好久没发帖了,不知不觉又到了除夕,祝大家新年快乐~
by devseed, 本贴论坛和我的博客同时发布
本贴代码开源详见我的github: GalgameReverse, ReverseUtil。
上篇链接:Galgame汉化中的逆向(六):动态汉化分析_以MAJIROv3引擎为例
0x0 前言
上节 Galgame汉化中的逆向(六):动态汉化分析_以MAJIROv3引擎为例,我们介绍了动态汉化。动态汉化不用分析封包结构,不用分析opcode,看上去很方便,但是动态汉化解决同步问题会很麻烦,比如说改完文本后backlog文本仍是日文、返回主界面再载入文本没有变动等问题。动态汉化也有可能出现莫名其妙的崩溃bug,且这些bug不容易被调试。
针对动态汉化的上述缺点,本节我们将介绍一种这种半动态汉化的方案。与上节的方法不同,本节不进行文本级替换,而是文件级别的替换。即去hook相关函数,动态将解密后的缓冲区替换为我们汉化后的文件。适合于那种封包与加密特别麻烦或复杂的游戏。
本文将以azsystem为例,来分析:
- 引擎如何加载游戏脚本,如何定位关键点提取脚本
- 引擎如何加载图片,如何解压各通道数据,如何将图片数据送入帧缓存渲染
- 汉化如何用
inline hook对加载后的内容进行替换

0x1 脚本文件分析与提取
(1) asb文件的分析
和上节相同,第一步先分析文件,无论静态分析算法还是动态dump缓冲区,先把文件提取出来。
由于方法差不多,这里不再详细展开了。
这个游戏封包为.arc文件,用文件长度哈希值来作为加密密钥,里面有若干个.asb脚本文件。IDA里面直接搜.asb字符串就能找到相关函数了,读取脚本文件函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
|
简单分析后,我们可以得到asb的文件头结构、校验文本函数、解压函数以下结论,具体如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
(2) asb文件的解密与提取
提取只需要hooksub_40AB65,frida代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
|
用其他工具如arc unpack可以得到arc封包的文件名,把文件名录入frida脚本,即可dump出全部asb脚本。
0x2 动态替换脚本文件
(1) 替换解密的asb缓冲区
结合上面文件分析,我们可以在004311E1| E8 7F99FDFF| call lamune.40AB65| decompress进行inlinehook,在此直接加载我们已经解密并汉化的asb文件。解密的缓冲区是前面new出来的,我们还需要修改缓冲区大小。另外还要nop掉缓冲区crc校验的函数。
上节我们用了detours,这期我们来手动inlinehook,步骤如下:
在需要
hook的位置用5字节call(E9)或jmp(E8)进行相对跳转到我们的函数上,机器码为
E8 XXXXXXXX,E9 XXXXXXXX。XXXXXXXX为相对于下一条指令的偏移,即targetva - (va + 5)执行完后
hook的函数后,结尾手动修复一下被我们修改5字节破坏的代码,跳转到下个指令处。
动态替换解密后的缓冲区脚本代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 |
|
上面代码中load_rawasb即为我们读取对应解密文件的代码,这里为了减少零碎文件,我采取了从zip文件中读取的方法。
此处不再赘述,详见我的github。
(2) 修改sjis检测字节支持gbk编码
导入中文文本后,经测试发现一大堆半角乱码。
这是因为有sjis首字节字符编码范围检测,不在sjis范围内的字符将被解析为单字节文本。

与其他游戏不同,此游戏不是用cmp ax, 0x81等指令来检测sjis字符,而且位置过多过于分散,修改起来很麻烦。
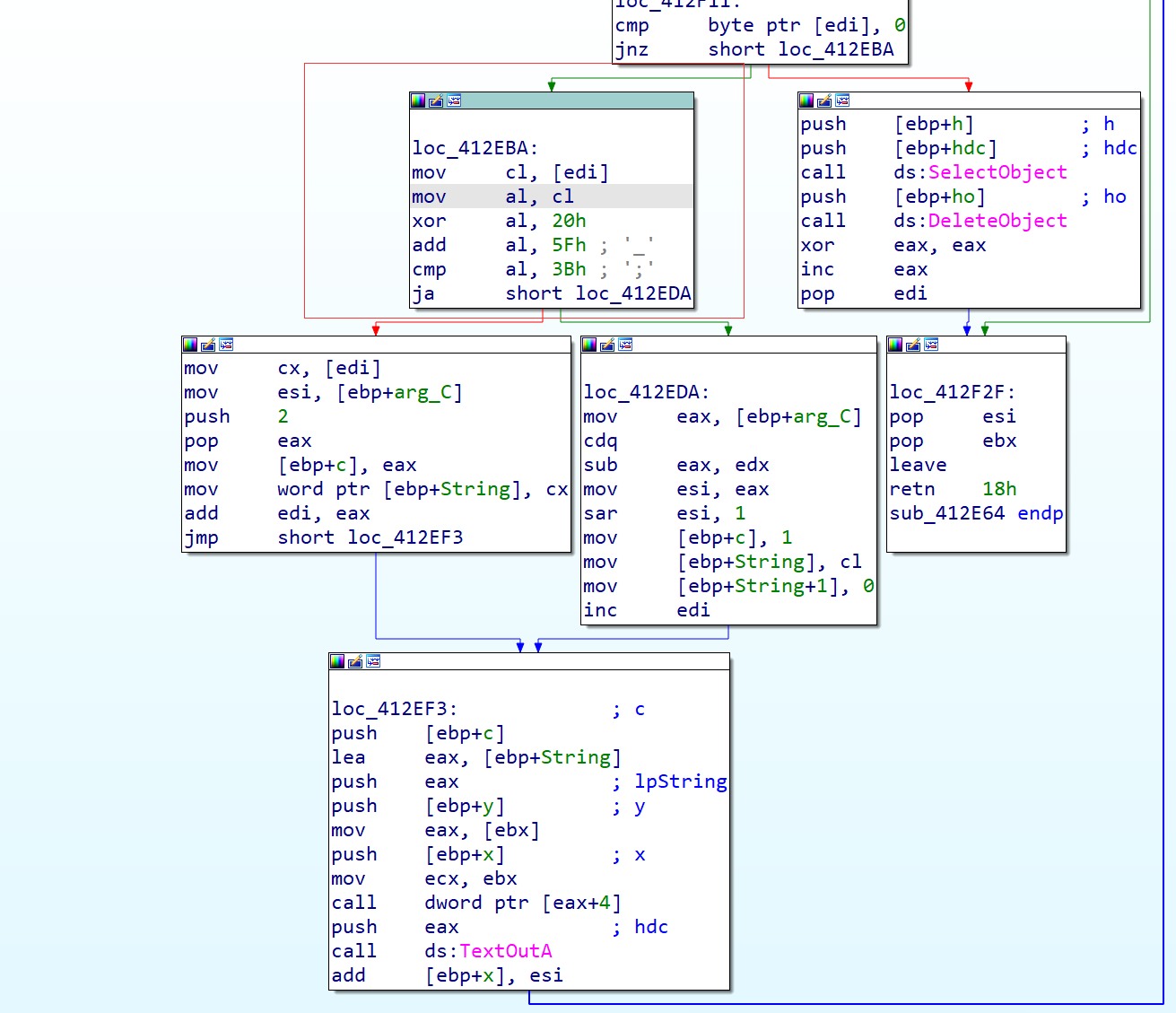
这部分定位我们可以在TextOutA下断点,往上慢慢找,可以看到下图位置:
这里非常巧妙,用一条c^0x20 + 0x5f > 0x3B就可以判断是否为sjis首字符了,具体分析如下:
1 2 3 4 5 6 7 8 |
|
修改方法也很简单,把上面xor和add用noppatch,编码检测改为cmp dl, 0x80即可。
修改完后,虽然文本框正确了,但我们发现backlog中文本还有乱码。
这时候就要在搜索其他地方的检测字符函数了,可以试着搜cmp al|bl|cl|dl, 0x3b,逐个下断点,启动backlog看哪里断下。


(3) asb opcode分析
以0nana.asb为例,这个opcode是对齐的,很工整,如下图:
总结起来就是optype 4, oplengh 4, payload n结构,超长文本只需要修正一下oplengh和jmp相关的指令就行了,如下:
1 2 3 4 5 6 7 8 9 10 |
|
将测试文本导入后,我们可以完成超长文本的汉化测试了~
0x3 图片文件的加载和渲染分析
(1) 定位图片显示缓冲区
这个游戏是通过Windows compatible DC进行绘图的,我们可以在CreateDIBinfo下断点,然后一层层往上跟,找到在缓冲区填充像素的函数,之后bitblt到帧缓冲位置。这里有个麻烦事,这游戏有很多虚函数通过虚表来寻址,如v3=(*(**v7+12))(*v7, v5, v10,a3这种。静态跟起来很费劲,可以尝试动态来看虚表。由于跟踪过于繁琐了,具体流程从略了,callback和具体调用流程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
(2) cpb图片加载
上面我们来讲了一下定位方法,和整体加载流程。在这节我们来分析一下cpb文件如何读取和加载渲染到屏幕上的。
.1 cpb结构
cpb中像素是分通道存储的,数据结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
.2 prepare DC
在渲染图片之前,游戏引擎先进行DC的初始化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
|
.3 load cpb
这部分是读取cpb到内存里,并检验文件头等信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
|
加载后,会根据通道数不同调用不同的解压缩函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
.4 decompress cpb
这个游戏有多个cpb解压函数,对应着不同通道数的文件,这里以32位图为例分析。
注意这里vv1 = (*(*obja + 0xC))(obja)中的vv1值为prepare dc中的v5 = CreateDIBSection(0, &pbmi, 0, this + 0x28, 0, 0) 此句的DIB缓冲区。
我们可以替换decompress_channel_40AA38后的缓冲区为汉化后的图片,然后让游戏引擎帮我们复制到DIB缓冲区内。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
|
解压各通道算法,看起来有点像lzss改版?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
|
.5 bitblt screen dc
最后再通过bitblt到屏幕帧缓存中,至此整个游戏图片渲染分析完毕。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
|
0x4 动态替换图片文件
为了搞明白这个游戏游戏引擎图像如何渲染的,我把很多的虚函数都跟了一遍。
其实汉化图片只需要逆向到如何解压cpb文件那里就足够了。这个游戏麻烦地方在于不同通道对应的不同处理函数,要依次来hook替换缓冲区。另外在读取文件适合要记录一些文件名,用于缓冲区动态替换我们汉化的图片。
以24位图片代码替换为例,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
|
这里采取的是png格式存储的汉化图片,为了方便用了stb进行加载。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
|
加载后遇到渲染bug,我们把对应缓冲区dump出来放到ct2中进行查看,确定原因。
这里发现原来是stbi_load_from_memory函数对于tga格式有些问题,换成png格式最后参数为0,问题解决。
至此,图片汉化问题全部解决。
0x5 后记
这个游戏我逆向了一周多把引擎的加载方式搞明白了,之后又测试导入翻译断断续续修复bug一个月,基本上汉化完美了。这里有个坑,通关后没法打开gallary。这是官方的bug,下载了升级补丁可以修复。但是之前给我的文件是初版游戏,我说基于这个版本分析的。还得把旧版搬到新版上,非常麻烦。这个故事告诉我们,以后汉化要第一时间检查更新补丁。
整体来讲,这游戏有三大难点。难点之一在封包上,有加密和校验非常麻烦,因此我们采取了动态替换解密后的缓冲区;其二,图像缓冲区不好找,里面有大量虚函数,需要一点点跟;其三,sjis字符检测过于分散,需要手动一个个调整,而且也是用非主流方式判断的。因此,我认为此游戏比较适合半动态汉化。这种基于文件的替换方式可以免去复杂的封包,同时相比文本层面上的全动态汉化,可以更方便调试,少引发一些文本同步之类的问题。
另外我用stb加载图片,这里遇到了问题,xp上运行会崩溃。
调试定位在了mov eax, large fs:2Ch上,这是因为这个库用了__declspec(thread),在win xp上LoadLibrary遇到tls就会崩,定义宏#define STBI_NO_THREAD_LOCALS即可解决。
然后进行了若干测试,我这个汉化兼容补丁性还不错~ win xp, win7, win8 , win10甚至连linux wine,exagear都测试了,可以说是全平台兼容了~ 完结撒花~

如有侵权请联系:admin#unsafe.sh