管理操作可视化的基础上,BaaS通常通过RBAC和联盟治理投票机制保障节点生命周期管理操作的严谨性和安全性。
4、联盟组网
联盟组网是指在企业级联盟链场景中,通过一系列的组网工具和组件,突破网络环境、云环境的限制,各联盟成员可以部署节点,组成联盟网络。联盟组网可以极大地降低组网门槛,提升组网效率。为突破云环境的限制,BaaS通常具备节点的跨云部署能力;为突破网络环境的限制,BaaS通常提供可视化、自动化的组网工具,联盟成员可在自有IT环境中自动化安装,部署节点组成联盟网络。
对链和节点的管理,本质上是对状态的管理。这意味着可以采用FSM(Finite StateMachine,有限状态机)管理链和节点,从而实现有计划的、集中的、自动的资源调度。
有限状态机是根据现实事物运行规则,抽象而成的一个数学模型,由状态、事件、动作、变换四个概念组成。链和节点的状态可以定义为初始、运行、已停止、故障和已删除5种,如下表所示。

事件定义为用户对链和节点进行操作的一次请求,如用户请求创建链、请求启用节点等;动作定义为事件所对应的执行逻辑,如用户请求创建链的事件,对应的动作就是创建链;变换定义为状态转移,即从一个链和节点的状态转移到另一个状态。
链和节点的状态转移图如下图所示。

- 如果链和节点处于初始状态,则当用户请求创建事件时,执行创建动作,状态转移为运行状态。
- 如果链和节点处于运行状态,则当用户请求停用事件时,执行停用动作,状态转移为已停止状态;当用户请求重启、配置事件时,执行重启、配置动作,状态转移为运行状态。
- 如果链和节点处于已停止状态,则当用户请求启用事件时,执行启用动作,状态转移为运行状态;当用户请求配置事件时,执行配置动作,状态转移为已停止状态;当用户请求删除事件时,执行删除动作,状态转移为已删除状态。
上述创建、重启、配置、启用、停用、删除动作在执行过程中,如果出现异常,则状态转移为故障状态。
- 如果链和节点处于故障状态,则当用户请求恢复事件时,执行恢复动作,状态转移为运行状态。
- 如果恢复异常,则状态转移为故障状态。
在全部动作执行过程中,都加入超时条件。如果某次动作执行时达到超时时长但仍无法达到指定的目标状态,则状态统一转移为故障状态。
(3)智能合约管理
智能合约管理是通过综合、系统地运用智能合约相关开发工具、SDK等组件,对智能合约进行开发、部署,或者对已经部署的智能合约进行查询、操作等一系列活动的总称。
智能合约是区块链2.0阶段的核心特性,实现了区块链的可编程性,使得区块链应用在链上具备复杂逻辑的处理能力,绝大多数的区块链应用都离不开智能合约。而智能合约管理可以通过升级、冻结智能合约等方式提高区块链应用的安全性,可以通过有效收集、处理智能合约数据实现智能合约数据的可视化分析,因此,智能合约管理对区块链应用具有重要意义。
通用的智能合约管理方案应该满足以下两个要求。
- 第一,数据结构不会随着区块链应用的改变而改变
- 第二,可插拔地支持多语言、多区块链的智能合约
如下图所示,这是一个通用智能合约管理方案架构图。

该方案将智能合约管理系统分为三个组成部分:UI层、System层、插件层。
- UI层是与用户进行交互的前端界面,由IDE、生命周期管理、数据可视化三个模块组成。
- System层是实现管理功能的后端服务,由文件管理、插件管理、核心功能三个模块组成。
- 插件层是对多语言、区块链智能合约管理的具体实现,包括不同语言的智能合约开发插件(称为开发插件)和不同区块链底层的智能合约特性插件(称为链特性插件)。其中,插件可以是独立于智能合约管理系统的子服务,也可以是集中在智能合约管理系统中的内建模块;插件可以在前端的技术体系中直接实现,也可以在后端的技术体系中通过提供接口的形式实现。
UI层的三个模块抽象了智能合约管理的四大功能:
- 智能合约开发IDE
- 智能合约生命周期管理
- 智能合约数据可视化
- 智能合约安全检测
System层体现了智能合约管理的管理对象,包括智能合约文件、智能合约插件和智能合约实例(已经部署的智能合约)。插件层满足了可插拔地支持多语言、多区块链的智能合约管理需求。
1、智能合约开发IDE
智能合约开发是指根据用户要求编写区块链应用中智能合约程序的过程。智能合约开发IDE(Integrated Development Environment,集成开发环境)是指提供智能合约开发环境的应用程序,其一般集成了代码编写、分析、编译和调试等功能。
智能合约开发IDE的上述功能都由多语言的开发插件实现。针对不同语言的智能合约,插件提供语法高亮、关键字补全、智能提示、格式化等接口,以实现代码编写功能;提供静态分析、形式验证等接口,以实现代码分析功能;提供编译、部署、执行、Debug等接口,以实现代码编译和调试功能。
代码编写功能多由前端插件实现。插件提供语法描述元文件(如语法高亮的XML格式文件、关键字列表文件等),由前端的IDE框架通过正则匹配或语法分析等方法来动态解析、渲染并实现相应的代码编写功能。
代码分析功能多由后端插件实现。插件提供静态分析和形式化验证等主流的智能合约安全分析接口,分别实现漏洞检测和验证智能合约逻辑是否满足需求的功能。
代码编译和调试功能可由前端或后端插件实现。前端插件的实现原理一般是调用库或内建虚拟机,后端插件的实现原理一般是调用工具或运行虚拟机。
2、智能合约生命周期管理
智能合约生命周期是指智能合约在区块链上从部署到销毁的整个过程。该过程一般包括部署、调用、冻结、解冻、升级、销毁等流程。智能合约生命周期管理就是对智能合约生命周期的流程性控制,必须具有相应权限才能进行操作。BaaS通过RBAC实现对智能合约生命周期管理的权限控制,同时通过联盟治理投票机制,符合联盟成员投票策略的智能合约操作才允许执行。
智能合约生命周期管理的功能由链特性插件实现。因为不同的链支持不同语言的智能合约,提供不同的生命周期管控接口,所以为了兼容差异性,BaaS抽象了链特性插件的通用接口,该接口包括部署、调用、升级和自定义操作。其中,部署、调用、升级是几乎所有主流区块链都支持的功能,而自定义操作是除这三个功能之外的其他功能的扩展接口,如冻结、解冻、销毁等功能可以通过自定义操作进行识别和实现。
3、智能合约数据可视化
智能合约数据是指持久化在区块链中的状态数据,即区块链最新的世界状态。智能合约数据可视化是指收集、处理智能合约数据,通过图形化技术直观地传达智能合约数据的过程。智能合约数据可视化有利于用户便捷地查询智能合约数据,辅助审计人员直观、高效地完成数据验证。
BaaS中收集、处理智能合约数据的方案除利用智能合约相关工具和SDK提供的接口查询数据之外,还可以通过定义SQL语句实现智能合约数据的结构化查询。可视化技术呈现区块链底层智能合约数据,并提供条件筛选、分组筛选、关键词搜索等功能。
4、智能合约安全检测
智能合约一旦部署上链,就难以修改,如果智能合约存在漏洞,也将难以修复,这意味着应该在部署之前对智能合约进行充分的安全分析。
智能合约安全检测通过一系列安全检测手段,检测智能合约漏洞和语法问题,同时提供修复建议的智能研发工具。智能合约是区块链业务安全运行的核心,如果智能合约遭受安全攻击,则会面临不可挽回的业务损失。智能合约安全检测工具可以在极大程度上降低智能合约安全问题对于业务造成的影响,因此,从联盟链治理的安全角度来看,智能合约安全检测具有重要意义。智能合约安全检测通常分为以下两种方式。
- 静态分析。通过整理已知的攻击模式和安全漏洞,形成通用的安全规则,加入规则库,扫描智能合约时若发现不符合规则库中的安全规则,则触发警告。
- 形式化验证。形式规范是一种定义智能合约功能的模型接口语言,以注释形式出现在智能合约中。形式化验证通过模型检测的方法来验证智能合约是否符合形式规范。
跨链互操作技术指的是在已有的区块链平台基础上,延伸出的不同链之间的可信交互技术。在目前各种异构区块链平台之间,不同链之间的交易可信验证机制、数据传播方式、共识算法、加密体系和通信协议都存在很大的差异,多链协同面临全方位的挑战。
跨链问题概述
随着区块链应用的不断发展,不同的区块链底层也呈现百花齐放的局面。受制于业务和技术条件,当前主流区块链应用大多是一个独立的、垂直的封闭体系,不同链之间高度异构、难以互通,从而形成各自的“价值孤岛”,可信数据价值难以得到充分利用。这极大限制了区块链技术和应用生态大规模、多层次的健康发展,跨链需求也由此而来。
跨链互操作通过技术手段连接相对独立的区块链系统,实现不同区块链之间的互操作。跨链交互依据其跨链交互内容不同,大体上可以分为资产交换和信息交换。
- 在资产交换方面,不同区块链上的资产处于互相隔离的状态,它们之间的资产交换主要依靠中心化交易所完成,中心化交易所的交换方式不安全,规则也不透明
- 在信息交换方面,主要涉及链与链之间的数据同步和相应的跨链调用,相应的技术实现难度更高,各区块链之间的信任机制不同,很难进行有效地进行链上信息的可信共享。
区块链因其本身的链式结构和共识算法,确保了链自身信息的真实可信和不可篡改。而跨链是两个区块链系统之间一种信任的传递,需要保证在交换过程中数据的互通、互认。要实现这种跨链交易,还存在一些技术难点有待解决。
- 一是如何保障跨链交易的原子性,即一笔跨链交易要么完全发生(两条链上的账本同步修改),要么不发生(两条链上的账本均不修改),保持两条链上账本的同步性与一致性,否则两个系统的安全性都会受到较大的威胁
- 二是如何实现对交易的确认。因为区块链系统本身是较为封闭的系统,缺乏主动获取外部信息的机制,因此,获取本链上的交易提交状态非常容易,但是获取其他链上的交易提交状态比较复杂,需要依靠“中间人”来实现对交易的确认。当前实现方案包括公证人机制、中继机制、主侧链等多种形式。
在业务与技术的双重需求下,链与链之间的互操作将得到越来越多的重视,跨链已经成为区块链技术的必要需求和必然发展趋势。跨链技术作为连接各区块链的桥梁,其主要目的是实现不同区块链之间的资产原子性交易、信息互通、服务互补等功能,跨链协议必将成为“价值互联网”的基础性支撑技术之一。
跨链原理
不同于单一区块链,在多链互联的场景下,不论是链间通信还是数据可信验证,都增加了跨链互操作的复杂度。
本节就跨链场景下的这些问题,分别从跨链模型、跨链交易验证、跨链事务管理和跨链数据安全四个方面进行阐述。
(1)跨链模型
从跨链技术出现到现在,无论是学术界还是工业界,都提出了许多解决方案,也出现了各种跨链模型。虽然当前区块链行业还没有形成统一的跨链解决方案,但是几种典型的跨链模型已经有了成熟的跨链应用场景落地,它们代表着事实上的行业公认技术,这其中包括哈希时间锁定(Hash Time Lock)、公证人机制(Notary Schema)和侧链/中继(Side chains/Relays)这三大技术,分别适用于不同的跨链场景,是相对成熟的跨链解决方案。
1、哈希时间锁定
2008年,比特币横空出世,任何人都可以在比特币网络上进行自由的转账交易,都有对自己比特币的控制权。加密货币的应用范围不断增加,各种针对其他场景的加密货币纷纷涌现。不同种类加密货币的出现,使得加密货币领域对于加密货币之间的流动性有了更高的要求。加密货币行业急需一种不同加密货币之间能够进行兑换的技术机制。
哈希时间锁定技术应运而生,首次出现在比特币的闪电网络中。哈希时间锁定和普通的一次区块链交易最大的不同是出现了哈希锁(Hash Lock)和时间锁(Time Lock)的概念。这是一种有限定条件的支付模式,在该支付模式下,收款方需要在限定时间内主动进行收款操作,否则就会触发超时,导致转账交易失效,汇款自动退回原账户。
通过一个简单的跨链资产交换的例子进行说明,比特币网络上的Alice需要向以太坊网络上的Bob转账1BTC以换取20ETH,Alice、Bob在双方网络上都有账户。
- 首先,Alice生成一个只有自己知道的秘密数s,并对其进行哈希操作,得到Hash(s)。
- Alice在比特币网络上发起一笔交易,内容是转账1BTC到Bob在比特币网络上的账户,条件是:Bob能够在超时时间T1内,提供一个秘密数s'和Bob自己的签名使Hash(s')=Hash(s)。
- Bob也在以太坊网络上发起一笔交易,内容是转账20 ETH到Alice在以太坊网络上的账户,条件是:Alice能够在超时时间T2内,提供一个秘密数s'和Alice自己的签名使Hash(s')=Hash(s)。
- Alice在以太坊网络上发起交易,提供秘密数s去解锁Bob的20 ETH。此时公开了秘密数s。
- Bob得到了秘密数s,在比特币网络上发起交易,提供秘密数s去解锁Alice的1BTC。
通过上面的步骤,Alice和Bob在没有第三方参与的情况下完成了一次跨链转账,并且无论在以下哪种情况下,都能保证双方都成功或都失败,所以说哈希时间锁定能够保证跨链交易的原子性。
- 如果Alice一直不提供秘密数s,则Alice和Bob的BTC和ETH都会自动转回各自的账户,双方都没有损失。
- 如果Alice提供了秘密数s来解锁Bob的20 ETH,并且Alice发起的交易超时时间T1比Bob发起的交易超时时间T2长,则Alice无法阻止Bob通过已公开的秘密数s来解锁自己的1BTC。
通俗地说,在这个场景中,Alice和Bob相当于”一手交钱一手交货“,
- Alice给Bob交钱,Bob给Alice交货
- 由于Bob是先给Alice交货,所以主动权在Alice手上,故担保锁定时间T1要大于T2,即Alice确认收到了货之后,Bob依然还有额外的时间可以用于接受Alice的钱并发起确认
虽然哈希时间锁定通过密码学的机制保证了跨链交易的原子性,但是在资产跨链场景下还是有一定的局限性。
- 哈希时间锁定要求交易双方所在链使用的哈希算法一致,否则会出现无法解锁资产的情况。
- 无法实现资产转移,只能进行资产交换(资产转移是双方都只在单条链上拥有账户,而资产交换要求双方都必须在两条链上拥有账户)。
- 如果交易失败,则发起方等待交易时间锁触发可能需要很久,造成资产长时间被锁定,发起方可能会有一定的损失。
2、公证人机制
公证人机制是另一种常见的跨链方案,其主要思想和传统金融体系的处理方式类似。为了解决跨链资产交换中交易双方不可信问题,公证人机制通过引入一个与利益无关的公信第三方(这个第三方可以是某个具体的公司,也可以是某个可信组织)来保证交易的可信传递,这个第三方就像传统金融体系中的银行。
公证人机制的思想在生活中随处可见,仲裁机构、支付宝甚至是法院这样的国家机构在某种程度上都是公证人机制的体现。在跨链场景中,该方案相对来说最容易理解,也最容易实现。在行业中采用比较多的、最有名的Ripple的Interledger协议,就是以公证人机制为基础的。
因为比特币一出生打响的口号便是去中心化的电子现金,这使得区块链行业普遍对于中心化的机制是有抵制心理的,所以传统的中心化公证人机制应用到跨链场景下时,出现了更具去中心化色彩的多签名公证人机制和分布式签名公证人机制。
- 中心化公证人机制。中心化公证人机制也被称为单签名公证人技术,和现在的银行基本类似。交易双方需要完全信任一个中心机构,交易发起方直接发起交易,但是双方交易都需要公证人进行确认才能最终有效,交易的原子性也必须由公证人保证,因此,中心化公证人机制面临着过于依赖中心机构、交易失败的安全问题。
- 多签名公证人机制。多签名公证人机制是为了克服中心化公证人机制的问题而提出的。为了解决中心化公证人机制中出现的问题,引入了多个可信的公证人,并规定双方链上发起的跨链交易必须有一定阈值的公证人签名数量才能生效,该机制能够有效减少单个公证人被攻击的风险,但是要求双方链上必须支持交易的多重签名技术。
- 分布式公证人机制。分布式公证人机制在多签名公证人机制的基础上强化了安全性。公证人采用分布式技术,交易需要分布式签名技术、门限签名技术等的支持。技术方案在实现上更加复杂,而且也进一步降低了跨链交易的执行效率。
这三种公证人机制并没有绝对的优劣之分,根据不同的跨链场景,不同的跨链解决方案也是有其优势的,所以还是需要根据具体场景进行选择。
3、侧链/中继链
侧链最早出现在比特币网络中,在2014年由BlockStream团队提出。随着比特币的不断发展,比特币设计上的一些缺陷开始凸显(如每秒7笔交易的吞吐量限制、不支持图灵完备的智能合约等)。而直接在比特币网络上进行重构必将使比特币主链承受巨大的资金风险,因此,诞生了侧链技术。通过侧链技术,可以运行一些实验性的区块链作为比特币侧链,这样既能够连接比特币主链防止侧链资金流动性不足,又能够在侧链出现问题时不影响主链的运行。
侧链采用的是双向锚定(Two-way Peg)机制,与之对应是单向锚定(One-way Peg)机制,单向锚定机制能够确保如果在比特币主链中销毁了一定数量的比特币,那么在一条侧链上就能获得相应数量的其他代币。例如,在主链上,将比特币发送到一个不可使用的地址可以销毁你所持有的比特币。其他链在检测到这笔交易之后,会向侧链的地址转入相应数量的新代币。这样的过程是不可逆的,之后无法再拿回已经销毁的比特币。
侧链的双向锚定机制便是在此基础上进行改进的,该机制在主链上保留了收回已经销毁的比特币的功能。在该机制中,不需要将比特币发送到一个不可用的地址,而将比特币发送到一个特殊地址,这个特殊地址不属于任何人,仅由一段脚本进行控制。如果你能提供在侧链销毁了一定数量的另一种代币的“证明”,那么这段脚本就会将比特币转回相应的账户。
侧链技术具备跨链的雏形,当时考虑的场景非常有限,基本是在比特币的架构体系内进行跨链的资产操作的,没有更多地考虑不同区块链架构(如以太坊)之间的跨链操作,以及非公有链下的跨链场景。中继链技术和侧链技术在跨链模式上基本一致,只是侧链更加依附主链,中继链技术中一般没有主链的概念,更加独立化,而且跨链技术的发展赋予了中继链技术更多的内涵。例如,Cosmos采用的Hub和Polkadot采用的Relay chain都属于中继链的范畴。
(2)跨链交易验证
在区块链中,一笔交易的验证通常是对发送方签名的验证,即交易验证通过且上链,表示交易是有效的。
跨链交易验证是对跨链交易的存在性和有效性进行验证,
- 跨链交易不能凭空产生,需要对跨链交易进行存在性验证
- 但是存在性验证通过不表示交易是有效的,如果验证人(矿工)集体作恶,伪造跨链交易,那么就需要对跨链交易进行有效性验证
存在性验证是对跨链交易真实性来源的一种证明方式。例如,跨链交易确实存在于来源链上,也确实是发送给目的链的,这种验证方式通常使用类SPV证明或背书策略证明来实现。
类SPV证明要求区块链有类似默克尔树的功能,如比特币和以太坊。如下图所示,假设区块中存在16笔交易,一个节点能够通过生成一条仅有4个交易哈希值的默克尔路径来证明区块中存在一笔交易K。
该路径有4个哈希值
- HL
- HIJ
- HMNOP
- HABCDEFGH
由这4个哈希值产生的认证路径,再通过计算另外三个哈希值
- HKL
- HIJKL
- HIJKLMNOP
- 默克尔根(在图中由虚线标注)
任何节点都能证明HK包含在默克尔根中。目的链可以利用区块的默克尔根及默克尔路径快速验证跨链交易存在于来源链上。

背书策略证明要求区块链有背书节点签名功能,如Hyperledger Fabric,其目的链利用背书节点的证书进行验签,如下图所示,Proposal是交易提案,Hash是对交易内容Content的哈希摘要,Endorser中有三个背书节点的证书,对应Signature中三个背书节点签名,如果三个背书节点签名都验证成功,则表示跨链交易存在于来源链上。

存在性验证可以证明跨链交易的真实性,结合有效性验证可以证明跨链交易执行状态的有效性。例如,跨链转移的资产是否处于冻结状态、是否被双花攻击过或来源链验证人(矿工)是否存在其他作恶行为,Polkadot(波卡链)提供了对应的解决方案。简而言之,Polkadot网络存在钓鱼人和验证人等角色,钓鱼人的存在保证了平行链上的验证人出现作恶行为时进行惩罚处理,扣除验证人抵押在Polkadot网络中的Token资产,进而保证整个Polkadot网络的安全性。
由于联盟链内数据的自封闭性,联盟链之间的跨链交易验证成本相对公有链较高,为了保证联盟链跨链交易验证的有效性,需要监管机构的介入,监管机构的主要功能如下。
- 监管机构拥有访问联盟链内数据的权限。
- 联盟链需要信任监管机构,监管机构类似联盟链内的管理员。
- 联盟链如果发生作恶行为,则监管机构要能及时制止跨链交易的执行,并回滚对应的跨链交易。
(3)跨链事务管理
在数据库中,通常将一个或多个数据库操作组成一组,称为事务。在跨链操作中,不同区块链上的子操作构成一个跨链事务。跨链事务和传统分布式系统里的事务相似,只是传统分布式系统的参与方是不同业务系统或不同数据库,而跨链操作的参与方是不同区块链。
下面举个例子说明跨链事务的概念,可以用链间资产交换的例子来说明。例如,Alice想以1:10的兑换率用1个BTC交换Bob的10个ETH,此时,他们之间的资产交换包括以下两个操作。
- 在比特币网络中,Alice向Bob的地址转1个BTC。
- 在以太币网络中,Bob向Alice的地址转10个ETH。
这两笔转账子操作分别发生在不同的区块链系统中,彼此互相独立,同时它们构成了一个完整的跨链事务。
数据库中的事务需要具备原子性、一致性、隔离性和持久性四个特性,跨链事务也需要具备这四个特性。下面以Alice和Bob之间资产交换的例子来说明这四个特性。
- 原子性指的是Alice和Bob在比特币和以太坊网络中的操作要同时成功或失败
- 一致性指的是跨链事务操作之前和之后,Alice和Bob在比特币上的资产总量和在以太坊上的资产总量是不变的
- 隔离性指的是多个跨链事务之间要相互隔离,避免被干扰
- 持久性指的是如果跨链事务完成了,则Alice和Bob在链上的操作就是永久的且不会被回滚
由于区块链是串行系统,交易在区块链上的执行是一个接一个的,所以跨链事务管理机制可以不用考虑隔离性,由业务系统保证即可。
在跨链操作中,持久性可以转化为如何保证跨链子操作的最终确认性问题。区块链中的操作和传统分布式系统的操作不同的是,区块链中有可能出现操作被撤销的情况。例如,前一秒账户A的余额增加10,由于区块链产生分叉,这个操作又不存在了,可能会引起事务的不一致。如下图所示,一开始跨链交易存在于13号区块,但是在14号区块后,一个出到16号区块的链取代了前面的链,那么13号区块的跨链交易就变为无效,也就是本来扣的额度,现在又回来了,或者本来加的额度,现在又没了。

为了避免这种情况发生,需要对区块链上的交易进行一个最终的确认。针对这种情况,一般有两种解决方案。
- 第一种,如果区块链采用的是PoW这种概率确认性的共识算法,那么就需要对其上的交易设置一个确认阈值,也就是在积累了一定数量的区块之后再进行确认。例如,在比特币中,若一个区块后面连接着6个区块,那么这个区块被撤销的概率非常小;
- 第二种,采用类似PBFT的最终确认性共识算法,这种算法保证了只要交易上链,就不会被回滚。
原子性和一致性的设计需要从两个跨链场景进行讨论,一个是资产交换,另一个是复杂业务。
对于资产交换的跨链场景,可以使用哈希时间锁定机制保证事务的原子性。哈希时间锁定机制的原理之前已经详细讨论过,这里不再赘述。
这里主要讨论在异构跨链场景下,如何在区块链上实现超时机制。因为哈希时间锁定机制中锁定的资产有超时时间,使用PoW共识算法的区块链可以使用区块高度作为粗略的时间度量单位,但是对于使用PBFT共识算法的区块链,可能没有一个可以依赖的计时手段,这时候就需要借助Oracle技术,下图是Oracle时间解决方案,Oracle程序每2分钟将时间戳Oracle智能合约里的时间变量加一,时间戳Oracle智能合约就拥有了一个以2分钟为刻度的时间。哈希时间锁定机制在锁定资产时可以以时间戳Oracle智能合约中的时间为参考设定超时时间。

对于复杂业务的跨链场景,可以参考传统分布式事务处理方案,如2PC协议、3PC协议等。但是它们都依赖一个可信的第三方协调者,这种中心化的方案违背了区块链去中心化理念,所以跨链事务中需要借助中继链来充当协调者。
下图为BitXHub(趣链跨链技术平台)跨链事务管理机制,其参考了传统分布式事务的本地消息表处理方案,采用的是最终一致性解决方案。

本地消息表的核心思想是将分布式事务拆分为本地事务进行处理。发送方的写业务数据和写消息数据要保证原子性,如果写业务数据成功了,那么写消息数据一定能成功。写消息数据会被同步到kafka中,最终被消费方消费。如果消费方在业务上面执行失败,则可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。在跨链事务中,可以由中继链取代kafka,区块链A上可以由智能合约保证只要账户A扣了500,就一定会抛出跨链事务,最后同步到中继链,再到区块链B进行相关操作。如果在区块链B中的操作失败了,则将失败的消息由中继链同步后到区块链A进行回滚等操作。
总的来说,设计跨链事务方案时需要先解决跨链交易最终确认性问题,也就是要保证跨链操作的确定性,然后再考虑去中心化的原子性保证问题。在资产交换场景中,可以使用哈希时间锁定机制保证原子性,在复杂业务场景中,可以引入中继链作为协调者协调整个事务的完成。
(4)跨链数据安全
在跨链事务中,不同来源的跨链交易通过共识在所有的区块链节点流转。这对某些交易中的隐私数据来说会有很大的风险。所以对于跨链交易的隐私保护成了一个至关重要的问题,需要通过一些方法和途径防止跨链交易被除参与方外的其他人查看,也要防止跨链交易的具体内容在跨链交易传输过程中被恶意攻击者解析。
对于跨链交易的隐私保护问题,隐私交易是一种可行的解决方案。所谓隐私交易,就是双方在交易过程中的资产交换或数据互通是保密的,无法被第三方查看和解析。在这种隐私交易的方式下,用户不愿公开的敏感数据将会被隐藏,保证了数据的机密性和安全性。
当跨链交易采用中继链的方式时,各个跨链参与方的跨链交易数据全部在中继链上参与共识,对于任意一个跨链参与方,获取其他跨链参与方的跨链交易数据是非常轻松的。而隐私交易通过部分节点可见的方式来保证跨链交易的内容不被不相干的节点查看。
从下图中可以看到,跨链交易只在交易的相关节点中传输,在区块链的共识过程中,各个节点只对交易哈希进行共识。通过这种方式,跨链交易的其他节点能查看到的只有交易哈希,而无法得到任何交易内容的信息,从而保证了隐私交易的安全性。

除此之外,跨链交易在传输过程中对内容的保护也有很大的需求。在中继链方式下,当用户不希望自己的跨链交易内容在中继链传输过程中被查看时,可以采用协商加密。协商加密需要交易双方在进行跨链交易之前,对跨链交易内容加密的密钥进行协商,整个过程要保证高效自动化,同时要保证加密的密钥不容易被破解。在协商密钥完成以后,交易方就可以将跨链交易的内容通过对称加密的方式加密,发送到中继链。由于跨链内容已经被协商密钥加密,所以中继链上的节点可以得到的信息是交易双方的地址、交易哈希及被加密无法解析的交易内容。中继链将交易哈希进行共识记录,并将加密的交易内容发送到目的区块链上。目的区块链可以用之前协商的密钥解密出跨链交易的内容。
下图是密钥协商和加密流程。其具体步骤如下。
- 区块链应用在注册到中继链时,将自己的公钥上传到中继链,用来为协商密钥做准备。
- 当链二想要发送加密交易到链一时,首先,向中继链请求链一的公钥,然后,用链一的公钥和链二自己的私钥计算得到对称加密密钥。
- 链二用步骤(2)得到的对称加密密钥对交易内容进行加密,并通过中继链发送给链一。
- 链一在接收到链二发送的交易内容后,首先检验其是否为加密传输。
- 链一在检验到链二发送的交易内容为加密传输后,向中继链请求链二的公钥,然后用链二的公钥和链一自己的私钥计算得到对称加密密钥。
- 链一用步骤(5)得到的对称加密密钥对链二发送的跨链交易内容进行解密,从而获得真正的跨链交易内容。

除隐私交易和协商密钥之外,日渐成熟的TEE(Trussted Execution Environment)技术也成了跨链交易数据安全保护的手段之一。TEE为可信执行环境,即当原本的操作环境的安全级别无法满足要求时,TEE为一系列敏感性操作提供保障。所以在跨链交易的执行过程中,把大量数据的处理放在TEE中可以保证数据的安全性。为了提高效率,只把必要结果等关键信息上链。通过TEE不仅提高了效率,也将用户担心被暴露的隐私数据放置在了一个TEE下,保证了数据的安全性。
随着跨链应用场景越来越多,用户对跨链交易中数据安全的要求也越来越高,除以上对数据安全加密的方法以外,还可以通过零知识证明和同态加密等方式保障在跨链交易中隐私保护和数据安全问题。
典型跨链协议
早期跨链协议主要关注资产转移,以瑞波和BTC Relay为代表。随着区块链应用的不断落地,实际应用场景的不断丰富,跨链协议也持续不断地发展。现有跨链协议更多地关注基础设施建设,以Polkadot、Cosmos和BitXHub为代表。下面将分别介绍这三种跨链协议。
(1)Polkadot
Polkadot是一个使用中继链技术实现的具有可伸缩安全性和互操作性的异构多链系统,同时是一个协议,其允许独立的区块链之间互相传输信息。Polkadot的建立是为了连接公有链、联盟链、私有链及其他Web3.0技术,使它们能够通过Polkadot的中继链实现信息的交换和无须信任的交易。
1、Polkadot架构与组成
下图是Polkadot整体架构。Polkadot由中继链、平行链和转接桥组成。
- 中继链处于网络中心位置,为整个网络提供统一的共识和安全性保障
- 平行链和中继链相连,是负责具体业务场景的应用链
- 转接桥是一种特殊的平行链,用于连接其他外部独立的区块链,如以太坊等

Polkadot网络中存在多种角色。
- 验证人(Validators):验证人需要抵押足够多的押金。其负责接收平行链提交的候选区块,进行验证并再次发布验证过的区块。
- 收集人(Collators):维护特定平行链的全节点,负责收集和执行平行链的交易并产生候选区块,将候选区块和一个零知识证明提交给一个或多个验证人,并通过收集交易获得手续费。收集人类似PoW共识算法当中的矿工。
- 提名人(Nominators):提名人通过放置风险资本来表示其信任特定的验证人在维护网络的过程中负责任的行为,提名人也会受到和验证人总押金同样比例的奖励和惩罚。
- 钓鱼人(Fishermen):监控验证人的非法行为,若验证人作恶(如批准了无效的平行链提交的候选区块),则钓鱼人可以向其他验证人举报并获得相应奖励。
2、Polkadot跨链流程
Polkadot的跨链协议为XCMP(Cross-chain Message Passing)协议,使用基于默克尔树的队列机制解决跨链消息传递的真实性,保证跨链消息在平行链间高效、有序、公平地传输。每个平行链都维护一个出口和入口消息队列,以进行跨链消息的传输。
假设Alice想要转移平行链A的资产到平行链B,以下是其简要流程。
- Alice调用平行链A上的智能合约,产生跨链消息,该跨链消息的目的链为平行链B。
- 平行链A的收集人把跨链消息及目的链和时间戳信息一起放入平行链A的出口消息(Outgoing)队列。
- 平行链B的收集人会持续地询问其他平行链的收集人是否存在目的链为平行链B的新的跨链消息,如果存在,则把它放入自己的入口消息(Incomming)队列。
- 平行链A和平行链B的验证人同样会读取出口消息队列的消息,以便进行交易的验证。
- 平行链B的收集人将入口消息队列中的跨链消息及收到的其他交易一起打包进下个新区块。
- 当处理新区块时,跨链交易被执行,平行链B的智能合约被调用,将资产转移至Alice账户。
- 至此完成了跨链资产转移。
3、Polkadot关键技术
对交易有效性验证而言,Polkadot包含三个级别的有效性验证。
- 第一级别的有效性验证由平行链的验证人实现,可以防止收集人作恶。平行链上的收集人收集交易、生成区块以后,会生成一个区块有效性证明。然后收集人将区块、区块有效性证明及跨链消息都发送给当前平行链的验证人。平行链的验证人验证该区块,如果该区块无效,则忽略该区块;如果该区块有效,则将收到的内容分成多个部分,构造一棵默克尔树,然后将每份内容、默克尔证明及区块信息组合、签名并分发给其他验证人验证。
- 第二级别的有效性验证由钓鱼人保证,可以防止平行链验证人作恶及平行链验证人和收集人联合作恶。钓鱼人首先需要在中继链上放置押金,然后持续从收集人处收集区块,并验证其有效性。如果区块中包含无效交易,则钓鱼人将提交报告。事实证明,如果钓鱼人的判断是正确的,则钓鱼人将获得丰厚的奖励,但如果判断错误,钓鱼人将失去自己的押金。
- 第三级别的有效性验证是非平行链验证人执行的。非平行链验证人的选举过程是非公开的,且验证人数量由钓鱼人给出的无效报告数量和收集人给出的不可用报告数量确定。如果检测到无效的平行链区块,则为其签名的验证人将受到惩罚,其押金将部分或全部扣除。
从以上三个级别的有效性验证可以看出,Polkadot设计了一种经济激励机制来确保验证人没有经济动力去批准一个无效区块,同时确保钓鱼人有经济动力去监督Polkadot网络,找出作恶行为。Polkadot网络中的安全性依赖经济学,同时,引入一个共享安全模型,平行链通过在中继链上共享状态来共享安全,从而保证整个网络的安全性。因为中继链的区块通常由平行链的有效性验证组成,所以当中继链的区块确定时,平行链的区块也是确定的。要回滚平行链的区块,攻击者必须回滚整个Polkadot网络,这几乎是不可能实现的。
(2)Cosmos
Cosmos最初是由Tendermint团队构建的开源社区项目,其是一个由独立平行链组成的支持跨链交互的异构多链系统,和Polkadot一样,Cosmos也由中继链技术实现。
1、Cosmos架构与组成
Cosmos架构如下图所示,其主要包含以下组件。
- Hub:Cosmos网络运行的第一条区块链称为Hub,它通过区块链间的通信协议(Inter-Blockchain Communication,IBC)连接其他区块链。
- Zone:在Cosmos网络中和Hub相连的众多运行Tendermint共识算法的同构区块链称为Zone,其中,Peg Zone可以作为桥梁连接概率最终性的异构区块链(如以太坊),Zone通过跨链协议和Hub交互。

Cosmos的平行链使用Tendermint共识算法,Tendermint是部分同步运作的拜占庭容错共识算法,其特点在于简易性、高性能及分叉责任制。该算法要求有固定且熟知的一组验证人(类似PoW中的矿工),其中,每个验证人都通过公钥进行身份验证。每个区块的共识轮流进行,每轮都由一个验证人发起区块,其他验证人进行投票表决,超过2/3的选票同意即可达成共识,确定区块。
2、Cosmos跨链流程
Cosmos使用链间通信(IBC)协议进行链间消息传递。IBC协议中有一个称为中继器(Relayer)的角色,它负责监控实现了IBC协议的各个区块链节点,并传递跨链消息。
Cosmos的原生代币称为Atom。假设链A的Alice想转移100 Atom到链B的Bob,具体流程如下。
- 链A的Tendermint共识算法在收到Alice的交易后,首先检查区块的高度、Gas消耗情况和节点投票情况等信息。
- 执行区块中的交易,减少Alice 100 Atom,增加托管账户Escrow 100 Atom,存储Alice和Escrow的账本。
- 构建跨链交易MsgPackage数据包,根据DestinationChannel和DestinationPort定位Outgoing队列,将MsgPackage数据包存入该队列。
- 区块内交易全部执行完成后,Tendermint共识算法进行事件处理和IavlStore持久化等操作。
- IavlStore通过当前所有的Iavl Tree Root构建默克尔树。
- 链A的Tendermint共识算法通过默克尔根生成区块哈希。
- 链A的Tendermint共识算法准备进行下一轮出块。
- Relayer轮询链A的Outgoing队列,发现Outgoing队列中存在MsgPackag数据包。
- Relayer解析MsgPackage数据包的来源和目的;如果发现链B的区块高度大于超时高度,则移除链A的MsgPackage数据包,向链A的Incomming队列发送MsgTimeout数据包。
- Relayer向链B的Incomming队列发送MsgPackage数据包,链B解析MsgPackage数据包,验证MsgPackage数据包的有效性。
- 托管账户Escrow铸币100 Atom,并发送给Bob。
- 链B构建MsgAcknowledgement数据包,Relayer轮询链B的Incomming队列,将其放入链B的Outgoing队列。
- 链A收到链B的MsgAcknowledgement数据包或MsgTimeout数据包后,如果MsgAcknowledgement数据包中包含执行失败的状态或存在MsgTimeout数据包,则根据MsgTimeout数据包内的信息向托管账户赎回对应的金额。
3、Cosmos关键技术
Relayer不属于IBC协议的一部分,但是其却是一个不可多得的重要角色。在IBC协议的构想中,不同的区块链如何获取对方链的信息不是链本身需要考虑的,链本身只需要提供需要发送出去的Message,然后提供一套处理跨链信息的Handler。IBC协议的Handler要求发送的Message满足定义的某些接口,所有Message的验证工作都需要在链上完成。
IBC协议在现阶段的设计中只考虑跨单条链的场景,如何支持跨多条链(Multi-hop)的事务操作可能要等待新的设计。在跨单条链的场景下,IBC协议通过链上互相验证+超时机制来保证跨链事务。
例如,链A发起一笔跨链交易,并且在该交易中指定一个TimeoutHeight和TimeoutTimestamp,需要注意的是,TimeoutHeight和TimeoutTimestamp指对方链上的高度和时间。IBC协议设想的是,如果目的链的MsgTimeout数据包没有传过来,那么来源链是不能随意结束一个跨链交易的。
IBC协议的这种机制建立在参与跨链的各个Zone可信的基础上(Relayer不要求可信,但至少有一个正常工作的Relayer)。对方Zone不存在恶意不发回MsgTimeout数据包导致跨链发起方的资产长期被锁定,或者持续等待的情况。
IBC协议号称是区块链领域的TCP/IP协议,所以在设计上也和TCP/IP协议部分类似。例如,在开始发送跨链交易之前,必须经过类似“TCP三次握手”的过程,在拥有对方链轻客户端的情况下,建立连接(Connection)和通道(Channel)。
一次完整的跨链数据发送需要经历以下流程。
- 进行跨链交互的两条链,分别初始化对方链的一个轻客户端,追踪对方链的区块头等信息。
- 建立连接。
- 一方发起ConnOpenInit请求,Relayer路由该请求并发送ConnOpenTry信息到对方链,进行Connection初始化的必要检查和准备。
- 在对方链处理完ConnOpenTry信息之后,Relayer通过ConnOpenACK信息通知发起链,发起链再返回ConnOpenConfirm信息,这样就完成了一次建立连接的握手流程。
- 建立通道。与建立连接的流程基本一致,ConnOpenInit、ConnOpenTry、ConnOpenACK、ConnOpenConfirm信息分别对应ChanOpenInit、ChanOpenTry、ChanOpenACK、ChanOpenConfirm信息。
- 发送跨链数据。
发送跨链数据必须通过通道进行。如下表所示,IBC协议规定了数据包的结构,Data为自定义的上层数据,为字节数组,编码和解码由应用层指定。

具体的流程图如下图所示。

可以看到,和TCP三次握手相比,IBC协议的握手过程分为两个部分,一个部分是连接的建立,另一个部分是通道的建立,二者的顺序不可调换。按照Cosmos的设计,多个通道是可以复用一个连接的。
从设计上来说,多个通道可以满足不同上层跨链应用、跨链交易互不干扰的需求,每个通道都各自维护自己的交易序号等状态信息。而复用的连接负责更新和验证对方链上新的状态,不必让各个通道分别进行验证,减轻了链上验证的成本。
(3)BitXHub
趣链科技基于链间互操作的需求提出了一种类似TCP/IP协议的通用链间传输协议(Inter-Blockchain Transfer Protocol,IBTP),并基于该协议实现了同时支持同构及异构区块链间交易的跨链技术示范平台(BitXHub)。该平台具有通用跨链传输协议、异构交易验证引擎、多层级路由三大核心功能特性,保证跨链交易的安全性、灵活性与可靠性。
1、BitXHub架构与组成
下图为BitXHub架构图。BitXHub的主要组成部分如下。

- 中继链(Relay-chain):中继链用于应用链管理及跨链交易的可信验证与可靠路由,是一种实现IBTP的开放许可链。
- 跨链网关(Pier):跨链网关担任区块链间收集和传播交易的角色,既可以支持应用链和中继链之间的交互,又可以支持中继链与中继链之间的交互。
- 应用链(App-chain):应用链负责具体的业务逻辑,分为同构应用链(支持IBTP的区块链,如趣链区块链平台)和异构应用链(不支持IBTP的区块链,如Hyperledger Fabric、以太坊等)。
2、BitXHub跨链流程
异构应用链共识算法、加密机制、数据格式等的不同会导致交易合法性证明的不同,为使中继链更方便地进行跨链消息验证和路由,以及跨链网关更一致地进行跨链消息处理,BitXHub设计并实现了IBTP。其数据结构如下表所示。

BitXhub跨链交易的主要流程如下。
- 来源链发起跨链交易,记为ct1。
- ct1由来源链对应的跨链网关捕获,转换成IBTP格式并提交到来源链所关联的中继链A上。
- 中继链A验证ct1是否可信,一是验证交易来源的可信,二是验证交易证明是否满足应用链对应的规则。如果验证不通过则执行步骤(4),否则执行步骤(5)。
- 非法交易回滚,执行步骤(11)。
- 中继链A判断ct1的目的链是否在其管理的应用链列表中,如果在则执行步骤(6),否则执行步骤(7)。
- 目的链对应的跨链网关在接收到ct1之后,解析IBTP并转换成目的链对应的交易格式,将ct1提交到目的链,执行步骤(11)。
- 提交ct1到中继链A相关联的跨链网关1。
- 跨链网关1根据ct1的目的链地址,在跨链网关集群中通过分布式哈希表的方式进行查询,如果目的链所关联的中继链B的跨链网关2存在则执行步骤(9),否则执行步骤(4)。
- 跨链网关1将ct1发送给跨链网关2,跨链网关2将其提交到目的链所关联的中继链B上。
- 中继链B验证ct1是否通过前置中继链(中继链A)的验证背书;如果背书验证可信则执行步骤(6),否则执行步骤(4)。
- 结束交易。
3、BitXHub关键技术
为了跨链交易进行有效性验证,BitXHub的中继链设计并实现了一种高效、可插拔的验证引擎,基于动态注入的验证规则对相应应用链提交的证明进行验证。
在应用链接入之前,首先进行验证规则的编写和注册,并由中继链审核后部署到验证引擎。对于每笔跨链交易,中继链都需要对其进行验证,防止交易被伪造或篡改。验证引擎通过智能合约的方式管理多种验证规则,对不同区块链跨链技术平台的交易进行合法性验证,并支持验证规则的在线升级和改造。
验证引擎的工作流程主要分为以下三个步骤。
- 协议解析。是验证引擎内部对跨链交易的解析。由于所有跨链交易都遵循IBTP,因此该步骤可以解析出交易的来源链信息和验证证明信息,作为后续验证引擎的输入。
- 规则匹配。是验证引擎根据上述步骤解析出的来源链信息去匹配对应的验证规则脚本。
- 规则执行。是验证引擎的核心,主要通过WASM虚拟机动态加载验证规则脚本,然后对跨链交易的Proof字段进行验证,从而确定跨链交易的合法性。
综上所述,中继链的验证引擎具有以下诸多优势。
- 高效:通过WASM虚拟机保证了验证规则执行的高效性。
- 更新:验证规则依据不同区块链规则的变化快速、低成本的热更新。
- 全面:满足各类型区块链的验证体系。
- 便捷:应用链的业务人员可以直接管理验证规则脚本中的验证规则。
- 安全:对WASM虚拟机设置安全限制,只能调用验证引擎自身所允许的函数和库。
在上述三种典型跨链协议中,Polkadot和Cosmos自称为异构多链系统,但是实际上它们的平行链或Zone都是同构区块链,如果要接入异构区块链,必须由专门的同构平行链或PegZone作为桥接器接入。而BitXHub在同构区块链和异构区块链的接入方式上没有差异,都通过跨链网关接入,因此,BitXHub可以被认为是真正的异构跨链协议。
从安全性上讲,Polkadot提供了一种共享安全模型,其各条平行链共享中继链提供的安全性保证,可以保证整个网络的安全性;在Cosmos中,Zone的安全性只能由自己保证,Cosmos不提供整体的安全性保证;BitXHub主要面向联盟链场景,对安全性方面的要求没有公有链那么高,BitXHub做了很多工作来验证跨链交易的有效性。例如,中继链的验证引擎可以防止恶意的跨链交易等。
以太坊
以太坊是由Vitalik Buterin与一些加密货币爱好者在2013年11月提出的一个具有智能合约的区块链项目。
与其他公有链区块链项目类似,以太坊有名为以太币(Ether)的数字货币,运行在整个以太坊网络中,以太币被用于以太坊的经济激励模型及整个网络正常运行的Gas消耗。每个用户在以太坊网络中都是一个独立的个体,都可以自由、平等地使用以太坊网络,不受任何中心化组织或个人的控制。
除了内置加密货币,以太坊的另一个核心亮点是支持智能合约,这使得开发者能够基于以太坊智能合约创建更多的分布式应用项目,这些项目也被称为DApp(Decentralized Application)。DApp被部署在以太坊区块链上,DApp使用者可以运行开发者编写好的智能合约,在上面转移构建的资产或存储数据信息。
(1)项目概述
以太坊是一个基于区块链的开源、公共的分布式账本项目,支持图灵完备的智能合约执行引擎。它与比特币类似,都是分布式的公共区块链网络设施,但是二者在功能上存在巨大差异。比特币提出了一种点对点的现金系统,而以太坊虽然有以太币作为自己的价值交换媒介,但是其真正价值在于提出了一种可以运行可编程代码的区块链平台,使开发者能够利用在不可信环境中执行业务逻辑来构建区块链应用程序,同时利用以太坊网络的高可用性,开发者可以在上面运行更高效的App。
基于以太坊的DApp,可以完成很多传统应用不能够完成的事情。
- 构建一个不可审查的匿名应用。
- 建立一个分散自制的财产管理系统(DAO)或虚拟世界。
- 实现一个新的资产。
以太坊上的DApp是由以太坊智能合约支持的应用程序。这些应用程序不使用集中式服务器或数据库,而依靠区块链作为程序逻辑和存储的后端。这使得任何可以运行前端的用户都可以很轻松地连接到后端以太坊网络,使用DApp提供的功能。
以太坊是由很多核心技术组合构建的,并不是一个单一的个体,其涵盖了密码学、P2P、存储技术等。下图为以太坊整体架构图。

1、应用层
以太坊应用层主要包含各种Wallet(钱包)及DApp。
钱包的主要功能是管理用户账户私钥,并发送各种类型的交易到以太坊网络。
DApp通常由前端和后端组成,前端可以由简单的html+ js + css组合开发完成,也可以利用各种前端开发框架,如react、vue.js、angulars等。DApp的后端类似传统Web应用后端,负责给前端提供业务数据供其进行展示,只不过DApp是将传统的中心化数据库替换成以太坊网络。这使得任何开发者都可以在以太坊网络中开发DApp,任何用户也都可以访问以太坊网络上的DApp。
2、接口层
以太坊为了更好地提供服务给各种应用,提供了各种各样的API,包括查询账户余额、部署智能合约、调用智能合约等。通过这些API,上层应用可以发送交易到以太坊网络,查询和修改以太坊网络的区块链数据。但是在通常情况下,开发者不会直接访问这些API,而是借助以太坊网络提供的各种类似SDK的交互工具发送交易。使用如web3.js、web3j、ether.js等快速地在应用代码中组织交易,而不用从0开始构建代码来完成一个RPC请求。使用SDK大大简化了开发者的代码工作量,使得与以太坊网络交互变得简单方便。
3、核心技术层
核心技术层涉及的技术大部分都在前面章节进行了详细展示。
4、基础层
基础层类似建筑的基础设施,提供以太坊网络运转的基础。包括存储模块使用的Leveldb存储;加密、签名、验签所使用的crypto;各节点之间的点对点消息传递所用的P2P协议。这些基础设施都不是以太坊独创的,而是通过修改已有的代码或算法融合进以太坊的。
以太坊使用这些基础设施,并针对自身的使用情况进行优化,形成以太坊区块链中不可或缺的一部分。
(2)项目实战
本节基于以太坊进行项目实战,以一个企业利用应收账款融资的场景,设计一个实际的应用项目。
1、项目背景简介
应收账款主要用于将企业应收账款转化为标准化资产凭证,在系统中实现应收账款的灵活流转、拆分和融资,实现核心企业信用的多级传导。其主要解决了中小微企业融资难的问题,有助于核心企业的供应链体系和社会信用体系更加完善。
如下图所示,在应收账款融资场景中,通常由核心企业、金融机构、供应商、物流公司多方角色进行业务协作。
- 企业利用应收账款融资是指某些供应商将自己的应收账款转让给金融机构,并从金融机构中获得贷款。
- 上级供应商(一级供应商)可以将自己持有的应收账款转给下级供应商(二级供应商),由二级供应商去向金融机构申请贴现。
- 金融机构一般在经过审核应收账款票据后,给供应商应收账款面值的50%~90%的贷款额。
- 供应商获得贷款额后向核心企业发出转让通知,并要求其付款至融资的金融机构,这样就通过应收账款流转完成了一整套的业务协作流程。

如上图所示,假设核心企业(具有较大社会影响力,有足够的银行信用背书)需要从供应商处采购一批生产设备,但是因为采购数量较多,企业现金流不足以支撑采购设备的付款额度,此时便可以通过以下步骤来完成应收账款融资流程。
- 核心企业联系供应商发起一笔应收账款的设备订单。
- 供应商在收到订单后进行确认,随后对应收账款票据进行签发并发送给核心企业。
- 核心企业在收到应收账款票据后对该票据进行承兑,因为签发的应收账款需要收款人承兑后才生效,因此未承兑的应收账款不允许进行贴现、兑付等操作。
- 当核心企业完成承兑后,通知供应商发货,供应商联系物流公司发货。
- 供应商发货后可以选择向金融机构申请贴现,以便提前获取融资。
- 金融机构审批应收账款票据,如果审批通过,则贴现给供应商,此时应收账款票据持有人变为金融机构。
- 供应商也可以将自己的应收账款票据转给二级供应商,持有人将变成二级供应商。
- 核心企业在签收货物后,可以选择主动向金融机构兑付应收账款,或者等待应收账款到期后,自动执行兑付操作。核心企业划拨资金至金融机构账户,应收账款状态变更为已结清(最终状态),并且持有人变为核心企业。
在该流程中,读者可着重关注应收账款在各个机构中的流转状态,以及区块链技术在整个流程中的作用和价值:自动化的业务协同及去中心化的价值流转。
2、应用架构设计
现有某银行、某核心企业、某供应商、某二级供应商四家企业决定依托以太坊区块链技术,对传统的应收账款票据流转流程进行改造,实现一套新的基于以太坊区块链的应收账款系统。
下图为基于以太坊区块链的应收账款系统整体架构图。本系统主要分为4个模块:
- App
- 核心企业
- 供应商
- 银行前置系统
- web3接口层
- 以太坊网络

- App:用户可以通过App对应收账款票据进行查询、下单、出票、发货、转让、贴现、兑付等操作。
- 核心企业、供应商、银行前置系统:前置系统是对接App的业务系统层,通过接收App的请求进行支付管理和票据业务的处理。将处理后的请求通过web3接口层转发到以太坊网络。
- web3接口层:负责提供后台业务层与底层区块链交互的接口,接口采用RPC请求的方式。
- 以太坊网络:底层基于以太坊节点搭建,多个以太坊节点组成了一个以太坊网络,负责应收账款票据智能合约的数据存储和读取。
3、智能合约设计
本节将根据应收账款的需求场景进行智能合约设计。以太坊上智能合约开发的主流语言为Solidity,本节将采用Solidity完成智能合约的设计。
根据上文需求与功能的分析,可以设计出如下图所示的智能合约类图。

AccountContract负责存储和维护应收账款融资场景中用户的相关信息。用户通过调用账户智能合约的注册信息接口,将信息注册到区块链上。
//账户信息智能合约 contract A ccountContract { struct AccountInfo { address owner; //用户地址 string userName; //用户名 string enterpriseName; //企业名称 RoleCode role; //角色 AccountStatus status; //账户状态 string certNo; //证件号码 string acctSvcrName; //开户行名称 } }
RecOrderContract负责应收账款订单信息的记录,用户可以通过调用应收账款订单创建接口,完成对应收账款订单的创建。
contract RecOrderContract is AccountContract { struct RecOrder { address owner; //订单创建者账户地址 string orderNo; //订单编号 string goodsNo; //货物编号 string receivableNo; //应收账款票据编号 } }
ReceivableContract负责应收账款票据信息的记录。其继承了RecOrderContract和AccountContract的所有方法,是整个应收账款票据智能合约的入口。用户通过该智能合约可以完成账户注册、订单创建及应收账款票据的签发流转等一系列操作。
contract ReceivableContract is RecOrderContract{ struct Receivable { string receivableNo; //应收账款编号 string orderNo; //订单编号 address owner; //应收账款持有者 address acceptor; //承兑人账号 uint256 discountApplyAmount; //贴现申请金额 ReceivableStatus status; //应收账款状态 } }
定义应收账款票据智能合约被上层应用调用的方法接口,如下表所示。

通过以上定义的智能合约,能够较好地实现整个应收账款融资场景的应用需求。
下面以一个以太坊example为例,学习基于以太坊sdk开发dAPP的流程。




可以看到,example.sol的代码被编译为智能合约字节码,并部署到了以太坊中,基于以太坊区块链网络,智能合约中的代码得以执行,完成业务逻辑(投票)。
上层的业务逻辑是开发者可控的,而dAPP的执行过程是基于分布式以太坊网络的,从而该dAPP具备了分布式共识的特性。
Hyperledger Fabric
(1)项目概述
Hyperledger(超级账本)Fabric是由Linux基金会主导的、开源的企业级区块链项目,吸引了全球多个行业的“领头羊”。Hyperledger Fabric是一种安全的、模块可插拔的、可拓展的通用区块链技术。2016年,IBM提供了经过IBM测试与认证的Hyperledger区块链代码,持续在开源项目仓库中贡献代码。Hyperledger Fabric支持在多个平台上安装部署,开发者可以基于Hyperledger Fabric快速构建区块链应用。
下图为Hyperledger Fabric系统架构图,可以从上层应用开发和底层实现原理两个角度进行分析。

- 从上层应用开发的角度来看,Hyperledger Fabric提供相应的API,并封装多种语言的SDK,例如Node.js、Java、Python、Rest、Go等语言。Hyperledger Fabric主要包含身份管理、账本管理、交易管理和智能合约四个功能。
- 身份管理。Hyperledger Fabric提供一种成员身份管理服务,为区块链网络中的节点、客户端、管理员等参与方提供证书。证书中包含参与方的身份信息,Hyperledger Fabric通过身份信息可以确定参与方在系统中的权限。此外,区块链网络中参与方的操作都需要通过与证书关联的密钥进行签名与验证。
- 账本管理。Hyperledger Fabric的账本由区块链和世界状态组成。用户可以对账本数据的存储进行配置,如世界状态的数据库配置、区块数据的存储配置、区块和交易索引的存储配置等。除此以外,Hyperledger Fabric还提供多种区块索引方式,用户可以通过区块编号、区块哈希、交易编号等索引信息获取想要的区块和交易信息。
- 交易管理。账本数据的更新需要通过执行交易实现,SDK提供交易的构造、提案等一系列调用方法。上层应用通过SDK发送交易,SDK将交易提交到背书节点,得到所需的背书,经过排序节点排序后,最终提交到账本上。SDK还提供对交易提交的监测方法,方便应用程序确定交易的状态。
- 智能合约。智能合约定义了更新账本数据的可执行逻辑。现实生活中的业务在交互之前,需要先定义好概念、规则、流程等内容,即业务模型。开发者可以通过JavaScript、Go、Java等编程语言将业务模型表示成智能合约,提高业务流程的处理效率。
- 从底层实现原理的角度来看,Hyperledger Fabric主要提供以下四类服务。
- 成员管理服务。MSP(Membership Service Provider)是Hyperledger Fabric中可以信任的、管理组织成员身份的组件。在Hyperledger Fabric中通过证书表示参与方的身份,采用PKI(PublicKey Infrastructure)模型,在区块链网络中,参与方的通信都需要通过签名与验签。MSP将通过身份验证的参与方添加到区块链网络中。Hyperledger Fabric提供的HyperledgerFabric CA组件能够管理拥有证书的Hyperledger Fabric参与方的数字身份,提供成员注册、证书的新增与删除等功能。
- 共识服务。在区块链系统中,节点通过共识算法各自维护一个账本的副本。Hyperledger Fabric提供一种可插拔的共识服务模块,将执行交易和维护账本的节点进行解耦,分为背书节点(Endorser)、记账节点(Committer)和排序节点(Orderer)。这三类节点在HyperledgerFabric交易流程中的主要作用如下。
- 客户端发送交易提案请求到背书节点。
- 背书节点对交易进行模拟验证,通过验证后进行背书签名,将提案响应返回给客户端。
- 客户端根据背书策略收集到足够多的背书签名后,构造交易请求提交到排序节点。
- 排序节点对交易进行排序,产生区块,并广播给记账节点。
- 记账节点在验证通过区块的有效性后,提交到区块链账本。
-
- 链码服务。智能合约定义了业务的交易逻辑,一个或多个智能合约被打包进链码,部署到区块链网络。在Hyperledger Fabric中,链码运行在与节点进程隔离的Docker容器中,即使链码出现问题也不会影响节点的运行。Hyperledger Fabric的链码支持多种语言编写,包括Go、node.js和Java等。
- 安全和密码服务
- 。Hyperledger Fabric提供可插拔的密码服务,由BCCSP(BlockChain CryptographicService Provider)模块提供密钥生成、签名验签、哈希计算等功能。目前,HyperledgerFabric支持SW、PKCS11算法,随着国密算法的发展,越来越多的社区和生产厂商对Hyperledger Fabric进行国密改造。
Libra
(1)项目概述
1、项目背景与目标
自20世纪以来,互联网的诞生使得全球数十亿人可以互相连通,在任意角落都可以访问全世界的信息。强大的互联网因其便利性、透明性推动了金融业的发展,尽管如此,全球仍有17亿成年人未接触到金融系统,这些人受制于传统金融系统的高手续费、可信度差及跨系统转账复杂等客观因素,无法享受传统金融系统提供的金融服务而被金融系统拒之门外。
Libra是由Facebook公司在近几年推出的区块链加密货币项目。Libra结合了区块链技术的优点,如安全性高、去中心化治理、开放性访问与强大的组织监管框架,旨在打造一个低成本、强连通性、强可达性的全球支付系统和金融基础设施。
Libra项目主要由三部分组成。
- 安全的、可扩展的和可靠的区块链。
- Libra储备金由现金和短期政府证券组成,是一种价值稳定的资产储备,并支持Libra币。
- 独立的Libra协会管理。
Libra的底层区块链技术网络具有许多特点,包括去中心化治理、网络不由单一中心控制;允许任何人通过互联网相互连接;加密机制完善、资金安全性高。为了实现构建全球金融基础设施的目标,Libra正在积极进行底层区块链的开发,并优先考虑其可扩展性、安全性,以及在存储容量和交易吞吐量上的效率。
现如今大多数加密货币的价值都由市场决定,并不稳定,而Libra币是由真实资产储备提供支持的。储备金具体包括现金和短期政府证券,用来维持Libra币的储备价值和人们对Libra币的信任。
Libra采用协会的组织形式来支持系统的运行,协会是非营利性且独立的,协会成员包括不同领域的公司,如信用卡公司Visa和Mastercard,互联网应用公司Uber和Lyft,以及其他投资公司和学术机构等。显然,协会的设计保证了决策的公平性,不同领域公司的加入有利于Libra的推广。
2、项目架构
与其他区块链项目相似,Libra区块链系统同样由许多独立的模块组成。下图是Libra底层区块链架构图,下面将进一步介绍各个功能模块。

- 客户端可以向准入控制模块发送两种请求:提交交易和查询存储,其中,钱包包含了用户的私钥和资金信息。
- 准入控制模块的主要目的是响应来自客户端的GRPC请求,如果收到了提交交易请求,则先检查交易签名,并转发到验证器进行虚拟机验证,验证通过后,将交易转发到内存池进行下一步处理;如果收到了查询存储请求,则不进行额外的处理,直接将该请求转发到存储模块。
- 在共识提交之前,交易会在内存池中保留一段时间,并且内存池中的交易与验证器的交易是共享的。内存池的主要作用是构建交易,并基于手续费对交易进行排序,保证共识的正确性。
- 网络模块专门作用于共享内存池与共识协议,其主要的作用有:转发客户端的GRPC请求;发现并维护连接的其他节点的信息;定时探测其他节点的连接,确保运行情况等。
- 执行模块接收排序后的交易,通过Move语言虚拟机计算每笔交易的输出,并把输出结果传到存储模块,通过把交易输出添加到上一个状态来形成新的状态。
- 存储模块持久化底层区块链的所有数据,并为查询存储请求提供默克尔证明,这主要得益于存储模块中数据的组织形式是默克尔累加器(Merkle Accumulator)和稀疏默克尔树(Sparse Merkle Tree)。
趣链区块链平台
(1)项目概述
1、项目简介
随着科技的升级和产业的变革,区块链技术得以持续而猛烈地发展,应用推广力度也越来越大,在社会各界都得到了广泛的关注,尤其是金融界和IT界。
基于此背景,趣链科技研发出了国产自主可控联盟链基础技术平台——趣链区块链平台,以联盟链的形式针对企业、政府机构和产业联盟的区块链技术需求,提供企业级的区块链网络解决方案。
趣链区块链平台是第一批通过工信部与信通院区块链标准测试的底层平台,具有验证节点授权机制、多级加密机制、共识算法、图灵完备的高性能智能合约执行引擎、数据管理等核心特性,支持企业基于现有云平台快速部署、扩展和配置管理区块链网络,对区块链网络的运行状态进行实时可视化监控。
2、项目特性
趣链区块链平台架构图如下图所示,其具有高性能、高可用、高安全、隐私性、可拓展、易运维等特性。

- 在接口层,
- 平台配套提供了多种语言的SDK供开发者选择,包括JavaSDK、GoSDK、JsSDK、luaSDK、CSDK软件开发工具等,未来还会提供更多语言的SDK。多种语言的SDK对开发者更为友好,可以选择自己熟悉或喜欢的语言,降低了学习成本与开发难度。
- SDK与平台之间采用JSON-RPC协议进行通信,接口定义规范明了。
- 在技术拓展层,
- 在隐私保护方面,平台采取分区共识的方式,通过命名空间实现对业务和数据在物理级别上的隔离,通过隐私交易,切分交易粒度进行隐私保护
- 在CA身份认证方面,平台同时集成了自建CA与CFCA,使CA体系更为灵活,保证机构的安全
- 在安全方面,平台采用多级加密机制,使用SHA-3或SM3哈希算法生成数据指纹,使用椭圆曲线ECDSA和SM2非对称加密算法生成数字签名来保证节点间的通信安全,使用ECDH、3DES、SM4加密算法实现密钥协商技术对传输层进行数据加密,使用基于SGX的节点密钥管理和数据加密存储实现TEE(Trusted Execution Environment),用户的账户信息和业务数据可按需加密,在保证安全性的同时做到可查验、可审计。另外,还提供了交易去重机制来防止重放攻击和双花攻击,该机制根据交易哈希对交易进行去重处理,节点进行交易验证时检查交易是否存在过,如果存在过则判定为重复交易,节点将拒绝对这笔交易进行处理
- 在数据管理方面,平台支持数据索引,可进行复杂查询并迅速生成数据报表
- 在消息订阅方面,平台拥有独立的消息推送体系,可以推送区块、智能合约事件、平台异常状态等消息,外界可以通过订阅实时了解平台的运行情况
- 在可信数据源方面,平台实现可信的实体Oracle预言机,通过从外部引入世界状态的信息,如URL数据、搜索引擎及跨链数据等,解决区块链中智能合约只能被动处理内部触发的条件,不能调用链外的信息,与外界数据隔离的问题
- 在区块链治理方面,联盟链的准入机制虽然能在一定程度上保障其安全性,但为了支撑更复杂的商业应用场景需求,平台提出了分级的权限管理机制,进一步保障了商业隐私和安全,并使用CAF(Consortium Automonous Framework,自治联盟组织)成立了一个自治组织,每位组织成员都可以提出提案、审议提案,最终以去中心化的形式决定某项提案通过与否,可支持提案包括成员管理、系统升级、智能合约升级等,高效地实现了提案的分发及投票的聚合,为共识服务的可用性打下了坚实的基础
- 在网络管理方面,平台实现了节点网络自发现机制,某一节点只需要配置其相邻节点的网络信息,便可以通过自发现机制找到其他相应的节点
- 在运维管理方面,平台提供了热备切换机制,通过关联NVP节点与VP节点,在VP节点出现故障时,关联的NVP节点可自动升级为VP节点,达到无缝衔接切换的效果。同时支持动态增删节点,可以在不停止其他节点的情况下方便地控制联盟成员的准入和准出。
- 在协议层,在硬件适配层,主要对物理机云平台等基础资源、硬件加密机、密码卡等设备进行硬件层面的适配,使平台可在云服务、软硬件结合、物联网等多种场景下安全、稳定运行。在物理层的硬件层面,可通过加密机、密码卡等硬件设备来保证密钥的安全性。另外,平台对区块链组件进行了模块化,可以部署在多种终端之上,支持容器化部署,兼容支持suse11/12、CentOS、Ubuntu等UNIX操作系统,以及一些物联网硬件设备,配套搭建扫描设备、通信模组、摄像设备等,底层支持多种关系型或非关系型数据库,能在不同操作系统、中间件、数据库之间进行系统移植。
- 平台支持多种共识算法,实现自适应共识,同时支持RBFT、RAFT、NoxBFT等多种共识算法,可以在不同的应用场景下使用最为合适的共识算法。其中,RBFT为高性能鲁棒共识算法,在系统延时300ms以内的情况下,TPS可达到1w左右,同时提供动态数据失效恢复机制,通过主动索取区块和正在共识的区块信息使自身节点的存储尽快和系统中的最新存储状态一致,达到快速恢复的效果
- 在网络方面,平台采用GRPC作为节点间的通信协议,使用protobuf二进制消息,支持子协议定义及跨域多层级路由转发,支持IPv4、IPv6协议及IPv4和IPv6协议混用,同时支持同构跨链和异构跨链两种跨链模式。另外,通过流控机制对超过系统设置上限的流量拒绝接收,降低了由于压力过大导致节点异常的可能。经测试,即使在复杂网络如节点数目众多、网络抖动频繁、节点连接多样等情形下,平台依然能够保持稳定的性能,不妨碍其原有功能
- 在数据存储方面,平台采用对象存储、关系型存储、非关系型存储结合的混合型存储,支持多类型、多组织形式的数据可信存储,实现高性能、高可扩展链上存储,每天可上链1T数据。在防止存储文件被篡改的问题上,基于默克尔DAG组织形式的结构化和非结构化数据存储可达到不可篡改的效果,当链上数据过多时,还可以进行数据定期归档,将一部分链上数据归档,存储到链下,解决了数据无限膨胀可能带来的问题
- 在智能合约执行引擎方面,平台支持多种虚拟机,包括EVM、HVM,可以使用Java作为智能合约语言,同时支持兼容Solidity。对于基于Java的HVM执行引擎采用原生高性能智能合约引擎沙箱,保证智能合约的执行速度,并对智能合约全生命周期进行管理,可实现智能合约无缝升级。
区块链测评概述
在区块链高速发展且具有可塑性的阶段,引入区块链技术的技术规范和标准化,有助于统一对区块链的认识,规范和指导高质量的区块链系统在各行各业的发展,促进区块链的共性技术攻关,对于区块链产业生态发展意义重大。
(1)区块链信息系统质量模型
本节参考了常见的ISO 9126软件质量模型(1993年)和ISC/IEC 25010质量模型,结合了区块链行业标准及测评的实践,得出了区块链信息系统质量模型。该模型大体上分为功能性、性能、安全性、可靠性、可维护性、可移植性、互操作性和可扩展性八个部分,如下图所示。

- 功能性:区块链系统功能质量模型主要从功能的角度考察系统的准确性、完备性和适合性,可以从基础设施层、平台协议层、技术拓展层和接口层四个层级展开,如下图所示。
- 性能:通过公允的基准测试工具模拟多种正常、峰值和异常负载条件,查看区块链系统的容量、时间特性、资源利用率和稳定性。
- 安全性:指区块链系统对信息和数据的保密性、完整性、真实性和防抵赖。
- 可靠性:在规定场景下,考察区块链系统的可用性、容错性、健壮性和易恢复性。
- 可维护性:考察区块链系统是否模块化,发生错误时是否可被诊断及诊断的难易程度,对区块链系统实施修改的难易程度,测试的难易程度,是否可升级。
- 可移植性:考察不同软硬件环境下区块链系统跨平台的适应性,是否易安装,组件是否可替换及替换的难易程度。
- 互操作性:考察区块链系统节点间的数据一致性,以及与其他区块链系统间的可协同性和易替换性。
- 可扩展性:存储模块是否可扩展,执行模块是否可扩展。

(2)区块链评价体系
根据上一节提到的区块链信息系统质量模型分为功能性、性能、安全性、可靠性、可维护性、可移植性、互操作性和可扩展性八个部分,区块链评价体系将这八个部分统一整理成功能、性能、安全和拓展性四大方面进行阐述。
1、功能评价
区块链评价体系的功能评价参考区块链系统功能质量模型,从基础设施层、平台协议层、技术拓展层和接口层四个层级展开说明。
- 基础设施层评价要素主要包括:
- 混合型存储:区块链系统运行过程中产生的各种类型的数据,如区块数据、账本数据和索引数据等,不同类型数据的数据库选型不同,分为关系型和非关系型数据库
- 点对点网络:考察区块链系统采用的网络通信协议是否支持上层功能
- 硬件加密:硬件加密提供硬件TEE,保证区块链系统的底层数据加密存储,并做到密钥存储管理。
- 平台协议层评价要素主要包括:
- 分布式账本:区块链系统内的节点共同参与记账,去中心化共同维护区块链系统账本,并且保证账本安全可追溯
- 组网通信:主要考察区块链节点之间的组网方式、是否支持消息转发、是否支持节点动态加入和退出
- 共识算法:用于保证分布式系统一致性的机制,这里主要考察共识算法的多样性、共识节点数量、交易顺序一致性、账本一致性和节点状态一致性
- 智能合约执行引擎:智能合约是区块链应用业务逻辑的载体,而智能合约执行引擎保证了这些应用的落地。这里主要考察智能合约执行引擎是否拥有完备的业务功能、可确定性、可终止性、完备的升级方案等
- 密码学:区块链系统支持的密码算法类型,以及是否支持密钥管理,如密钥生成、密钥存储、密钥更新、密钥使用、密钥销毁
- 区块链治理:区块链治理模式,以提案的形式管理区块链系统行为,如系统升级、节点管理、智能合约升级等
- 账户管理:考察是否支持针对区块链账户的一些常规的管理操作,如账户注册、账户变更、账户注销、角色权限、账户查询等
- 跨链技术:考察区块链系统是否支持跨链交互
- 技术拓展层评价要素主要包括:
- 可信数据源:从外部引入世界状态的信息,如URL数据、搜索引擎及跨链数据等,考察区块链系统是否支持将区块链外的数据源接入区块链,执行更复杂的业务逻辑,支持更丰富的业务场景
- 数据索引:用来存储区块链系统中关键的索引信息,提高数据查询效率,考察区块链系统是否在链下提供可选择的索引数据库
- 隐私保护:保证区块链数据的隐私性,考察区块链系统是否提供隐私保护机制
- 区块链审计:考察区块链系统是否提供审计功能,数据访问是否可审计,账本数据变更是否可审计,节点一致性校验失败是否可审计
- 接口层评价要素主要包括:
- 外部接口:一般是指对链外系统开放的接口,如预言机、跨链
- 用户接口:考察是否提供针对账户体系的查询服务,如账户体系的基本信息查询、业务提供的服务查询、事务操作查询
- 管理接口:提供节点的管理入口,如节点信息查询、节点状态查询、节点服务的开关、节点配置管理及节点监控
2、性能评价
区块链系统的性能评价要素主要从系统容量、时间特性、资源利用率和稳定性四个方面展开。
- 系统容量主要指交易吞吐量满足度,考察在要求的负载下,单位时间内可处理的最大请求数量是否满足需求。
- 时间特性主要指响应时间满足度,单条命令的响应时间是否满足需求。
- 资源利用率主要包括系统对硬件资源如CPU、内存、带宽等的占用是否符合需求限度。
- 稳定性主要指被测系统在特定软件、硬件、网络条件下,给系统一定的业务压力,使系统运行一段时间,检查系统资源消耗情况,以此检测系统是否稳定。一般稳定性测试时间为n×12个小时。
3、安全评价
在对各领域的积极探索过程中,区块链技术所应用的数据存储、网络传输共识算法、智能合约等存在的安全问题逐渐暴露。如今,区块链技术正处于快速上升期,其存在的安全问题除了外部组织的恶意攻击,也可能由内部机构引起。截止到2018年4月,在全世界区块链领域出现的安全问题导致了近30亿美元的经济损失。区块链系统的安全评价要素可以从数据存储、网络传输、共识算法、智能合约和权限控制五个层面展开,如图12-3所示。

4、拓展性评价
拓展性评价包含可靠性、可维护性、可移植性、互操作性和可扩展性五个部分,可参考区块链信息系统质量模型,这里就不再展开讲述了。
功能性测评
功能性测评主要考察区块链系统各项功能是否满足准确性、完备性和适合性三大关键因素,本节主要针对区块链系统提供的功能展开相关测评项的描述。
区块链系统的基础功能性测评从基础设施层、平台协议层、技术拓展层和接口层展开描述。
- 基础设施层
- 混合型存储测评要素包括:
- 区块链存储方式多样化:区块链系统中不同类型的数据结构采用不同的存储方式
- 节点高效稳定存储:能够提供高效、稳定、安全的数据服务。
- 点对点网络测评要素包括:
- 节点之间通信:能够进行点对点通信,并且保证通信安全
- 通信协议多样化:支持的通信协议类型是否多样化,支持根据业务场景选择最优通信协议
- 增删通信节点:支持动态增加节点,动态删除节点。
- 硬件加密测评要素包括:
- 密钥存储:能够将关键密钥信息托管到TEE中不再导出,以便保护关键密钥
- 数据加密:在密钥存储的基础上,提供特定节点的密钥加解密功能。
- 混合型存储测评要素包括:
- 平台协议层
- 分布式账本测评要素包括:
- 多节点拥有完整的区块和账本数据,且数据一致
- 支持账本数据同步,同步后数据状态一致
- 账本的操作记录可查询、可追溯。
- 组网通信测评要素包括:
- 节点间是否支持消息转发
- 是否支持节点动态加入,以及最多加入集群的节点个数
- 是否支持节点动态退出。
- 共识算法测评要素包括:
- 系统支持多节点参与共识与确认
- 可容忍拜占庭节点,在拜占庭节点的容错范围内,系统可正常运行。
- 智能合约执行引擎测评要素包括:
- 是否提供多种语言支持及配套的智能合约编译执行环境,如虚拟机
- 是否支持智能合约编译、智能合约部署、智能合约升级和智能合约版本管理。
- 密码学测评要素包括:
- 支持多种加密类型,可按照具体的业务场景选择加密方式
- 支持国密算法,如SM2、SM3和SM4等
- 密钥管理功能:密钥生成、密钥存储、密钥更新、密钥使用、密钥销毁。
- 区块链治理测评要素包括:
- 成员管理
- 系统升级
- 智能合约升级。
- 账户管理测评要素包括:
- 账户注册、账户变更、账户注销、账户查询
- 是否提供账户角色权限控制管理。
- 跨链技术测评要素包括:
- 区块链系统是否支持跨链交互。
- 分布式账本测评要素包括:
- 技术拓展层
- 可信数据源测评要素包括:
- 区块链系统是否提供可信数据源的功能
- 验证可信数据源的真实性。
- 数据索引测评要素包括:
- 考察区块链系统是否在链下提供可选择的索引数据库
- 数据查询效率是否有所提升。
- 隐私保护测评要素包括:
- 考察区块链系统是否提供分区共识的功能,分区共识的分区之间互不干扰
- 支持交易粒度的隐私保护,隐私交易数据只存储在交易的相关方。
- 区块链审计测评要素包括:
- 考察区块链系统是否提供审计功能
- 数据访问是否可审计
- 账本数据变更是否可审计
- 节点一致性校验失败是否可审计。
- 可信数据源测评要素包括:
- 接口层
- 外部接口测评要素包括:
- 区块链系统是否提供预言机操作接口,是否提供可信数据源查询的可编程接口。
- 用户接口测评要素包括:
- 账户体系的基本信息查询
- 业务提供的服务查询
- 事务操作查询。
- 管理接口测评要素包括:
- 节点信息和节点状态可查询
- 提供节点级别配置管理接口
- 提供节点监控入口。
- 外部接口测评要素包括:
性能测评
区块链的性能测评大致可从三个角度进行考量:
- 交易处理性能
- 数据查询性能
- 稳定性
下面将从这三个角度展开介绍区块链的性能测评。
(1)交易处理性能
在一般情况下,区块链性能指的是交易处理性能,区块链集群通常能够处理两种类型的交易,
- 普通转账交易
- 智能合约交易
为了比较不同区块链平台的性能,可选用典型的普通转账交易作为标准性能测试用例进行测评。测评工具可选用Caliper和Frigate,通过模拟正常、峰值及异常负载条件对区块链集群发送交易,观察当负载逐渐增加时,区块链集群的各项性能指标及资源占用的变化情况。
区块链性能指标主要考量区块链的交易吞吐量和延迟时间。
- 交易吞吐量(TransactionPer Second,TPS)指单位时间内,区块链能够处理的交易数量。
- 延迟时间(Latency)指一笔交易从发起到最终确认的时间,主要包括网络传输和系统处理时间。
在区块链系统中,交易吞吐量和延迟时间主要受共识算法和集群节点数量影响。由于公有链节点众多,网络环境复杂,因此无论采用什么共识算法,公有链平台的性能都普遍较低。例如,以太坊的交易吞吐量在20TPS左右,延迟时间则为几分钟,而联盟链或私有链平台由于节点数量大幅减少,网络简单,相对健壮,因此其交易吞吐量在特定场景下能达到千级、万级,延迟时间能达到秒级甚至毫秒级。
下图为主流区块链平台以太坊、Hyperledger Fabric(kafka版本)、Libra和趣链区块链平台的性能对比情况。

(2)数据查询性能
常见的数据查询有区块查询、交易查询、回执查询、账本查询等,可通过在不同数据量级时进行数据查询性能测试,考察区块链数据查询性能,以及区块链数据量增长对数据查询性能的影响。
与交易处理性能不同,数据查询性能指标主要为
- 并发用户数
- TPS
- 响应时间
由于数据查询操作并不需要进行共识,因此其响应时间一般要求达到秒级。
(3)稳定性
区块链稳定性测试是在交易处理性能测试的基础上,通过延长/缩短测试时间和增大/减小负载量进行的,一般分为以下几种场景。
- 高负载压力测试,以最大负载持续运行一段时间,观察交易处理速度和资源占用情况。
- 低负载持续运行7×24小时,观察交易处理速度和资源占用情况。
- 尖峰冲击,瞬时向集群发送2倍最大负载的交易量,观察集群状态、处理成功率。
另外,还可以进行混沌测试,对集群施加一定干扰,观察集群的抗干扰能力和异常恢复能力。
安全测评
为了保障区块链产品的安全性,需要从区块链自身的体系架构进行分析和梳理,针对区块链产品的安全测评大致可以从数据存储、网络传输、共识算法、智能合约和权限控制五个方面展开。
(1)数据存储
数据不可篡改和去中心化是区块链最重要的两个特性,所有的参与方节点都保存着全部的区块数据。这就要求区块链对链上数据的一致性和保密性进行保障。
- 数据一致性。数据一致性是指区块链中所有的参与方节点在参与共识后,对于交易的打包和执行都应该相同,保证最后上链的数据保持一致。同时,当一个或少数节点存储的区块数据被篡改时,应该能够得到及时地监测和恢复。
- 数据保密性。数据保密性就是区块链应提供相应加密手段保障链上数据的私密性,防止交易信息被其他无权限的参与方节点获取。
(2)网络传输
实现区块链去中心化最重要的一个基础就是P2P网络,所有共识的交易都需要进行全网的广播。这就要求区块链保证网络传输过程的传输加密性和消息不可篡改。
- 传输加密性。传输加密性需要保证节点间数据的转发和广播应使用可加密的方式进行,用密文代替明文进行传输。
- 消息不可篡改。消息不可篡改要求区块链能够及时发现在传输过程中被恶意篡改的交易,并保证该交易无法上链。
(3)共识算法
共识算法是区块链技术的核心,按照其制定的规则,各区块链节点都可以对交易的处理和执行达成共识。共识算法保证了数据的写入需要大部分参与方节点认同,有效构建了去中心化系统。同时,能保障区块链集群能够容纳一定的错误节点或恶意节点。区块链的共识安全应考虑其容错性和可用性,如果支持转账交易,则需要防止双花攻击。
- 容错性。区块链共识的容错性指的是在错误节点数少于理论值时,整个集群依然能够维持正常的交易共识和处理。
- 可用性。可用性指的是在存在恶意节点的情况下,整个集群也能对交易进行正确的处理,即保证合法交易能够共识成功,非法交易无法上链。
- 防止双花攻击。防止双花攻击主要是避免同一笔代币在不同的交易中被花费。应保证节点能够正确应对双花攻击,其中一条交易成功,其他交易都应该失败。
(4)智能合约
智能合约对区块链而言,是在不同应用领域进行区块链实践的基石。智能合约与区块链技术的结合能够帮助区块链应用实现更复杂的业务。但是,如果智能合约运行的虚拟机环境或智能合约管理、智能合约编码本身存在漏洞,那么很可能导致极大的风险。
- 智能合约运行安全。智能合约运行安全主要要求虚拟机在智能合约运行出现异常时,如访问地址越界、堆栈溢出等,能够将智能合约状态进行回滚,保证虚拟机正常工作。
- 智能合约管理安全。智能合约管理安全保障智能合约拥有完备的生命周期管理,能够对链上已部署的智能合约进行冻结、解冻、升级或删除等管理操作,能留下相关的操作日志。同时,需要保证链上智能合约和数据无法被恶意篡改。
- 智能合约编码安全。智能合约编码安全主要针对上层应用,不安全的智能合约可能导致极大的安全漏洞,如整型溢出、重入攻击等。所以要配备相应的智能合约安全检测工具和平台,以保证智能合约编码的安全性。
(5)权限控制
权限控制主要是指对区块链众多用户进行角色和权限的管理和划分,对链上数据的操作和访问进行严格的控制。同时,需要建立完善的节点准入机制。
- 账户权限管理。账户权限管理要求区块链能够对链上的账户进行授权和权限回收,严格管理高风险操作的执行权限,同时确保所有操作能够被记录。
- 节点准入机制。节点准入机制的建立主要是保证区块链集群能够有效鉴别非法节点的身份,所有节点的加入都要获得大部分节点的认可和授权。
- 接口权限控制体系。接口权限控制体系由角色权限体系、接口权限控制和接口访问控制组成,需要根据一定规则区分角色权限、接口类型和接口的访问权限,考察是否存在越权操作现象。
- 数据访问控制权限。数据访问控制权限考察区块链系统是否按照既定的规则配备一套完善的数据访问控制规则,检查系统是否存在越权访问数据的危险。
拓展性测评
拓展性测评主要包括可靠性、可维护性、可移植性、互操作性和可扩展性五个方面的测评。
- 可靠性测评要素
- 可用性。考察在特定条件下,区块链系统可提供服务的程度。
- 容错性。考察集群在处理错误操作如异常查询、异常接口调用时,系统可提供服务的程度。
- 健壮性。当集群节点发生异常时,集群可识别,并通过一定机制恢复到正常状态;考察单个节点故障能否导致区块链集群不可用。
- 易恢复性。考察在发生异常时,集群节点是否能自行恢复到正常状态,是否可以通过其他节点恢复到正常状态。
- 可维护性测评要素
- 易分析性。考察区块链系统发生错误时是否可被诊断及诊断的难易程度。
- 易变更性。对区块链系统实施修改的难易程度。
- 易测试性。区块链系统测试的难易程度。
- 可升级性。考察区块链系统是否可升级,以及升级之后对旧版本的兼容性。
- 可移植性测评要素
- 适应性。考察在不同软硬件环境下,区块链系统是否能正常运行。
- 易安装性。考察区块链系统易安装和易部署的程度。
- 可替换性。考察在相同软硬件环境下,区块链系统组件是否可替换及替换的难易程度。
- 互操作性测评要素
- 数据一致性。区块链系统节点间数据的一致性。
- 可协同性。与其他区块链系统间的互操作程度。
- 易替换性。考察在相同执行环境下,替换或升级部分组件,功能是否能正常使用,数据是否可兼容。
- 可扩展性测评要素
- 存储可扩展。存储模块是否可扩展,是否支持分片。
- 执行可扩展。执行模块是否可扩展,是否支持分片。
如有侵权请联系:admin#unsafe.sh