API Server:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发行等机制,该服务运行在Master节点上。 etcd:保存了整个集群的状态,该服务运行在Master节点上。 Controller Manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等,该服务运行在Master节点上。 Scheduler:负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上,该服务运行在Master节点上。 Kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理。该服务运行在所有的Master和node节点上。 Container Runtime:负责镜像管理以及 Pod 和容器的真正运行(CRI)。该服务运行在所有的Master和node节点上。 Kube-proxy:负责为 Service 提供 Cluster 内部的服务发现和负载均衡。该服务运行在所有的Master和node节点上。
Master控制节点
kube-apiserver etcd kube-scheduler kube-controller-manager
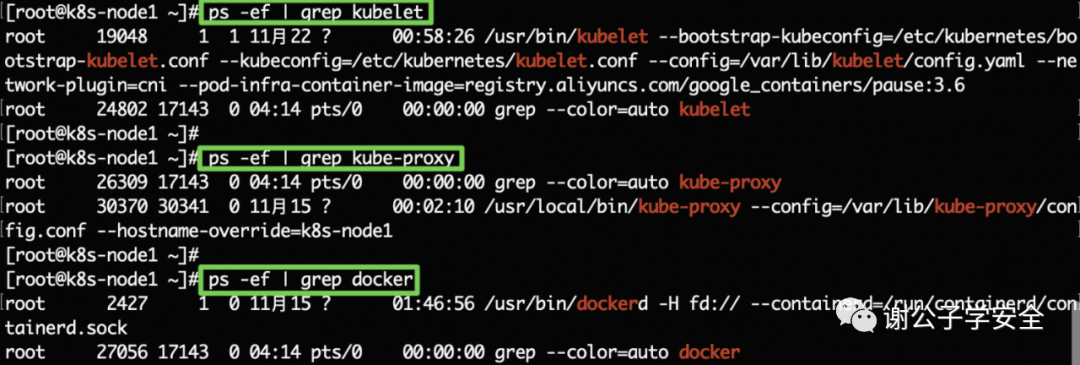
kubelet kube-proxy Container Runtime:在集群内每个节点上都会安装Container Runtime容器运行时环境,以使Pod可以在上运行。可以是Docker或者其他容器平台如container。
“
kube-apiserver
“
etcd
“
kube-scheduler
“
kube-controller-manager
Node工作节点
kubelet: 此服务会在集群中每个master和Node节点运行,负责K8s Master控制节点和Node工作节点之间的通信,还负责Pod对应的容器创建,启动和停止等任务,以实现集群管理的基本功能。 kube-proxy: 此服务会在集群中每个master和Node节点运行,是集群中每个Node节点上运行的网络代理,是实现K8s服务概念的一部分。它维护节点上的一些网络规则,这些网络规则会允许从集群内部或外部的网络会话与Pod进行网络通信。 Container Runtime: 在集群内每个节点上都会安装Container Runtime容器运行时环境,以使Pod可以在上运行。可以是Docker或者其他容器平台如container。
Pod
Replication Controller
确保pod数量:它会确保Kubernetes中有指定数量的Pod在运行。如果少于指定数量的pod,Replication Controller会创建新的,反之则会删除掉多余的以保证Pod数量不变。 确保pod健康:当pod不健康,运行出错或者无法提供服务时,Replication Controller也会杀死不健康的pod,重新创建新的。 弹性伸缩 :在业务高峰或者低峰期的时候,可以通过Replication Controller动态的调整pod的数量来提高资源的利用率。同时,配置相应的监控功能(Hroizontal Pod Autoscaler),会定时自动从监控平台获取Replication Controller关联pod的整体资源使用情况,做到自动伸缩。 滚动升级:滚动升级为一种平滑的升级方式,通过逐步替换的策略,保证整体系统的稳定,在初始化升级的时候就可以及时发现和解决问题,避免问题不断扩大。
Deploment
Replication Controller全部功能:Deployment继承了上面描述的Replication Controller全部功能。 事件和状态查看:可以查看Deployment的升级详细进度和状态。 回滚:当升级pod镜像或者相关参数的时候发现问题,可以使用回滚操作回滚到上一个稳定的版本或者指定的版本。 版本记录: 每一次对Deployment的操作,都能保存下来,给予后续可能的回滚使用。 暂停和启动:对于每一次升级,都能够随时暂停和启动。 多种升级方案:Recreate:删除所有已存在的pod,重新创建新的; RollingUpdate:滚动升级,逐步替换的策略,同时滚动升级时,支持更多的附加参数,例如设置最大不可用pod数量,最小升级间隔时间等等。
“
Replication Set
“
创建deployment
kubectl create deploy nginx-deploy --image=nginx:alpine --dry-run=client -o yamlspec下面的replicas参数代表的是副本数,用户描述希望创建多少个pod,默认为1。通过副本数字段,我们可以提高应用的可用性,减少因意外导致旧Pod被删除、新Pod未起引起可用性下降的问题。此外,K8s集群会监控Deployment的中Pod的状态,如果Pod因意外被删除,导致集群中的Pod数量低于期望的replicas,K8s会自动创建Pod,以达到yaml中对replicas的期望值。 spec下面的selector参数作用是“筛选”出要被 Deployment 管理的 Pod 对象,筛选的规则是通过下面的“matchLabels”字段,定义了 Pod 对象应该携带的 label。它必须和“template”里 Pod 定义的“labels”完全相同(指name相同的label值相同,不是要具有Pod所有的labels),否则 Deployment 就会找不到要控制的 Pod 对象,apiserver 也会告诉你 yaml 格式校验错误无法创建。 spec下面的template参数定义了pod应该是什么样的,它其实就是Pod资源对象中的内容。K8s会根据spec.replicas字段,创建出spec.replicas个Pod,每个Pod描述样子就是spec.template所描述的。
#使用yml文件在指定test命名空间下创建部署kubectl apply -f 1.yml -n test#查看部署kubectl get deploy nginx-deploy -n test#查看指定命名空间下的podkubectl get pods -n test#查看 Deployment 创建的 ReplicaSetkubectl get replicaSet -A#使用yam文件在指定test命名空间下删除部署kubectl delete -f 1.yml -n test#在指定test命名空间下创建一个名为nginx的deployment部署kubectl create deployment nginx-deploy2 --image=nginx:alpine --port=8080 -n test#使用名字删除部署kubectl delete deployments.apps nginx-deploy2 -n test
Namespace
“
kube-system
“
kube-public
“
kube-node-lease
“
default
“
kubernetes-dashboard
非常感谢您读到现在,由于作者的水平有限,编写时间仓促,文章中难免会出现一些错误或者描述不准确的地方,恳请各位师傅们批评指正。
如果你想一起学习内网渗透、域渗透、云安全、红队攻防的话,可以加入下面的知识星球一起学习交流。
文章来源: http://mp.weixin.qq.com/s?__biz=MzI2NDQyNzg1OA==&mid=2247491738&idx=1&sn=1cf416d070839f1ce773368d6542c72c&chksm=eaae60a7ddd9e9b10624830553212876402568d933db2c5e7d213d4a4fa68e062ebb893607ea#rd
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh