
本文是一个较为完整的 mitmproxy教程,侧重于介绍如何开发拦截脚本,帮助读者能够快速得到一个自定义的代理工具。
本文假设读者有基本的 python 知识,且已经安装好了一个 python 3 开发环境。如果你对 nodejs 的熟悉程度大于对 python,可移步到 anyproxy,anyproxy 的功能与 mitmproxy 基本一致,但使用 js 编写定制脚本。除此之外我就不知道有什么其他类似的工具了,如果你知道,欢迎评论告诉我。
本文基于 mitmproxy v5,当前版本号为 v5.0.1。
Introduction
顾名思义,mitmproxy 就是用于 MITM 的 proxy,MITM 即中间人攻击(Man-in-the-middle attack)。用于中间人攻击的代理首先会向正常的代理一样转发请求,保障服务端与客户端的通信,其次,会适时的查、记录其截获的数据,或篡改数据,引发服务端或客户端特定的行为。
不同于 fiddler 或 wireshark 等抓包工具,mitmproxy 不仅可以截获请求帮助开发者查看、分析,更可以通过自定义脚本进行二次开发。举例来说,利用 fiddler 可以过滤出浏览器对某个特定 url 的请求,并查看、分析其数据,但实现不了高度定制化的需求,类似于:“截获对浏览器对该 url 的请求,将返回内容置空,并将真实的返回内容存到某个数据库,出现异常时发出邮件通知”。而对于 mitmproxy,这样的需求可以通过载入自定义 python 脚本轻松实现。
但 mitmproxy 并不会真的对无辜的人发起中间人攻击,由于 mitmproxy 工作在 HTTP 层,而当前 HTTPS 的普及让客户端拥有了检测并规避中间人攻击的能力,所以要让 mitmproxy 能够正常工作,必须要让客户端(APP 或浏览器)主动信任 mitmproxy 的 SSL 证书,或忽略证书异常,这也就意味着 APP 或浏览器是属于开发者本人的——显而易见,这不是在做黑产,而是在做开发或测试。
事实上,以上说的仅是 mitmproxy 以正向代理模式工作的情况,通过调整配置,mitmproxy 还可以作为透明代理、反向代理、上游代理、SOCKS 代理等,但这些工作模式针对 mitmproxy 来说似乎不大常用,故本文仅讨论正向代理模式。
Features
- 拦截HTTP和HTTPS请求和响应并即时修改它们
- 保存完整的HTTP对话以供以之后重发和分析
- 重发HTTP对话的客户端
- 重发先前记录的服务的HTTP响应
- 反向代理模式将流量转发到指定的服务器
- 在macOS和Linux上实现透明代理模式
- 使用Python对HTTP流量进行脚本化修改
- 实时生成用于拦截的SSL / TLS证书
- And much, much more…
Installation
“安装 mitmproxy”这句话是有歧义的,既可以指“安装 mitmproxy 工具”,也可以指“安装 python 的 mitmproxy 包”,注意后者是包含前者的。
如果只是拿 mitmproxy 做一个替代 fiddler 的工具,没有什么定制化的需求,那完全只需要“安装 mitmproxy 工具”即可,去 mitmproxy 官网 上下载一个 installer 便可开箱即用,不需要提前准备好 python 开发环境。但显然,这不是这里要讨论的,我们需要的是“安装 python 的 mitmproxy 包”。
安装 python 的 mitmproxy 包除了会得到 mitmproxy 工具外,还会得到开发定制脚本所需要的包依赖,其安装过程并不复杂。
首先需要安装好 python,版本需要不低于 3.6,且安装了附带的包管理工具 pip。这里不做展开,假设你已经准备好这样的环境了。
安装开始。
在 linux 中:
sudo pip3 install mitmproxy
在 windows 中,以管理员身份运行 cmd 或 power shell:
pip3 install mitmproxy
在macos中:
brew install mitmproxy
安装完成后,系统将拥有 mitmproxy、mitmdump、mitmweb 三个命令,由于 mitmproxy 命令不支持在 windows 系统中运行(这没关系,不用担心),我们可以拿 mitmdump 测试一下安装是否成功,执行:
mitmdump --version
应当可以看到类似于这样的输出:
Mitmproxy: 5.0.1
Python: 3.8.2
OpenSSL: OpenSSL 1.1.1f 31 Mar 2020
Platform: macOS-10.15.3-x86_64-i386-64bit
Run
要启动 mitmproxy 用 mitmproxy、mitmdump、mitmweb 这三个命令中的任意一个即可,这三个命令功能一致,且都可以加载自定义脚本,唯一的区别是交互界面的不同。
mitmproxy 命令启动后,会提供一个命令行界面,用户可以实时看到发生的请求,并通过命令过滤请求,查看请求数据。形如:
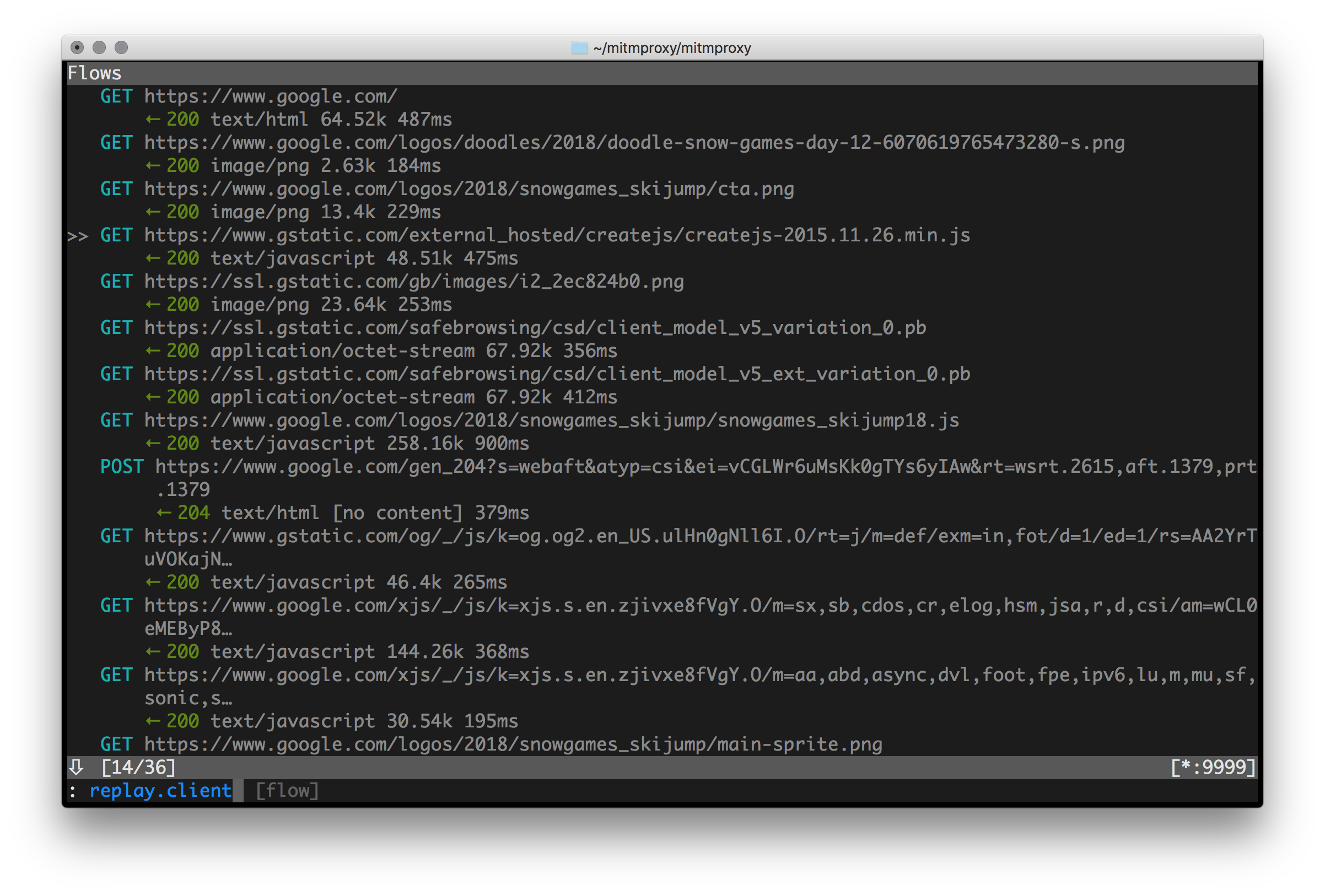
配置代理的方法与配置burpsuite一样,我用的谷歌浏览器(127.0.0.1 8080),然后命令行执行
mitmproxy --listen-host 127.0.0.1 -p 8080
之后,浏览器地址访问http://mitm.it/,点击Other下载安装证书,下图所示:


usage: mitmproxy [options]
#可选参数:
-h, --help show this help message and exit
--version show version number and exit
--options Show all options and their default values
--commands 显示所有命令及其签名
--set option[=value] 设置一个选项。 省略该值时,布尔值设置为true,字符串和整数设置为None(如果允许),并且序列为空。 布尔值可以为true,false或toggle
-q, --quiet Quiet.
-v, --verbose 增加日志详细程度
--mode MODE, -m MODE 模式可以是“常规”,“透明”,“ socks5”,“反向:SPEC”或“上游:SPEC”。 对于反向和上游代理模式,SPEC是主机规范,形式为“ http [s]:// host [:port]”
--no-anticache
--anticache 去除可能导致服务器返回304-not-modified的请求头
--no-showhost
--showhost 使用Host标头构造用于显示的URL
--rfile PATH, -r PATH 从文件读取流量
--scripts SCRIPT, -s SCRIPT 执行脚本。 可能会多次通过
--stickycookie FILTER 设置粘性Cookie过滤条件,根据要求匹配
--stickyauth FILTER 设置粘性身份验证过滤条件,根据要求匹配
--save-stream-file PATH, -w PATH 流量到达时保存到文件(附加路径)。
--no-anticomp
--anticomp 尝试令服务器向我们发送未压缩的数据。
--console-layout {horizontal,single,vertical} 控制台布局
--no-console-layout-headers
--console-layout-headers 显示布局组件标题
#代理选项:
--listen-host HOST 绑定代理的地址到HOST
--listen-port PORT, -p PORT 代理服务端口
--no-server, -n
--server 启动代理服务器( 默认启用)
--ignore-hosts HOST 忽略主机并转发所有流量,而不对其进行处理。 在透明模式下,建议使用IP地址(范围),而不要使用主机名。 在常规模式下,仅SSL流量会被忽略,应使用主机名。 利用正则表达式解释提供的值,并与ip或主机名匹配
--allow-hosts HOST 与--ignore-hosts相反
--tcp-hosts HOST 与--ignore-hosts相反。 对于与该模式匹配的所有主机,可以通过通用TCP SSL代理模式。 与--ignore相似,但是SSL连接被拦截。 通信内容以详细模式打印到日志中
--upstream-auth USER:PASS 通过将HTTP基本身份验证添加到上游代理和反向代理请求。 格式:用户名:密码
--proxyauth SPEC 需要代理身份验证。 格式:“用户名:密码”,“任何”以接受任何用户/密码组合,“ @ path”以使用Apache htpasswd文件或用于LDAP认证的“ ldap [s]:url_server_ldap:dn_auth:password:dn_subtree”
--no-rawtcp
--rawtcp 启用/禁用实验性原始TCP支持。 以非ascii字节开头的TCP连接将被视为与tcp_hosts匹配。 启发式方法很粗糙,请谨慎使用。 默认禁用
--no-http2
--http2 启用/禁用HTTP / 2支持。 默认情况下启用HTTP / 2支持
#SSL:
--certs SPEC 形式为“ [domain =] path”的SSL证书。 该域可以包含通配符,如果未指定,则等于“ *”。 路径中的文件是PEM格式的证书。 如果PEM中包含私钥,则使用私钥,否则使用conf目录中的默认密钥。 PEM文件应包含完整的证书链,并将叶子证书作为第一项
--no-ssl-insecure
--ssl-insecure, -k 不要验证上游服务器SSL / TLS证书
--key-size KEY_SIZE 证书和CA的TLS密钥大小
#客户端重发:
--client-replay PATH, -C PATH 重发来自已保存文件的客户端请求
#服务端重发:
--server-replay PATH, -S PATH 从保存的文件重发服务器响应
--no-server-replay-kill-extra
--server-replay-kill-extra 在重发期间杀死额外的请求。
--no-server-replay-nopop
--server-replay-nopop 使用后,请勿从服务器重发状态中删除流量。 这样可以多次重发相同的响应。
--no-server-replay-refresh
--server-replay-refresh 通过调整日期,到期和最后修改的header头,以及调整cookie过期来刷新服务器重发响应。
#更换:
--replacements PATTERN, -R PATTERN 替换形式:替换形式为``/ pattern / regex / replacement'',其中分隔符可以是任何字符。 可能会多次通过。
#设置Headers:
--setheaders PATTERN, -H PATTERN 格式为“ /pattern/header/value”的标题设置模式,其中分隔符可以是任何字符。
#Filters:
有关过滤条件表达式语法,请参见mitmproxy中的帮助。
--intercept FILTER 设置拦截过滤表达式。
--view-filter FILTER 将视图限制为匹配流。
mitmdump是mitmproxy的命令行模式。 它提供了类似tcpdump的功能,可帮助你查看,记录和以编程方式转换HTTP流量。 有关完整的文档,请参见--help。
例1.
mitmdump -w outfile #保存流量
以代理模式启动mitmdump,并将所有流量写入outfile中。
例2.
mitmdump -nr infile -w outfile "~m post" #保存过滤后的流量
在不绑定代理端口(-n)的情况下启动mitmdump,从infile中读取所有流,应用指定的过滤表达式(仅匹配POST),然后写入outfile。
例3.
mitmdump -nc outfile #客户端重发
在不绑定代理端口(-n)的情况下启动mitmdump,然后重发outfile(-c filename)中的所有请求。 以较明显的方式组合的标志,因此您可以重播来自一个文件的请求,并将结果流写入另一个文件:
mitmdump -nc srcfile -w dstfile
有关更多信息,请参见client-side replay部分。
例4.
mitmdump -s examples/add_header.py #运行一个脚本
这将运行add_header.py示例脚本,该脚本仅向所有响应添加新的header头。
例5.
mitmdump -ns example/add_header.py -r srcfile -w dstfile #脚本化数据转换
此命令从srcfile加载数据请求,根据指定的脚本对其进行转换,然后将其写回到dstfile文件中。
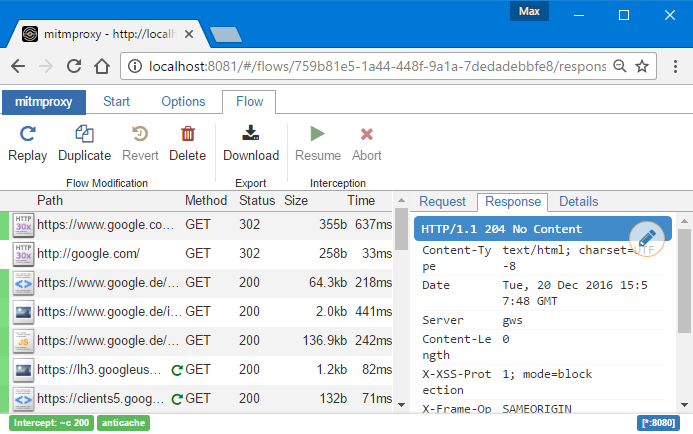
mitmweb 命令启动后,会提供一个 web 界面,用户可以实时看到发生的请求,并通过 GUI 交互来过滤请求,查看请求数据。形如:
Scripts
完成了上述工作,我们已经具备了操作 mitmproxy 的基本能力 了。接下来开始开发自定义脚本,这才是 mitmproxy 真正强大的地方。
脚本的编写需要遵循 mitmproxy 规定的套路,这样的套路有两个,使用时选其中一个套路即可。
第一个套路是,编写一个 py 文件供 mitmproxy 加载,文件中定义了若干函数,这些函数实现了某些 mitmproxy 提供的事件,mitmproxy 会在某个事件发生时调用对应的函数,形如:
import mitmproxy.http
from mitmproxy import ctx
num = 0
def request(flow: mitmproxy.http.HTTPFlow):
global num
num = num + 1
ctx.log.info("We've seen %d flows" % num)
第二个套路是,编写一个 py 文件供 mitmproxy 加载,文件定义了变量 addons,addons 是个数组,每个元素是一个类实例,这些类有若干方法,这些方法实现了某些 mitmproxy 提供的事件,mitmproxy 会在某个事件发生时调用对应的方法。这些类,称为一个个 addon,比如一个叫 Counter 的 addon:
import mitmproxy.http
from mitmproxy import ctx
class Counter:
def __init__(self):
self.num = 0
def request(self, flow: mitmproxy.http.HTTPFlow):
self.num = self.num + 1
ctx.log.info("We've seen %d flows" % self.num)
addons = [
Counter()
]
这里强烈建议使用第二种套路,直觉上就会感觉第二种套路更为先进,使用会更方便也更容易管理和拓展。况且这也是官方内置的一些 addon 的实现方式。
我们将上面第二种套路的示例代码存为 addons.py,再重新启动 mitmproxy:
mitmweb -s addons.py
当浏览器使用代理进行访问时,就应该能看到控制台里有类似这样的日志:
Web server listening at http://127.0.0.1:8081/
Loading script addons.py
Proxy server listening at http://*:8080
We've seen 1 flows
……
……
We've seen 2 flows
……
We've seen 3 flows
……
We've seen 4 flows
……
……
We've seen 5 flows
……
这就说明自定义脚本生效了。
Events
上述的脚本估计不用我解释相信大家也看明白了,就是当 request 发生时,计数器加一,并打印日志。这里对应的是 request 事件,那总共有哪些事件呢?不多,也不少,这里详细介绍一下。
事件针对不同生命周期分为 5 类。“生命周期”这里指在哪一个层面看待事件,举例来说,同样是一次 web 请求,我可以理解为“HTTP 请求 -> HTTP 响应”的过程,也可以理解为“TCP 连接 -> TCP 通信 -> TCP 断开”的过程。那么,如果我想拒绝来个某个 IP 的客户端请求,应当注册函数到针对 TCP 生命周期 的 tcp_start 事件,又或者,我想阻断对某个特定域名的请求时,则应当注册函数到针对 HTTP 声明周期的 http_connect 事件。其他情况同理。
1. 针对 HTTP 生命周期
def http_connect(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 收到了来自客户端的 HTTP CONNECT 请求。在 flow 上设置非 2xx 响应将返回该响应并断开连接。CONNECT 不是常用的 HTTP 请求方法,目的是与服务器建立代理连接,仅是 client 与 proxy 的之间的交流,所以 CONNECT 请求不会触发 request、response 等其他常规的 HTTP 事件。
def requestheaders(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自客户端的 HTTP 请求的头部被成功读取。此时 flow 中的 request 的 body 是空的。
def request(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自客户端的 HTTP 请求被成功完整读取。
def responseheaders(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自服务端的 HTTP 响应的头部被成功读取。此时 flow 中的 response 的 body 是空的。
def response(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 来自服务端端的 HTTP 响应被成功完整读取。
def error(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 发生了一个 HTTP 错误。比如无效的服务端响应、连接断开等。注意与“有效的 HTTP 错误返回”不是一回事,后者是一个正确的服务端响应,只是 HTTP code 表示错误而已。
2. 针对 TCP 生命周期
def tcp_start(self, flow: mitmproxy.tcp.TCPFlow):
(Called when) 建立了一个 TCP 连接。
def tcp_message(self, flow: mitmproxy.tcp.TCPFlow):
(Called when) TCP 连接收到了一条消息,最近一条消息存于 flow.messages[-1]。消息是可修改的。
def tcp_error(self, flow: mitmproxy.tcp.TCPFlow):
(Called when) 发生了 TCP 错误。
def tcp_end(self, flow: mitmproxy.tcp.TCPFlow):
(Called when) TCP 连接关闭。
3. 针对 Websocket 生命周期
def websocket_handshake(self, flow: mitmproxy.http.HTTPFlow):
(Called when) 客户端试图建立一个 websocket 连接。可以通过控制 HTTP 头部中针对 websocket 的条目来改变握手行为。flow 的 request 属性保证是非空的的。
def websocket_start(self, flow: mitmproxy.websocket.WebSocketFlow):
(Called when) 建立了一个 websocket 连接。
def websocket_message(self, flow: mitmproxy.websocket.WebSocketFlow):
(Called when) 收到一条来自客户端或服务端的 websocket 消息。最近一条消息存于 flow.messages[-1]。消息是可修改的。目前有两种消息类型,对应 BINARY 类型的 frame 或 TEXT 类型的 frame。
def websocket_error(self, flow: mitmproxy.websocket.WebSocketFlow):
(Called when) 发生了 websocket 错误。
def websocket_end(self, flow: mitmproxy.websocket.WebSocketFlow):
(Called when) websocket 连接关闭。
4. 针对网络连接生命周期
def clientconnect(self, layer: mitmproxy.proxy.protocol.Layer):
(Called when) 客户端连接到了 mitmproxy。注意一条连接可能对应多个 HTTP 请求。
def clientdisconnect(self, layer: mitmproxy.proxy.protocol.Layer):
(Called when) 客户端断开了和 mitmproxy 的连接。
def serverconnect(self, conn: mitmproxy.connections.ServerConnection):
(Called when) mitmproxy 连接到了服务端。注意一条连接可能对应多个 HTTP 请求。
def serverdisconnect(self, conn: mitmproxy.connections.ServerConnection):
(Called when) mitmproxy 断开了和服务端的连接。
def next_layer(self, layer: mitmproxy.proxy.protocol.Layer):
(Called when) 网络 layer 发生切换。你可以通过返回一个新的 layer 对象来改变将被使用的 layer。详见 layer 的定义。
5. 通用生命周期
def configure(self, updated: typing.Set[str]):
(Called when) 配置发生变化。updated 参数是一个类似集合的对象,包含了所有变化了的选项。在 mitmproxy 启动时,该事件也会触发,且 updated 包含所有选项。
def done(self):
(Called when) addon 关闭或被移除,又或者 mitmproxy 本身关闭。由于会先等事件循环终止后再触发该事件,所以这是一个 addon 可以看见的最后一个事件。由于此时 log 也已经关闭,所以此时调用 log 函数没有任何输出。
def load(self, entry: mitmproxy.addonmanager.Loader):
(Called when) addon 第一次加载时。entry 参数是一个 Loader 对象,包含有添加选项、命令的方法。这里是 addon 配置它自己的地方。
def log(self, entry: mitmproxy.log.LogEntry):
(Called when) 通过 mitmproxy.ctx.log 产生了一条新日志。小心不要在这个事件内打日志,否则会造成死循环。
def running(self):
(Called when) mitmproxy 完全启动并开始运行。此时,mitmproxy 已经绑定了端口,所有的 addon 都被加载了。
def update(self, flows: typing.Sequence[mitmproxy.flow.Flow]):
(Called when) 一个或多个 flow 对象被修改了,通常是来自一个不同的 addon。
Reference:
- mitmproxy 官方文档:https://docs.mitmproxy.org/stable
- mitmproxy 脚本示例:https://github.com/mitmproxy/mitmproxy/tree/master/examples
如有侵权请联系:admin#unsafe.sh