By Laura Bauman
During my internship at Trail of Bits, I prototyped a harness that improves the testability of the eBPF verifier, simplifying the testing of eBPF programs. My eBPF harness runs in user space, independently of any locally running kernel, and thus opens the door to testing of eBPF programs across different kernel versions.
eBPF enables users to instrument a running system by loading small programs into the operating system kernel. As a safety measure, the kernel “verifies” eBPF programs at load time and rejects any that it deems unsafe. However, using eBPF is a CI / CD nightmare, because there’s no way to know whether a given eBPF program will successfully load and pass verification without testing it on a running kernel.
My harness aims to eliminate that nightmare by executing the eBPF verifier outside of the running kernel. To use the harness, a developer tweaks my libbpf-based sample programs (hello.bpf.c and hello_loader.c) to tailor them to the eBPF program being tested. The version of libbpf provided by my harness links against a “kernel library” that implements the actual bpf syscall, which provides isolation from the running kernel. The harness works well with kernel version 5.18, but it is still a proof of concept; enabling support for other kernel versions and additional eBPF program features will require a significant amount of work.
With great power comes great responsibility
eBPF is an increasingly powerful technology that is used to increase system observability, implement security policies, and perform advanced networking operations. For example, the osquery open-source endpoint agent uses eBPF for security monitoring, to enable organizations to watch process and file events happening across their fleets.
The ability to inject eBPF code into the running kernel seems like either a revelation or a huge risk to the kernel’s security, integrity, and dependability. But how on earth is it safe to load user-provided code into the kernel and execute it there? The answer to this question is twofold. First, eBPF isn’t “normal” code, and it doesn’t execute in the same way as normal code. Second, eBPF code is algorithmically “verified” to be safe to execute.
eBPF isn’t normal code
eBPF (extended Berkeley Packet Filter) is an overloaded term that refers to both a specialized bytecode representation of programs and the in-kernel VM that runs those bytecode programs. eBPF is an extension of classic BPF, which has fewer features than eBPF (e.g., two registers instead of ten), uses an in-kernel interpreter instead of a just-in-time compiler, and focuses only on network packet filtering.
User applications can load eBPF code into kernel space and run it there without modifying the kernel’s source code or loading kernel modules. Loaded eBPF code is checked by the kernel’s eBPF verifier, which tries to prove that the code will terminate without crashing.
The picture above shows the general interaction between user space and kernel space, which occurs through the bpf syscall. The eBPF program is represented in eBPF bytecode, which can be obtained through the Clang back end. The interaction begins when a user space process executes the first in the series of bpf syscalls used to load an eBPF program into the kernel. The kernel then runs the verifier, which enforces constraints that ensure the eBPF program is valid (more on that later). If the verifier approves the program, the verifier will finalize the process of loading it into the kernel, and it will run when it is triggered. The program will then serve as a socket filter, listening on a socket and forwarding only information that passes the filter to user space.
Verifying eBPF
The key to eBPF safety is the eBPF verifier, which limits the set of valid eBPF programs to those that it can guarantee will not harm the kernel or cause other issues. This means that eBPF is, by design, not Turing-complete.
Over time, the set of eBPF programs accepted by the verifier has expanded, though the testability of that set of programs has not. The following quote from the “BPF Design Q&A” section of the Linux kernel documentation is telling:
The [eBPF] verifier is steadily getting ‘smarter.’ The limits are being removed. The only way to know that the program is going to be accepted by the verifier is to try to load it. The BPF development process guarantees that the future kernel versions will accept all BPF programs that were accepted by the earlier versions.
This “development process” relies on a limited set of regression tests that can be run through the kselftest system. These tests require that the version of the source match that of the running kernel and are aimed at kernel developers; the barrier to entry for others seeking to run or modify such tests is high. As eBPF is increasingly relied upon for critical observability and security infrastructure, it is concerning that the Linux kernel eBPF verifier is a single point of failure that is fundamentally difficult to test.
Trust but verify
The main problem facing eBPF is portability—that is, it is notoriously difficult to write an eBPF program that will pass the verifier and work correctly on all kernel versions (or, heck, on even one). The introduction of BPF Compile Once-Run Everywhere (CO-RE) has significantly improved eBPF program portability, though issues still remain. BPF CO-RE relies on the eBPF loader library (libbpf), the Clang compiler, and the eBPF Type Format (BTF) information in the kernel. In short, BPF CO-RE means that an eBPF program can be compiled on one Linux kernel version (e.g., by Clang), modified to match the configuration of another kernel version, and loaded into a kernel of that version (through libbpf) as though the eBPF bytecode had been compiled for it.
However, different kernel versions have different verifier limits and support different eBPF opcodes. This makes it difficult (from an engineering perspective) to tell whether a particular eBPF program will run on a kernel version other than the one it has been tested on. Moreover, different configurations of the same kernel version will also have different verifier behavior, so determining a program’s portability requires testing the program on all desired configurations. This is not practical when building CI infrastructure or trying to ship a production piece of software.
Projects that use eBPF take a variety of approaches to overcoming its portability challenges. For projects that primarily focus on tracing syscalls (like osquery and opensnoop), BPF CO-RE is less necessary, since syscall arguments are stable between kernel versions. In those cases, the limiting factor is the variations in verifier behavior. Osquery chooses to place strict constraints on its eBPF programs; it does not take advantage of modern eBPF verifier support for structures such as bounded loops and instead continues to write eBPF programs that would be accepted by the earliest verifiers. Other projects, such as SysmonForLinux, maintain multiple versions of eBPF programs for different kernel versions and choose a program version dynamically, during compilation.
What is the eBPF verifier?
One of the key benefits of eBPF is the guarantee it provides: that the loaded code will not crash the kernel, will terminate within a time limit, and will not leak information to unprivileged user processes. To ensure that code can be injected into the kernel safely and effectively, the Linux kernel’s eBPF verifier places restrictions on the abilities of eBPF programs. The name of the verifier is slightly misleading, because although it aims to enforce restrictions, it does not perform formal verification.
The verifier performs two main passes over the code. The first pass is handled by the check_cfg() function, which ensures that the program is guaranteed to terminate by performing an iterative depth-first search of all possible execution paths. The second pass (done in the do_check() function) involves static analysis of the bytecode; this pass ensures that all memory accesses are valid, that types are used consistently (e.g., scalar values are never used as pointers), and that the number of branches and total instructions is within certain complexity limits.
As mentioned earlier in the post, the constraints that the verifier enforces have changed over time. For example, eBPF programs were limited to a maximum of 4,096 instructions until kernel version 5.2, which increased that number to 1 million. Kernel version 5.3 introduced the ability for eBPF programs to use bounded loops. Note, though, that the verifier will always be backward compatible in that all future versions of the verifier will accept any eBPF program accepted by older versions of the verifier.
Alarmingly, the ability to load eBPF programs into the kernel is not always restricted to root users or processes with the CAP_SYS_ADMIN capability. In fact, the initial plan for eBPF included support for unprivileged users, requiring the verifier to disallow the sharing of kernel pointers with user programs and to perform constant blinding. In the wake of several privilege escalation vulnerabilities affecting eBPF, most Linux distributions have disabled support for unprivileged users by default. However, overriding the default still creates a risk of crippling privilege escalation attacks.
Regardless of whether eBPF is restricted to privileged users, flaws in the verifier cannot be tolerated if eBPF is to be relied upon for security-critical functionality. As explained in an LWN.net article, at the end of the day, “[the verifier] is 2000 lines or so of moderately complex code that has been reviewed by a relatively small number of (highly capable) people. It is, in a real sense, an implementation of a blacklist of prohibited behaviors; for it to work as advertised, all possible attacks must have been thought of and effectively blocked. That is a relatively high bar.” While the code may have been reviewed by highly capable people, the verifier is still a complex bit of code embedded in the Linux kernel that lacks a cohesive testing framework. Without thorough testing, there is a risk that the backward compatibility principle could be violated or that entire classes of potentially insecure programs could be allowed through the verifier.
Enabling rigorous testing of the eBPF verifier
Given that the eBPF verifier is the foundation of critical infrastructure, it should be analyzed through a rigorous testing process that can be easily integrated into CI workflows. Kernel selftests and example eBPF programs that require a running Linux kernel for every kernel version are inadequate.
The eBPF verifier harness aims to allow testing on various kernel versions without any dependence on the locally running kernel version or configuration. In other words, the harness allows the verifier (the verifier.c file) to run in user space.
Compiling only a portion of the kernel source code for execution in user space is difficult because of the monolithic nature of the kernel and the kernel-specific idioms and functionality. Luckily, the task of eBPF verification is limited in scope, and many of the involved functions and files are consistent across kernel versions. Thus, stubbing out kernel-specific functions for user space alternatives makes it possible to run the verifier in isolation. For instance, because the verifier expects to be called from within a running kernel, it calls kernel-specific memory allocation functions when it is allocating memory. When it is run within the harness, it calls user space memory allocation functions instead.
The harness is not the first tool that aims to improve the verifier’s testability. The IO Visor Project’s BPF fuzzer has a very similar goal of running the verifier in user space and enabling efficient fuzzing—and the tool has found at least one bug. But there is one main difference between the eBPF harness and similar existing solutions: the harness is intended to support all kernel versions, making it easy to compare the same eBPF program across kernel versions. The harness leaves the true kernel functionality as intact as possible to maintain an execution environment that closely approximates a true kernel context.
System design
The harness consists of the following main components:
- Linux source code (in the form of a Git submodule)
- A LibBPF mirror (also a Git submodule)
header_stubs.h(which enables certain kernel functions and macros to be overridden or excluded altogether)- Harness source code (i.e., implementations of stubbed-out kernel functions)

The architecture of the eBPF verifier harness.
At a high level, the harness runs a sample eBPF program through the verifier by using standard libbpf conventions in sample.bpf.c and calling bpf_object__load() in sample_loader.c. The libbpf code runs as normal (e.g., probing the “kernel” to see what operations are supported, autocreating maps if configured to do so, etc.), but instead of invoking the actual bpf() syscall and trapping to the running kernel, it executes a harness “syscall” and continues running within the harnessed kernel.
Compiling a portion of the Linux kernel involves making a lot of decisions on which source files should be included and which should be stubbed out. For example, the kernel frequently calls the kmalloc() and kfree() functions for dynamic memory allocation. Because the verifier is running in user space, these functions can be replaced with user space versions like malloc() and free(). Kernel code also includes a lot of synchronization primitives that are not necessary in the harness, since the harness is a single-threaded application; those primitives can also safely be stubbed out.
Other kernel functionality is more difficult to efficiently replace. For example, getting the harness to work required finding a way to simulate the Linux kernel Virtual File System. This was necessary because the verifier is responsible for ensuring the safe use of eBPF maps, which are identified by file descriptors. To simulate operations on file descriptors, the harness must also be able to simulate the creation of files associated with the descriptors.
A demonstration
So how does the harness actually work? What do the sample programs look like? Below is a simple eBPF program that contains a bounded loop; verifier support for bounded loops was introduced in kernel version 5.3, so all kernel versions older than 5.3 should reject the program, and all versions newer than 5.3 should accept it. Let’s run it through the harness and see what happens!
bounded_loop.bpf.c:
#include "vmlinux.h"
#include <BPF/BPF_helpers.h>
SEC("tracepoint/syscalls/sys_enter_execve")
int handle_tp(void *ctx)
{
for (int i = 0; i < 3; i++) {
BPF_printk("Hello World.\n");
}
return 0;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL";
Using the harness requires compiling each eBPF program into eBPF bytecode; once that’s done, a “loader” program calls the libbpf functions that handle the setup of the bpf syscalls. The loader program looks something like the program shown below, but it can be tweaked to allow for different configuration and setup options (e.g., to disable the autocreation of maps).
bounded_loop_loader.c:
#include
#include
#include "bounded_loop.skel.h"
static int libbpf_print_fn(enum libbpf_print_level level, const char *format, va_list args) {
return vfprintf(stderr, format, args);
}
int load() {
struct bounded_loop_bpf *obj;
const struct bpf_insn *insns;
int err = 0;
libbpf_set_print(libbpf_print_fn);
obj = bounded_loop_bpf__open();
if (!obj) {
fprintf(stderr, "failed to open BPF object. \n");
return 1;
}
// this function invokes the verifier
err = bpf_object__load(*obj->skeleton->obj);
// free memory allocated by libbpf functions
bounded_loop_bpf__destroy(obj);
return err;
}
Compiling the sample program with the necessary portions of Linux source code, libbpf, and the harness runtime produces an executable that will run the verifier and report whether the program passes verification.

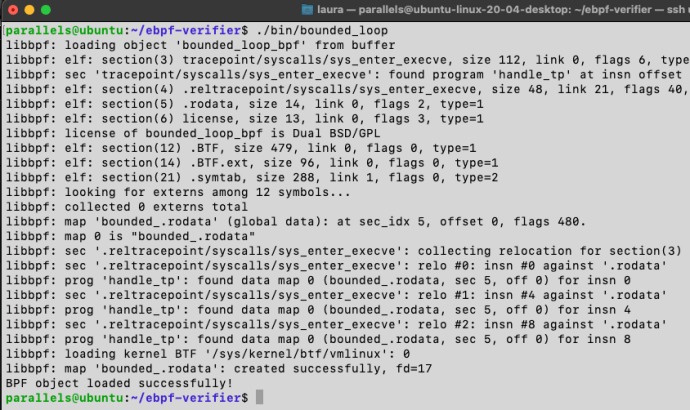
The output of bounded_loop.bpf.c when run through version 5.18 of the verifier.
Looking forward
The harness is still a proof of concept, and several aspects of it will need to be improved before it can be used in production. For instance, to fully support all eBPF map types, the harness will need the ability to fully stub out additional kernel-level memory allocation primitives. The harness will also need to reliably support all versions of the verifier between 3.15 and the latest version. Implementing that support will involve manually accounting for differences in the internal kernel application programming interfaces (APIs) between these versions and adjusting stubbed-out subsystems as necessary. Lastly, more cohesive organization of the stubbed-out functions, as well as thorough documentation on their organization, would make it much easier to distinguish between unmodified kernel code and functions that have been stubbed out with user space alternatives.
Because these issues will take a nontrivial amount of work, we invite the larger community to build upon the work we have released. While we have many ideas for improvements that will move the eBPF verifier closer to adoption, we believe there are others out there that could enhance this work with their own expertise. Although that initial work will enable rapid testing of all kernel versions once it’s complete, the harness will still need to be updated each time a kernel version is released to account for any internal changes.
However, the eBPF verifier is critical and complex infrastructure, and complexity is the enemy of security; when it is difficult to test complex code, it is difficult to feel confident in the security of that code. Thus, extracting the verifier into a testing harness is well worth the effort—though the amount of effort it requires should serve as a general reminder of the importance of testability.