写论文需要用到CNVD漏洞库的数据,然而,该页面有反爬机制,无法抓取全部数据,因此,使用js绕过反爬,实现效果如下:
CNVD共享漏洞爬虫效果
可以直接到GitHub查看完整代码,欢迎留言点赞打赏提issue点star
环境
windows 10 Chrome浏览器 Sublime Text 3代码编辑器
前期准备
注册该网页账号并登陆即可
需求分析
首先,我们需要该漏洞库的全部漏洞数据,但是,使用python书写爬虫会被反爬机制识别到,从而无法自动大量下载数据
这里,发现该网页有共享的xml数据
img 共享漏洞
因此,我们考虑从这里做文章
然鹅,一个个点击下载也十分耗时,因此,考虑使用js脚本进行下载
这里有两个思路:
一是分别控制脚本挨个点击链接并翻页 二是直接请求每个链接获得数据
这里采用第二种思路,通过查看链接发现其均为 https://www.cnvd.org.cn/shareData/download/+一个数字的形式,因此,直接使用循环遍历请求即可
代码编写
确定了思路之后,直接开始编写代码,但是遇到了一个问题,就是浏览器无法通过js请求直接保存为本地文件,这里借鉴了一篇博客,使用FileSaver.js这个脚本来实现js下载文件到本地
FileSaver.js
该脚本代码如下:
/* FileSaver.js
* A saveAs() FileSaver implementation.
* 1.3.2
* 2016-06-16 18:25:19
*
* By Eli Grey, http://eligrey.com
* License: MIT
* See https://github.com/eligrey/FileSaver.js/blob/master/LICENSE.md
*/ /*global self */
/*jslint bitwise: true, indent: 4, laxbreak: true, laxcomma: true, smarttabs: true, plusplus: true */
/*! @source http://purl.eligrey.com/github/FileSaver.js/blob/master/FileSaver.js */
var saveAs = saveAs || (function(view) {
"use strict";
// IE <10 is explicitly unsupported
if (typeof view === "undefined" || typeof navigator !== "undefined" && /MSIE [1-9]\./.test(navigator.userAgent)) {
return;
}
var
doc = view.document
// only get URL when necessary in case Blob.js hasn't overridden it yet
, get_URL = function() {
return view.URL || view.webkitURL || view;
}
, save_link = doc.createElementNS("http://www.w3.org/1999/xhtml", "a")
, can_use_save_link = "download" in save_link
, click = function(node) {
var event = new MouseEvent("click");
node.dispatchEvent(event);
}
, is_safari = /constructor/i.test(view.HTMLElement) || view.safari
, is_chrome_ios =/CriOS\/[\d]+/.test(navigator.userAgent)
, throw_outside = function(ex) {
(view.setImmediate || view.setTimeout)(function() {
throw ex;
}, 0);
}
, force_saveable_type = "application/octet-stream"
// the Blob API is fundamentally broken as there is no "downloadfinished" event to subscribe to
, arbitrary_revoke_timeout = 1000 * 40 // in ms
, revoke = function(file) {
var revoker = function() {
if (typeof file === "string") { // file is an object URL
get_URL().revokeObjectURL(file);
} else { // file is a File
file.remove();
}
};
setTimeout(revoker, arbitrary_revoke_timeout);
}
, dispatch = function(filesaver, event_types, event) {
event_types = [].concat(event_types);
var i = event_types.length;
while (i--) {
var listener = filesaver["on" + event_types[i]];
if (typeof listener === "function") {
try {
listener.call(filesaver, event || filesaver);
} catch (ex) {
throw_outside(ex);
}
}
}
}
, auto_bom = function(blob) {
// prepend BOM for UTF-8 XML and text/* types (including HTML)
// note: your browser will automatically convert UTF-16 U+FEFF to EF BB BF
if (/^\s*(?:text\/\S*|application\/xml|\S*\/\S*\+xml)\s*;.*charset\s*=\s*utf-8/i.test(blob.type)) {
return new Blob([String.fromCharCode(0xFEFF), blob], {type: blob.type});
}
return blob;
}
, FileSaver = function(blob, name, no_auto_bom) {
if (!no_auto_bom) {
blob = auto_bom(blob);
}
// First try a.download, then web filesystem, then object URLs
var
filesaver = this
, type = blob.type
, force = type === force_saveable_type
, object_url
, dispatch_all = function() {
dispatch(filesaver, "writestart progress write writeend".split(" "));
}
// on any filesys errors revert to saving with object URLs
, fs_error = function() {
if ((is_chrome_ios || (force && is_safari)) && view.FileReader) {
// Safari doesn't allow downloading of blob urls
var reader = new FileReader();
reader.onloadend = function() {
var url = is_chrome_ios ? reader.result : reader.result.replace(/^data:[^;]*;/, 'data:attachment/file;');
var popup = view.open(url, '_blank');
if(!popup) view.location.href = url;
url=undefined; // release reference before dispatching
filesaver.readyState = filesaver.DONE;
dispatch_all();
};
reader.readAsDataURL(blob);
filesaver.readyState = filesaver.INIT;
return;
}
// don't create more object URLs than needed
if (!object_url) {
object_url = get_URL().createObjectURL(blob);
}
if (force) {
view.location.href = object_url;
} else {
var opened = view.open(object_url, "_blank");
if (!opened) {
// Apple does not allow window.open, see https://developer.apple.com/library/safari/documentation/Tools/Conceptual/SafariExtensionGuide/WorkingwithWindowsandTabs/WorkingwithWindowsandTabs.html
view.location.href = object_url;
}
}
filesaver.readyState = filesaver.DONE;
dispatch_all();
revoke(object_url);
}
;
filesaver.readyState = filesaver.INIT;
if (can_use_save_link) {
object_url = get_URL().createObjectURL(blob);
setTimeout(function() {
save_link.href = object_url;
save_link.download = name;
click(save_link);
dispatch_all();
revoke(object_url);
filesaver.readyState = filesaver.DONE;
});
return;
}
fs_error();
}
, FS_proto = FileSaver.prototype
, saveAs = function(blob, name, no_auto_bom) {
return new FileSaver(blob, name || blob.name || "download", no_auto_bom);
}
;
// IE 10+ (native saveAs)
if (typeof navigator !== "undefined" && navigator.msSaveOrOpenBlob) {
return function(blob, name, no_auto_bom) {
name = name || blob.name || "download";
if (!no_auto_bom) {
blob = auto_bom(blob);
}
return navigator.msSaveOrOpenBlob(blob, name);
};
}
FS_proto.abort = function(){};
FS_proto.readyState = FS_proto.INIT = 0;
FS_proto.WRITING = 1;
FS_proto.DONE = 2;
FS_proto.error =
FS_proto.onwritestart =
FS_proto.onprogress =
FS_proto.onwrite =
FS_proto.onabort =
FS_proto.onerror =
FS_proto.onwriteend =
null;
return saveAs;
}(
typeof self !== "undefined" && self
|| typeof window !== "undefined" && window
|| this.content
));
// `self` is undefined in Firefox for Android content script context
// while `this` is nsIContentFrameMessageManager
// with an attribute `content` that corresponds to the window
if (typeof module !== "undefined" && module.exports) {
module.exports.saveAs = saveAs;
} else if ((typeof define !== "undefined" && define !== null) && (define.amd !== null)) {
define("FileSaver.js", function() {
return saveAs;
});
}
下载共享漏洞
首先,封装函数以调用FileSaver.js:
var downloadTextFile = function(mobileCode,a) {
if(!mobileCode) {
mobileCode = '';
} var file = new File([mobileCode], a+".txt", { type: "text/plain;charset=utf-8" });
saveAs(file);
}
然后,因为该页面使用了jQuery,因此可以直接使用封装好的ajax请求资源链接,书写代码循环遍历漏洞库:
var a = 242;
var timer = setInterval(function(){
a = a+1;
if(a>733){clearInterval(timer)}
$.ajax({method:'GET',url:'/shareData/download/'+a,success:function(res){
downloadTextFile(res,a)}}
)}, 2000)
a为资源链接后面的数字,经过观察,从242开始,到733结束,结束的数字根据最新的漏洞xml链接而定,鼠标放在链接上,页面左下角就会显示链接:
查看最新的资源链接
末尾的2000表示每隔2秒发送一次请求
运行代码
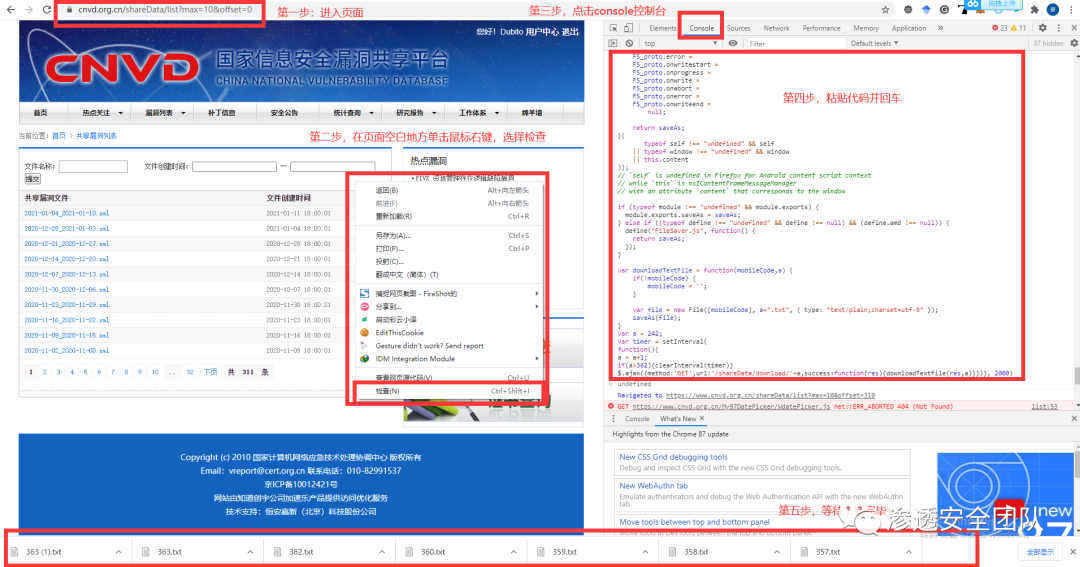
打开CNVD漏洞库的页面 鼠标右键单击检查 点击 console控制台复制上述代码(三段代码合并在一起即可),也可以直接到GitHub下载完整代码复制(其中spider.js为完整js代码,filter为后续过滤结果的代码,欢迎留言点赞打赏提issue点star),粘贴到控制台中,按下回车,代码开始运行 静等下载完毕即可,下载的文件存放在浏览器设定的下载路径里
运行代码步骤示意图
过滤结果
下载完成后,发现有一些资源为空,大小仅有1kb:
初始结果
因此,书写python将这些结果过滤掉:
import osdef file_path(path):
for (root, dirs, files) in os.walk(path):
for file in files:
del_small_file(root + '/' + file)
def del_small_file(file_name):
size = os.path.getsize(file_name)
file_size = 2 * 1024
if size < file_size:
os.remove(file_name)
if __name__ == '__main__':
path = r'./CNVD'
file_path(path)
其中,path为存放文件的地址
完成结果
至此,CNVD漏洞库爬取完成,耗时大概10分钟,经过过滤,共成功抓取文件311个:
爬取结果
和网页上的原数据对比:
CNVD共享数据页面
数目吻合,表明我们已经爬取了该页面的所有共享数据
- END -https://www.jianshu.com/p/1d0f634f0c86★
欢 迎 加 入 星 球 !
代码审计+免杀+渗透学习资源+各种资料文档+各种工具+付费会员
进成员内部群
星球的最近主题和星球内部工具一些展示
关 注 有 礼
还在等什么?赶紧点击下方名片关注学习吧!
推荐阅读
如有侵权请联系:admin#unsafe.sh