上个月 sourcegraph 放出了 conc[1] 并发库,目标是 better structured concurrency for go, 简单的评价一下每个公司都有类似的轮子,与以往的库比起 2023-1-30 08:53:42 Author: Go语言中文网(查看原文) 阅读量:72 收藏
上个月 sourcegraph 放出了 conc[1] 并发库,目标是 better structured concurrency for go, 简单的评价一下
每个公司都有类似的轮子,与以往的库比起来,多了泛型,代码写起来更优雅,不需要 interface, 不需要运行时 assert, 性能肯定更好
我们在写通用库和框架的时候,都有一个原则,并发控制与业务逻辑分离,背离这个原则肯定做不出通用库
整体介绍
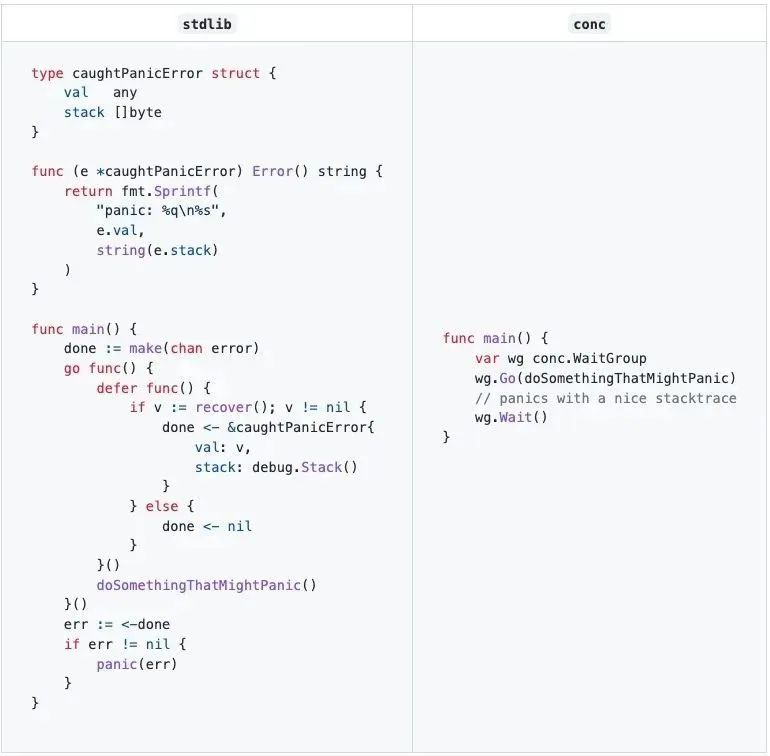
1. WaitGroup 与 Panic
标准库自带 sync.WaitGroup 用于等待 goroutine 运行结束,缺点是我们要处理控制部分
代码里大量的 wg.Add 与 wg.Done 函数,所以一般封装成右侧的库
type WaitGroup struct {
wg sync.WaitGroup
pc panics.Catcher
}// Go spawns a new goroutine in the WaitGroup.
func (h *WaitGroup) Go(f func()) {
h.wg.Add(1)
go func() {
defer h.wg.Done()
h.pc.Try(f)
}()
}
但是如何处理 panic 呢?简单的可以在闭包 doSomething 运行时增加一个 safeGo 函数,用于捕捉 recover
原生 Go 要生成大量无用代码,我司 repo 运动式的清理过一波,也遇到过 goroutine 忘写 recover 导致的事故。conc 同时提供 catcher 封装 recover 逻辑,conc.WaitGroup 可以选择 Wait 重新抛出 panic, 也可以 WaitAndRecover 返回捕获到的 panic 堆栈信息
func (h *WaitGroup) Wait() {
h.wg.Wait() // Propagate a panic if we caught one from a child goroutine.
h.pc.Repanic()
}
func (h *WaitGroup) WaitAndRecover() *panics.RecoveredPanic {
h.wg.Wait()
// Return a recovered panic if we caught one from a child goroutine.
return h.pc.Recovered()
}
2. ForEach 与 Map
高级语言很多的基操,在 go 里面很奢侈,只能写很多繁琐代码。conc封装了泛型版本的 iterator 和 mapper
func process(values []int) {
iter.ForEach(values, handle)
}func concMap(input []int, f func(int) int) []int {
return iter.Map(input, f)
}
上面是使用例子,用户只需要写业务函数 handle. 相比 go1.19 前的版本,泛型的引入,使得基础库的编写更游刃有余
// Iterator is also safe for reuse and concurrent use.
type Iterator[T any] struct {
// MaxGoroutines controls the maximum number of goroutines
// to use on this Iterator's methods.
//
// If unset, MaxGoroutines defaults to runtime.GOMAXPROCS(0).
MaxGoroutines int
}
MaxGoroutines 默认 GOMAXPROCS 并发处理传参 slice, 也可以自定义,个人认为不合理,默认为 1 最妥
// ForEachIdx is the same as ForEach except it also provides the
// index of the element to the callback.
func ForEachIdx[T any](input []T, f func(int, *T)) { Iterator[T]{}.ForEachIdx(input, f) }
ForEachIdx 在创建 Iterator[T]{} 可以自定义并发度,最终调用 iter.ForEachIdx
// ForEachIdx is the same as ForEach except it also provides the
// index of the element to the callback.
func (iter Iterator[T]) ForEachIdx(input []T, f func(int, *T)) {
......
var idx atomic.Int64
// Create the task outside the loop to avoid extra closure allocations.
task := func() {
i := int(idx.Add(1) - 1)
for ; i < numInput; i = int(idx.Add(1) - 1) {
f(i, &input[i])
}
} var wg conc.WaitGroup
for i := 0; i < iter.MaxGoroutines; i++ {
wg.Go(task)
}
wg.Wait()
}
ForEachIdx 泛型函数写得非常好,略去部分代码。朴素的实现在 for 循环里创建闭包,传入 idx 参数,然后 wg.Go 去运行。但是这样会产生大量闭包,我司遇到过大量闭包,造成 heap 内存增长很快频繁触发 GC 的性能问题,所以在外层只创建一个闭包,通过 atomic 控制 idx
func Map[T, R any](input []T, f func(*T) R) []R {
return Mapper[T, R]{}.Map(input, f)
}func MapErr[T, R any](input []T, f func(*T) (R, error)) ([]R, error) {
return Mapper[T, R]{}.MapErr(input, f)
}
Map 与 MapErr 也只是对 ForEachIdx 的封装,区别是处理 error
3. 各种 Pool 与 Stream
Pool 用于并发处理,同时 Wait 等待任务结束。相比我司现有 concurrency 库
增加了泛型实现 增加了对 goroutine 的复用 增加并发度设置(我司有,但 conc 实现方式更巧秒) 支持的函数签名更多
先看一下支持的接口
Go(f func())
Go(f func() error)
Go(f func(ctx context.Context) error)
Go(f func(context.Context) (T, error))
Go(f func() (T, error))
Go(f func() T)
Go(f func(context.Context) (T, error))
理论上这一个足够用了,传参 Context, 返回泛型类型与错误。
Wait() ([]T, error)
这是对应的 Wait 回收函数,返回泛型结果 []T 与错误。具体 Pool 实现由多种组合而来:Pool, ErrorPool, ContextPool, ResultContextPool, ResultPool
func (p *Pool) Go(f func()) {
p.init() if p.limiter == nil {
// No limit on the number of goroutines.
select {
case p.tasks <- f:
// A goroutine was available to handle the task.
default:
// No goroutine was available to handle the task.
// Spawn a new one and send it the task.
p.handle.Go(p.worker)
p.tasks <- f
}
}
......
}
func (p *Pool) worker() {
// The only time this matters is if the task panics.
// This makes it possible to spin up new workers in that case.
defer p.limiter.release()
for f := range p.tasks {
f()
}
}
复用方式很巧妙,如果处理速度足够快,没必要过多创建 goroutine
Stream 用于并发处理 goroutine, 但是返回结果保持顺序
type Stream struct {
pool pool.Pool
callbackerHandle conc.WaitGroup
queue chan callbackCh initOnce sync.Once
}
实现很简单,queue 是一个 channel, 类型 callbackCh 同样也是 channel, 在真正派生 goroutine 前按序顺生成 callbackCh 传递结果
Stream 命名很差,容易让人混淆,感觉叫 OrderedResultsPool 更理想,整体非常鸡肋
超时
超时永远是最难处理的问题,目前 conc 库 Wait 函数并没有提供 timeout 传参,这就要求闭包内部必须考滤超时,如果添加 timeout 传参,又涉及 conc 内部库并发问题题
Wait() ([]T, error)
比如这个返回值,内部 append 到 slice 时是有锁的,如果 Wait 提前结束了会发生什么?
[]T 拿到的部分结果只能丢弃,返回给上层 timeout error
Context 框架传递参数
通用库很容易做的臃肿,我司并发库会给闭包产生新的 context, 并继承所需框架层的 metadata, 两种实现无可厚非,这些细节总得要处理
小结
代码量不大,感兴趣的可以看看。没有造轮子的必要,够用就行,这种库写了也没价值
参考资料
conc: https://github.com/sourcegraph/conc,
推荐阅读
如有侵权请联系:admin#unsafe.sh