
官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序
一、前言
在渗透测试的初期时,目录扫描是必不可少的,它是信息收集阶段最重要的工作之一,相信各位大神的手上都有一款适合自己的目录扫描神器。但是呢,总是用别人的工具,不一定就能满足自己的日常测试需要,也不利于培养自己的编程能力(拒绝当脚本小子)。我在平时的测试工作中,习惯于自己写各种测试脚本来辅助测试,尽可能地多使用自己编写的工具。
今天,为大家带来的是多线程目录扫描脚本的编写方法。
二、编写思路
编写目录扫描脚本的思路非常简单:如果请求url的返回报文的状态码为200,那么我们就可以认为这个url是真实存在的(涉及Python的requests库)。另外,涉及到扫描、爆破等方面的知识点,使用多线程也是必不可少的(涉及Python的threading库)。
三、需要掌握的知识点
1、requests库、threading库、queue库和optparse库的使用
2、多线程的理解和运用
四、编写过程
1、脚本参数配置
首先,使用optparse模块创建脚本的参数信息,涉及参数有ip地址、线程数和扫描字典:
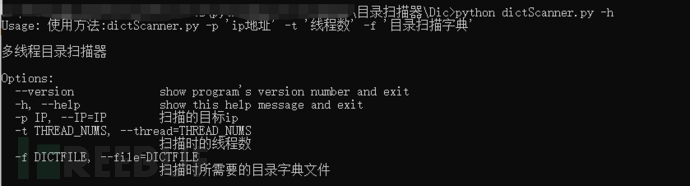
parser = OptionParser(usage="使用方法:%prog -p 'ip地址' -t '线程数' -f '目录扫描字典'", version="%prog 1.0", description="多线程目录扫描器")
parser.add_option("-p", "--IP", action="store", dest="ip", help="扫描的目标ip")
parser.add_option("-t", "--thread", action="store", dest="thread_nums", type="int", help="扫描时的线程数")
parser.add_option("-f", "--file", action="store", dest="dictfile", help="扫描时所需要的目录字典文件")
(options, args) = parser.parse_args()
thread_nums = options.thread_nums
ip = options.ip
file = options.dictfile2、字典分割
一般我们的目录扫描字典都是比较大的,如果不对字典进行分割,会导致创建多线程非常困难,从而导致脚本扫描效率低下。代码如下:
# 初始化队列
q = queue.Queue(maxsize=0)
dict_list = []
dict = open(file, "r", encoding="utf-8")
for d in dict:
dict_list.append(d.replace("\n", ""))
dict.close()
# 把大字典进行分块,每个线程处理一个列表块。这里默认每个列表块的长度为30,可根据实际情况做修改
list = [dict_list[i:i + 30] for i in range(0, len(dict_list), 30)]
for index in range(len(list)):
q.put(list[index])3、创建发送数据包的函数
这个比较简单,直接利用requests库来判断响应报文的状态码是否为200即可:
def exploit(ip, q):
while not q.empty():
exp_list = q.get()
for n in exp_list:
URL = "http://" + ip + n
code = requests.get(url=URL).status_code
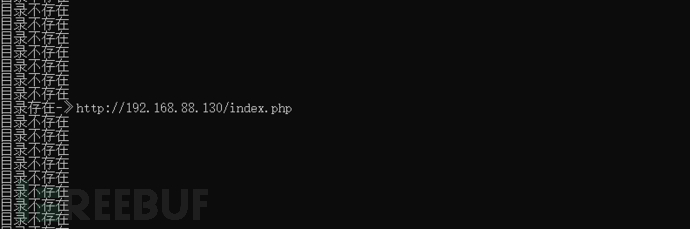
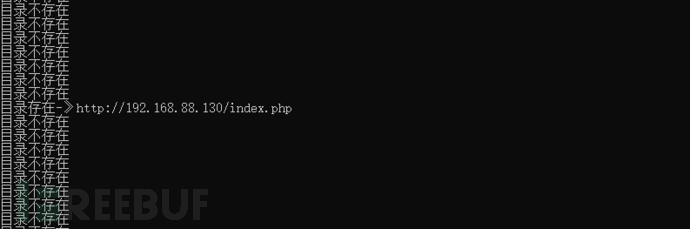
if code == 200:
print("目录存在-》{}".format(URL))
else:
print("目录不存在")4、创建多线程
代码如下:
for num in range(thread_nums):
t = threading.Thread(target=exploit, args=(ip, q))
t.start()四、完整的脚本
import requests
import queue
import threading
from optparse import OptionParser
def exploit(ip, q):
while not q.empty():
exp_list = q.get()
for n in exp_list:
URL = "http://" + ip + n
code = requests.get(url=URL).status_code
if code == 200:
print("目录存在-》{}".format(URL))
else:
print("目录不存在")
if __name__ == '__main__':
parser = OptionParser(usage="使用方法:%prog -p 'ip地址' -t '线程数' -f '目录扫描字典'", version="%prog 1.0", description="多线程目录扫描器")
parser.add_option("-p", "--IP", action="store", dest="ip", help="扫描的目标ip")
parser.add_option("-t", "--thread", action="store", dest="thread_nums", type="int", help="扫描时的线程数")
parser.add_option("-f", "--file", action="store", dest="dictfile", help="扫描时所需要的目录字典文件")
(options, args) = parser.parse_args()
thread_nums = options.thread_nums
ip = options.ip
file = options.dictfile
# 初始化队列
q = queue.Queue(maxsize=0)
dict_list = []
dict = open(file, "r", encoding="utf-8")
for d in dict:
dict_list.append(d.replace("\n", ""))
dict.close()
# 把大字典进行分块,每个线程处理一个列表块。这里默认每个列表块的长度为30,可根据实际情况做修改
list = [dict_list[i:i + 30] for i in range(0, len(dict_list), 30)]
for index in range(len(list)):
q.put(list[index])
for num in range(thread_nums):
t = threading.Thread(target=exploit, args=(ip, q))
t.start()五、测试结果
这里使用的靶场是经典的metasploit的DVWA靶场。
查看帮助信息:
开始以30线程扫描:
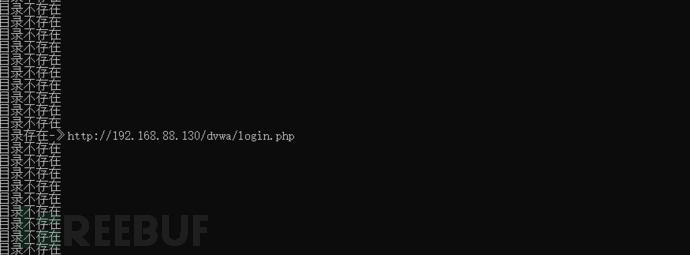
部分扫描结果: